
基于改进实用拜占庭容错的可信分布式区块链信任机制研究
2024-12-31 00:00:00张英豪肖满生陈大鹏周荣烨
软件工程 2024年7期
关键词:区块链技术

关键词:区块链技术;PBFT;信誉模型;信任机制
0 引言(Introduction)
《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》中明确指出要发展云计算、大数据、物联网、工业互联网、区块链、人工智能、虚拟现实和增强现实七大数字经济重点产业。在此背景下,区块链技术[1]再次得到社会各界的广泛关注与深入应用。实用拜占庭容错算法,作为区块链共识算法[2-4]中最广泛应用于联盟链的投票类算法,有效地解决了节点间通信可能出现的拜占庭将军问题[5],进一步提升了区块链技术的稳定性和可靠性。但是,实用拜占庭容错算法存在主节点选取随机性大、缺乏信誉机制、易遭受Sybil女巫攻击[6]及节点间的通信次数过多等问题,导致整个系统的共识效率低与链上空间存储冗余。
针对上述问题,对PBFT共识算法进行研究,设计信用模型[7-9]和投票机制,用于动态更新用户状态,并根据节点的行为达成共识,提出具有分组评分机制和人工蜂群优化共识过程的算法[10-12],缓解网络节点通信的骤增,降低恶意节点的影响。TANG等[13]通过引入信任公平评分机制,动态调整共识节点列表,简化共识过程,优化共识效率。
基于上述研究,本文提出一种改进PBFT算法设计的可信分布式信任机制,即TM-PBFT。首先,该机制设计了多因素分权节点信誉模型,通过分层共识优化其三阶段协议中一致性协议的预准备阶段。其次,采用IPFS星际文件系统实现节点数据的分布式存储。通过与其他模型进行对照实验,结果证明TM-PBFT在通信效率上具有显著优势。
1 改进PBFT分布式信任机制设计(Distributedtrust mechanism design based on improved PBFT)
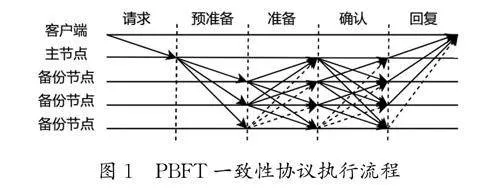
PBFT共识算法的本质是一种状态机副本复制算法,为了保证节点在分布式系统内达成共识,需要3种协议以满足算法的安全性与活性,即一致性协议、检查点协议和视图更换协议。一致性协议作为PBFT共识算法的核心协议,执行顺序分为5个步骤(图1)。
如图1所示,一致性协议包含5个节点,自上而下分为1个客户端节点、1个主节点和3个备份节点,其中最底端的备份节点为拜占庭节点。垂直线表示过程分界线,水平线表示各节点,箭头线表示消息广播由一个节点发送到另一个节点,虚线箭头代表恶意节点的错误信息或不传递信息。
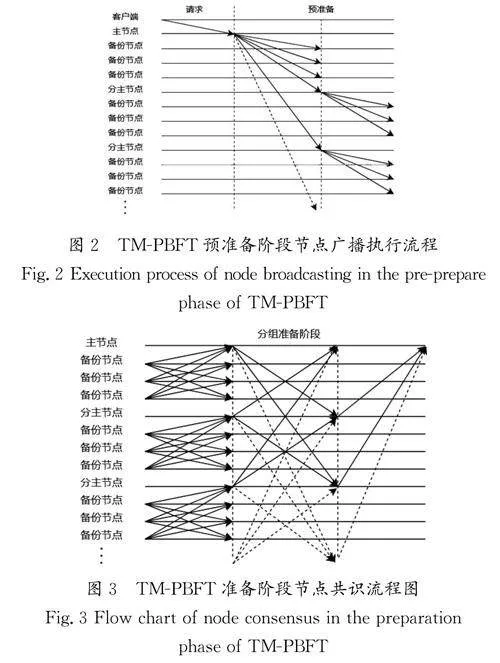
PBFT的一致性协议是一种相对高效和安全的共识算法,但节点的信息传输与备份节点共识的并发操作仍然存在改进和优化的空间。每个节点都需要广播自己的消息给其他节点,会造成通信时延与复杂度过高,每个操作都必须经过3个阶段(预准备、准备和提交)才能达成一致。因此,本研究提出一种节点预准备分层共识对协议进行优化,改进后的TM-PBFT预准备阶段节点广播执行流程如图2所示。
在请求阶段,客户端向主节点传输信息并进行分发;在预准备阶段,对节点进行分组,图2中的虚线箭头线代表未画出的其他分组分主节点。
PBFT中的每个节点都需要广播自己的消息给其他节点,这会造成大量的消息传输,可以通过压缩、合并和筛选消息减少传输的数据量,从而提高网络的效率。准备阶段引入分组并发共识机制,使节点能够并行地处理请求。TM-PBFT准备阶段节点共识流程图如图3所示。
图3中,实线箭头代表预准备阶段之后,节点进行广播共识;虚线箭头代表遭受Sybil女巫攻击的恶意节点的虚假信息或者不进行广播的节点信息,将传统PBFT算法的准备阶段分成3个部分,主节点分组并发共识,有效地解决了原始拜占庭容错[5]算法效率不高的问题,将节点之间两两确认共识的复杂度从O(n2)降低至O(log n)。
2 信誉模型设计(Design of reputation model)
为了解决PBFT共识算法中节点选取随机性高、优劣节点混杂的问题,设计节点信誉模型用于评估参与节点行为质量,将节点分为3种类型:正常节点、故障节点、恶意节点。引入节点奖惩机制,信誉模型使用历史数据和参与者之间的交互数据计算每个参与者的信誉分数,以评估参与节点的可信度和价值,旨在通过激励节点积极性,进而提升系统共识效率。
设每个加入区块链的节点的初始信誉分数Rinit 为50分,低于40分的节点Rbad 不参与共识,信誉分数最高的节点Rmax为100,到达100分即不再增加。
节点信誉分数的增减由多种因素共同决定,如节点鲁棒性、节点投入成本、通信成功率、节点间的投票数及参与共识轮次等。
节点鲁棒性评估:在每个节点加入区块链系统参与共识前,对自身稳定性与算力进行评估,剔除垃圾节点,防止Sybil女巫攻击,评估指标为交易吞吐量Tt 与响应能力Rb,节点鲁棒性评估公式Nr 为(α1,α2 为评估系数):
节点投入成本:节点加入区块链系统需要根据上述评估结果提交对应比例的保证金Pn 作为置信凭证,保证金的数量与Nr 成反比,但不影响节点信誉分数评估,若所有节点保证金总和为PSum,则节点保证金对节点信誉分的影响P 为
通信成功率:每一次成功通信,节点的置信度都会提高,总通信成功率C 为通信成功次数Csuc 除以总通信次数Csum,其计算公式如下:
节点间的投票数:为提高各个节点间的参与度,给节点赋予投票权,给每个与本节点参与过信息交互的节点进行投票。规定每个节点可以给任意除自身外的交互过的节点投票,每个节点有1票,在每轮共识结束后统计票数,票数高的节点参与主节点选举,避免主节点共识轮数过多而产生中心化特征,增加共识成功概率,提升可信度。设有n 个节点,Vi 代表节点i对节点j 的投票,Vj 代表节点j 的总票数,计算节点间投票数的公式如下:
参与共识轮次:节点的可信度与节点参与的共识轮次呈正相关,参与轮次越多,说明节点共识安全越值得信赖。因此,给节点信誉模型引入衰退函数,当节点n 参与了前i 轮次的共识且不被标记为拜占庭节点,则(i+1)轮次的信誉分数不受衰退函数的影响;当节点n 未参与前i 轮次的节点,则使用如下衰退函数f(n)计算(θ 为衰退指数,s 为节点总共识轮次),计算参与共识轮次的公式如下:
结合上述多层次因素考虑,可以得出信誉分数的增减机制,主节点的选举则与节点信誉分数呈正相关,节点信誉分数Ri 的计算公式如下(β1,β2,β3,β4,β5 分别为节点信誉权重):Ri=Rinit+β1Nr+β2P+β3C+β4Vj-β5f(n),Ri∈[0,100]
在上述信誉模型中,节点计算信誉分数会产生额外的时间与算力成本,进而降低系统共识效率,但不计算节点信誉分数又会导致系统出现受Sybil女巫攻击、节点产生中心化特征、备份节点产生惰性等问题,因此系统设定每进行3次共识则计算1次信誉分数,每计算3次信誉分数则进行1次主节点选举,这种方法极大地提高了参与节点的共识积极性,确保了系统的安全与高效。
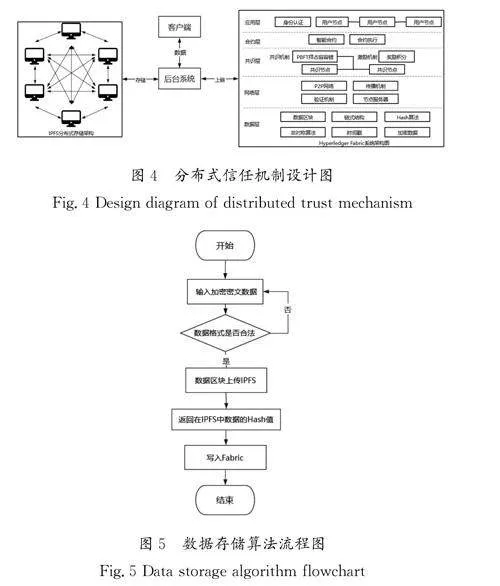
本设计以后台服务开发为核心,将所设计的后台系统作为连接客户端、IPFS及Fabric区块链的服务部件。分布式信任机制设计图如图4所示。数据存储算法流程图如图5所示。
IPFS存储文件的过程是分布式的,文件不是存储在单个中心化服务器上,而是分布在多个节点上。因此,IPFS在存储和传输文件方面具有较高的可靠性、安全性和效率。IPFS与区块链结合,为构建可信的分布式信任机制提供了一种创新的解决方案,并在未来的数字经济中得到了广泛应用。
当大量数据需要可靠实时地存储和验证时,必须将数据以某种形式存入区块链。传统区块链系统的数据存储容量与速率非常低,无法存放大规模数据。基于此,利用“区块链+分布式存储”的方式可以解决大规模数据上链的问题,将原始数据存储于分布式文件管理系统中,并将源文件的地址存储于区块链,用户可以通过区块链上文件的地址信息随时获取这些数据。同时,为了保证IPFS上的数据不被篡改,必须将文件的指纹(哈希算法结果)也一并存入区块链,这样用户可以对链上数据进行验证,以确定数据的完整性与可靠性。
3 理论与实验分析(Theoretical basis andexperimental analysis)
实验采用Java编程语言设计开发出一个多节点高并发的区块链系统,在吞吐量、共识时延及通信开销等方面与文献[14]中的C-PBFT共识算法进行实验对比分析,系统开发配置信息为Intel(R) Core(TM) i5-7300HQ CPU@2.50GHz双CPU和16 GB运行内存,开发软件使用操作系统的版本为Ubuntu 20.04,Node.js的版本为10.16.0,通过Docker搭建Hyperledger Fabric分布式集群和IPFS。
3.1 吞吐量
吞吐量对比是指通过在同一设备单位时间内完成交易传输数据的数量,即TPS(Transaction Per Second),其公式如下:
其中:Transaction 为单位时间内传输数据的数量,Δt 为传输数据所用的时间,吞吐量通常与硬件因素密切相关,因此在相同硬件条件下,所设计的系统吞吐量越大,则表示系统共识效率越高。数据吞吐量对比结果如图6所示。
图6的横坐标代表节点数量,纵坐标代表数据吞吐量。随着节点数量的增加,3种算法的吞吐量都有一定幅度的减少,而在相同的节点数量下,TM-PBFT 的吞吐量明显高于传统PBFT算法的吞吐量,略微高于对照实验的C-PBFT算法的吞吐量。并且,随着节点的增加,即增加共识次数,改进后的TMPBFT算法在吞吐量方面有明显的优势。
3.2 共识时延
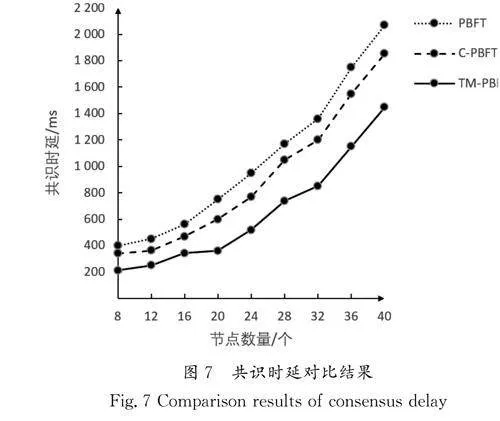
共识时延对比是指不同共识算法在相同网络架构下的共识过程所需的时间延迟对比。通过对步长为4的节点数量进行增加,确保实验的准确性。不同节点数量重复10次实验,将10次实验的时延总和的平均值作为最终结果,确保实验的一般性。共识时延对比结果如图7所示。
由图7可知,共识时延与节点数量呈正相关,即节点数量越多,则共识时延越久。优化了一致性协议的TM-PBFT算法与C-PBFT算法和传统PBFT算法相比,在共识时延方面具有显著优势。
3.3 通信次数
通信次数是指各节点之间两两进行信息传递的次数。通常情况下,通信次数越多,共识效率越低,传统PBFT共识算法通信次数计算公式如下:
其中,K 为对节点进行分组的簇数。对于本文设计的TMPBFT算法,同样对节点进行分簇处理,通过公式(10)计算得到通信总次数:
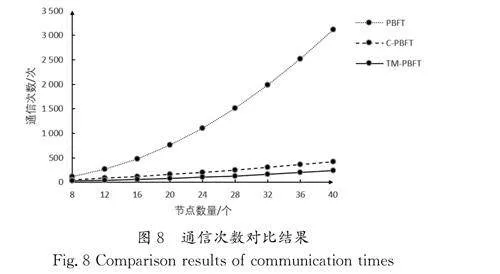
利用公式(8)和公式(9)得到3个阶段的通信次数对比结果如图8所示。
实验结果表明,在节点数量相同的情况下,分层对组内节点进行共识相比于原始的PBFT算法,通信次数大大降低,而在40个节点时,相较于传统PBFT 算法,通信次数下降了85.8%,相较于C-PBFT算法,通信次数下降了27.7%,呈现出节点越多,TM-PBFT算法与传统PBFT算法和C-PBFT算法的通信次数相差越大的趋势。
4 结论(Conclusion)
通过对PBFT算法的深入研究,将改进的PBFT共识算法同IPFS星际文件系统相结合,提出一种效率优化的分布式信任机制。改进后的共识算法有效地优化了PBFT共识算法存在的通信复杂度高和通信效率低等问题;结合IPFS星际文件系统,降低了链上存储压力;引入节点信誉模型避免了受到Sybil女巫攻击、恶意节点充当主节点及替补节点积极性不高等问题。对比实验数据发现,在共识时延、通信开销、系统吞吐量及系统安全性等方面,本文提出的模型的表现明显优于传统PBFT算法和C-PBFT算法,有效地提升了系统的共识效率、安全性和可靠性。但是,该模型仍有许多不足之处,后续将进一步对节点的动态调整副本组成与分层分组进行优化,最大限度地降低通信复杂度。
猜你喜欢
中国医药导报(2017年27期)2017-10-23 19:09:27
中小企业管理与科技·上旬刊(2017年9期)2017-09-27 12:38:20
合作经济与科技(2017年19期)2017-09-18 04:18:40
商情(2017年28期)2017-09-04 18:47:20
卷宗(2017年23期)2017-09-02 03:23:49
会计之友(2017年15期)2017-08-17 09:18:15
对外经贸实务(2017年7期)2017-08-09 22:37:27
西部金融(2017年5期)2017-07-27 00:17:24
中国市场(2017年14期)2017-06-02 22:28:50
档案管理(2017年3期)2017-05-08 22:23:00
