
基于多任务辅助学习的全景感知低电压监测技术及应用
2024-12-31 00:00:00李强杜丰夷范李平沈映彤
科技创新与应用 2024年35期
关键词:低电压

摘" 要:针对目前配网低电压数据量大且零散,提取数据特征效率低下且分析定位能力较差等问题,该文基于多任务辅助学习构建全景感知低电压监测模型。提出一种基于DBSCAN聚类的电力客户分群方法,实现高效、准确的电力客户分群。构建一种基于多任务辅助学习的配网低电压成因分析模型,将BiGRU与多任务学习有机结合,面对复杂的电力数据也能有效地定位引发配网低电压的原因。结果表明,实现低电压智能分级可以更好地进行配网低电压可视化监测,模型的构建可大大提升低电压成因分析的效率与准确性。
关键词:低电压;全景感知;DBSCAN;多任务辅助学习;BiGRU
中图分类号:TM714" " " 文献标志码:A" " " " " 文章编号:2095-2945(2024)35-0094-04
Abstract: Aiming at the current problems of large and scattered low voltage data in distribution networks, inefficient data feature extraction, and poor analysis and location capabilities, this paper builds a panoramic sensing low voltage monitoring model based on multi-task assisted learning. A power customer clustering method based on DBSCAN clustering is proposed to achieve efficient and accurate power customer clustering. A multi-task assisted learning based analysis model for the causes of low voltage in the distribution network is constructed. It organically combines BiGRU with multi-task learning to effectively locate the causes of low voltage in the distribution network in the face of complex power data. The results show that realizing intelligent classification of low voltages can better perform visual monitoring of low voltages in the distribution network, and the construction of the model greatly improves the efficiency and accuracy of the analysis of the causes of low voltages.
Keywords: low voltage; panoramic sensing; DBSCAN; multi-task assisted learning; BiGRU
近年来,随着城乡用电户数及负荷持续增加,农田灌溉、农业生产及充电设备大规模接入,造成末端用户低电压问题显著增长,给用户的生产和生活带来严重影响,问题主要表现为供电线路线径小、供电半径长、抗灾害能力差和低压设备运维不到位等[1]。因此,亟需提升对低电压工单、电网设备、服务资源的高效管理与业务支撑能力。
目前,配网低电压数据量大且零散,通过人工方式提取数据特征的工作量过于庞大,且无法精准提取数据的有效特征,同时,现有研究较少考虑特征之间的关联,从而导致分析定位能力较差,难以精准定位配网低电压的具体原因[2-4]。故本文基于DBSCAN聚类方法,提出了一种可以实现高效、准确的电力客户分群的智能分级模型,同时将BiGRU与多任务学习有机结合,构建基于多任务辅助学习的配网低电压成因分析模型,该模型充分利用了BiGRU在时序信息捕获方面的能力和多任务学习中信息共享及关联关系学习的优势,实现配网低电压成因的精准识别,提升了低电压监测技术的效率与精确率。
1" 构建低电压智能分级模型
1.1" 数据预处理与特征提取
在进行聚类分析之前,需要对数据进行预处理。本文研究中,结合数据集中存在的一些问题,对于数据的预处理主要包括填补缺失值、数据类型转换、提取特征值和标准化处理等操作,对数据进行一些必要的转换,以便于后续的建模和分析。
1.1.1" 缺失值处理
数据缺失值会对数据分析或挖掘的结果产生影响。数据缺失值的处理通常采取删除法和填充法。本文研究的数据集中有缺失值,主要存在于用电时刻属性中。若部分用户存在某一时刻的数据缺失,为避免空值导致数据计算有误或者删除客户值造成样本损失带来的影响,对缺失数据用数值0进行填充。
1.1.2" 异常值处理
针对超出正常范围的异常值,采用数据平滑法来统一处理。
1.1.3" 数据类型转换
数据类型转换是将数据源的数据类型统一转换为一种兼容的数据类型。
1.1.4" 特征值提取
特征值提取是从原始数据中选择或构造出有用的特征来降低数据的维度,减少计算量。通过多层次提炼数据,提高模型的泛化能力。
首先,结合供电公司对客户分析的要求,确定电力客户聚类分群这一中心议题,让参与会议的人员交换相互之间的信息,进行头脑风暴,初步选出备选特征值;其次,再对所有备选特征值进行整理、分析、筛选及合并同类项;最后,聘请有关的电力资深专家进行专家评审,经过多次比选,确定数据集的特征值。
1.1.5" 标准化处理
标准化处理是对数据进行线性或非线性的变换,使其符合标准正态分布或者映射到指定的区间内,以消除量纲、量级和分布的影响。由于本文研究的数据集中,存在极端最大值和最小值的情况,因此,对特征值进行标准化处理时采用了Z-Score标准化的方法。
1.2" 模型的构建
1.2.1" DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法是基于密度的聚类算法,常用于非线性或非球面数据集。DBSCAN算法主要有领域半径(Eps)和最小点数(MinPts)2个参数,其值不同,聚类的结果也往往不同。具体步骤如下。
1)任意选取一个点p,并得到所有从p关于?着和MinPts密度可达的点。
如果p是一个核心点,则找到一个聚类。
如果p是一个边界点,没有从p密度可达的点,DBSCAN 将访问数据集中的下一个点。
2)继续这一过程,直到数据集中的所有点都被处理。
1.2.2" 模型构建
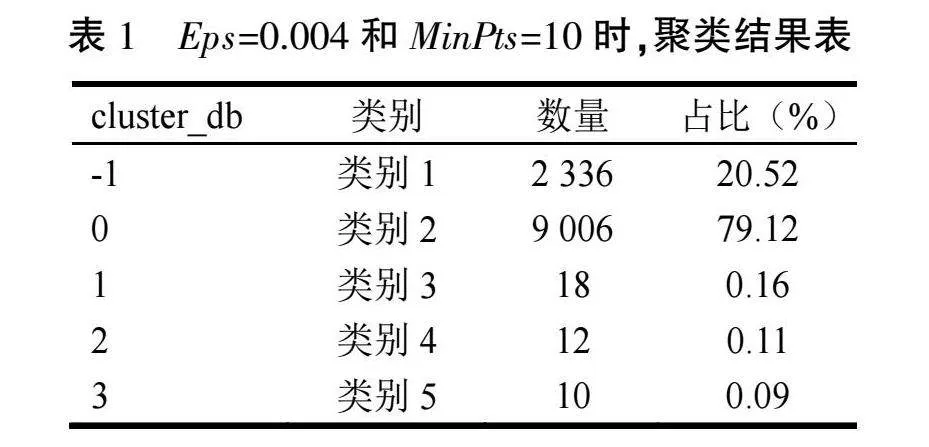
先自定义DBSCAN聚类算法中的2个参数:领域半径(Eps)和最小点数(MinPts),然后将标准化后的数据放在DBSCAN聚类算法中进行训练。不同的Eps和MinPts,会得到不同的模型。“cluster_db”表示聚类的类别,数值-1表示噪声点类,属于偏离类数据,其他非负数值表示某一聚类群。当Eps=0.004,MinPts=10时,其聚类结果见表1。
1.3" 实验与结果分析
1.3.1" 实验环境设计
实验采用由1个master主节点和3个工作节点组成的Spark集群。Client是用来执行Spark任务中的main方法,也是作为Spark的驱动器节点,从Client向Master提交任务;Executor主要负责运行组成Spark中的应用任务task,将数据存在内盘或磁盘中,再将结果返回给Client驱动器进程。
1.3.2" 模型评估与结果分析
轮廓系数(Silhouette Coefficient)是聚类算法的常见评估方法,体现簇的密集与分散程度,是一个较为合适的评价指标。轮廓系数的值介于-1和1之间,该值越接近于1,说明簇越紧凑,聚类越好。
经分析,当Eps为0.006,MinPts为10时,整体聚类效果较好。此时聚类数目为5类,其中类别1为噪声点类别,本文不作深入分析;类别2为标准差相对较小,且其他特征值较为稳定的用电客户;类别3为标准差相对较大,低谷段用电负荷极低,高峰段用电负荷略低于平段用电负荷的用电客户;类别4为低谷段用电负荷明显高于高峰段和平段的用电客户;类别5为标准差极大,用电负荷不稳定,且工作日用电均值和周末用电均值的用电负荷较为不稳定的用电客户。
无论是在工作日还是周末,无论是高峰段、平段还是低谷段,类别2的用电负荷都较为稳定,可以正常供电;类别3、类别4、类别5用电负荷不稳定,可以根据高峰段、平段、低谷段的用电负荷量进行适当的调整,错峰供电,对这些客户提供个性化和精准化的供电服务。
2" 构建低电压成因分析模型
2.1" 配网低电压成因分析模型
2.1.1" 输入层
由于配网低电压用户数据和配网低电压相关数据是2个独立的数据集,无法直接作为模型的输入。本文利用配网低电压用户数据,对配网低电压相关数据中的电流、电压等数据进行关联操作。与此同时,为了确保数据的完整性和一致性,进行预处理操作,经过预处理后的数据会作为模型的输入X,设序列为n的输入数据X=[x1,x2,x3,…,xn]。
2.1.2" BiGRU共享层
首先,经过输入层处理后的数据X,将作为BiGRU共享层的输入,数据进入BiGRU共享层之后,将分别输送到正向GRU神经元和反向GRU神经元中,先经过GRU中的重置门和更新门,利用配网低电压数据样本在当前时间步t的时序特征Xt和上一个时间步t-1的隐藏状态Ht-1,得到保留部分隐藏状态Ht-1后的重置特征Rt及替换部分当前状态Xt后的更新特征Zt,如式(1)、(2)所示。
, (1)
, (2)
式中:Wxr、Whr、Wxz、Whz为权重矩阵;bz和br为偏置。
其次,重置特征Rt和更新特征Zt再结合上一个时间步t-1的隐藏状态Ht-1,得到配网低电压数据样本时间步t的候选隐藏信息t,与此同时,将配网低电压数据样本在时间步t的重置特征Rt、更新特征Zt及候选隐藏信息t进行整合操作,得到配网低电压数据样本在时间步t的时序特征Ht。
最后,将前向GRU神经元和反向GRU神经元计算得到的时序特征t和t合并,得到配网低电压数据样本最终的双向时序特征" ",如式(3)、(4)及(5)所示。
, (3)
, (4)
, (5)
式中:Wxh、Whh为权重矩阵;bh为偏置;⊙为向量间的点乘;tanh为激活函数;t、t分别为前向GRU神经元和反向GRU神经元计算得到的时序特征。
2.1.3" 多任务辅助训练层
为了挖掘并学习各原因间的关联特征,本文模型设置了7个辅助任务帮助提高主任务的泛化能力。其中,主任务为获得引起配网低电压的7种原因(台区出口侧配网低电压、无功补偿不足、三相电流不平衡、配变重过载、户均容量小、供电半径大和低压线路线径细)的主成因。辅助任务分别为:获得由台区出口侧配网低电压引起配网低电压的概率;获得由无功补偿不足引起配网低电压的概率;获得由三相电流不平衡引起配网低电压的概率;获得由配变重过载引起配网低电压的概率;获得由户均容量小引起配网低电压的概率;获得由供电半径大引起配网低电压的概率;获得由低压线路线径细引起配网低电压的概率。
从BiGRU共享层学习的双向时序特征" 在全连接层中对主任务进行辅助特征融合和降维运算,对子任务进行降维运算。
经过全连接层运算后的双向时序特征将作为任务层的输入,并在任务层中利用softmax激活函数,计算降维后配网低电压数据特征的类别概率分布yt,并对yt进行最大值的下标取值操作,得到预测结果ypredict。
得到预测结果ypredict之后,将利用交叉熵损失函数计算主任务和各子任务的预测结果ypredict与真实结果ytrue之间的误差LOSSi,并根据主任务和各子任务的损失权重Wi,对主任务和各子任务的损失加权求和,计算模型的整体损失TotalLoss。在TotalLoss反向传播过程中,各任务的全连接网络会与BiGRU共享层之间进行参数交互,共同优化模型参数,寻求模型最优解,促使模型学习更好表征。
2.2" 实验及分析
2.2.1" 数据集及数据预处理
实验使用的数据来自于本市电网获取的配网低电压数据集,通过对原始数据进行缺失数据填充、异常数值替换及单位统一等操作,构建了用于本实验的无标签原始数据集。
由于原始数据的局限性,本项目仅针对台区出口侧配网低电压、配变重载、配变过载、无功补偿不足和三相电流不平衡5种原因进行分析。
2.2.2" 实验环境及超参设置
本项目实验使用12th Gen Intel(R) Core(TM) i7-12700 2.10 GHz处理器,NVIDIA RTX 2080Ti显卡,在Anaconda(基于python3.8)环境下进行。同时,将数据集的80%划分为训练集,20%划分为验证集,BiGRU的层数设置为4层,每层128个神经元,使用Adam优化更新网络参数,初始学习率为0.001,训练轮数为500轮。
2.2.3" 评价指标
由于5种原因的数据占比分布非常不平衡,评估指标只采用准确率(Accuracy)是不可靠的,故本文实验又加入了精确度(Precision)、综合指标F1-score及Recall等适用于数据分布不平衡情况的评估指标,用来综合评估模型分析定位引发配网低电压原因的能力。
Accuracy代表被正确分类的样本总数占总样本数的比例;Precision代表精确度,表示真实正样本占预测为正样本的比例;Recall代表召回率,表示正样本被正确分类的样本总数占正样本总数的比例;F1-score代表Precision和Recall的调和平均,越趋近于1表示分类的综合性能越好。
2.2.4" 实验与结果分析
1)损失占比分析。为促进模型更好地理解任务之间的关联性、平衡各任务对模型的影响,并提升模型性能,本文对比了各任务在不同损失占比情况下模型的性能。
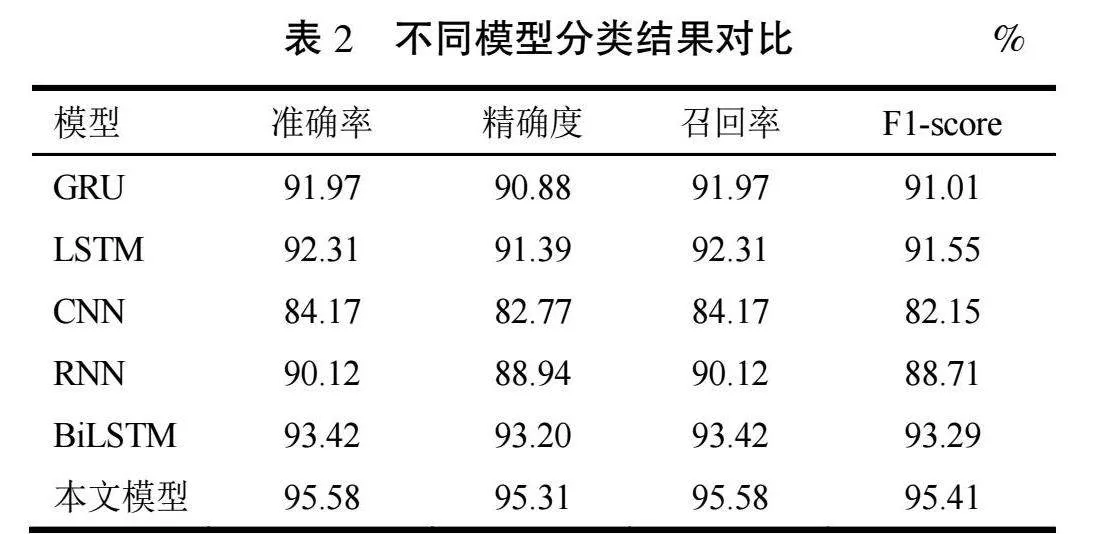
当主任务的损失占比在0.90及以上时,模型的各项评估指标都很出色,都在95%以上,其中,当各辅助任务损失占比分别为0.005、0.015、0.05、0.01和0.02时,模型的准确率、召回率、F1-score达到最高,分别为95.58%、95.58%、95.41%;而当主任务和辅助任务的损失占比分别为0.80、0.03、0.03、0.08、0.03和0.03时,模型的各项评估指标达到最低,相比最高值分别下降1.35%、1.12%、1.35%和1.17%。出现这种情况,原因在于辅助任务损失占比偏多且各辅助任务的占比分配不合理,致使模型的性能下降。
2)消融分析。针对本文提出的多任务辅助学习模块进行消融分析。本文通过实验对比添加辅助任务与不添加辅助任务的损失和准确率,可得模型在添加辅助任务的情况下,模型的准确率比未添加辅助任务的准确率整体偏高。与此同时,在前200轮的训练中,添加辅助任务的模型损失比未添加辅助任务的模型损失整体偏大,且损失下降速度相比较慢;而从200轮以后,添加辅助任务的模型损失比未添加辅助任务的模型损失普遍偏小,并且损失下降的速度比其更快。
此外,还将本项目提出的模型与GRU、LSTM、BiLSTM、CNN和RNN 5种分类模型进行对比实验,得到的模型分类结果见表2。
由表2可以看出,本文采用的模型分类效果普遍高于其余5种分类模型,具有更好的泛化能力。
3" 结束语
综上所述,在配电网供电中,低电压属于较为常见的问题,但其较容易影响到用户的正常用电,甚至对用户的用电设备造成损害,为了提升配网低电压成因分析的效率与精确程度,本文基于多任务辅助学习研究了全景感知低电压监测技术。研究结果表明,该监测模型可实现高效、准确的电力客户分群,面对复杂的电力数据能有效地定位引发配网低电压的原因,给相关部门提供更加精准的结果。
参考文献:
[1] 陈光明.配电线路低电压问题分析及综合治理方案研究[J].电气技术与经济,2023(10):1-3.
[2] 曾小刚,欧阳安妮.配电网低电压成因分析及治理措施[J].科技创新与应用,2022,12(8):108-110.
[3] 夏得青,向星宇,李宽龙,等.农村配电网低电压治理研究进展[J].电气技术,2023,24(6):1-5.
[4] 王小虎,戴乔旭.低电压问题成因分析及措施制定系统的设计[J].机电工程技术,2022,51(12):238-240,256.
猜你喜欢
电子制作(2017年1期)2017-05-17 03:54:27
广西电力(2016年4期)2016-07-10 10:23:38
通信电源技术(2016年4期)2016-04-04 02:58:06
通信电源技术(2016年4期)2016-04-04 02:57:20
当代化工研究(2016年2期)2016-03-20 16:21:17
电测与仪表(2015年16期)2015-04-12 00:44:38
电测与仪表(2015年9期)2015-04-09 11:59:38
电测与仪表(2015年8期)2015-04-09 11:50:08
电机与控制应用(2015年10期)2015-03-01 03:50:18
电测与仪表(2014年7期)2014-04-04 12:09:30
