
Python爬虫技术在学术聚合系统中的应用
2024-12-31 00:00:00崔梦银邓茵刘满意
现代信息科技 2024年10期
关键词:大数据技术



摘" 要:爬虫技术是搜索引擎和信息网站获取数据的核心技术之一,专用的网络爬虫能够在短时间内从网络上抓取大量有用数据。基于为研究者提供所需学术资源的目的,研究了爬虫技术在爬取学术网站论文数据中的应用。分析了Python爬虫技术在学术聚合系统中的应用,借助大数据技术手段对所爬取的学术数据进行存储、清洗、聚合、消歧和融合。Python爬虫技术在学术聚合系统中起着关键作用,助力研发人员构建强大的数据聚合和分析平台,为学术研究人员提供有价值的信息资源,对学术研究、文献检索和信息发现都具有重要意义。
关键词:Python爬虫;学术资源;大数据技术;学术聚合系统
中图分类号:TP311.5;TP312" 文献标识码:A" 文章编号:2096-4706(2024)10-0068-07
The Application of Python Crawler Technology in Academic Aggregation Systems
CUI Mengyin1, DENG Yin1, LIU Manyi2
(1.Guangdong University of Science and Technology, Dongguan" 523083, China;
2.Shenzhen Huanxuntong Technology Co., Ltd., Shenzhen" 518000, China)
Abstract: Crawler technology is one of the core technologies for search engines and information websites to obtain data. Specialized web crawlers can quickly crawl a large amount of useful data from the network. In order to meet the needs of researchers crawling academic paper data on academic websites to obtain academic resources, the application of Python crawler technology in academic aggregation systems is studied. With the help of big data technology, the crawled academic data is stored, cleaned, aggregated, disambiguated, and fused. Python crawler technology plays a crucial role in academic aggregation systems, helping developers build powerful data aggregation and analysis platforms, providing valuable information resources for academic researchers, and is of great significance for academic research, literature retrieval, and information discovery.
Keywords: Python crawler; academic resource; big data technology; academic aggregation system
0" 引" 言
在信息时代,网络上的数据量不断膨胀,成千上万的学术资源散布在各种学术网站之间,为学术研究人员提供了丰富的知识和信息[1]。对于研究人员而言,获取并利用这些学术资源是其工作不可或缺的一部分。然而,这个庞大的信息海洋也带来了一个挑战:如何高效地获取和利用这些宝贵的学术资源。爬虫技术,作为搜索引擎和信息网站的核心技术之一,能够在极短的时间内从网络上抓取大量有用的数据,为解决这一挑战提供了强大的工具。
早期的搜索引擎如Google、Bing等,以及爬虫工具如Nutch和Scrapy等,为了建立互联网上的索引和提供搜索服务,开发了强大的爬虫技术[2]。这些技术用于从网页上抓取信息并构建搜索引擎的数据库。一些学术搜索引擎如Google Scholar、Microsoft Academic等专注于学术领域,提供了学术文献的搜索和检索功能。它们通过爬虫技术从学术网站和期刊中收集学术论文和研究成果。已经建立了许多学术数据库和索引,例如PubMed、IEEE Xplore、Web of Science等。这些数据库提供了广泛的学术文献和研究成果,但它们的数据通常是有结构的,可以通过API进行访问。开发了许多文献管理工具,如EndNote、Mendeley、Zotero等,用于帮助研究人员组织和管理他们的文献资源[3]。这些工具通常包括文献导入、引用管理和文献搜索功能。在学术数据处理方面,已经有一些工具和技术用于清洗、聚合和消歧学术数据。这些工具有助于提高数据的质量和可用性。学术资源聚合和爬虫技术方面已经取得了重要的进展。然而,新的挑战和机会不断涌现,因此,不断改进和创新这些技术和工具仍然是学术领域的一个重要任务。
Python爬虫技术在学术聚合系统中的应用,介绍Python网络爬虫技术的基本原理和关键技术,研究了学术聚合系统的设计和实现,包括网络爬虫技术、大数据处理工具,以及数据清洗、消歧和融合的关键步骤。这一综合性的研究对于构建强大的学术聚合系统,为学术研究提供有价值的信息资源,具有重要的意义。
1" 相关技术
1.1" Python网络爬虫
Python是一个非常受欢迎的编程语言,因其简单易学、拥有丰富的库和框架,而成为网络爬虫的首选语言之一。Python的Requests库通常用于发起HTTP请求,而Beautiful Soup和lxml等库用于解析和处理网页内容[4]。Python网络爬虫是一种自动化获取网页信息的程序。它通过模拟用户浏览网页的行为,从网站上抓取所需的数据,并将其保存到本地或数据库中。Python网络爬虫广泛应用于搜索引擎、数据挖掘、舆情分析等领域。
1.2" 网络爬虫的原理
网络爬虫的第一步是获取要爬取网页的链接,如何获取这些链接一般有三种方式:
1)通过站点地图(sitemap)获取链接。
2)爬取站点的索引页获取链接。
3)跟随链接。爬虫通常会在解析过程中发现其他链接,这些链接指向其他页面。爬虫会递归地跟随这些链接,以获取更多页面的内容。这种递归过程被称为爬取深度优先搜索(DFS)或广度优先搜索(BFS),取决于策略。停止条件可以是达到预定的爬取深度、访问特定数量的页面、或满足某些特定条件。
面对成千上万的爬虫任务时,通过会把落地页链接存放在Redis中,这样做的好处主要是爬虫程序一旦中断或爬取失败时无须再次从头爬取,从中断处爬取即可。网络爬虫的工作流程如下:
1)发起HTTP请求。爬虫程序首先从Redis缓存中获取一个或多个URL,然后向这些URL发起HTTP请求。这些请求可以是HTTP GET请求,用于获取页面内容,或者是HTTP POST请求,用于提交表单数据等。
2)获取响应。爬虫接收到目标网站的HTTP响应,这个响应包含了页面的内容和其他相关信息。响应通常包括HTTP状态码、响应头和响应体(HTML内容)。
3)提取数据。爬虫使用解析后的HTML页面来定位和提取感兴趣的数据。这可以包括文本、链接、图像、表格等各种类型的信息。数据提取通常依赖于HTML文档的结构和标签。
4)存储数据。爬虫将提取的数据存储在本地文件或数据库中,以备后续使用。数据存储的方式取决于爬虫的设计和需求。
5)处理异常和错误。在执行过程中,爬虫可能会遇到各种异常和错误,例如网络连接问题、网站反爬虫措施、页面不存在等。爬虫需要具备处理这些情况的能力,可以重新尝试、记录错误或采取其他措施。
需要注意的是,合法的网络爬虫必须遵守网站的使用政策和robots.txt文件中定义的规则。robots.txt文件告诉爬虫哪些页面可以访问,哪些不可以,以及爬取速度限制等。
1.3" 网络反爬技术
在相关网络爬虫技术发展的同时,反爬虫技术也在不断发展[5],目前反爬虫技术主要使用以下基本策略:
1)User-Agent控制请求。网站服务器可以检查HTTP请求的User-Agent标头,以识别爬虫请求。爬虫可以伪装自己的User-Agent标头,使其看起来像普通浏览器的请求。这可以通过在HTTP请求中设置合适的User-Agent标头来实现。
2)IP限制。网站可以根据IP地址封锁或限制请求。使用代理服务器可以轮流更改爬虫的IP地址,以避免被封锁。代理服务器可以提供多个IP地址,爬虫可以在不同的请求中使用不同的IP地址。
3)Session访问控制。Session是用户请求服务器的凭证,在服务器端根据短时间内的访问量来判断是否为网络爬虫,将疑似网络爬虫的Session禁用。通过网络爬虫技术可以注册多个账号,使用多个Session轮流对服务器进行访问,避免Session被禁用。
4)验证码。一些网站要求用户在访问之前输入验证码,以验证其身份。爬虫可以使用OCR(光学字符识别)技术来自动解析验证码,尽管这可能需要更复杂的实现。另外,可以考虑手动输入验证码或使用可视化自动化工具(如Selenium)来模拟用户输入验证码。
5)动态加载。一些网站使用JavaScript动态生成页面内容,这对传统爬虫来说是一个挑战。使用支持JavaScript渲染的爬虫工具(如Selenium、Puppeteer)来加载和解析页面[6]。这些工具可以模拟浏览器行为,获取动态生成的内容。
6)人工智能检测。高级反爬虫系统可能使用机器学习和人工智能技术来检测爬虫行为。这是一个更复杂的问题,通常需要不断调整爬虫的行为以规避检测。爬虫开发者可能需要随机化请求间隔、模仿人类浏览行为,并采取其他措施来减少检测风险。
1.4" 大数据处理技术应用
大数据处理技术为网络爬虫提供了强大的工具和平台,用于高效处理、分析和存储大规模数据,以支持各种数据驱动的任务和应用[7]。开发一个用于生产环境的网络爬虫时,一个不容忽视的问题是如何处理和存储原始网页数据。在一些简单的使用情况下往往会忽略这个问题。例如,当用户只需要获取某个网站的数据并达到某个数量时,如果在处理某个特殊页面时发生错误,直接跳过也是可以接受的。然而,一旦用户对数据质量提出更高要求,就需要考虑更为严格和完备的技术方案。在这些情况下,存储和管理原始数据成为不可或缺的一部分。
保存原始数据是提高数据质量的前提,其一,保存原始数据可以在网站改版的时候,保证数据不丢失,只要修改抽取规则,对原始网页重新处理即可;其二,原始数据是网页信息抽取模块的输入,原始数据可以让研发迭代信息抽取算法,优化用户使用体验。
HBase是一个适用于大规模数据的高性能、高可用性、高扩展性的分布式NoSQL数据库[8]。它适用于多种用例,包括时间序列数据存储、实时分析、监控、日志处理和大规模数据存储等。在构建大数据应用程序时,HBase常常是一个有力的数据存储和检索解决方案。学术聚合系统涉及数百个学术站点的爬取,爬取的网页达到10余亿个,因此选用Hbase作为网页库用于保存原始网页数据,其中使用URL的md5值作为Rowkey,网页内容作为值存放在列族中的列中。
PySpark是Spark的Python API,它提供了在Python中使用Spark分布式计算引擎进行大规模数据处理和分析的功能[9]。通过PySpark,可以利用Spark的分布式计算能力处理和分析海量数据集。PySpark支持各种数据源的读取,如文本文件、CSV、JSON、Parquet等。它还支持Spark SQL、流式计算、机器学习等库。本研究使用PySpark作为学术网页信息抽取、学术核心库数据构建以及数据消歧。
2" 学术聚合系统架构设计
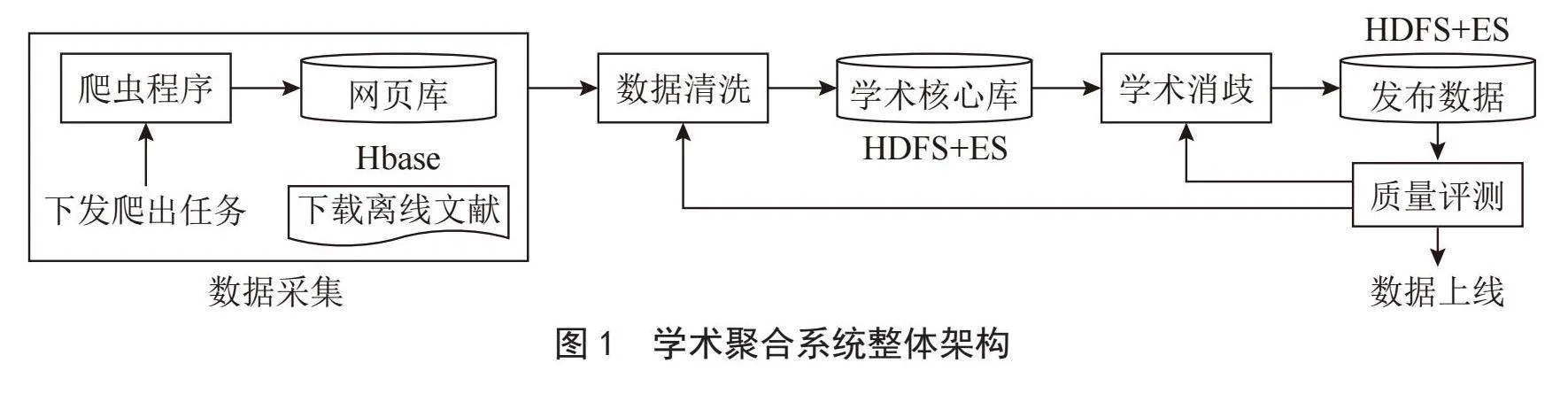
学术聚合系统是一个较为复杂的信息处理系统,旨在从各种学术资源源源不断地获取、处理和提供学术信息。整体架构如图1所示,主要包括数据采集、数据清洗、数据消歧和数据质量评测模块。
2.1" 数据采集
数据源来自两部分,一是网络爬虫程序,用于收集各个学术站点的网页信息,将这些网页信息存储在HBase中。另一部分是离线文件,其中部分学术站点提供了元数据的离线下载地址,下载后经过清洗可以用于丰富学术核心库。
2.2" 数据清洗
使用PySpark对采集到的网页数据和离线文件进行清洗,将它们转换为具有标准结构的数据(schema格式)。随后,这些清洗后的数据会被存储到学术核心库中,其中会有两份副本,一份存储在HDFS上用于后续的数据消歧,另一份存储在Elasticsearch(ES)中主要用于问题定位和案例修复。
2.3" 数据消歧
此阶段主要任务是将来自多个不同来源的数据融合在一起,以提高数据的完整性和质量。这有助于确保数据的一致性和准确性。
2.4" 数据质量评测
数据质量评测是一个关键的环节,通过对学术数据的质量差异进行评估,可以帮助识别数据质量问题,验证研究结果的可重复性,以及监测学术数据的变化。只有通过质量评测的数据才能被认为合格,并被允许上线使用。
这个流程的主要目标是确保从不同来源获取的数据经过清洗和消歧之后,具备高质量、一致性和可用性,以满足学术研究的需求。
3" 学术聚合系统实现
3.1" 编程环境
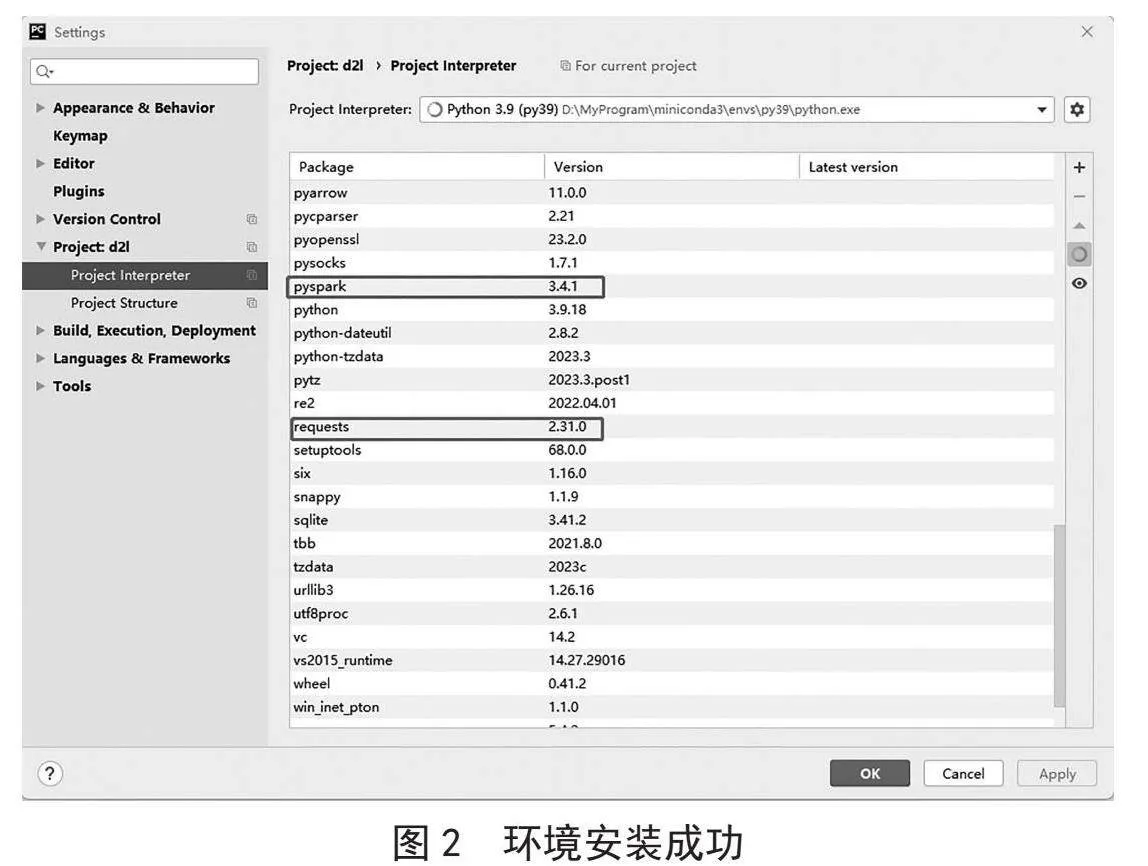
在Windows 11操作系统下设置开发环境,使用Miniconda作为包管理器,并安装了Python 3.9.16环境。选择PyCharm Community版本作为集成开发环境(IDE)。在PyCharm中,创建项目,并成功安装了重要的Python依赖包,包括Requests、lxml和PySpark,如图2所示。这些依赖包的安装是为支持项目和开发工作。最终,建立了一个功能齐全的开发环境,可以开始进行Python编程和相关项目的开发。
3.2" 学术站点数据爬取
3.2.1" 获取网站信息
要爬取整个学术网站,首先需要获取网站的所有落地页链接。以“semantic”为例,获取全站链接的步骤为:
首先,在浏览器的地址栏中输入学术网站的根域名,然后在后面加上“/robots.txt”,以查看网站的robots.txt文件。这个文件包含了网站允许爬虫访问的链接信息,如图3所示。在robots.txt文件中,你可以找到网站提供的不同类型链接,如作者、论文和主题相关的链接。这可以帮助你了解网站的结构和可以访问的内容。
其次,你可以打开论文相关的链接,如图4所示。通常每个链接中都包含大量论文的落地页链接。这些链接大概包含3万篇论文的链接地址,如图5所示。
最后,一旦获得了这些链接,就可以开始编写爬虫程序,以获取网页内容或接口数据,进一步处理和分析这些数据。
这些链接的获取是爬取学术网站数据的关键步骤,它们提供了访问网站内容的入口点。有了这些链接,就可以有选择地获取特定类型的数据,如论文信息、作者信息等。
3.2.2" 网站爬取的代码实现
使用Python语言爬取学术网站(Semantic Scholar)的网站地图(Sitemap)上的链接,并将这些链接保存到名为“semantic_url.txt”的文本文件中。导入Requests库,用于发送HTTP请求和获取网页内容。导入re库,用于正则表达式匹配。定义要访问的学术网站地图的URL,这个URL包含了一系列论文的链接。使用Requests库发送GET请求来获取指定URL的网页内容,并将响应存储在resp变量中。使用正则表达式(lt;locgt;(.*?)lt;/locgt;)从响应文本中提取包含在lt;locgt;标签内的链接。这将创建一个包含所有链接的列表links。打开一个名为“semantic_url.txt”的文本文件以供写入,如果文件不存在则创建它。mode=‘a'表示以追加模式打开文件,这意味着如果文件已经存在,新的链接将追加到文件末尾。迭代处理从网页中提取的链接列表。将每个链接写入到文本文件中,每个链接之间用换行符分隔,以便每个链接占据一行。网站爬取的代码实现如下所示:
import requests
import re
url =“https://www.semanticscholar.org/sitemap-paper-0000000.xml”
resp = requests.get(url)
links = re.findall(‘lt;locgt;(.*?)lt;/locgt;', resp.text)
with open(‘./data/semantic_url.txt', mode=‘a', encoding=‘utf-8') as f:
for link in links:
f.write(link + “\n”)
3.2.3" 学术系统爬虫架构
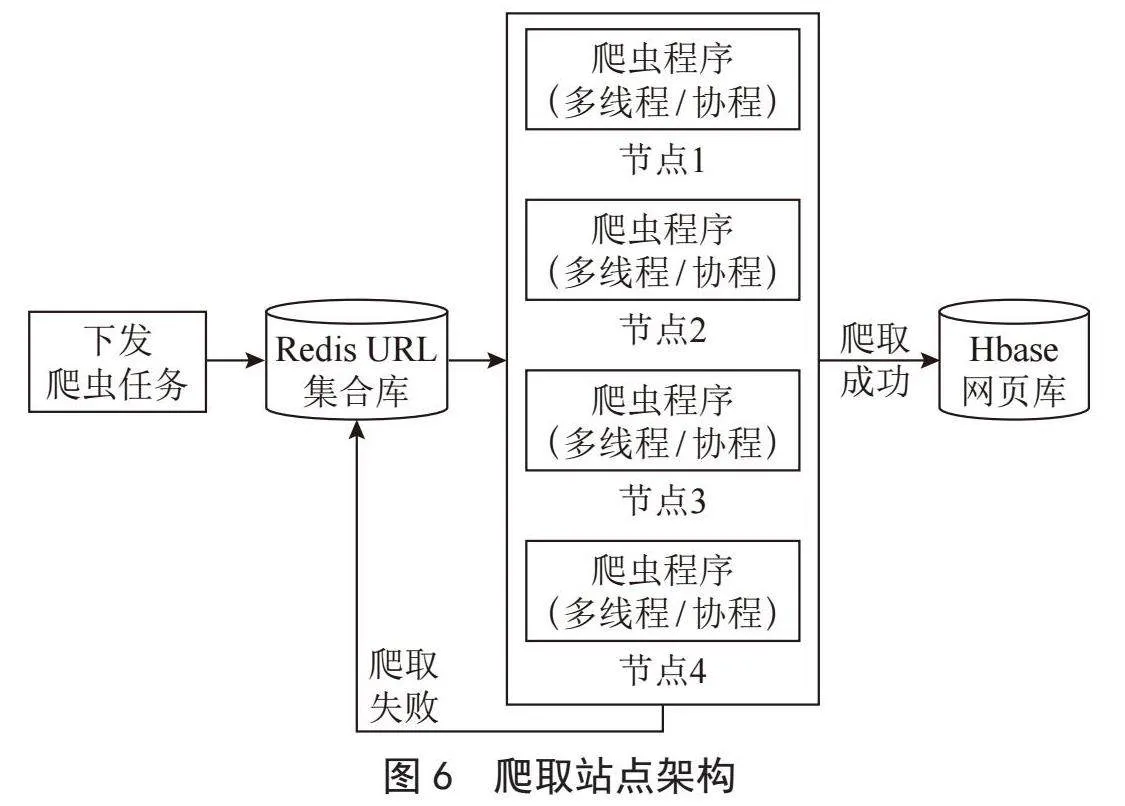
如图6所示,学术系统爬虫架构中,一旦获取到学术落地页链接,这些链接将被存储在一个名为Redis集合的数据结构中。这里的Redis是一个高性能内存数据库,用于存储这些链接。爬虫程序自动从Redis集合中领取爬取任务,这些任务包括要爬取的网页链接。爬取程序会尝试访问这些链接,如果爬取成功,它会将网页信息存储在Hbase网页库中,以供后续的处理和分析。如果爬取失败,爬虫程序会自动将失败的URL重新放回到Redis中,等待下次重新尝试爬取。这个架构允许爬虫系统高效地管理爬取任务,确保尽可能多的页面被成功抓取,并具有自动重试机制以处理爬取失败的情况。这有助于保持数据的完整性和质量。
3.3" 数据清洗
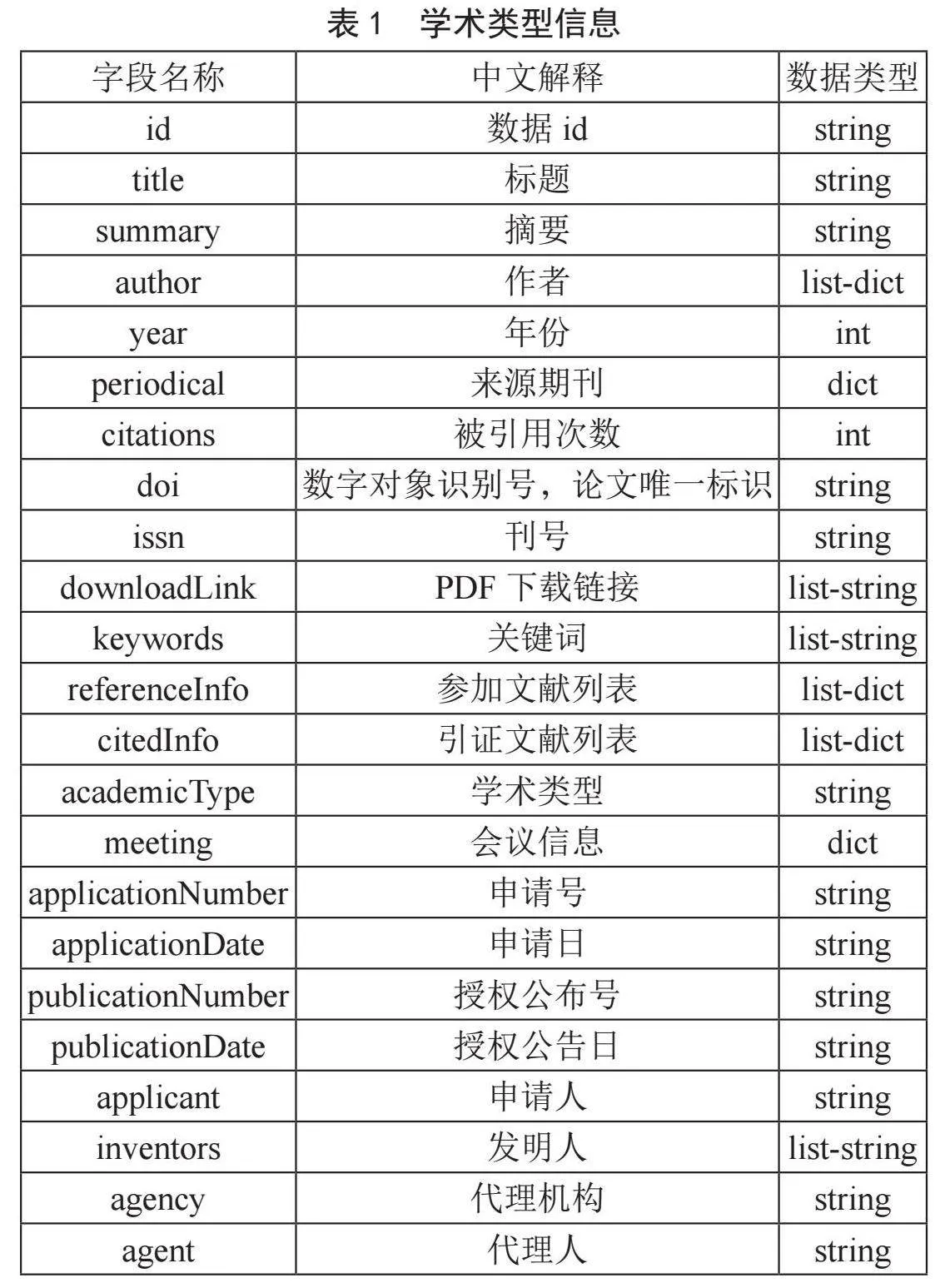
在对学术网页或离线数据进行清洗之前,首先需要定义学术数据的结构,这就是所谓的schema,即数据的结构和组织方式[10]。这个schema应该明确定义了不同类型的学术数据,包括期刊、会议、学位论文、专利和报告等,如表1所示。这个schema描述了数据包括的字段,以及字段的数据类型和结构。
在数据清洗过程中,将原始学术数据按照预定义的schema(数据结构)进行整理。每一篇学术文章都会被处理成一条JSON格式的数据记录。需要特别注意的是,一些字段可能包含复杂的结构,但将按照数据样例的实际情况来清洗这些数据。清洗的结果应该符合定义的数据结构,以确保数据的一致性和可用性。可以让数据更容易存储、分析和应用。
使用Pyspark进行数据清洗,关键代码下所示:
class BaseProcess:
@staticmethod
def process(html_data):
url = html_data[\"url\"]
content = html_data[\"html\"]
data = {}
data[\"url\"] = url
BaseProcess.gen_id(data)
obj = etree.HTML(content)
BaseProcess.extract_title(obj, xpath_dict.get(\"title\"), data)
BaseProcess.extract_summary(obj, xpath_dict.get(\"summary\"), data)
BaseProcess.extract_author(obj, xpath_dict.get(\"author\"), data)
BaseProcess.extract_citations(obj, xpath_dict.get(\"citations\"), data)
BaseProcess.extract_periodical(obj, periodical_dict, data)
BaseProcess.extract_doi(obj, xpath_dict.get(\"doi\"), data)
BaseProcess.extract_downloadLink(obj, xpath_dict.get(\"downloadLink\"), data)
BaseProcess.extract_issn(obj, xpath_dict.get(\"issn\"), data)
BaseProcess.extract_year(obj, xpath_dict.get(\"year\"), data)
BaseProcess.extract_keywords(obj, xpath_dict.get(\"keywords\"), data)
return data
if __name__ == '__main__':
current_date = time.strftime(\"%Y%m%d\")
print(current_date)
sc = SparkContext(appName=\"academic\")
input_hdfs = \"/data/html_data_20231003\"
save_hdfs = f\"/data/academic_data_{current_date}\"
sc.textFile(input_hdfs).map(json.loads).map(BaseProcess.process).map(json.dumps).saveAsTextFile(save_hdfs)
经过清洗的数据示例如下所示:
{
\"url\": \"https://link.springer.com/article/10.1007/s40544-022-0726-2\",
\"id\": \"f6a3a5d2e8bfb2d1ce47d3851c0cba75\",
\"title\": \"Achieving near-infrared-light-mediated switchable friction regulation on MXene-based double network hydrogels\",
\"summary\": \"MXene possesses great potential in enriching the functionalities of hydrogels due to its unique metallic conductivity…...\",
\"author\": [
{
\"name\": \"Pengxi Wu\"
},
{
\"name\": \"Cheng Zeng\"
},
{
\"name\": \"Jinglun Guo\"
},
{
\"name\": \"Guoqiang Liu\"
},
{
\"name\": \"Feng Zhou\"
},
{
\"name\": \"Weimin Liu\"
}
],
\"citations\": 2,
\"periodical\": {
\"name\": \"Friction\",
\"volume\": \"12\",
\"issue\": \"1\",
\"pages\": \"39-51\",
\"year\": 2023
},
\"doi\": \"10.1007/s40544-022-0726-2\",
\"downloadLink\": [
\"https://link.springer.com/content/pdf/10.1007/s40544-022-0726-2.pdf\"
],
\"issn\": \"2223-7704\",
\"year\": 2023,
\"keywords\": [
\"Mechanical Engineering\",
\"Nanotechnology\",
\"Tribology, Corrosion and Coatings\",
\"Physical Chemistry\",
\"Surfaces and Interfaces, Thin Films\"
]
}
3.4 数据消歧和融合
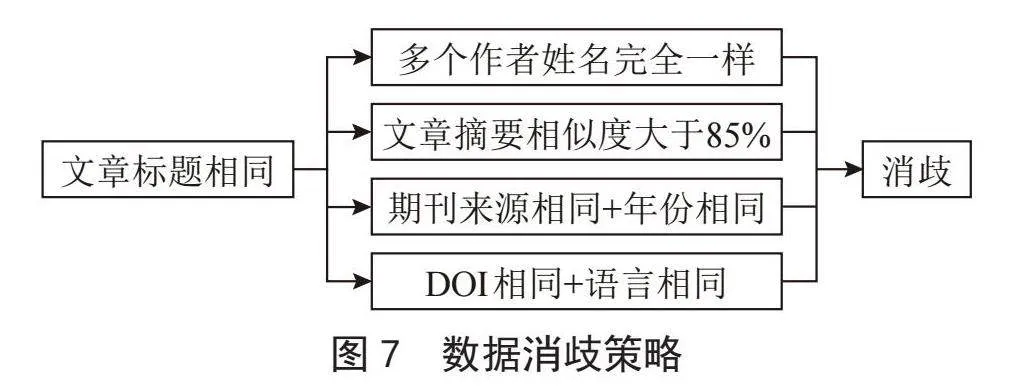
学术论文数据来自各个站点,每个站点的数据质量参差不齐,如何从多源数据提炼出高质量的数据供用户检索使用是聚合系统的核心。而数据消歧是一种有效的解决办法,数据消歧在搜索引擎的数据开发中具有重要的作用,它有助于提高搜索结果的准确性、提高搜索效率、提供一致的用户体验、降低数据误解的风险,并支持数据的可信度和个性化推荐。这是搜索引擎提供高质量信息检索服务的关键环节之一。文本采用的消歧策略如图7所示。如果两篇文章的标题不同,那么它们可以被确定为不同的文章,不需要进行消歧处理。但是,当两篇文章的标题相同时,当两篇文章的标题相同时需要进一步判断是否满足消歧条件,用于区分相同标题的不同文章,以确保数据的准确性和唯一性。
具体步骤如下:
1)使用PySpark从HDFS中读取学术数据,并将其加载为JSON格式的数据。
2)使用文章标题作为关键字段进行数据聚合。如果有相同标题的文章,需要进一步判断它们是否是同一篇文章。如果是同一篇文章,将它们合并为一篇新的文章,继续聚合。
3)重复步骤2),一直持续聚合,直到所有文章都被正确聚合。
4)此时,不同来源的相同文章已经聚合在一起。接下来,需要从多源数据中选择最终的数据,这个过程被称为数据融合。融合的策略是基于站点的权重和投票来确定最终数据。
5)融合后的待发布数据将被保存到HDFS和Elasticsearch(ES)中,各有一份副本。
6)对待发布数据进行质量评测。只有通过质量评测的数据才能够上线使用,以确保数据的准确性和可用性。
4" 结" 论
在研究中,探讨了Python爬虫技术在学术聚合系统中的应用,旨在提供研究者便捷的学术资源获取途径。爬虫技术作为搜索引擎和信息网站数据获取的核心技术之一,为构建这一系统提供了强有力的工具。通过专用的网络爬虫,能够高效地从学术网站上抓取大量有用的学术数据,为学术研究提供了宝贵的信息资源。在研究中,不仅实现了数据的高效抓取,还利用大数据技术手段对爬取的学术数据进行了清洗、聚合和消歧。这些步骤不仅有助于提高数据质量,还确保了数据的一致性和可用性。
参考文献:
[1] 巫伟峰,张群英.基于互联网学术搜索引擎分析国内树莓研究现状——以“百度学术”为例 [J].安徽农学通报,2019,25(14):50-52.
[2] 聂莉娟,方志伟,李瑞霞.基于Scrapy框架的网络爬虫抓取实现 [J].软件,2022,43(11):18-20.
[3] 文献管理工具——Zotero简介 [J].华西口腔医学杂志,2022,40(5):609.
[4] 杨健,陈伟.基于Python的三种网络爬虫技术研究 [J].软件工程,2023,26(2):24-27+19.
[5] 郭晋豫.基于Spark Streaming的反爬虫系统的设计与实现 [D].西安:西安电子科技大学,2021.
[6] 时春波,李卫东,秦丹阳,等.Python环境下利用Selenium与JavaScript逆向技术爬虫研究 [J].河南科技,2022,41(10):20-23.
[7] 郎为民,李宇鸽,田尚保,等.大数据处理技术研究 [J].电信快报,2022(4):1-6+12.
[8] 曹丽蓉.基于HBase数据库的数据分布式存储方法 [J].兰州工业学院学报,2022,29(5):46-50.
[9] 姜庆玲,张樊.基于Python和Requests快速获取网页数据的方法研究 [J].现代信息科技,2023,7(16):100-103+108.
[10] 李琳,董博,郑玉巧.大型风力机异常功率数据清洗方法 [J].兰州理工大学学报,2022,48(3):65-70.
作者简介:崔梦银(1993.05—),女,汉族,河南商丘人,教师,硕士,研究方向:数据分析与数据挖掘;邓茵(2002.11—),女,汉族,广东廉江人,本科在读,研究方向:数据挖掘与分析;刘满意(1992.04—),男,汉族,河南商丘人,软件工程师,硕士,研究方向:数据分析与数据挖掘。
猜你喜欢
前线(2016年12期)2017-01-14 03:54:04
科技资讯(2016年25期)2016-12-27 18:38:16
中国管理信息化(2016年21期)2016-12-27 14:45:06
中国经贸导刊(2016年32期)2016-12-21 13:34:42
经济研究导刊(2016年24期)2016-12-12 15:02:45
合作经济与科技(2016年24期)2016-12-07 02:51:14
新媒体研究(2016年20期)2016-12-02 19:11:35
中国新技术新产品(2016年22期)2016-11-29 04:57:27
电子技术与软件工程(2016年18期)2016-11-14 01:25:39
电脑知识与技术(2016年21期)2016-10-18 23:30:16
