
复杂场景中准确实时的人物识别算法研究
2024-12-31 00:00:00杨锦景飞张童童涂娅欣
现代信息科技 2024年10期
关键词:注意力机制






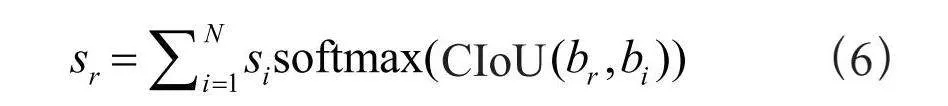
摘" 要:目前,基于深度学习的单步目标检测器已被广泛用于实时目标检测,但其对目标的定位精度较差,并且存在目标漏检、误检等问题。文章提出了一种用于复杂场景中准确实时的人物识别算法。首先,使用高斯YOLOv3来估计预测框的坐标和定位不确定性,然后,采用基于注意力机制的非极大值抑制方法去除冗余的检测框,提高目标检测结果的准确性。经自建数据集训练并测试,改进的高斯YOLOv3对人物的识别精度为83.1%,比YOLOv3提高了1.68%,检测模型可以应用于军事战场人物的识别和定位,为战场态势感知系统提供有效的技术支持。
关键词:人物识别;高斯模型;注意力机制;高斯YOLOv3;非极大值抑制
中图分类号:TP391.4" " 文献标识码:A" 文章编号:2096-4706(2024)10-0046-05
Research on Accurate and Real-time Character Recognition Algorithms in Complex Scenes
YANG Jin1,2, JING Fei1,2, ZHANG Tongtong1,2, TU Yaxin3
(1.The 29th Research Institute of CETC, Chengdu" 610036, China; 2.Sichuan Province Engineering Research Center for Broadband Microwave Circuit High Density Integration, Chengdu" 610036, China; 3.Measurement Center of State Grid Sichuan Electric Power Company, Chengdu" 610045, China)
Abstract: Currently, single step object detectors based on Deep Learning have been widely used for real-time object detection, but their positioning accuracy for targets is poor, and there are problems such as missed detection and 1 detection of targets. This paper proposes an accurate and real-time character recognition algorithm for complex scenes. Firstly, this paper uses Gaussian YOLOv3 to estimate the coordinates and positioning uncertainty of the prediction box. Then, a Non-Maximum Suppression method based on Attention Mechanism is used to remove redundant detection boxes and improve the accuracy of target detection results. After self-built dataset training and testing, the improved Gaussian YOLOv3 has a character recognition accuracy of 83.1%, which is 1.68% higher than YOLOv3. The detection model can be applied to the recognition and positioning of military battlefield characters, providing effective technical support for battlefield situation awareness systems.
Keywords: character recognition; Gaussian model; Attention Mechanism; Gaussian YOLOv3; Non-Maximum Suppression
0" 引" 言
战场态势感知是对作战和保障部队的部署、武器装备、战场环境(地形、气象、水文等)进行实时感知的过程,在未来的信息战中,提高战场态势感知能力可以有效地增强战争的整体控制能力。目前,军事目标的识别和定位是影响战场态势感知的关键技术[1]。因此,研究复杂环境下军事目标的自动检测技术,对战场态势的生成和分析具有重要意义。在战场侦察领域,视频和图像比文本和电报信息更直观、更实用,是目前有效的侦察方法之一。因此,基于视频和图像的战场态势感知技术可以为指挥决策者提供相对丰富、生动的战场全局数据[2]。
近年来,学者们逐渐将基于深度学习的方法应用于战场态势感知,可以有效解决当前信息化战场中复杂的战场态势生成和分析问题。基于深度学习的多层人工神经网络模型具有较强的特征学习能力,大多数现有的基于深度学习的目标检测算法可以分类为两级检测器和一级检测器。两级检测器由区域建议阶段和分类阶段组成。首先,在区域建议阶段,通过许多区域建议策略产生候选框,然后,通过分类方法将这些候选框分为不同的类别,以实现目标检测。周华平[3]等在基于Faster R-CNN框架的基础上提出了一种改进其特征网络ResNet-101的方法,算法平均检测精度提高了5.1%。刘寅[4]在R-FCN网络的基础上采用自适应非极大值抑制修正预测框置信度,利用在线难例学习方法并优化候选框参数,优化后的R-FCN网络对教室内的人物目标识别准确率为89.52%。两级检测器可以实现相当高的检测精度,但检测速度较低,难以应用于实时检测的场景。
相比之下,一级检测器直接返回对象的分类概率和位置坐标,而不需要区域建议过程。例如,YOLO [5]将图像分割成小网格,并同时预测每个区域的候选框概率和分类概率。与两级探测器相比,YOLO实现了速度的颠覆性提高,但目标检测精度较低,其定位误差源于对网格单元的处理。为了提高一级检测器的性能,SSD [6]修改了深度学习网络,增加了多参考和多分辨率策略,以提高检测精度。RefineDet [7]基于SSD网络架构,使用ARM模块和ODM模块互连,以提高检测速度和准确性。与深度网络的修改不同,RetinaNet [8]对其他策略进行了微调,并用焦点损失取代了YOLOv3 [9]中的交叉熵损失,以专注于难以分类的例子,并丢弃负例。Zheng等人[10]提出了一种CIoU损失函数,与GIoU [11]损失和IoU [12]损失函数相比提高了网络的检测精度和收敛速度。高斯YOLOv3 [13]利用高斯函数来确定预测框的定位不确定性。此类检测模型速度较快,但精度相对较低。
由于战场态势的高度动态性,对军事目标的实时检测提出了很高的要求。此外,在战场环境中,军事目标经常受到照明、目标大小、伪装和遮挡的影响,检测算法需要能够适应复杂的战场环境。高斯YOLOv3算法具有良好的实时性和检测性能,因此本文选择高斯YOLOv3作为检测算法的基本结构并对其进行了改进。为了准确、实时地识别复杂场景中的人物,本文提出了一种用于复杂场景中准确实时的人物识别算法。本文首先采用了改进的高斯YOLOv3作为检测算法的基础结构,使用高斯函数来估计预测框的坐标和定位不确定性,有效地提高复杂场景中人物的检测精度。本文提出一种基于注意力机制的非极大值抑制算法,提高了非极大值抑制算法在消除多余候选框的准确性,从而减少了冗余的候选框对检测结果的影响,提高人物检测结果的准确性。
1" 高斯YOLOv3模型
1.1" 基础网络结构
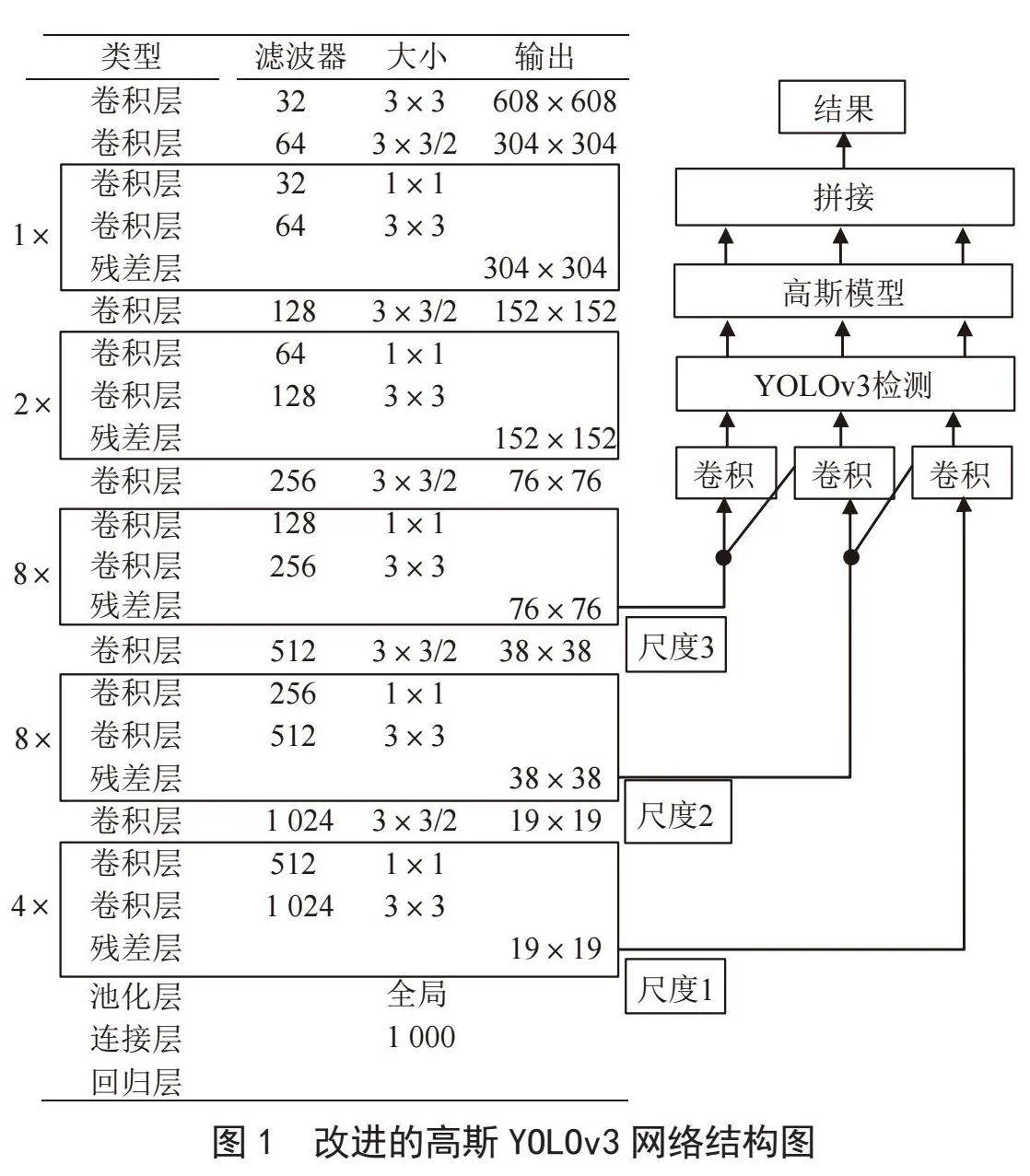
图1给出了改进的高斯YOLOv3框架的架构(图中最左列中的数字1、2、4和8表示重复的残差分量数量),该框架由75个卷积层、23个快捷层、4个路由层、3个YOLO层和2个上采样层组成。改进的高斯YOLOv3生成三个大小分别为76×76、38×38和19×19的特征图,输入图像大小设置为608×608。在改进的高斯YOLOv3网络中,“卷积”模块用于预测对象的边界框坐标、对象置信度值和三个尺度的锚框的类概率。改进的高斯YOLOv3使用“高斯建模”模块来估计预测框的坐标,从而可以确定预测框的定位不确定性。最后,比较了三种尺度的检测结果,并使用一些阈值来确定最终结果。因此,改进的高斯YOLOv3可以在保持实时检测速度的同时提高检测精度。
1.2" 高斯模型
YOLOv3输出预测框坐标、对象得分和类得分,并基于对象和类的置信度对对象进行分类。然而,YOLOv3不能确定预测框的置信度,因此预测框的坐标不确定性是未知的。因此,YOLOv3可能无法准确地确定目标人物的定位。
为了解决这个问题,网络引入高斯函数来估计预测框坐标的不确定性,包括中心信息(即tx和ty)和预测框大小信息(即tw和th)。高斯模型将预测框坐标的均值和方差函数作为输入,因此改进的高斯YOLOv3将YOLOv3中预测框的输出数量从4个增加到8个。预测框的不确定性可以使用tx、ty、tw和th的每个单独的高斯模型进行建模。对于给定的测试输入x,使用以下公式计算单个高斯模型的输出y:
其中,μ(x)和" 分别表示预测框坐标的均值和方差。
此外,高斯YOLOv3调整了网络的损失函数,因此,可以估计高斯YOLOv3中预测框的定位不确定性。tx的损失函数描述如下:
其中W和H分别表示水平和垂直网格的数量。K表示锚框的数量, 表示在(i,j)网格中的第k个锚框处的tx, 表示tx的不确定性, 是tx的GT。通过使用与tx相同的策略来计算ty、tw和th的损失函数。χ为对数函数的数值稳定性指定值10-9。γijk表示权重惩罚系数,其计算如下:
其中ωscale表示基于图像中GT框的宽度和高度比计算,计算式为:
其中, 表示当GT框和当前锚框之间的CIoU损耗大于某个阈值时被设置为1,并且如果没有合适的GT则" 等于零。
预测框坐标的定位不确定性以及对象性得分和类得分被认为是检测标准。考虑定位不确定性的检测标准如式(5)所示:
其中Cr表示高斯YOLOv3的检测标准,σ(Object)是对象性得分,σ(Classi)是第i类的得分。Uncertaintyaver指示预测框坐标的平均不确定性。定位不确定性与预测框的置信度呈负相关。
2" 复杂场景中准确实时的人物识别算法
2.1" 数据集
总所周知,数据在深度学习中占有重要地位,高质量的数据集能够提高模型训练的质量和模型预测的准确性。目前已有许多适用于目标检测的数据集,如COCO2017、PASCAL VOC [14]、ImageNet等。针对复杂环境下军事人物检测任务,本文构建了真实陆地战场作战环境中的军事人物数据集。
数据集中包含了丛林、城市、雪地、沙漠等常见的陆地作战场景,同时目标包含来自不同国家的人物,并且考虑了影响目标检测结果的因素,例如前景遮挡、伪装、烟雾、照明、目标尺寸、成像视角等,部分图像示例如图2所示。数据集中共包含1 507张图片,将数据集中的图片6:2:2的比例划分为训练集、验证集和测试集。数据集图片中的人物目标采用LabelImg标记软件进行标记,并与PASCAL VOC数据集中的标签格式保持一致。
2.2" 网络结构
如上所述,YOLOv3算法在直接应用于检测复杂场景人物时,可能会产生不准确的缺陷定位、漏检、误检等问题。因此,本文采用高斯YOLOv3作为基础网络架构,通过在YOLOv3网络中引入高斯函数,用于复杂场景的人物检测,如图1所示。基于高斯函数的YOLOv3包括两个模块:基础YOLOv3网络和高斯建模模块。首先,YOLOv3网络提取缺陷特征,然后在YOLOv3中引入高斯函数来预测预测框的坐标,从而确定坐标的定位不确定性。具体来说,将预测框的定位不确定性与对象性得分和类得分一起作为检测标准,可以提高检测精度。此外,该模型用注意力机制的非极大值抑制算法代替了IoU损失函数,进一步提高了回归精度和收敛速度。改进的高斯YOLOv3使用特征金字塔在三个不同尺度的特征下进行对象检测。因此,改进的高斯YOLOv3可以适应各种不同大小的对象检测任务。
2.3" 基于注意力机制的非极大值抑制算法
现有的目标检测网络使用的非极大值抑制算法需手动设置阈值,阈值设置不合理容易出现漏检、误检等情况,并且评价方式不太合理,影响网络的检测精度。基于上述问题,本文提出一种基于注意力机制的非极大值抑制算法。
基于注意力的置信度,其计算公式为:
候选边界框集合B = {b1,…,bN},每个候选边界框对应的分类置信度集合S = {s1,…,sN};其中,si表示集合B中的第i个候选框的置信度值,CIoU是全交并比损失函数值,br和sr分别表示当前候选框及其对应的基于注意力的置信度值。
所述的基于注意力机制的置信度加权惩罚算法,其计算公式为:
bm表示当前集合B中置信度最高的候选框,bi是集合B中的第i个候选框,si是式(6)计算得到的置信度值。
3" 实验结果及分析
3.1" 实验参数配置
本文涉及的各项训练及测试实验是在操作系统为Ubuntu18.04的服务器中进行,图形处理器为TITAN RTX。为客观分析算法性能,本文首先使用通用数据集PASCAL VOC预训练改进的高斯YOLOv3模型,然后使用自建军事人物数据集对其进行微调。为了公平比较,各模型学习样本的大小和学习率分别设置为128和0.000 5。
3.2" 检测结果
本文从定性及定量两个维度全面评估算法的性能,首先定性的评估算法的漏检、误检等情况,然后采用均值平均精度(mAP)定量的评估检测算法的检测精度。
本文首先在自建的数据集上对改进的高斯YOLOv3和一些方法进行了全面的定性评估,图3给出了在自建数据集中对来自验证集的一些图像的一些实验结果。从图中可以发现,当使用高斯YOLOv3时存在漏检(第1、4列)、错检(第2列)等问题。相反,本文提出的改进的高斯YOLOv3可以从这些图像中准确地检测所有人物。显然,改进的高斯YOLOv3比高斯YOLOv3人物识别准确率高。
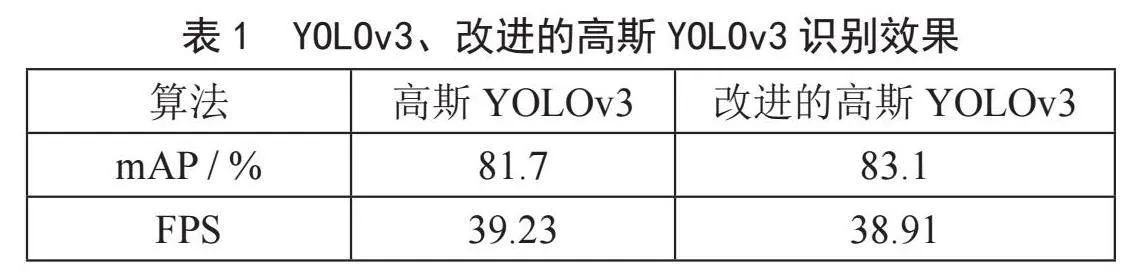
人物识别模型的检测结果如表1所示,实验结果表明,高斯YOLOv3与改进的高斯YOLOv3算法均具有较高的实时性,改进的高斯YOLOv3对人物的识别精度为83.1%,比高斯YOLOv3提高了1.68%。
本文进一步使用三个指标对量种方法进行了定量评估:假阴性(FN)、假阳性(FP)和真阳性(TP)。FN描述人物被漏检,FP表示其他对象被错误地识别位人物;TP表明人物被正确检测和识别。显然,一种优秀的人物是被方法应该具有高TP值和低FN和FP值。表2给出了高斯YOLOv3和改进的高斯YOLOv3的对比情况。从表格可知,改进的高斯YOLOv3获得了最高的TP值和最低的FP和FN值,同时,与高斯YOLOv3相比,FP、FN分别降低了60.00%、40.91%,增加了4.20%的TP。因此,所提出的算法优于以往的研究,适合用于复杂场景的人物识别应用。
4" 结" 论
本文提出了一种用于复杂场景中准确实时的人物识别算法,网络首先采用高斯函数对预测框的坐标进行建模,然后,采用基于注意力机制的非极大值抑制方法去除冗余的检测框,提高目标检测结果的准确性。在自建数据集上的定量和定性对比实验结果表明,所提出的改进的高斯YOLOv3在保持实时性的同时,提高了精度,增加了TP,并显著降低了FP、FN,可以提高人物识别的准确定。在某些情况下,本文算法性能的改善并不明显。本文下一步将针对小目标、目标重叠的目标检测进行研究,进一步提高算法的识别准确率。
参考文献:
[1] 于博文,吕明.改进的YOLOv3算法及其在军事目标检测中的应用 [J].兵工学报,2022,43(2):345-354.
[2] 蒋超,崔玉伟,王辉.基于图像的无人机战场态势感知技术综述 [J].测控技术,2021,40(12):14-19.
[3] 周华平,殷凯,桂海霞,等.基于改进的Faster R-CNN目标人物检测 [J].无线电通信技术,2020,46(6):712-716.
[4] 刘寅.基于R-FCN的教室内人物识别 [J].科学技术创新,2021(30):88-90.
[5] REDMON J,DIVVALA S,GIRSHICK R. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779–788.
[6] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot Multibox Detector [C]//in Lecture Notes in Computer Science(including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics).Amsterdam:Springer,2016:21–37.
[7] ZHANG S,WEN L,BIAN X,et al. Single-Shot Refinement Neural Network for Object Detection [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4203–4212.
[8] LIN T Y,GOYAL P,GIRSHICK R,et al. Focal Loss for Dense Object Detection [C]//2017 IEEE International Conference on Computer Vision (ICCV) 2017.Venice:IEEE,2017:2999–3007.
[9] REDMON J,FARHADI A. YOLOv3: An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV](2018-04-08).https://arxiv.org/abs/1804.02767.
[10] ZHENG Z,WANG P,LIU W,et al. RenDistance-IoU Loss: Faster and Better Learning for Bounding Box Regression [J/OL].arXiv:1911.08287 [cs.CV].(2019-11-19).https://arxiv.org/abs/1911.08287.
[11] REZATOFIGHI H,TSOI N,GWAK J,et al. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression [C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:658–666.
[12] JIANG B,LUO R,MAO J,et al. Acquisition of Localization Confidence for Accurate Object Detection [C]//Computer Vision-ECCV 2018.Cham:Springer,2018:816–832.
[13] CHOI J,CHUN D,KIM H,et al. Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul:IEEE,2019:502–511.
[14] EVERINGHAM M,GOOL L V,WILLIAMS C,et al. The PASCAL Visual Object Classes Challenge Workshop 2008 [J].International Journal of Computer Vision,2010,88(2):303-338.
作者简介:杨锦(1996.04—),男,汉族,四川成都人,工程师,硕士研究生,研究方向:机器视觉、深度学习。
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
无线互联科技(2019年9期)2019-07-29 00:41:36
无线互联科技(2019年9期)2019-07-29 00:41:36
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
