
针对恶意逃避行为的PDF文档检测
2024-12-31 00:00:00李东帅尚培文
现代信息科技 2024年10期
关键词:网络攻击


摘" 要:便捷式文档格式(PDF)是全球数据交换中广泛使用的格式之一,人们对其有很高的信任度。然而,近年来不法分子利用PDF文档进行恶意网络攻击的情况越来越严重。随着黑客技术的进步,他们也逐渐采用一些逃避检测的方法,使得常见的学习算法难以检测到这种恶意文件。针对这些“更聪明”的恶意PDF攻击样本,对PDF文档的特性进行了分析,提取了25维特征,并应用调参后的Adaboost算法训练模型,准确率达到99.63%,优于同领域的其他研究成果。
关键词:PDF;逃避检测;Adaboost算法;网络攻击
中图分类号:TP309" 文献标识码:A" 文章编号:2096-4706(2024)10-0007-06
PDF Document Detection for Malicious Evasion Behavior
LI Dongshuai, SHANG Peiwen
(School of Electronics amp; Information Engineering, Liaoning University of Technology, Jinzhou" 121001, China)
Abstract: The Portable Document Format (PDF) is one of the widely used formats in global data exchange, and people have a high level of trust in it. However, in recent years, the situation of criminals using PDF documents for malicious network attacks has become increasingly serious. With the advancement of hacker technology, they are gradually adopting methods to evade detection, making it more difficult for common learning algorithms to detect such malicious files. In response to these “smarter” malicious PDF attack samples, an analysis of the characteristics of PDF documents is conducted, and 25-dimensional features are extracted. By applying a finely-tuned Adaboost algorithm for model training, an accuracy rate of 99.63% is achieved, surpassing other research achievements in the same field.
Keywords: PDF; evading detection; Adaboost algorithm; network attack
0" 引" 言
便捷式文档格式(Portable Document Format, PDF)是全球数据交换中广泛使用的格式之一。然而,不法分子利用PDF文档进行恶意网络攻击的情况越来越严重。恶意PDF是指设计用于进行恶意活动的PDF文件,它包含了恶意代码或利用漏洞的文件。恶意PDF通常通过电子邮件、社会工程等方式传播,并诱使用户打开PDF文档或点击文档中的链接。一旦用户执行恶意PDF文档中的操作,就可能导致系统被感染、数据泄露或其他安全问题。PDF作为现今用户量极大的办公软件,常被黑客们用来作为APT(Advanced Persistent Threat)实施攻击的第一步,成为APT攻击的重要载体。在过去的几年中,Locky勒索软件曾经通过钓鱼邮件传播,并使用恶意PDF文档作为附件。用户打开这些PDF文件后,文档会解密恶意代码并将其运行,导致用户的文件被加密并要求支付赎金才能解密。在暗网上,有人出售定制的恶意PDF文档,这些文档可以用于各种攻击,如钓鱼、远程代码执行等。攻击者可以购买这些恶意PDF文档,然后将它们用于自己的攻击活动。由此可见,应该及时预防和应对此类危害[1]。
随着时间的推移,恶意PDF检测技术已经得到改进。过去,基于签名的检测是通常采用的方法,通过检查文件的元数据和有效载荷,并尝试将其与预定义的恶意签名/模式集相匹配来检测恶意软件。然而,这种方法存在一些局限性,例如黑客们可以通过混淆恶意内容来逃避检测,以避免模式匹配。此外,签名数据库必须频繁更新,以便及时识别并抵御新出现的恶意软件。另一种技术是使用基于行为的检测,可将代码在沙箱中运行并监控行为,包括初始化进程、API调用、CPU和内存影响,以确认程序是良性的还是恶意的。然而,基于行为的分析也有一些无法检测到恶意软件的局限性,因为黑客开始使用一些逃避技术,例如,一些恶意软件使用延时方法,在恶意内容被归类为良性后立即延迟其执行;其他恶意软件具有一些高级功能,可以检测到沙盒环境的存在,从而一直保持空闲状态,直到它被发布到生产环境[2]。
要应对恶意PDF的威胁,需要开发新的、更加高效和智能的检测和防御技术。为了解决传统方法存在的局限性,近年来研究者们开始使用机器学习分类技术来解决恶意PDF检测问题。使用机器学习的优势在于,可以通过训练特定数据集并提取数据特征来做出决策,从而确定文件是恶意的还是良性的。通过使用机器学习,可以让计算机自动学习和识别特定模式或特征与传统的基于签名和规则的检测方法相比,机器学习能够提供更准确、更快速和更智能的检测和识别方式。
然而,针对这些基于机器学习的检测器,黑客们也会逃避每个类中发现的共同显著特征,从而绕过检测器的防御。这使得它们更难被常见的学习算法检测到。这将研究人员在将恶意的PDF文件与正常PDF文件分开方面遇到了困难。
本文提出了一种新的PDF恶意软件检测方法,是基于机器学习的综合模型,该方法可以从大量逃避检测的PDF文件中识别出恶意PDF文件。并且在数据集Evasive-PDFMal2022上实现了99.63%的预测精度,实验结果证明了所提出的PDF检测系统的高效性。
1" 相关工作
针对传统基于签名、规则匹配的研究在2010年之后已经很少,因为其存在着一些局限性,已不再受到研究的关注。文献[3]和文献[4]提到通过签名、规则匹配检测分析恶意样本,然而,这类方法需要大量时间和资源维护规则库,并且更新周期长,很难及时处理和应对新出现的恶意文档。此外,由于规则制定过于依赖专家经验,往往会漏报变异程度较大或是新型的恶意文档,降低了检测的准确性和可靠性。因此,这些方法在实际应用中的效果有限,需要进一步改进。
JavaScript是PDF攻击的主流,绝大部分恶意PDF文档要完成特殊操作的函数和JS代码等要做动态的恶意行为都是在JavaScript中实现的,所以“/JavaScript”和“/JS”关键字数量越大越可能是恶意的,在2014年至2017年的文献中,大量文献仅对JavaScript进行检测。文献[5]基于JavaScript攻击的PDF样本文件分析,包括解压缩与解密各个PDF文件流对象,以及对解密后的JavaScript代码进行完整的预处理,形成有效的特征向量集,在此基础上建立规则特征库来判断恶意PDF。文献[6]对提取到的JavaScript数据流进行还原处理及反混淆等方法处理,然后对得到的原始JavaScript代码提取相应的特征向量,再利用支持向量机训练出的分类器进行静态检测。文献[7]使用N-gram算法提取JavaScript特征向量,使用半监督学习,结合三种不同的分类器,提高了检测精度和泛化能力。
近些年检测恶意PDF的特征提取工程逐渐完善,部分研究也针对类不平衡的情况做出分析。文献[8]通过对不均衡PDF样本集的双向采样,提出了一种新的方法K-Means,它可以有效地消除欠采样,再结合TBSMOTE,将样本分类到均衡状态,从而提高检测效果。文献[9]提出了一种新的检测方法,它利用特征集聚和卷积神经网络技术,有效地解决了特征维度高、数据集样本少导致模型欠拟合的问题,并采用Ward最小方差聚类技术将聚合特征转换为卷积神经网络,从而实现了对恶意PDF的准确检测。文献[10]在针对对抗样本的检测上,提出了一种基于文档图结构和卷积神经网络的检测方法,经过计算得到图的拉普拉斯矩阵,并以此作为特征送入CNN分类模型进行训练,性能优于KNN和SVM分类模型。文献[11]中Jiang等人使用小波能量谱基于熵序列提取结构特征以及统计特征,采用随机子采样策略来训练多个子分类器。每个分类器都是独立的,增强了检测时的泛化能力。使用半监督学习算法(Semi-SL),实验结果表明,尽管使用仅11%标记的恶意样本的训练数据,该方法的准确率仍达到94%。文献[12]中Mohammed等人创建了一个名为MaleX的新数据集,其中包含约100万个恶意软件和良性Windows可执行样本,用于大规模恶意软件检测和分类实验,采用深度ResNet-50卷积神经网络(ResNet-50 RNN)准确率达到96%。
随着技术的进步,黑客们也通过尝试绕过检测器的防御,随之PDF领域也出现了防御对抗的相关研究。文献[13]主要介绍了一种防御恶意样本逃逸SVM模型检测的方法,通过提取正常和恶意PDF样本集合中的高频节点作为特征,并利用增加正常节点对恶意PDF进行伪装的方式,将生成的逃逸样本加入SVM分类器的训练集中,经过多次迭代,以达到检测这类逃逸样本的目的。文献[14]通过模拟不同强度的攻击,将对抗样本添加到训练集中,提出集成决策树方法来对对抗样本进行检测。文献[15]通过使用逃避攻击方法实现对KNN算法在恶意PDF分类进行攻击,有效提高KNN分类器的鲁棒性。文献[16]同样在Evasive-PDFMal2022数据集上采用随机森林算法对逃避PDF实现了较高的准确率。文献[17]中Abu Al-Haija等人采用可优化决策树算法在Evasive-PDFMal2022数据集上通过提取32维有效特征使用了2.174微秒的短预测间隔内实现了较高的检测精度。
2" PDF介绍
PDF是一种可移植文件格式,用于在不同操作系统和设备上共享文档。与其他格式不同的是,PDF文件的布局和格式都是固定的,这意味着除非使用专业的PDF编辑工具,否则无法更改其内容。因此,PDF文件通常被用作电子文档、电子书籍、学术论文、合同协议等需要保护内容不被篡改的场合。
2.1" 物理结构
PDF的物理结构指的是文件在磁盘或存储介质上的实际布局。PDF文件的物理结构由头部、中间部分、相关索引表以及文件尾组成。PDF文件头部包含了“%PDF-”版本的规范信息,并以一个序号标记。比如,“%PDF-1.7”显示出PDF文档完全符合PDF1.7的标准。所有以Obj开头和Endobj结尾的对象构成了一个完整的集合。每个对象都有一个唯一的编号,用于在文件中引用。对象中间可能包含stream数据流或子对象。索引表cross-reference类似一个目录,它记录了文件中各个对象的位置和编号,并提供了快速查找和访问对象的方式,其地址通常在文件尾部的“Trailer”开头标志处指定。关键字Trailer处为文件尾,包含cross-reference的地址和一些文档描述信息包括所有对象的数量、创建时间、ID等,如图1所示。
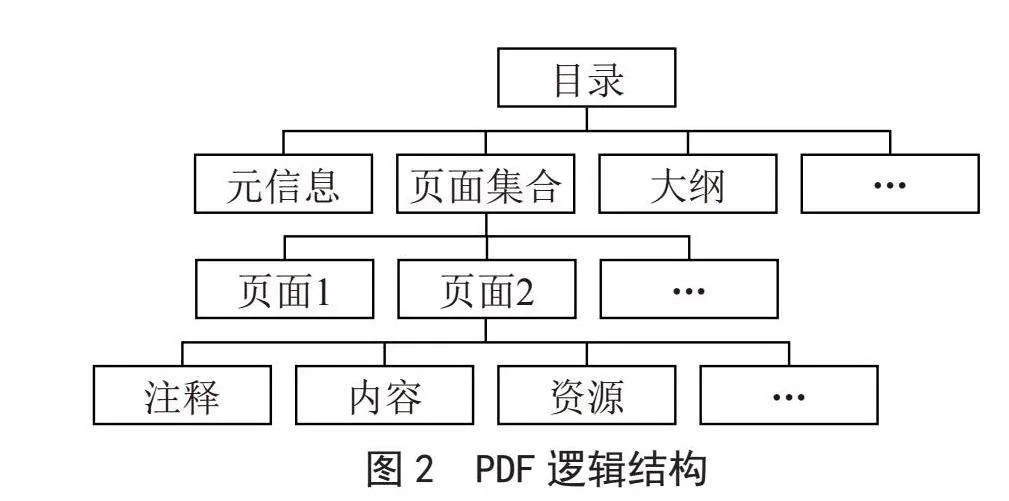
2.2" 逻辑结构
PDF的逻辑结构是指文件中内容的组织和布局方式,涉及目录结构、文档结构、标签树和区域结构等元素。逻辑结构定义了文档的层次结构、页面顺序、标签语义等信息,以便于文档的浏览、导航和索引。PDF文件从逻辑上看是一个以Catalog为根节点的树形结构,如图2所示,其下包括Pages、Outlines等子对象节点。Catalog字典中还包括一些承载不同PDF文件信息的节点对象,如Type、Version、AA等对象节点。具体而言,Type节点指定了所使用的PDF版本类型,Version节点记录了PDF版本号,PageLabels节点存储了PDF文件的页码标签信息,PageLayout节点指定PDF文件页面的布局,AA节点存储了一些PDF执行动作的信息。Pages是Page的集合入口,包括Count、Kids、Parent、Type等字段,其中Page对象包含content、annotations、resources等信息。
物理结构和逻辑结构是PDF文档的两个重要方面,它们相互依赖并共同构成了完整的PDF文件。通过正确与协调地组织物理结构和逻辑结构,可以实现文档的正确显示、导航和处理。物理结构提供了文件的整体框架和组织方式,确保文件在存储介质上的正确读取和解析。逻辑结构描述了文件中的内容、布局和层次结构,使得读取和解析后的数据能够按照逻辑方式进行显示和处理。物理结构和逻辑结构之间通过文件头部和交叉引用表进行联系和映射。文件头部包含了重要的文档信息和结构定义,交叉引用表记录了文件中各个对象的位置和关系,使得逻辑结构能够正确地访问和使用物理结构中的数据。而本文提取出的各关键字数量就是从PDF源码层面统计出来的。
2.3" 逃逸手段及结构分析
PDF的逃逸手段总结归纳为以下几种,包括:
1)使用加密算法或压缩技术隐藏恶意代码,在结构中体现为:PDF文件是否使用了加密算法对内容进行加密;PDF文件中使用的过滤器的总数,过滤器可以用于压缩或加密数据,也可能隐藏了恶意代码;PDF文件中包含嵌套过滤器的对象的数量,嵌套过滤器可能用于多层次的数据处理和隐藏恶意代码;“stream”关键字数量和“endstreams”关键字数量,统计PDF文件中涉及流对象的关键字数量,流对象可以用于存储压缩或加密的数据,其中可能隐藏了恶意代码等。
2)采用多层嵌套或动态生成来增加检测难度,在结构中体现为:“obfuscation”的数量,这可能包括使用随机生成的名称、使用非常短的名称等方式来混淆代码结构;嵌套过滤器的对象数量;流对象的数量,流对象可用于存储和隐藏大量数据,包括恶意代码,从而增加了检测难度;PDF文件中所有流对象的平均大小等。
3)利用JavaScript来执行自动化操作、远程控制、欺骗用户访问可疑链接等,同时还可能对代码进行混淆,在结构中体现为:关键词“/JS”和“/JavaScript”的数量,JavaScript可以用于执行各种操作,包括自动化、远程控制和欺骗用户等;关键词“/URI”和“/Action”的数量,这些关键词通常与JavaScript代码的执行和跳转相关,用于触发特定的操作或访问可疑链接;关键词“/launch”和“/submitForm”的数量,这些关键词通常与JavaScript代码的执行和控制相关;obfuscations的数量:PDF文件中名称模糊化的对象数量,包括JavaScript函数、变量和对象等。名称模糊化可以增加代码的复杂性和阅读难度。
4)恶意代码还可能被隐藏在对象的末尾或文件结尾的Trailer中,同时对象本身也可能会被隐藏或加密,在结构中体现为:关键词“/Endobj”的数量,恶意代码可能会被隐藏在一个对象的末尾,使用
“/Endobj”作为结束标志;关键词“/Trailer”的数量,恶意代码可能会被隐藏在文件结尾的Trailer中;关键词“/Xref”和“/Startxref”的数量,这些关键词通常与恶意代码被隐藏或篡改相关。
5)关键节点可能会被混淆,使得用户难以发现恶意代码的存在,在结构中体现为:唯一字体总数,恶意代码可能会通过字体来混淆和隐藏关键节点;关键词“/Encrypt”和“/Decrypt”的数量,加密和解密可以用于隐藏恶意代码和数据;关键词“/ObjStm”
“/JS”和“/JavaScript”的数量,这些关键词通常与恶意代码和关键节点的混淆和隐藏相关;被压缩对象数量,压缩可以用于隐藏恶意代码和数据。
6)正常情况下,PDF文件中的对象会以关键字“Obj”开始并以“Endobj”结尾,攻击者可能会利用这一点来欺骗检测系统,将恶意代码隐藏在没有明确结束标志的对象中,在结构中体现为:关键词“/Obj”和“/Endobj”的数量:PDF文件中涉及对象和结束标志的关键词数量。攻击者可能会利用这些关键词来隐藏恶意代码和数据,并绕过检测系统。
3" 实验方法
3.1" 特征工程
总结归纳对逃避检测的恶意PDF关键特征,如图3所示。本文利用fitz提取了PDF大小、是否加密、元数据大小、page数量、PDF头等一般特征,然后利用pdfid从PDF源码提取“Obj”“Endobj”“stream”“endstream”“/JS”“/JavaScript”“/Action”
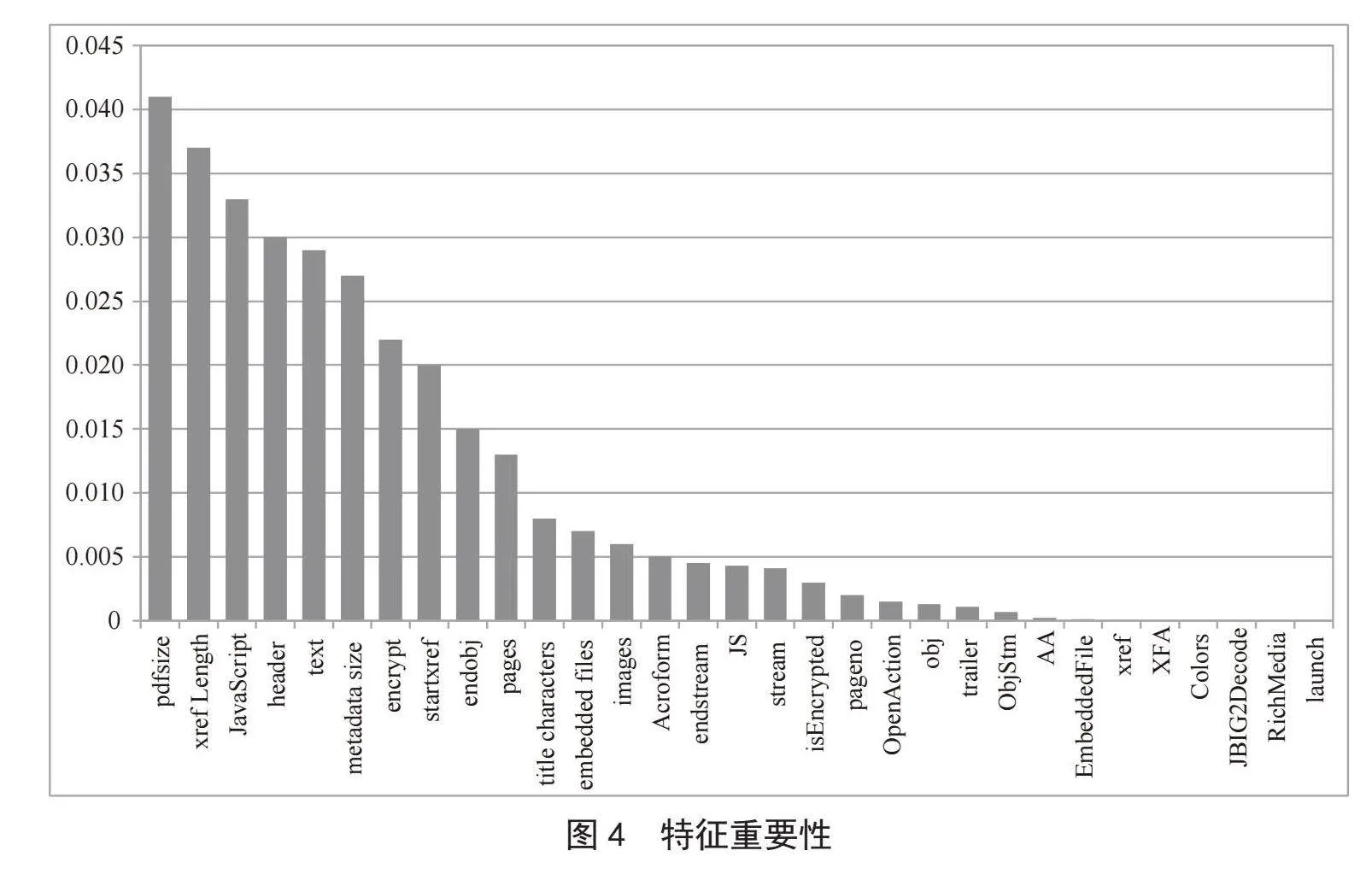
“/AA”等关键字数量进行收集,并将各关键字的数量作为结构特征。基于不同特征对分类器性能的影响不同,我们使用决策树算法进行了特征重要性评估。最终确定了重要性排名前24的特征作为本文实验的特征集,特征重要性的排序如图4所示。
3.2" 分类模型
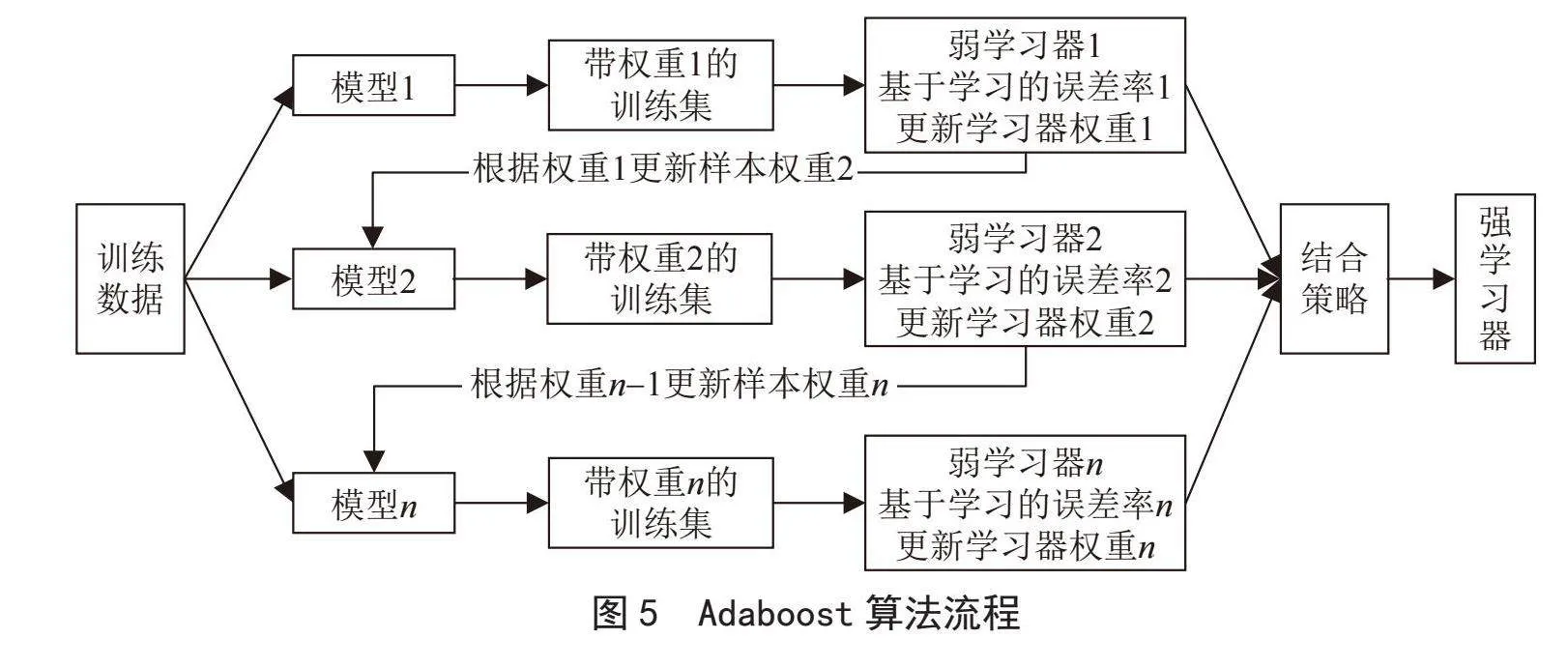
本文采用了Adaboost算法来构建模型。Adaboost是一种集成自适应增强机器学习方法,旨在通过组合多个弱分类器来构建一个强分类器,基本思想是依次训练一系列分类器,并根据之前分类器的错误情况来调整样本权重,较高的权重分配给错误分类的示例,使得错误分类的样本在后续的分类器训练中得到更多关注,这有助于减少学习过程中的偏差和方差,对逃避样本在迭代训练中得到更多的关注,如图5所示。同时,我们在实验中也使用了随机森林和Stacking这两个集成学习算法训练出来的模型进行对比实验,并进行了实验效果评估。相对以上两种算法,从原理的角度来看,Adaboost算法尤其在处理复杂问题和存在噪声的数据集时表现优异,而本文数据集是逃避检测的PDF样本,可以根据权重的分配自适应调整来重点关注被错误分类的PDF样本,通过迭代再进一步调整权重,从而在训练过程中更加关注恶意逃避的特征,Adaboost算法通过串行训练多个弱分类器并组合它们的结果,这意味着该算法仍可能通过组合多个弱分类器的结果来捕获和识别恶意特征。总体而言,Adaboost由于其自适应调整和集成学习的特性使得它在该实验环境下具有一定优势。
4" 实验流程
4.1" 数据集
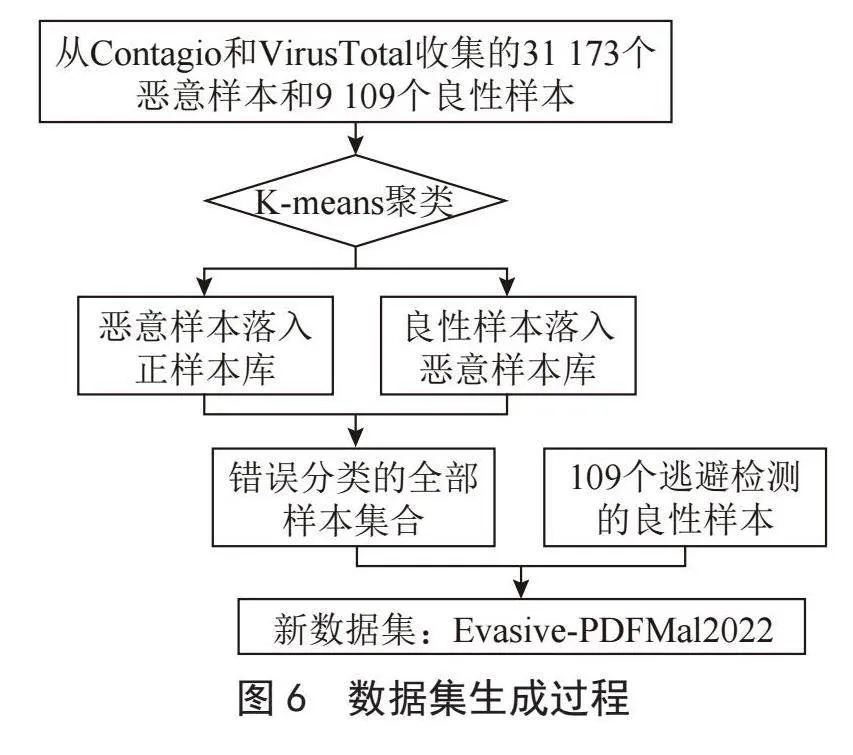
本研究引用CIC Evasive-PDFMal2022数据集。本数据集是由4 468个良性文件和5 557个恶意文件组成,是经过4万多个文件经过处理筛选出错误分类的逃避检测样本集合。数据发布者采用K-means机器学习算法进行分析,样本被分到错误的恶意标记聚类中被认为是恶意记录规避集,这些样本与其他同类样本的特征相差较大,因此未被聚类到大部分具有相同标签的样本中。此样本集将分类错误的良性样本和分类错误的恶意样本合并得到了一份新数据集作为CIC Evasive-PDFMal2022数据集,如图6所示。
图6" 数据集生成过程
4.2" 实验设置
K折交叉验证(k = 5),将数据集分成训练集、验证集和测试集三部分。数据表经过的数据清理后,使用k折交叉验证方法进行随机拆分,将数据集分成5个不同的子集。按照顺序选择其中一个子集作为验证集,而将剩下的4个子集作为训练集。将对每个子集分别进行一次训练和验证。在进行模型训练时,使用4个训练集中的数据来训练模型,在进行模型验证时,使用当前选定的验证集来评估模型的性能和效果。可以使用验证集上的评估结果来优化模型的超参数或调整算法。最终得到5个不同的折叠训练和验证集,利用训练集和验证集反复迭代训练和验证模型,迭代更新出最佳模型,然后对模型进行评估,计算其性能指标。
4.3" 评估指标
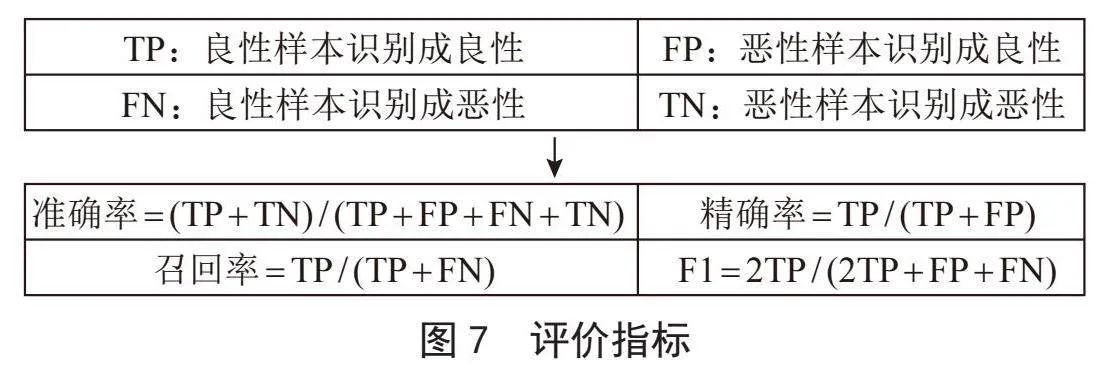
本文实验的评估指标包括:准确率、精确率、召回率和F1值。图7为呈现该指标的混淆矩阵。
4.4" 实验结果及分析
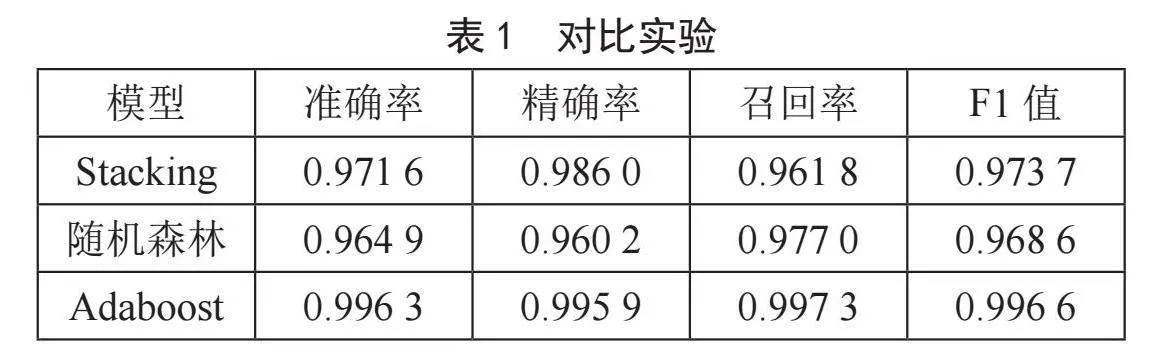
依次使用Adaboost、Stacking和随机森林训练并测试模型,经过比较,如表1所示,我们发现使用Adaboost算法训练出的模型表现最佳,因此最终选择Adaboost作为模型训练的方法。
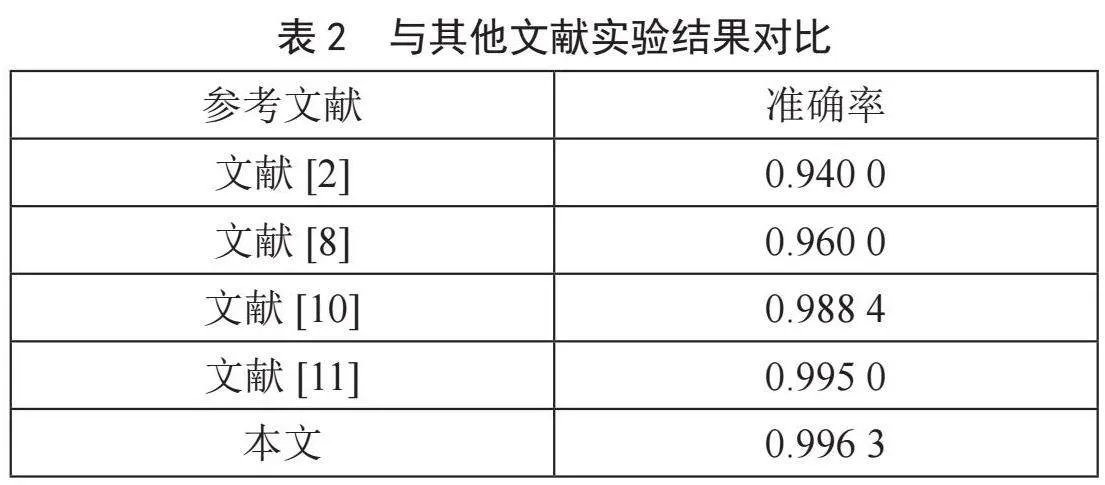
我们将本文所提出的方法与同领域的研究进行了对比,比较结果如表格2所示。经过对比可以看出本文所提出的方法在准确率上优于其他模型。本文经过提取了最佳特征组合,再结合Adaboost算法针对本文的逃避检测PDF样本,根据权重的分配自适应调整重点关注被错误分类的PDF样本,通过迭代调整权重,在训练过程中更加关注恶意逃避的特征。Adaboost算法通过组合多个弱分类器的结果捕获和识别恶意特征,实验证明,其由于自适应调整和集成学习的特性而在该实验环境下具有一定优势。
5" 结" 论
随着数字化转型和远程工作的全球趋势,数字文档需求显著增加。然而,数字文档的广泛应用也带来了针对用户文件和机器的恶意软件开发的风险。其中,PDF文件是全球最常用的数字文件之一,也是各种威胁和恶意代码攻击的目标。黑客们会在PDF文件中嵌入恶意代码,并将其隐藏,以感染受害者的机器。因此,本文提出、开发并评估了一种新的PDF恶意软件检测智能系统。该系统采用高性能机器学习模型AdaBoost算法。我们在使用称为Evasive-PDFMal2022的新数据集上训练并评估模型。结果在检测准确度、精确度、召回率、F1值具有优越性,并在同一研究领域优于其他最先进的模型。因此,所提出的模型在各个领域都可以推广和应用。
参考文献:
[1] 喻民,姜建国,李罡,等.恶意文档检测研究综述 [J].信息安全学报,2021,6(3):54-76.
[2] 林杨东,杜学绘,孙奕.恶意PDF文档检测技术研究进展 [J].计算机应用研究,2018,35(8):2251-2255.
[3] BACCAS P. Finding Rules for Heuristic Detection of Malicious Pdfs: With Analysis of Embedded Exploit Code [EB/OL].[2023-09-06].https://pobicuscom.files.wordpress.com/2018/04/vb2010-baccas.pdf.
[4] 张福勇,齐德昱,胡镜林.基于C4.5决策树的嵌入型恶意代码检测方法 [J].华南理工大学学报:自然科学版,2011,39(5):68-72.
[5] 胡江,周安民.针对JavaScript攻击的恶意PDF文档检测技术研究 [J].现代计算机:专业版,2016(1):36-40.
[6] 徐建平.基于SVM模型的恶意PDF文档检测方法 [J].电脑知识与技术,2016,12(24):90-92.
[7] 李睿,杨淑群,张新宇.一种双向采样的恶意PDF文档检测方法 [J].软件导刊,2022,21(5):67-72.
[8] 俞远哲,王金双,邹霞.基于特征集聚和卷积神经网络的恶意PDF文档检测方法 [J].信息技术与网络安全,2021,40(8):35-41.
[9] 俞远哲,王金双,邹霞.基于文档图结构的恶意PDF文档检测方法 [J].信息技术与网络安全,2021,40(11):16-23.
[10] JIANG J G,SONG N,YU M,et al. Detecting Malicious PDF Documents Using Semi-Supervised Machine Learning [C]//DigitalForensics 2021: Advances in Digital Forensics XVII.[S.I.]:Springer,Cham,2021,612:135-155.
[11] MOHAMMED T M,NATARAJ L,CHIKKAGOUDAR S,et al. Malware Detection Using Frequency Domain-Based Image Visualization and Deep Learning [J/OL].arXiv:2101.10578 [cs.CR].[2023-09-02].https://doi.org/10.48550/arXiv.2101.10578.
[12] CUAN B,DAMIEN A,DELAPLACE C,et al. Malware Detection in PDF Files Using Machine Learning [C]//15th International Conference on Security and Cryptography.Porto:SciTePress,2018,2:412-419.
[13] 李坤明,顾益军,张培晶.对抗环境下基于集成决策树的恶意PDF文件检测 [J].计算机应用与软件,2020,37(10):318-322+333.
[14] 李坤明,顾益军,王安.逃避攻击下恶意PDF文件检测技术 [J].中国人民公安大学学报:自然科学版,2019,25(3):60-64.
[15] AlMahadeen A,alkasassbeh M. PDF Malware Detection Using Machine Learning [J/OL].computer science and mathematics,2023:2023010557[2023-08-20].https://doi.org/10.20944/preprints202301.0557.v1.
作者简介:李东帅(1999—),男,汉族,吉林四平人,硕士研究生在读,研究方向:恶意软件检测;尚培文(1996—),男,汉族,山西晋中人,硕士研究生在读,研究方向:威胁检测。
猜你喜欢
电子技术与软件工程(2016年19期)2016-12-19 20:10:11
电子技术与软件工程(2016年19期)2016-12-19 20:03:56
俪人·教师版(2016年15期)2016-11-22 05:00:11
电脑知识与技术(2016年22期)2016-10-31 18:53:49
中国科技博览(2016年19期)2016-10-19 12:19:12
企业导报(2016年8期)2016-05-31 19:54:38
电脑知识与技术(2015年34期)2016-03-07 12:03:06
科技视界(2016年5期)2016-02-22 10:08:37
电脑知识与技术(2015年23期)2015-11-13 11:42:47
科技资讯(2015年16期)2015-07-21 21:00:55
