
面向流程偏差根因分析的港口物流流程挖掘方法及应用
2024-11-04 00:00:00蔡敏王学涛宋容嘉刘聪雒兴刚黄磊
计算机应用研究 2024年9期





摘 要:
港口物流是一种高度以人为中心、复杂灵活的业务流程。现有研究对其进行流程挖掘时,存在自动发现流程模型质量低的问题,同时缺少对于流程偏差进行系统化根因分析的支持,这造成港口流程偏差分析能力较弱。针对这一问题,提出一种面向流程偏差根因分析的港口物流流程挖掘方法。该方法基于事件日志进行港口物流活动统计实现流程绩效分析,使用Split Miner和Inductive Miner发现实际流程模型,并使用对齐方法识别流程偏差,接着结合分类决策树和桑基图对流程偏差进行根因分析。通过在某大型港口物流提货流程进行实际应用,结果表明,应用该方法能发现实际执行流程的更多细节来为流程偏差根因分析提供支持,并可以对流程偏差进行系统化的根因分析。该方法强化了港口物流流程偏差分析能力,进而降低了港口物流管理风险。
关键词:流程挖掘;流程发现;一致性检查;根因分析;港口物流
中图分类号:TP399 文献标志码:A 文章编号:1001-3695(2024)09-018-2690-09
doi:10.19734/j.issn.1001-3695.2023.12.0622
Port logistics process mining method and application towards root cause analytics of process deviations
Cai Min1, Wang Xuetao1, Song Rongjia1, Liu Cong2, Luo Xinggang1, Huang Lei3
(1.Experimental Center of Data Science & Intelligent Decision Making, School of Management, Hangzhou Dianzi University, Hangzhou 310018, China; 2.School of Computer Science & Technology, Shandong University of Technology, Zibo Shandong 255000, China; 3.School of Economics & Management, Beijing Jiaotong University, Beijing 100044, China)
Abstract:
Port logistics is a highly human-centered, complex and flexible business process. Existing research on process mining has the problem of automatically discovering low quality process models, and lacks support for systematic root cause analysis of process deviations, which results in a weak ability to analyze process deviations in ports. To address this issue, this paper proposed a process mining method framework for root cause analysis of process deviation in port logistics. The method was based on event logs for port logistics activity statistics, used Split Miner and Inductive Miner to discover the actual process model, used the alignment method to identify the process deviation, combined the classification decision tree and Sankey diagram to conduct root cause analysis on process deviations. Through the practical application in a large port logistics pick-up process, the results show that the method can discover more details of the actual execution process to provide support for the root cause analysis of process deviation, and carry out a systematic root cause analysis of process deviation. The method strengthens the capability of analyzing process deviations in port logistics, which in turn reduces the risk of port logistics management.
Key words:process mining; process discovery; conformance checking; root cause analysis; port logistics
0 引言
港口物流是经济全球化的重要组成部分,这对物流流程的高效、安全运行提出了更高要求[1]。随着信息技术的快速发展,港口企业根据业务需求,依靠港口业务中的一线员工、管理者和领域专家,开发出了对应的港口物流信息管理系统,用于支持港口物流的运营[2]。虽然港口物流通常有着一套标准的执行流程,但实际港口物流面临着业务流程灵活、业务类型繁多和客户需求多样等问题[3],这使得港口物流信息系统需要具备一定的灵活性来应对各种情况,然而信息系统中的标准流程往往和实际执行流程之间存在偏差,这些偏差会带来一系列管理风险[4]。例如,据中华人民共和国海事局发布的事故案例显示,2021年1月4日,出港船O轮与进港船A轮在航行时因违反信息系统中的出入港标准流程而发生碰撞,事故造成直接经济损失355万人民币,而引航员违规下达操作指令是造成这一流程偏差的原因之一[5]。目前,港口物流中流程偏差发生的原因很难人工发现并进行分析,如何有效地分析港口流程偏差发生的原因以降低港口的管理风险已经成为从业者关注的焦点[6,7]。
流程挖掘技术可以从事件日志中获取流程知识,能够发现实际执行流程、识别流程中的瓶颈和偏差、预测和检查一致性问题,为发现和改进各种应用领域中的流程提供了新的手段[8]。
近年来,一些研究将流程挖掘技术应用在港口物流领域,这些研究主要涉及对港口物流流程进行流程发现、绩效分析和一致性检查。例如:Veenstra等人[9]使用Heuristic Miner算法发现船舶实际到港流程,并选择绩效指标进行绩效分析,改进了到港流程中的绩效瓶颈;Zerbino等人[10]使用Fuzzy Miner算法发现港口实际货运出口流程,分析影响港口货运出口时间性能的因素;Wang等人[11]考虑到港口物流的复杂性和灵活性会导致流程存在各种问题,提出了一种典型的港口物流流程挖掘方法。该方法分四个阶段:第一阶段从物流信息系统中进行事件日志提取和预处理;第二阶段从事件日志中自动发现流程模型来分析实际物流流程,该阶段使用Fuzzy Miner、Heuristic Miner算法;第三阶段对事件日志进行物流流程绩效分析来揭示流程瓶颈及其影响因素;第四阶段使用基于轨迹重放的一致性检查方法来详细诊断出实际物流流程和标准流程之间的偏差。
以上研究表明流程挖掘对港口物流流程优化有很好的适用性,但已有研究在港口物流流程偏差根因分析方面仍然存在显著不足。一方面,港口物流结构松散和动态的性质使得港口物流流程数据具有高复杂性,已有研究在挖掘流程模型时,使用的Fuzzy Miner、Heuristic Miner算法会将低频但关键的路径作为噪声过滤掉,发现低质量的流程模型[12],而这些低频路径会影响人们对实际流程问题的发现和根因分析[13]。因此有必要在不丢失关键细节的情况下发现高质量的流程模型,能够更准确地分析港口物流流程中存在的问题。另一方面,港口物流活动受多种因素影响,对流程中的异常需要根据其原因采取对应的处理方式[14]。已有方法虽然能够检测出港口物流中实际流程和标准流程之间的偏差,但并不能系统化地分析出复杂流程偏差发生的原因。因此有必要对港口物流中的偏差流程进行系统化的根因分析,根据原因制定能有效降低流程风险的优化方案。
虽然目前的港口物流信息系统无法反映实际港口物流流程的多样性、复杂性和灵活性,但信息系统中海量的数据积累,为本文基于数据层面分析港口物流流程提供了研究基础。因此,为了解决上述问题,本文提出一套数据驱动的面向流程偏差根因分析的港口物流流程挖掘方法,实现对港口物流流程偏差进行系统化的根因分析,以支持港方企业可以根据流程偏差原因制定能够有效降低流程风险的优化方案。
本文主要贡献为:
a)提出了一套面向流程偏差根因分析的港口物流流程挖掘方法。该方法可以通过港口物流流程绩效分析和港口物流流程模型自动发现,为流程偏差根因分析提供支持,并在港口物流流程一致性分析诊断出流程偏差后,通过港口物流流程偏差根因分析对具体流程偏差进行系统化的根因分析,进而提出改进港口物流流程的建议。
b)在港口物流流程模型自动发现阶段,为了更准确地支持港口物流实际流程问题的发现和根因分析,提出使用Split Miner[13]和Inductive Miner[15]算法以挖掘出高质量的港口物流流程模型,便于分析实际流程执行细节。
c)在港口物流流程偏差根因分析阶段,综合考虑分类决策树和桑基图分析的特点,提出使用分类决策树分析港口物流流程中部分属性值和流程偏差的关系,并使用桑基图分析港口物流流程在任意属性值间的转换趋势,用于获得使用决策树进行分析的隐藏见解,进行流程偏差根因分析。
d)将本文方法应用到国内某大型港口,并与现有方法进行对比,验证了本文方法的有效性和科学性。
1 相关研究
1.1 流程挖掘相关算法研究
流程挖掘已有大量研究,并且产生了许多算法,当前针对流程挖掘算法的研究主要分为流程模型发现、流程模型改进和流程知识挖掘。本文主要关注其中的流程模型发现算法和流程模型改进算法。
流程模型发现是指在没有任何先验信息的情况下,从记录流程行为的事件日志中生成实际的流程模型[16]。已有研究提出了多种用于流程发现的算法,如Split Miner、 Inductive Miner、 Heuristic Miner[17]和Fuzzy Miner[18]。当事件日志记录的流程行为结构简单时,Heuristic Miner 和Fuzzy Miner能够输出简单且准确的流程模型;然而随着数据复杂性的增加,这些算法生成的模型质量会迅速恶化[19,20]。为了避免丢失信息,同时保留可解释的结构,改进的流程发现算法Split Miner和Inductive Miner可以更好地处理蕴涵复杂流程的事件日志,能够发现低复杂度、高拟合度和高精确度的流程模型[12,20]。
流程模型改进需要输入事件日志和标准流程模型,目标是指出事件日志和标准模型不一致的地方并进行模型优化[8,21]。Rozinat等人[22]提出基于轨迹重放的一致性检查方法,流程模型表示为Petri网,事件日志中的轨迹在模型上重放,根据重放过程中缺失和剩余的token计算一致性,但没考虑最优对齐。文献[23]提出基于对齐的一致性检查方法,日志中的每个轨迹都映射到尽可能接近观察到的模型行为,检查结果显示了跳过和插入的事件,可以在事件级别观察流程偏差,这种方式比缺失和剩余的token更容易解释。对齐通常被视为标准的一致性检查技术,但在大型事件日志上计算对齐是比较耗时的[8],现有研究已经提出了更高效的一致性检查方法,如沈晓林等人[24]将流程模型转换为流程树模型并将流程树分解为子树,利用分布式平台Spark计算最优对齐。
1.2 流程问题根因分析方法研究
在流程挖掘领域已有许多研究致力于寻找流程问题的根本原因。Suriadi等人[25]将事件日志转换为适合分类分析形式的数据,然后使用数据挖掘中的决策树方法来发现影响流程实例类别的关键属性;Ferreira等人[26]将事件日志转换为逻辑表示,然后根据流程时间对流程实例进行分类并用决策树提取规则,产生的规则用于解释流程实例延迟的原因;Bozorgi等人[27]使用动作规则挖掘技术来识别在某些条件下与结果同时出现的处理,然后使用提升树来发现在调整混杂变量后处理对结果的影响;Qafari等人[28]通过寻找对问题贡献最大的一组特征和特征值对来确定有因果影响的特征,然后建立结构方程模型,并在模型上对特征集进行因果推理。
在以上根因分析方法中,分类决策树能够从事件日志中提取知识并以决策规则(if-then)的形式来匹配流程部分属性和类别之间的关系,是一种可解释性较强的分析工具[29]。经典的决策树算法包括ID3、CART、C4.5和C5.0,其中C5.0具有更高的识别关键分类变量能力和预测准确性,并呈现适当的决策规则。使用决策树分析具体有以下优点:a)决策树易于理解和解释,通过解释后人们有能力理解决策所表达的意义,同时,可以进行可视化分析,容易提取规则;b)决策树对于数据的准备比较简单,并可同时处理连续型和离散型的数据;c)运算速度相对比较快,在相对短的时间内能对大型数据源作出可行且效果良好的结果;d)可以对有许多属性的数据集构造决策树,且冗余的属性不会影响决策树的准确性。
机器学习技术通过描述性特征来解释目标特征,无论模型的准确性如何,总会有不精确分析的风险[30]。而且仅根据分类器的发现来判断特征之间的因果关系,可能会陷入将相关性视为因果关系的陷阱[28]。
综上所述,本文通过对流程挖掘相关算法(流程发现、一致性检查)和流程问题根因分析方法的比较分析发现,考虑到港口物流流程数据的复杂性,改进的流程发现算法(Split Miner、Inductive Miner)可用于挖掘高质量的港口物流流程模型,发现更多流程细节来支持流程偏差根因分析;分类决策树具有可解释性强等优点,可用于进行流程偏差根因分析,但该方法仍存在一些缺陷。这些发现进一步明确了相关方法对解决本文研究问题的适用性与缺陷,为后续构建面向流程偏差根因分析的港口物流流程挖掘方法提供了理论基础。
2 面向流程偏差根因分析的港口物流流程挖掘方法
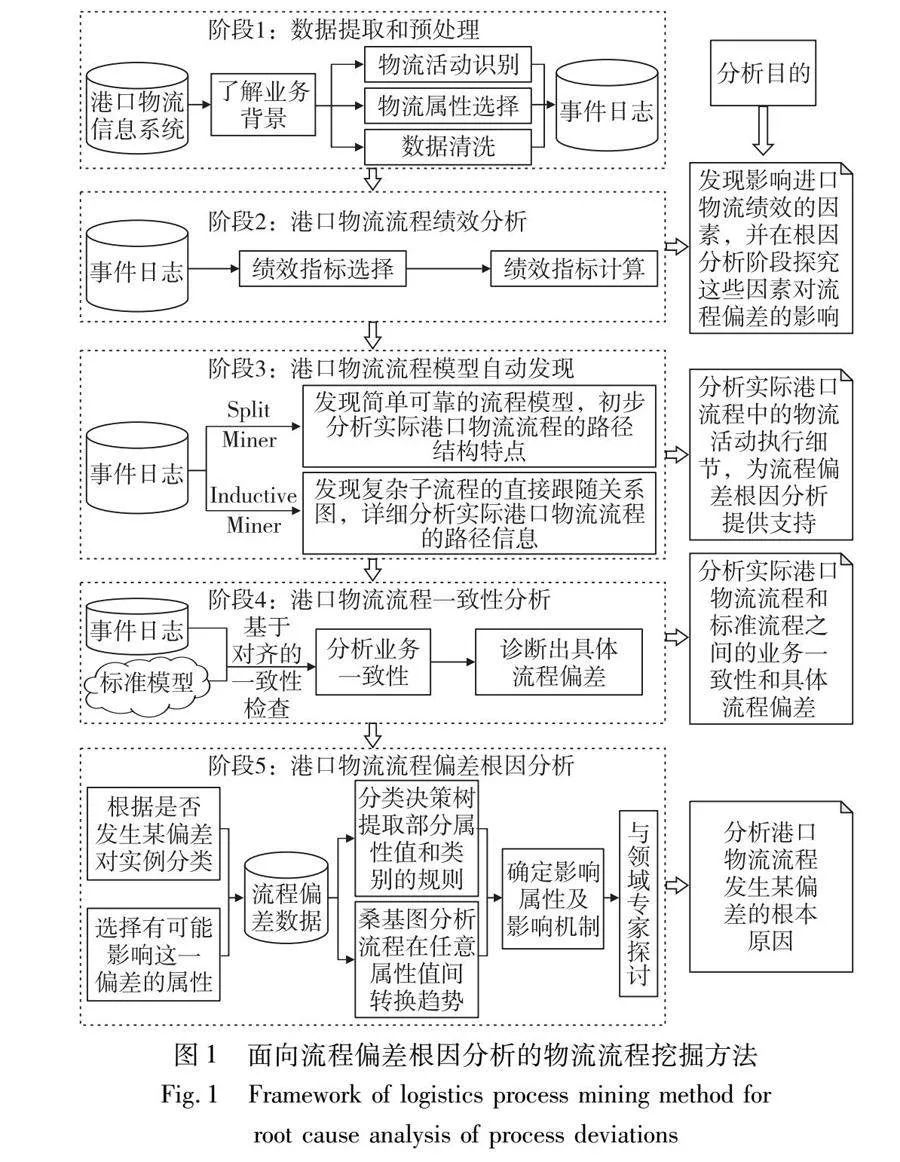
本章针对引言部分提到的已有研究在港口物流流程偏差根因分析方面的不足,基于相关方法,为解决本文研究问题的适用性与缺陷提出了一种面向流程偏差根因分析的港口物流流程挖掘方法(图1)。该方法分为数据提取和预处理、港口物流流程绩效分析、港口物流流程模型自动发现、港口物流流程一致性分析和港口物流流程偏差根因分析五个阶段,其步骤将在2.1~2.5节中进行介绍。
2.1 数据提取和预处理
由于大多数港口物流信息系统的关注点往往在于实现物流流程的自动化,不是标准的工作流系统,通常没有现成的事件日志。本阶段进行以下操作获取有效的事件日志:
a)物流活动识别。信息系统中,一个完整流程中多个物流活动的实际执行信息会保存在多个表中,可以根据表之间的字段依赖关系将流程中的物流活动识别出来。
b)物流属性选择。除了基本的活动名称、时间戳等信息外,也可以根据分析目的选取其他流程属性,如货物类型、活动执行人等,为进行流程偏差根因分析提供支持。
c)数据清洗。提取数据并处理成事件日志后,需要清洗事件日志以满足挖掘算法要求,例如,剔除不完整的流程实例,填补和修改缺失值和异常值,剔除明显错误的记录等。
2.2 港口物流流程绩效分析
本阶段的主要目的是发现实际港口物流流程中影响物流绩效的因素,并在后续流程偏差根因分析中考虑将这些因素转换为实例属性,并探究其对流程偏差的影响。
绩效分析包括流程瓶颈识别和性能比较等,进行绩效分析有助于分析物流流程的流程偏差等异常和持续优化业务流程[31]。港口物流的动态性会导致物流绩效受多种因素影响,物流活动分析可以找出各种因素对物流绩效的实际影响[11,32]。本阶段通过以下步骤对物流流程进行绩效分析:
a)根据应用场景中的问题背景选择物流绩效指标;
b)统计事件日志中的相关物流活动进行绩效指标计算,分析影响物流绩效的因素,并讨论这些因素对流程偏差可能产生的影响。
2.3 港口物流流程模型自动发现
本阶段的主要目的是发现事件日志中蕴涵的港口物流流程,通过获得不同抽象级别的流程模型,分析实际港口流程中物流活动的执行细节,为流程偏差根因分析提供支持。
流程发现经常从事件日志中生成控制流模型,可用于分析实际流程中物流活动的执行顺序。港口物流流程数据具有高复杂性,已有研究使用的流程发现算法会挖掘出低质量的流程模型,从而影响实际港口物流流程问题的发现和根因分析。为了解决这一问题,本文通过对流程发现算法的对比分析,提出可以结合Split Miner和Inductive Miner来挖掘出高质量的港口物流流程模型。因为,Split Miner能够:a)处理根据事件日志生成的直接跟随图中相邻节点之间的并发性、冲突和因果关系,保证发现无死锁的流程模型;b)从复杂事件日志中过滤掉无效路径,快速发现复杂性低的控制流模型,同时最大化地平衡流程模型的拟合度和精确度。Inductive Miner能够处理复杂的事件日志,对事件日志中的不完全性、噪声和低频路径具有鲁棒性,生成的直接跟随图模型具有高可解释性。港口物流流程模型自动发现具体步骤如下:
a)先用Split Miner从整个事件日志中发现简单可靠的流程模型,初步分析实际港口物流流程主要路径的结构特点;
b)针对上一步发现的流程模型中的复杂子流程,用Inductive Miner从事件日志中发现直接跟随图,详细分析实际港口物流流程的路径信息。
2.4 港口物流流程一致性分析
本阶段的主要目的是分析实际港口物流流程和标准流程之间的业务一致性和具体流程偏差,并对主要流程偏差进行讨论。
流程一致性分析旨在全面检测出实际流程和标准流程之间不一致的地方。一致性分析需要输入事件日志和标准流程模型,选择度量指标(例如拟合度)来量化二者之间的业务一致性,并分析存在的流程偏差。本阶段使用基于对齐的一致性检查方法[23]分析实际港口物流流程和标准流程之间的业务一致性。对齐将事件日志与标准模型的执行流程连接起来(表1),表1第一行表示事件日志中某一实例中事件的执行流程或>>,第二行表示标准模型执行流程或>>,表中的每一列就是对齐的一个移动,分为以下三种:
a)同步移动,实例轨迹中的事件和模型流程中的事件一致,如(a, a),表示实例和模型流程以相同的方式执行。
b)日志移动,实例轨迹的一个事件表明一个活动应该被执行,但依据模型该活动不能被执行,如(b, >>),表示实例和模型之间存在偏差。
c)模型移动,一个活动依据模型应该被执行,但实例轨迹中没有相应的事件,如(>>, c),也表示实例和模型之间存在偏差,模型中的活动被跳过。
表1所示只是一种可能的对齐,对于相同的实例轨迹和模型流程,可能存在很多对齐。一致性检查是基于最优对齐,即尽可能以最少的偏差将实例轨迹和模型流程连接起来的对齐。该方法可以针对每个实例提供详细的诊断,指出某个特定的活动经常被跳过,能在事件级别分析具体流程偏差。
2.5 港口物流流程偏差根因分析
本阶段的主要目的是分析港口物流流程发生某偏差的根本原因,为相关部门根据原因制定针对性的优化方案提供支持。
一些流程偏差的发生可能是多种因素的结果,需要对其进行系统化的根因分析。港口物流活动受多种因素影响,已有研究并不能系统化地分析出复杂流程偏差发生的根本原因。为了解决这一问题,本文通过对根因分析方法的对比分析,提出分类决策树可以用于港口物流流程偏差根因分析,因为决策树具有可解释性强等优点,已被广泛应用于从事件日志中提取部分属性值和类别的组合规则来分析异常流程的原因。但仅发现部分属性值和类别的关系进行根因分析存在不精确分析的风险[30]。而桑基图可用于分析复杂的多步骤流程,因为桑基图能够可视化流程在任意属性值上的数据流向,显示流程从一种属性值转换到另一种属性值的可能性和可变性[33]。在进行港口物流流程偏差根因分析时,为了确保根因分析结果的可靠性和完整性,提出用桑基图进一步分析流程实例在任意属性值间的转换趋势,用于获得使用决策树进行分析的隐藏见解。港口物流流程偏差根因分析的具体步骤如下:
a)流程偏差数据准备。确定所要分析的流程偏差,从事件日志中根据对应流程活动发生的时间戳大小对流程实例进行分类(正常/偏差),并提取可能影响这一流程偏差的属性,整合类别数据和属性数据形成流程偏差数据。
b)用C5.0算法挖掘流程偏差数据的分类决策树模型,用于提取流程实例部分属性值和类别之间的规则。
c)绘制流程偏差数据的桑基图,用于分析流程实例在任意属性值间的转换趋势。
d)结合步骤b)c)的分析结果,确定流程偏差的影响属性及影响机制,在此基础上与港口物流管理人员进行探讨,系统化地分析流程偏差发生的根本原因。
3 案例分析
本文以国内某大型港口为例进行方法验证和案例分析。该港口的物流信息系统自2009上线以来,保持24 h不间断运行,记录了港口进出口业务流程中各物流活动的发生时间、货物属性等丰富数据,平均每秒钟都会产生一条新数据。这些累积的海量数据,是应用本文方法进行流程偏差根因分析的重要基础。
在该港口的整个物流流程中,货物装卸服务是其核心业务,主要是指货物通过大船卸到港口和客户通过车、卡、驳的方式进行提货,将货物运出港口,其中实际提货流程涉及到的人员广、活动多、凭证单据复杂,流程具有复杂灵活的特点。相关研究指出,该港口的实际提货流程和港口物流信息系统中的标准流程经常出现偏差。例如,部分流程实例在没有确保所有单据计费流程终止的条件下,就进行出库单完单,这存在管理风险[2,6]。因此,本文以该港口的提货流程进行方法验证和案例分析。
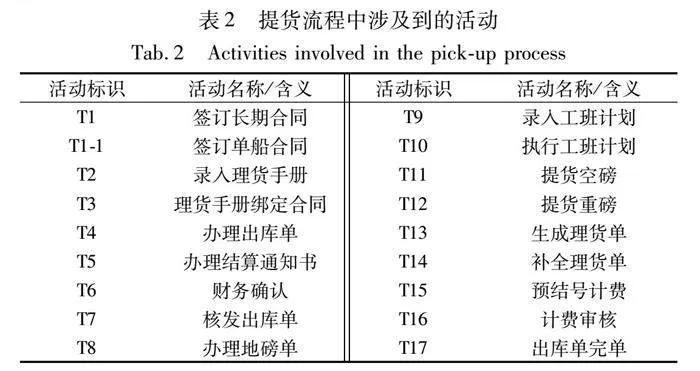
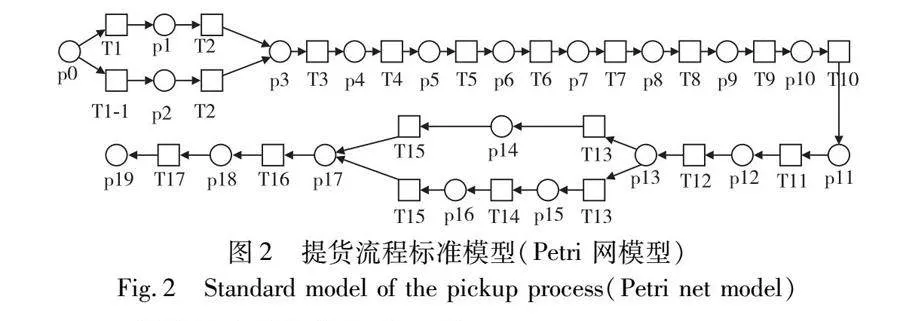
表2提供了该港口提货流程涉及到的活动(从签订长期/单船合开始,到出库单完单结束),图2是提货流程的标准模型。
3.1 提货流程数据提取和预处理
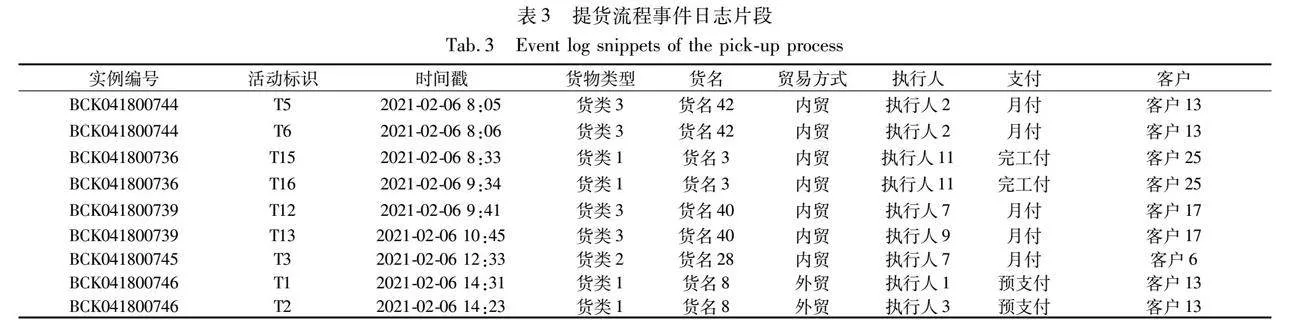
提货流程中涉及到的物流活动信息存在于该港口物流信息系统的各种物流单据中(如出库单、地磅单等),这些单据中都有出库单号这一字段,可以根据出库单号从这些单据中识别出流程活动,并以出库单号作为流程的实例编号。在这一阶段,选择的活动属性除了活动标识和时间戳外,还包括货物类型、货名、贸易方式、执行人、支付方式和客户。由于港口数据保密,对部分活动属性值进行匿名化。为了分析的可靠性,需要剔除不完整流程实例和填补缺失值,最终事件日志有1 622个流程实例。表3展示了事件日志片段。
3.2 提货流程绩效分析
在这一阶段,使用Disco对提货流程进行绩效分析。港口物流作为一项劳动密集型任务,港口资源的预测不佳或规划不当会对港口物流流程造成影响[34]。基于此,本文案例选择提货流程中不同时间的事件发生个数、不同货类的流程实例持续时间作为绩效指标进行分析。
1)不同时间的事件发生个数
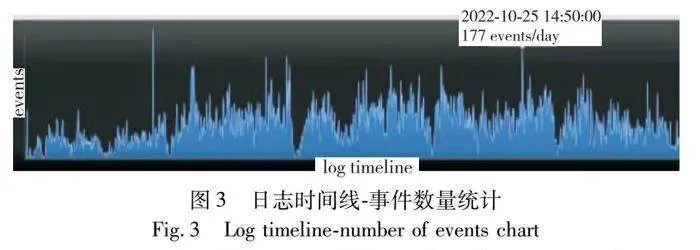
提货流程具有灵活性,不同时间事件发生个数可能会有所不同,分析事件发生个数随时间的变化规律有助于帮助港口提前进行相应的资源调整。图3展示了不同时间的事件发生个数。
图3表明在日志时间线(横轴)同事件数量(纵轴)建立的空间矩阵中会规律性地出现顶峰,例如有几处顶峰分别发生在2022-10-25、2022-11-28、2022-12-27,由此可推测每月月末是流程事件发生的高峰期。考虑到整个提货流程需要人工确认各种文件以保障流程的有序进行,在每月月末,业务量的加大会增加执行人的作业压力,可能出现因办单不及时造成流程拥挤和流程偏差等问题。
2)不同货类的流程实例持续时间
实际提货流程中不同流程实例的持续时间有较大差异,且由于签订合同或付费活动的持续时间不太具有参考价值,所以选择T2~T14这一子流程的持续时间进行分析。该子流程所有实例的平均持续时间为64天,由于货类对货物的存储期和装卸效率有很大影响,研究了该指标超过64天的实例的主要货类分布,结果如表4所示。
表4表明货类1和4的实例持续时间超过平均时间的相对比率较低,说明这些货类的实例持续时间普遍较短,而货类2和3的实例在港口停留时间较长。这一现象也可能与流程偏差有关,需要后续进行流程偏差根因分析才能进一步洞察。
3.3 提货流程模型自动发现
在这一阶段,分别对实际提货流程的主要模型和复杂子流程的详细模型进行自动发现,分析实际提货流程中的物流活动执行细节,为后续流程偏差根因分析提供支持。
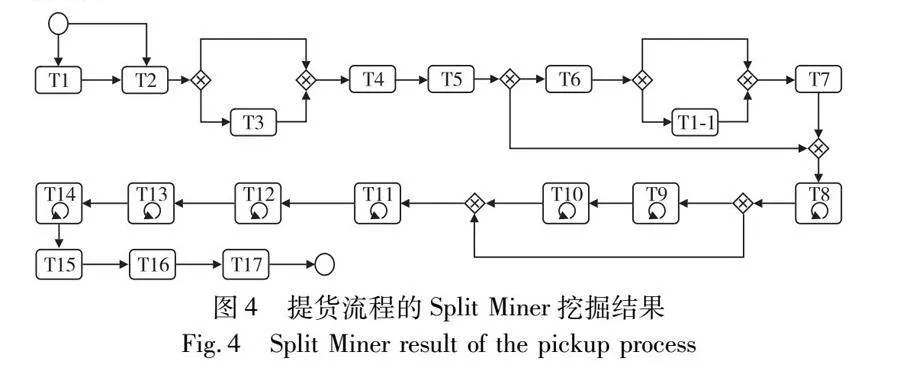
a) 首先用ProM中的Discover BPMN model with Split Miner插件发现主要的控制流模型(图4说明:为了显示的紧凑性,对模型布局进行了调整)。可以发现,实际提货流程中的物流活动执行路径基本符合标准模型,但T1~T14的子流程存在分支和自循环路径。这些路径增加了流程的复杂性。
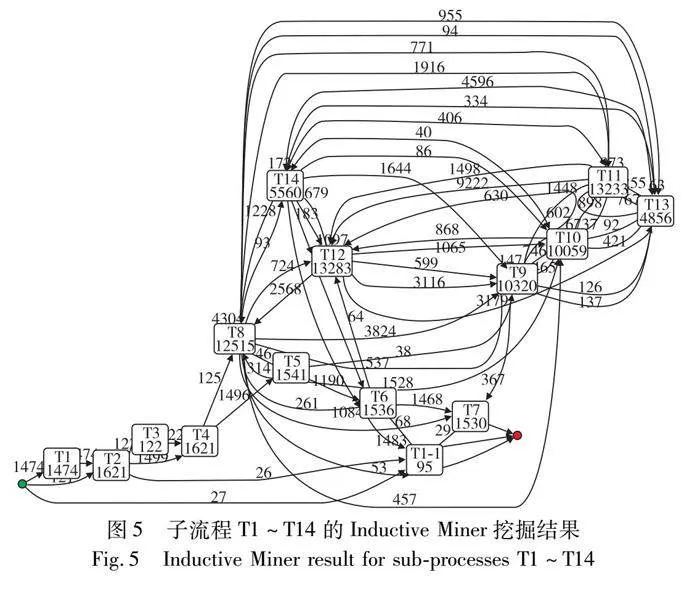
b) 进一步用ProM中的Mine with Directly Follows visual Miner插件详细分析T1~T14的子流程,图5是发现的直接跟随图(设置显示80%的路径),其中,绿色和红色圆圈分别代表流程开始和结束(参见电子版),每个节点代表流程中的一种活动,边代表活动间的路径关系,数字代表活动或路径的发生次数。可以发现,不同活动及活动之间的路径执行次数存在差异,也存在一些低频路径不符合标准模型的情况。这些信息反映了实际提货流程的灵活性,对其进行分析有助于更好地了解实际流程执行情况。
结合图4、5,本文对实际提货流程中的物流活动执行情况进行以下分析:
a)实际提货流程主要起始于“T1→T2”这一分支。图4表明实际流程主要起始于“T1签订长期合同”或“T2录入理货手册”,且后续整个提货流程基本符合标准模型;图5进一步表明有1 474个实例起始于T1,只有27个实例起始于“T1-1签订单船合同”。对于共享同一长期合同的实例,会在开始时直接使用已有的合同,否则需要到港后重新签订,签订合同是流程起始环节,不及时签订合同可能会影响后续提货流程,造成流程拥挤。
b)“T3理货手册绑定合同”未能正常进行。图4表明流程实例存在跳过T3的情况;图5进一步表明只有122个实例进行T3。结合提货流程实际场景得知,进行该活动是为了“T7核发出单”时使用合同信息,不进行T3不影响T4~T6,港口为了方便通常允许在T7前绑定合同到出库单,这反映了实际提货流程的灵活性。
c)实际提货流程主要执行“T13→T14→T15”这一分支。图4表明“T8办理地磅单”至“T14补全理货单”之间的活动会多次有序执行;图5进一步表明一个流程实例平均需要8次过地磅活动,其主要执行顺序为“T8→T9→T10→T11→T12→T13→T14”,同时也存在分支和自循环的情况。与港口物流管理人员讨论得知,出库单经过核发后,一般会分单为多个地磅单通过车、卡、驳的方式同时进行提货作业,但每个地磅单的作业顺序是固定的,这期间生成的多个理货单需要多次进行T14。
上述分析了实际提货流程在符合标准流程模型下的物流活动执行情况。此外,实际提货流程模型(图5)中的一些其他路径,如“T4→T8”“T5→T8”“T6→T1-1→T7”等,表明实际流程存在偏离标准模型的情况,后续需要进行全面的流程一致性分析。
3.4 提货流程一致性分析
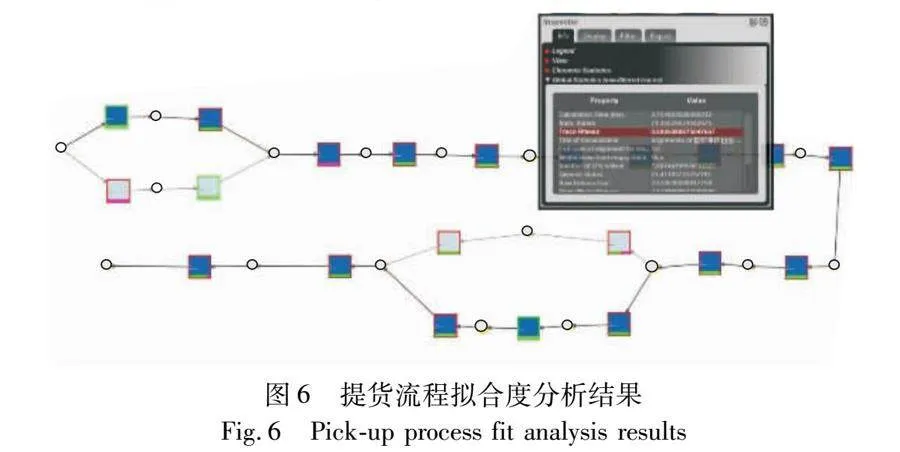
在这一阶段,使用ProM中的Replay a Log on Petri Net for Conformance Analysis插件分析实际提货流程和标准流程之间的业务一致性和具体流程偏差,该插件需要输入提货流程事件日志和标准模型(图2),结果显示二者间的拟合度为0.808 5(图6),这表明大部分流程实例与标准模型还是匹配的,但仍有小部分偏差。
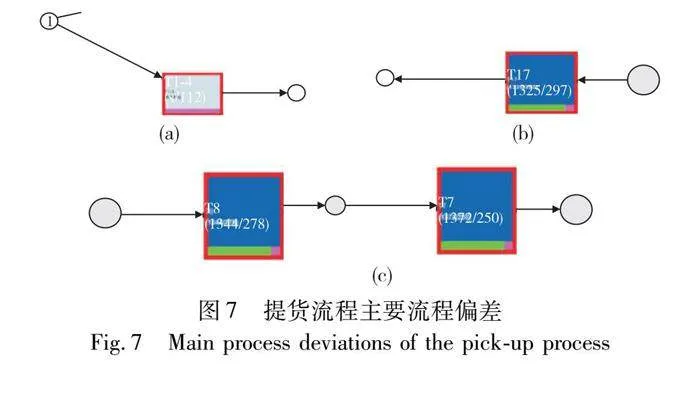
根据一致性分析的结果,对存在的主要流程偏差进行分析。由于3.3节已经分析了活动T3的相关偏差,本节不再对其进行探讨。提货流程中的主要流程偏差如图7所示,图7(a)~(c)分别代表三处流程偏差,每张图中,活动编号代表流程偏差发生的位置,左边的数字代表发生日志移动(提货流程实例表明活动被执行,但依据标准模型该活动不能被执行)的数量,右边的数字代表发生模型移动(提货活动依据标准模型应该被执行,但提货流程实例中没有相应的事件)的数量。这些信息可以针对每个提货流程实例提供详细的流程诊断,能够分析具体提货活动的流程偏差,具体分析如下:
a)图7(a)表明T1-1发生113次模型移动,即提货流程事件日志的轨迹中“T1-1签订单船合同”被跳过113次。通过调研得知,单船合同需要每次到港后签订且需要很长时间,导致合同不能及时签订,实例在等待签订合同期间会选择执行后续与合同无关的活动。
b)图7(b)表明T17发生297次模型移动,即提货流程事件日志的轨迹中“T17出库单完单”被跳过297次。T17是流程结束环节,不进行该活动会影响信息系统中流程实例执行的完整性。通过检查港口物流信息系统得知,T17虽然作为流程规定的结束,但是不影响客户进行实际提货作业,而且系统也没有控制必须去执行这个活动。
c)图7(c)表明T6、T7分别发生278、250次模型移动,即提货流程事件日志的轨迹中“T6财务确认”被跳过278次,“T7核发出库单”被跳过250次。与港口管理人员探讨后得知,这可能与流程实例先执行“T8办理地磅单”,后执行“T7核发出库单”有关,而地磅单是通过对出库单的结存进行消减才能办理的,出库单未经核发不能作为凭证办理地磅单,否则会加大后面的工作量,从而降低流程的效率并增加流程的管理风险。考虑到会有多种因素造成这一现象,本案例将在3.5节中对这一偏差进行系统化的根因分析。
3.5 提货流程偏差根因分析
3.4节c)中反映出实际提货流程中有相当一部分流程实例存在先办理地磅单后核发出库单这一流程偏差,本阶段对该流程偏差进行系统化的根因分析。
1)流程偏差数据准备
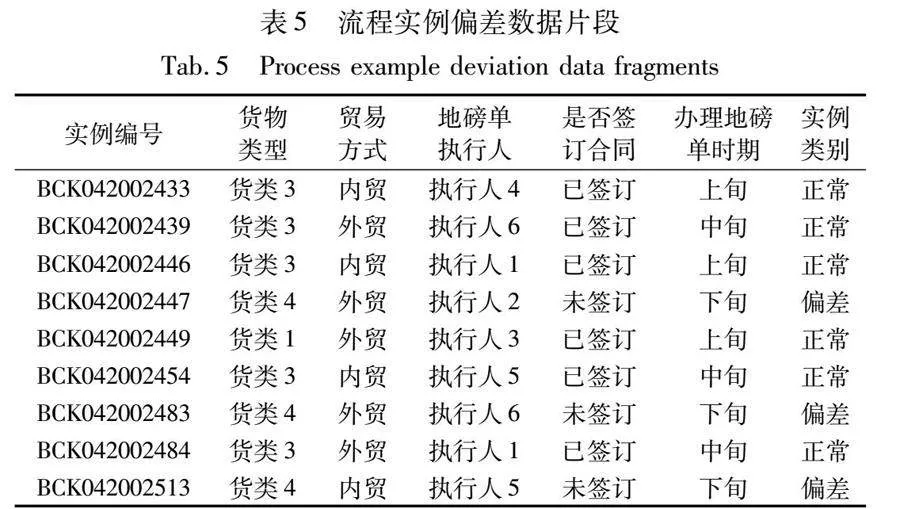
首先,在事件日志中根据核发出库单和办理地磅单的时间戳大小对流程实例进行分类(正常/偏差)。其次,通过与港口物流管理人员进行探讨,选择可能影响这一流程偏差的属性,如表3中已有的属性:货物类型、贸易方式、地磅单执行人。另外结合3.2节a)中发现每月月末是流程事件的高峰期和3.4节a)中发现部分流程实例未能及时签订合同,这两个因素也可能造成本节所要分析的流程偏差。因此,从事件日志中生成两个新属性:办理地磅时期(上旬:每月1~10日、中旬:每月11~20日、下旬:每月21~31日)和流程实例在核发出库单时是否已经签订合同(已签订、未签订)。最后,整合类别数据和属性数据,得到流程实例偏差数据(表5)。
2)分类决策树分析
使用IBM SPSS Modeler 18.0的C5.0算法挖掘流程偏差数据的决策树模型,用于提取实例部分属性和类别之间的规则。考虑到数据中类别为“偏差”和“正常”实例数相差较大会影响决策树分类,本文案例选择了所有的449个类别为“偏差”实例,随机抽取了600个类别为“正常”实例,最终决策树模型(图8)具有较高的精确度(79.89%),表明流程的属性值组合与类别有关。其描述的属性值和类别之间的关系可以转换为一系列规则(表6)。
3)桑基图分析
使用可视化工具RAW Graphs 2.0绘制流程偏差数据的桑基图,用于分析提货流程实例在任意属性值间的转换趋势。本文案例分析了流程实例在货物类型、是否签订合同、地磅单执行人、实例类别间的桑基图(图9)。其中桑基图由节点和路径组成,数据由左边节点流向右边节点,每个节点和路径的宽度分别表示经过节点和路径流量的大小。
图9(a)左部路径的宽度表明相比于其他货物类型的实例,货类1和4的实例有更大比例在核发出库单时尚未签订合同;中间节点的宽度及右部路径的宽度表明大部分实例在核发出库单时已经签订合同,未签订合同的实例比已签订合同的实例有更大比例出现流程偏差。
图9(b)左部路径的宽度表明相比于其他货物类型的实例,货类1和4的实例有更大比例经由执行人2和4办理地磅单;右部路径的宽度表明经由执行人2和4的实例比其他执行人的实例有更大比例出现流程偏差。
4)确定原因
决策树发现办理地磅单时期、货物类型和地磅单执行人的部分属性值组合与实例发生偏差有关系,但并不清楚这些属性值间的转换关系。结合桑基图的结果作进一步分析,桑基图表明流程实例在“货物类型→是否签订合同→实例类别”和“货物类型→地磅单执行人→实例类别”的转换过程中,不同属性值间的转换趋势有所不同。
因此,可以确定办理地磅单时期、货物类型、地磅单执行人和是否签订合同这些属性及影响机制会造成流程实例出现“T7核发出库单”和“T8办理地磅单”执行顺序的偏差。结合决策树和桑基图的结果,通过和港口物流管理人员探讨,进一步明确该流程偏差发生受以下因素的叠加影响:
a)每月下旬是各种流程事件的高峰期,核发出库单需要一定时间,业务量的加大会造成不能及时核发出库单,并产生流程拥挤;而货物类型为货类1和4的实例需要更短的物流周期,客户想通过一次到岗就办理所有业务;并且地磅单执行人2和4更容易在办理地磅单时没有严格审核是否已经核发出库单。大部分实例在以上情况下更容易出现T7和T8执行顺序的偏差。图4和5也表明这种偏差主要发生在流程执行T4或T5之后,就执行T8。
b)签订单船合同需要每次到港后进行且需要一定时间,而核发出库单需要合同内容,办理地磅单则不需要,图4和5也表明T1-1通常发生在T7之前,只有少量实例执行“T1-1→T2”这一路径。这导致有快速办单需求(货类1和4)的实例更可能出现未签订合同的情况,而实例未签订合同通常会造成T7和T8执行顺序的偏差。
c)有快速办单需求(货类1和4)的客户和部分地磅单执行人(执行人2和4)业务往来比较频繁,这部分执行人更容易出现审核不严的情况,造成实例出现T7和T8执行顺序的偏差。
4 讨论
4.1 案例讨论
案例分析表明,本文方法能够准确发现港口物流提货流程存在的问题,并能分析出发生流程偏差的根本原因。本章对从案例中获得的见解进行以下讨论。
4.1.1 港口物流的拥挤问题
港口物流存在拥挤问题,一方面是由于港口资源配置不合理,无法满足高峰需求,这符合已有研究[11,34];另一方面,通过自动发现能够还原更多流程行为的控制流模型,本文发现部分提货流程设计不合理也会造成拥挤。
a)提货流程绩效分析发现每月下旬是各种流程活动发生的高峰期,业务量加大会增加执行人的作业压力,导致因办单不及时而产生提货流程拥挤。为此,港口物流管理人员可以加强对港口业务量的实时监控,在每月下旬的时候增加执行人数量,减轻执行人的作业压力。
b)自动发现的实际提货流程模型表明有较少实例需要签订单船合同,且该活动通常发生在“T7核发出库单”之前,这是因为重新签订合同需要到港后进行,不及时签订合同通常无法进行T7及后续流程,导致提货流程拥挤。本文通过调研发现大部分合同都是根据模板生成的,可以通过智能手段提前传递合同信息,缩短到港后的合同签订时间。
通过进行提货流程偏差根因分析,本文发现以上造成流程拥挤的因素,也是部分实例先违规办理地磅单,后核发出库单的原因。
4.1.2 港口物流标准流程模型不能充分满足客户需求
港口物流高度以人为中心,客户的需求和操作是多样化的,单一的港口物流执行顺序不能满足客户的多样化需求,会增加流程偏差的风险。如:
提货流程偏差根因分析表明货物类型为货类1和4的实例需要快速通过港口,客户通常会一次办理所有业务,这增加了办单顺序的不确定性。为此,港口业务部门可以对有快速办单需求的货类设立快速办单通道,以满足客户的需求并实现对办单顺序的控制。
4.1.3 执行人的违规操作问题
港口物流由多个物流活动构成,需要人工确认各种文件以保障流程的有序进行[34]。提货流程偏差根因分析结果表明,执行人的违规操作是提货流程发生某些偏差的原因。如:
办理地磅单执行人存在没有严格审核是否核发出库单就办理地磅单的违规操作,特别是部分执行人(执行人2和4)长期违规办理某些货物类型(货类1和4)的地磅单。为此,管理部门应加强对执行人的规范操作培训和检查,并针对违规行为制定相应的惩罚措施。
4.2 方法框架讨论
为了强化港口物流流程中的流程偏差根因分析能力,本文从数据提取和预处理、绩效分析、模型自动发现、一致性分析和偏差根因分析五个阶段进行了面向流程偏差根因分析的港口物流流程挖掘方法框架研究。本文方法与现有方法的对比结果如下。
4.2.1 与现有方法发现的港口物流流程模型对比
Fuzzy Miner和Heuristic Miner是现有港口物流流程挖掘中常用的流程模型自动发现方法。其中,Fuzzy Miner用于研究港口物流的主要流程,Heuristic Miner用于研究港口物流的详细流程信息。但这两种分法都可能会将低频但关键的路径作为噪声过滤掉,或产生不合理的模型。本文在港口物流流程模型自动发现阶段,首先使用Split Miner挖掘主要流程,然后使用Inductive Miner来挖掘复杂子流程的详细流程信息。
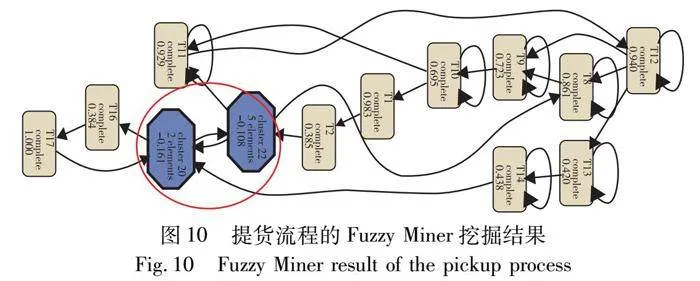
1)Split Miner与Fuzzy Miner发现的模型对比
在挖掘本文案例提货流程日志数据的主要流程模型时,图4是使用Split Miner的挖掘结果,图10是使用Fuzzy Miner的挖掘结果。比较图4和10可以发现,图4能够快速、准确地反映实际提货流程的结构特点,并且在保持模型低复杂性的同时保留了流程中的相关活动及路径;图10显示的提货流程比较混乱,不能快速分析出流程的结构特点,而且会把流程中的低频活动(活动T1-1、T3、T4、T5、T6、T7和T15)及路径聚合成新的活动(在图10用红色圆圈标出),从而无法使人们分析这些活动的执行信息。
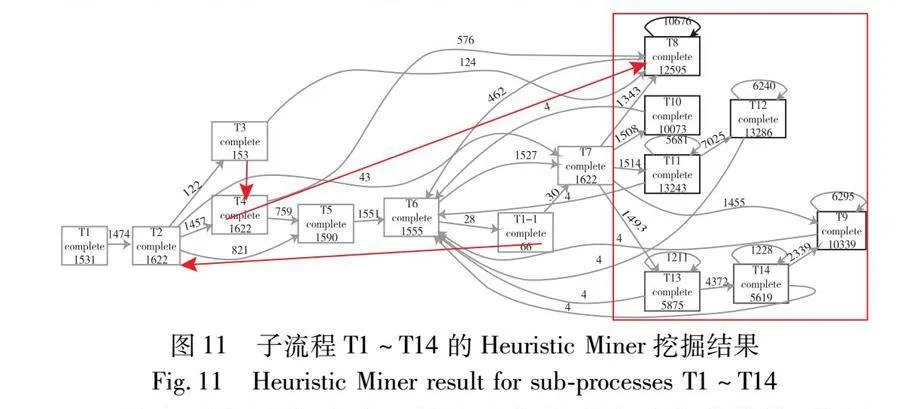
2)Inductive Miner与Heuristic Miner发现的模型对比
在挖掘本文案例提货流程中复杂子流程日志数据的详细流程模型时,图5是使用Inductive Miner的挖掘结果。图11是使用Heuristic Miner的挖掘结果,图11中的每个方框代表提货流程中的一种活动,边代表活动间的路径关系,数字代表活动或路径的发生次数,图11中的信息虽然能在一定程度上显示实际提货流程的执行细节,但不能有效地表达低频路径和复杂流程部分。比较图5和11可以发现,图5显示了详细的路径信息,能够很好地处理复杂流程部分,也能够发现流程中的低频路径;图11“T8→T9→T10→T11→T12→T13→T14”这一部分比较不合理(在图11用红色方框标出),没有像图5那样显示出这些活动的主要顺序关系,而且图11过滤掉了一些低频路径,例如“T4→T8”“T1-1→T2”和“T3→T4”(在图11用红色箭头标出)。案例分析表明,图5中的这些低频路径为提货流程中的偏差分析提供了支持。
以上对比显示,在港口物流流程模型自动发现阶段,使用Split Miner和Inductive Miner算法从不同抽象级别来发现简洁、合理、还原更多流程行为的流程模型,能够更准确地发现实际流程执行细节,为后续流程偏差根因分析提供支持。
4.2.2 对比两种方法进行港口物流流程偏差根因分析的结果
Wang等人[11]提出了一套由流程发现、绩效分析和一致性检查相关技术构成的方法,以获得港口物流流程知识,但该方法不能对港口物流流程偏差进行根因分析,造成港口物流流程偏差分析能力较弱。本文对该方法进行了延伸,加入港口物流流程偏差根因分析阶段。首先,使用分类决策树提取流程实例部分属性值和类别之间的规则;考虑到仅使用决策树存在不精确分析的风险,使用桑基图进一步分析流程实例在任意属性值间的转换趋势。案例分析结果表明,这两种方法成功发现了港口物流流程偏差的影响属性及影响机制。以下是使用两种方法的分析结果对比。
在对港口物流流程偏差进行根因分析时,图8是使用分类决策树分析的结果,图9是使用桑基图分析的结果。可以发现:图8显示了流程实例类别与办理地磅单时期、货物类型和地磅单执行人之间的规则,这些规则在一定程度上解释了港口物流流程偏差的影响属性及影响机制,但并不清楚流程实例在这些属性值间的转换关系;图9则显示了流程实例在货物类型、是否签订合同、地磅单执行人和流程实例类别间的转换趋势有所不同,进一步明确了港口物流流程偏差的影响属性及影响机制。
以上对比显示,本文在港口物流流程偏差根因分析阶段,结合决策树和桑基图进行分析,这两种方法的结果既有相同之处也有各自的发现,在最后确定原因时结合二者的结果进行分析,确保根因分析结果的可靠性和完整性。
综上,与现有方法作对比,本文方法能发现实际执行流程的更多细节,为流程偏差根因分析提供支持,并可以对流程偏差进行系统化的根因分析,强化了港口物流流程偏差分析能力,从而验证了本文方法的有效性和科学性。
5 结束语
本文提出了面向流程偏差根因分析的港口物流流程挖掘方法。该方法从港口物流信息系统中进行事件日志提取和预处理,接着对事件日志进行以下分析:首先,对事件日志中的港口物流活动进行流程绩效分析,发现影响流程绩效的因素并将其作为可能造成流程偏差的属性;其次,使用Split Miner、Inductive Miner自动发现实际流程模型,分析实际港口流程执行细节,为后续流程偏差根因分析提供支持;然后,通过基于对齐的一致性检查方法,分析实际港口物流流程和标准流程之间的业务一致性和具体流程偏差;最后,基于分类决策树和桑基图这两种方法,对具体港口流程偏差进行系统化的根因分析。通过在国内某大型港口物流提货流程上的实际应用,发现了港口物流拥挤、港口物流标准流程模型不能充分满足客户需求和执行人违规操作有关方面的问题是提货流程发生流程偏差的根本原因,并提出了针对性的管理洞察,验证了本文方法的适应性。
未来的工作可以从以下两个方面进行改进:首先,在数据提取和预处理阶段,本文仅考虑了港口物流信息系统中与流程活动相关的属性,未来研究可以与其他来源的数据结合起来;其次,在港口物流流程一致性分析阶段,由于研究数据规模并不是很大,本文所使用的基于对齐的一致性检查方法未考虑在大型事件日志上的耗时问题,未来应引进更高效的一致性检查方法。
参考文献:
[1]Hsu C T,Chou M T,Ding J F. Key factors for the success of smart ports during the post-pandemic era[J]. Ocean & Coastal Management,2023,233: 106455.
[2]王英. 港口物流中的流程知识挖掘研究和智能优化设计[D]. 北京: 北京交通大学,2014. (Wang Ying. Research on process mining in port logistics andintelligent design for the process improvement[D]. Beijing: Beijing Jiaotong University,2014.)
[3]Irannezhad E,Prato C G,Hickman M. An intelligent decision support system prototype for hinterland port logistics[J]. Decision Support Systems,2020,130: 113227.
[4]Zerbino P,Aloini D,Dulmin R,et al. Process-mining-enabled audit of information systems: methodology and an application[J]. Expert Systems with Applications,2018,110: 80-92.
[5]中华人民共和国海事局. 以案为鉴|引航安全不容忽视[EB/OL]. (2022-02-14) [2023-12-12]. https://www.msa.gov.cn/page/article.do?articleId=7812C350-4F25-4B18-8449-72A7EBD-57586. (Maritime Safety Administration of the People’s Republic of China. Learn from cases safety cannot be overlooked[EB/OL]. (2022-02-14) [2023-12-12]. https://www.msa.gov.cn/page/article.do?articleId=7812C350-4F25-4B18-8449-72A7EBD-57586.)
[6]孙迪. 散杂货港口商务管理流程挖掘研究[D]. 北京: 北京交通大学,2018. (Sun Di. Research on process mining in bulk and groceries port business management[D]. Beijing: Beijing Jiaotong University,2018.)
[7]Jia Xiaohui,Zhang Donghui. Prediction of maritime logistics service risks applying soft set based association rule: an early warning model[J]. Reliability Engineering & System Safety,2021,207: 107339.
[8]Van der Aalst W M P. Process mining: a 360 degree overview[M]. Berlin: Springer-Verlag,2022: 3-34.
[9]Veenstra A W,Harmelink R L A. Process mining ship arrivals in port: the case of the port of antwerp[J]. Maritime Economics & Logistics,2022,24(3): 584-601.
[10]Zerbino P,Aloini D,Dulmin R,et al. Towards analytics-enabled efficiency improvements in maritime transportation: a case study in a mediterranean port[J]. Sustainability,2019,11(16): 4473.
[11]Wang Ying,Caron F,Vanthienen J,et al. Acquiring logistics process intelligence: methodology and an application for a Chinese bulk port[J]. Expert Systems with Applications,Elsevier,2014,41(1): 195-209.
[12]Li Keyi,Marsic I,Sarcevic A,et al. Discovering interpretable medical process models: a case study in trauma resuscitation[J]. Journal of Biomedical Informatics,2023,140: 104344.
[13]Augusto A,Conforti R,Dumas M,et al. Split miner: automated discovery of accurate and simple business process models from event logs[J]. Knowledge and Information Systems,2019,59(2): 251-284.
[14]Sarkar B D,Shankar R,Kar A K. Severity analysis and risk profiling of port logistics barriers in the industry 4.0 era[J]. Benchmarking: An International Journal,2023,30(9): 3253-3280.
[15]Leemans S J,Fahland D,van der Aalst W M P. Scalable process discovery and conformance checking[J]. Software & Systems Modeling,2018,17: 599-631.
[16]刘聪,程龙. 流程挖掘: 技术与应用概述[J]. 中国科技产业,2021(7): 50-51. (Liu Cong,Cheng Long. Process mining: techno-logy and application overview[J]. Science & Technology Industry of China,2021(7): 50-51.)
[17]Weijters A,Van der Aalst W M P,De Medeiros A. Process mining with the heuristics miner-algorithm[J]. Technische Universiteit Eindhoven,2006,166: 1-34.
[18]Gyunther C W,Van der Aalst W M P. Fuzzy mining-adaptive process simplification based on multi-perspective metrics[C]// Proc of the 5th International Conference on Business Process Management. Berlin: Springer,2007: 328-343.
[19]朱锐,张志幸,莫启,等. 支持复杂结构的混成过程挖掘方法[J]. 计算机集成制造系统,2018,24(7): 1653-1670. (Zhu Rui,Zhang Zhixing,Mo Qi,et al. Hybrid process mining method supporting complex structures[J]. Computer Integrated Manufacturing Systems,2018,24(7): 1653-1670.)
[20]Augusto A,Carmona J,Verbeek E. Advanced process discovery techniques[M]. Berlin: Springer,2022: 76-107.
[21]白少康,方贤文,钱陈婧. 基于数据影响的业务流程一致性检查方法[J]. 计算机应用研究,2024,41(2): 540-547. (Bai Shaokang,Fang Xianwen,Qian Chenjing. Business process conformance checking method based on data impact[J]. Application Research of Computers,2024,41(2): 540-547.)
[22]Rozinat A,Van der Aalst W M P. Conformance checking of processes based on monitoring real behavior[J]. Information Systems,2008,33(1): 64-95.
[23]van der Aalst W M P,Adriansyah A,van Dongen B. Replaying history on process models for conformance checking and performance analy-sis[J]. WIREs Data Mining and Knowledge Discovery,2012,2(2): 182-192.
[24]沈晓林,刘聪,李会玲,等. 基于流程模型分解的分布式合规性检查方法[J/OL]. 计算机集成制造系统. (2023-03-30). https://kns.cnki.net/kcms/detail/11.5946.TP.20230329.1714.003.html. (Shen Xiaolin,Liu Cong,Li Huiling,et al. Distributed conformance checking method based on process model decomposition[J/OL]. Computer Integrated Manufacturing Systems. (2023-03-30). https://kns.cnki.net/kcms/detail/11.5946.TP.20230329.1714.003.html.)
[25]Suriadi S,Ouyang Chun,Van der Aalst W M P,et al. Root cause analysis with enriched process logs[M]// La Rosa M,Soffer P. Business Process Management Workshops.Berlin:Springer,2013:174-186.
[26]Ferreira D R,Vasilyev E. Using logical decision trees to discover the cause of process delays from event logs[J]. Computers in Industry,2015,70: 194-207.
[27]Bozorgi Z D,Teinemaa I,Dumas M,et al. Process mining meets cau-sal machine learning: discovering causal rules from event logs[C]// Proc of the 2nd International Conference on Process Mining. Pisca-taway,NJ: IEEE Press,2020: 129-136.
[28]Qafari M S,van der Aalst W M P. Feature recommendation for structural equation model discovery in process mining[J/OL]. Progress in Artificial Intelligence. (2022-06-25). https://doi.org/10.1007/s13748-022-00282-6.
[29]Cai Min,Wu Miaohuan,Luo Xinggang,et al. Integrated framework of kansei engineering and kano model applied to service design[J]. International Journal of Human-Computer Interaction,2023,39(5): 1096-1110.
[30]Qafari M S,van der Aalst W M P. Case level counterfactual reasoning in process mining[M]// Nurcan S,Korthaus A. Intelligent Information Systems. Berlin: Springer,2021: 55-63.
[31]Mahabir R J,Pun K F. Revitalising project management office operations in an engineering-service contractor organisation: a key perfor-mance indicator based performance management approach[J]. Business Process Management Journal,2022,28(4): 936-959.
[32]Berberoglu Y,Kazancoglu Y,Sagnak M. Circularity assessment of logistics activities for green business performance management[J]. Business Strategy and the Environment,2023,32(7): 4734-4749.
[33]Otto E,Culakova E,Meng Sixu,et al. Overview of sankey flow diagrams: focusing on symptom trajectories in older adults with advanced cancer[J]. Journal of Geriatric Oncology,2022,13(5): 742-746.
[34]Sarkar B D,Shankar R,Kar A K. Port logistic issues and challenges in the industry 4.0 era for emerging economies: an India perspective[J]. Benchmarking: An International Journal,2023,30(1): 50-74.
收稿日期:2023-12-09;修回日期:2024-03-06 基金项目:国家自然科学基金资助项目(72371086,72171064,61902222);山东省泰山学者工程专项基金资助项目(tsqn201909109);山东省自然科学基金优秀青年基金项目(ZR2021YQ45);山东省高等学校青创科技计划创新团队项目(2021KJ031)
作者简介:蔡敏(1973—),女,浙江温州人,副教授,博士,主要研究方向为人因与工效学、数字化工程与管理;王学涛(1998—),男,河南周口人,硕士,主要研究方向为流程挖掘;宋容嘉(1992—),女(通信作者),辽宁沈阳人,讲师,博士,主要研究方向为业务流程管理、数字/智化(rongjia.song@hdu.edu.cn);刘聪(1990—),男,山东淄博人,教授,博士,主要研究方向为流程挖掘、业务流程管理;雒兴刚(1971—),男,新疆奇台人,教授,博士,主要研究方向为产品/服务开发、运作管理、质量管理;黄磊(1965—),男,北京人,教授,博士,主要研究方向为企业数字化、信息系统.
