
结合核函数与神经网络的实体嵌入规范化
2024-12-31 00:00:00谢晟祎 陈新元 陈庆强
信息系统工程 2024年10期
关键词:聚类
摘要:开放的知识库缺少本体信息,进一步影响服务下游应用的能力,需对实体进行规范化。传统相似性度量方法及现有机器学习/深度学习方法泛化能力有待提升。提出结合核函数与神经网络的规范化表示框架,引入外源辅助信息,与实体嵌入拼接,增强细粒度的维度互动以改善语义识别能力,将相似性得分用于实体聚类。在行业数据集和开放知识图数据集上验证框架的实体规范化能力,并进一步开展链路预测任务,与基准模型比较以验证性能。
关键词:知识图嵌入;实体规范化;实体消歧;行业领域;聚类
一、前言
知识图是事实集合,以三元组的形式组织知识,在问答系统等领域应用广泛。三元组可表示为(h,r,t),h,t∈E分别为头、尾实体,r∈P表示实体之间的关系。现有知识图缺失事实,许多三元组不完整,缺少实体/关系。知识图嵌入(Knowledge Graph Embedding,KGE)[1]将三元组嵌入低维向量空间中,应用机器学习技术补全知识图。实体表示规范化有助于正确识别实体,是知识图补全/更新的重要任务。
开放知识图(OpenKG)缺少本体信息支撑,下游应用的性能受到影响,更需要规范化。以在线求职平台LinkedIn为例,平台包含大量行业信息,如公司/机构名称、岗位和技能等,但绝大部分内容为企业/个人用户提供,缺少统一规范的描述框架,内容变化程度高,如华尔街日报的表示包括“Wall Street Journal”“www.wsj.com”“wsj.com”“WSJ”等,既存在语义相同或相近的缩写或简写,也有“WSJ Online”“WSJ Pro”“WSJ Vacation”等分支下属机构,分支名中可能覆盖了“WSJ”。此外,正确识别相关实体还涉及“Wall Stret Journal”拼写错误及领域特定概念等情况。
传统统计学方法使用静态模型,通过人工设计规则/特征模式进行实体规范化,在大规模数据集上学习领域特定概念或近似语义的能力较弱。本文提出结合核函数与神经网络的嵌入表示规范化框架(An Embedding amp; Canonicalization Framework with Kernel Functions and Neural Network,ECF),将外源辅助信息与实体的嵌入表示拼接,通过元素积和范式距离等方式增强不同维度上的信息互动,进一步在神经网络中使用核函数将数据映射到高维特征空间,发掘细粒度[2]的语义相似性用于聚类相同实体,在行业数据集和开放知识图上验证框架的相似性识别能力,并进一步执行链路预测任务,与基准模型进行比较。
二、相关研究
KGE将实体/关系表示嵌入低维向量空间[3],可分为基于平移/旋转的模型和基于语义的模型,前者如TransE[1],认为若三元组成立,则头实体经关系平移后靠近尾实体,即vh+vr≈vt,vh,vr,vt分别表示头/尾实体和关系。后续模型如TransH(用超平面wr取代关系向量),TransR(使用投影矩阵Wr替换超平面wr)以及TransD、STransE和TranSparse等[4]。语义模型关注实体间的语义相似性,经典模型如RESCAL、DistMult和ComplEx等。近年,神经网络模型在KGE中得到广泛应用。
传统规范化方法借助人工定义的特征空间,对于相似性的识别能力有限。Han等[5]和Vashishth等[6]结合嵌入模型的思路,借助外部辅助信息对实体和关系进行联合处理,但受稀疏性、噪声和领域特定上下文信息缺失等因素影响,图模型在对实体进行无监督聚类时性能欠佳。因此,本文利用Wikidata和必应搜索接口补充领域特定的上下文信息。
Yan等[7]设计了基于二分法的公司名称规范化方法,将公司的完整文本介绍作为辅助信息,在LinkedIn社交图数据集上验证,但对于缺少信息的新公司实体学习能力较弱。上述研究未能彻底解决模型泛化能力较弱的问题。ECF框架尝试将文本描述与实体嵌入拼接,通过元素积、范式距离等方式增强向量在不同纬度上的互动,从而提取细粒度的语义信息。
此外,基于核函数的模型将数据映射到高维特征空间,从而实现非线性数据的线性可分,在身份检测、迁移学习和分类等任务中应用广泛。本文利用核函数计算开销低,学习能力强的优点,将其与神经网络结合,进一步捕捉潜在语义关系。聚合层次聚类(Hierarchical Agglomerative Clustering,HAC)被广泛应用于规范化任务,本文参考这一思路,并应用嵌入拼接、增强互动和引入核函数等方法提升自动聚类的准确性。
三、ECF
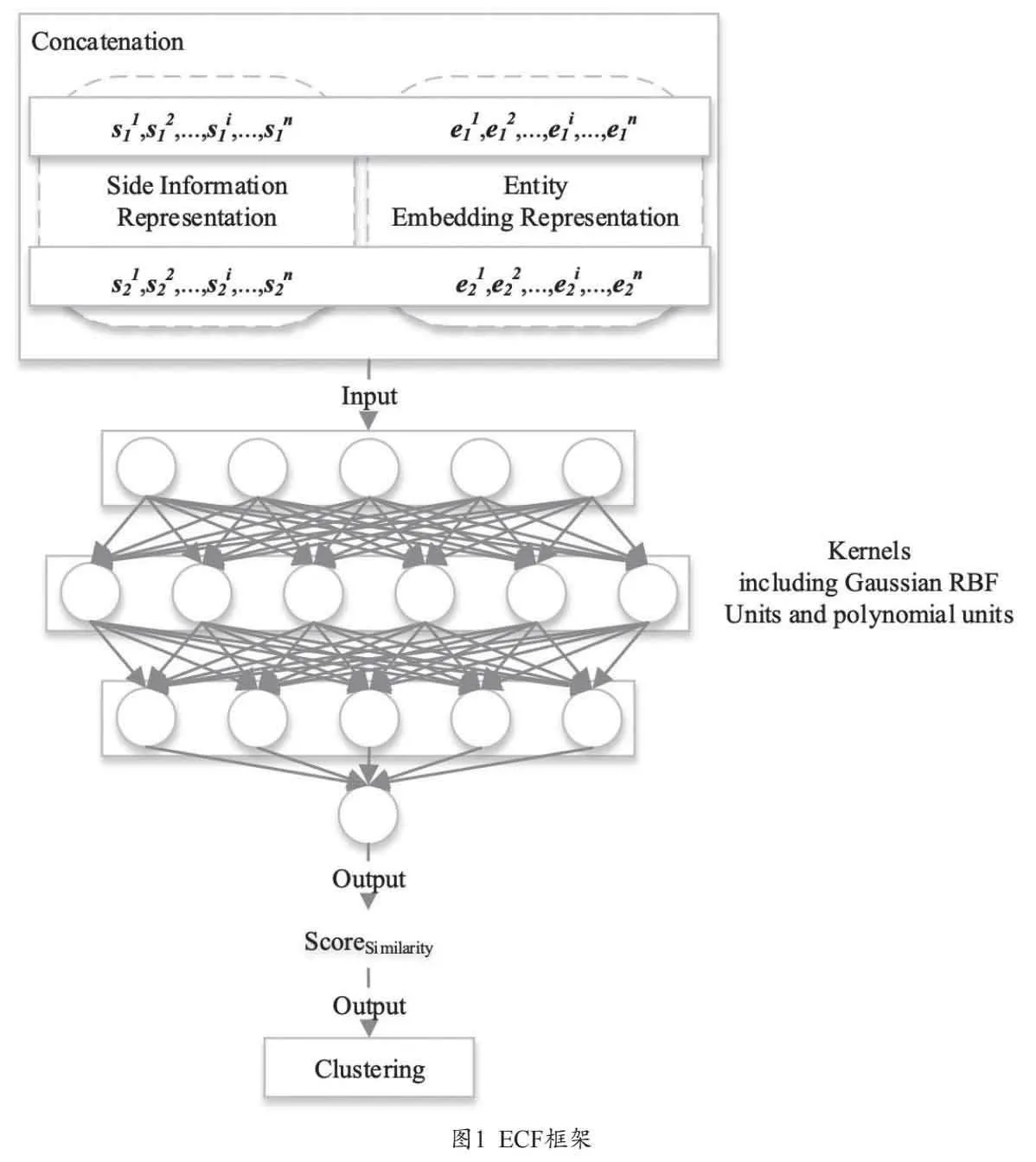
本文核心任务是利用外部辅助信息判定实体间相似性,即对于实体的嵌入表示e1,e2∈E,其辅助信息分别为s1,s2∈S,目标是找到fsimilarity(e1,e2,s1,s2),进一步在此基础上为所有实体对生成相似性矩阵,并应用聚类算法找到特定实体所对应的向量簇,实现规范化。
本文框架如图1所示,生成实体嵌入表示和外源辅助信息的嵌入表示后,拼接作为核函数神经网络的输入,获得实体对的相似度得分,进一步用于后续聚类。
CaRe使用GloVE[8]的预训练嵌入表示,但未能解决实体类型兼容性问题。Jain等[9]和Xie等[10]分别引入多向量关系映射和层次类型结构进行改进,但都依赖知识库的本体信息。考虑到在开放知识图上的应用,ECF框架采用distilled S-BERT模型的预训练结果以保证类型兼容性。为每一对候选实体(e1,e2)生成m维向量的上下文嵌入表示。
借助Wikidata和必应(Bing.com)检索接口获取外源辅助信息。Wiki信息可分为企业簇(C)、机构簇(I)、技能簇(S)和职位簇(D)。必应接口用于获取实体的文本描述,公司描述包括性质、位置、类型、董事等,如“Jeff Bezos founded Amazon from his garage in Bellevue, Washington, on July 5, 1994. It started as an online marketplace for books but expanded to sell ... ”,同样使用预训练的distilled S-BERT模型为每个实体生成n维向量s,与对应实体嵌入拼接,表示为ir=s⊙e,其中⊙为向量/矩阵拼接,ir为m+n维向量。进一步处理得到Inp=|ir1-ir2 |p⊙(ir1·ir2),其中p=1或p=2,|ir1-ir2 |p表示实体对拼接表示的向量距离,·表示元素积(element-wise product)。Inp为2×(m+n)维向量,作为神经网络的输入单位,维度根据轮廓系数(silhouette index)[11]确定。神经网络中包括多项式核和高斯径向基核,逐维度处理向量的元素积和向量L1/L2距离,在细粒度级别上学习实体对间的非线性关系和对称表示,从而提升泛化能力。神经网络使用ReLU函数输出,设置正则惩罚避免梯度消失,采用随机失活策略。设定核数为Inp维度的整数倍。近似性可被视作实体对属于同一概念的概率。在得到所有实体对概率得分和近似性矩阵的基础上应用聚合层次聚类,将单一概念映射为矩阵。
四、实验与分析
(一)实体相似性识别
行业数据集来源为LinkedIn,包括2864个企业簇(C)、2259个机构簇(I)、165个技能簇(S)和762个职位簇(D),人工标定,指标一致性系数0.87。样本中去除非ASCII字符。为平衡样本分布,以实体对为单位生成负样本。开放知识图数据集包括ESCO和DBpedia,ESCO(S)和ESCO(D)分别表示技能和职位,前者包括2644个实体簇和35554个实体对,后者包括2903个实体簇和62969个实体对。DBpedia(C)通过检索公司名称提取,包括2949个实体簇和182511个实体对。训练集/测试集划分为80%-20%。使用准确率(Precision)和F1得分衡量模型表现。
将本文模型与Distilled S-BERT+cosine、CharBiLSTM+A、WordBiLSTM+A以及CharBiLSTM+A+Word+A进行比较。Distilled S-BERT+cosine使用相同的预训练模型进行嵌入表示,但计算余弦相似度,且没有外源辅助信息支持。CharBiLSTM+A使用字符嵌入作为双向LSTM网络的输入,结合注意力机制。WordBiLSTM+A使用词级输入,其他设置相同。CharBiLSTM+A+Word+A综合了上述2种模型的架构。
使用Adam优化器和交叉熵损失函数,模型失活率dropout rate设为0.2,learning rate l∈{0.001,0.005,0.01,0.05},dimensionality m,n∈{128,256,512,1024},batch size s∈{512,1024,2048},使用Grid Search网格搜索发现最优组合,在行业数据集上为{l=0.005,m=n=256,s=1024},在ESCO上{l=0.01,m=n=256,s=1024},在DBpedia上{l=0.001,m=n=512,s=1024}。最大迭代训练轮数epochs设置为3000,但10轮MRR提升lt;0.01时停止。其他模型尽可能尊重原研究的最优参数设置。
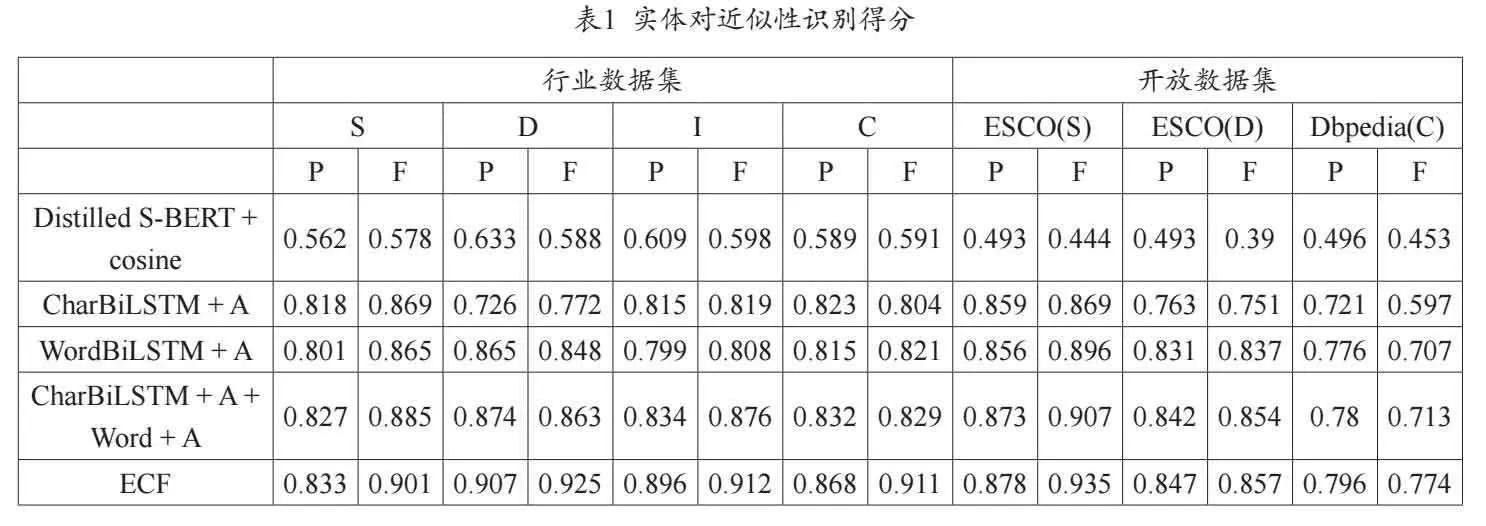
近似性识别结果见表1,可见ECF框架在所有指标上相比主流模型都有一定提升。Distilled S-BERT + cosine模型的得分普遍偏低,应为缺少外源辅助信息导致部分实体变化识别能力较弱,如“Wall Street Journal”和“WSJ”的相似性得分仅为0.59,ECF得分为0.93,说明上述文本在语义空间中实现了有效的非线性映射。对于“www.wsj.com”和“WSJ”,Distilled S-BERT + cosine得分0.84,说明该模型具备一定的学习字符重叠结构信息的能力,ECF得分更高为0.96。所有模型在部分重叠的实体文本上都表现较好。在开放数据集上,Distilled S-BERT + cosine得分相比行业数据集有明显降低,进一步说明了外源辅助信息的重要性。对于领域特定的概念,如近义词组“State Protocol Development”和“REST Developer”,在外源辅助信息的支持下,BiLSTM系列模型和ECF表现都较稳定(gt;0.85),但是移除外源信息嵌入后,都有一定程度的性能下降,可能是因为“State Protocol”的嵌入表示与“REST”存在较大差异。
ECF相比CharBiLSTM + A + Word + A,由于引入核函数神经网络加强了实体互动,语义提取的能力有所提升。CharBiLSTM + A + Word + A相比仅使用词级嵌入或字符级嵌入表现也较好。词级嵌入整体上性能表现优于字符级嵌入(plt;0.01),说明前者能更好地提取语义信息。但是,对于拼写错误,如“Wall Stret Journal”和“WSJ”,词级嵌入仅给出了0.67的近似度得分,字符级嵌入却达到了0.91,CharBiLSTM + A + Word + A 0.89,ECF 0.90,说明ECF对于该类文本的识别能力接近逐字符匹配的模型,规范化能力较强。
(二)链路预测
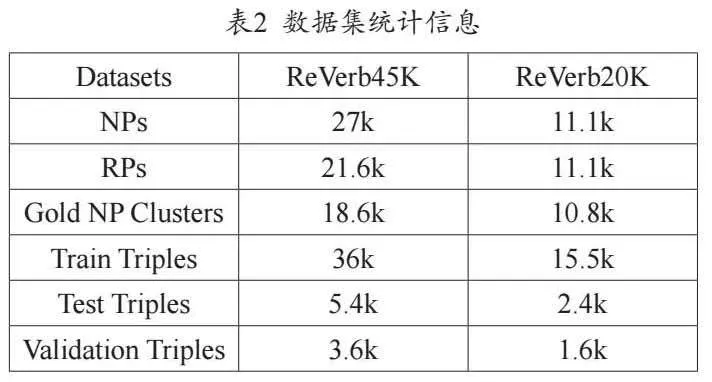
进一步在开放数据集ReVerb45K和ReVerb20K上进行链路预测,该任务在给定头/尾实体和关系的前提下预测缺失实体,对候选集合进行排序。上述数据集来自开放知识库ReVerb,统计信息见表2,NP和RP分别表示三元组的实体和关系。可见数据集的NP/RP分布稀疏,在此类数据集上的链路预测更符合真实世界的场景设置。训练集/测试集划分、负例生成与实验设置与CaRe[8]相同。使用平均排名(Mean Rank,MR)、平均倒数排名(Mean Reciprocal Rank, MRR)、排名在第1位的有效实体的比例(Hits@1)以及Hits@3、Hits@10作为评估指标。
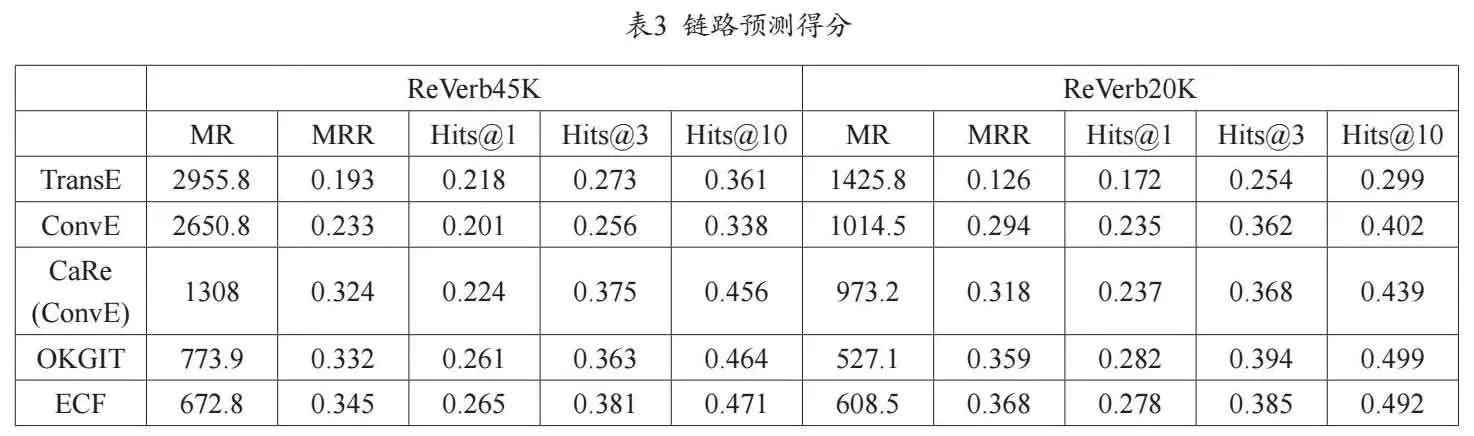
将ECF框架与TransE、ConvE、CaRe(图卷积网络GCN的引入有可能导致性能下滑,故采用ConvE方案)和OKGIT等基准模型比较,链路预测结果见表3。ECF的表现明显优于CaRe,可见ECF的规范化能力有一定提升。在ReVerb20K数据集上,ECF相比CaRe优势更大,而OKGIT的整体表现略优于ECF,说明ECF框架使用的预训练嵌入能有效保证类型兼容性,而类型映射和隐式类型得分可能有助于进一步提升,改进模型在开放数据集上的表现,将其作为未来的工作方向之一。基于平移的TransE模型和基于神经网络语义提取模型ConvE在稀疏开放数据集上表现欠佳。
五、结语
缺少本体信息的开放数据集存在大量噪声,为实现实体规范化,将实体嵌入与外源辅助信息结合,使用结合核函数与神经网络嵌入的方法实现细粒度的非线性特征提取和聚合层次聚类,规范实体表示并将其应用于行业数据集和开放数据集上,近似性识别和链路预测任务验证了方案可行性。未来计划设计关系规范化并与ECF框架集成,以及改进模型在外源辅助信息较少时的规范化能力。
参考文献
[1]张天成,田雪,孙相会,等.知识图谱嵌入技术研究综述[J].软件学报,2023,34(01):277-311.
[2]Pavlick E, Rastogi P, Ganitkevitch J, et al. PPDB 2.0: Better paraphrase ranking, fine-grained entailment relations, word embeddings, and style classification[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2015: 425-430.
[3]Nickel M, Rosasco L, Poggio T. Holographic embeddings of knowledge graphs[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2016, 30(1): 17-25.
[4]金婧,万怀宇,林友芳.融合实体类别信息的知识图谱表示学习[J].计算机工程,2021,47(04):77-83.
[5] Han X, Sun L, Zhao J. Collective entity linking in web text: a graph-based method[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. 2011: 765-774.
[6] Vashishth S, Jain P, Talukdar P. Cesi: Canonicalizing open knowledge bases using embeddings and side information[C]//Proceedings of the 2018 World Wide Web Conference. 2018: 1317-1327.
[7] Yan B, Bajaj L, Bhasin A. Entity resolution using social graphs for business applications[C]//2011 International Conference on Advances in Social Networks Analysis and Mining. IEEE, 2011: 220-227.
[8] Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
[9] Jain P, Kumar P, Chakrabarti S. Type-sensitive knowledge base inference without explicit type supervision[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018: 75-80.
[10] Xie R, Liu Z, Sun M. Representation Learning of Knowledge Graphs with Hierarchical Types[C]// IJCAI. 2016: 2965-2971.
[11] Starczewski A, Krzyżak A. Performance evaluation of the silhouette index[C]//International conference on artificial intelligence and soft computing. Springer, Cham, 2015: 49-58.
基金项目:1.福建省教育科学“十三五”规划 2020 年度课题(项目编号:FJJKCG20-402);2.福建省中青年教师科技类教育科研项目(项目编号:JAT210619)
作者单位:谢晟祎,福建农业职业技术学院;陈新元,福州工商学院;陈庆强,福建理工大学
■ 责任编辑:王颖振、杨惠娟
猜你喜欢
铁道通信信号(2019年6期)2019-10-08 09:02:40
电子测试(2017年15期)2017-12-18 07:19:27
雷达学报(2017年6期)2017-03-26 07:53:02
光学精密工程(2016年5期)2016-11-07 09:05:53
互联网天地(2016年1期)2016-05-04 04:03:17
自动化学报(2016年8期)2016-04-16 03:38:58
现代计算机(2016年17期)2016-02-28 18:35:32
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
河南科技(2014年23期)2014-02-27 14:19:14
