
优化初始类中心的自适应K-medoids算法
2025-01-01 00:00:00刘金金
河南师范大学学报(自然科学版) 2025年1期
关键词:特征选择
















摘 要:针对传统的K-medoids聚类算法在聚类时需要随机选择初始类中心且指定聚类数目K,及聚类结果不稳定的问题,提出了一种优化初始类中心的自适应K-medoids算法(adaptive K-medoids algorithm for optimizing initial class centers,CH_KD).其思想是定义了特征重要度,以此筛选出每一簇中最优的代表特征,组成特征子集,并重点研究了传统划分算法的自适应优化与改进.首先,利用特征标准差定义特征区分度,选择出区分度强的特征.其次,利用皮尔逊相关系数度量特征簇中每个特征的冗余度,选择出冗余度低的特征.最后,将特征区分度与特征冗余度之积作为特征重要度,以此筛选出每一簇中最优的代表特征,组成特征子集.实验将所提算法与其他聚类算法在14个UCI数据集上进行对比,结果验证了CH_KD算法的有效性与优势.
关键词:无监督;特征区分度;特征冗余度;CH函数;特征选择
中图分类号:TP391""""" 文献标志码:A""" 文章编号:1000-2367(2025)01-0106-10
聚类算法是将数据集划分成不同的簇,目的是使同一个簇中的样本相异度较低,而不同簇间的样本相异度较高.对于处理大规模无标签数据,聚类算法[1]在数据挖掘领域占据了重要地位,其发展至今已有众多分支,主要分为2大类[2]:层次聚类算法和划分聚类算法.K-medoids算法是其中一种划分聚类算法,由于其划分聚类结构清晰、时间效率高而得到了广泛的应用.此算法首先经过簇数量的选择,然后选取合适的初值,最后完成初始化过程后进行聚类.K-medoids算法是基于K-means算法的一种改进算法.
K-medoids聚类算法的优点是能够处理大型数据集,结果簇相当紧凑,且簇与簇之间分明清晰.但缺点是传统的K-medoids聚类算法随机选择初始类中心,而且需要人为指定聚类数目K,导致聚类结果不稳定.由于聚类算法初始化对结果的影响非常大,所以现有方法大多是将其他算法与K-medoids结合使用,这样可以有效地提高K-medoids算法在聚类的准确率和效率,快速准确地找到最佳簇中心.
赵成[3]提出一种基于聚类和中心向量的快速K近邻分类算法.王全民等[4]将经典的果蝇优化算法与K-medoids算法结合为一种新型的K-medoids算法,使得此新算法的聚类效果更好.魏霖静等[5]将K-medoids算法与聚类簇思想结合起来,对每个聚类簇进行混合蛙跳算法优化.管雪婷等[6]提出一种优化萤火虫的K-medoids聚类算法且融合了云模型,可以有效地抑制K-medoids算法易陷入局部最优的问题.管雪婷[7]提出一种基于改进的萤火虫优化的K-medoids算法.杨楠[8]提出一种基于改进布谷鸟算法的K中心点聚类算法.刘叶等[9]将K-means算法与K-medoids算法相结合.李莲[10]提出了一种基于改进的人工蜂群的K-medoids聚类算法.谭成兵等[11]使用布谷鸟优化的K-medoids算法进行聚类,通过多节点并行聚类的方式可以提高聚类效率.李欣宇等[12]将K-medoids算法与密度聚类算法的思想结合,减少算法执行的时间且提高聚类结果的准确度.但这些算法存在特征维度高与冗余度高的问题.
针对K-medoids算法初始类中心的问题,可以利用类内误差平方和选取初始类中心的候选集[13],对K-medoids的初始类中心进行优化.针对文献[14-15]中存在的K值问题,根据文献[16]中的方法,可利用基于中位数的轮廓系数或CH函数来确定合适的K值.
本文的算法思想如下.首先,设计了算法1和算法2来解决选取初始类中心候选集和K-medoids聚类算法最佳聚类数目K的问题,由此提出一种优化初始类中心的自适应K-medoids算法(adaptive K-medoids algorithm for optimizing the initial class center,CH_KD).然后,使用CH_KD算法将特征集划分簇.最后,特征选择根据定义的特征重要度来选取每个特征簇中最具有代表性的特征,组成最终的特征子集.
本文的特征选择是基于优化类中心的自适应K-medoids算法的无监督特征选择,其目的是降低维度,保留具有高分类信息且冗余度低的特征[17].利用优化类中心的自适应K-medoids算法对特征进行聚类,使相似(冗余)特征聚为一类,以便选出冗余度低且区分度强的特征子集.为了选出区分度强的特征,利用特征标准差定义特征区分度;为了选出冗余度低的特征,利用皮尔逊相关系数度量[18]特征簇中每个特征的冗余度;并以特征区分度和特征冗余度之积定义特征的重要度,以此选出每一簇中最优的代表特征,组成特征子集.
实验在MATLAB R2016b上进行了14个数据集上的对比,实验结果表明,本文所提的CH_KD算法与K-medoids、K-means以及KCOIC进行实验对比后发现,CH_KD算法聚类结果最优;CH_KDFS算法与其他算法相比,特征个数越少且AUC(Aera under the curve)值高,表明分类效果好.
1 K-medoids算法
K-medoids算法是一种迭代重定位的算法,基本思想是:首先,从数据集中随机选择K个样本作为初始类中心.其次,按距离最近原则将其余的样本划分到离其最近的类中心所在的簇中.然后,从每个簇中选择使得类内误差平方和最小的样本作为新的类中心.最后,直到类中心不再变化或者达到指定的迭代次数时,算法结束.
给定样本xi和xj,则样本xi和xj之间的欧氏距离
式中,q为样本的特征数目,xif表示样本xi在第f个特征上的取值.样本之间的距离越近,则表明2样本之间越相似,反之则越相异.
类内误差平方和
式中k=1,2,…,K,K表示类别数目,Ck表示第k类样本集合,x为Ck的样本,Ok表示Ck的类中心,样本x和Ok的相异度d(x,Ok)以欧氏距离度量.SEC的值越小则表示算法的聚类效果越好.
2 K-medoids算法自适应优化
传统的K-medoids聚类算法随机选择初始类中心,而且需要人为指定聚类数目K,但选择的初始类中心和聚类数目K决定着聚类的结果,所以导致K-medoids算法的聚类结果不稳定.针对K-medoids算法初始类中心的问题,受文献[13]的启发,可以利用类内误差平方和选取初始类中心的候选集,对K-medoids的类中心进行优化.针对K-medoids算法K值的问题,受文献[16]的启发,可利用基于中位数的轮廓系数或CH函数来确定合适的K值.由此,本文设计了一种优化初始类中心的自适应K-medoids算法(adaptive K-medoids algorithm for optimizing initial class centers,CH_KD).
假设给定的数据集为X={xi|xi∈Rq,1in},即数据集中有n个样本,每个样本有q维特征,第i个样本的第f个特征值为λi,f;欲将数据集X划分为K个簇Ck,1kK.
定义1 数据集X的平均样本距离
式中,dM(X)由数据集X中任意2个样本间距离和的平均值计算得到.
定义2 簇间相似度
SC=min(d(Oi,Oj)),(4)
式中,i=1,2,…,n,j=1,2,…,n,Oi和Oj分别表示簇Ci和簇Cj的类中心,可知簇间相似度由2个簇的类中心欧式距离计算得到.SC的值越小表示2簇之间的距离越近,则2簇的相似度越高,反之则越相异.
定义3 样本xi的误差平方和
式中,样本xi的误差平方和根据其与其余样本间的欧氏距离平方和计算得到.
CH(Calinski-Harabasz)函数作为内部聚类效果的衡量标准之一,其原理是通过簇间方差和簇内方差来评估聚类效果,定义如下.
式中,z表示数据集的平均值,zj表示Cj簇内所有样本的平均值.可知,tr(B)表示簇间的离散程度,tr(W)表示簇内的紧密程度.CH(K)则体现了在聚类数目为K时聚类质量的好坏,CH值越大则表明聚类效果越好.
本文提出的CH_KD算法主要包括2个部分:首先利用类内误差平方和选取初始类中心候选集,其次利用中位数的轮廓系数或者CH函数来确定合适的K值.为了更直观地说明改进的2种算法,图1给出算法的大致流程图.
依据图1可知,为解决K-medoids聚类算法初始类中心的问题,设计算法1.
算法1 选取初始类中心候选集算法伪代码如下.
为解决K-medoids聚类算法聚类数目K的问题,设计算法2.
算法2 确定最佳聚类数目算法的伪代码如下.
算法1实现初始类中心的选取,其中步骤4)~14)的时间复杂度为O(n1/2(n+n+n)),则算法1的总时间复杂度为O(n3/2).算法2实现聚类数目的确定,其中步骤2)~12)的时间复杂度为O(n1/2(tK(n-K)2+n1/2+n)),其中t为迭代次数,K为聚类数目,则算法2的时间复杂度可估计为O(n5/2).总体上来看,本问所提算法CH_KD的时间复杂度可估计为O(n5/2).
3 特征重要度确定
特征选择的目的是降低维度,保留具有高分类信息且冗余度低的特征.利用优化类中心的自适应K-medoids算法对特征进行聚类,使相似(冗余)特征聚为一类,以便选出冗余度低且区分度强的特征子集.为了选出区分度强的特征,利用特征标准差定义特征区分度,为了选出冗余度低的特征,利用皮尔逊相关系数度量特征簇中每个特征的冗余度[19],并以特征区分度和特征冗余度之积定义特征的重要度,以此选出每一簇中最优的代表特征,组成特征子集.
现给定数据集为X={xi|xi∈Rq,1in},n、q分别表示数据集的样本数量和特征数量.用fi=(f1i,f2i,…,fni)表示第i个特征向量,则有X={f1,f2,…,fq}.
定义4 特征fi的区分度
式中,i=1,2,…,q,fji表示特征fi在第j个样本上的取值.由于区分能力强的特征其方差较大,所以以特征的标准差来度量特征的区分度ddis,i是合理的.
定义5 特征fi的冗余度
式中,i=1,2,…,q,Ci表示第i个特征簇,rij表示特征fi和特征fj间的皮尔逊相关系数,rij绝对值越小,则表示特征fi和fj之间越不相关.dred,i表示特征fi在特征簇Ci中的冗余度,dred,i的值越大则表明fi特征冗余度越低.
定义6 特征fi的重要度
dimp,i=ddis,idred,i.(12)
由式(12)可知,特征fi的重要度dimp,i定义为特征fi的区分度与特征fi的冗余度之积,特征fi的重要度dimp,i的值越大,则表明特征fi越重要.并且由此设计了基于优化类中心的自适应K-medoids算法的无监督特征选择(unsupervised feature selection of adaptive K-medoids algorithm based on optimal class center CH_KDFS),称算法3.
算法3 CH_KDFS算法的伪代码如下.
算法3实现特征选择,步骤2的时间复杂度为O(q5/2),步骤3的时间复杂度为O(nq),步骤4)~7)的时间复杂度为O(nq2).则算法3总的时间复杂度可估计为O(q5/2).
4 实验结果与分析
4.1 实验准备
为验证所提聚类算法的聚类效果及其特征选择效果的好坏,在15个数据集上进行实验对比.表1给出了实验所使用的15个数据集的详细描述.其中前10个数据集为UCI数据集,UCI数据库是用于机器学习的数据库.后5个数据集为ASU数据集(Academic Search Ultimate,综合学科参考类全文数据库).
使用准确率(Accuracy,ACC)、兰德系数(Rand Index,RI)、F-measure(F1)、调整互信息(Adjusted Mutual Information,AMI)、归一化互信息(Normal Mututal Information,NMI)和调整兰德系数(Adjusted Rand Index,ARI)这6种指标对聚类结果进行评价,这6种评价指标均为值越大则表示算法性能越好.在SVM、NB、和KNN分类器下,使用分类精度precision和AUC这2种指标对分类效果进行评价,分类精度和AUC的值越大,则表明分类效果越好.为避免特征量纲带来的影响,提高算法的准确率,使用文献[20]的方式对数据进行标准化.
实验结果中加粗的数值表示实验结果的最优值.实验的主要环境是Windows10 64位操作系统,处理器为Inter(R)Core(TM)i5-8500和3.00 GHz 8.0 GB 内存;实验在MATLAB R2016b上进行.
4.2 CH_KD算法聚类结果分析
将CH_KD算法与K-medoids聚类算法、K-means聚类算法及KCOIC聚类算法进行实验对比,验证所提CH_KD聚类算法的有效性.本节实验在常用的9个UCI数据集Seeds、Waveform21、Statlog、Segmentation-test、Heart、Zoo、Soybean-small、Ionosphere和Iris上进行,为充分体现算法的有效性,采用6种评价指标ACC、RI、F1、AMI、NMI和ARI对算法的聚类效果进行评价.表2给出K值自适应聚类算法CH_KD算法和KCOIC算法的聚类数目,K-means算法和K-medoids算法的聚类数目与真实类别数相等.
由表2可知,在Seeds、Waveform21、Segmentation-test、Heart、Ionosphere和Iris这6个数据集上,CH_KD算法确定的类数目与真实类数目相等,与其他算法相比准确率更高.在Zoo和Soybean-small数据集上,CH_KD算法确定的类数目最接近真实类数目.在Statlog数据集上,CH_KD算法确定的类数目明显多于真实类数目.从本节实验所选的9个常用UCI数据集的实验结果来看,CH_KD算法确定最佳聚类数目的性能优于KCOIC算法.
由表3可知,在Ionosphere数据集上,CH_KD算法获得了准确的聚类数目,但其聚类效果低于K-medoids算法,分析其原因可能是Ionosphere数据集簇间离散程度相差较大,导致未选到更为合理的类中心,使得聚类结果略差.在Waveform21数据集上,CH_KD算法的聚类效果与K-means算法和K-medoids算法相差不多.在Seeds、Statlog、Segmentation-test、Heart、Zoo、Soybean-small和Iris这7个数据集上的聚类效果明显优于K-means算法和K-medoids算法.在Waveform21数据集上,4种算法的聚类效果相差不大,且CH_KD算法的聚类效果优于KCOIC算法.特别是在4种聚类算法表现均良好的Heart数据集、Zoo数据集和Iris数据集上,CH_KD算法在6个指标上均取得了最优值.在Heart数据集上,CH_KD算法在ACC、RI、F1、AMI、NMI和AMI指标上分别高出其他对比算法0.74%~20.55%、13.83%~15.6%、20.54%~40.96%、18.38%~23.89%、10.96%~24%、26.99%~31.23%.在Zoo数据集上,CH_KD算法在ACC、RI、F1、AMI、NMI和AMI指标上分别高出其他对比算法4.95%~8.81%、1.7%~12.7%、3.76%~17.33%、5.6%~18.5%、1.56%~19.11%、4.14%~38.23%.在Iris数据集上,CH_KD算法在ACC、RI、F1、AMI、NMI和AMI指标上分别高出其他对比算法0.96%~23.45%、4.98%~10.42%、14.12%~17.7%、3.58%~23.58%、5.02%~14.92%、10.29%~15.6%.
总体上来看,CH_KD算法在Seeds数据集、Statlog数据集、Segmentation-test数据集、Heart数据集、Zoo数据集、Soybean-small数据集和Iris数据集上的聚类结果最优.则有效地验证了所提算法的可行性及有效性.
4.3 CH_KDFS(CH_KD feature selection)算法的实验结果与分析
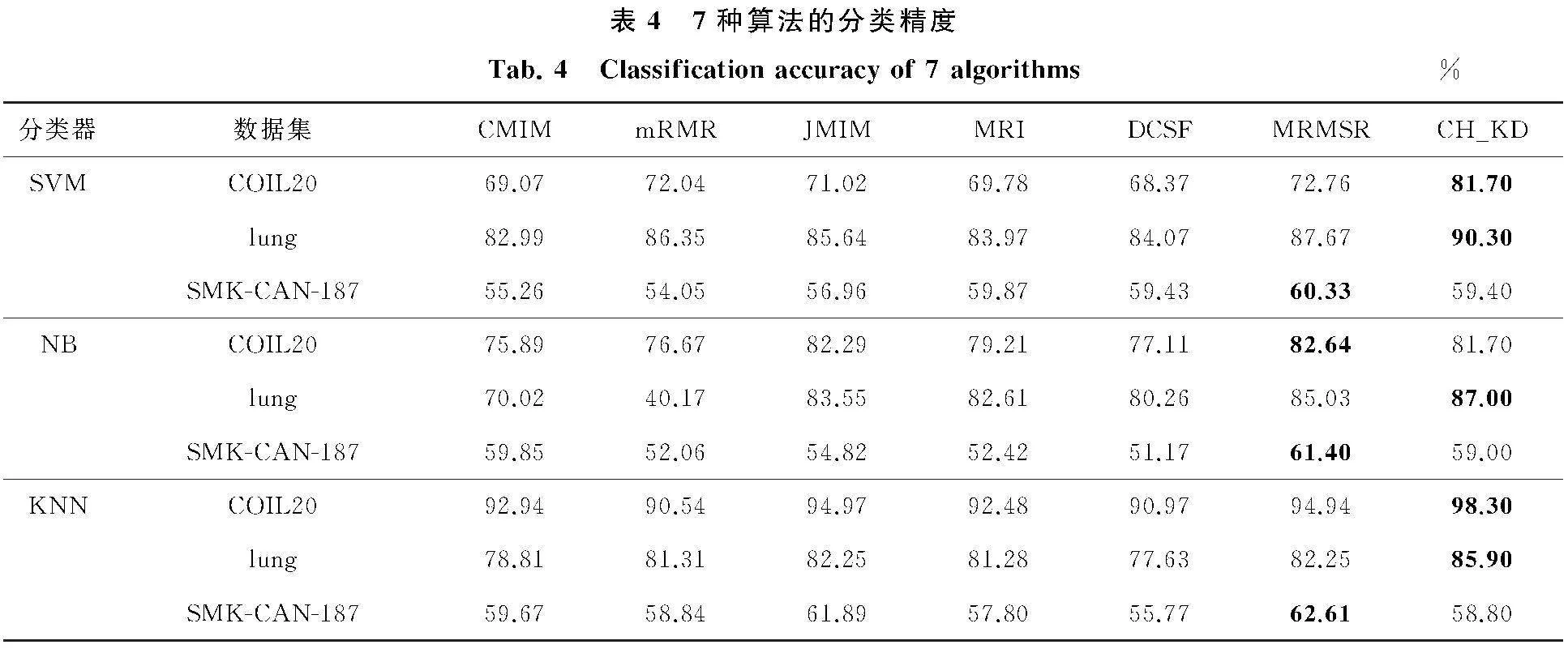
CH_KDFS算法与CMIM算法、mRMR算法、JMIM算法、MRI算法、DCSF算法以及MRMSR算法在SVM、NB和KNN(K=1)这3个分类器下的分类精度如表4所示.分类器的各参数根据文献[21-22]进行设置.
由表4可知,在lung数据集上,CH_KDFS算法在SVM、NB和KNN这3个分类器上的分类精度均最优.在COIL20数据集上,CH_KDFS算法在SVM和KNN这2个分类器上的分类精度最优.在SVM分类器上高出其他6种算法8.94%~13.33%,在KNN分类器上高出其他6种算法3.33%~7.76%,但在NB分类器上的分类精度略低于部分算法.在SMK-CAN-187数据集上,CH_KDFS算法的分类精度均略低于部分算法.上述分析表明,CH_KDFS算法易受分类器的影响,但整体来看CH_KDFS算法具有更好的分类性能.
CH_KDFS算法、FSFC算法和WFSFC算法在5个数据集DLBCL、colon、lung、ORL和COIL20数据集上所选特征个数,以及在SVM、NB这2个分类器下的AUC值如表5和表6所示.特征个数越少且AUC值越高,表明分类效果越好.实验中各分类器使用5折交叉验证.
由表5和表6可知,在SVM分类器上,CH_KDFS算法在DLBCL、colon、lung和ORL数据集上均以较少的特征取得了最优的分类效果.特别是在ORL数据集上,CH_KDFS算法分别比FSFC、WFSFC算法高出23.2%、10.5%.在COIL20数据集上,CH_KDFS算法能以较少的特征个数达到略低于对比算法的分类效果.在NB分类器上,CH_KDFS算法在colon和lung数据集上均取得了最少的特征个数且分类效果最优.在colon数据集上分别比FSFC、WFSFC算法高出33.7%、6.7%,在lung数据集上分别比FSFC、WFSFC算法高出8.0%、7.7%.在ORL数据集上,尽管CH_KDFS算法的分类效果低于WFSFC算法,但所选的特征个数远少于WFSFC算法.综上所述,CH_KDFS算法在特征选择的个数以及分类效果上优于对比算法.
5 结 论
针对传统K-medoids算法的缺点,本文提出了CH_KD算法,其目的是优化K-medoids算法的随机选择初始类中心且需要人为指定聚类数目K而导致聚类结果不稳定的问题.此算法为自适应优化初始类中心的K-medoids算法,利用特征标准差定义特征区分度,利用皮尔逊相关系数度量特征簇中每个特征的冗余度,将特征区分度和特征冗余度的乘积定义为特征的重要度,以此选出每一簇中最优代表特征,组成特征子集.在MATLAB R2016b实验表明,在8个常用UCI数据集上,CH_KD算法确定最佳聚类数目的性能优于KCOIC算法.在Seeds数据集、Statlog数据集、Segmentation-test数据集、Heart数据集、Zoo数据集和Soybean-small数据集上CH_KD算法的聚类结果最优.CH_KDFS算法与FSFC算法和WFSFC算法相对比,在DLBCL、colon、lung、ORL和COIL20这5个数据集上所选特征个数,以及在SVM、NB这2个分类器下的AUC值相比,特征个数越少且AUC值越高,表明CH_KDFS算法分类效果越好,即CH_KDFS算法在特征选择的个数以及分类效果上优于对比算法.综上所述,CH_KD算法具有可行性和有效性,实验聚类效果较好,且算法分类效果较好.
参 考 文 献
[1]LI H L.Multivariate time series clustering based on common principal component analysis[J].Neurocomputing,2019,349:239-247.
[2]黄晓辉,王成,熊李艳,等.一种集成族内和族间距离的加权k-means 聚类方法[J].计算机学报,2019,42(12):2836-2848.
HUANG X H,WANG C,XIONG L Y,et al.A Weighting k-Means Clustering Approach by Integrating Intra-Cluster and Inter-Cluster Distances[J].Chinese Journal of Computers,2019,42(12):2836-2848.
[3]赵成.基于萤火虫算法和改进K近邻的文本分类研究[D].重庆:重庆邮电大学,2020.
ZHAO C.Research on text classification based on firefly algorithm and improved K nearest neighbor[D].Chongqing:Chongqing University of Posts and Telecommunications,2020.
[4]王全民,杨晶,张帅帅.一种基于改进果蝇优化的K-mediods聚类算法[J].计算机技术与发展,2018,28(12):17-22.
WANG Q M,YANG J,ZHANG S S.A new K-mediods clustering algorithm based on improved fruit fly optimization algorithm[J].Computer Technology and Development,2018,28(12):17-22.
[5]魏霖静,宁璐璐,郭斌,等.基于混合蛙跳算法的K-mediods聚类挖掘与并行优化[J].计算机科学,2020,47(10):126-129.
WEI L J,NING L L,GUO B,et al.K-mediods cluster mining and parallel optimization based on shuffled frog leaping algorithm[J].Computer Science,2020,47(10):126-129.
[6]管雪婷,石鸿雁.融合云模型优化萤火虫的K-mediods聚类算法[J].统计与决策,2021,37(5):34-39.
GUAN X T,SHI H Y.K-mediods clustering algorithm of glowworm swarm optimization combined with cloud model[J].Statistics amp; Decision,2021,37(5):34-39.
[7]管雪婷.基于改进的萤火虫优化的K中心点算法[D].沈阳:沈阳工业大学,2021.
GUAN X T.K-center algorithm based on improved firefly optimization[D].Shenyang:Shenyang University of Technology,2021.
[8]杨楠.基于改进布谷鸟算法的K中心点聚类分析及并行实现[D].兰州:西北师范大学,2018.
YANG N.K-center clustering analysis and parallel implementation based on improved cuckoo algorithm[D].Lanzhou:Northwest Normal University,2018.
[9]刘叶,吴晟,周海河,等.基于K-means聚类算法优化方法的研究[J].信息技术,2019,43(1):66-70.
LIU Y,WU S,ZHOU H H,et al.Research on optimization method based on K-means clustering algorithm[J].Information Technology,2019,43(1):66-70.
[10]李莲.基于蜂群和粗糙集的聚类算法研究[D].长沙:长沙理工大学,2014.
LI L.Research on clustering algorithm based on bee colony and rough set[D].Changsha:Changsha University of Science amp; Technology,2014.
[11]谭成兵,刘源,徐健.基于布谷鸟算法的K-medoids聚类挖掘与并行优化[J].台州学院学报,2021,43(03):7-12.
TAN C B,LIU Y,XU J,et al.K-medoids clustering mining and parallel optimization based on the cuckoo algorithm[J].Journal of Taizhou University,2021-43(03):7-12.
[12]李欣宇,傅彦.改进型的K-mediods算法[J].成都信息工程学院学报,2006,21(4):532-534.
LI X Y,FU Y.Improved K-mediods algorithm[J].Journal of Chengdu University of Information Technology,2006,21(4):532-534.
[13]钟志峰,李明辉,张艳.机器学习中自适应k值的k均值算法改进[J].计算机工程与设计,2021,42(1):136-141.
ZHONG Z F,LI M H,ZHANG Y.Improved k-means clustering algorithm for adaptive k value in machine learning[J].Computer Engineering and Design,2021,42(1):136-141.
[14]陈江勇.基于平衡性的无监督特征选择算法研究[D].合肥:安徽大学,2021.
CHEN J Y.Research on unsupervised feature selection algorithm based on balance[D].Hefei:Anhui University,2021.
[15]裴华欣.自适应密度峰划分聚类算法研究及应用[D].杭州:浙江工业大学,2018.
PEI H X.Research and application of adaptive density peak division clustering algorithm[D].Hangzhou:Zhejiang University of Technology,2018.
[16]吴礼福,姬广慎,胡秋岑.强混响环境下基于K-medoids特征聚类的话者计数[J].南京大学学报(自然科学),2021,57(5):875-880.
[17]胡军,王海峰.基于加权信息粒化的多标记数据特征选择算法[J/OL].智能系统学报:1-10[2023-04-12].http://kns.cnki.net/kcms/detail/23.1538.tp.20230317.1408.004.html.
HU J,WANG H F.Feature selection algorithm for multi tag data based on weighted information granulation[J/OL].Journal of Intelligent Systems:1-10[2023-04-12].http://kns.cnki.net/kcms/detail/ 23.1538.tp.20230317.1408.004.html.
[18]赵源上,林伟芳.基于皮尔逊相关系数融合密度峰值和熵权法的典型新能源出力场景研究[J/OL].中国电力:1-10[2023-04-13].http://kns.cnki.net/kcms/detail/11.3265.TM.20230227.0856.006.html.
ZHAO Y S,LIN W F.Research on typical new energy output scenarios based on Pearson correlation coefficient fusion densitypeak value and entropy weight method[J/OL].China Power:1-10[2023-04-13].http://kns.cnki.net/kcms/detail/11.3265.TM.20230227.0856.006.html.
[19]徐久成,黄方舟,穆辉宇,等.基于PCA和信息增益的肿瘤特征基因选择方法[J].河南师范大学学报(自然科学版),2018,46(2):104-110.
XU J C,HUANG F Z,MU H Y,et al.Tumor feature gene selection method based on PCA and information gain[J].Journal of Henan Normal University(Natural Science Edition),2018,46(2):104-110.
[20]战庆亮,葛耀君,白春锦.流场特征识别的无量纲时程深度学习方法[J].工程力学,2023,40(02):17-24.
ZHAN Q L,GE Y J,BAI C J,et al.A dimensionless time history in-depth learning meth od for flow field feature recognition[J].Engineering Mechanics,2023,40(02):17-24.
[21]雍菊亚,周忠眉.基于互信息的多级特征选择算法[J].计算机应用,2020,40(12):3478-3484.
YONG J Y,ZHOU Z M.Multi-level feature selection algorithm based on mutual information[J].Journal of Computer Applications,2020,40(12):3478-3484.
[22]刘艳,程璐,孙林.基于K-S检验和邻域粗糙集的特征选择方法[J].河南师范大学学报(自然科学版),2019,47(2):21-28.
LIU Y,CHENG L,SUN L.Feature selection method based on K-S test and neighborhood rough sets[J].Journal of Henan Normal University(Natural Science Edition),2019,47(2):21-28.
Adaptive K-medoids algorithm for optimizing initial class center
Abstract: To solve the problem that the traditional K-medoids clustering algorithm needs to randomly select the initial cluster center and specify the number of clusters K, and the clustering results are unstable, this paper proposes an adaptive K-medoids algorithm to optimize the initial cluster center(CH_KD). The purpose is to define the feature importance, so as to screen out the best representative features in each cluster and form a feature subset, and focus on the adaptive optimization and improvement of the traditional partition algorithm. First, the feature discrimination is defined by the feature standard deviation, and the features with strong discrimination are selected. Secondly, Pearson correlation coefficient is used to measure the redundancy of each feature in the feature cluster, and the features with low redundancy are selected. Finally, the product of feature discrimination and feature redundancy is taken as the feature importance to screen out the best representative features in each cluster and form a feature subset. The experiment compares the proposed algorithm with other clustering algorithms on 14 UCI datasets, and the results verify that CH_KD the effectiveness and advantages of algorithm.
Keywords: unsupervised; feature differentiation; feature redundancy; CH function; feature selection
猜你喜欢
软件工程(2024年12期)2024-12-28 00:00:00
电信科学(2017年6期)2017-07-01 15:44:35
自动化学报(2017年5期)2017-05-14 06:20:50
电子制作(2017年23期)2017-02-02 07:17:06
电测与仪表(2016年23期)2016-04-12 00:23:08
西北工业大学学报(2015年4期)2016-01-19 03:31:47
智能系统学报(2015年4期)2015-12-27 09:38:21
电测与仪表(2015年24期)2015-04-09 12:04:32
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
