
数字化钻井ETL增量数据抽取与同步机制
2024-12-31 00:00:00康芳玲 王建胜
信息系统工程 2024年10期

摘要:随着石油钻井行业数字化转型的深入推进,数据的实时性、准确性和完整性对提高钻井效率和决策质量至关重要。针对数字化钻井环境下数据抽取、转换和加载(ETL)过程中的增量数据抽取与同步问题,提出了一种基于时间戳和变更数据捕获(CDC)的混合机制。该机制通过对源数据系统的日志分析和数据比对,实现了高效、准确的增量数据识别和抽取。同时,采用分布式消息队列和实时流处理技术,构建了一个低延迟、高吞吐量的数据同步管道。
关键词:数字化钻井;ETL;增量数据抽取;数据同步;变更数据捕获
一、前言
数字化钻井作为石油勘探开发领域的前沿技术,正在深刻改变传统钻井作业模式。它通过采集、传输和分析各类钻井参数和地质数据,实现钻井过程的实时监控、优化和预测,从而提高钻井效率、降低成本和风险。然而,数字化钻井系统的有效运行依赖于大量异构数据源的及时整合和分析,对传统的ETL流程提出了严峻挑战。在数字化钻井环境中,数据源通常包括钻机设备传感器、泥浆录井系统、地质导向系统等,这些系统产生的数据具有高频率、大容量和实时性强的特点。传统的全量数据抽取方法不仅耗时长、效率低,还会对源系统造成不必要的负担。因此,设计一种高效的增量数据抽取与同步机制,成为数字化钻井ETL过程中的关键问题。本研究旨在解决数字化钻井ETL过程中的增量数据抽取与同步问题,提出一种创新的机制来提高数据集成的效率和实时性。通过深入分析数字化钻井数据的特点和ETL需求,设计并实现了一套基于时间戳和CDC的混合增量抽取机制,并结合分布式消息队列和实时流处理技术,构建了高效的数据同步管道。
二、数字化钻井数据特征分析
(一)数据源类型和结构
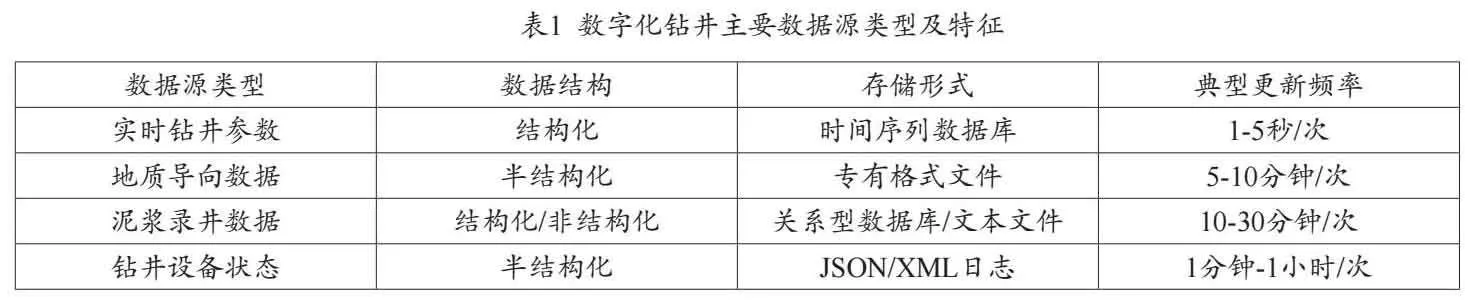
数字化钻井系统涉及多种异构数据源,主要包括实时钻井参数、地质导向数据、泥浆录井数据和钻井设备状态数据。实时钻井参数由钻机上的各类传感器采集,包括钻压、转速、泵压、钩载等,这些数据通常以高频时间序列的形式存储。地质导向数据包括伽马测井、电阻率测井等,用于实时评估地层情况和优化钻井轨迹。泥浆录井数据包括岩屑分析、气测等信息,有助于识别地层和预测地下压力。钻井设备状态数据则反映了关键设备的运行状况,如顶驱、泥浆泵、泥浆循环系统等[1]。这些数据源的结构差异较大,既有结构化的关系型数据库存储的钻井作业记录,也有半结构化的设备状态日志,还有非结构化的地质报告或测井曲线图像。数据的存储形式包括关系型数据库、专有格式文件、文本文件和时间序列数据库等。每种数据源都有特定的更新频率,从秒级到小时级不等,直接影响了数据抽取和同步策略的设计。
表1总结了主要数据源类型及其特征,包括数据结构、存储形式和典型更新频率。这种多样性和复杂性对ETL过程提出了严峻挑战,需要设计灵活且高效的数据抽取和同步机制。
(二)数据更新频率和模式
数字化钻井环境中,不同类型的数据具有不同的更新频率和模式。实时钻井参数通常以秒级的频率更新,形成连续的数据流。这些数据采用追加写入的模式,新数据不断添加到现有数据集的末尾。地质导向数据的更新频率较低,通常每隔5到10分钟进行一次测量和更新。这类数据的更新模式既包括新数据的添加,也可能涉及对已有数据的修正,特别是在数据处理和解释阶段。泥浆录井数据的更新频率通常在10到30分钟一次,主要取决于钻井进度和地层变化情况。这类数据的更新既包括新记录的插入,也包括对现有记录的更新。例如,当获得更精确的岩屑分析结果时[2],钻井设备状态数据的更新频率差异较大,从分钟级到小时级不等,通常采用覆盖写入的模式,即新的状态信息会替换旧的记录。
了解这些数据更新的特性对于设计有效的增量数据抽取策略至关重要。高频更新的数据可能需要实时流处理方法,而低频更新的数据则可以采用批处理方法。同时,不同的更新模式也要求ETL过程能够灵活处理插入、更新和删除操作。
(三)数据质量和一致性要求
在数字化钻井环境中,数据质量和一致性直接影响到钻井决策的准确性和安全性。数据质量的主要衡量指标包括准确性、完整性、时效性和一致性。准确性要求数据能够真实反映现场情况,这通过传感器校准、数据验证算法等方法来保证。完整性要求在数据传输和处理过程中不丢失关键信息,这需要健壮的网络传输和错误恢复机制。时效性要求数据能够及时反映现场状况,这对实时钻井参数尤为重要。一致性要求不同系统间的数据保持同步,避免决策基于不一致的信息。为了满足这些要求,ETL过程需要实施严格的数据质量控制措施。在数据抽取阶段,需要进行数据有效性检查,确保源数据的完整性和准确性。在转换阶段,应用数据清洗和标准化规则,解决数据不一致、缺失值和异常值等问题[3]。在加载阶段,执行数据一致性验证,确保转换后的数据符合目标系统的要求。同时,需要建立数据质量监控机制,通过实时监控和报警,及时发现和处理异常数据。
这些数据质量和一致性要求对增量数据抽取与同步机制提出了更高的要求。系统不仅需要高效地识别和抽取增量数据,还需要保证数据在传输和处理过程中的完整性和一致性。这就需要在ETL过程中引入事务处理、数据校验和异常处理等机制。
三、增量数据抽取机制设计
(一)基于时间戳的增量识别方法
基于时间戳的增量识别是一种高效的数据抽取方法,特别适用于数字化钻井环境中的时间序列数据。这种方法的核心是在源数据表中维护一个最后更新时间戳字段,ETL程序每次抽取时,只需提取上次抽取时间之后更新的记录。实现这种方法时,首先需要确保源系统的所有表都包含最后更新时间戳字段,并在数据插入或更新时自动维护该字段。ETL程序则需要维护一个元数据表,记录每张表的最后抽取时间。这种方法的优势在于实现简单,对源系统的影响小,特别适合于那些主要以追加方式更新的数据,如实时钻井参数和日志数据。然而,这种方法也存在一些局限性。它无法有效处理数据删除的情况,也可能因时钟不同步导致数据遗漏。此外,对于频繁更新的数据,可能会导致重复抽取,增加系统负担。
为了克服这些限制,对基本的时间戳方法进行了优化。引入了增量标识字段,用于标记记录的状态(新增、更新或删除)[4]。同时,实现了一个智能的时间窗口机制,根据数据更新频率动态调整抽取时间窗口,既保证数据的完整性,又避免不必要的重复抽取。
(二)CDC技术应用
CDC技术提供了一种更为精确的增量数据识别方法。在数字化钻井环境中,CDC技术可以实时捕获数据库中的插入、更新和删除操作,从而实现精确的增量数据抽取。主要采用了基于日志的CDC方法,通过解析数据库的事务日志来捕获数据变更。这种方法对源系统的性能影响最小,同时能够提供最细粒度的变更信息。在实际应用中,对数据库系统进行了特定配置,启用详细的日志记录模式。CDC程序作为一个独立的服务运行,持续监控和解析这些日志文件。当检测到相关表的变更时,CDC程序提取变更信息,包括变更类型(插入、更新或删除)、变更时间、变更前后的数据值等。这些信息被转换为标准格式的变更事件,发送到消息队列系统中,供后续的ETL过程使用。
为了处理大规模数据和高频变更,实现了一个分布式的CDC架构。多个CDC实例可以并行处理不同的日志文件或数据库分片,显著提高了数据捕获的吞吐量。同时,引入了变更事件的批处理机制,在保证实时性的同时,提高了系统的处理效率。
(三)混合抽取策略的优化算法
考虑到数字化钻井环境中数据源的多样性和复杂性,结合时间戳和CDC技术的优势设计了一种混合抽取策略。这种策略的核心是根据数据源的特性和ETL需求,动态选择最适合的抽取方法。混合策略的优化算法基于以下几个关键因素:数据更新频率、数据量、系统负载和数据一致性要求。对于更新频繁的小规模数据,如实时钻井参数,倾向于使用CDC技术实现实时同步。这种方法能够捕获每一次细微的数据变化,满足实时监控和分析的需求[5]。对于大规模但更新较少的数据,如地质数据,采用基于时间戳的方法进行批量抽取。这种方法能够有效处理大量数据,同时减少对源系统的影响。算法还考虑了系统负载因素。在源系统负载高峰期,算法会自动降低抽取频率或切换到低影响的抽取方法。同时,算法会根据目标系统的处理能力动态调整数据传输速率,避免数据积压。
为了应对复杂的数据更新模式,算法实现了一个自适应学习机制。通过持续监控和分析数据变更模式,算法能够自动调整抽取策略参数,如时间窗口大小、CDC捕获粒度等,以优化抽取效率和准确性。这种混合策略极大地提高了ETL过程的灵活性和效率,能够适应数字化钻井环境中复杂多变的数据特性。通过智能地平衡实时性、完整性和系统性能,该策略为构建高效可靠的数据集成平台奠定了基础。
四、实时数据同步管道实现
(一)分布式消息队列的选择与配置
在实时数据同步管道中,分布式消息队列扮演着关键角色,它能够解耦数据生产者和消费者,提供数据缓冲,并支持高吞吐量的数据传输。经过比较和评估,选择了Apache Kafka作为消息队列系统,主要考虑了其高吞吐量、可靠的消息持久化机制以及良好的扩展性。在Kafka的配置中,重点关注了主题设计、分区策略、复制因子和消息压缩等方面。根据数据类型和业务需求,设计了多个主题,如实时钻井参数、地质数据等,以便于数据的分类和处理。考虑到数据的时序性和负载均衡,采用了基于时间和钻井ID的复合分区策略。为保证数据的可靠性,设置了适当的复制因子,确保每条消息在集群中有多个副本。同时,启用了消息压缩功能,在保证性能的同时减少网络带宽使用。
为了优化Kafka集群的性能,进行了一系列调优,包括调整broker的配置参数,如增加网络线程数、优化日志刷新策略等。还实现了动态分区分配机制,根据数据流量自动调整分区数量,以适应不同时期的数据量变化。此外,建立了全面的监控体系,实时跟踪消息积压、消费延迟等关键指标,确保系统的健康运行。
(二)数据一致性和故障恢复机制
为保证数据一致性和系统可靠性,采取了多层次措施。利用Kafka的事务特性和Flink的检查点机制,实现了端到端的exactlyonce语义。对于跨系统数据更新,实现了基于两阶段提交的分布式事务机制。在故障检测和恢复方面,通过心跳机制监控系统组件健康状态,触发自动恢复流程。还引入了版本控制机制支持数据回滚和历史查询,设计了异常数据处理机制,将处理失败的消息存储在死信队列中,配合人工干预确保问题数据得到妥善处理。
五、系统性能评估与优化
(一)实验设计与评估指标
为了全面评估增量数据抽取与同步机制的性能,设计了一系列实验,模拟真实的数字化钻井环境。实验环境包括多个虚拟化的数据源系统,一个Kafka集群,以及多节点的Flink集群。选取了数据延迟、吞吐量、资源利用率和数据一致性作为关键评估指标。数据延迟指标衡量从数据产生到可供查询的时间差,直接反映了系统的实时性能。通过在数据源端和目标端植入时间戳,计算端到端的处理延迟。吞吐量指标则衡量系统每秒能够处理的数据量,反映了系统的整体处理能力。通过逐步增加数据生成速率,测试系统的最大吞吐能力。
资源利用率指标关注CPU、内存、网络和磁盘I/O的使用情况。使用系统监控工具收集这些指标,分析资源瓶颈并指导优化方向。数据一致性指标则通过比对源系统和目标系统的数据,评估数据同步的准确性和完整性。设计了多种测试场景,包括稳定负载测试、峰值负载测试和长时间运行测试。在每种场景下,模拟了不同类型的数据源和更新模式,全面评估系统在各种条件下的表现。
(二)性能测试结果分析
实验结果表明,设计的增量数据抽取与同步机制在各项指标上都表现出色。在稳定负载下,系统能够保持亚秒级的数据延迟,吞吐量达到每秒数十万条记录。即使在模拟的峰值负载下,系统也能够通过自动扩展资源来维持性能,延迟增加不超过50%。长时间运行测试证明了系统的稳定性,7天持续运行期间未出现明显的性能衰减。表2展示了不同数据源类型下的平均处理延迟和吞吐量。实时钻井参数的处理延迟最低,平均在100毫秒以内,吞吐量最高能达到每秒20万条记录。地质数据虽然更新频率较低,但单条记录较大,因此吞吐量较低,但仍能满足实时处理需求。
对资源利用率分析显示,在峰值负载下,CPU使用率达到了75%,内存使用率为60%,网络带宽利用率为65%,表明系统资源分配合理,还有一定的扩展空间。数据一致性测试结果令人满意,在所有测试场景下,源系统和目标系统的数据差异率均低于0.01%。
(三)系统瓶颈识别与优化建议
通过分析,识别出几个潜在瓶颈并提出优化建议。对于Kafka集群的磁盘I/O瓶颈,建议升级到固态硬盘并优化日志压缩策略。针对复杂地质数据处理时的内存消耗,建议增加Flink TaskManager内存配置并优化数据序列化方式。对于CPU密集型操作,考虑使用GPU加速。在网络方面,建议采用Kafka的地理复制功能减少长距离数据传输,并考虑边缘计算技术。建议优化Kubernetes的自动扩、缩容策略,提高资源分配响应速度,并实现预测性扩容机制应对可预见的负载高峰。这些优化建议将进一步提升系统性能和可扩展性,更好地适应数字化钻井环境的需求。
六、结语
本研究针对数字化钻井环境下ETL过程中的增量数据抽取与同步问题,提出了一种创新的解决方案。通过结合时间戳和变更数据捕获技术,实现了高效、准确地识别和抽取增量数据。同时,利用分布式消息队列和实时流处理技术,构建了一个低延迟、高吞吐量的数据同步管道。实验结果表明,该机制显著提高了数据同步的效率和实时性,为数字化钻井平台的数据集成和分析提供了有力支撑。未来的研究方向将聚焦于进一步优化增量抽取算法,提高系统在复杂网络环境下的鲁棒性,以及探索基于机器学习的自适应ETL策略。这些进展将为数字化钻井技术的持续发展和应用提供重要的数据基础支撑。
参考文献
[1]张宝平,龚明.基于数字化海图和大数据的自升式钻井平台就位技术[J].海洋石油,2024,44(01):88-91+101.
[2]王博,罗叶.用于煤矿瓦斯钻孔施工数据采集的数字化钻机研制与应用[J].煤矿机械,2022,43(11):195-199.
[3]胡延霞,张建卿.侍德益.钻井液用处理剂质量数字化智能评价方法研究[J].科技资讯,2022,20(15):86-88.
[4]王雷.基于数据中心的数字化钻井施工模式的构建[J].中国管理信息化,2022,25(14):107-109.
[5]高晓军,杨杰.钻井液高速离心机数字化自动控制系统研制与应用[J].中国设备工程,2020(22):16-17.
作者单位:长庆钻井总公司信息与档案管理中心
■ 责任编辑:王颖振、杨惠娟
