
基于可变形高斯核的训练数据生成的人群计数方法
2024-12-31 00:00:00陈树骏
现代信息科技 2024年10期
关键词:卷积神经网络
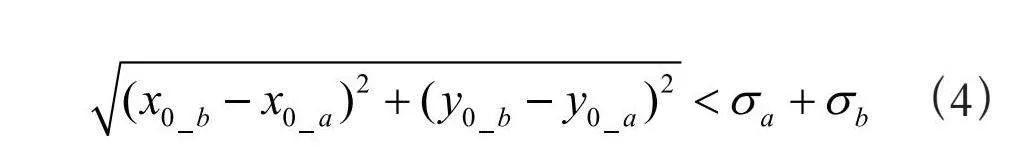
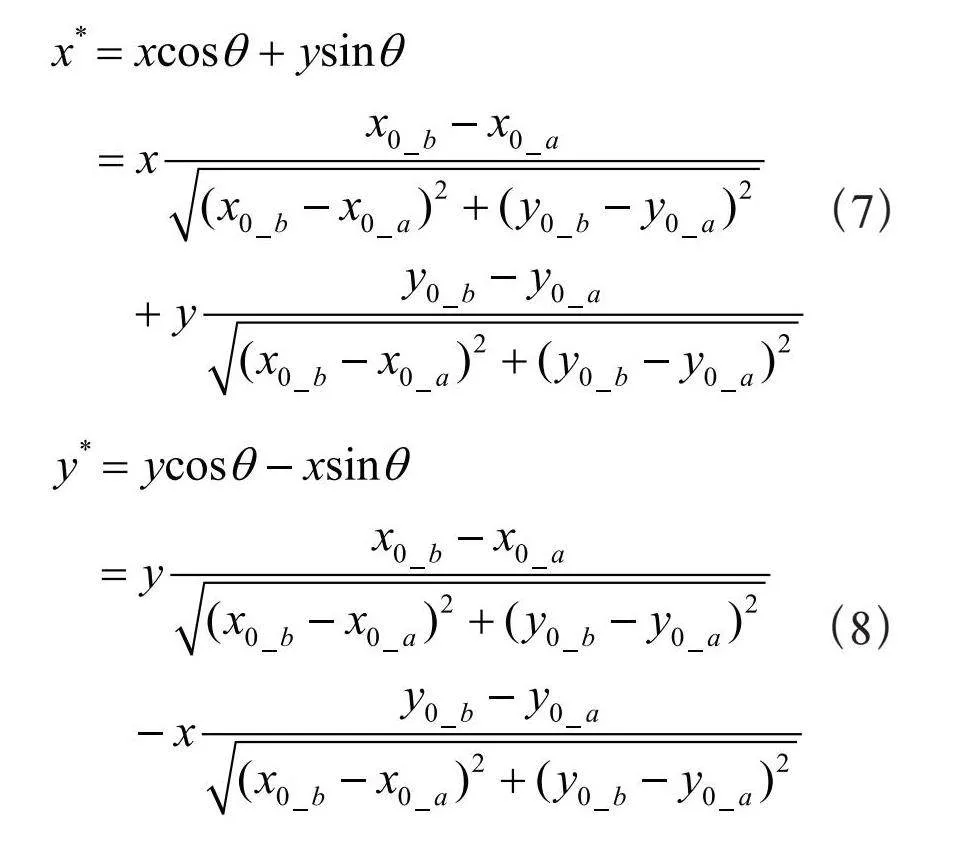
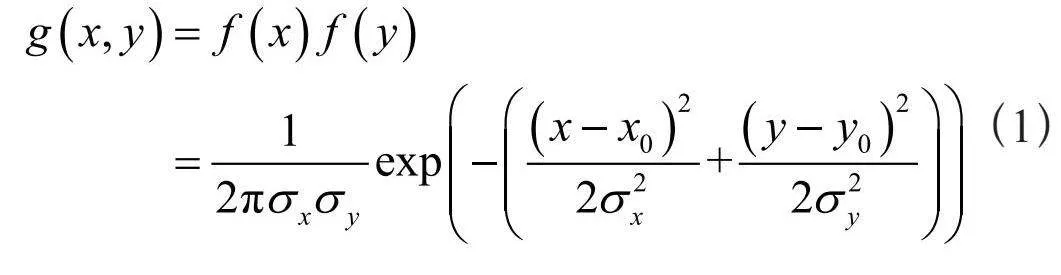

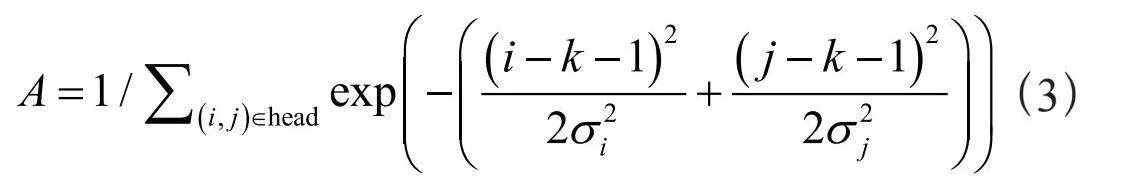
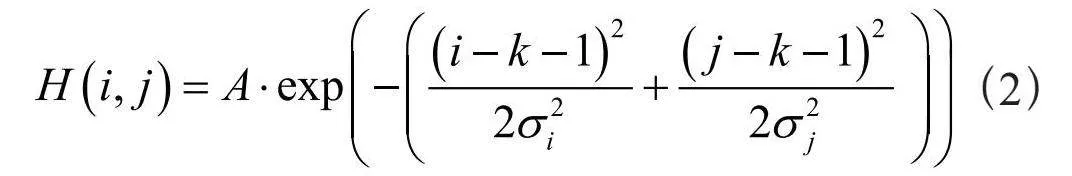
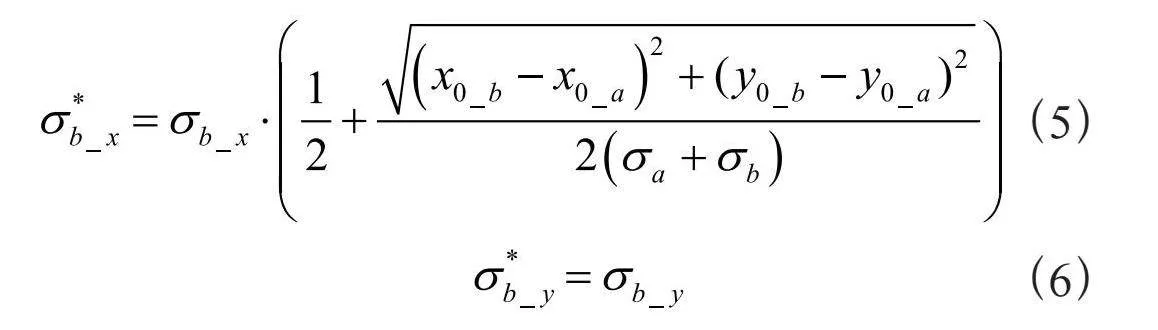

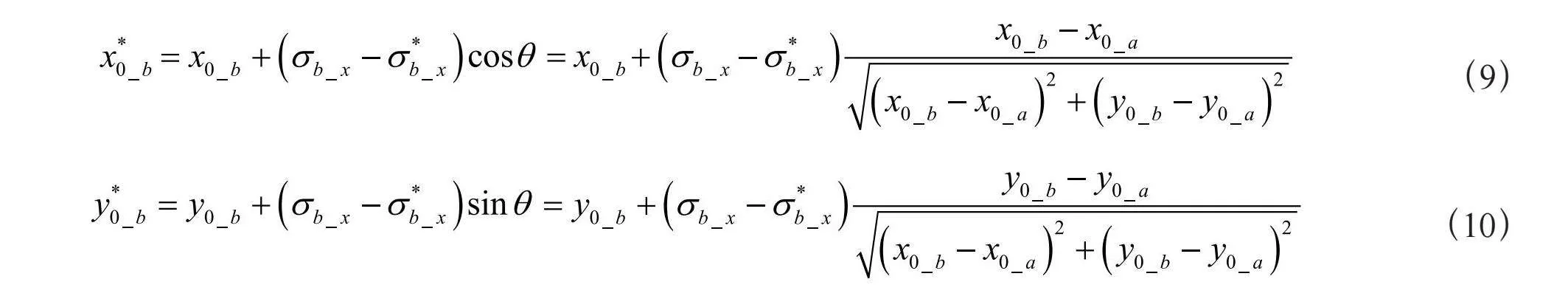
摘" 要:人群计数作为计算机视觉和模式识别任务中重要的子课题,在智能监控中发挥着极其重要的作用。对于被严重遮挡的月牙形人头,传统高斯核生成方法找到的月牙形视觉中心严重偏离人类标注的完整圆形中心,导致算法在训练中不易收敛。针对严重遮挡情况下的人群计数误差问题,提出一种基于可变形高斯核的训练数据生成的人群计数方法,对基于人类标定结果生成的高斯核的形状、角度和位置进行高效调整,从而提升算法的收敛性和精度。实验结果表明,该方法可以显著提升人群计数的性能。
关键词:人群计数;高斯核;卷积神经网络
中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2024)10-0037-05
A Crowd Counting Method Generated Based on Training Data of Deformable Gaussian Kernels
CHEN Shujun
(CRSC Communication amp; Information Co., Ltd., Beijing" 100070, China)
Abstract: Crowd counting, as an important sub topic in computer vision and pattern recognition tasks, plays an extremely important role in intelligent monitoring. For crescent-shaped human heads that are severely occluded, the crescent-shaped visual center found by traditional Gaussian kernel generation methods deviates significantly from the complete circular center annotated by humans, making it difficult for the algorithm to converge during training. A crowd counting method generated based on training data of deformable Gaussian kernel is proposed to address the issue of crowd counting errors in severe occlusion situations. The method adjusts efficiently the shape, angle, and position of the Gaussian kernel generated based on human calibration results, thereby improving the convergence and accuracy of the algorithm. The experimental results show that this method can significantly improve the performance of crowd counting.
Keywords: crowd counting; Gaussian kernel; Convolutional Neural Networks
0" 引" 言
如今,人工智能技术迅速发展,并且在全球范围内普及,以往需要大量人力的工作,现在完全可以由计算机完成[1]。人群计数是计算机视觉领域中的一个热门研究课题,其目的是通过计算机对输入图像进行处理来估计图像中的人数。随着人口数量的激增,在火车站、旅游景点、商场等诸多场景中,都会出现大量人群快速聚集的情况。而人群计数能够针对这些特定场景下的人群目标数量进行估计,做到对重大事件的事先警告以及在事后复盘中发挥重要作用[2,3]。此外,人群计数方法也能够辅助实现实时估计场景人数,进而对各个场景中人数进行有效的管控,减少人群的聚集。
近年来人群行为分析常用的基础方法是基于卷积神经网络[4-7]深度学习的人群计数系统,其主要原理是:通过大量的训练,让卷积神经网络自动学习人类头部的主要特征(例如近似圆形,相对于背景来说颜色较深的头发等),最终将网络输出的卷积图与事先做好的、使用类似于人头形状的二维高斯核密度函数(以下简称高斯核)来表示每个人头所在的位置的人群密度图的对比差异。因为单个高斯核在人群密度图中的各个像素点处数值的积分之和为1,所以只需要统计输出的人群密度图中属于各个高斯核的像素点处数值的积分总和,系统就可以得到对原始画面中总人数的估计数值。系统将其对总人数的估计数值与训练数据中的实际数值,以及网络输出的卷积图与训练数据中的人群密度图之间的差异,作为网络反向误差传播的依据,最终通过迭代,修改网络中的相关参数,训练网络对于人头形状目标的识别能力。
然而在现实中人群图片中大量存在一个现象,即人头因为互相遮挡而出现重叠,并且按照透视关系原理,两个相互遮挡的人头在摄像机视角方向的中心点位置越接近,其相互重叠的面积比例越高。按照现有方法,相互重叠的两个人头都用各向均等的圆形高斯核来代表,而在原始人群图片中位置靠前的人头拥有比较完整、清晰的圆形边缘,与训练数据中的圆形高斯核的形状非常近似,卷积神经网络可以比较容易地通过学习训练数据,将其识别出来;而位置靠后被遮挡的人头依照重叠程度的大小呈现不同程度的月牙形,其视觉重心向未重叠部分移动。此时,如果继续使用圆形高斯核,由于高斯核自身的性质,其越接近圆心处灰度数值越大,两个相互重叠的圆形高斯核的视觉重心位于其中心点连线附近。此时就会使得被遮挡的人头在原图中的视觉中心,不仅与对应的被遮挡的高斯核在训练数据人群密度图中得视觉重心不一致,还容易与遮挡其的人头对应的高斯核融合成一个整体,人群计数系统的卷积神经网络不容易通过对圆形的高斯核的训练,学习到被遮挡的人头的特征规律并将其与前方遮挡其的人头分开,最终导致算法训练不易收敛,训练结果不确定性大,系统输出的人群密度图不准确,人群计数的误差较大。
针对上述问题,本文提出了一种人群计数系统中基于可变形高斯核的训练数据生成方法,其有效地增加了训练数据的人群密度图与真实图像的特征相似性,使卷积神经网络更容易学习到训练数据与真实图像之间的规律,提高了人群计数系统的精确性。我们分别在具有挑战性的Shanghai Tech_A [8]、Shanghai Tech_B [8]、UCF_QNRF [9]和UCF_CC_50 [10]数据集上进行了大量的实验来验证本文所提出模型的结果。实验结果表明,我们的方法大大优于当前主流的人群计数方法。
1" 相关方法
鉴于现有的绝大部分人群计数数据库中只给出图片中的人头二维坐标作为训练数据(即训练算法去完成的目标),为了便于系统将输出的人群密度图与训练数据进行误差比对,优化卷积神经网络的训练效果,系统需要将训练数据中每个人头的二维坐标,转化为画面中类似人头的形状。因此,人群计数系统的训练数据生成方法,均采用二维高斯核密度函数,以每个人头位置坐标为中心点,在画面中生成用于训练的模拟人头形状,以达到对更好训练效果。
如上所述,人群计数系统的训练数据生成中,最关键的一个步骤就是以人头的二维坐标为中心点,生成与之对应的高斯核,为了解释高斯核的具体生成方法,首先将连续型二维高斯函数的表达式展示如下:
(1)
其中,(x0,y0)为该函数的中心点位置,即人头坐标。σx与σy分别为该函数在x轴方向与y轴方向的方差。考虑到人头基本可以视作圆形,为了便于计算,上述文献中默认取σx = σy。
于是在离散域内,一个尺度为(2k+1)×(2k+1)离散的高斯核可以被表示为:
(2)
其中,A为为了使高斯核截止区域内各个像素点的高斯核灰度数值积分后等于1而设置的常数,其数值并不一定等于式(1)中的1/2πσxσy项的数值,需要根据实际情况加以调整,调整的目的是使得属于同一个人头head对应的那个高斯核的各个离散像素点的灰度数值相加总和为1,因此,其计算方法如下:
(3)
将式(3)称为:传统人群计数系统的离散高斯核表达式。系统对训练数据中的每一个人头的坐标,重复上述过程,然后将生成的所有高斯核离散像素点的灰度数值以叠加的方式绘制在同一张画面中,就完成了训练数据的生成。
2" 本文方法
本文提供一种人群计数系统中基于可变形高斯核的训练数据生成方法,该方法有效地增加了训练数据的人群密度图与真实图像的特征相似性,使卷积神经网络更容易学习到训练数据与真实图像之间的规律,提高了人群计数的精确性。
为实现上述目的,采取以下技术方案:一种人群计数系统中基于可变形高斯核的训练数据生成方法,其包括以下步骤:
1)从训练数据中找出一组相互重叠的高斯核,依次读取使用传统人群计数系统的高斯核生成的训练数据中每个高斯核的中心点坐标(即人头中心点坐标),将该高斯核记录为被选取过的高斯核,并找出与之距离最近的另一个高斯核的中心点坐标。
对于上述两个高斯核a与b中心点坐标分别为(x0_a,y0_a)与(x0_b,y0_b),其各自高斯核密度函数方差分别为σa与σb(因为原始训练数据中的高斯核在二维坐标系下为圆形,故此处对每个高斯核用单一的方差数值),若其中心点坐标之间的几何距离小于其方差相加之和,则认为这两个训练数据的高斯核在原始图片中所对应的人头之间发生重叠,即这两个高斯核之间发生重叠:
(4)
每个高斯核只与和自身中心点坐标之间的几何距离最近的另一个进行是否相互重叠的判断,若判断结果为它们相互重叠,则将它们都作为被选取过的高斯核,然后转至步骤2);否则,转至步骤5)。
2)对被遮挡的高斯核,根据两个高斯核的方差及其中心点距离,沿单坐标轴方向进行伸缩。对于被判断为相互重叠的高斯核a与b,如果其中一个高斯核a的方差大于另一个高斯核b的方差,即σa>σb,则认为是a对应的人头离拍摄人群画面摄像头的直线距离更近,在画面中a遮挡了b。
此时,需要对高斯核b沿坐标轴方向进行伸缩。将高斯核b的方差分解为分别沿x轴与y轴的两个相互独立的方差分量σb_x与σb_y,并默认将x轴方向作为高斯核a与b中心点坐标连线的方向。按照以下公式将被遮挡的高斯核b沿着x轴方向的方差分量减小,并保持高斯核b沿着y轴方向的方差分量不变,得到对高斯核b的经过伸缩后的沿x轴与y轴的两个相互独立的方差" 与 ,如式(5)、式(6)所示:
(5)
(6)
将伸缩后的高斯核b的方差代入传统人群计数系统的离散高斯核表达式,即式(3),就可以得到经过伸缩后的离散高斯核表达式。
3)对被遮挡的高斯核,根据画面坐标轴与两个高斯核中心点连线的夹角,沿反时针方向进行旋转:
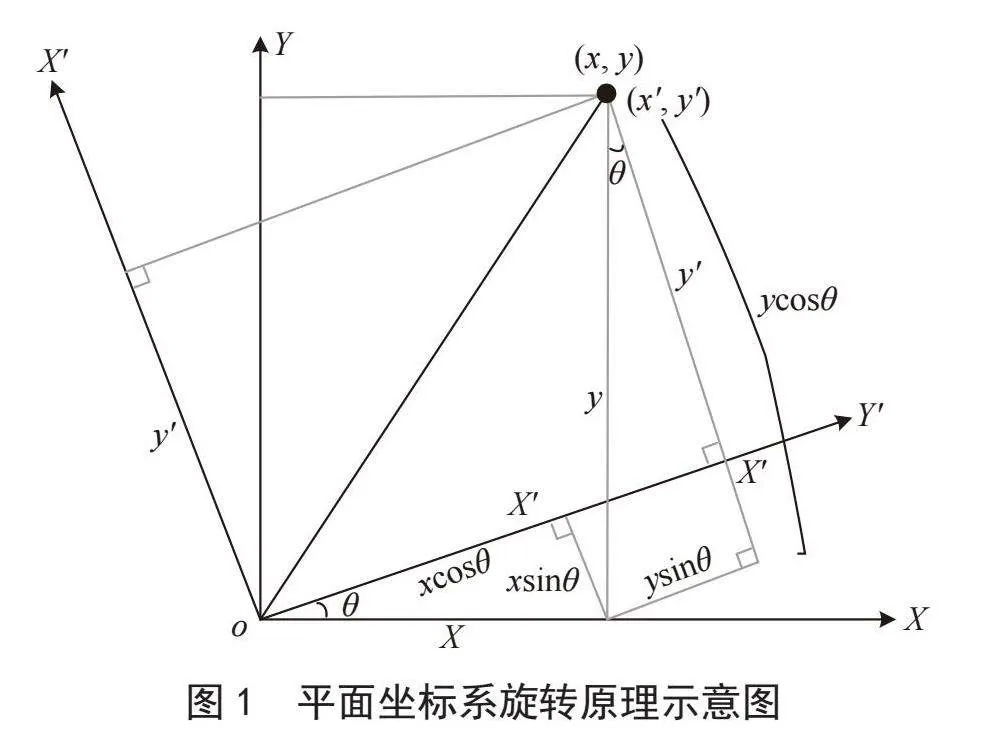
在实际中,高斯核a与b的中心点连线方向可能为人群密度图画面的二维坐标系中的任意方向,其不一定为b自身的x轴方向。假设人群密度图画面的x轴正向与高斯核a与b的中心点连线指向b的一端沿着反时针方向相差角度θ,则高斯核b需要以其中心点为原点,沿着反时针方向旋转角度θ,如图1所示。
将属于人群密度图画面中的点的坐标(x,y)按照平面直角坐标系反时针方向旋转角度θ的坐标变换规则进行变换,就得到该点在被遮挡的高斯核b旋转后的坐标系中的坐标(x*,y*)。将该点在被遮挡的高斯核b旋转后的坐标系中的坐标代入经过伸缩后的离散高斯核表达式,得到经过伸缩、旋转后的离散高斯核表达式,如式(7)、式(8)所示:
(7)
(8)
图1" 平面坐标系旋转原理示意图
4)对被遮挡的高斯核,根据两个高斯核的方差及其中心点距离,沿两个高斯核中心点连线方向进行中心点坐标调整。
由于高斯核b被a遮挡,其对应的人头在原始图片中的视觉效果是,其未被遮挡部分(即可视部分)的几何重心点实际上也发生了变化,即沿着人头在其中心点连线向高斯核b对应人头的方向移动。为了保证人群密度图的视觉特征与原始图片接近,将高斯核b的中心点坐标沿着高斯核a与b的中心点连线方向,向着高斯核b的方向移动,移动的距离等于步骤2)中高斯核b的方差沿着x轴减少的数值 。通过上述操作完成对于对被遮挡的高斯核b的中心点坐标的调整。高斯核b调整后的中心点坐标(,)如下:
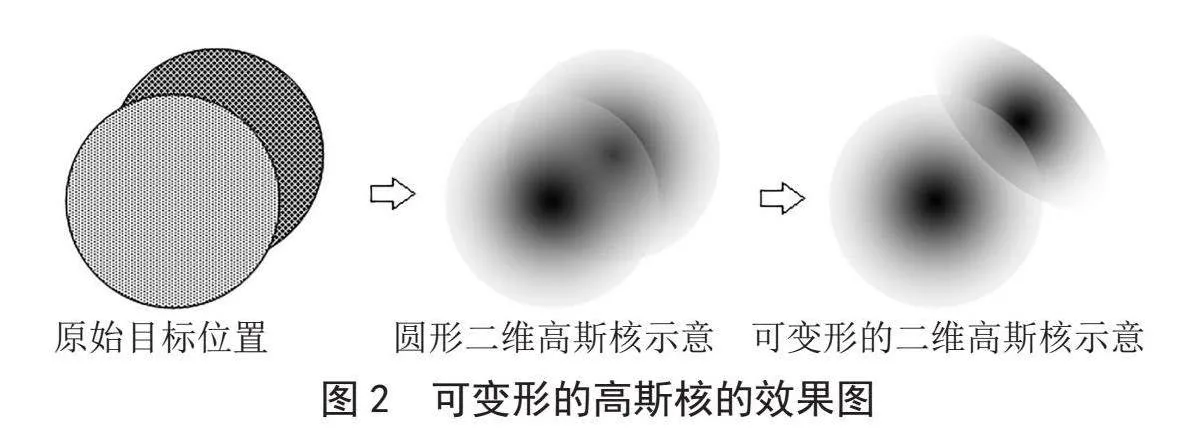
将被遮挡的高斯核b的调整后中心点坐标代入经过伸缩、旋转后的离散高斯核表达式,得到经过伸缩、旋转、中心点坐标调整后的离散高斯核表达式。可变形的高斯核的效果如图2所示。
图2" 可变形的高斯核的效果图
5)判断训练数据中是否还有未被选取过的高斯核。如果训练数据中还有未被步骤1)选取过的高斯核,则转至步骤1);反之,则对人群密度图中每个像素点,将其所属的高斯核的灰度数值相加,并将得到的带灰度数值的人群密度图作为训练数据输出,结束。
综上,本文使用可变形的高斯核代替传统方法中固定的圆形高斯核。当判断出传统的圆形存在相互遮挡的现象时,其认为高斯和对应的人头发生了相互遮挡。对于被遮挡的高斯核,本文通过依次使用伸缩、旋转、中心点坐标调整等变形方法,将变形后的高斯核在人群密度图中的视觉重心调整到与原始图片中被遮挡的人头露出来的部分的视觉重心基本一致,同时还增加了相互遮挡的高斯核的视觉重心之间的分离度,有利于卷积神经网络对于被遮挡的人头的特征学习。因为被遮挡的高斯核的完整性没有被破坏,所以本文保证了训练数据中每个高斯核积分后的数值仍然为1,仍然满足人群计数的要求。通过本文的改进,保证了训练数据中作为目标的人群密度图与实际图片中的特征规律的一致性,增强了卷积神经网络的训练效果,最终提高了人群计数的精确性。
3" 实验结果与分析
本文在4个公开可用的数据集上进行实验验证,分别是Shanghai Tech_A(SHA)、Shanghai Tech_B(SHB)、UCF_QNRF(QNRF)和UCF _CC_50(UCF50)数据集。
实验基于PyTorch [11]、CUDA 10.1下进行,并且在Ubuntu 18.04操作系统和NVIDIA GeForce RTX 3080的GPU条件下设置实验。我们使用在ImageNet数据集上预训练的VGG-16 [10]作为我们的骨干网络,并通过Adam优化器以固定学习率2×10-4优化网络,批量大小为8。为使模型充分训练,在图像的不同位置执行随机翻转、剪切操作,以提升模型鲁棒性。
3.1" 评估标准
我们遵循人群计数中常用的指标,使用平均绝对误差(Mean Absolute Error, MAE)和均方误差(Mean Squared Error, MSE)进行评估,其定义公示为:
其中,Ntest为测试图像数量; 和yi分别为第i张测试图像的实际人数和预测人数。
3.2" 实验结果分析
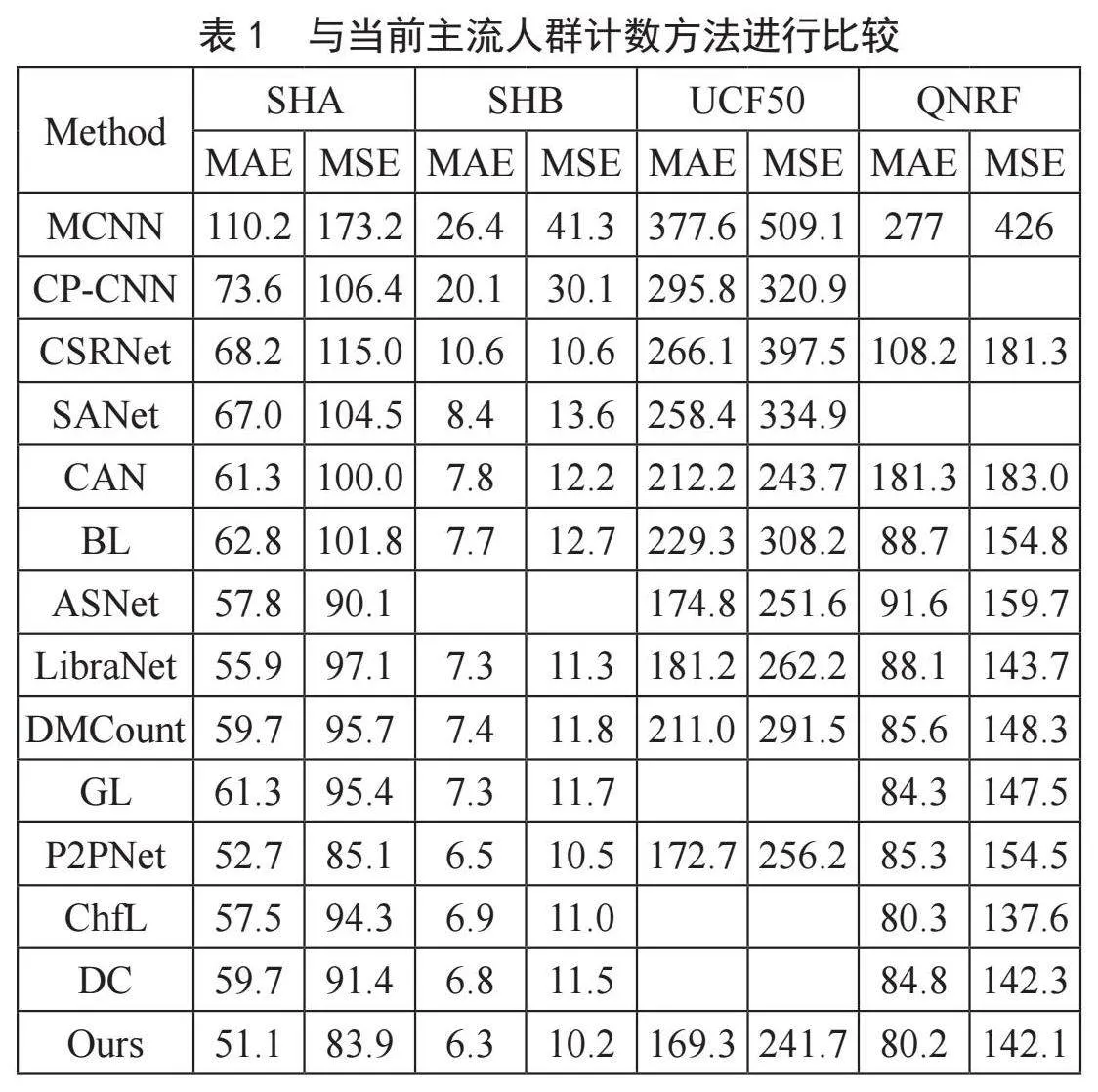
我们在SHA、SHB、UCF50、QNRF四个数据集上将所提出方法与当前主流的人群计数方法进行比较,实验结果如表1所示。所提出的方法在SHA、SHB数据集上的MAE和MSE分别能达到51.1、83.9和6.3、10.2,在UCF50数据集上的MAE和MSE分别能达到169.3和241.7,在QNRF数据集上的MAE和MSE分别能达到80.2和142.1。在四个数据集上均取得了出色的结果,足以证明本文所提出方法保证了训练数据中作为目标的人群密度图与实际图片中的特征规律的一致性,增强了卷积神经网络的训练效果,最终提高了人群计数的精确性。
同时,为了能够直观的展示本文方法的预测效果,列出了生成的预测密度图的可视化结果,如图3所示。本文方法能够生成高质量的人群密度图,有效降低计数误差,可以看出预测密度图与原始真实图十分接近。
4" 结" 论
人群计数存在烦琐的数据标注问题,限制了其在实际场景中的应用。本文提出一种人群计数系统中基于可变形高斯核的训练数据生成方法,使用可变形的高斯核代替传统方法中固定的圆形高斯核。并分别在四个具有挑战的数据集上进行实验验证,结果表明本文所提出方法可以取得更好的MAE和MSE,有效提升了算法的收敛性和最终的结果精度。
参考文献:
[1] 盖荣丽,蔡建荣,王诗宇,等.卷积神经网络在图像识别中的应用研究综述 [J].小型微型计算机系统,2021,42(9):1980-1984.
[2] SHAO J,KANG K,LOY C C,et al. Deeply Learned Attributes for Crowded Scene Understanding [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:4657-4666.
[3] CAO X K,WANG ZH P,ZHAO Y Y,et al. Scale Aggregation Network for Accurate and Efficient Crowd Counting [G]//Computer Vision – ECCV 2018.Munich:Springer,2018:757–773.
[4] LECUN Y,BOSER B,DENKER J S,et al. Backpropagation Applied to Handwritten Zip Code Recognition [J].Neural computation,1989,1(4):541-551.
[5] SAM D B,SAJJAN N N,BABU R V,et al. Divide and Grow: Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE,2018:3618-3626.
[6] LIU J,GAO C Q,MENG D Y,et al. DecideNet: Counting Varying Density Crowds Through Attention Guided Detection and Density Estimation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:5197-5206.
[7] DING X H,LIN Z R,HE F J,et al. A Deeply-Recursive Convolutional Network For Crowd Counting [C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Calgary:IEEE,2018:1942-1946.
[8] ZHANG Y Y,ZHOU D S,CHEN S Q,et al. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:589-597.
[9] IDREES H,TAYYAB M,ATHREY K,et al. Composition Loss for Counting, Density Map Estimation and Localization in Dense Crowds [J/OL]. arXiv:1808.01050 [cs.CV].[2023-09-22].https://doi.org/10.48550/arXiv.1808.01050.
[10] IDREES H,SALEEMI I,SEIBERT C,et al. Multi-source Multi-Scale Counting in Extremely Dense Crowd Images [C]//2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland:IEEE,2013:2547-2554.
[11] CHEN K M,COFER E M,ZHOU J,et al. Selene: A PyTorch-Based Deep Learning Library for Sequence Data [J].Nature methods,2019,16(4):315-318.
作者简介:陈树骏(1981—),男,汉族,江苏南通人,高级工程师,本科,研究方向:视频分析、周界入侵。
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22 23:24:25
电脑知识与技术(2016年33期)2017-03-21 23:19:04
科技创新与应用(2017年5期)2017-03-16 09:48:22
电脑知识与技术(2016年30期)2017-03-06 20:14:45
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
软件(2016年5期)2016-08-30 06:27:49
电脑知识与技术(2016年10期)2016-06-16 21:27:26
