
基于BERT的用户评论情感分析
2024-12-31 00:00:00漆阳帆
现代信息科技 2024年10期
关键词:情感分析

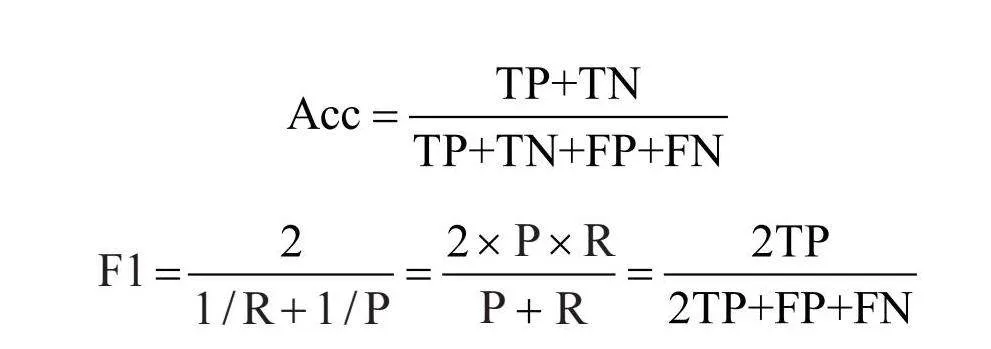
摘" 要:情感分析(SA)是互联网时代非常重要的自然语言处理(NLP)子任务,可以帮助使用者进行评论分析、舆情分析等。然而,现有大多数研究都致力于提升情感分析任务的整体表现,很少有针对不同文本特征的分类研究。分类研究可以帮助研究者找到当前分析方法在特定场景中的短板,也可以指导使用者在面对不同场景时选择更合适的分析方法。文章基于BERT模型,按照文本长度和评价目标个数对SentiHood进行分类,使用不同的分析方法进行分组实验。实验结果表明,各个方法在短文本分析中的表现优于长文本分析中的表现,单目标分析的表现优于多目标分析。在不同的文本特征下,分别有不同的分析方法体现出最优性能。
关键词:情感分析;文本特征;BERT
中图分类号:TP391" " 文献标识码:A" 文章编号:2096-4706(2024)10-0123-05
Sentiment Analysis of User Comments Based on BERT
QI Yangfan
(Jilin University, Changchun" 130012, China)
Abstract: Sentiment Analysis (SA) is a very important sub-task of Natural Language Processing (NLP) in the Internet era, which can help users to analyze comments and public opinion. However, most existing studies focus on improving the overall performance of sentiment analysis tasks, and there are few categorical studies targeting different text features. Classification research can help researchers find the shortcomings of current analysis methods in specific scenarios, and can also guide users to choose more appropriate analysis methods when facing different scenarios. Based on the BERT model, SentiHood is classified according to text length and number of evaluation targets, and different analysis methods are used to conduct group experiments. The experimental results show that each method performs better in short text analysis than in long text analysis, and the performance of single objective analysis is better than that of multi-objective analysis. Under different text features, there are different analysis methods that demonstrate optimal performance.
Keywords: SA; text feature; BERT
0" 引" 言
随着计算机技术和互联网技术的不断发展,网民通过服务评价、买家讨论、自媒体留言等方式产生海量有价值的信息。然而,由于信息数量庞大,通过人工提取的方式不可能完成对所有信息的处理,依托计算机强大的批处理能力进行评论分析变得愈发重要。
情感分析(Sentiment Analysis, SA)是指利用计算机技术对产品、服务、事件、话题等进行分析,挖掘文本中的观点、情感、评价和态度,输出对评价对象情感极性的计算研究[1]。
情感分析从最初依赖于纯理论的研究方法(例如支持向量机、最大熵、朴素贝叶斯、情感词典等),逐步与深度学习相结合,借助Word2Vec词嵌入技术、前馈神经网络(FNN)、卷积神经网络(CNN)、循环神经网络(RNN)、LSTM网络等提高整体性能表现。近年来,随着BERT、GPT、ELMo等预训练模型的问世,情感分析的性能表现走向一个新的高度[2]。
然而,几乎所有的研究(如基于词共现的模型和融合BERT多层特征的模型)都致力于提高模型预测的整体表现,鲜少有针对不同场景的分类研究[3,4]。事实上,针对不同场景进行分类研究有着特殊的意义。例如,对于影评平台而言,其长评数量往往大于短评数量,因此长文情感分析有着更大的应用价值;同时,对于产品测评平台而言,多对象横向对比的场景多于单对象分析,多对象情感分析显得尤为重要。
对数据集进行分类研究有助于发现现有方法的优势与短板,在处理不同特征的数据集时可以根据实际情况选择更合适的方法。同时,分类研究对于未来的研究具有指导意义,各个团队可以根据他们所关心的特征场景或分类分析报告中呈现出的短板情景进行针对性优化。
本文使用SentiHood数据集将所有数据按两种方式分为多组:按照评价目标数量将数据分为单目标组和多目标组;按照文本长度将数据分为数量大致相等的5组[5]。对于不同的数据集,本文将基于BERT(Bidirectional Encoder Representation from Transformers)模型,采用NLI_M、QA_M、NLI_B、QA_B四种不同的辅助句构造方式,分别探究同一方法在不同特征测试集上的预测表现以及不同方法在相同特征测试集上的预测表现[6,7]。
1" 研究方法
1.1" 任务描述
情感分析根据粒度特征的不同可以分为篇章级、句子级和方面级。篇章级和句子级情感分析属于粗粒度情感分析,这两类任务假设一段文本只包含单一情感,对文本进行整体分析,丢失了许多细节信息。方面级情感分析属于细粒度情感分析,对句子中的方面项(Aspect Term)、方面类别(Aspect Category)、观点项(Opinion Term)、情感极性(Sentiment Polarity)等进行分析,可以帮助分析者从句子中提取更多有价值的信息[8,9]。
本文使用的方法用于解决给定目标的方面级情感分析任务(TABSA)[5]。所用数据集中的原始数据包含以下几个要素:目标(Target),T = {LOCATION1,LOCATION2};方面(Aspect),A = {General,Price,Transit-location,Safety};情感极性(Polarity),y ∈ {Positive,Negative,None}。根据辅助句构造方式的不同,本文分别以目标、方面作为评价对象,以情感极性作为输出进行三分类任务;以目标、方面、情感极性作为评价对象,以正误作为输出进行二分类任务。
1.2" 方法描述
本文使用预训练的BERT模型,根据文中的任务进行微调。
1.2.1" 辅助句构造
考虑到BERT模型在句对分类任务上的出色表现及其在问答系统(QA)和自然语言推理(NLI)上的优越性能,本文采用了针对TABSA任务的优秀方法,利用四种辅助句构造方式将单句分类任务转化为句对分类任务,分别采用不同特征的数据集进行实验[6]。
以“location - 1 actually has quite a cool feel to it”为例,四种构造方式如表1所示。
对于指定的目标对象,*_M方法将会生成4个辅助句;*_B方法由于额外包含情感极性信息,所生成的辅助句数量为*_M方法的3倍。
1.2.2" 输入词嵌入
实验通过将原始输入语句与辅助句相结合,将单句分类任务转化为句对分类任务。根据预训练模型中提供的词表,将原始输入语句和生成的辅助句转化为词元(token)列表。将原始输入语句与辅助句的词元列表拼接,在列表首尾分别加上“[CLS]”标签和“[SEP]”标签,并在两句中间插入“[SEP]”标签作为分隔,最后将其进一步转化为id列表,形成input_ids。将原始输入语句中各词元位置及首尾标签位置设为1,将辅助句中各词元位置及句末标签位置设为0,形成segment_ids,用以区分两个不同的句子。考虑到BERT不同于其他模型的双向特性,将上述句子中的各词元位置(包括标签位置)依次从0开始标号,形成position_ids,用以标记各词元在句中的原始位置。基于上述列表分别形成张量并相加,得到输入张量。
1.2.3" 模型微调
将经过词嵌入处理的张量送入由多层Transformer-Encoder堆叠形成的BERT中,选用“[CLS]”标签所在位置经过处理的结果作为分类器层的输入,分类结果经过Softmax函数处理,最终生成各分类的概率并给出预测结果。
1.3" 数据集
本文使用针对TABSA任务设计的SentiHood数据集[5]。为了研究实验所用方法对不同特征文本的预测能力,本文对测试集的评价目标个数及原始文本长度进行分类。根据评价目标个数,测试集被分为单目标组和双目标组。根据辅助句拼接前的原始文本长度(以token个数衡量),测试集被分为数据量大致相等的5组:(0, 10)、[10, 15)、[15, 20)、[20, 25)、[25, +∞)。
1.4" 实验参数
实验使用预训练基于BERT的uncased_L-12_H-768_A-12模型进行微调,模型共包含12层Transformer-blocks,隐藏层大小为768,自注意力头数量为12,总参数量约为110M。本次实验中,对于不同的辅助句构造方式均采用相同的微调参数:warmup为0.1,dropout_prob为0.1,max_seq_length为512,batch_size为24,learning_rate为2e-5,epoch为4。
1.5" 结果预测
根据Sun等人在论文中对模型优化原因的分析,语料丰度的提升会提高预测精度[6]。根据这一结论进行结果预测,多目标的分析精度会高于单目标分析精度,包含更多信息长文本的分析精度会高于短文本分析精度。同理,*_B模型会生成比*_M模型更多的辅助句,因此预测*_B模型的分析精度会高于*_M模型。
2" 实验结果
2.1" 分类结果展示
2.1.1" 目标数量
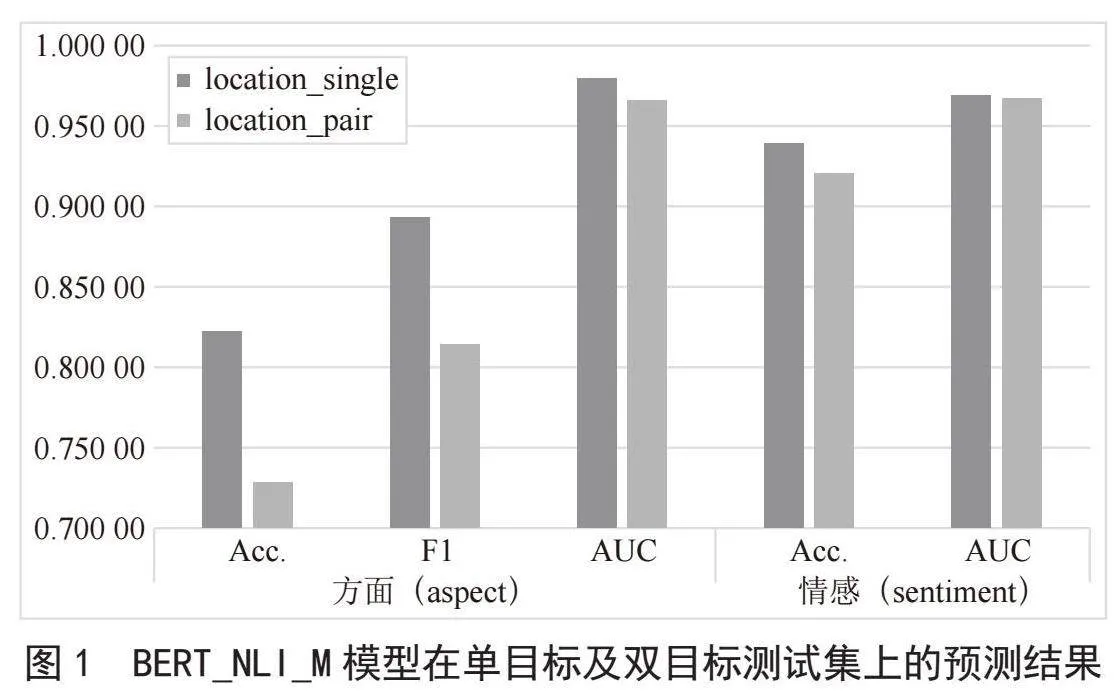
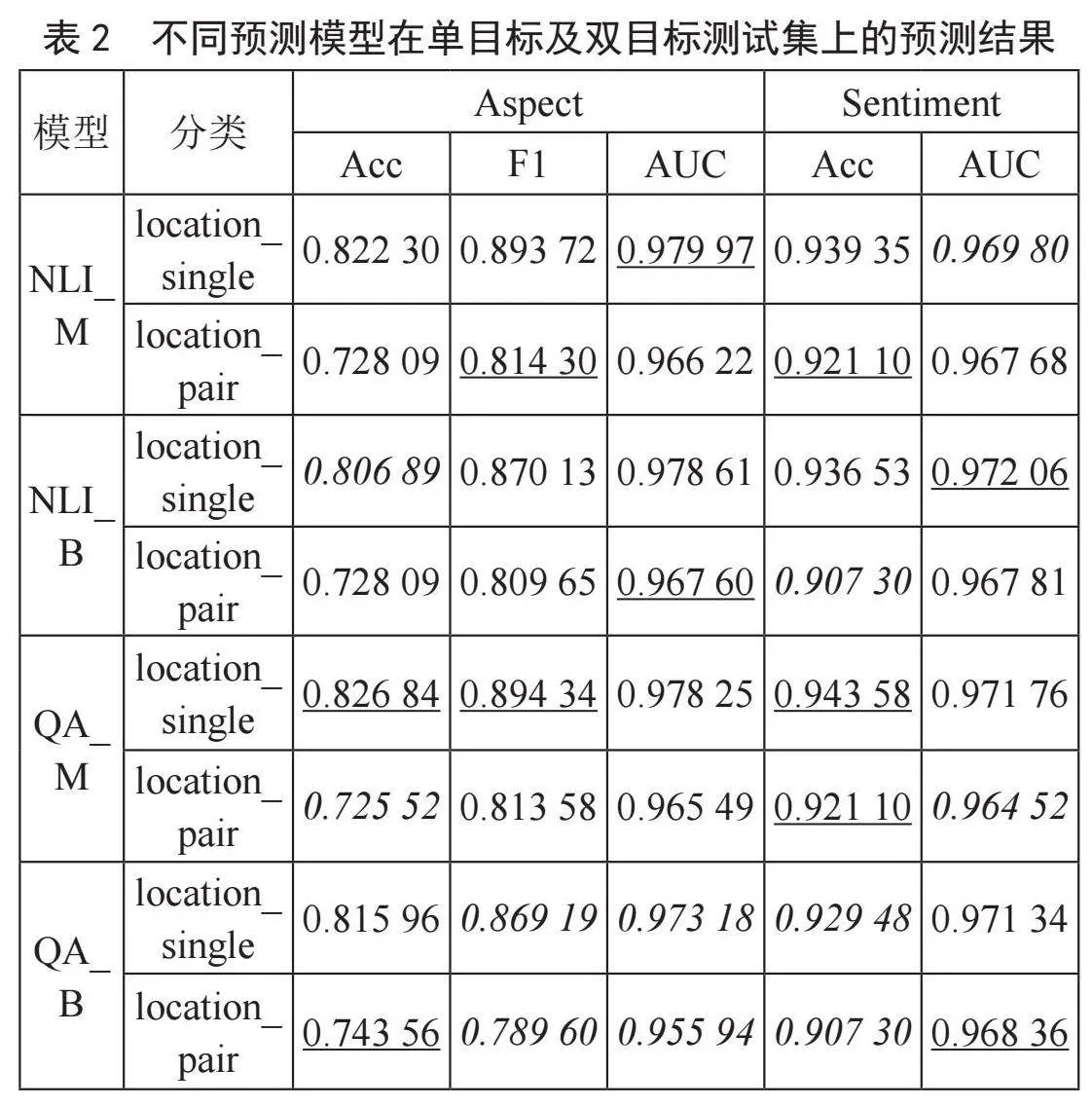
四种辅助句构建模型在单目标及双目标测试集上的预测结果如图1所示。表2中用下划线表示各测试集上的最优预测结果,用字体倾斜表示各测试集上的最差预测结果。
表2中相关评估指标计算式及相关概念如下:
TP(True Positive)表示真阳性,即预测结果为阳性,实际样本也为阳性的样本数量。
FP(False Positive)表示假阳性,即预测结果为阳性,实际样本为阴性的样本数量。
TN(True Negative)表示真阴性,即预测结果为阳性,实际样本也为阴性的样本数量。
FN(False Negative)表示假阴性,即预测结果为阴性,实际样本为阳性的样本数量。
ROC曲线:表示受试者工作特征曲线(Receiver Operating Characteristic Curve, ROC),以假阳性概率(False Positive Rate)为横轴,真阳性概率(True Positive Rate)为纵轴组成的坐标图。
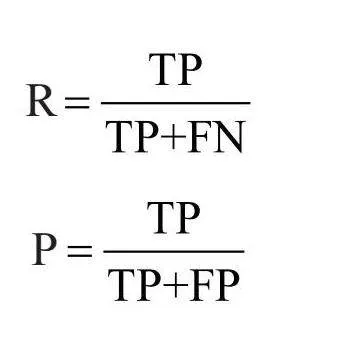
召回率(Recall, R)、精确率(Precision, P)、Acc、F1的公式分别如下,其中,Acc值越大代表分类器性能越好,ROC曲线下的面积即AUC值越大代表分类器性能越好。
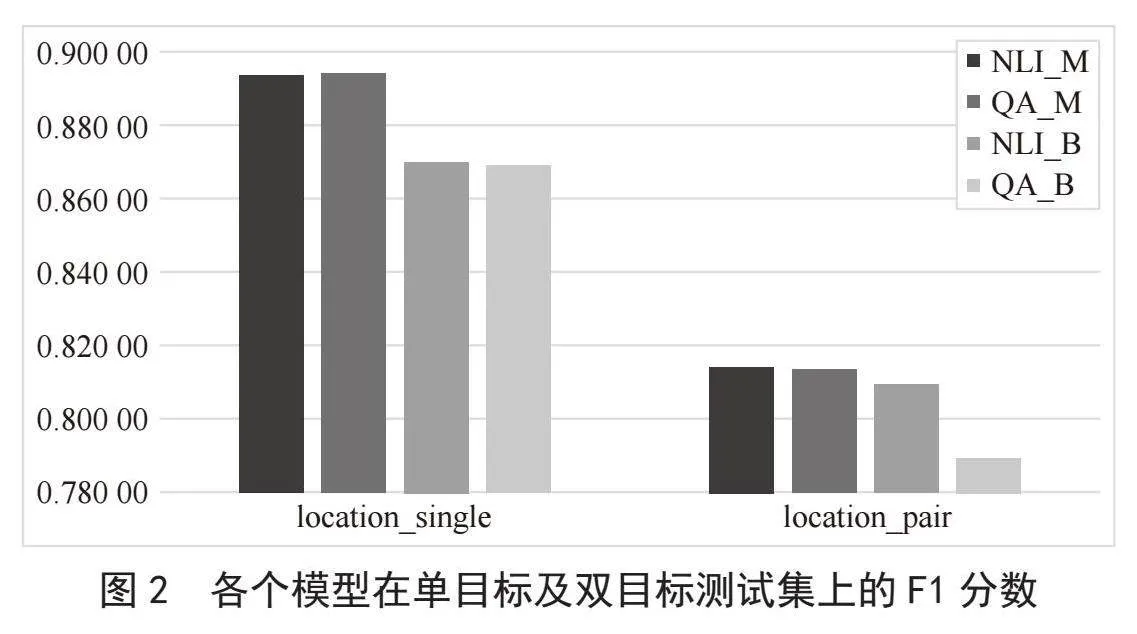
在单个模型内部,以BERT_NLI_M模型为例,单目标及双目标测试集的预测结果如图1所示。结合表2与图1,可以看出所有模型的单目标预测效果在各个方面都优于双目标预测,且单目标的aspect_F1有显著优势。
在各个模型之间,以F1分数为例,单目标及双目标测试集的预测结果如图2所示。结合表2与图2,可以看出*_M辅助句构造方式的预测效果优于*_B。
就单目标分析而言,综合考虑所有评分项,QA_M有更精确的分析能力,其F1分数是各种模型中最优的,aspect_AUC和sentiment_AUC分数虽然不是最优的,但与最优值差距极小,绝对差值分别为0.001 71和
0.000 30,相对值分别为最优值的99.825%、99.969%。
就多目标分析而言,综合考虑所有评分项,NLI_M有微弱优势,其F1分数是各种模型中最优的,aspect_AUC和sentiment_AUC分数同样与最优值差距极小,绝对差值分别为0.001 37和0.000 68,相对值分别为最优值的99.858%、99.930%。
2.1.2" 原始文本长度
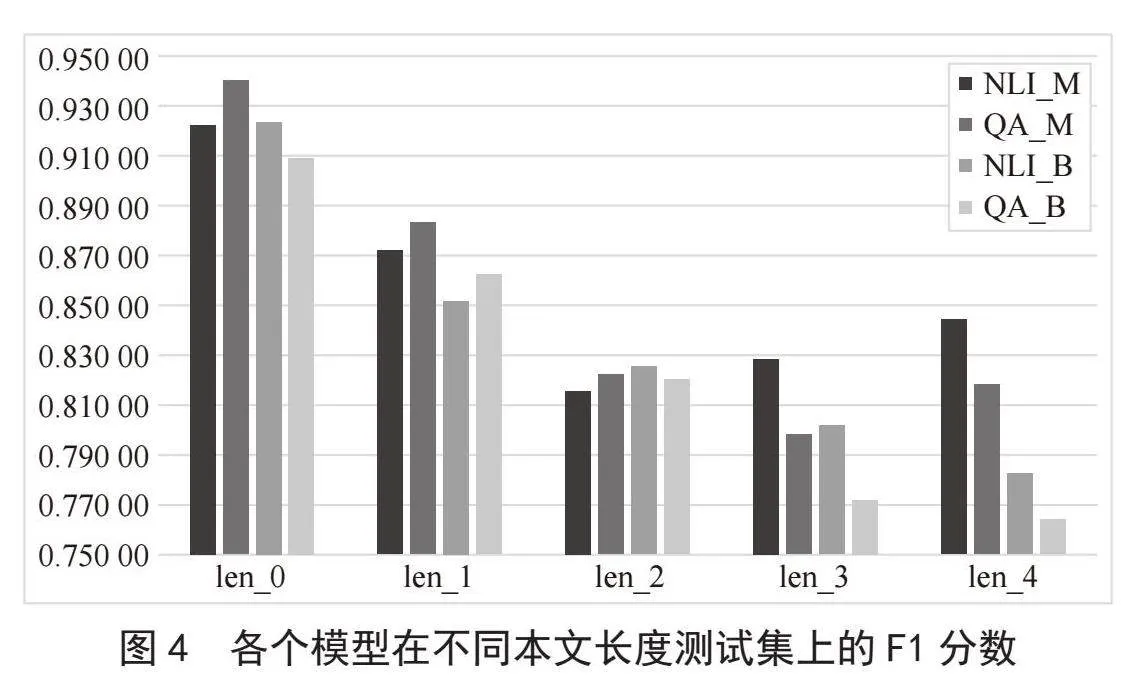
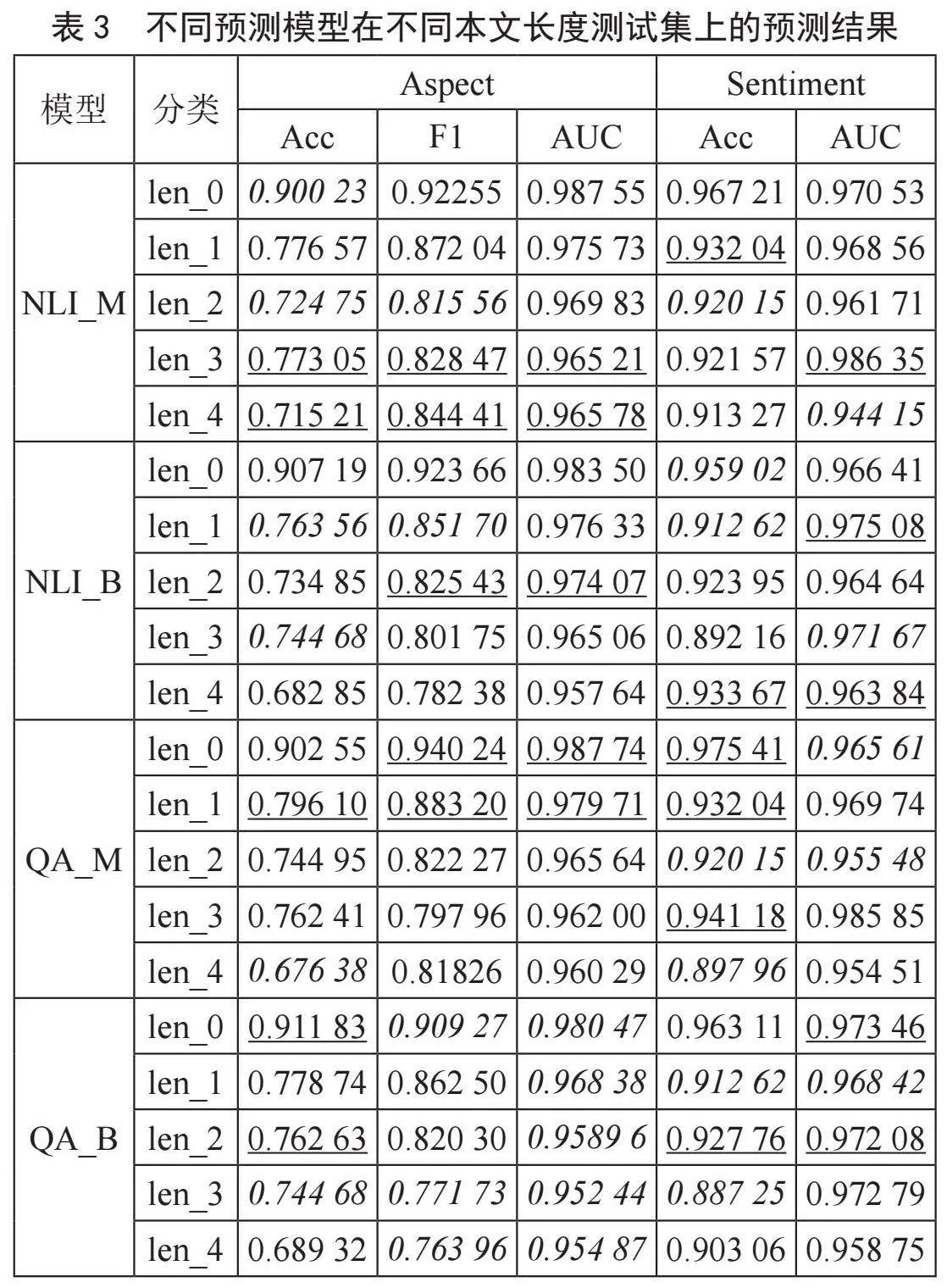
四种辅助句构建模型在不同本文长度测试集上的预测结果如表3所示。
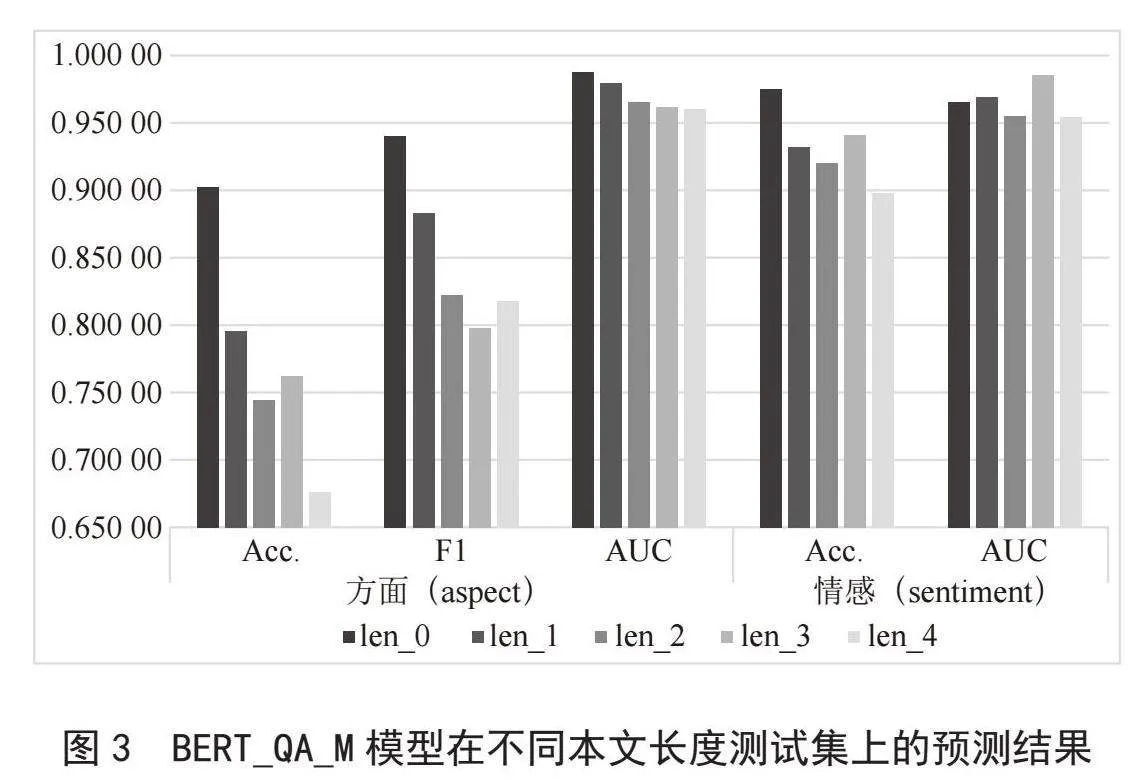
在单个模型内部,以BERT_QA_M模型为例,不同本文长度测试集的预测结果如图3所示。结合表3与图3,可以看出短文本分析精度普遍高于长文本分析精度,且随着文本长度的增加,大部分指标整体上呈下降趋势。
在各个模型之间,以F1分数为例,不同本文长度测试集的预测结果如图4所示。结合表3与图4,可以看出*_M辅助句构造方式的预测效果优于*_B。
就短文本分析而言,根据本实验的分类方法为15词以内,QA_M有更精确的分析能力。其F1分数和aspect_AUC是各模型中最优的。
就长文本分析而言,根据本实验的分类方法为20词以上,NLI_M有更精确的分析能力,其F1分数和aspect_AUC是各模型中最优的。
2.2" 预测结果对比
根据实验数据可以发现,实验结果与预测结果恰好相反,单目标情感分析和短文本情感分析有着更高的分析精度,并且*_M模型在各个评估指标上也普遍优于*_B模型。*_B模型不但精度表现不佳,而且由于生成了更多的辅助句语料,其整体耗时约为*_M模型耗时的三倍。除了部分场景中的sentiment_AUC之外,更多的辅助句语料不但没有带来分析表现的提升,还造成更大的时间和硬件开销。
对于以上现象,推测可能源于以下原因:
1)对多目标文本情感分析而言,虽然句中包含更多的信息,但对象之间的相互关系会更加复杂,更多的信息也意味着更多的相互干扰,导致多目标分析的精度降低。
2)对长文本情感分析而言,虽然长句包含更多的信息,但长句的句子结构更加复杂,存在冗余和噪声问题,导致对长文本中方面相关信息的特征提取不够充分,分类不精准,从而降低长文本分析精度[10]。
3)对*_B模型而言,虽然额外将情感极性编入辅助句,但辅助句构建只是简单的排列组合,过多的辅助句不但没有提高有效信息的密度,反而形成了噪声,导致*_B模型的分析精度偏低。
3" 结" 论
实验中除了探究各个文本场景的最优方法外,还展现出若干现象及问题,对此有下几种思考,同时也是日后深入研究的方向:
1)多目标分析结果较差。以双目标分析为例,双目标之间的关系可能为正向、反向或无关。对于正向或反向的场景,能否提前识别并将双目标聚合,利用各自的有效信息加强对其中一个对象情感极性的预测,进而得到另一个对象的情感极性。对于相互无关的场景,能否提前识别并将无关语料从原始语料中裁剪出来,暂时将双目标分析问题转化为单目标分析问题以提高分析精度。
2)长文本分析结果较差。句子中各词的词性对句意理解有着重要作用,能否对输入语料进行词性标注并将标注结果嵌入到输入向量中,帮助计算机准确找到有效的注意力焦点。考虑到短文本的分析精度更高,能否对原始文本进行裁剪,将长句转化为短句以提高分析精度。
3)辅助句生成方式不够巧妙。过多的低质量辅助句不仅造成时间的浪费,还难以带来性能的提升。能否将情感分析任务与内容生成任务相结合,通过内容生成任务构造辅助句,使辅助句更贴合原始文本,携带更多有效信息,进而达到减少时间开销以及提升分析精度的能力。
参考文献:
[1] ZHANG L,WANG S,LIU B. Deep Learning for Sentiment Analysis: A Survey [J/OL].Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery,2018,8(4)[2023-09-06].https://doi.org/10.1002/widm.1253.
[2] JATNIKA D,BIJAKSANA M A,SURYANI A A. Word2vec Model Analysis for Semantic Similarities in English Words [J].Procedia Computer Science,2019,157:160-167.
[3] 杨春霞,姚思诚,宋金剑.基于词共现的方面级情感分析模型 [J].计算机工程与科学,2022,44(11):2071-2079.
[4] 陈叶楠.基于BERT模型的方面级情感分析研究 [D].西安:西安石油大学,2023.
[5] SAEIDI M,BOUCHARD G,LIAKATA M,et al. Sentihood: Targeted Aspect Based Sentiment Analysis Dataset for Urban Neighbourhoods [J/OL].arXiv:1610.03771v1 [cs.CL].[2023-09-12].https://arxiv.org/abs/1610.03771.
[6] SUN C,HUANG L Y,QIU X P. Utilizing BERT for Aspect-based Sentiment Analysis via Constructing Auxiliary Sentence [J/OL].arXiv:1903.09588v1 [cs.CL].[2023-09-08].https://arxiv.org/abs/1903.09588v1.
[7] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805v2 [cs.CL].[2023-09-08].https://arxiv.org/pdf/1810.04805.
[8] 王海燕,陶皖,余玲艳,等.文本细粒度情感分析综述 [J].河南科技学院学报:自然科学版,2021,49(4):67-76.
[9] ZHANG W X,LI X,DENG Y,et al. A Survey on Aspect-based Sentiment Analysis: Tasks, Methods, and Challenges [J].IEEE Transactions on Knowledge and Data Engineering,2023,35(11):11019-11038.
[10] 王昆,郑毅,方书雅,等.基于文本筛选和改进BERT的长文本方面级情感分析 [J].计算机应用,2020,40(10):2838-2844.
作者简介:漆阳帆(1999—),男,汉族,湖北黄石人,讲师,本科,研究方向:自然语言处理。
猜你喜欢
知识管理论坛(2016年6期)2017-05-27 19:42:13
电子技术与软件工程(2016年15期)2017-04-27 16:11:38
软件工程(2016年12期)2017-04-14 02:05:53
电脑知识与技术(2017年5期)2017-04-08 07:54:12
电脑知识与技术(2017年3期)2017-03-27 14:05:09
智能计算机与应用(2017年1期)2017-03-23 13:24:04
物联网技术(2016年11期)2017-01-12 19:41:22
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
预测(2016年5期)2016-12-26 17:16:57
读写算·教研版(2016年17期)2016-11-08 22:20:36
