
基于余弦相似度的内容比对程序设计与实现
2024-11-29 00:00:00胡雪赵佳英
电脑知识与技术 2024年27期

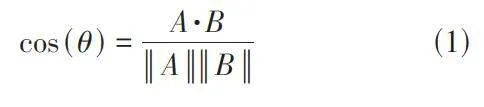
摘要:文章设计并实现了一个基于Python语言,利用余弦相似度进行内容比对的程序。该程序能够高效地比对Word和PDF文档内容相似度,通过内容解析、文本分词以及余弦相似度计算等关键技术,实现对文档内容相似度的精确评估。与其他相似应用相比,该程序能够进行脱机处理,可用于本地化作业查重。论文详细阐述了程序的设计思路、关键技术、具体编程实践以及测试验证过程,为文档内容比对的研究与应用提供参考。
关键词:余弦相似度;相似度比对;文件解析;数据分词;程序设计与开发
中图分类号:TP311.52 文献标识码:A
文章编号:1009-3044(2024)27-0042-03
0 引言
随着信息化时代的迅猛发展,人们每天都被海量信息和数据淹没。从新闻报道、工作文档到个人文件,信息的快速增长对如何高效检索、快速比对数据提出了严峻挑战。文档内容的相似度比对[1]技术成为了文献查重、信息检索、数据挖掘等多个领域不可或缺的工具,在快速识别出重复和相似内容,提高信息处理的效率和准确性上发挥着巨大作用。然而,在本地化文档内容相似度[2]比对的细分领域,仍存在显著的空白与挑战。例如,当教师面对大量学生提交的本地作业文档时,缺乏有效的轻量级程序来快速而准确地比对这些文档的相似度。现存的一些文档比对工具大多依赖于网络连接,在一定程度上限制了使用范围;同时,一些工具操作复杂,界面不够友好,对非技术背景人员来说难以上手;此外,许多工具需要用户将文档上传至云端进行比对,这无疑增加了数据泄露的风险。因此,设计并开发一款专为本地化文档内容设计,能够离线运行、操作简单、高效且注重隐私的轻量级程序是一个亟待解决的实际问题。
本论文设计并实现了一种基于余弦相似度的内容比对程序,利用余弦相似度算法对Word和PDF文档进行内容相似度计算。该程序整体界面简单、友好易用,可运行于本地化脱机环境,极大提升了本地化文档比对的效率和准确性。特别是在教育领域的作业查重方面,展现出强大的实用性与创新性,弥补了现有内容比对领域的不足,具有一定的实践价值。
1 程序设计
本程序是一个基于Python语言自主开发的文档内容相似度比对的脱机程序。它整体采用模块化架构设计,确保了程序的高内聚低耦合特性,便于后续维护与扩展。该程序可独立运行于Windows本地环境,无须依赖额外的服务器或网络,极大地提高了使用的便捷性。
在用户界面设计上,程序使用图形化界面、操作流程简便,为用户提供了两种比对模式:一对一文件比对和某一文件路径下多文件的相似度比对。用户可以根据实际需求,在左侧栏选择相应的比对模式,右侧会立即展现相应的操作界面。
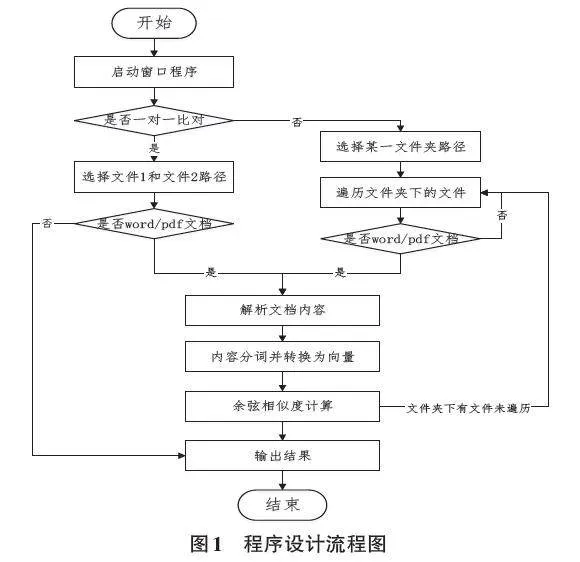
在业务逻辑设计上,程序通过总控程序进行全局调度与管理,确保各模块间的协同工作。程序设计的流程图如图1所示。首先,用户启动程序并在界面左侧选择一对一文件比对或者多文件比对模式。
在一对一比对模式下,用户须分别选定两个待比对的文件。点击比对按钮后,程序会检测文件是否为可比对类型,若不是Word或PDF文档,须提示“程序暂不支持此文件类型比对”。对于支持的文件类型,程序先根据文件类型调用相应的方法进行内容解析;获取文本内容后,将连续的文本转换为易于分析的词汇单元,并利用词频-逆文档频率技术将分词结果转换为数值向量,最后计算两个向量的余弦得出相似度作为结果输出。
在多文件比对模式下,用户需要选定某一文件夹路径。点击比对按钮后,程序开始遍历该文件夹下的所有文件,同时,利用排列组合的方式生成两两比对的文档组合。这种方法与嵌套两层for循环不同,可以有效避免重复组合,提升程序的比对效率。对于非Word或PDF文档,程序须自动忽略包含任一非规定文档的组合。后续处理逻辑与一对一比对模式相似,可复用代码。
2 关键技术
程序的设计围绕三大核心技术展开:内容解析、文本分词和余弦相似度[3-4]计算。
首先,内容解析是程序的基础环节,专注于从不同格式的文档中精准提取出文本内容。程序结合了python-docx库来读取doc、docx等Word文档的内容。同时,利用PyPDF2库进行PDF文档内容的提取,确保了本程序能够支持多种格式的文档内容比对。
接下来,文本分词是将连续文本切割成独立词汇单元的预处理环节,为后续相似度计算奠定基础。程序采用jieba[5]库对中文文档内容进行分词处理,该库算法是一种基于前缀词典,并结合动态规划算法和隐马尔可夫模型实现的分词算法。对于英文文档,则直接采用简单的空格作为分词依据进行分词处理。分词后的文本内容被拆分为多个词组,进而利用scikitlearn[6-7]库中的TfidfVectorizer 类生成TF-IDF 向量[8]。通过统计各个词在词汇集中出现的次数和词汇集合的大小计算出词频,同时统计包含各词的集合数计算出逆文档频率,再者,将词频和逆文档频率进行相乘,形成文本向量,为相似度计算作准备。
最后,余弦相似度计算是衡量两个文本向量之间相似度的指标,是得出程序结果的关键技术。其通过计算两个向量夹角的余弦值,就可以判断它们之间的相似程度。其算法逻辑见公式(1),A、B 为文本向量,A·B 表示两个向量的点积,||A||、||B||分别为两个向量的模。余弦相似度值越接近1,表示两个文本越相似;值越接近0,表示两个文本越不相似。
3 实现与测试
3.1 代码实现
程序的主要代码结构遵循模块化设计原则,分为四大模块:main.py作为主程序入口,负责程序的启动与整体流程控制;GUI.py提供用户交互界面;logic.py 负责逻辑处理,执行程序的核心功能;commonTools.py 包含多个公共方法,供其他模块调用。这种设计使得每个模块的职责清晰且单一,有效降低了模块间的耦合度,提升了代码的可读性、可维护性和可扩展性。
main.py是整个程序的入口点,负责初始化必要的资源,启动图形用户界面等。
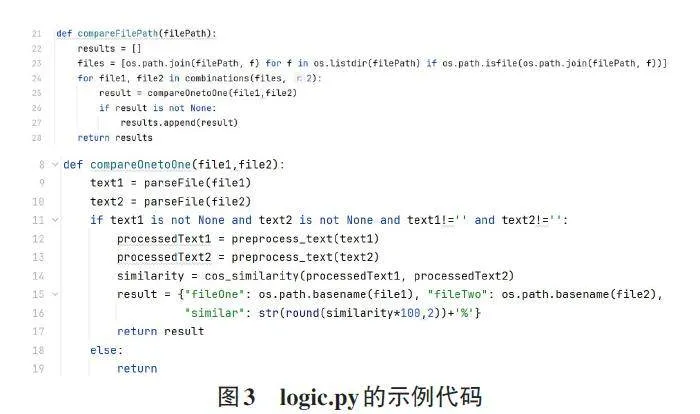
GUI.py负责构建和管理用户与程序之间的交互界面,使用图形化元素,如按钮、输入框、表格等来呈现程序的功能和结果。GUI.py绘制了左右布局的页面窗口,左侧供用户选择比对模式,右侧根据模式变换显示。若选择一对一比对,右侧则显示两个文件的路径选择框、比对按钮和结果展示区;若选择多文件比对,右侧则显示单个文件夹选择框、比对按钮和结果展示区。GUI.py同时也定义了事件处理逻辑,当用户选择比对模式和比对按钮时,程序会捕获按钮事件,分别调用compare_one_to_one()和compare_mul⁃tiple_files()方法,其代码如图2所示。这两个方法处理逻辑类似,都是通过获取页面的文件路径,并分别调用具体的比对方法compareOnetoOne()和compareFile⁃Path()之后,最后将返回结果插入result_treeview变量,最终展示在结果区。
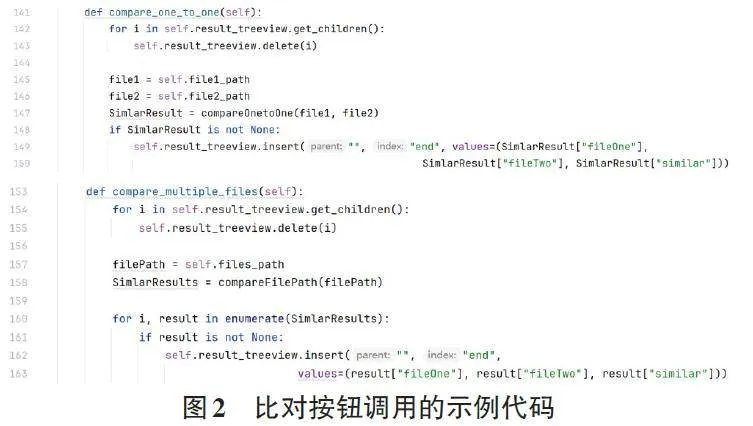
logic.py是程序的核心处理逻辑代码文件,包含compareOnetoOne()和compareFilePath()两个方法,负责进行具体文件内容的比对。首先调用commonTools中的parseFile()方法解析文件,然后,将解析结果传入preprocess_text()方法进行文本分词并转换为向量,之后,通过调用cos_similarity()方法计算余弦相似度,计算出两个文件间的内容相似度,返回至result变量。compareFilePath()通过itertools 中的combinations 生成指定路径下的两两文件组合,通过循环调用compare⁃OnetoOne()方法,完成文件夹下文件的内容比对,具体的处理逻辑如图3所示。
commonTools.py包含了一系列公共方法和工具函数,用于辅助文件内容比对。这些方法可以在多个方法中进行重复使用,降低了代码的冗余度,也提高了代码的可维护性和可重用性。parseFile()、prepro⁃cess_text()、cos_similarity()就位于commonTools.py 中,用于文档内容的解析提取、文本分词预处理并转换为向量、计算余弦相似度等。preprocess_text()方法调用jieba.cut()方法对解析的文档内容进行分词,通过Tfid⁃fVectorizer()方法创建TF-IDF 向量化器,通过调用fit_transform()方法将字符串文本转换为向量,调用pairwise.py中的cosine_similarity()直接计算两个向量间的余弦值。
3.2 程序测试
为检测基于余弦相似度的内容比对程序的有效性和实用性,在Windows系统的D盘目录下创建了一个名为test的文件夹,用于存放测试所需的文件。该文件夹中包含了Word文档(.docx,.doc) 、PDF文件(.pdf) 和图片(.png,.jpg) 等多种类型的文件。文档以“模型概述.docx”为基础文档,其内容包含公式、特殊字符等情况,并对不同文件的内容进行了不同程度的删减,同时另存为了多种不同类型的文件,以增加程序测试的可靠性。
接下来,双击similarity.exe文件启动程序,左侧选择一对一比对模式,右侧分别选定两个文件,为“模型概述.docx”和“模型概述-副本.docx”,点击比对按钮。由于文件1是由文件2复制而来,如图4(a) 所示,其检测到的文件内容相似度为100%。另外,程序可支持PDF和Word文档的比对,如图4(b) 所示,分别选择“模型概述.docx”和“模型概述.pdf”,相似度为98.59%,推测原因是格式转变解析内容时稍有偏差,但还是很明显能感受到相似度非常高。
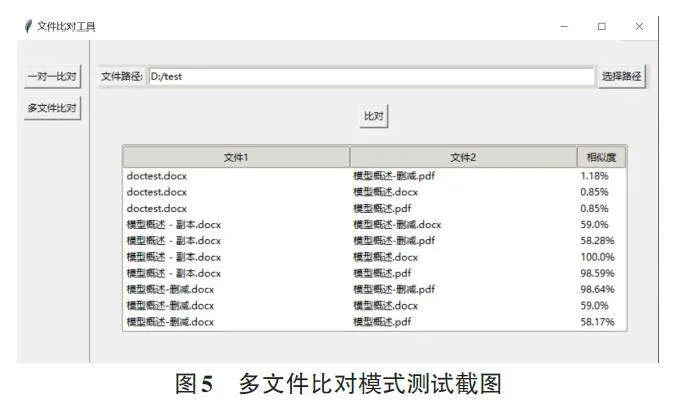
左侧选择多文件比对模式,将右侧选择文件夹路径指定为“D:/test”,点击比对按钮,程序遍历文件夹下的所有文件,遇到png文件等非支持文档时则忽略。运行结果如图5所示,文件夹下的文件进行了两两组合匹配,通过鼠标滚轮滚动,可在结果框中查看所有文件内容的相似度。
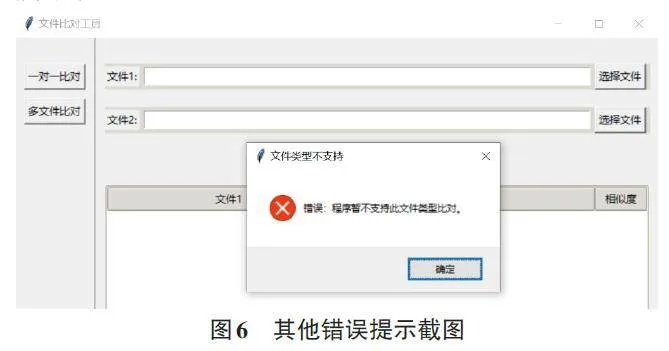
程序对暂不支持的文档类型进行了提示,当选择非Word或PDF文件时,由于程序不支持文件内容的解析,因此提示“程序暂不支持此文件比对”,如图6 所示。
4 总结
本文设计并实现了一种基于Python语言的余弦相似度内容比对程序。该程序通过文档内容解析、数据分词预处理和余弦相似度计算等关键技术,实现了对Word和PDF文档的高效、准确相似度比对。测试结果表明,该程序具有较高的实用价值,可为本地化作业查重提供有力支持。同时,随着内容解析技术和比对算法的逐渐精进,该程序可持续支持更多文件类型的比对。通过进一步优化算法效率,可进行更多应用场景的拓展。
参考文献:
[1] 马智勤,廖雪花,邓威,等.基于分布式ElasticSearch相似内容比对算法研究[J]. 计算机与数字工程,2020,48(12):2843-2849.
[2] 宋玲,马军,连莉,等.文档相似度综合计算研究[J].计算机工程与应用,2006,42(30):160-163.
[3] 张振亚,王进,程红梅,等.基于余弦相似度的文本空间索引方法研究[J].计算机科学,2005,32(9):160-163.
[4] 闫建红,段运会.动量余弦相似度梯度优化图卷积神经网络[J].计算机工程与应用,2024,60(14):133-143.
[5] 石凤贵.基于jieba中文分词的中文文本语料预处理模块实现[J].电脑知识与技术,2020,16(14):248-251,257.
[6] 邓子云.scikit-learn的机器学习流水线技术与应用[J].信息化研究,2020,46(2):53-57.
[7] SHIHAB E,JING Y.Sentiment Analysis of Twitter Data Using Machine Learning Techniques and Scikit-learn[C].Sanya:2018International Conference on Algorithms,Computing and Artifi⁃cial Intelligence (ACAI 2018),2018.
[8] 武永亮,赵书良,李长镜,等.基于TF-IDF和余弦相似度的文本分类方法[J].中文信息学报,2017,31(5):138-145.
【通联编辑:谢媛媛】
