
基于深度学习的有机番茄鉴别
2024-12-31 00:00:00陈思维李嘉璐卢哲颜文婧
安徽农学通报 2024年13期





基金项目 北京市属高校教师队伍建设支持计划高水平科研创新团队项目(BPHR20220104)。
作者简介 陈思维(2003—),男,吉林长春人,从事机器学习研究。
通信作者 颜文婧(1985—),女,安徽淮南人,博士,副教授,从事生物信息智能处理、图像信号处理、机器学习和模式识别研究。
收稿日期 2024-04-30
摘要 为满足消费市场上不断增长的有机番茄食用与鉴别需求,基于质谱检测数据,本文研究了一种有机番茄快速鉴别深度学习模型。首先,模型使用无监督降维方法对原始质谱检测数据进行降维,提取关键信息;其次,使用长短期记忆网络(Long short-term memory,LSTM)和Transformer网络提取序列信息特征;最后,利用反向传播(Back propagation,BP)神经网络构建分类器,实现面向有机及非有机番茄的精准识别。模型识别准确率在训练集上表现为98.437%,在测试集上表现为97.478%。结果表明,模型在有机及非有机番茄质谱快速检测识别任务上具有一定应用潜力,可部分满足有机番茄市场的发展需求,为有机番茄鉴别提供一定参考。
关键词 深度学习;有机番茄;降维;神经网络;长短期记忆网络
中图分类号 TP391.4;S641.2"" 文献标识码 A
文章编号 1007-7731(2024)13-0095-08
Organic tomatoes identification based on deep learning framework
CHEN Siwei1""" LI Jialu2""" LU Zhe2""" YAN Wenjing2
(1School of Light Industry Science and Engineering, Beijing Technology and Business University, Beijing 100048, China;
2School of Computer and Artificial Intelligence, Beijing Technology and Business University, Beijing 100048, China)
Abstract In order to satisfy the growing demand for organic tomatoes consumption and identification in the consumer market, a deep learning model for rapid identification of organic tomatoes was researched based on mass spectrometry detection data. Firstly, the model used the unsupervised dimensionality reduction method to reduce the dimensionality of the original mass spectrometry detection data and extract key information. Secondly, long short-term memory (LSTM) and Transformer network were used to extract sequence information features. Finally, back propagation(BP) neural network was used to construct classifiers to achieve accurate recognition of organic and non-organic tomatoes. The recognition accuracy of the model was 98.437% on the training set and 97.478% on the test set. The results indicated that the model had potential for application in the rapid detection and identification of organic and non-organic tomatoes mass spectrometry tasks, which could partly meet the development needs of the organic tomatoes market and provide references for the identification of organic tomatoes.
Keywords deep learning; organic tomatoes; dimensionality reduction; neural networks; long short-term memory
番茄具有多种对人体有益的营养物质,如抗坏血酸、烟酸、番茄红素、β-胡萝卜素和槲皮素等[1]。在农业生产中施用部分农用化学品可以适当提高番茄生产率,也可能会影响番茄的矿物质和代谢物含量[2]。有机番茄是指在种植、管理和收获过程中遵循有机农业标准种植的番茄。由于其生产过程中不使用化肥、农药和转基因等农用化学物质[1],其营养成分含量相对较高[3],具有更好的口感。近年来,消费者对有机番茄的需求量越来越高,有机番茄的市场价格高于普通番茄,市面上存在部分利用普通番茄冒充有机番茄的现象,因此,研究快捷实时的有机番茄鉴别技术具有重要的现实意义。
使用质谱仪(Mass spectrometer,MS)可以获取农作物中的化合物信息[4],进而对农作物进行安全和质量分析[5]。许多研究结合MS数据与机器学习(Machine learning,ML)算法,面向食品领域类别的识别、掺假检测等问题构建了智能鉴别模型。例如,Gredell等[6]基于快速蒸发电离质谱法(Rapid evaporative ionization mass spectrometry,REIMS)数据采用随机森林(Random forest,RF)等8种机器学习算法对牛肉质量属性进行预测,实现了牛肉质量属性的准确分类。Lim等[7]基于直接输注质谱数据(Direct infusion-mass spectrometry,DI-MS),构建RF和带径向基函数核的支持向量机(Support vector machine,SVM)模型,实现了对大米的高精度鉴别。
在有机番茄鉴别领域,研究者也提出了相关的机器学习模型,比如,王世成等[8]采用基于稳定同位素比例质谱和液相色谱—高分辨质谱(Liquid chromatography-high resolution mass spectrometry,LC-HRMS)分析技术,筛选有机番茄的标志因子,并结合偏最小二乘法判别分析方法构建模型(Partial least squares discriminant analysis,PLS-DA)实现了面向有机番茄的智能鉴别。De等[9]开发了一种基于质谱—机器学习技术的番茄分类方法,包括质谱数据提取、数据归一化和去噪,通过决策树算法自适应增强(Adaptive boosting,ADAboost)构建了分类模型,对质谱数据进行分类,确定潜在的生物标志物。该模型能够准确地将番茄样品分类为有机和非有机。
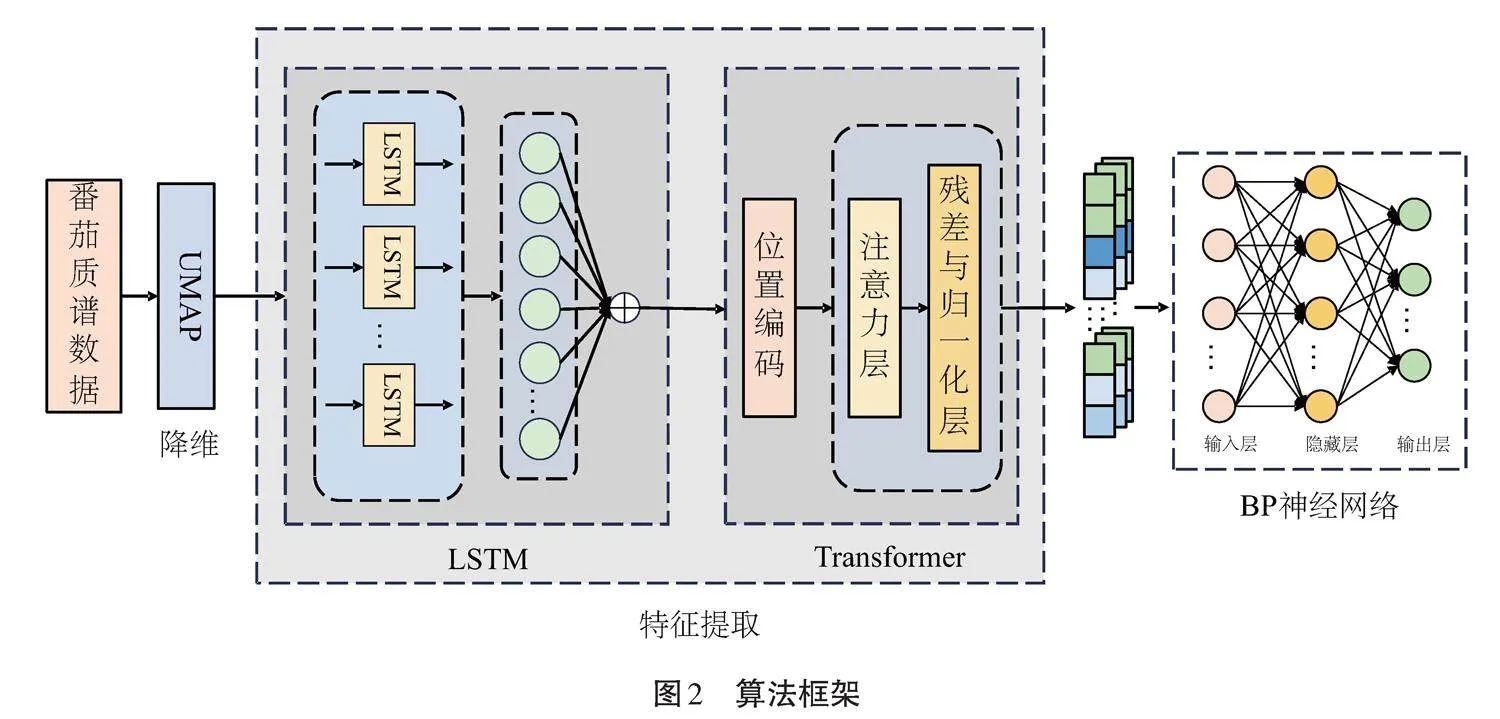
机器学习方法在农作物智能识别领域的应用潜力较大[10],实践中,部分研究方法是对MS数据进行分析,获取关键的差异代谢化合物碎片数据,在代谢化合物分析的基础上构建智能模型。由于差异代谢物分析耗费时间较长,难以满足快速、实时的检测需求。因此,本研究提出一种基于深度学习的检测方法,利用番茄的原始MS数据构建深度学习模型,实现面向有机番茄的快速识别。首先,基于大量有机及非有机番茄MS数据,使用统一流形逼近与投影(Uniform manifold approximation and projection,UMAP)技术,以非监督降维算法提取MS数据中的重要信号特征;其次,基于LSTM和以注意力机制为核心算法的Transformer网络构建深度学习模型,以捕捉特征序列中的长短依赖特征,实现面向有机及非有机番茄的快速识别。
1 材料与方法
1.1 数据准备
本研究采用De等[9]提供的公开数据集。该数据集中的MS数据采集于160个成熟番茄果实,其中有机组80个,由某有机农业合作社提供,该社种植的各种作物在生长过程中均不使用任何农药;非有机组80个,采购自各地的农贸市场,这些番茄在种植过程中均使用过农药。
番茄果实的样品制备如下。首先,将果实在茎瘢痕区切成X形,与花梗相连。然后,将1 cm2的硅胶片60 G(默克公司,达姆施塔特,德国)放在切处,压在番茄上30 s(所有番茄在实验前均不进行任何清洗或处理)。30 s之后,将硅胶板放置在塑料管中。随后在试管中装入400 µL的MilliQ水溶液(MilliQ水∶甲醇=1∶1),漩涡振荡1 min后静置10 min,得上清液。最后,取250 µL的上清液,用甲酸(0.1%)电离后进行分析。
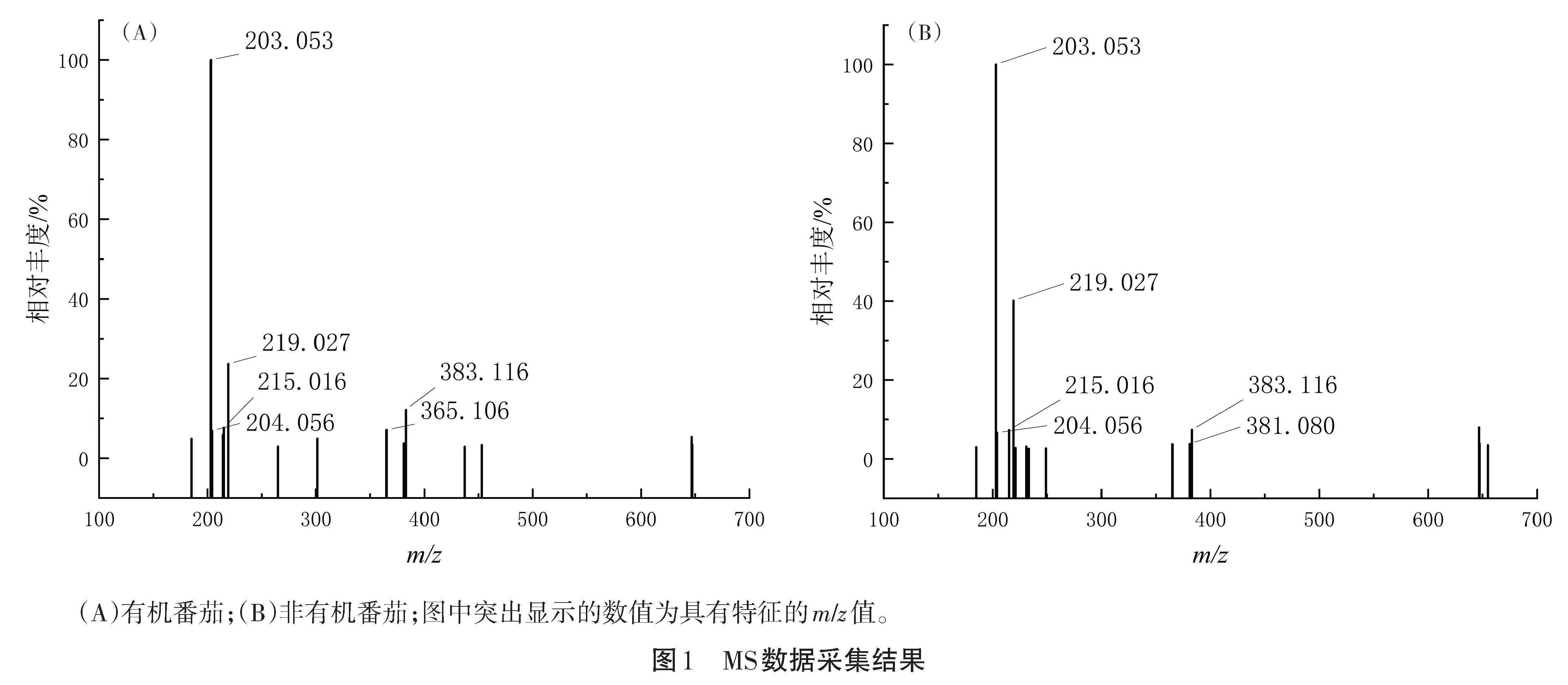
在每天内和每日间随机对样品高分辨率MS数据进行采集。采集过程:直接注入HESI-Q-Exactive轨道rap质谱仪(Thermo scientific,Bremen,Germany),质量分辨率设置为140 000 FWHM,用于正离子模式下的数据采集。MS参数:m/z范围为150~1 700,每个样品进行10次光谱采集,每次光谱进行40次扫描,流动注射速率10 µL/min,氮气鞘气流量为8个单位,辅助气体加热器温度30 ℃,毛细管温度320 ℃,喷涂电压3.70 kV,自动增益控制(Automatic gain control,AGC)目标值设置为106、射频透镜(RF-lens)设置为50。对80个有机组番茄果实和80个非有机组番茄果实进行光谱采集,共获取1 600条光谱数据,数据采集结果如图1所示。
1.2 算法设计
1.2.1 特征降维" 番茄MS数据集是高度非线性数据空间,为提高数据分析效率及分析结果的准确性,采用非监督数据降维算法提取关键信息。使用主成分分析(Principal component analysis,PCA)技术、t分布、随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)以及UMAP对数据分别进行降维分析,以选取效果较好的降维方法。算法框架如图2所示。
(1)PCA降维。PCA是一种经典的无监督学习算法,用于降低高维数据的复杂性并发现数据中的潜在结构。在数据科学和机器学习中,PCA被广泛应用于数据预处理、特征提取和可视化等领域。该方法可对高维数据进行分析,并从中捕获重要信息,通过线性变换,将原始数据投影到一个新的特征空间,使得投影后的特征具有最大的方差,从而捕捉数据中的主要变化模式。通过计算协方差矩阵的特征向量和特征值以进行识别,称为主成分的新特征,实现对原始维度特征的重构,从而达到缩小数据空间以及加快算法计算速度的效果。
(2)t-SNE降维。t-SNE是一种非线性、无监督和基于流形的特征提取方法,用于数据探索和高维数据可视化。通过将高维数据点映射到低维空间(通常是二维或三维)来实现。这种映射过程使得在高维空间中相距较近的数据点在低维空间中保持相对的近距离,而相距较远的数据点在低维空间中保持较远的距离。
(3)UMAP降维。UMAP是一种基于黎曼几何和代数拓扑理论而构建的数据降维算法,依据高维空间映射到低维空间的相似度理论对高维数据进行降维。通过优化流形学习的方法来实现数据的降维,利用局部邻域的连通性来创建一种低维表示,该表示尽可能地保持原始高维空间中数据点之间的距离关系。不仅能够有效地捕捉数据中的非线性结构,还能够处理大规模数据集,并在保留全局结构的同时明显减少降维后的计算复杂度。
1.2.2 特征提取" 采用LSTM和Transformer的方法进行特征提取。
(1)LSTM。LSTM能够避免长序列训练过程中的梯度消失和梯度爆炸问题,更好地捕捉序列之间的依赖关系。LSTM模型的核心是细胞状态,通过遗忘门、输入门和输出门删除或添加信息到细胞状态,分别确定t时刻细胞状态的保留信息和输入的保留信息。
LSTM模型构建了[Ct、Ct−1和Ct],其分别表示当前状态、先前状态和临时状态。在学习过程中,[ℎt]和[ℎt−1]分别表示当前隐藏状态和先前隐藏状态。模型使用遗忘门[ft]、记忆门[it]和输出门[ot]实现面向信息的学习,具体如下。
[ft=σWfxt+Wfℎt−1+bf] (1)
[it=σWixt+Wiℎt−1+bi] (2)
[ot=σWoxt+Woℎt−1+bo] (3)
[Ct=ft×Ct−1+it×Ct] (4)
[Ct=tanhWCxt+WCℎt−1+bC] (5)
对于LSTM的隐藏状态[ℎt],定义如下。
[ℎt=ot×tanhCt] (6)
式(1—6)中,[Wf、Wi、Wo和WC]分别表示遗忘门、记忆门、输出门和当前细胞状态的权重矩阵;[bf、bi、bo和bC]分别表示遗忘门、记忆门、输出门和当前细胞状态的偏移向量;[tanh]为激活函数。
(2)Transformer。Transformer通过注意力机制提高模型的训练速度,具有更好的并行性能。模型将给定的番茄MS数据降维后的特征视为整体,并融合位置编码,以捕获特征信息之间的依赖,提取数据的整体和局部特征。
Transformer模型的核心是多头注意力机制,通过构建Query、Key和Value矩阵[Q]、[K]和[V],对特征序列[X=x1, x2, ..., xn]进行计算处理。多头注意力机制的定义如下。
[MultiHeadQ, K, V=Concatℎead1, ℎead2, …, ℎeadi]"""""""""""""""""""""""""" [Wo] (7)
[ℎeadi=AttentionQWqi, KWki, VWvi] (8)
[AttentionQ, K, V=softmaxQKTdkV] (9)
式(7—9)中,[Wo、Wq、Wk和Wv]为线性投影的权重参数。
Transformer使用残差与归一化层(Layer normalization)对注意力大小进行缩放,以避免梯度消失,同时调整输入数据的均值和方差,加快收敛速度。归一化层的输出记为[L],具体如式(10)所示。
[L=LayerNormX+MultiHeadQ, K, V] (10)
模型将L传递至前馈网络层,该层包括一个双层的全连接网络和一个非线性激活函数。双层的全连接网络实现两次线性变换,第一层使用激活函数,第二层不使用激活函数。前馈网络的输出记为[FFNL],具体如式(11)所示。
[FFNL=σXW1+b1W2+b2] (11)
式(11)中,[σ]为激活函数,[W1、b1、W2和b2]为可学习的参数矩阵。
1.2.3 分类器设置" 分类器采用BP神经网络。BP神经网络基于反向误差传播训练模型,模型由输入层、隐藏层和输出层组成。
BP神经网络是一种多层前馈神经网络,可以实现从输入到输出的复杂映射,由输入层、隐藏层和输出层组成。数据首先从输入层传递至隐藏层,然后通过输出层输出,输入层的输出表示如式(12)。
[a1i=f1j=1nw1ijpj+b1i, i=1, 2, …, n] (12)
输出层的输出表示如式(13)。
[a2k=f2w2kipi+b2k," k=1, 2, …, m] (13)
式(12—13)中,[pj]是输入层第[j]个神经元的输入,[a1i]是包含第[i]个节点的隐藏层的输出;[a2k]是输出层节点[k]的输出;[w1ij]是第[i]、 [j]个节点的连接权重;[w2ki]是第[i]、[k]个节点的连接权重;[b1i]和[b2k]分别为隐藏层第[i、j]个节点的阈值;[f1]、[f2]分别是隐藏层和输出层的传递函数;[n]和[m]分别是输入层节点和输出层节点的数量。
最后一层输出结果通过[Sigmoid]函数映射至(0,1)区间。BP神经网络基于误差的反向传播算法进行训练,通过梯度下降法不断调整网络的权重和阈值,使输出值[yi]逐渐接近参考值[yi]。损失函数采用交叉熵定义。
[L=−yilogy+(1−yi)log(1−y)] (14)
式(14)中,[yi]是真实标签;[y]是模型预测为正类的概率。
神经网络误差是在设定的学习次数内继续进行信息前向传播和误差反向传播的过程,当误差达到指定范围时停止。
1.3 实验平台选择
实验依赖的编译环境为Python 3.8,操作系统为Windows 10。计算机处理器为Intel(R)Core(TM) i5-11400F,主频2.60 GHz;内存16 GB;显卡使用NVIDIA GeForce RTX 3050,显存容量8 GB;使用CUDA进行加速训练。
2 模型分类评价标准
为了对算法的分类效果进行定量分析,本文采取以下指标对模型进行评价:精确度(Precision)、召回率(Recall)、准确率(Accuracy)、马修斯相关系数(Matthews correlation coefficient,MCC)及曲线下的面积(Area under curve,AUC),各个指标的公式如下。
[Precision=TPTP+FP] (15)
[Recall=TPTP+FN] (16)
[Accuracy=TP+TNTP+FP+FN+TN] (17)
[MCC=TP×YN−FP×FNTP+FPTP+FNTN+FPTN+FN] (18)
通常情况下,采用准确率指标不能很好地反映模型的性能,为此可以采用受试者工作特性曲线(Receiver operating characteristic,ROC)来更好地评价模型。以真正例率(True positive rate,TPR)为纵轴,以假正例率(False positive rate,FPR)为横轴,在不同的阈值下获得坐标点,并连接各个坐标点,得到ROC曲线。曲线下的面积AUC可以直观地评价分类器的好坏,ROC曲线越接近左上角,AUC越大,该模型的性能越好。
[TPR(%)=TPTP+FN×100] (19)
[FPR(%)=FPTN+FP×100] (20)
式(15—20)中,[TP]表示正样本被正确预测为正样本的个数;[FP]表示负样本被错误预测为正样本的个数;[FN]表示正样本被错误预测为负样本的个数;[TN]表示负样本被正确预测为负样本的个数;精确度表示在所有被预测为正样本的样本中,真实的正样本占的比例;召回率表示在真实正样本中,被预测为正样本占的比例;准确率表示预测正确的样本数占所有样本数的比例;马修斯相关系数表示实际分类与预测分类之间的相关系数。
3 结果与分析
3.1 降维结果可视化
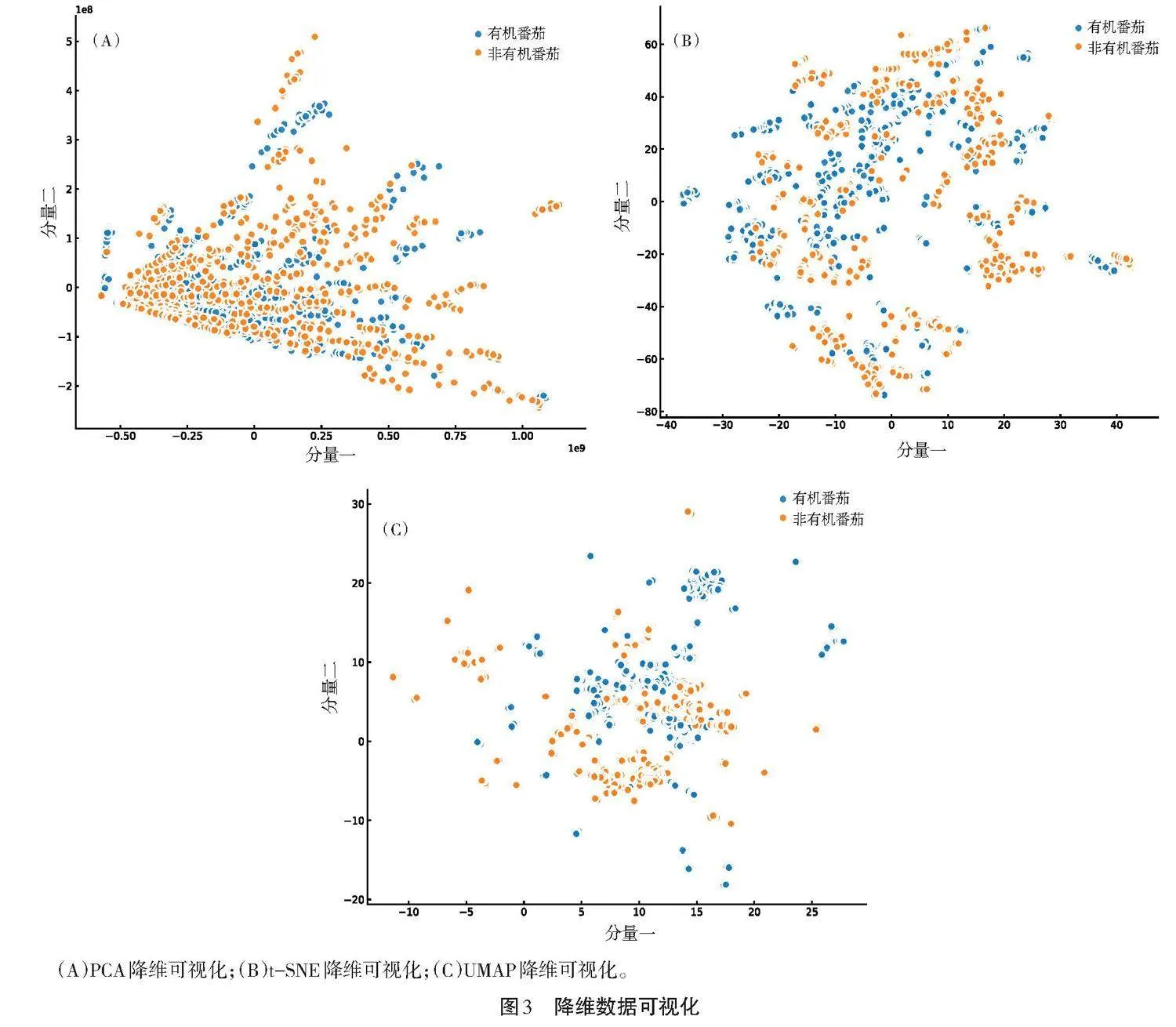
有机及非有机番茄的MS原始数据维度为1 600[×]16 228,使用PCA、t-SNE和UMAP方法降维后获得的特征序列向量维度为1[×]200。将降维后的数据映射到二维空间里进行可视化,由图3可见,使用UMAP降维方法得到的特征,在数据空间中具有更好的分离性。
3.2 消融实验
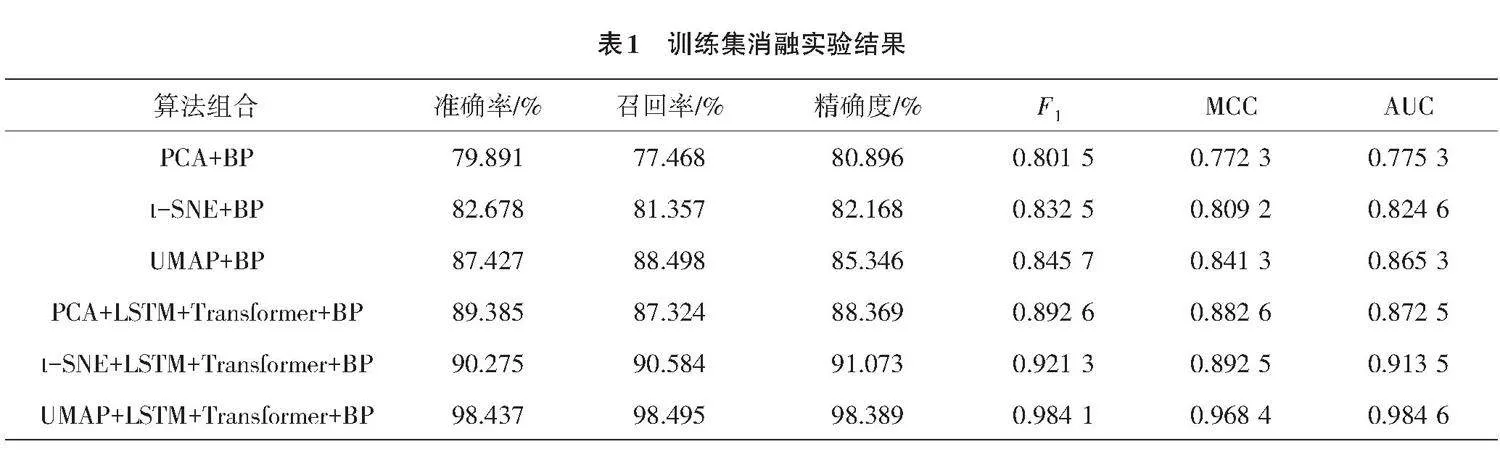
为了对模型的性能进行评估,采用6种不同的策略进行对比,包括PCA+BP、t-SNE+BP、UMAP+BP、PCA+LSTM+Transformer+BP、t-SNE+LSTM+Transformer+BP和UMAP+LSTM+Transformer+BP。设置6种策略的目的在于对比不同降维方法对鉴别模型准确率的影响,以及特征提取模块对鉴别模型准确率的影响。所有结果均是使用五折交叉验证获得,将所有的数据集划分成5份,每次选取不同的组合,以4∶1的比例构建训练数据集和测试数据集,以确保每次训练使用的训练集和测试集不相同。最终的结果是5次训练结果的平均值。具体结果如表(1—2)所示。结果表明,UMAP+LSTM+Transformer+BP组合的性能较优,具体表现为准确率达到98.437%,MCC达到0.968 4,AUC达到0.984 6。
3.3 模型训练参数分析
使用不同的参数对算法涉及的模型进行调整,以获得较好的性能。模型采用一层LSTM模块,由200个单元组成;Transformer模型采用的注意力模块为12层,一共有6头注意力机制;BP模型由一个输入层和两个隐藏层构成,输入层的神经元有200个,两个隐藏层的神经元分别有100和50个。模型训练损失函数参数如表3所示。
3.4 模型性能分析
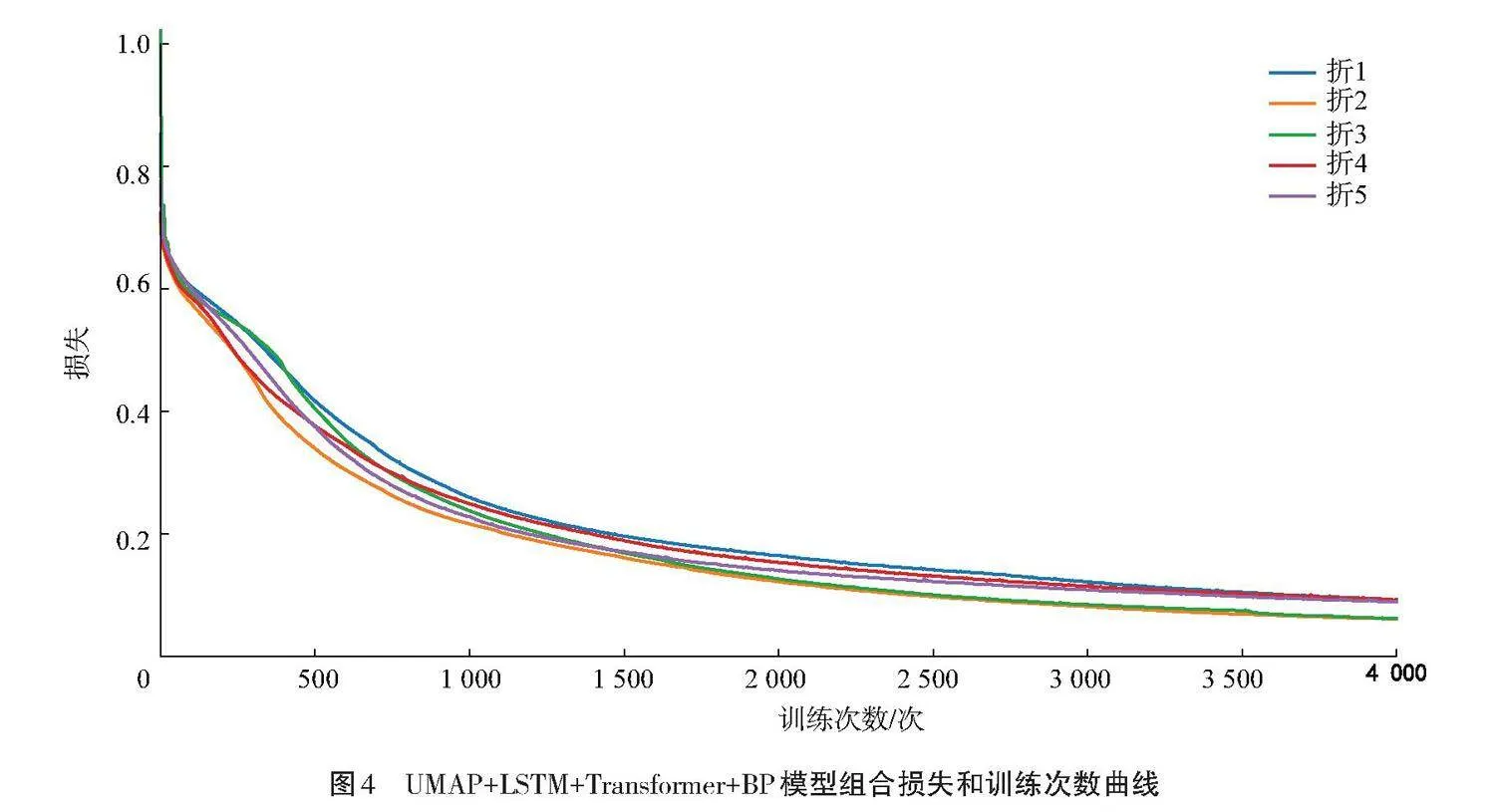
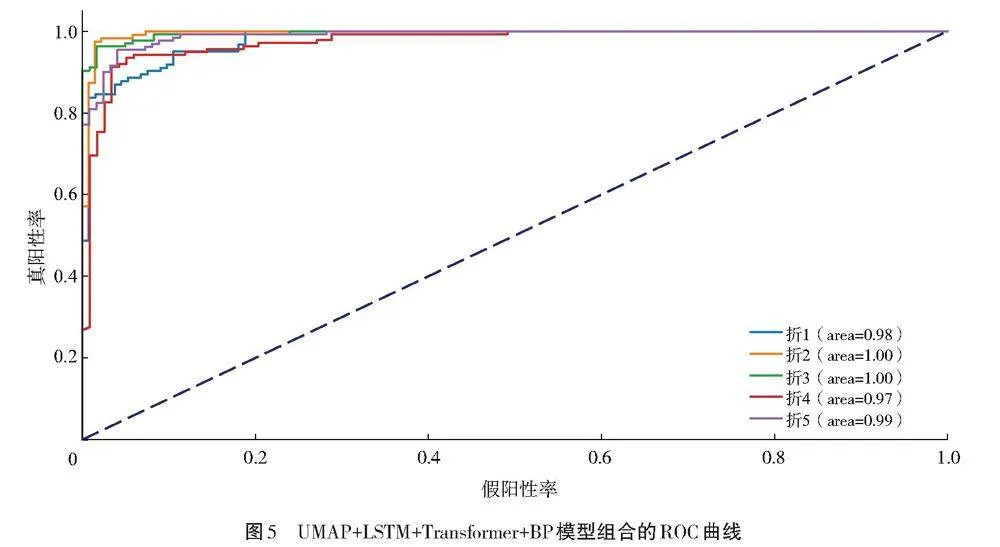
模型训练的迭代次数为4 000次,五折交叉验证在训练集的识别上均达到了收敛,图4展示了收敛过程。图5为五折交叉验证在训练集上的ROC曲线。每一折训练所取得的具体性能如表4所示。
从图4可以看出,随着模型训练的进行,每一折的损失都在降低,在前1 500次迭代过程中损失下降较快,自第3 000次迭代后,每一折的损失趋势逐渐平缓,这表明模型已经接近收敛。
AUC衡量的是整个ROC曲线下的二维区域面积,取值从0到1.0,其提供了一个在所有分类阈值上的综合性能度量。从图5可以看出,折3的曲线最接近左上角,其AUC为0.993 5,这表明模型在折3上的效果较好;折4的曲线略差于其余4条曲线,其AUC为0.973 4。除折4的AUC略低之外,其余折的结果均接近1.0,这说明在大多数条件下,该模型能够很好地区分样本类别。
4 结论
本文基于质谱检测数据对有机及非有机番茄构建了深度学习识别模型,通过融合数据降维方法UMAP,序列特征提取方法LSTM和Transformer,提取了高效数据特征,并使用BP神经网络实现了准确分类。结果表明,深度学习框架可以基于原始质谱检测数据实现快速精准的有机及非有机番茄检测识别,基本满足有机番茄市场的发展需求,具有较大的应用潜力。
参考文献
[1] ALI M Y,SINA A A,KHANDKER S S,et al. Nutritional composition and bioactive compounds in tomatoes and their impact on human health and disease:a review[J]. Foods,2020,10(1):45.
[2] WATANABE M,OHTA Y,SUN L C,et al. Profiling contents of water-soluble metabolites and mineral nutrients to evaluate the effects of pesticides and organic and chemical fertilizers on tomato fruit quality[J]. Food chemistry,2015,169:387-395.
[3] PARK H A,HAYDEN M M,BANNERMAN S,et al. Anti-apoptotic effects of carotenoids in neurodegeneration[J]. Molecules,2020,25(15):3453.
[4] 李晓慧,李建洪,王洪萍,等. 植物源性食品中化学性危害物质的色谱—质谱检测技术研究进展[J]. 分析测试学报,2023,42(10):1357-1369.
[5] 玛尔哈巴·帕尔哈提,朱靖蓉,赵多勇,等. 稳定同位素技术在有机农产品真实性鉴别中的应用进展[J]. 食品安全质量检测学报,2022,13(22):7191-7199.
[6] GREDELL D A,SCHROEDER A R,BELK K E,et al. Comparison of machine learning algorithms for predictive modeling of beef attributes using rapid evaporative ionization mass spectrometry (REIMS) data[J]. Scientific reports,2019,9(1):5721.
[7] LIM D K,LONG N P,MO C,et al. Combination of mass spectrometry-based targeted lipidomics and supervised machine learning algorithms in detecting adulterated admixtures of white rice[J]. Food research international,2017,100(Pt 1):814-821.
[8] 王世成,李国琛,王莹,等. 基于氮稳定同位素比例质谱和液相色谱—高分辨质谱的有机番茄鉴别[J]. 食品科学,2021,42(14):159-164.
[9] DE OLIVEIRA A N,BOLOGNINI S R F,NAVARRO L C,et al. Tomato classification using mass spectrometry-machine learning technique:a food safety-enhancing platform[J]. Food chemistry,2023,398:133870.
[10] JOSEPH D S,PAWAR P M,PRAMANIK R. Intelligent plant disease diagnosis using convolutional neural network:a review[J]. Multimedia tools and applications,2023,82(14):21415-21481.
(责编:王 菁)
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
海峡姐妹(2019年12期)2020-01-14 03:24:40
电子制作(2019年19期)2019-11-23 08:42:00
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
