
基于知识图谱的柴油发动机故障诊断研究与系统设计
2024-12-31 00:00:00陈柯谭屈山王佳李伟江雨澳袁文丹吴浩
现代信息科技 2024年10期










摘" 要:由于高速公路施工项目工期短、成本高等原因,高速公路施工现场的柴油发动机在发生故障时,需要得到及时的故障诊断和故障处理。通过BiLSTM-CRF模型实现故障实体抽取和关系抽取,利用结构化的语义网络来描述柴油发动机故障知识,以此构建柴油发动机故障领域知识图谱。同时,结合贝叶斯网络实现故障原因推理以对其知识图谱进行补全,还设计了基于知识图谱的柴油发动机故障诊断系统,以全面提升高速公路施工现场工程机械的维修效率。
关键词:柴油发动机;故障领域;实体抽取;语义网络;贝叶斯网络
中图分类号:TP311" 文献标识码:A" 文章编号:2096-4706(2024)10-0112-06
Diesel Engine Fault Diagnosis Research and System Design Based on Knowledge Graph
CHEN Ke1, TAN Qushan2, WANG Jia2, LI Wei2, JIANG Yuao2, YUAN Wendan1, WU Hao1
(1.Chengdu Branch of Sichuan Chengmian Cangba Expressway Construction amp; Development Group Co., Ltd., Chengdu" 618206, China; 2.Sichuan Digital Transportation Technology Co., Ltd., Chengdu" 610218 China)
Abstract: Due to the short construction period and high cost of highway construction projects, diesel engine on the highway construction site needs to receive timely fault diagnosis and troubleshooting when it malfunctions. It uses the BiLSTM-CRF model to extract fault entities and relationships, a structured semantic network is used to describe the knowledge of diesel engine faults, and a knowledge graph in the field of diesel engine faults is constructed. At the same time, Bayesian networks are combined to achieve fault cause inference and complete its knowledge graph. A diesel engine fault diagnosis system based on knowledge graph is also designed to comprehensively improve the maintenance efficiency of construction machinery on highway construction site.
Keywords: diesel engine; fault field; entity extraction; semantic network; Bayesian network
0" 引" 言
高速公路施工现场的柴油发动机在运行过程中会产生大量的部件故障信息,这些数据中蕴含着丰富的价值,但维修人员无法充分利用这些数据进行故障诊断和故障排除[1],因此构建柴油发动机故障领域知识图谱和故障诊断系统是需要深入研究的课题[2],这一研究过程需要以语义信息为基础[3]。
通常,知识图谱构建[4]过程中采用的中文命名实体识别方法[5]大都是基于词的标注度,在中文分词的过程中难免会产生一些错误,所以其精度决定了构图质量[6],对其预训练的静态呈现机制而言,它无法解决文本中的多义性[7]。此外,有关高速公路施工现场柴油发动机故障信息实体识别这一方面的研究比较匮乏,故本文采用基于词的BiLSTM-CRF模型来提升故障识别准确度,并以此构建知识图谱。
陈洪转等人基于故障树、专业知识和实践经验来创建贝叶斯网络,并据此进行故障因果推理[8],文献[9]主要探讨了如何利用多视角聚类框架来改善知识图谱嵌入的效果,文献[10]提出了一种智能的电力信息采集系统故障诊断方法,旨在提高故障诊断的效率和智能化水平。根据这些研究,本文使用所构建知识图谱中的知识建立贝叶斯网络,并完成故障诊断系统的设计。
1" 柴油发动机故障领域知识图谱构建
1.1" 构建流程
柴油发动机故障领域存在大量有关故障的数据,包括故障类型、故障原因、维修方法等信息。通过对这些数据的收集和分析,可以更好地了解柴油发动机的运行状况,及时发现并解决故障问题,提高柴油发动机的可靠性和使用寿命。因此对柴油发动机故障领域维修数据进行有效的管理和应用具有十分重要的意义。知识图谱构建流程如下:
1)数据收集。目前的柴油发动机故障领域还没有公开的数据集,故采用Python方法在网络上爬取故障相关信息(包括非结构化数据和结构化数据)。
2)数据处理。对所收集的数据进行预处理等操作。
3)故障原因推理。采用贝叶斯网络模型进行故障原因推理,并以此进行知识图谱补全。
4)知识图谱构建。按照一定的规则和算法来构建知识图谱。知识图谱中的节点表示实体,边表示实体之间的关系。构建过程中需要考虑实体之间的关联关系、语义表示等问题。
整体的构建过程图如图1所示。
1.2" 数据处理
1.2.1" 数据预处理
去除重复数据、缺失数据、异常数据等,以保证数据的质量和准确性,通过Python的Pandas库对数据进行清洗,包括数据清洗、数据格式转换、数据去重等。数据预处理的目的是保证后续步骤中数据的准确性和可用性。采用自然语言处理、图像识别等技术从为数众多的文本、图像中抽取有用的信息,并将其转换成结构化数据,预处理之后的部分数据如图2所示。
1.2.2" 数据划分及标注
在进行故障实体标注之前,需要先确定标注规则。这些规则可以根据具体任务的需求而定,包括标注的类型、标注的位置、标注的符号等。在完成标注规则确定和收集数据集之后,就可以进行故障实体标注了。标注过程中需要仔细阅读文本并根据标注规则对文本中出现的实体进行标注。标注的结果应该清晰、准确、一致。
本文对1 001条柴油发动机故障事件进行自动化标注,构建了柴油发动机故障数据集,如表1所示。本文采取BIO标注方法将数据集中的文本信息划分成两类实体,一类是由B(文本信息的开头)和I(文本信息的中间或者结尾)组成,另一类是由O(不属于任何特定的类型)组成。
在预处理完成之后,需要将数据集划分为训练集、验证集和测试集。训练集是模型训练的主要数据来源,通常占总数据集的60%左右;验证集是用于评估模型性能的数据集,通常占总数据集的20%左右;测试集是用于最终评估模型性能的数据集,通常占总数据集的20%左右。划分数据集时需要注意数据的随机性和均衡性,以便更好地评估模型的性能。
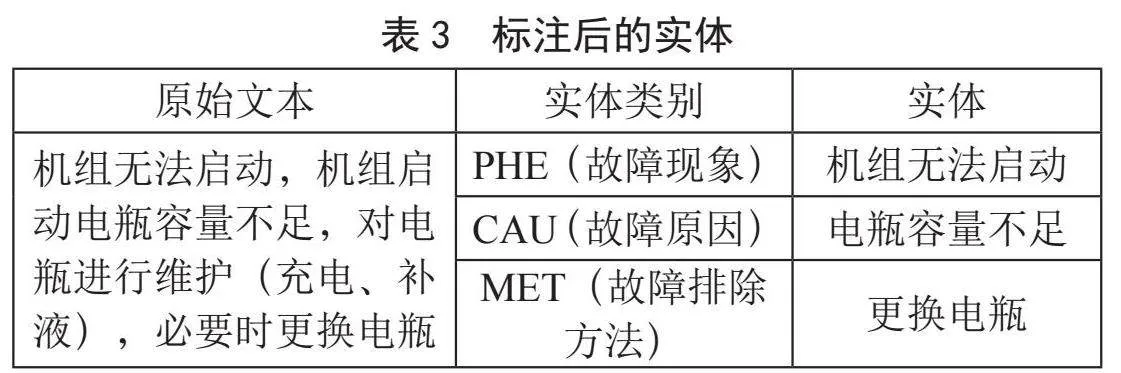
故障实体的标注类型共分为三种:故障现象(Phenomenon, PHE)、故障原因(Cause, CAU)、故障排除方法(Method, MET)。故障现象是指机器或设备出现的问题或异常表现,例如发动机无法启动。故障原因是指导致故障现象的具体原因,可能是由机器或设备的部件损坏、使用不当、环境状况等因素造成的。故障排除方法是指针对具体的故障原因所采取的解决办法。各类故障实体的标注情况如表2所示,标注后的故障实体如表3所示。
1.2.3" 故障实体识别
使用主流的BiLSTM-CRF方法对标注后的故障实体进行识别。BiLSTM-CRF的输入是故障实体的词向量,输出是每个单词预测的序列标注。BiLSTM-CRF模型的输入是一个包含所有单词的序列,输出是每个单词的序列标注。在输入序列中,每个单词都被表示为一个词向量。BiLSTM层用于学习上下文信息,输出每个单词对应于每个标签的得分概率。这些得分作为CRF层的输入,用于学习标签之间的顺序依赖信息,最终得到预测结果,例如PHE-马达故障、CAU-更换、B-启动、O-必要时。BiLSTM-CRF模型的基本结构如图3所示。
1.2.4" 故障关系抽取
依存关系分析是一种自然语言处理任务,用于分析文本中每个单词与其他单词之间的依存关系。通过依存关系分析了解每个单词在句子中扮演的角色,从而更好地理解文本的含义。使用spaCy进行依存关系分析,只需使用如图4所示的伪代码即可。“zh_core_web_sm”(识别中文文本)。
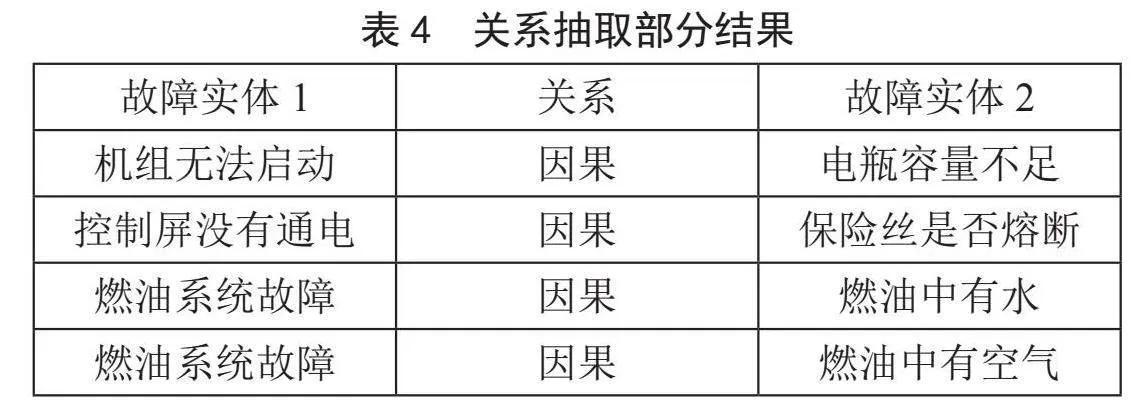
在上述实体识别数据集的基础上,使用spaCy加载文本数据并进行处理,如分词、去除停用词等操作,然后使用spaCy的关系抽取功能对文本中实体之间的关系进行抽取。抽取后的部分结果如表4所示。
1.3" 基于贝叶斯网络的故障原因推理
1.3.1" 故障原因查询
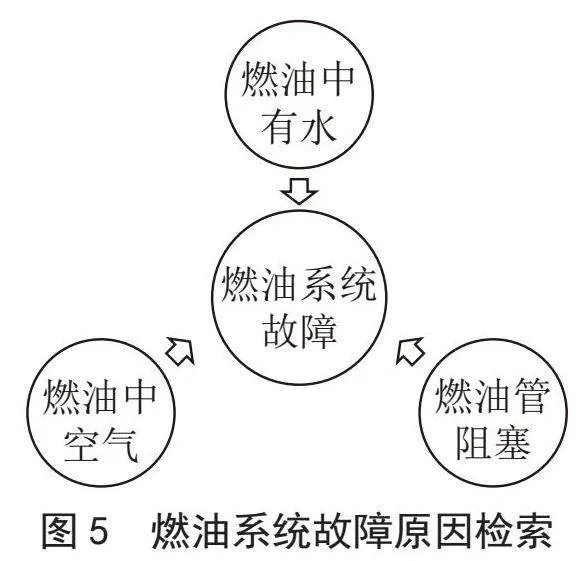
基于存储于Neo4j中的知识图谱数据,使用Cypher语言查询发动机的故障原因,这一方法是具有确定性的,致使每个故障原因出现的概率相同。通过MATCH (engine:Engine) WHERE engine.name = \"Your Engine Name\" ,MATCH (failure:Failure) WHERE failure engine = engine ,RETURN failure.description。在这个查询中,我们首先使用MATCH语句找到名为“Your Engine Name”的发动机。然后使用MATCH语句找到发动机上的所有故障,并使用RETURN语句返回每个故障的描述。注意,在这个查询中,我们使用了一个名为“Failure”的节点来表示故障,并将其与发动机节点进行了匹配。在Cypher语言中,每个节点都有一个唯一的标识符,即“node:type”,其中type是节点类型的名称。因此,我们使用“node:type:Failure”表示一个名为“Failure”的节点。例如对“燃油系统故障”原因的查询结果如图5所示。
1.3.2" 建立贝叶斯网络模型
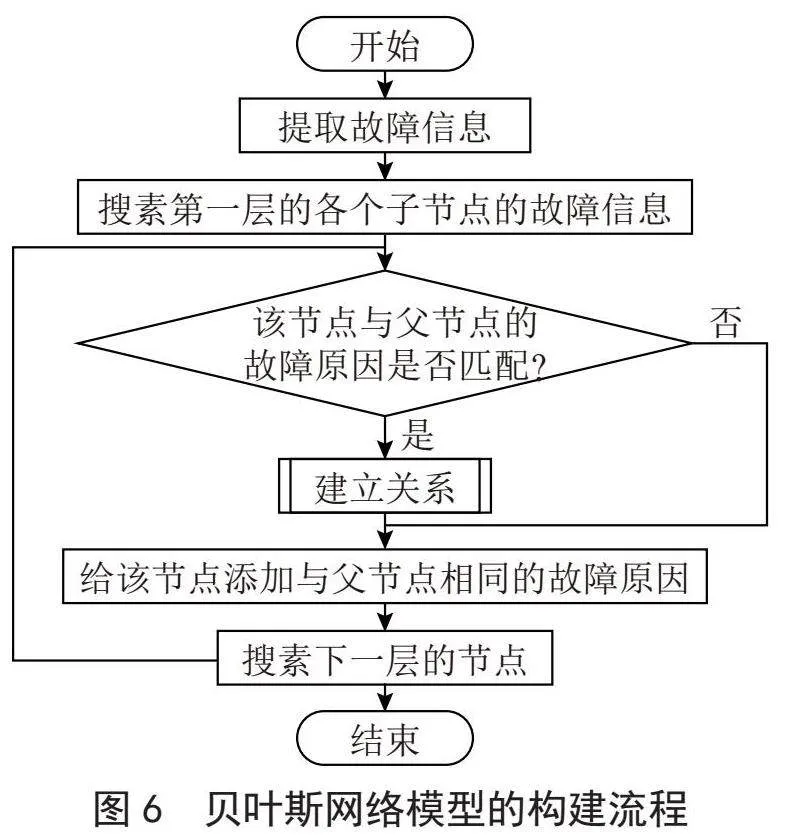
首先建立一个包含多个变量和条件依存关系的贝叶斯网络模型。例如,可以将发动机故障树中的各个节点作为变量,将不同节点之间的连接表示为条件依存关系。整个网络模型的构建流程如图6所示。
1.3.3" 故障原因的推理和诊断
在构建完贝叶斯网络模型之后,可以使用该模型进行故障诊断和预测。具体来说,可以根据输入的故障信息和已有的先验知识,基于贝叶斯定理计算出每个变量的后验概率分布,从而推断出可能的故障原因。同时,还可以针对不同的故障情况选择合适的诊断方法和措施来确定故障并排除故障。
基于贝叶斯网络的发动机故障原因推理可以通过贝叶斯定理进行计算,计算式为:
其中,P( yi | xi)表示第i个变量在给定观测值情况下的条件概率分布,P(xi)表示第i个变量的先验概率分布。
对于柴油发动机故障原因的推理,我们可以假设有多个可能的原因,每个原因都有一个对应的条件概率分布。例如,如果某个故障原因与发动机温度有关,该原因的条件概率分布可以表示为:
其中,P(xij | yij, yji-1)表示第j个变量在给定其观测值和前一个变量观测值的情况下与发动机温度有关的概率分布,P( yji-1 | xji-1)表示第j - 1个变量在给定其观测值的情况下与发动机温度有关的概率分布。通过这种方式,我们可以根据已知的故障数据和相应的条件概率分布推断出可能的故障原因,机组故障原因检索效果如图7所示。
2" 故障实体识别对比实验
2.1" 实验评价指标
本文使用准确率(Precision)、召回率(Recall)和F1值作为模型的评估指标。计算式为:
TP(True Positive)表示真正例,即实际为正例且被正确预测为正例的数量;FP(False Positive)表示假正例,即实际为负例但被错误预测为正例的数量。FN(False Negatives)表示假负例,即实际为正例但被模型预测为负例的案例数量。F1表示准确率和召回率的调和平均数。
2.2" 实验环境
本实验的实体识别是基于PyTorch构建的,具体环境为:深度学习框架采用PyTorch 1.9.5、Python 3.7,CPU是Intel i9,GPU是RTX4060。
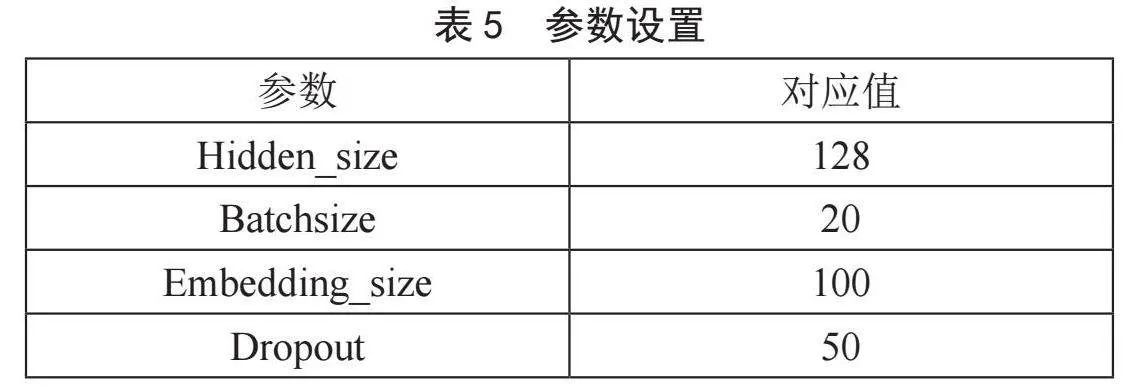
本实验所采用BiLSTM-CRF模型的参数设置如表5所示。
2.3" 实验结果
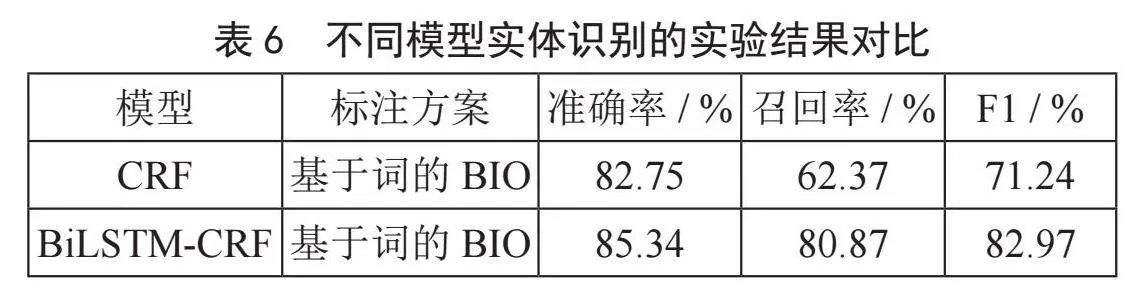
采用层次抽样的方法来构建训练集、验证集和测试集。具体来说就是,根据数据集的大小和样本数量将整个数据集划分为若干个层次,然后从每个层次中随机抽取一定数量的样本作为该层次的样本。最后对每个层次中的样本按照一定的比例进行划分,得到训练集、验证集和测试集。具体的实验结果如表6所示。
从表6中的数据可以看出,CRF模型和BiLSTM-CRF模型在基于词的BIO标注方案下的准确率、召回率和F1值分别为82.75%、62.37%和71.24%,以及85.34%、80.87%和82.97%。
从这些结果中可以得出以下结论:
1)CRF模型在基于词的BIO标注方案下的表现略低于BiLSTM-CRF模型,这可能是因为CRF模型对于序列标注任务的建模能力相对较弱,需要借助更多的特征工程来提高性能。
2)BiLSTM-CRF模型在基于词的BIO标注方案下的表现较好,准确率和召回率均较高,且F1值也比较稳定。这表明BiLSTM-CRF模型对于序列标注任务具有较好的建模能力和泛化能力。
3)需要注意的是,这些结果只是针对基于词的BIO标注方案而言,对于其他标注方案或其他任务类型可能会有不同的表现。因此,在评估模型性能时需要考虑多个指标和多个任务类型。
BiLSTM可以捕捉上下文信息,从而更好地表达单词之间的依赖关系。这使得BiLSTM-CRF能够更加准确地预测单词的标签。BiLSTM可以捕捉长距离依赖,从而更好地解决复杂的序列标注问题。这使得BiLSTM-CRF能够更加准确地预测长距离依赖的标签。BiLSTM-CRF可以得到更准确地标注结果,从而提高文本分析的准确性和效率。BiLSTM-CRF的结果可以通过观察每个单词的得分来解释,从而更好地理解模型的决策过程。
BiLSTM-CRF和CRF的总体对比:基于BIO词向量标注的BiLSTM-CRF模型是一种端到端的深度学习模型,不需要手动设计特征,只需将句子中的单词变为ID输入给模型即可。相比之前的模型,CRF计算整个标记序列的联合概率分布,而不是在给定当前状态条件下定义下一个状态的状态分布。因此,CRF的参数更多,训练量更大,复杂度更高。
3" 故障诊断系统设计
3.1" 系统需求分析
基于知识图谱的柴油发动机故障诊断系统主要是面向高速公路施工现场的维修人员,系统可满足维修人员对故障原因等信息的快速查询和录入。
3.1.1" 具体功能需求分析
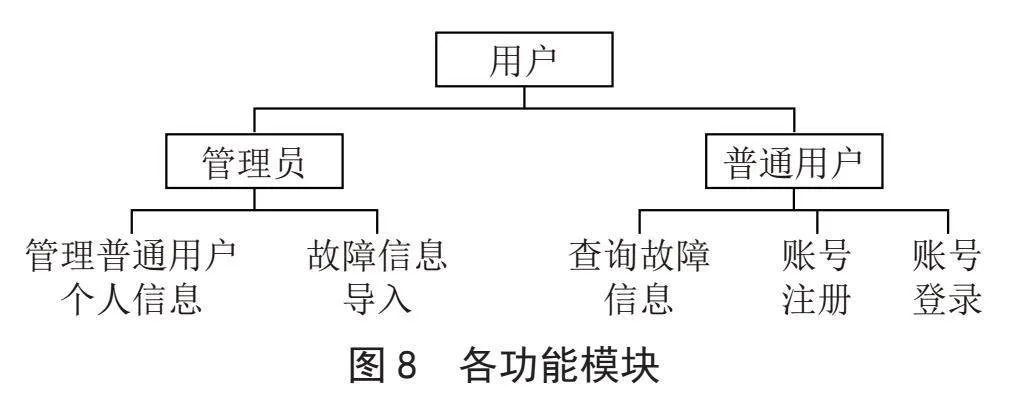
此系统面向两类用户,一类是管理员和普通用户(维修人员就是管理员)。系统的注册功能是提供给普通用户的,管理员的账号是系统自动生成的,管理员拥有系统的最高权限,可录入故障信息,而普通用户是不能录入故障信息的,普通用户只能进行故障信息查询和账号注册。如图8所示为各功能模块的示意图。
3.1.2" 非功能需求分析
该故障诊断系统除了满足具体的功能需求之外,还满足一定的非功能需求,它们两个是缺一不可的,非功能需求包括以下几种:
1)性能需求。例如页面的响应时间、后台静态资源利用率等。
2)可靠性需求。例如数据的容错性、恢复性、稳定性等。
3)可用性需求。例如用户界面操作的易用性、易学习性等。
4)可维护性需求。例如程序的模块化程度、可复用性、可分析性等。
3.2" 系统总体结构设计
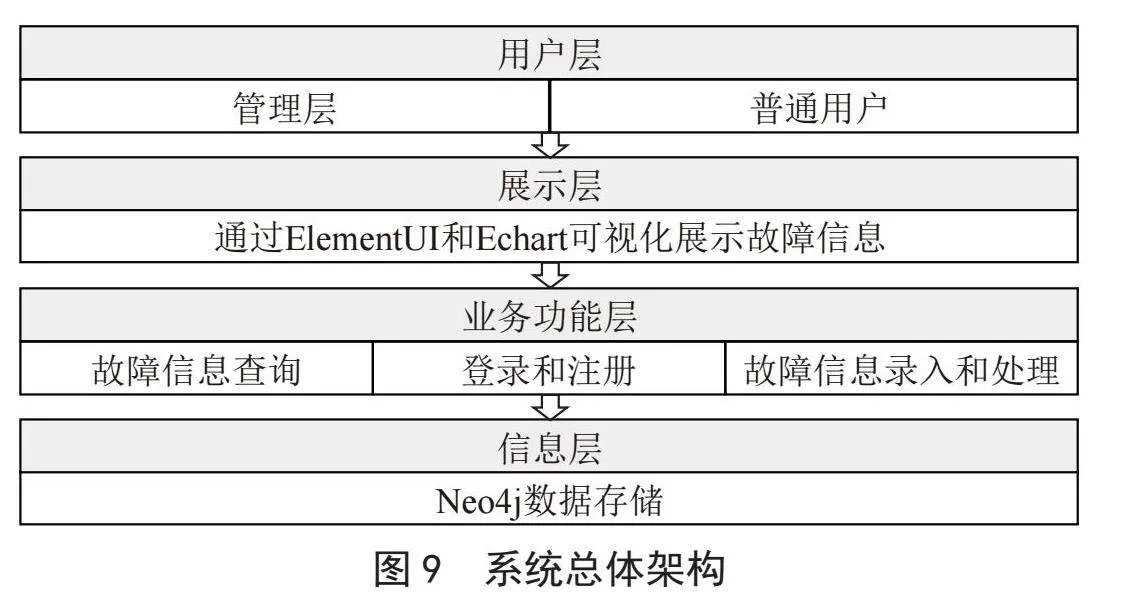
该故障系统的开发采用Web前后端分类模式,后台使用Django框架,前台使用ElementUI和Echart实现故障信息的可视化操作,前台和后台通过HTTP请求实现互通,后台的数据存入Neo4j图数据库。整体结构分为四层,分别为用户层、展示层、业务功能层、信息层,用户层主要包括两类用户(管理员和普通用户),展示层主要包括前端页面的可视化展示,业务功能层主要实现对信息的管理操作,连接展示层和信息层,信息层主要实现对数据的存储管理,保证了数据的安全。系统总体架构如图9所示。
3.3" 系统开发环境设计
该故障系统是一个Web应用网站,后台的主要语言是Python,前台的主要语言是HTML和JavaScript,具体开发环境如表7所示。
3.4" 系统功能模块设计
基于知识图谱的柴油发动机故障诊断系统的核心功能模块如下,如图10所示为核心模块的展示图。
1)登录和注册模块。普通用户只有在注册账号之后才能使用该系统的功能,注册成功之后方可登录系统。
2)故障信息查询模块。用户可通过该模块查询各种故障实体的相关信息,例如故障原因和故障排除方法。用户随意输入一个故障现象文本信息,系统将推断出其故障原因和排除方法返回给前端(如果该故障原因是数据库中没有的则会进行存储),维修人员可针对故障原因,采用相应的故障排除方法解决故障问题。
3)故障信息录入和处理模块。管理员通过界面按钮实现故障事件文本信息的自动导入,后台使用与BiLSTM-CRF模型相结合的命名实体识别方法对故障事件文本信息进行实体识别,提取出故障类型、故障原因、故障现象等实体及关系信息,并将抽取出的故障实体和关系表示为三元组形式,存储到Neo4j数据库中。
4)普通用户个人信息管理模块。管理员通过该模块管理普通用户的个人基本信息,可对用户账号进行增删改查。
4" 结" 论
本文构建了包含3 003个实体和300 234个三元组的柴油发动机故障领域知识图谱,实验结果表明在基于词的标注度方面,BiLSTM-CRF模型明显优于CRF模型。开发基于知识图谱的柴油发动机故障诊断系统,有利于降低高速公路施工现场工程机械故障的维修成本。
参考文献:
[1] 陈昭明,邹劲松.智能制造领域的数字孪生技术研究可视化知识图谱分析 [J].机械科学与技术,2023,42(8):1249-1260.
[2] 钟保强,钟建栩,佘俊,等.基于知识图谱的IT设备故障分析方法研究 [J].电子设计工程,2022,30(14):48-52.
[3] ZHAO H,YAO Q M,LI J D,et al. Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks [C]//Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax:Association for Computing Machinery,2017:635-644.
[4] AL-MOSLMI T,OCAÑA M G,OPDAHL A L,et al. Named Entity Extraction for Knowledge Graphs: A Literature Overview [J].IEEE Access,2020,8:32862-32881.
[5] LI Y,MA Q X,WANG X. Medical Text Entity Recognition Based on CRF and Joint Entity [C]//2021 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC). Dalian:IEEE,2021:155-161.
[6] LIU X,CHEN H Q,XIA W G. Overview of Named Entity Recognition [J].Journal of Contemporary Educational Research,2022,6(5):65-68.
[7] SHEN Y F,LIU J H. Comparison of Text Sentiment Analysis Based on Bert and Word2vec [C]//2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC). Greenville:IEEE,2021:144-147.
[8] 陈洪转,赵爱佳,李腾蛟,等.基于故障树的复杂装备模糊贝叶斯网络推理故障诊断 [J].系统工程与电子技术,2021,43(5):1248-1261.
[9] XIAO H,CHEN Y D,SHI X D. Knowledge Graph Embedding based on Multi-View Clustering Framework [J].IEEE Transactions on Knowledge and Data Engineering,2021,33(2):585-596.
[10] FENG Y,ZHAI F,LI B F,et al. Research on Intelligent Fault Diagnosis of Power Acquisition Based on Knowledge Graph [C]//2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE). Xiamen:IEEE,2019:1737-1740.
作者简介:陈柯(1984—),男,汉族,四川成都人,
高级工程师,本科,研究方向:高速公路管理;谭屈山(1990—),男,汉族,四川大英县人,工程师,硕士研究生,研究方向:大数据、人工智能;王佳(1997—),男,汉族,陕西咸阳人,工程师,本科,研究方向:智慧交通;李伟(1995—),男,汉族,四川巴中人,助理工程师,本科,研究方向:人工智能、计算机网络;江雨澳(1994—),男,汉族,四川成都人,助理工程师,硕士研究生,研究方向:人工智能,智慧交通;通讯作者:袁文丹(1983—),女,汉族,四川大竹县人,工程师,本科,研究方向:高速公路管理;吴浩(1993—),男,汉族,重庆荣昌人,工程师,硕士研究生,研究方向:高速公路建设管理。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:00
装备制造技术(2020年11期)2021-01-26 00:39:16
北京航空航天大学学报(2020年3期)2021-01-14 00:36:56
中国军转民(2017年9期)2017-12-19 12:11:06
现代电子技术(2017年1期)2017-02-16 11:45:32
科技资讯(2016年25期)2016-12-27 16:22:32
南水北调与水利科技(2016年5期)2016-12-27 12:04:04
软件导刊(2016年9期)2016-11-07 17:50:19
计算技术与自动化(2015年3期)2015-12-31 17:14:47
世界汽车(2015年10期)2015-09-10 23:18:21
