
数据挖掘技术在医院逃费预测分析中的应用
2009-01-20 01:56刘新宇
中国集体经济 2009年11期
刘新宇
摘要:文章论述了关联规则以及贝叶斯算法在医院住院患者逃费预测分析中的实现原理及应用,阐述了属性权重分析方法、分类分析进行逃费预测的实现。
关键词:商业智能;贝叶斯算法;关联规则;医院信息系统。
一、引言
医院的信息化建设在商业智能领域属于初级阶段,商业智能针对医院信息系统中所产生的庞大数据,通过BI所提供的各种强大的分析功能进行多角度、多层次的分析,为医院的科学管理和科学决策提供有价值的信息资源,真正实现医院全方位智能化管理,这将是医院信息化的大势所趋。
二、需求分析
从业务发展角度看,医院作为救死扶伤的机构承担着治病救人的社会职责。但另一方面,作为经营性实体,医疗机构同时也要对就诊者收费。由于种种原因,不少医院不同程度地面临着各式各样的欠逃费现象,医疗收费难成为不少医院的隐痛,为此本文将通过数据挖掘技术实现逃费分析预测模型,这是解决这些问题的第一步。纵观医院历年来的逃费记录来看,每年都有大量的逃费患者,包括急诊救治、住院、术后等各种状况,在现有医疗体制的大环境下,对逃费概率较高的患者需要多加关注,从管理的层面尽可能地将逃费的现状在一定程度上改善。逃费预测分析主要应用思路就是基于现有的医院信息系统历年的数据,采用数据挖掘模型的关联规则从多方位、多角度形成出逃费的模型,并据此模型对现有住院患者进行逃费分析,并将分析结果提供给护士以及相应管理人员,提供管理依据。
三、设计方案
(一)数据仓库与数据挖掘
数据仓库是一种管理技术,它将分布在企业中的异构数据集成在一起,实现数据的采集、归纳和处理,使医院的业务工作环境和信息分析环境相分离,为数据挖掘的应用奠定基础。把异构的数据抽取、清理、转载和更新到数据仓库中,是医院数据挖掘应用的基础。
(二)建立逃费影响因素的关联模型
1、数据准备和属性权重分析。数据准备需要做的工作主要为:使用数据提取、转换和装载工具基于事务型数据库建立逃费相关的主题数据仓库,使用数据有效性过滤方法过滤掉不完整的记录,使用数字规范化方法把逃费的结果归纳成布尔值(0不逃费,1逃费),在数据处理完毕后,利用Microsoft Naive Bayes算法找出各住院相关的属性影响逃费的权重。权重是根据对应属性取不同值时,影响病人逃费的概率统计。其中,权重大于零的属性被认为是与逃费相关的属性,权重小于等于零的属性被认为是对逃费没有影响的属性。下文针对权重大于零的属性,利用关联规则进行相关性分析。
2、关联规则基本概念。设I={i1,i2,i3,…,in}是事件全集。设集合D是事件的集合(D?奂I)。A、B是两个事件,关联规则是形如A→B的蕴涵式,其中A∈I,B∈I。规则A→B在事件集D中成立,具有支持度s,其中s是D中的事件包含A∪B(A和B同时发生)的概率,记为P(A∪B)。规则A→B在事件集D中具有置信度c,c是在D中包含事件A的条件下也包含B的概率,即条件概率P(B|A)。分别记为:Support(A→B)=P(A∪B)Confidence(A→B)=P(B|A)。
3、Microsoft关联规则的应用。关联规则在应用中考虑的是事件的存在与不存在,即布尔值0或1,所以它是布尔关联规则。根据规则中涉及的数据维可以分为单维关联规则和多维关联规则。对于使用关联规则中的项或属性每个只涉及一个维的方法,是单维关联规则。
例1:RA→IsEscape(逃费):表示入院来源为A的病人逃费情况为逃费(其中支持度和置信度省略)。符号说明:RA——入院来源A,HB——户籍B,MA——医保类型A,JB——职业类型B,其他类推;下文均符合这个约定。
同样,对于使用多个维度进行关联的分析的方法,称为多维关联规则。
例2:RA∧HD→IsEscape(逃费):表示入院来源为A并且户籍属于D的病人,逃费情况为逃费。
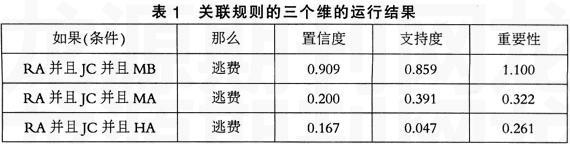
在关联分析模型中的维数可以任意地进行指定,不过指定的维数与数据挖掘进行的速度是成反比的,而且大于3个维度的置信度将会非常小,模型具有实际意义的可能性很小。表1是一个3个维度关联分析的运行结果,可以看到不同属性的组合能够影响逃费情况的量化判定。以第一行为例:入院来源为A、职业为C并且医保类型为B的病人逃费的置信度为90.9%,支持度为85.9%。可以看出入院来源为A、职业为C并且医保类型为B的病人逃费概率比较高(90.9%的逃费概率)。
(三)分类分析进行逃费预测
分类分析是针对离散值进行预测的方法,这个方法的天然特性决定了其适合于解决逃费这个布尔值的预测问题。该方法实现采用Naive Bayes算法,该算法所需的运算量小,能够快速生成挖掘模型以发现输入列和可预测列之间的关系。应用分类分析需要三个主要步骤:
第一步:建立预测模型。本例中使用基本属性作为样本属性,同时简化逃费情况的分类,逃费状态只分为逃费和不逃费两类。使用已知分类结果的训练数据集计算出a式中P(Xk|Ci)和P(Ci)的值(i=1,2;1≤k≤5),这些概率已知后,给任一样本X就可以根据a式判定出它属于哪个分类,这样预测模型就建立了。
第二步:模型准确性的评价。利用同样已知分类结果的测试数据集来评价第一步中生成的预测模型,即把测试数据集的预测结果和实际情况进行比较,评价的结果为预测矩阵,行标表示实际发生的结果,列标表示预测的结果,对角线上的数据表示预测模型预测正确的次数,数据部分反对角线上的两个数据是预测结果与实际结果不符的情况发生的次数,同时可以获得模型的准确程度为97.8%。如果对模型不满意,可以通过调整贝叶斯方法入口参数值,重新进行第一步,直到获得满意的准确度。入口参数即为a式中P(Xk|Ci)的人为设定的最小参考值,当P(Xk|Ci)小于设定的入口参数时,P(Xk|Ci)的值由设定的入口参数值替代,这个参数设置的目的是为了保证样本属性k取值为Xk时,把样本预测为属于分类Ci的概率,入口参数通常结合属性权重分析结果设定,入口参数在0-1之间变化。
第三步:预测模型的应用。对模型准确度满意后,就可以将分类模型应用于应用数据集;这里的应用数据集是医院住院数据的病人相关资料信息,但是没有逃费情况的数据集。应用数据集存储在一个数据表中,把这个数据表中的记录分别作为预测模型(a式)的输入预测出病人逃费的结果,可以把预测结果的逃费率与历史上相同情况的逃费率进行比较,判定某个医疗环节是否需要调整以及优化。或者通过预测模型的准确度和某病人的逃费概率,提前针对逃费病人采取措施,以避免逃费情况的发生。
四、结论与建议
在当前的大环境下,我国与国外的医疗信息化的发展步伐相比,还有很多方面需要建设与完善,尤其是在商业智能的应用领域还处于初级阶段状态下,合理、适时的逃费分析预测系统有现实的建设意义。
参考文献:
1、段云峰,李剑威,韩洁,宋美娜.数据仓库基础[M].电子工业出版社出版,2004.
2、邵峰晶,于忠清.数据挖掘原理与算法[M].水利水电出版社,2003.
3、韩家炜.数据挖掘概念与技术[M].机械工业出版社,2006.
(作者单位:上海互联网软件有限公司)
猜你喜欢
计算机世界(2017年38期)2017-09-27
消费导刊(2016年4期)2017-01-10
电脑知识与技术(2016年25期)2016-11-16
数字技术与应用(2016年9期)2016-11-09
科技视界(2016年18期)2016-11-03
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
科技传播(2016年11期)2016-07-20
中小企业管理与科技·下旬刊(2009年4期)2009-06-30
