
DeepSeek如何影响汽车业?
2025-02-27 00:00:00包校千陈亮赵成李皙寅晏玉婷
财经 2025年4期

汽车正在变得更聪明。不再需要生硬地反复唤醒车机,人与车的对话越来越自然,仿佛车内多了一位智能助理。同时,自动驾驶也变得更加流畅和可靠。更重要的是,这些原本专属于高端豪华车的体验,正逐渐下探到普惠车型。
这些场景的实现并不遥远,越来越多的汽车产业界人士将希望寄托于AI技术。2025年春节期间,DeepSeek风潮吹入汽车行业,让上述畅想离现实更近一步。
2月10日,比亚迪董事长王传福表示,新车全系搭载智驾,接入DeepSeek,高阶智驾开始覆盖10万元以下车型。
越来越多的车企宣布接入DeepSeek大模型。从2月8日至10日的短短三天内,吉利、岚图、东风、智己、长安,这样的名单正越来越长,近20家车企已在智舱端或AI运营领域深度融合DeepSeek。
在当前汽车行业中,头部车企在智能化领域的竞争已趋同化,难以凸显差异或维持领先优势。面对这一现状,整个行业都在热切期盼更高级别的智能化技术涌现,为汽车行业带来更为显著和可观的变革。在这样的背景下,像DeepSeek这样的AI技术逐渐成为车企眼中的“宠儿”。
长期以来,车企在智能化布局中面临高昂成本,主要源于对高算力芯片及算法资源的依赖。而以DeepSeek为代表的低算力方案,通过优化算法结构,大幅降低了成本,为汽车智能化的普及提供了突破口。
突破交互瓶颈:汽车能深度听懂“人话”
汽车里的按键越来越少了,按照车厂的美好畅想,汽车能听懂乘员指令,不但能够调温度、座椅角度、设定路线,还能辅助决策、理顺日程,成为一个聪明的车载助理。现实并没那么美好,现有车机系统需要逐一呼叫车辆小名,回答内容简单机械,既不方便也不智能,甚至不如挂在支架上的手机。
为了打破如上瓶颈,车企将宝押在DeepSeek等新技术上,希望借此更好地理解乘员提出的模糊指令,进而优化车辆控制、人车交流、售后等各种体验。不只是优化既有功能体验,车企更有意借助DeepSeek完善自己的人工智能系统,以便展开联合训练。
更懂乘员,能够听懂并说人话的智能座舱,这恰恰是DeepSeek“上车”的抓手。目前,DeepSeek尚处于开发阶段,其中DeepSeek-R1作为推理模型,其主要作用体现在智能座舱的语言训练中。
开源证券研报认为,座舱是智能业务助理的载体,车企纷纷探索有关应用落地。R1模型有望带来更优的座舱交互体验,座舱智能业务助理将实现前所未有的功能提升,并有望孕育全新应用场景。同时其对算力的节约也让模型更容易在座舱端本地化部署,实现更优的体验。
结合最近各大车企公布的DeepSeek大模型融合情况,可以看到对于智能座舱的颠覆具体表现为以下几点:对话更丝滑,更像人与人交流,而不再机械和呆板,突破以往一问一答模式;同时,更懂车和乘员,能够基于地理位置、气象信息、用户过往习惯等,更聪明地控制车辆、建议售后维保等。
摆脱“算力霸权”:低算力能否撼动英伟达芯片地位
DeepSeek所采用的“蒸馏法”,允许在非安全领域内减少对高算力芯片的依赖,用国产工规或消费级芯片实现替代,进一步降低整体成本。
数据蒸馏是一种业内常见的技术,通过算法和策略对原始复杂数据进行去噪、降维和提炼,从而得到更精炼、有用的数据。其核心目标是将复杂模型的知识提炼到简单模型中。
试举一例,以前的大模型训练相当于使用题海战术,在大量的数据中训练。而蒸馏就相当于让在题海战术里磨炼过的优秀大模型充当新模型的老师,筛选出有效题目,再让新的大模型训练。
与传统AI训练方法不同,DeepSeek降低成本的关键在于采用了全新的强化学习(RL)方式进行训练,而非依赖于监督微调(SFT)或人工标注数据。这一模式不仅优化了训练效率,更降低了对高端AI芯片的依赖,颠覆了算力市场一贯的发展逻辑。
高性能、低成本是DeepSeek模型开发的准则。其推理模型R1通过采用一种名为“动态蒸馏”的技术,在已有的通用大模型V3基础之上浓缩为精华版的小模型。由此一来,在没有超强算力的情况下也能实施部署。
也就是说,DeepSeek向行业证明了一件事:不用堆叠算力也可以搞好大模型,AI芯片霸权或就此终结。
回看2024年,国产智驾集体进入“端到端”时代,有头部智驾解决方案企业CEO(首席执行官)表示,其应用深度的差异仿佛代表了技术领先性。当时,面对AI的高门槛和复杂性,国内的智驾玩家普遍以特斯拉为范式,囤算力、囤数据,不断训练、不断迭代。
在此之前,不少车企有意投入巨资,大量购买乃至囤积算力卡。理想智驾研发副总裁郎咸朋曾表示,伴随着智驾参数量的持续扩大,以及未来智驾向L4级的深入,理想每年单在算力集群上的花销就达到10亿美元左右(折合人民币72.8亿元)。
如今,把钱砸向算力不再是唯一的解题思路,许多AI转型计划因受限于算力、算法和成本而面临困境,DeepSeek的方案则为这些企业提供了本地化部署大模型的机会,自动驾驶领域同样如此。有分析认为,DeepSeek开源、低成本、低算力的模型,有可能成为新能源汽车和自动驾驶行业智能化跃迁的催化剂。
DeepSeek作为多模态大模型的代表,其核心价值在于通过端侧高效推理能力,推动智能驾驶系统从“感知驱动”向“认知驱动”升级。在黑芝麻智能首席市场营销官杨宇欣看来,有助于降低开发门槛:黑芝麻智能专为下一代AI模型设计的A2000芯片,已支持当前主流大模型的部署,通过软硬件协同优化,帮助车企减少算法适配成本,加速功能迭代。
DeepSeek的算法为低成本训练提供了解题思路,不过短期内要用DeepSeek+国产芯片的方案去替代英伟达芯片难度不低。罗兰贝格全球合伙人时帅就向《财经》指出,目前全球80%以上的大模型是基于英伟达芯片训练的。
算法魔力:DeepSeek如何重塑智驾生态?
自2022年ChatGPT爆火后,汽车企业便开始陆续推动AI大模型上车。部分新势力车企还发布了自有AI大模型,如2023年6月理想汽车发布了Mind GPT;小鹏汽车发布了XGPT灵犀大模型。业内普遍认为,DeepSeek的出现不仅将迅速推动大模型上车,更会加速推动高阶智驾落地。
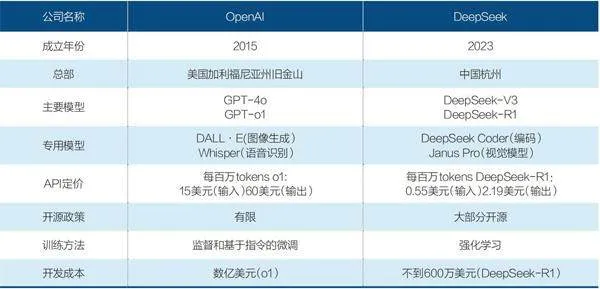
OpenAI和DeepSeek主要信息对比
在全球大模型竞赛中,以往方法是围绕“数据、算法、算力”三要素中的算力进行突破,通过不断堆高算力水平来实现大模型训练和推理的加速。就像在一场跑步比赛中,大家都在试图通过更强的体能来赢得比赛。而DeepSeek的出现,打破了这种传统模式。它选择从架构和算法创新入手,就像是跑步比赛中的选手,不再单纯依靠提升体力,而是通过改进跑步姿势、节奏等技巧来提高跑步速度。通过创新的架构和算法,DeepSeek可以在有限的算力与训练成本下,显著提升算力利用效率。
那么,DeepSeek为什么能够做到成本低、算法优,它的技术原理到底好在哪里?
简单地说,DeepSeek之所以在某些方面比其他AI大模型表现更优,不仅仅是因为它采用了高效架构设计、轻量化模型、分布式计算等技术,更重要的是它在技术细节的实现、创新点的结合以及对实际应用场景的深度优化上做得更好。这些技术细节包括算法创新、数据利用、模型优化、场景适配、资源管理、生态整合等方面进行的更深度优化和创新。这些优势不仅体现在技术层面,还体现在对实际应用场景的深刻理解和快速响应能力上。
比如在自动驾驶实验中,真实路测难以覆盖所有危险场景(如行人突然横穿马路)。DeepSeek可以构建高保真的虚拟驾驶场景(如极端天气、突发事故等),通过合成数据训练模型,弥补真实数据中罕见场景的不足。同时生成对抗网络(GAN),包括生成多样化的行人、车辆行为模式等,以提升模型对复杂交通场景的适应能力。
基于此,DeepSeek所构建的虚拟仿真场景数据,可以使模型提前学习应对策略,避免实际路测中的安全隐患。同时,通过云端协同的方式将数据合成,并与仿真训练放在云端完成,车端仅需加载轻量化模型,避免占用车端算力。
在应用于具身智能(如自动驾驶、智能机器人等)场景数据训练过程中,DeepSeek所具备的自我进化能力可以自发地产生一些高级推理行为,如自我反思。并且,它还会重新审视和评估自己之前的推理步骤,以及探索多种解题思路,尝试从不同角度解决问题。这一特殊性能可以很好地被利用在基于基础驾驶场景的泛化设计处理中。
此外,如果将DeepSeek的思维方法应用到自动驾驶中,还可以通过边缘计算在车端部署轻量化模型,实时处理传感器数据(如摄像头、激光雷达),实现低延迟决策。同时辅以增量学习在车端注入新数据持续优化模型。借用DeepSeek流式数据处理方式、辅以边缘计算、在线学习、记忆回放、弹性权重巩固等技术,实现自动驾驶中的实时数据处理与增量学习。
比如,此前车辆在面对某一个危险场景下,已有专家策略是进行障碍物大小识别后,进行绕行避撞,如果此时复现该类似场景,那么就可以通过记忆回放直接调用之前的处理小模型,再次利用绕行避撞策略进行局部端到端的处理。
有业内人士指出,DeepSeek需与传统的自动驾驶技术栈(如控制理论、SLAM、强化学习)深度融合,其核心价值在于解决开放环境下的认知智能问题,而非替代现有感知-决策-控制链路。
在智能化时代,优秀的用户体验、更快的迭代速度和更低的成本,成为车企竞争的关键指标。
国联证券认为,DeepSeek是智驾重要工具。一方面智能驾驶安全边界较高,仍需要较长训练时长保证功能安全;另一方面针对不同车型算力和架构,蒸馏后仍需要完成定向开发。从未来功能实现层面来看,尚未实现智能驾驶功能完整性部署前,DeepSeek的使用或加速缩小各家车企之间的时间差距。实现功能突破后智能驾驶领先企业有望保持用户黏性和高阶功能性能的领先。
10万元智能车的钥匙:智能驾驶向主流车下沉
自动驾驶行业虽然尚未提出结合DeepSeek的相关技术应用,不过低成本、低算力、高性能模式,与当下高阶智驾技术,逐渐向10万元级车型普及的方向相一致。
显而易见,这是DeepSeek带来的积极意义。小鹏汽车董事长兼CEO何小鹏认为,DeepSeek有两个技术细节与小鹏汽车的判断吻合:一是蒸馏技术是有效保存模型能力的方法;二是巨大模型的蒸馏后效果强于小模型的强化学习。
开源证券2月5日的研报指出,DeepSeek-R1模型的诸多优化方法有望为智驾行业所借鉴。目前自动驾驶玩家推动大语言模型甚至视觉语言动作模型(VLA)上车提升智驾算法的认知能力,DeepSeek-R1有望作为优秀的教师模型,将其性能蒸馏给车端模型,进一步提升车端模型的能力。
2024年,中国高阶智驾的渗透率突破了10%。按照中国电动汽车百人会的预测,这一数字将在2025年达到20%,提升近一倍。
而低成本、高性能的开源模型,将加速自动驾驶的迭代周期。传统车企训练自动驾驶模型需三个至六个月,相比之下,DeepSeek的MoE(混合专家)架构可将训练周期压缩至45天。
与DeepSeek的融合,有望受益于DeepSeek R1的算法优化和算力节约,全面提升自动驾驶系统的性能和用户体验,实现科技创新与市场价值的双赢。
可见,在AI技术的驱动下,当下自动驾驶技术已告别硬件堆叠、比拼算力的时代,一场锚定AI融合的高阶智驾、智能座舱“新竞赛”即将拉开帷幕。
DeepSeek不是万能药:大模型落地的挑战
一位国内领先智能驾驶公司技术专家告诉《财经》,目前公司尝试在一些项目中使用DeepSeek-R1。相较于ChatGPT4o模型来说,DeepSeek目前不稳定,对高并发情况(通过设计保证系统能够同时并行处理很多请求)处理不如ChatGPT稳定。
纯语言模型专注于文本数据的处理和生成。而现实物理世界还有图像、视频和音频等多模态,多模态模型可以理解和处理除了文本以外的各种模态。因此,纯语言模型应用场景不如多模态模型广泛。
DeepSeek曾推出过Janus Pro多模态模型,可以将文字生成图片,但应用范围在娱乐领域。上述人士表示,在自动驾驶这种严谨性高、安全系数高的场景中,目前的应用还颇为受限,但是其对自动驾驶研发具有借鉴意义。
不过,能看得出DeepSeek本身也在进化和迭代当中,为此智驾公司对其抱有不小的期待。在杨宇欣看来,DeepSeek有助于显著提升智驾技术中的场景理解能力,具体来说DeepSeek可融合视觉、语音、环境等多维度数据,实现更拟人化的驾驶决策,例如在复杂路口动态调整路径规划,或在突发状况中快速生成安全策略。
除了技术难题待解,如何真正体现技术价值,而不是停留在纸面乃至营销上,这是对于汽车在内的诸多应用级玩家的挑战。
当前车企对包括DeepSeek在内的诸多AI技术的理解和开发还处于初级阶段,技术深度和实际应用仍有很大提升空间。例如部分车企追求营销噱头,将AI功能生硬地堆砌到产品中,不仅未能提升用户体验,反而使消费者对产品的实用性产生怀疑。
当一个又一个大模型在各行各业落地应用,大模型落地似乎没有想象中的那么难,难的是,落地后真正体现出价值。
对于汽车业来说,要持续思考三个问题:车主是否真正提升了用车体验?车企是否真正提升了经营业绩?整个产业生态链是否真正获得了稳定利润?
猜你喜欢
新华月报(2024年7期)2024-04-08 02:10:56
都市人(2023年11期)2024-01-12 05:55:06
卫星应用(2023年1期)2023-02-21 06:51:50
现代经济信息(2022年22期)2022-11-13 18:32:00
学生天地(2020年5期)2020-08-25 09:09:08
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
电子测试(2018年10期)2018-06-26 05:53:36
