
中文分词方法及常用国内分词工具
2024-12-31 00:00:00种惠芳
三角洲 2024年14期
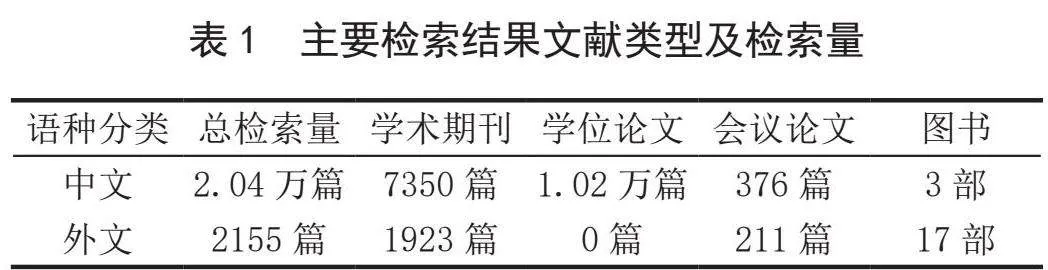



为使机器能够更充分地理解输入语句,必须首先对输入语句进行分词。与英文等其他具有天然分隔标识符的西方语言相比,中文缺少此类符号,为此研究中文分词方法及常用分词工具,对中文自然语言处理具有非常重要的意义。中文分词是将输入计算机中的连续中文字序列按照某种规则进行分割,切分为具有相对独立意义中文词序列的过程。中文分词在众多涉及汉语的自然语言处理领域(如模式识别、机器翻译等)都起着非常重要的作用,分词可以将复杂非结构化语言学问题转化为结构化数学计算问题,提高问题建模能力。与英语等其他语言相比,中文无明显分词特征,切分准则不统一;中文存在大量一词多义语言现象,容易出现歧义;未登录词等其他语言分词需要考虑的语言现象时中文分词也需考虑,为此中文分词成为众多从事自然语言处理研究学者的研究内容。在中国知网上以“分词”为检索词,以“主题”为检索字段进行文献检索,截至2023年8月,共检索到中文文献2.04万篇,文献类别情况如表1所示。
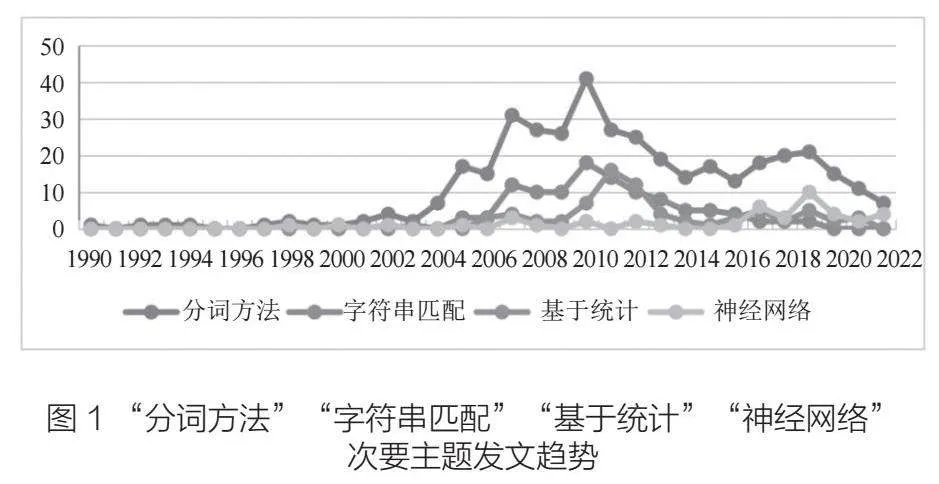
从发展历程角度看,中文分词方法可划分为基于词典匹配的分词方法、基于统计的分词方法和基于深度学习的分词方法。在中国知网上以“中文分词方法”主题词进行检索,并对检索结果按次要主题“分词方法”“字符串匹配”“基于统计”“神经网络”进行文献趋势对比分析,可见自2017年以来,深度学习方法逐步代替匹配与统计两类方法成为分词方法研究的主流,如图1所示。
基于词典匹配的分词方法主要是通过各种算法将文本与词典进行匹配,从而实现对输入内容的划分,匹配算法的设计和词典的构建直接影响分词的效能与性能,该阶段分词方法主要研究词典的构建和匹配算法的设计。
基于词典匹配的分词方法简单,分词速度快,但分词准确率与词典质量密切相关,也难以处理未登录词及一词多义等语言现象。
基于统计的分词方法建立在统计指标和统计模型基础之上,通过计算词与词之间的组合出现概率来确定是否进行分词,其核心思想是:按照上下文顺序,相邻两字的频数统计次数越大,则其成为一个词语的概率越大。
基于统计的分词方法建立在词频数学计算基础之上,不考虑词意,一定程度上可以解决基于词典匹配的分词方法中未登录词及一词多义问题,但该方法需要基于大规模训练语料来实现。随着互联网语料规模的不断增大、深度神经网络技术的不断发展和计算机算力的不断提升,基于统计的分词方法正逐渐被深度学习分词方法取代。
2006年,Hinton等人提出了深度学习概念,强调深度学习模型学习得到的特征数据对原数据有更本质的代表性。2012年,AlexNet在ImageNet图像分类比赛中以碾压第二名的成绩激起了人们对深度学习研究的热潮,如何使用深度学习方法提高中文分词效果也成为众多学者积极研究的热点。在中国知网以“深度学习”和“中文分词”为主题词进行检索,共获得414篇检索结果,其中最早关于深度学习的中文分词文献出现在2015年。
基于深度学习的分词方法与基于统计的分词方法相比,无需人工进行特征选择,且特征学习深度不受限。典型深度学习分词方法以循环神经网络为基础,目前越来越多的深度学习模型被应用于中文分词中,如林德萍将预训练模型BERT引入中文分词的过程实现了对新闻文本的高效分词。
常用国内中文分词工具及简要分析
jieba(中文名为“结巴”)是优秀的中文分词第三方库,可以进行简单分词、并行分词、命令行分词,支持精确模式、全模式、搜索引擎模式和Paddle模式四种分词模式,支持繁体分词和自定义词典,除分词功能外,还支持关键词提取、词性标注、词位置查询等功能,支持C++、JAVA、Python语言。精准模式试图将句子进行最精确的切开(分词后的概率连乘最大),适合文本分析,已被分出的词语将不会再次被其他词语占有;全模式将句子中所有可能成词的词语都扫描出来(如果单字被词语包含,不扫描出单字),速度快,但可能存在歧义;搜索引擎模式在精确模式的基础上,对长词(字数gt;2)再次切分,提高召回率,适用于搜索引擎分词;Paddle模式使用Paddle(飞桨)深度学习框架以加速分词,jieba 0.40及以上版本支持Paddle模式,相对于前三种传统分词算法,Paddle模式采用了基于卷积神经网络的深度学习模型,可以获得更高的分词准确度和更快的分词速度。
目前,jieba不提供可视化应用程序接口,用户需在编程环境中调用来实现,代码示例如下。
import jieba
s1=”我用手一把把门把手把住了”
word=jieba.lcut(s1)
print(word)
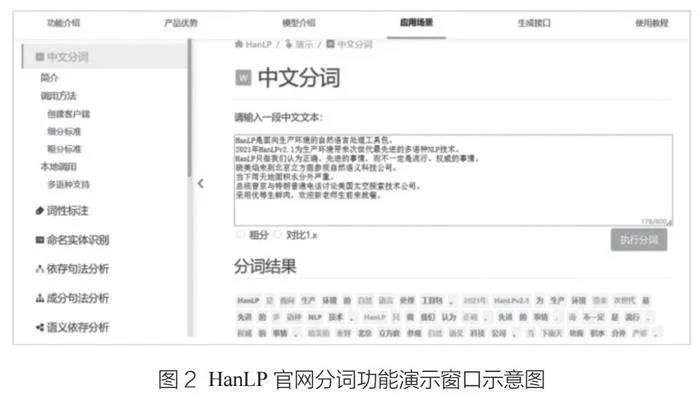
HanLP是一个提供分词、词性标注、关键词提取、自动摘要、依存句法分析、命名实体识别、短语提取、拼音转换、简繁转换等功能的自然语言处理工具包,支持包括简繁中英日俄法德在内的104种语言分词功能,采用全球范围内已知最大的亿字级别中文分词词库,支持CRF模型分词、索引分词、N-最短路径分词、NLP分词、极速词典分词、标准分词、深度学习分词、自定义词典分词等,各种分词方式及其特点如表2所示。
HanLP官网提供了不同分词方法的相应接口及功能演示窗口(如图2所示),用户也可以像使用jieba库一样通过编程环境调用HanLP模块来使用,HanLP支持C++、JAVA、Python语言的使用。
from pyhanlp import *
print(HanLP.segment(‘我用手一把把门把手把住了’))
THULAC是清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC工具分词准确率高、速度较快,曾在Windows测试环境下利用第二届国际汉语分词测评发布的国际中文分词测评标准对国内不同分词软件进行了速度和准确率测试,测试结果显示其综合性能排名靠前。THULAC支持C++、JAVA、Python语言的使用,在其官网上提供了网页版在线平台演示功能(如图3所示)。
FoolNLTK是一款采用BiLSTM算法实现的开源深度学习中文分词工具包,可提供分词、词性标注、实体识别功能,也支持用户自定义字典以加强分词效果。FoolNLTK需在编程环境下安装并调用工具包来进行分词,示例如下。
import fool
print(print(fool.cut(‘我用手一把把门把手把住了’)))
SnowNLP是一个处理中文文本内容的python类库,其主要功能包括分词、词性标注、情感分析、汉字转拼音、繁体转简体、关键词提取,以及文本摘要等,其分词功能采用了基于字符的生成模型方法。SnowNLP需在编程环境下安装工具包后调用该工具进行分词。
import snownlp
print(snownlp.SnowNLP(u’我用手一把把门把手把住了’).words)
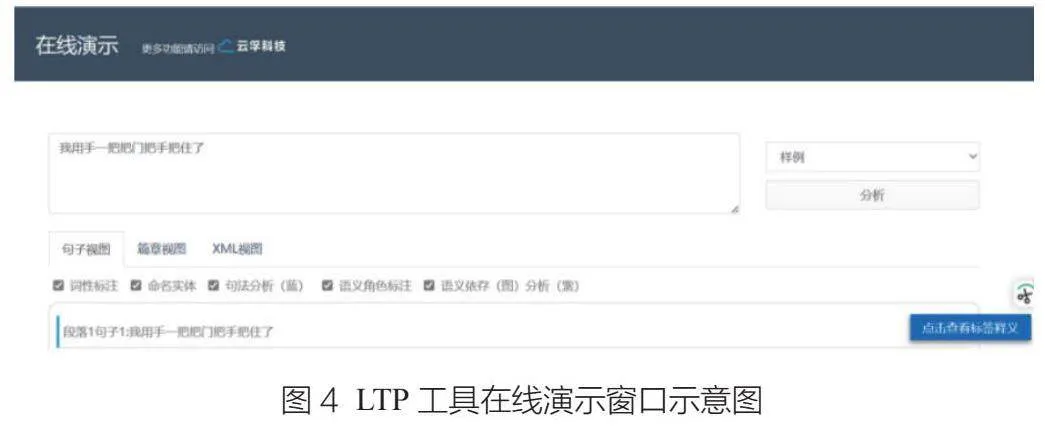
LTP是由哈尔滨工业大学社会计算与信息检索研究中心开发的一款集中文词法分析(分词、词性标注、命名实体识别)、句法分析(依存句法分析)和语义分析(语义角色标注、语义依存分析)六大功能为一体的自然语言处理工具集,其最新4.0版本基于多任务学习框架进行统一学习,使全部六项任务可以共享语义信息,达到了知识迁移的效果,既有效提升了系统的运行效率,又极大缩小了模型的占用空间,采用了基于预训练模型进行统一的表示,有效提升了各项任务的准确率,基于教师退火模型蒸馏出单一的多任务模型,进一步提高了系统的准确率,基于PyTorch框架开发,提供了原生的Python调用接口,通过pip包管理系统一键安装,极大提高了系统的易用性。该工具官网上提供了详细的说明文档,并提供在线演示功能,用户可以便捷使用。
from ltp import LTP
ltp = LTP()
words = ltp.pipeline([‘我用手一把把门把手把住了’],tasks=[“cws”],return_dict=False)
除了上述六个分词工具,还存在如NLPIR、CoreNLP、NLTK等中文分词工具,表3集中展示了上述六个中文分词工具的关键特点。
中文分词技术正在由以传统字符匹配方法和统计方法为主的分词方法向由深度学习方法为主的阶段过渡,新的深度学习方法也不断被应用于分词任务中。随着语料数据的不断增加和计力的增强,中文自然语言处理过程中是否需要单纯的分词阶段是相关研究人员探讨的问题,也将是笔者下一阶段研究的内容。此外,笔者认为,数据科学和语言科学如何更好地融合以发挥彼此优势也是值得探讨的课题。
(作者单位:国防科技大学)
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
文苑(2019年24期)2020-01-06 12:06:50
智富时代(2019年6期)2019-07-24 10:33:16
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
