
健身运动知识表达与智能查询系统构建
2024-10-31 00:00:00黄涛郑嘉昕王坤黄杨毅刘逸婷夏泽涵林俊
首都体育学院学报 2024年5期


摘 要 科学健身运动在促进大众体质健康、心理健康等方面均发挥着重要作用。在数智时代背景下,健身运动知识的智能查询与精准查询成为延伸全民健身公共服务供给,提高全民健身公共服务质量的重要环节。鉴于此,通过知识图谱与大语言模型的协同互补,探索构建知识图谱驱动的健身运动知识智能查询系统,提出涵盖知识抽取与表达、知识整合与管理、知识查询与问答于一体的实施方案,进而为实现精准化健身运动知识智能查询的研究与应用提供参考。
关键词 健身运动知识;知识图谱;智能查询;大语言模型
中图分类号:G804 学科代码:040302 文献标志码:A
DOI:10.14036/j.cnki.cn11-4513.2024.05.003
Abstract Scientific exercise and fitness play an important role in promoting physical health, mental health, and overall development. In the digital intelligence era, the intelligent and precise querying of fitness and exercise knowledge has become a key aspect in expanding the supply and enhancing the quality of public exercise services. Therefore, a study was conducted to construct a knowledge graph-driven intelligent query system for fitness and exercise knowledge, utilizing the complementary strengths knowledge graphs and large language models. An integ-rated implementation approach that encompasses knowledge extraction and representation, knowledge organizat-ion and management, as well as knowledge inquiry and Q&A, was proposed. This will provide support for the development and implementation of intelligent querying in the fitness and exercise knowledge domain.
Keywords fitness and exercise knowledge; knowledge graph; intelligent query; large language model
随着全民健身国家战略的实施和主动健康理念的推广,我国广大民众对精准化健身运动知识查询及个性化健身运动指导的需求日益增长。在数智时代,搜索引擎仍是大众在互联网上获取健身运动知识的重要工具。然而,在网络信息爆炸式增长的态势下,传统搜索引擎的局限逐渐暴露[1]。由于缺乏知识层面的统一描述和概念之间的语义联系,传统搜索引擎的搜索结果精准度不高,用词习惯不一、词语概念定义表达不明确、术语间关系界定不清晰等现象普遍存在。这不仅增加了大众获取科学健身运动知识的难度,导致出现了“信息迷航”“认知过载”等问题[2],也使得因知识不足、方法不当造成的运动损伤在大众健身运动实践过程中频繁发生。可见,实现健身运动知识的高效查询已经成为推动全民健身与全民健康深度融合的途径之一。然而,如何实现健身运动知识的统一表达、组织整合与智能查询,满足大众多样化、精准化与个性化的需求,是亟待解决的科学问题。
《全民健身计划(2021—2025年)》中提出:“提供全民健身智慧化服务”[3]。当前,面临着信息检索的挑战,而以知识图谱为典型的知识工程技术为健身运动知识的有效查询提供了新视角[4]。知识图谱(KG)是一种由节点和边构成的图数据结构,通常用于描述客观世界存在的实体概念及其相互之间的关系[5]。知识图谱的出现使得领域知识的组织整合与管理复用变得方便、快捷,相关技术已经在网络舆情[6]、非遗档案[7]、医疗健康[8]等领域应用。此外,作为支撑机器向认知智能转化的重要基石[9],知识图谱为实现精准化诊断、开放式问答、个性化推介等智能场景提供了结构化、语义化、逻辑化的知识资源。鉴于知识图谱相关方法能够从形式多样、多源异构的领域知识信息资源中重构其知识层次与概念之间的语义联系[10],实现健身运动知识的统一表达和整合,本研究将重点探讨知识图谱驱动的健身运动知识智能查询模式的构建框架及实施方案,以期为精准化健身运动知识查询、个性化健身运动指导的实现提供新的思路和参考。
1 健身运动知识智能查询系统的构建框架
1.1 本体化的健身运动知识表达
健身运动知识的有效查询和使用有利于科学健身理念和健身运动方法的推广,帮助健身人群在健身运动实践过程中获得针对性的指导,实现相应的健身目标。然而,多源化、碎片化、截面化的健身运动领域知识信息致使语义模糊、多词同义、信息冗余等问题普遍存在,对健身运动知识的高效查询造成阻碍。因此,形成系统化、逻辑化的健身运动知识表达方法是解决上述问题的先决条件[11],也是实现健身运动知识智能查询的重要基础。
知识表达也称知识表示,主要作用是将认知对象中的要素与知识进行关联,便于人们对知识进行认知与理解[12]。当前,学界对知识表达方法进行了较为全面的研究。丁华等学者采用面向认知对象为主、产生式规则和过程表示为辅的混合知识表示模式,实现了对认知对象信息、设计过程和经验规则的集中表达,为建立知识库奠定了良好基础[13]。刘培奇等学者基于产生式规则和概念图的知识表达方法在自然语言理解中存在的问题提出了扩展产生式规则的知识表达方法,但是关于该方法的推理效率有待进一步提高[14]。李佳静等学者针对所述知识涉及多重领域、知识间关系复杂等问题,提出基于本体的知识表达方法,并利用本体对跨专业领域概念的关系进行语义定义,解决了知识表达中概念异构、关系模糊等问题[15]。通过上述方法之间的对比,将基于本体的知识表达法应用于健身运动知识表达是一种较为理想的技术手段。
本体一词源于亚里士多德对事物存在的本质的研究,在哲学上被定义为存在论,即对客观存在事物作出的系统性说明[16]。最初是从形而上学的角度,描述或假设物质存在基本范畴和关系,以便在其框架内定义实体及实体类型[17]。随后,本体逐渐演变成一种数据模型,旨在系统地阐述领域概念、术语及其相互之间的关系,并通过类层次结构的形式,对定义的概念进行模块化呈现[18]。鉴于本体的抽象功能较强,且具备逻辑推理能力,所以基于本体的知识表达方法在应急管理[19]、公共卫生[20]、医疗[21]、文献遗产[22]等多个领域得以应用。因此,本研究采用基于本体的知识表达方法解决健身运动知识概念异构、信息模糊、关系界定不清晰等问题。首先,通过建立健身运动知识表达框架,从健身人群、健身目的、健身方式、健身补剂、损伤预防、反兴奋剂等角度分析大众在健身运动实践过程中可能涉及的知识要素。其次,抽取健身运动领域核心知识源中的概念、关系、属性、规则等本体构成元素,建立健身运动知识统一表达模型。然后,依托相关软件(如Protégé等)构建健身运动知识本体。最后,通过对应实例进行本体验证,以实现本体化的健身运动知识表达。
1.2 知识图谱支持下的健身运动知识整合
在数智时代,知识图谱作为知识整合的重要途径之一,因其强大的功能,广泛应用于各个领域的知识服务场景中。例如,在中医领域,为实现智能诊疗,杨涛等学者以知识图谱为基础,提出包含知识抽取、知识整合和辅助诊疗于一体的中医智能诊疗模型及其构建方法[23]。在教育领域,为了实现智慧教学,罗江华等学者探讨了多模态学科知识图谱的基本内涵、构建框架和应用场景[24]。在航天领域,彭仕鑫等学者利用本体建模、知识抽取、知识融合等方法,通过Neo4j图数据库构建了知识图谱可视化系统[25]。可见,知识图谱为海量、多源的领域知识提供了一种高效的整合和管理方式[26],是实现领域知识集成共享、提高领域知识服务效率的重要技术手段。
鉴于健身运动知识专业性强、实例数量大、更新速度快且实体间语义关系复杂,本体化的知识表达成为健身运动知识整合的起始环节。健身运动知识本体,不仅可以完成领域概念的分类,避免歧义的产生,还可以通过概念关系形成的语义表达,实现领域知识的总体描述,为知识图谱提供结构化的基础[27]。此外,由于概念及概念之间的相互关系在本体中得到了明确的定义,所以健身运动知识图谱能够基于健身运动知识本体进行扩展和丰富,并清晰地展示其推理过程,进一步为大语言模型支持下的健身运动知识查询与问答结果赋予可解释性。因此,在健身运动知识本体的基础上,构建健身运动知识图谱以整合与管理多源异构的健身运动领域知识信息,进而为健身运动知识智能查询提供基础支撑。
鉴于健身运动领域知识信息多源化、碎片化和截面化的特点,本研究选用基于图数据库的知识图谱技术进行健身运动知识的整合与管理。相较于传统的关系型数据库,图数据库采用图论方式存储复杂的健身运动知识实体和概念关系,并支持图算法进行深入分析和挖掘[28]。图数据库可以实现健身人员所使用的运动项目、运动技术、动作规范、运动损伤预防、运动补剂等相关知识的灵活存储,以及健身人群、健身目的、健身方式、健身规范等不同本体模块所属实体之间关系的图示体现。据此,大众可以通过浏览健身运动知识图谱,探究不同类别健身运动知识之间的关联,并通过搜索功能围绕概念节点进行查询。
1.3 大语言模型支持下的健身运动知识查询
生成式人工智能(GAI)技术正引领新一轮人工智能研究范式的转变,并对智能查询方式产生了深刻影响。随着以Chat GPT等为典型的生成式人工智能技术的发展,大语言模型(LLM)可赋能并支持科学健身知识查询、指导和问答。大语言模型是以Transformer为基础的特殊深度学习模型[29],其核心技术包括自注意力机制、位置编码、前馈网络等。自注意力计算公式如下。
Attention(Q,K,V)=softmax() 1),
式中:Q、K、V分别表示查询、键和值矩阵,由输入矩阵通过不同的权重矩阵转换生成;dk表示键向量的维度,用于缩放点积,防止点积过大导致softmax函数进入梯度较小的区域。然而,由于Transformer模型缺乏循环或卷积结构,为了确保该模型能够兼顾序列中词语的先后顺序,需要输入位置编码,见式(2)和式(3)。
PE(pos,2i)=sin( pos / 10 000)2),
PE(pos,2i+1)=cos(pos/10 000) 3),
式中:pos表示位置;i表示维度;dmodel 表示模型的维度。通过这种方式,每个位置将被赋予独特的位置编码,模型即可利用上述信息捕捉序列中的词语的相对位置。随后,在每个Transformer块内,自注意力层的输出会被进一步传递至一个前馈网络,并对各个位置的词语进行独立的、一致的操作,这一过程如式(4)所示。
FFN(x)=max(0,xW1+b1 ) W2+b2 4),
式中:W1 、W2 、b1和b2均表示网络参数,使用ReLU作为激活函数。
在自然语言处理(NLP)技术的持续演进中,大语言模型的学习机制与决策模式相较于传统深度学习模型呈现出明显差异。具体体现在以下2个方面。1)在学习方面,改变传统有监督学习方式,转而融合自监督学习与强化学习策略以增进其性能。具体而言,自监督学习辅助大语言模型可以深入洞察文本内在的上下文语义联系,而强化学习则通过大语言模型与环境的动态交互,在对话系统、文本生成等特定任务中,引导大语言模型学习并采纳最优决策路径。2)在决策方面,与传统的分类或回归输出不同,大语言模型采用了生成式的结果输出方式[30-31],以生成更加丰富和灵活的内容。这种决策模式显著增强了自然语言处理技术在文本生成、机器翻译、自动摘要等领域的功能,使其能够基于上下文生成更加连贯、符合语言习惯的文本[32]。
由于传统搜索引擎依赖于关键词匹配和排序算法[10],大语言模型则可以弥补传统搜索引擎的不足,更好地满足大众查询健身运动知识的需求。然而,针对专业领域知识的查询与问答,大语言模型则存在不足之处[33-34]。受限于输入数据的质量与范围,大语言模型生成结果的准确性可能降低。在尝试填充信息空缺时,大语言模型会依赖内部生成逻辑创造不存在的事实,即“幻觉事实”[35]。例如,当用户询问如何进行某项运动时,大语言模型会利用习得的普遍性知识,生成一个看似标准的答案。然而,这种答案缺乏对个体差异的考虑,如身体状况、运动能力、伤病史等。因此,其生成答案可能并不完全准确或适用于所有个体。此外,基于数据更新的频率和算法的局限性,大语言模型可能无法及时捕捉并反映最新的信息,这将导致大语言模型提供的健身运动建议与最佳实践成效产生偏差。
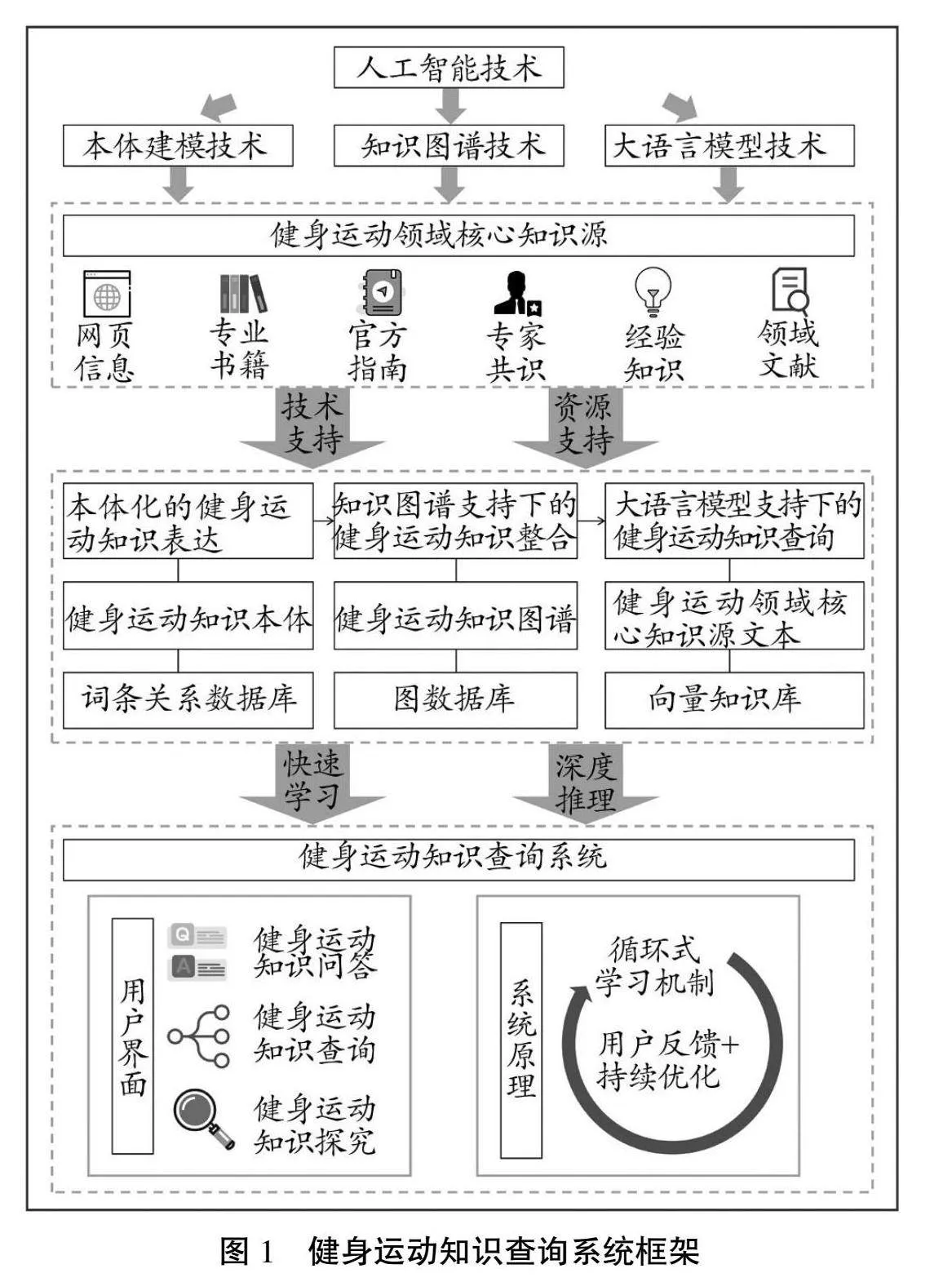
为了解决上述问题,引入并应用专业领域知识图谱尤为关键。作为一种结构化模型,知识图谱能够显示、存储经过严格验证的精确事实性知识[10]。基于专业领域知识图谱,大语言模型不仅能够更好地理解和适应该领域的知识体系和相关术语,生成更具领域针对性的文本内容,还能依托专业领域知识图谱的结构进行深度推理,并且可以有效规避事实性错误的风险[36]。此外,专业领域知识图谱实时更新的特性有助于大语言模型在文本生成过程中迅速抓取最新信息,进一步提高其输出内容的准确性和有效性。鉴于此,本研究结合大语言模型与知识图谱拟构建健身运动知识查询系统(见图1),实现健身运动知识的智能查询。
具体而言,本研究所构建的健身运动知识查询系统侧重于在大众实践过程中应用,其目标用户是有健身指导需求的非体育专业人群。健身运动知识查询系统框架如图1所示,构建流程主要包括以下内容:基于健身运动领域核心知识源数据构建系统所需的数据集和知识库,利用自然语言处理技术对数据源进行数据预处理。在健身运动知识图谱的基础上,利用大语言模型补充完善健身人群、健身目的、健身方式、健身规范等范围内的实体及实体之间的关系,形成健身运动知识图数据库。通过大语言模型的快速学习,将健身运动领域专家先验知识与健身运动领域多源知识相结合,提高健身运动知识查询与问答的专业水平与准确率,并设计健身运动知识查询系统的用户界面。
2 健身运动知识智能查询模式的实施方案
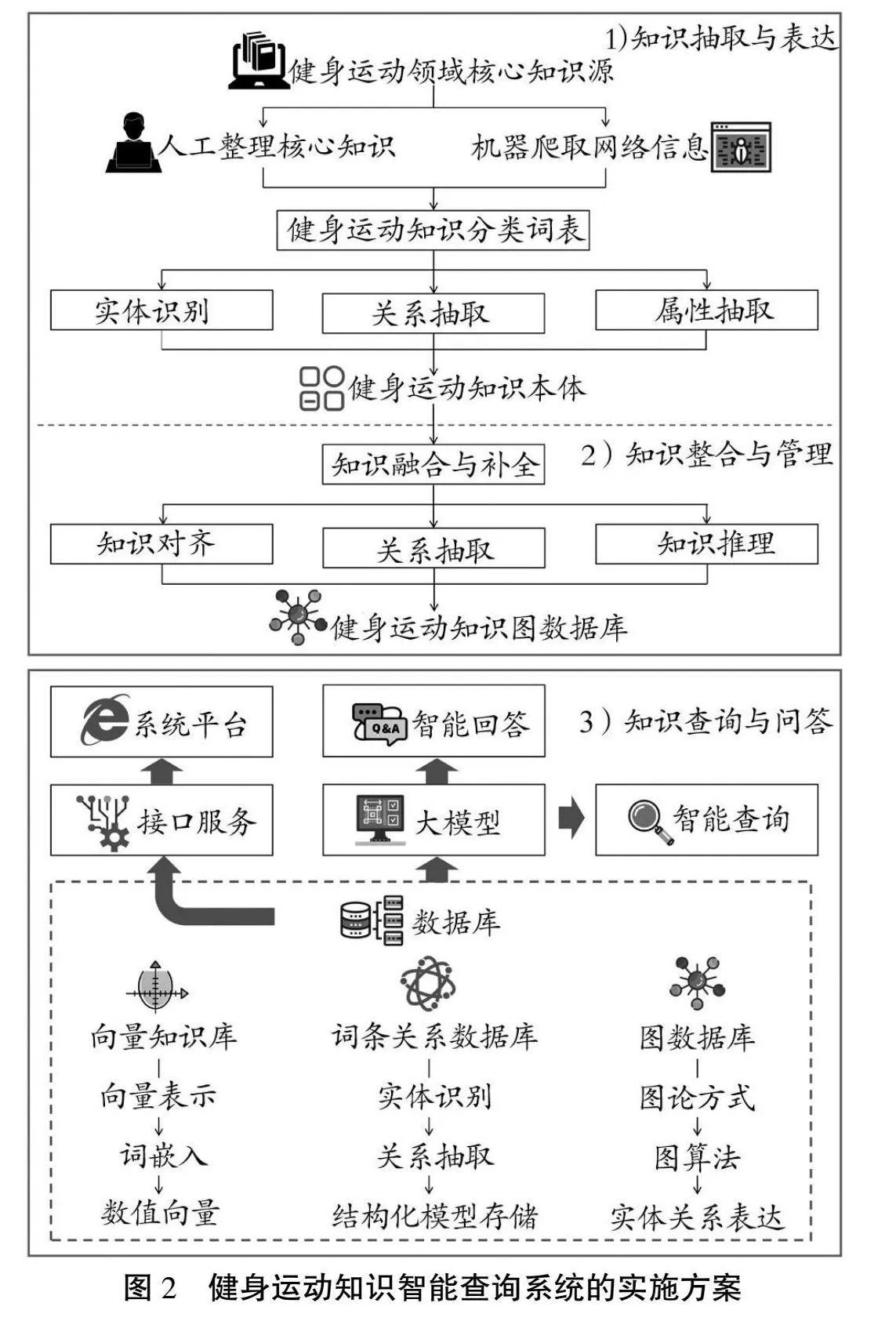
为了实现健身运动知识的智能查询,本研究提出的健身运动知识智能查询模式构建的实施方案(如图2所示)包含知识抽取与表达、知识整合与管理、知识查询与问答三大核心模块。
如图2所示:1)知识抽取与表达模块主要对多源异构的健身运动领域知识信息进行规模化挖掘与收集,基于抽取结果建立具有领域共识的健身运动知识统一表达模型,并构建相互依存的健身运动知识本体;2)知识整合与管理模块主要对健身运动领域知识进行对齐与融合,并以图数据库作为整合引擎,实现健身运动知识的集中集成、共享分析和管理复用;3)知识查询与问答模块主要利用大语言模型的深度推理,生成准确、专业的问答结果,以实现健身运动知识的智能查询。
2.1 知识抽取与表达
在技术层面,本体化的健身运动知识表达需建立在知识抽取基础上。
首先,针对研究目的与应用需求,在参考各国官方身体活动指南、运动科学和生理学相关专业书籍、中英文体育学权威学术期刊论文的基础上,梳理健身运动领域知识范围,确立健身运动领域核心知识源。同时,参考健身运动领域专业词表,依照健身运动领域知识本质属性或其他显著特征,由健身运动领域专家设计健身运动知识本体分类模块。
其次,从运动项目、健身器械、损伤类型、身体部位、健身补剂、个体特征、健康特征、环境特征等方面切入,综合词频、词义、词形、用户使用习惯等多种因素收集健身运动领域核心概念优选词。在完成一定数量的概念优选词的收集和整理后,对健身运动知识本体分类模块进行适用性测试,通过知识梳理与识别、知识产生与萃取、知识收集与评审等流程反复测试,促进健身运动知识本体分类模块的逐步完善。在此过程中,需要评估每个概念的重要性,形成健身运动知识分类词表,进而结合逻辑分析、语义分析等方法,从本体分类模块出发,建立包含健身运动领域知识逻辑抽象和本体建模主要过程的健身运动知识表达框架。引入类(或概念)、属性、关系、函数、实例和公理6个本体基本构成元素,定义健身运动概念类、健身运动概念类的通用关系和健身运动概念类的通用属性,构建基于本体的健身运动知识表达模型,其形式化定义如公式(5)所示。
O=< C,R,Ac,AR,H,X > 5),
式中:O表示健身运动知识本体;C表示类的集合(指健身运动知识中的概念、术语的集合);R表示类的关联关系集合;Ac表示概念属性的集合(对健身运动知识中的概念本身的特征进行描述);AR表示关系的属性集合,H表示实例集(指健身运动知识中的实例的集合);X表示公理(指已有事实,能够约束类或关系,是健身运动知识推理的基础约束)。
最后,根据斯坦福大学医学院创设的本体构建“七步法”[37],结合健身运动知识分类词表,使用软件“Protégé”为预先设置的健身运动知识表达模型添加实例与属性,完成健身运动知识本体的构建。基于德尔菲法,对健身运动知识本体的命名规则、体系架构及逻辑层次进行评价、修改和完善,以建立本体化的健身运动知识表达标准。
2.2 知识整合与管理
在健身运动知识本体的基础上构建健身运动知识图谱,旨在整合与管理健身运动领域知识信息,为健身运动知识查询系统提供基础支撑。健身运动知识图谱的实施方案如下。
首先,对健身运动领域核心知识源语料进行数据预处理,包括文本清洗、去噪、格式标准化等流程。其中,标准化处理即将数据按照比例缩放,使之处于一个特定区间。常见的方法有Min-Max标准化和Z-score标准化。公式(6)和公式(7)分别对应Min-Max标准化和Z-score标准化,通过消除错误、冗余和非结构化元素,为结构化输入提供清晰而一致的数据基础。
x'= 6),
式中:x是原始数据,x'是标准化后的数据。
z=7),
式中:μ是数据的均值,σ是数据的标准差。
其次,利用自然语言处理技术,如命名实体识别(NER)技术,确定构成健身运动知识图谱的基本元素(包括运动项目、技术要领、比赛规则、器材装备、运动场地等)。为了减少命名实体识别的误差,从数据集优化、特征表示优化、模型参数调整、外部知识引入、反馈机制建立等方面入手,综合应用上述技术方法,持续增强其在识别准确性、召回率、处理速度、泛化能力等方面的功能。
再其次,采用实体对齐、属性融合、关系匹配等方法,对多源异构的健身运动领域知识信息进行整合、消歧、加工等知识融合处理。同时,利用大语言模型,通过在预训练过程中设定特定任务,如关系预测、知识补全等任务,提高健身运动知识注入的效率及准确性。
最后,根据所抽取数据的性质和特点,选用适合的图数据库(如Neo4j等),对健身人群、健身目的、健身方式、健身规范等不同本体模块所属实体、属性及其之间的关系进行导入,构建成健身运动知识图谱。进而定期对其进行维护和更新,以反映健身运动知识领域的最新变化。
基于图数据库可视化功能形成的健身运动知识图谱是健身运动知识查询系统实现知识传播的关键部分。可视化是指健身运动领域知识信息的可视化,该功能可使健身运动领域核心知识源的复杂的实体与不同的健身运动方式产生联系,并转换成直观的图形界面,诸如个体特征、健康特征、环境特征及健身目的。与此同时,该功能还为健身运动领域知识信息的动态展示提供了技术支持。用户可以根据个性化查询观察所需健身运动知识节点的变化与比较结果。
2.3 知识查询与问答
在健身运动知识图谱的基础上,大语言模型被用于补充完善实体及其之间的关系,以形成全面和完善的健身运动知识图数据库。此外,为了应对大语言模型固有的黑箱特性,可通过向量知识库、词条关系数据库及图数据库的协同应用,增强大语言模型在健身运动知识查询与问答任务中的解释性和灵活性。
具体而言,向量知识库作为存储向量化知识数据的载体,可涵盖健身运动领域核心知识源文本内的专业术语、相关概念、运动项目类型、动作要领等。运用词嵌入等向量化方法可以使健身运动领域知识间的相似性与关联性得以高效度量,进而对向量相似度进行深入分析,能够显著增强大语言模型的可解释性,从而提升其在健身运动知识查询系统中应用的可信度和有效性。向量空间模型的灵活性赋以向量知识库扩展性和更新能力,这一特性使得向量知识库能够兼容多种类型的知识表示和查询,以满足健身运动知识查询系统用户的多样化的场景需求。
词条关系数据库则基于健身运动知识本体的存储和词条关系、属性的管理而形成。其主要功能在于存储词条的关联信息,包括同义词、反义词、上下位概念关系等多种类型。在大语言模型的训练过程中,结合词条关系数据库,可以引入词汇关系约束,进一步优化大语言模型对健身运动领域相关词汇和短语的识别与生成能力。同时,词条关系数据库能够针对用户的查询进行语义层面的深入扩展与精确修正,进而显著增强健身运动知识问答系统的精确度和鲁棒性。
如前文所述,图数据库主要用于表达健身运动领域实体间的关系,并描述健身运动领域关键事件的演进历程。通过运用图算法,大语言模型能够深入剖析健身运动领域知识的内在结构和深层联系,并且图数据库具有的可视化功能,可以使大语言模型在回答问题时的推理路径得以清晰展现。
综上所述,向量知识库、词条关系数据库、图数据库与大语言模型的紧密协作,为健身运动知识问答系统功能模块的形成提供了强有力的支撑。通过构建知识问答、知识查询及知识探究三大功能模块,该系统能够以更加智能、高效的方式处理与展示健身运动知识,并为用户提供丰富的探究体验。具体而言,健身运动知识问答模块旨在回答用户关于健身运动领域的各类开放式问题。健身运动知识查询模块包含健身人员在健身运动过程中需运用的运动项目、运动技术、动作规范、运动损伤预防、运动补剂、兴奋剂防范等相关知识。健身运动知识探究模块通过直观描述健身运动领域知识信息的复杂关系,辅助用户探究并理解不同类别健身运动知识间的联系。
有关健身运动知识查询系统的智能问答功能设计,主要注重建立闭环的学习系统。该功能运用多项技术实现对用户问题的精准回答,并通过持续学习可以不断地提供更优质的答案。首先,当用户提出问题时,该系统通过向量知识库进行初步搜索,将用户问题与核心知识源范围内的内容进行匹配和聚焦,以确保与问题的相关性和适用性。若问题与其中的内容高度相关,系统将利用向量表示的高相似性,将信息输入至大型语言模型进行深度推理。基于深度学习等技术,大语言模型能够理解开放式问题的语义含义,并可以生成答案。据此,健身运动知识查询系统将以较为完善的语言回答用户的问题,并提供相应的健身运动知识。用户得到答案后,该系统允许用户提供反馈。用户反馈的结果将被纳入大语言模型的学习过程,以此优化大语言模型,提高健身运动知识回答的准确性和科学性。这一循环过程使得健身运动知识查询系统可以持续改进,并为用户提供更为精准和全面的健身运动知识。
健身运动知识查询系统的智能查询功能同样建立循环式学习机制。首先,当用户提出问题时,该系统通过查询健身运动知识图数据库,搜索与问题相关的词条、概念关系和属性,从图数据库中获取可能与用户问题相关的知识片段。其次,随着健身运动领域知识的持续更新以及词条、概念关系的变化,健身运动知识查询系统的智能查询功能需要保持与图数据库的同步更新。因此,在通过查询健身运动知识图数据库获得初始信息之后,该系统凭借实时数据同步机制,可以确保所提供的答案属于最新的领域知识。最后,该系统将这些答案反馈给用户,同时也允许用户提供反馈。这种循环式学习机制有助于健身运动知识查询系统更为精准地满足用户对健身运动个性化和多样化知识的需求。
3 结束语
当前,大众对健身运动知识和科学锻炼方法的需求日益凸显,数字技术和人工智能技术的发展为科学健身运动知识和方法的查询提供了新的思路和视角。为了实现健身运动知识的智能查询,助力全民健身国家战略的实施,本研究对知识图谱驱动的健身运动知识智能查询系统进行了探索,提出了涵盖知识抽取与表达、知识整合与管理、知识查询与问答于一体的实施方案。然而,在实施技术路线和方法等方面,仍面临一些挑战和问题。因此,需要进一步探究如何更高效、精准地整合与管理健身运动领域知识信息,进而为健身运动知识智能查询的实施提供基础和参考。
参考文献:
[1] 郭卫宁,司莉. 国外语义搜索引擎调查与分析[J]. 图书馆情报工作,2013, 57(23): 121-129.
[2] KAMILARIS A, YUMUSAK S, ALI M I. WOTS2E: A search engine for a semantic web of things [C]//2016 IEEE 3rd World Forum on Internet of Things (WF-IoT). VA: IEEE, 2016: 436-441.
[3] 国务院关于印发全民健身计划(2021—2025年)的通知 [EB/OL]. (2021-08-03)[2024-03-30]. http://www gov.cn/zhengce/content/2021-08/03/content_5629218.htm.
[4] 刘鹏,叶帅,舒雅,等. 煤矿安全知识图谱构建及智能查询方法研究[J]. 中文信息学报,2020,34(11): 49-59.
[5] 刘峤,李杨,段宏,等. 知识图谱构建技术综述[J]. 计算机研究与发展,2016,53(3):582-600.
[6] 娄国哲,王兰成. 基于知识图谱的网络舆情知识组织方法研究[J]. 情报理论与实践,2019,42(1):58-64.
[7] 赵雪芹,路鑫雯,李天娥,等. 领域知识图谱在非遗档案资源知识组织中的应用探索[J]. 档案学通讯,2021,3: 55-62.
[8] 韩普,叶东宇,陈文祺,等. 面向多模态医疗健康数据的知识组织模式研究 [J]. 现代情报,2023,43(10):27-34, 151.
[9] 李振,周东岱,王勇. “人工智能+”视域下的教育知识图谱:内涵、技术框架与应用研究[J]. 远程教育杂志,2019,37(4): 42-53.
[10] 张鹤译,王鑫,韩立帆,等. 大语言模型融合知识图谱的问答系统研究[J]. 计算机科学与探索,2023,17(10): 2377-2388.
[11] 柯庆镝,孙伯骜,薛冰,等. 产品性能关联下绿色设计知识表达及获取方法 [J]. 中国机械工程,2022,33(22):2717-2726.
[12] 李勇, 杨思敏, 郭尚窈, 等. “物-工艺-基因”三维视角下手工艺类非遗的本体知识表达研究[J]. 图书情报工作, 2023,67(6):137-148.
[13] 丁华,常琦,杨兆建. 基于混合知识表示模型的采煤机规则库构建与应用 [J]. 机械设计与制造,2016(5): 204-207.
[14] 刘培奇, 李增智, 赵银亮. 扩展产生式规则知识表示方法[J]. 西安交通大学学报, 2004(6): 587-590.
[15] 李佳静,黎荣,武浩远,等. 面向多领域的转向架知识本体表达及重用研究 [J]. 机械设计与制造,2019(4): 55-58.
[16] STUDER R, BENJAMINS V R, FENSEL D. Knowledge engin-eering: Principles and methods[J]. Data & Knowledge Engin-eering, 1998, 25(1/2): 161-197.
[17] CARDOSO S D, DA SILVEIRA M, PRUSKI C. Construction and exploitation of an historical knowledge graph to deal with the evolution of ontologies[J]. Knowledge-Based Systems, 2020, 194: 1-10.
[18] MAEDCHE A, STAAB S. Ontology learning for the semantic web[J]. IEEE Intelligent Systems, 2001, 16(2): 72-79.
[19] 王芳,杨京,徐路路. 面向火灾应急管理的本体构建研究[J]. 情报学报,2020,39(9):914-925.
[20] 宋培彦,王晋明. 公共卫生领域多本体知识融合方法及其实证研究[J]. 图书与情报,2021(5):39-45.
[21] 许冬冬,林惠,段会龙,等. 健康行为改变干预本体的构建与应用[J]. 中国生物医学工程学报,2023,42(1): 74-81.
[22] 陈晓婷, 毛太田. 文献遗产本体构建——以《中国档案文献遗产名录》为例 [J]. 图书馆论坛,2023,43(9):120-131.
[23] 杨涛,漆隽之,胡孔法,等. 知识驱动的中医智能诊疗研究思路与方法[Z/OL].(2023-12-11)[2024-03-30]. http://kns.cnki.net/kcms/detail/21.1546.R.20231130.1320.002.html.
[24] 罗江华, 张玉柳. 多模态大模型驱动的学科知识图谱进化及教育应用[J]. 现代教育技术,2023,33(12):76-88.
[25] 彭仕鑫, 肖彪, 赵正彩, 等. 航天复杂薄壁零件加工工艺知识图谱构建及其应用[J]. 机电工程, 2024 , 41(4): 709-719.
[26] 赵一鸣. 知识图谱是一种知识组织系统吗? [J]. 图书情报知识,2017(5): 2.
[27] 李爱华,徐以则,迟钰雪. 本体构建及应用综述[J]. 情报理论与实践,2023,46(11):189-195.
[28] 王飞,易绵竹,谭新,等. 基于Neo4j对涉藏领域本体的存储方法研究[J]. 郑州大学学报(理学版), 2019, 51(2): 60-65.
[29] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// NIPS'17: Proceedings of the 31st Internatio-nal Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2017: 6000-6010.
[30] GUU K, LEE K, TUNG Z, et al. Retrieval augmented language model pre-training [C]// Proceedings of Machine Learning Re-search. Vienna: International Conference on Machine Learni-ng, 2020: 3929-3938.
[31] CHOWDHERY A, NARANG S, DEVLIN J, et al. Palm: Scalin-g language modeling with pathways[J]. Journal of Machine Learning Research, 2023, 24(240): 1-113.
[32] 车万翔,窦志成,冯岩松,等. 大模型时代的自然语言处理:挑战、机遇与发展[J]. 中国科学(信息科学),2023,53(9):1645-1687.
[33] 张鹤译,王鑫,韩立帆,等. 大语言模型融合知识图谱的问答系统研究[J]. 计算机科学与探索,2023, 17(10): 2377-2388.
[34] OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
[35] AZAMFIREI R, KUDCHADKAR S R, FACKLER J. Large language models and the perils of their hallucinations[J]. Critical Care, 2023, 27(1): 120.
[36] PAN S, LUO L, WANG Y, et al. Unifying large language mode-ls and knowledge graphs: a roadmap[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(7): 3580-3599.
[37] NOY N F, MCGUINNESS D L. Ontology development 101: A guide to creating your first ontology[J]. International Journal of Engineering and Technology, 2001, 3(1): 1-9.
