
基于深度学习的语音识别技术在音频档案数据化中的应用
2024-03-26 02:30杨巍浙江财经大学王茂焕台州市档案馆
浙江档案 2024年2期
杨巍 /浙江财经大学 王茂焕/台州市档案馆
1 引言
音频录像档案[1]是国家机关、社会组织或个人在履行法定职责过程中采用不同记录载体形成的、具有凭证、查考和保存价值并归档保存的以声音或影像为主要呈现方式的信息记录。人工智能技术的发展和应用推动了档案工作数字化转型,“数据化”成为新时代评价智慧档案馆的重要指标,将“档案数字化”转型为“档案数据化”是档案馆现代化管理需要首先解决的问题。音频档案数据化是将传统音频档案中的模拟音频向数字音频转化,并将数字音频的文本内容进行识别、分类、著录和标引等整个过程[2]。音频档案数据化主要包括音频信息文本化[3]、元数据标引和数据库建设等内容[4]。现阶段,纸质档案已经能够通过数字化扫描和OCR识别完成数据化的基础转化工作,而含有丰富语义的音频录像档案因其非结构化存储特性,无法像纸质档案一样批量完成文本识别工作,大量记录珍贵历史记忆的音频档案在档案馆中得不到充分的数据化管理和利用,这成为音频录像在档案大数据时代发挥自身价值的现实屏障。随着深度学习语音识别技术在社会生活和工作领域中的运用日渐成熟,将其引入档案数据化工作场景中,推动档案现代化建设具有重要的现实意义。
语音识别技术是电脑自动辨认或验证发出语音的说话人,将音频语音内容转换成对应的文本的信息技术,包括自动语音识别(automatic speech recognition,ASR)、电脑语音识别(computer speech recognition,CSR)或是语音转文本识别(speech to text,STT)[5]。识别过程如图1,系统核心是音频特征提取模块、声学模块和语言模块。
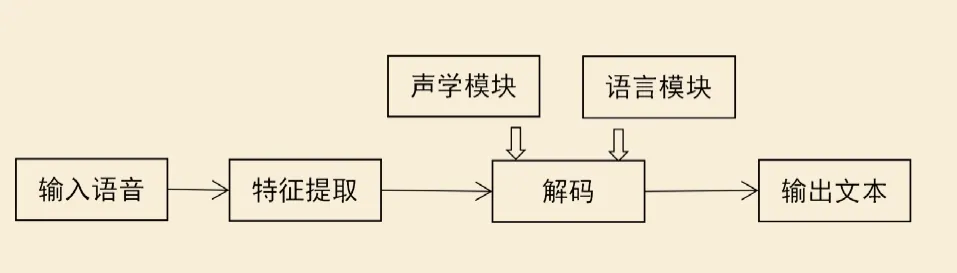
图1 语音识别过程
音频特征提取模块负责根据语音信号波形提取有效的声学特征[6],生成机器可以理解的语言特征向量序列,比如利用梅尔频率MFCC变换抽取原始语音特征,这类技术比较成熟;声学模块利用声学模型负责将语音特征映射成音素,其中音素是最小语音单位[7],比如“普通人”,可以分解成“p, u, t, o, ng, r, e, n”八个音素,声学模型是语音识别技术的核心;语言模块利用语言模型负责基于音素序列预测字符序列的概率,最终选择概率值最大的字符序列作为解码的文本结果,比如以上八个音素可能被预测为“扑通人”“普通仁”“普通人”等字符序列,但是“普通人”的概率最大,这类技术主要依托自然语言处理技术的发展。基于声学模型的技术迭代,其技术发展从GMM-HMM(传统声学模型)、DNN-HMM(神经网络和传统声学融合模型)发展到End-to-End(端到端模型)阶段,深度学习语音识别技术日渐成熟,推动现代社会在多场景中落地应用。
2 语音识别技术在音频档案数据化管理中的研究现状
语音识别技术在图书情报与档案领域中的应用最早可追溯到1994年美国启动的“数字图书馆”项目中,卡耐基—梅隆大学在该项目中负责研究如何将图像、语音和语言识别技术整合起来,使音频和视频具备与文字文献相同的查询、检索、分类和摘要功能,从而实现智能搜索和图像检索的目标[8]。21世纪初,医疗和法律档案系统率先掀起利用语音识别技术进行档案数字化建设的热潮[9],随后,数码音频笔、智能语音录入软件等产品先后问世,其便捷的音频功能和文字转换功能受到了档案工作者的青睐,语音识别法成为和扫描法、人工著录法同样重要的档案数字化方法之一。档案馆将语音识别技术用于口述历史的记录和收集工作之中,同时也广泛用在音视频档案数据转换和整理上[10],如美国互联网档案馆利用语音识别技术对其前总统特朗普电视演讲深度转录,保证美国公民更加直观及时了解特朗普政治观点[11]。
针对传统的模拟音频档案,深度学习语音识别技术能够在音频档案数据化中智能标注,生成的信息比人工标注更加准确、完整和规范[12]。同时深度学习语音识别技术为音频档案检索打开了新的检索思路,音频档案检索从单一的关键词检索上升到大词汇语音识别、字词单元检索、关键词识别和对讲话者检测[13]等基于内容的检索模式。刘涛认为深度学习语音识别技术所拥有的语音转换文本中精准的识别能力、智能的分析音频内容的能力和全内容分析编目能力能解决当前音频档案信息著录有限性和音频档案高需求利用之间的矛盾[14]。总体上看,当前档案领域对语音技术的研究主要集中在音频录像档案收集、编目、检索等环节,而对深度学习的语音识别技术在音频档案数据化中识别率有多大提升和其在档案领域具体的应用场景鲜有深度探讨,本文利用深度学习的语音识别技术deepspeech2_aishell模型对音频数据集进行了实证测试,验证了深度学习语音识别技术识别质量好、识别效率高、准确度精准等优势,同时探讨了深度学习语音识别技术在目前档案领域中的具体应用场景,以期档案领域利用深度学习语音识别技术进行音频档案数据化管理。
3 深度学习deepspeech2_aishell模型在传统模拟音频档案文本化中的实证测试
传统音频档案文本化是音频档案数据化工作中的首要任务,为了进一步加强验证,笔者以linux系统为例,进行deepspeech2_aishell模型的部署,命令行可以直接在系统的终端shell上执行,开发python代码进行最终的语音识别,input.wav为原始音频文件,text为最终输出的文本内容(如图2)。选取《中华人民共和国档案法》总则中的前5条内容,利用朗读工具生成5个音频文件,然后利用deepspeech2_aishell模型分别进行语音识别,5段音频内容,3条错误率为0%,2条错误率在3%以下,最终识别准确率如表1所示,通过上述实证测试可知,目前人工智能语音识别模型的识别结果,已经达到了比较高的准确率,在实际应用中有很大的可行性。

表1 语音模型识别结果分析

图2 deepspeech2_aishell模型的部署程序
4 深度学习语音识别技术在音频档案数据化中的应用
当前,国内大部分档案馆在传统音频数字化中采用人工转写方式,效率不高,而利用深度学习语音识别技术,可根据不同的功能需求,设置不同的语音指令和文本输出来进行交互,批量化、高精度、不间断地、快速完成音频档案信息到文本形式的转化,不但方便检索和编辑,还提高了音频档案管理的效率,节省了人力成本。同时,语音识别技术还可以对音频资料进行自动分类和标签化,进一步提高了音频档案的检索效率和准确性。所以,深度学习语音识别技术在音频档案数据化的各方面都有较大的应用价值。
4.1音频档案数据库建设
对音频档案著录标引,建成数据库是档案数字化工作的基本需求。传统音频档案数字化参照当前行业标准或国家标准通过人工听写、分类、标识,过程烦琐、编目简单粗放[15],难以全面描述录像档案所载信息。一方面,利用深度学习语音识别技术将录像档案文本化后,对文本中的所包含的内容、场景、人物、事件、地点、结果等资源属性进行结构化的描述,构建以人物、事件为核心属性的能被机器全文识别的数据库,并设定相应的语音指令,实现音频全内容检索。另一方面,语音识别技术还能对语音中的不同元素(如音色、音调、节奏等)的分类和特定词汇、短语或句子的标注和描述,促使不同模态的音频档案数据结构化存储。利用深度学习语音识别技术建设音频档案数据库的模式,是在现有录音档案数据库系统上进行简单扩展就能实现,是音频档案数据化发展的方向。
4.2音频档案数据知识化加工
语音识别技术为音频档案内容知识化加工和二次创作提供了千载难逢的机遇。目前,音频档案数字化处理不足,语义理解深度不够、音频档案信息复杂多样等问题导致音频档案知识化效率和质量受到限制。而利用深度学习语音识别技术对文本化的信息进行上下文理解和语义分析,然后自动化著录音频的主题、概念、事件、观点等信息,自动生成内容摘要,聚合音频数据,构建知识图谱,形成知识体系,为音频档案内容挖掘和知识化加工创造条件。京剧名家档案故事化手游开发项目[16],其中一个重要的组成部分就是收集京剧名家档案史料、音像档案与口述档案等音频档案进行知识化加工,推进音频档案故事化呈现,提高音频档案内容的张力。比如项目选取了一段关于荀慧生先生的珍贵音频档案,为了全方位呈现这位艺术家的风采,项目团队将音频档案进行了故事化处理。他们根据音频内容,制作了可视化知识图谱和一段动画视频,再现了荀慧生先生舞台上的场景,同时,项目团队注重音频档案故事与受众的交互方式,以互动游戏的形式实现对京剧名家档案数据的故事化呈现,通过这种音频档案故事化的方式,观众不仅能够听到珍贵的历史音频档案,还能够通过视觉和听觉的双重呈现,更好地理解档案的背景和意义。
4.3音频档案视听服务平台建设
语音识别技术可以为音频档案视听服务平台的建设提供有力支持。语音识别技术可以帮助实现语音与文字的快速转换,通过提高音频档案数字化处理效率,完善音频档案数据库建设,构建音频档案知识化体系、嵌入语音导航等多个步骤,可以建立一个高效、便捷、智能的音频档案视听服务平台,为档案用户特别是有视听障碍的特殊群体提供更加人性化的查档、用档服务,提升用户体验。目前,国家图书馆基于智慧化和新媒体技术手段研发和建设的影音视听资源知识服务平台[17],该平台创新资源生产、加工、组织与应用,运用智慧化和新媒体技术,优化音视频资源管理机制,深入挖掘资源关联和内容价值。同时,提供个性化知识服务,适配多终端设备,提升视听服务效益,助力智慧图书馆的进步与发展。
4.4音频档案信息在线扩展泛化
为了尽可能丰富和完善音频档案背景信息,深度学习语音识别技术为传统音频档案的传播、共享等在线扩展泛化过程创造了条件。第一,利用深度学习语音识别技术转变了音频档案的存在模态,将二进制的符号转变成可标识的结构化信息,以便于音频档案信息存储、传输和在线播放。第二,通过数据分析和挖掘技术提升音频档案的易读性,将音频档案中的数据信息多角度、多层次地被标注出来,提高音频档案的被理解力。第三,利用云计算分布存储技术保证音频档案数据的易用性,建成音频档案集中管理数据库,设定开放权限并连接互联网,用户通过身份认证可以即时在线访问音频档案数据,进而提高音频档案的利用价值和音频档案信息传递效率。第四,利用流媒体传输和智能推荐技术,将通过开放审核的音频档案及时通过流媒体主动推送到用户的设备上,面向社会及时分享音频档案内容,同时加强和用户的互动,收集音频档案相关的信息,不断补充和完善原有音频档案信息内容,能够更加真实完整全方位还原音频档案所记载的历史事件。荷兰国家档案馆在“De ijsberg zichtbaar maken”(“让冰山可见”)[18]人工智能技术转录档案项目中初步尝试这种模式,该项目通过馆藏档案数字化和新媒体信息技术,将荷兰皇室的档案、绘画、手稿、照片、音频等多模态档案数据聚合,利用新媒体技术向公众推送荷兰历史和文化,公众可以根据自己的知识背景和掌握的历史信息在线反馈给图书馆,图书馆工作人员根据反馈信息及时补充档案内容,在线扩展泛化模式成为馆藏补充资源、修正资源、完善资源的新模式,截至2023年约有200万份资源中部分资源已通过在线扩展模式进行了更正、更新和实体资料的补充和完善。
在人工智能技术发展的浪潮中,深度学习语音识别技术逐渐成熟并广泛应用社会各领域,也推动档案数字化建设进入新的数据化阶段。目前,我国档案馆内馆藏大量具有珍贵价值的模拟音频格式的档案和部分数字化设备生成的音频档案,亟需数字化转录和数据化挖掘,人工智能深度学习语音识别技术具有智能化、低成本、高识别率和高精准率等特点,能够解决音频档案数据化工作中的困境,深度学习语音识别技术不局限于转存音频档案,同时创新了档案工作方式,确保音频档案数据化转化的质量,有利于更加充分挖掘音频档案的价值。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
家庭影院技术(2018年11期)2019-01-21
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
小说界(2018年5期)2018-11-26
电子制作(2018年19期)2018-11-14
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
