
基于多任务判别器与注意力机制的虚拟试衣研究
2024-12-31 00:00:00魏峰郑军红何利力
软件工程 2024年7期
关键词:特征融合



关键词:虚拟试衣;高效通道注意力机制;多任务判别器;特征融合
0 引言(Introduction)
经济的快速发展和社会生活水平的提高,加速了人们对时尚产品的需求从单一需求特征到“多层次”“多元化”“个性化”需求特征的转变。为此,时尚零售商都在想方设法地为顾客带来更好的体验和感官刺激[1],这使得虚拟试穿技术的研究颇具商业价值。虚拟试衣的概念于2001年[2]被提出,基于图像生成的虚拟试衣技术具有高效、成本低廉的优点[3],目前已有的基于图像生成的虚拟技术,例如具有错位和遮挡处理条件的高分辨率虚拟试戴(High-Resolution Virtual Try-On with Misalignmentand Occlusion-Handled Conditions,HR-VITON)模型的测试结果中存在服装纹理不够真实、特征交互的局限性问题。通过改进,可以让虚拟试衣更加符合现实效果,为用户提供更加逼真的虚拟试穿体验。
本文基于HR-VITON虚拟试衣方法,在条件构造器中引入高效通道注意力机制;在生成对抗网络中新增马尔可夫判别器[4],并采用了多任务判别器结构。实验结果表明,改进后的网络结构提升了生成图像的局部细节清晰度和纹理质量,即提高了生成图像的真实感和质量。
1 本文方法(The proposed method
在HR-VITON虚拟试衣实验中,存在的主要问题是对服装纹理的变形处理不够真实,以及在特征交互和图像细节处理方面有限制。为了改进这一缺陷,本文采用端到端的训练方式对HR-VITON虚拟试衣实验进行了改善。HR-VITON虚拟试衣方法采用FlowNet处理服装变形。然而,FlowNet在处理过程中需要从输入图像对中提取特征,这一环节的特征提取与融合存在不足,从而直接影响了FlowNet的计算效果,特别是在处理服装的细节特征,如纹理和微小的设计元素时,FlowNet的特征提取机制可能无法精确捕捉和恰当处理这些细微变化,在处理服装变形的精细度和真实感方面表现尤为明显。此外,在HR-VITON的图像生成网络中仅包含一个多尺度判别器,没有专门用于判别像素级细节的判别器。这意味着在生成图像的质量上,尤其是在像素级的精确度和细节表现上,网络可能无法达到最优效果。因此,为了提升HR-VITON在服装特征保留和改善衣物与人体交互处理方面的性能,有必要对FlowNet特征提取和融合,以及图像生成网络进行改进。
本文以HR-VITON虚拟试衣方法为基础,提出了基于多任务判别器与注意力机制的虚拟试衣网络(图1),该网络在条件构造器特征融合模块中引入了高效通道注意力机制,提升了对重要特征的关注程度,也提高了网络特征融合和处理能力;在图像生成网络中引入马尔可夫判别器,可强化真实性,提升对局部细节的辨别力,进而提高试衣图像的整体质量。下面围绕改进的条件构造器和图像生成器网络两个部分进行介绍。
1.1 增强特征融合的条件构造器
在高分辨率的虚拟试衣领域,特征金字塔网络(FPN)被广泛应用于提取不同尺度的特征,以捕获衣物和人体姿态的复杂性。然而,FPN的一个局限性在于其通道特征权重是均匀的这意味着所有通道被赋予了相同的重要性,而实际上某些通道可能比其他通道包含更多与任务相关的信息。这种均匀的权重分配可能导致网络无法有效地关注和提取对生成高质量虚拟试衣图像至关重要的细节特征。
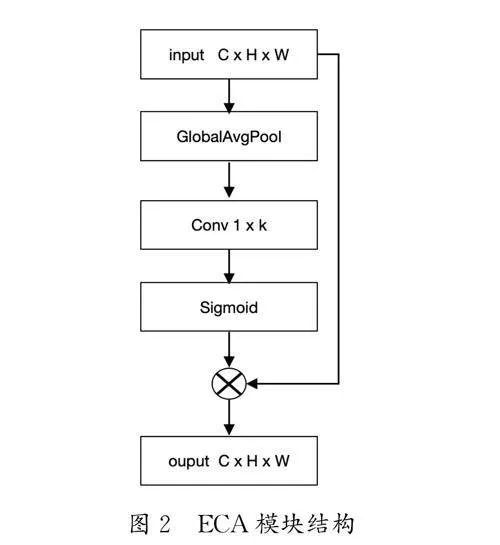
为了克服这一局限性,在FPN的基础上设计了一个高效通道注意力(Efficient Channel Attention, ECA)模块,它通过动态调整通道权重实现突出重要特征的目的,并抑制不相关的特征。ECA模块在各个层级的FPN编码器之后引入,直接作用于从ClothEncoder和PoseEncoder提取的高层特征。ECA模块结构如图2所示,通过全局平均池化(GAP)操作获取每个通道的全局信息,并利用1D卷积动态学习每个通道的权重,ECA模块可以自适应地重加权每个通道的特征响应,从而为特征融合提供了更丰富的表达。假设模块输入特征图X∈RC×H ×W ,其中C 为通道数,H 和W 分别是特征图的高度和宽度。
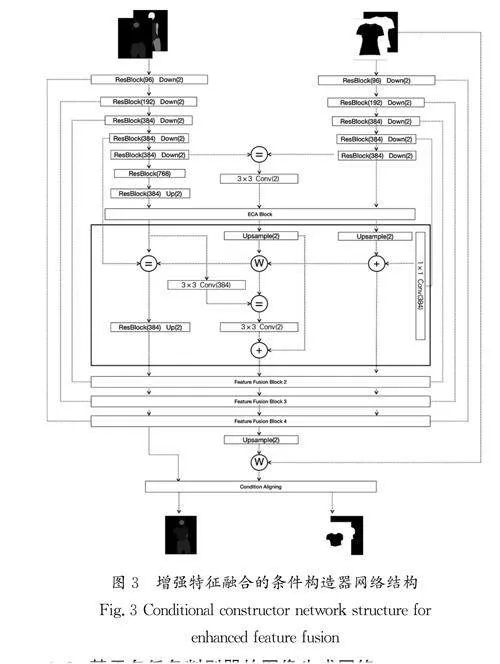
本文采用的增强特征融合的条件构造器主要分为4个步骤,包括特征提取、通道注意力增强、流图生成和特征融合,增强特征融合的条件构造器网络结构如图3所示。首先,对于训练数据中的每张服装图像和姿态图像,使用ClothEncoder和PoseEncoder进行特征提取,提取服装和姿态的关键特征。这些特征通过残差块的多层卷积和池化操作进行下采样,捕获输入图像的细节和上下文信息。提取后的特征通过高效通道注意力(ECA)模块进行通道注意力增强。ECA模块使用全局平均池化和一维卷积动态学习每个通道的权重,强调对当前任务最重要的特征通道。其次,利用这些增强的特征生成流图,流图是通过卷积层生成的,用于指导服装特征到模特姿态的空间映射。最后,通过特征融合步骤将服装和姿态特征结合起来,生成最终的虚拟试衣图像。融合过程包括上采样、1×1卷积和残差块的使用,确保服装特征与模特姿态的有效融合。最终的输出层根据配置选项进行特征的最后处理。整个网络使用一系列如交叉熵损失等损失函数和优化器进行反向传播,以更新网络参数,包括权重矩阵和特征表示。条件构造器网络的设计和实现旨在有效地处理和融合复杂的视觉信息,以生成高度准确和自然的扭曲后的服装图像、服装掩码、试穿服装后的人体分割图。
1.2 基于多任务判别器的图像生成网络
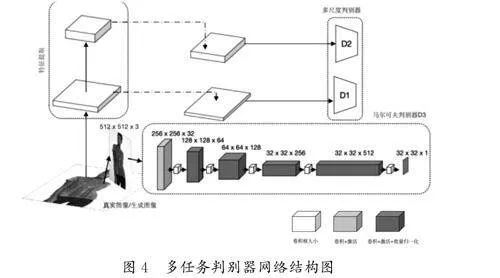
本研究中,对传统的生成对抗网络(GAN)[5]中的判别器结构进行了重要的改进。传统的GAN通常采用单一判别器评价生成图像的真实性。为了提高生成图像的质量和逼真度,本文引入了一种多任务判别器架构,它通过不同类型的判别器协同工作,从全局、局部多个层面对生成图像进行评估。如图4所示,多任务判别器由3个关键部分组成:D1、D2和D3。其中,D1和D2构成了多尺度判别器,它由多个基础判别器单元组成,能够在不同尺度上分析生成图像。这种多尺度策略能够使网络捕捉到生成图像的不同层次,从而更全面地评估其真实性。除此之外,D3判别器采用了马尔可夫判别器的设计理念,这种判别器充分考虑了图像的局部区域,能够更细致地评估图像的局部真实性。马尔可夫判别器的引入,能够有效地帮助模型识别并改进生成图像中可能存在的局部不一致性。
图像生成网络中的生成器由一系列具有上采样层的残差块组成,并且多任务判别器设计采用两个多尺度鉴别器实现条件对抗损失,采用马尔可夫判别器实现二维交叉熵损失[6],并且将频谱归一化[7]应用于所有卷积层。为了训练试穿图像生成器,总损失函数融合了条件对抗损失、感知损失、特征匹配损失及二维交叉熵损失。总损失函数表达式如下:
其中:λα 和λβ 表示不同的损失权重,LcGAN 表示条件对抗损失函数,LVGG 表示感知损失,LFM 表示特征匹配损失,Lp 表示二维交叉熵损失函数。
多尺度判别器实现条件对抗损失使用的是铰链损失函数(Hinge Loss)[8],它是一种用于支持向量机(SVM)和GAN模型的损失函数。在GAN中,它通常用于判别器的损失函数。铰链损失通过衡量模型对真实样本和生成样本之间的间隔来评估模型性能。具体而言,对于真实样本,它追求分数高于某个阈值,而对于生成样本,它希望分数低于另一个阈值。这种损失鼓励判别器能更好地区分真实样本和生成样本,通常导致更稳定的训练和更高质量的生成图像。条件对抗损失的计算公式如下:
其中:LDR 表示真实图像的损失函数之和,LDF 表示生成图像的损失函数之和,N 表示样本个数,x 表示输入的局部图像区域,D(x)表示判别器的输出,λR 和λF 表示不同的损失权重。
感知损失是通过在VGG-19网络的多个层次上比较两个图像的特征表示来计算,旨在捕捉图像在视觉内容和风格上的高层次差异。感知损失函数的计算公式如下:
其中:x 表示生成图像,y 表示目标图像,Fi(x)表示图像x 在VGG网络的第i 层的特征映射,Fi(y)表示图像y 在VGG网络的第i 层的特征映射,wi 表示第i 层的权重,layids表示一个索引列表。
特征匹配损失技术在GAN训练中表现突出,它帮助生成器关注除了最终判别器输出外的其他多个层次的学习,从而获得更丰富和多样化的梯度信息。这样的训练方法通常可以产生更加稳定和高质量的结果。特征匹配损失的计算公式如下:
其中:G 表示生成器,Dk 表示判别器的第k 个中间层,E(sx ) 表示对所有样本sx 取均值,Ni 表示第i 个中间层的特征数量,D(i) k (sx )表示样本sx 通过判别器Dk 中的第i个中间层得到的特种表示,G(sG ,G(sx ))表示生成器G 对样本sx 进行变换后的结果。
马尔可夫判别器使用的是二维交叉熵损失,这种损失函数允许模型关注图像的每个局部区域。对于每个像素点或Patch,模型都会输出一个概率值,表示该区域属于“真实”类别的置信度。通过最小化这个损失,Patch判别器学习区分生成的图像块和真实的图像块,使得生成器在生成图像时,必须在每个局部区域内都尽可能地接近真实图像,从而提高生成图像的整体质量。二维交叉熵损失的计算公式如下:
其中:N 表示图像中的像素点的总数,C 表示类别的总数,yij表示像素点i 是否属于类别j,pij 表示模型预测像素点i 属于类别j 的概率。
2 实验(Experiment)
2.1 数据集和实验设置
本实验采用Python 3.8和 Pytorch 1.8.2 构建软件仿真平台,图像处理器(GPU)采用4090 GPU,内存为24 GB。在实验中,所有训练和测试均在VITON- HD数据集上进行,并且公共超参数的设置与HR- VITON保持一致,其中数据集包含13 679个正面女性和顶级服装图像对。图像的原始分辨率为1 024×768,当需要时,图像被双三次下采样到所需的分辨率。研究人员将数据集分割为训练集与测试集,其中训练集包含11 647对数据,测试集包含2 032对数据。
2.2 评价指标
本文使用Learned Perceptual Image Patch Similarity(LPIPS)[9]、Fréchet Inception Distance(FID)[10]、StructuralSimilarity Index Measure(SSIM)[11]衡量生成图像的视觉质量。其中:LPIPS专注于图像的纹理和细节,而不仅仅是像素级别的差异;FID用来比较一组生成的试衣图像与一组真实图像的统计分布差异;SSIM是一种评估两张图像视觉相似度的指标,它考虑了亮度、对比度和结构3个维度。
2.3 实验结果
2.3.1 直观对比
本文实验采用HR-VITON虚拟试衣方法所带的数据集VITON-HD Dataset。本文将虚拟试衣结果与4种经典虚拟试衣结果进行视觉直观对比,对比结果如图5所示。在图5中,从左到右分别为模特/目标服装图、CP-VTON虚拟试衣效果图、PF-AFN虚拟试衣效果图、VITON-HD虚拟试衣效果图、HR-VITON虚拟试衣效果图、本文虚拟试衣效果图、细节放大效果图。从图5中可以看出,本文方法可以更细致地捕捉和渲染复杂的纹理细节,确保图案的精准对齐,同时保持色彩鲜明、自然。通过对比实验可以观察到,在保留原始服装设计元素的基础上,所生成的图像视觉效果更逼真,其纹理更丰富,颜色过渡更平滑。无论是在微观纹理还是宏观整体视觉上,该方法都优于其他对比方法。
2.3.2 定量对比
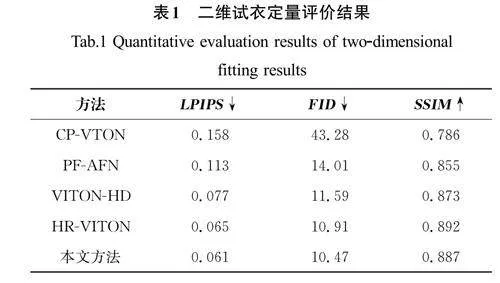
二维试衣定量评价结果见表1。从表1中可以看出,添加高效通道注意力模块和增加判别器后,图像感知相似度LPIPS降低了0.004,FID 降低了0.44,结构相似度SSIM 降低了0.005,训练时间减少了130 min。以上数据表明本文方法生成的图像在感知质量、统计特性和计算效率方面均得到了提升,但在保持结构相似度方面可能还需要进一步优化。
2.3.3 消融实验
为了进一步验证高效通道注意力机制与多任务判别器网络的有效性,本研究设计了消融实验。选择HR-VITON模型、加入注意力机制的HR-VITON(+ECA)、构建多任务判别器的HR-VITON(+MTD)和本文方法作为基线模型,在数据集上进行迭代训练生成结果的LPIPS、FID、SSIM。消融实验定量评价结果如表2所示。
从表2中的数据可以看出,加入高效注意力机制后的虚拟试衣网络的LPIPS降低了0.001、FID降低了0.39、SSIM 提高了0.002;而在构建多任务判别器网络后,LPIPS 降低了0.003、FID降低了0.27,SSIM 降低了0.006。以上结果说明引入高效注意力机制可以有效提升图像的整体质量,注意力机制能够更好地捕捉图像的关键信息,减少冗余和噪声,从而使输出图像更加清晰、逼真;相比之下,构建多任务判别器网络更注重提高感知质量,即在视觉效果上更接近真实场景。通过多任务学习的方法,网络可以更好地理解图像内容,并在保证一定的结构相似性的同时,提高感知质量。然而,该方法的局限性是,为提升感知质量,可能会降低部分结构相似性。
3 结论(Conclusion)
本文提出了一种使用注意力机制增强特征融合的条件构造器,以及设计了一个多任务判别器用于试衣图像生成。使用注意力机制后,网络能够更好地聚焦于衣物和人物的关键特征,从而在虚拟试衣中更精确地生成逼真的图像。同时,多任务判别器的引入,使得网络能够同时完成试衣图像的生成和鉴别任务,进一步提升了虚拟试衣的效果。实验结果表明,与其他虚拟试衣方法相比,本文方法在视觉质量、定量分析等方面有了显著提升,有效地解决了虚拟试衣过程中服装细节保留不足和复杂纹理表现不佳的问题。在未来的工作中,研究人员计划对现有的虚拟试衣网络架构进行改进,不断丰富虚拟试衣图像的数据库,以及探索新的技术手段增强虚拟试衣的视觉效果和提升用户体验。
猜你喜欢
电脑知识与技术(2018年14期)2018-07-12 09:37:50
现代电子技术(2018年9期)2018-05-05 05:42:50
现代电子技术(2018年1期)2018-01-20 18:33:33
数字技术与应用(2017年11期)2018-01-11 13:55:19
现代电子技术(2017年16期)2017-09-07 17:45:33
软件导刊(2017年7期)2017-09-05 06:27:00
无线互联科技(2017年12期)2017-07-18 17:40:58
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
