
多类别形态的未隶定青铜器铭文细粒度识别
2024-10-14 00:00:00刘可欣王慧琴王可王展王宏
计算机应用研究 2024年10期









摘 要:未隶定铭文的识别主要依靠传统卷积网络提供单一的全局特征,却忽略了部位识别和特征学习的关系,导致模型难以充分表达复杂形态的文字构造,进而产生识别误差。针对上述问题,提出了一种姿态对齐的多部位特征细粒度识别模型(MP-CNN)。在第一个阶段,构建空间转换器引导铭文统一字形姿态,辅助模型准确定位文字的鉴别性部位;在第二个阶段,构建级联的ECA(efficient channel attention)注意力机制引导特征通道组合,定位多个独立的鉴别性部位,并通过相互增强的方式细粒化地提取铭文的形态特征,解决复杂形态的文字识别问题;在第三个阶段,构建特征融合层获取识别结果。实验表明,该算法在铭文标准数据集和多类别形态数据集上的识别准确率分别为97.25%和97.18%,相比于传统卷积网络ResNet34分别提升4.63%和8.89%。结果显示,该算法能够有效针对铭文实际形态的独特性,实现未隶定铭文的细粒度识别。
关键词:未隶定青铜器铭文; 细粒度识别; 姿态对齐; ECA注意力机制; 特征融合
中图分类号:TP391.1 文献标志码:A
文章编号:1001-3695(2024)10-045-3194-07
doi:10.19734/j.issn.1001-3695.2023.11.0594
Fine-grained recognition of untranscribed bronze inscriptions based on multi-category morphology
Liu Kexin1, Wang Huiqin1, Wang Ke1, Wang Zhan2, Wang Hong2
(1.School of Information & Control Engineering, Xi’an Univversity of Architecture & Technology, Xi’an 710055, China; 2.Shaanxi Provincial Institute of Cultural Relics Protection, Xi’an 710075, China)
Abstract:Fine-grained recognition of untranscribed bronze inscriptions relies on traditional convolutional neural networks. However, this method used overlooks the relationship between localization and feature learning, leading to difficulties in accurately representing the complex structures of the text and resulting in recognition errors. This paper proposed a model, named MP-CNN, addressed this issues through a pose-aligned multi-part fine-grained recognition approach. In the first stage,it employed a spatial transformer to guide inscriptions to adopt a consistent glyph posture, aiding the model in accurately locating key text regions. The second stage incorporated constructing a cascaded efficient channel attention(ECA) mechanism to guide the combination of feature channels, locating multiple independent discriminative regions and refining the extraction of morphological features for complex text structures. Finally, in the third stage, it built a feature fusion layer to obtain the recognition results. Experimental results demonstrate that the algorithm achieves recognition accuracies of 97.25% and 97.18% on stan-dard and multi-category morphology datasets, respectively. Compared to the traditional convolutional network ResNet34, the method exhibits improvements of 4.63% and 8.89% on these datasets. The results indicate that the algorithm effectively adapts to the actual morphological variations in inscriptions, achieving fine-grained recognition of untranscribed bronze inscriptions.
Key words:untranscribed bronze inscriptions; fine-grained recognition; pose alignment; ECA attention mechanism; feature fusion
0 引言
中华青铜文明源远流长,青铜器铭文历经商周秦汉各个时期,记录了不同朝代的盛衰兴废,具有宝贵的研究价值[1]。目前,待识别的青铜器铭文数量庞大,人工释读面临着两个主要难题:首先,不同类别的铭文字体存在较多相似之处,部分文字仅在偏旁部首和笔画转折处呈现细微差异,且同类别铭文存在多种变体形式,特征信息差异性大,缺乏内在一致性;其次,青铜器年代久远,致使其表面遭受严重锈蚀,产生大量锈斑遮盖原有字体的偏旁部首,造成文字构件残缺。以上两点导致铭文难以获取与类别相匹配的特征,需要经验丰富的专家花费大量时间拆解文字的局部结构,再逐一比对细节特征,识别效率不高。
铭文的多类别形态指的是文字呈现出多种复杂形式,包括形近铭文、变体铭文和构件缺损铭文等不同表现形式。铭文识别多依赖于文字轮廓的全局特征[2]。罗彤瑶等人[3]提出融合形态特征的铭文分类方法,通过结合AlexNet网络[4]和SURF(speeded-up robust features)算子[5],旨在全面提取铭文的整体轮廓特征。然而对于同类别中存在显著差异的变体铭文和构件缺损铭文,仅通过整体轮廓的比对缺乏可信度。
细粒度特征学习为铭文识别提供了新的研究方向[6] 。受该思想启发,本文提出一种适用于多类别形态铭文的识别方法(MP-CNN),通过关注铭文图像多个独立的鉴别部位,解决文字高类内方差、低类间差异以及特征残缺的问题。在模型识别中,铭文图像的某一特征构件能够轻易区分其与不同类别时,卷积网络将会过分地依赖这一种学习到的特征,进而忽略其他部位产生的贡献。本文提出的部位识别方法,旨在通过单独的部位对铭文图像进行识别,学习文字具有鉴别力的细节特征,并通过相互增强的方式促进各独立部位学习更多的细粒度特征。在模型识别铭文时,若主要鉴别部位存在残缺,模型将定位和表示次要部位的特征,以弥补特征信息丢失导致的识别损失;对于形近铭文的识别,模型通过定位多个部位,获取不同特征部位的建议,以得到类别之间更具鉴别力的细微差异;而在变体铭文的识别中,模型采用独立的部位识别,消除对其他区域的依赖,优化与同类别相关的一组鉴别部位,总结文字结构的内部共通性[7]。本文期望通过以上方式,将模型应用于实际未隶定铭文的识别任务。
本文的主要贡献如下:基于多类别形态的未隶定铭文,设计了一种细粒度识别模型(MP-CNN)。首先是构建空间转换器[8],引导铭文对齐字形姿态,以减少多样化姿态对类内空间分布的影响,辅助模型在后续任务中准确定位鉴别性部位,其次是构建级联的ECA注意力[9]模块,以引导特征通道组合,选择性地定位多个具有独立鉴别能力的部位,并通过相互增强的方式细粒化地提取铭文的形态特征;最后是构建特征融合层,进一步利用部位集成的能力,获取综合识别结果,为释读工作提供更准确的参考意见。
1 相关工作
1.1 图像姿态对齐
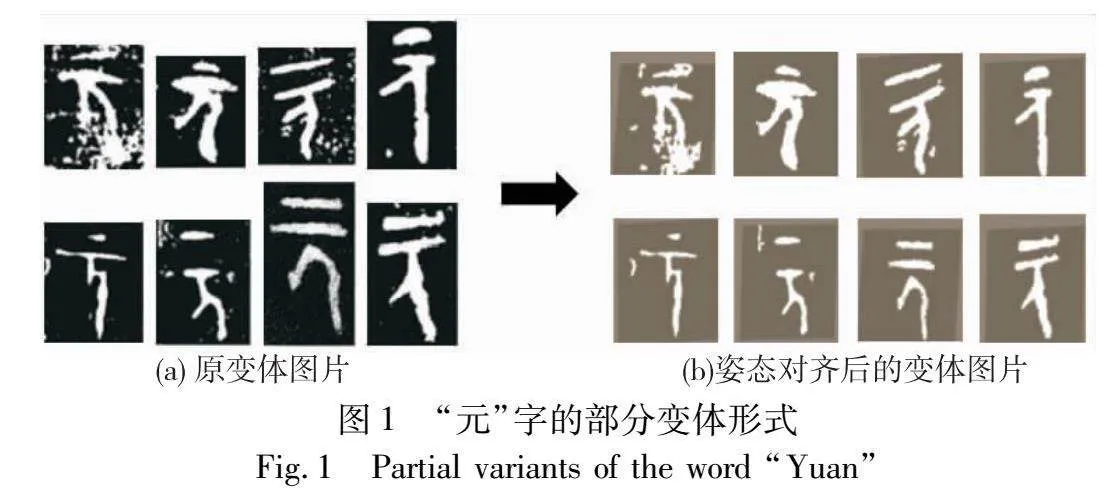
青铜器铭文类别繁多,不同书写者錾刻的变体形式风格迥异[10],例如字体的大小、位置和形态章法均各有千秋。传统卷积网络已被证实缺乏平移不变性[11],当铭文字体的结构位置发生偏移时,将会对识别结果产生影响。Wang等人[12]借助关键点估计算法学习图像的特征节点,并通过图卷积层匹配节点之间的关系信息,从而实现特征对齐。然而,铭文字体结构多变,缺乏明确的特征节点。Zhang等人[13]借助图像的局部特征信息,动态计算相似部位间的特征距离,以实现部位的姿态对齐。Liu等人[14]采用网络分层对齐的策略,以逐步校准图像的局部特征,解决姿态之间的空间错位问题。然而,由于铭文结构的特殊性,仅改变文字的局部形态易引起类别变化,所以期望模型能够基于字体的整体结构,对文字特征进行粗略对齐。其次,本文旨在卷积网络的层结构中使用姿态对齐模块,从而与网络形成端到端的学习,以协助特征提取模块从字体多样的姿态中推断出期望的形态轮廓,动态地矫正特征部位,达到缩小类内差异的目的。图1为“元”字的部分变体形式,图(a)中可以看出同类别铭文具有多样化的书写风格,文字的结构位置和形态大小均有差别。图(b)中通过空间转换器将铭文的空间位置、大小和姿态进行统一对齐。
1.2 细粒度图像识别
细粒度图像识别将目标对象划分为多个部分,主要方法分为强监督和弱监督模式下的特征学习两类。强监督方法除了使用类别级标签外,还利用边界框等额外注释定位图像的关键区域。 Zhang等人[15]提出基于目标层面的R-CNN方法,利用标注框辅助模型检测物体的关键部位。Huang等人[16]提出借助标注部位的堆叠策略,通过双分支结构定位目标对象的局部区域。Diao等人[17]基于多元异构数据提出一种联合学习的方法,通过融合视觉和元信息为模型提供充足的识别特征。然而,这些方法依赖于注释等额外信息,难以适用于大规模的铭文数据集。弱监督方法仅利用类别级标签,通过类激活映射等端到端的训练方式来定位鉴别区域。Hu等人[18]提出一种双线性注意力机制,用于定位图像的鉴别部位,并将定位区域进行裁剪和放大操作,从而捕获图像深层的细节特征。Wang等人[19]应用强大域适应性的ResNet50 IBN作为主干网络,增强模型特征提取的稳健性,并通过HDBSCAN算法聚类相邻特征,以引导模型学习类别间的鉴别信息。Chou等人[20]提出一种高温细化模块,通过逐层学习图像的全局和局部特征,以兼顾上下文结构的同时捕捉更为精细的鉴别特征。此外,该模型还结合了背景抑制模块用于去除图像噪声,以增强鉴别信息,实现相似图像的区分。然而,这些方法忽略了部位识别和特征学习的关系。独立的部位识别可以消除部位之间的依赖关系,进而优化相关部位的特征学习,提取更为准确的歧视性特征。同时,次要的鉴别部位也应在图像识别中受到关注,当主要特征不满足于鉴别相似的目标对象时,次要特征则起到关键的补充作用,这一点在识别形近铭文和构件缺损时尤为重要。
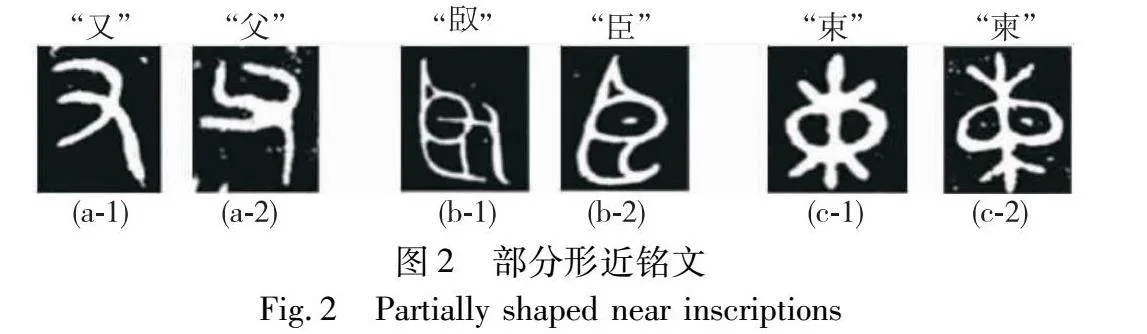
图2展示了三组不同类别的形近铭文,可以看出每组铭文具有相似的形态结构,其理想的鉴别部位仅在局部节点、笔画转折和偏旁构件等位置存在细微差异。
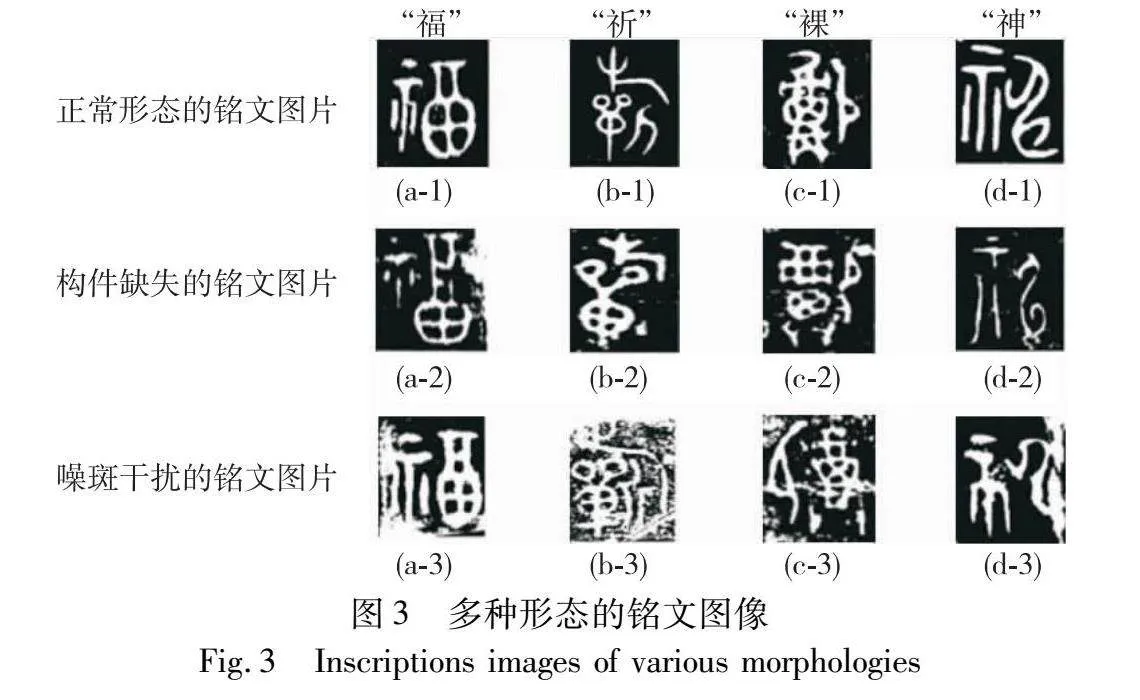
图3展示了多种形态的铭文图像。正常形态的铭文图像具有清晰的字体轮廓和完整的形态结构,构件缺损的铭文图像存在构件缺失。在第二行的铭文图像中,分别存在笔画缺失和部首缺失;在第三行的铭文图像中,分别存在噪斑和断痕。这些因素破坏了原始铭文字体的整体结构特征。
2 多注意力引导的卷积神经网络
青铜器铭文数据集涵盖了形近铭文、变体铭文以及构件缺损铭文等多种类别形式,具有高类内方差和低类间差异的特点。本文提出了一种细粒度识别的方法,即MP-CNN模型,旨在通过部位识别学习铭文鉴别性的特征,以解决实际场景中未隶定铭文的识别问题。模型结构通过姿态对齐、部位定位和特征融合三部分子网络构成,如图4所示。在MP-CNN模型中,采用ResNet34网络作为特征提取器,以提供基础特征。由于铭文涵盖众多类别,且每个类别的样本数量存在严重失衡,所以需要卷积网络具备一定的深度,同时保持良好的收敛效果,以提供充足的特征通道图,用于定位多个有效的鉴别部位。ResNet34网络引入了残差块,即恒等映射层,通过跳跃连接的方式,有效解决了不均衡数据在超深结构中容易过拟合的问题,从而不断挖掘铭文图像中各种鉴别性特征。
2.1 姿态对齐模块
姿态对齐模块旨在降低铭文的类内空间分布,辅助模型在后续任务中准确定位鉴别性部位。主要起到两个作用:首先,通过空间变换器降低铭文姿态对识别的干扰,使卷积网络在一定程度上保持字体形态的空间一致性,将铭文多样的姿态统一对齐为规范的、期待的样式,有助于模型准确定位鉴别性部位。其次,在铭文图像背景中存在噪斑,通过空间变换器剪裁图像边缘位置的噪斑,以抑制背景噪声。
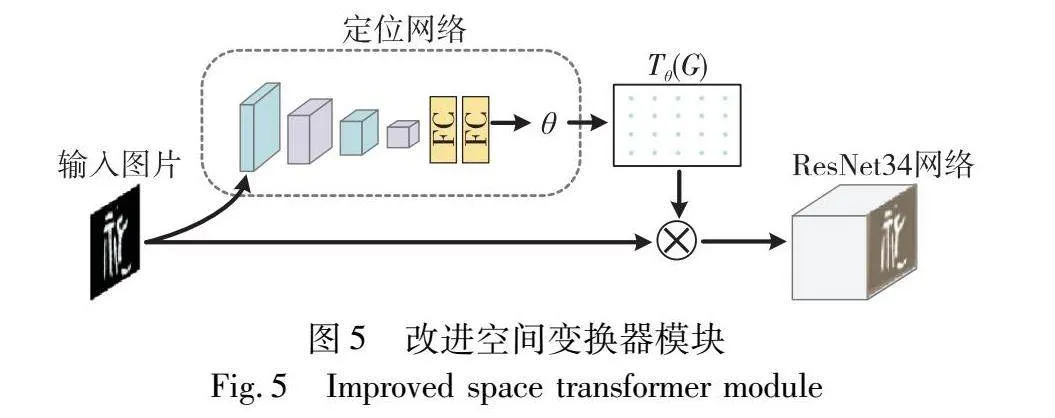
空间变换器由定位网络、采样网格和图像采样三部分构成。作为可微分模块并联接入ResNet34网络第一个卷积结构前,对每张输入的铭文图片,产生适当的空间位置变换。如图5所示,第一部分用于计算定位网络的输出参数θ,作为铭文图像空间变换的依据;第二部分利用预测的空间变换系数创建采样网格,并定义采样点处的像素;第三部分将输入图片与采样网格结合,生成姿态矫正后的铭文图片,提供给ResNet34网络进行特征提取。本文模型针对铭文类别中数量的不均衡性问题,通过优化空间变换器的网络层数以及卷积核数,减少对特定特征的依赖,这有效地避免了模型过度拟合每一种形态g1GjksnVqOOtUt5w/3SGrg==的铭文结构,提高网络的泛化能力。
定位网络接受输入的铭文图像X∈Euclid ExtraaBpH×W×C,其中H、W 和C分别为输入图片的高度、宽度和通道数。定位网络结构采用优化的AlexNet提取目标特征,在其基础架构上将5层卷积减少至4层。同时,限制每一层卷积核数最多为128,以降低模型的复杂度。随后,通过全连接层输出预测的空间变换参数θ=floc(X),即为应用于铭文图片二维仿射变换的系数Aθ。
Aθ=floc(X)=θ11θ12θ13θ21θ22θ23(1)
其中:二维仿射系数Aθ用于网络对输入的铭文图片进行裁剪、旋转和缩放的操作,同时通过裁剪可以去除边缘噪斑,从而增强图像中的目标对象。
采样网格用于执行输入铭文图像对应的输出映射变换。输出的映射图像Y∈Euclid ExtraaBpH1×W1×C1由位于规则采样网格上的像素Gi=(uti,vti)形成,其中H1、W1 和C1分别为变换后的高度、宽度和通道数。将其与二维仿射变换矩阵相结合,得到输出铭文图像特征映射Y在每个输入铭文图像特征映射X中对应的坐标位置,即为生成的采样网格Tθ(Gi)。
usivsi=Tθ(Gi)=Aθutivti1=θ11θ12θ13θ21θ22θ23utivti1(2)
其中:输入铭文图像的采样点由源坐标(usi,vsi)构成,输出特征图在规则网格上的目标坐标由(uti,vti)构成。在生成转换期间,通过定位网络查找并框选出铭文图像中的目标文字,从而生成相应的网格Gi。
通过采样网格,在输入铭文特征图X中寻找相应空间位置坐标(usi,vsi)处的像素值。使用双线性插值算法作为采样核,以同等方式计算不同通道下输出铭文图像的目标像素值,将其在经过空间转换后映射到给定输出坐标处的像素值Yci。
Yci=∑Hh∑WwXchwmax(0,1-usi-w)max(0,1-vsi-h)(3)
其中:Xchw代表输入铭文图像中第c维通道特征图对应空间坐标(h,w)处的像素值。通过像素间的局部相似性原理,取最邻近的像素点生成均值,填补铭文目标映射对应特征通道图中缺失的像素值Yci。同时,双线性采样具有可微分性质,允许使用反向传播,将梯度损失传递至定位网络的各层,从而不断更新输出参数,形成完整的端到端学习。
2.2 部位定位模块
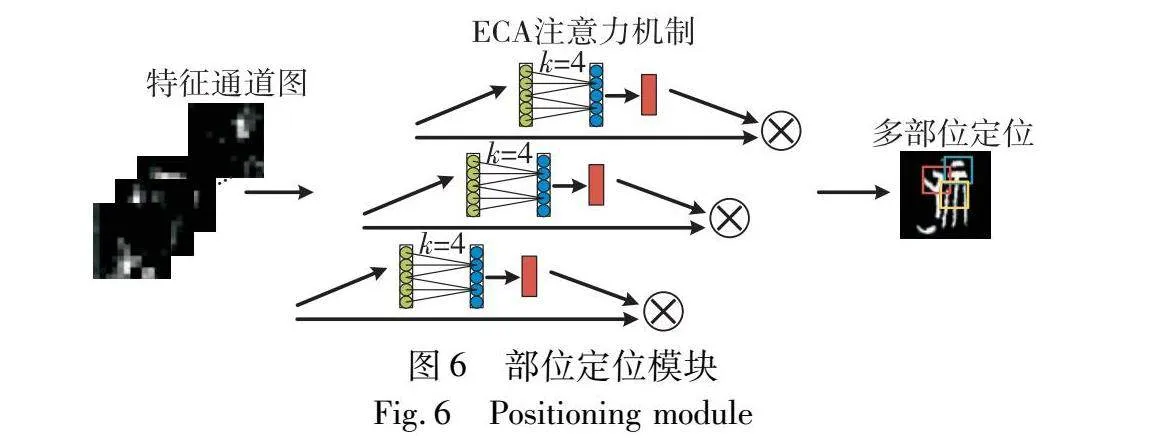
部位定位模块旨在对铭文图像实现细粒度识别,解决形近铭文、变体铭文以及构件缺损铭文的识别任务。主要起到两个作用:首先,利用通道特征图多样化的峰值响应,聚类一组最高峰值响应位置相邻的通道特征图,用于生成部位注意力图,以定位一个独立的鉴别区域。其次,通过各个独立的部位对铭文图像进行识别,交替学习对应部位的识别损失,并将学习结果回流至特征提取网络,使得部位识别和特征学习相互增强,促进模型提取更有鉴别性的特征,从而解决文字高类内方差、低类间差异以及特征残缺的问题。
如图6所示,部位定位模块通过级联ECA注意力机制,对输入的特征图进行聚类和部位定位。将姿态对齐的铭文图片X′ 输入ResNet34网络,卷积层中不同通道对铭文形态的关键信息有不同的感知能力,因此,将特征通道图展开,得到各通道对应的激活区域。其中,将每个特征通道表示为位置向量,最高响应值的坐标作为此通道的代表特征。
[l1x,l1y,l2x,l2y,…,lmx,lmy,…,lΩx,lΩy](4)
其中:lmx、lmy代表训练集中第m张铭文图片最高响应值的坐标;Ω为训练集的总数量。通过聚类不同通道相邻最高响应位置作为一簇,代表铭文图像的一组鉴别性部位,并对每一簇进行编码。
[1{1},1{2},…,1{C}](5)
其中:C代表第m张铭文图像经过ResNet34网络后的输出特征通道数目;1{·}代表当前通道是否属于对应簇,若属于则设置为1,若不属于则设置为0。由此聚类n个鉴别性部位。然而,特征通道硬性编码的分组方式不能确保网络进行反向传播。因此,采用每个ECA注意力机制对应一簇,代表一个部位注意力图。同时,通过一维卷积学习跨通道的交互关系,以近似编码产生各特征通道图的权重,并希望通过训练,使得分组卷积层的权重向量尽可能地趋近硬性编码。假设ResNet34提取得到铭文特征图为X″∈Euclid ExtraaBpW×H×C,每个ECA注意力层接受各通道的输入,产生一簇权重。首先,利用全局平均池化层d收缩铭文特征图的空间维度,将其空间信息聚合为d∈Euclid ExtraaBpc,有助于通道维度间的交互。
d(X″)=1W×H ∑W,Hi=1,j=1X″ij(6)
其次,采用卷积操作捕获局部通道间的依赖关系。铭文图片中第c维特征通道图dc,仅通过k=4个相邻特征通道之间的相互作用生成权重qn,文献[9]中表明当k=4时, ECA注意力机制具有最好的鲁棒性。
qnc(d)=∑kj=1wjcdjc(7)
其中:qn=[qn1,qn2,…,qnC]代表第n簇部位特征通道分组对应的权重;djc是第j张通道图的c×c维参数矩阵。通过训练使得权重qnc(d)≈[1{1},1{2},…,1{C}],并采用sigmoid函数归一化特征通道,依次得到对应的部位注意力特征图Mn。
Mn(X″)=sigmoid(∑Cc=1qncX″c)(8)
最后,对得到的部位注意力特征图进一步归一化。
Pn(X″)=∑Cc=1(MnX″c)(9)
部位定位网络通过级联ECA注意力机制,引导通道特征图进行分组,强调携带关键信息的特征通道,定位多个鉴别性部位。
2.3 特征融合模块
特征融合模块旨在利用部位集成获取全面的识别结果,主要作用为:充分考虑不同部位携带特征的能力存在显著差异。因此,为了避免使用均等权重以削弱最优辨别部位在识别中的贡献,从而采用了自适应加权融合特征的策略,以更精准地衡量各个部位的重要程度。
将n个部位以及基础特征进行加性融合,得到对应权重α′f,从而增强模型对最优辨别部位的关注度。
α′f=eωf∑n+1r=1eωr f=1,2,…,n+1(10)
其中:ωf为初始化指数权重;ωr为各特征权重。采用加性融合叠加各特征Pf,得出未隶定铭文的综合识别得分Ftotal。
Ftotal=∑nf=1α′fPf(11)
3 实验结果及分析
本文实验基于Windows 10操作系统,采用PyTorch 1.7.0深度学习框架搭建模型的基本环境,实验设备为AMD Ryzen 9 5900X 12-Core Processor 3.70 GHz处理器和NVIDIA GeForce 下RTX 3090 GPU。
3.1 实验数据集
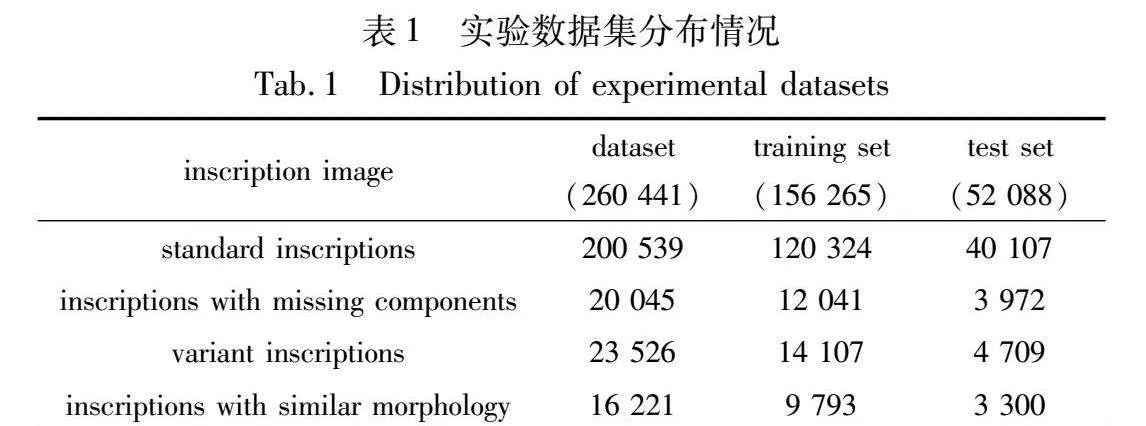
实验数据来源于《新金文编》全三册,该著作中铭文图像一律采用计算机剪贴原始拓片的方式,以最大化保留出土铭文的形态构造。为了进一步验证提出算法在未隶定铭文识别实际应用过程中的有效性,将其分为两类数据集进行对照,分别为标准数据集和多类别形态的铭文数据集。
a)标准数据集中仅包含形态结构完整且类别间差异较大的铭文图像,共整理出2 647个类别,每个类别包含3~80张铭文图像。
b)多类别形态的铭文数据集中包含了形近铭文、变体铭文和构件缺损铭文等多种类别形态的铭文图像,以模拟实际应用中末隶定铭文形态特征的不稳定性。该数据集共整理出2 647个类别,每个类别包含3~80张铭文图像。如图7所示为两类数据展示。
经过数据预处理后,将铭文图像的像素大小统一为224×224,按照6∶2∶2的分配比例随机为两种数据集划分出训练集、验证集和测试集,实验数据分布如表1所示。
3.2 实验参数设置
实验采用图4所示的MP-CNN模型结构,通过分阶段训练的方式使用梯度下降法完成模型权重参数的学习。batch size设置为128,第一步使用Adam优化器训练ResNet34_ST网络,epochs设置为50,learning_rate设置为0.000 1,以实现铭文图像的特征提取和姿态对齐。第二步固定ResNet34_ST学到的权重,使用Adam优化器训练ECA注意力机制,epochs设置为5,learning_rate设置为0.001,以引导模型准确定位各鉴别性部位。第三步使用SGD优化器训练整个模型,epochs设置为30,以全局优化调整各部位的特征权重。
3.3 消融实验
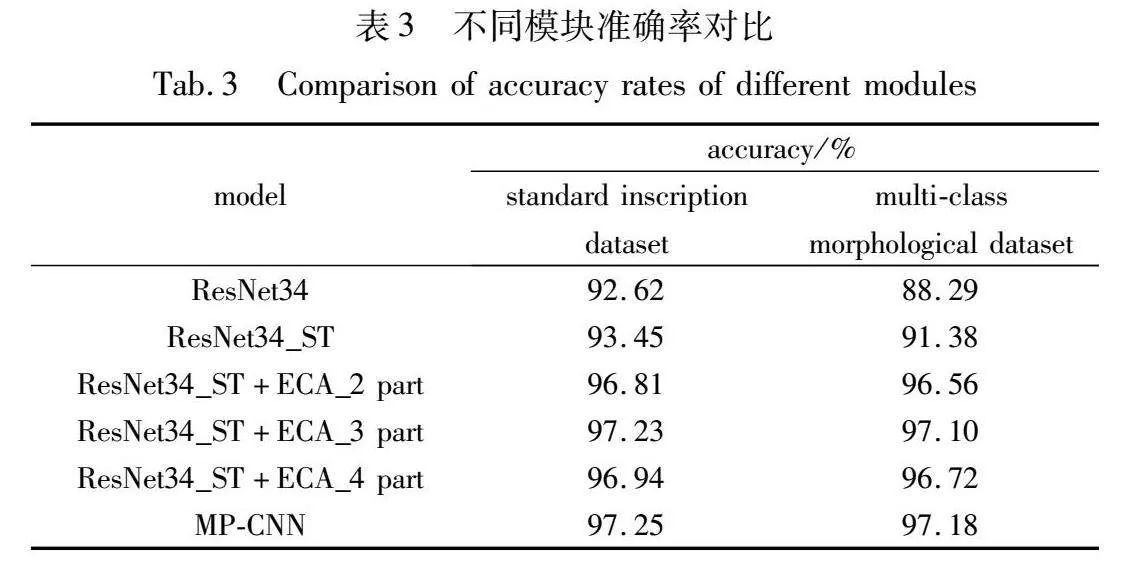
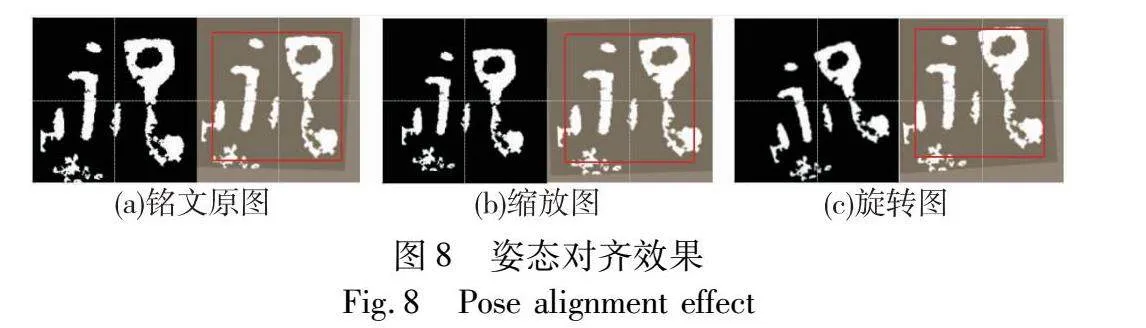
为验证改进的空间转换器的有效性,本文在标准和多类别形态的铭文数据集上,以ResNet34网络作为识别框架,对比了空间变换器中不同配置的定位网络,包括传统的AlexNet、精简层数的AlexNet、精简卷积核数的AlexNet以及本文提出的AlexNet。实验结果如表2所示,本文模型在两种数据集中表现出优于其他对比网络的性能。尽管不同铭文呈现多样性的姿态,但每个类别的图像数目仍然存在不均衡性,对网络的抗拟合能力提出了较高的要求。本文模型在更少参数量和计算复杂度的情况下,展现出更高的准确性。图8展示了姿态矫正后的效果图,其中,图(a)为原始的铭文图像;图(b)为对原始铭文图像进行了缩小处理;而图(c)在缩小后的铭文图像上再次施加了旋转操作。通过使用空间转换器实现文字姿态的对齐,使得不同尺度大小和结构位置的铭文图像能够在统一尺度下对齐至图像中心。
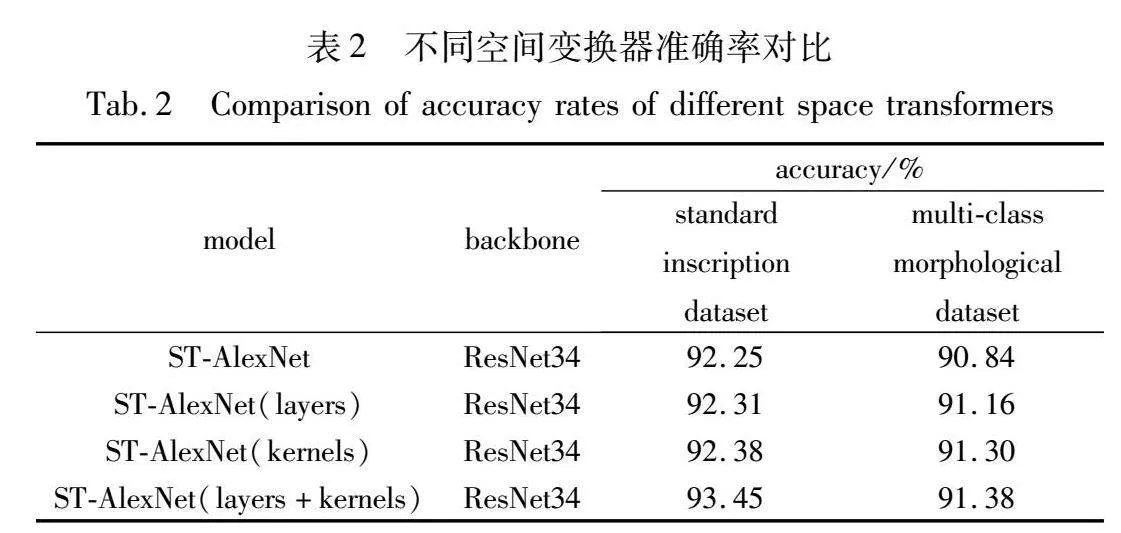
为了评估各模块对未隶定铭文识别的有效性,本文在两种铭文数据集上验证了不同模块的识别准确率,包括Resnet34网络、加入空间转换器的ResNet34_ST网络、两部位定位的ResNet34_ST+ECA_2 part网络、三部位定位的ResNet34_ST+ECA_3 part网络和四部位定位的ResNet34_ST+ECA_4 part网络,实验结果如表3所示。
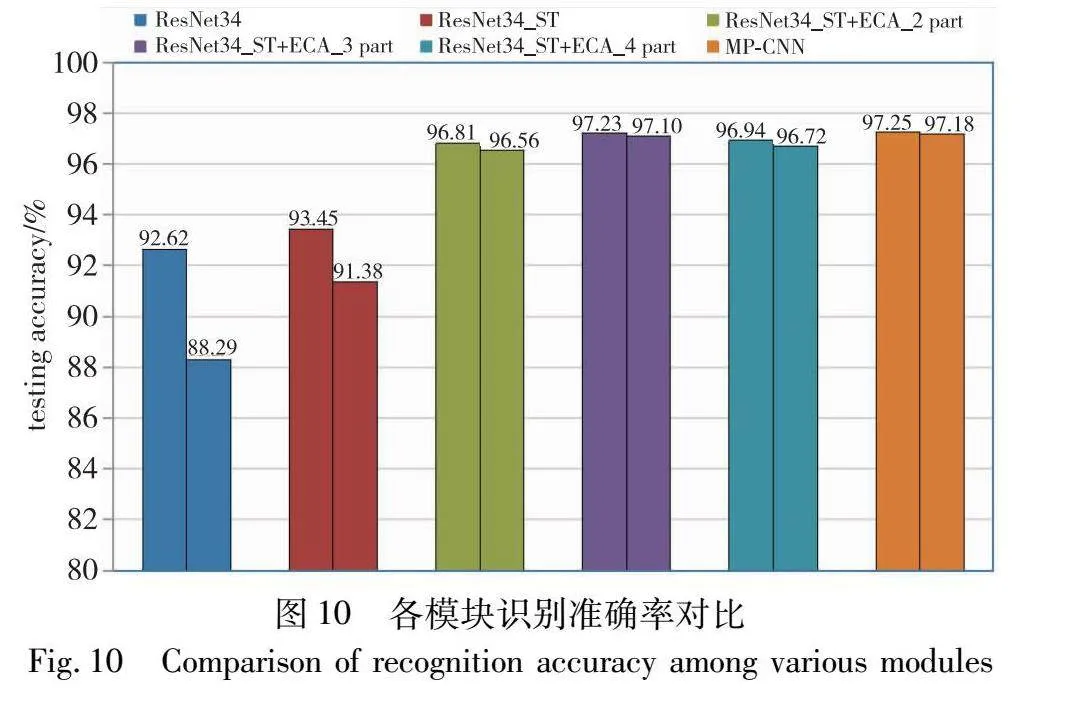
在两种数据集上,传统ResNet34模型的识别准确率分别为92.62%和88.29%。通过加入空间转换器对齐铭文姿态,有效地减小了类内空间分布的差异,使得定位区域更加精准,识别准确率提高至93.45%和91.38% 。进一步加入两个ECA注意力机制,用于定位两个独立的鉴别部位,以应对单一焦点区域存在噪斑和特征缺失,模型的识别准确率提升了3.36百分点和5.18百分点。当加入三个ECA注意力机制时,模型的识别准确率再次提高了0.42百分点和0.54百分点,表明两个独立的鉴别部位仍然不足以充分表达铭文多样化的形态特征。模型加至四个ECA注意力机制后,部分焦点区域重叠,特征信息开始产生冗余,识别准确率分别下降了0.29百分点和0.38百分点,表现出过拟合状态。图9展示在三种姿态下,五个模块区域定位的效果图。在图(b)中,受到铭文字体大小和角度的影响,定位区域产生偏移;在图(c)中,经过空间变换器对齐文字姿态,模型能够更加精准地定位鉴别区域;在图(d)中,模型定位了两个有效的鉴别部位;在图(e)中,模型定位了三个有效的鉴别部位,其中仅存在轻微的区域重叠;在图(f)中,重叠区域增加,蓝色方框区域即为冗余定位区域。
为了进一步分析各模块的有效性,图10展示了各部分消融模块的识别准确率条形图(参见电子版)。在标准数据集中,不同模块的识别准确率均高于复杂形态下的铭文数据集,而准确率差值主要源于形近铭文、变体铭文和构件缺损铭文等识别误差的影响。随着空间变换器、ECA注意力机制和加权机制的逐步引入,识别准确率差值由4.43百分点不断缩小至0.07百分点。这一趋势表明,通过逐步引入消融模块,MP-CNN模型在实际应用中的泛化能力得到了显著提升。
3.4 对比实验
为验证所提出模型的有效性,本文在两种铭文数据集上采用同等的参数配置,并以精确率(accuracy)作为评价指标,综合评估了本文MP-CNN模型与传统模型、相关铭文识别模型以及细粒度识别模型的性能表现。
青铜器铭文的识别因其具有独特的形态结构而具有挑战性,其中部分文字结构受到严重的风化腐蚀,导致大量团状噪斑和构件缺损。为验证MP-CNN模型相较于传统卷积网络,本文在表4中将MP-CNN模型与传统网络对复杂形态铭文的特征提取能力进行了对比。纵向观察,MP-CNN模型的识别准确率均优于传统网络,这表明传统网络粗粒度的特征提取方式直接应用于铭文识别,难以充分捕捉文字的形态特征。横向观察,在两种数据集下,AlexNet相差5.32百分点,VGG16网络相差1.22百分点,ResNet34网络相差4.33百分点,而MP-CNN模型相差0.07百分点,这表明传统网络在应对形近铭文、变体铭文以及构件缺损的铭文时,难以精准地定位至有效的鉴别部位。
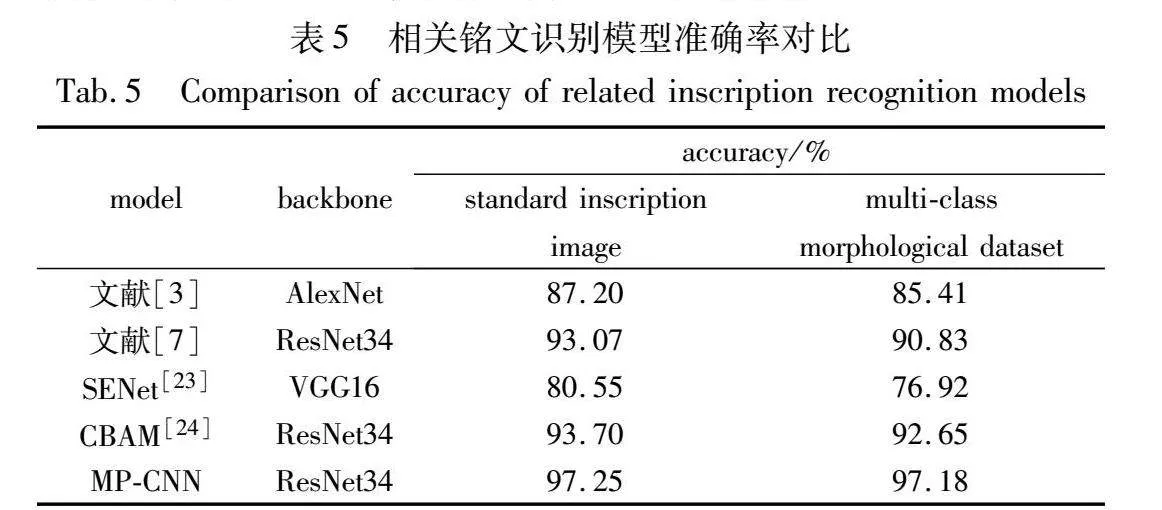
表5展示了两种数据集下,MP-CNN模型和相关铭文识别模型的对比。文献[3,7]中,分别采用两阶段映射和融合算法,旨在关注文字更多的细微特征,以区分形近字体。SENet[23]和CBAM[24]利用注意力机制引导模型关注文字更具鉴别性的位置,但受限于模型提取鉴别性特征的能力。相较之下,MP-CNN模型通过定位多个独立的辨别部位,获取更多精准的鉴别特征,解决铭文图像中高类内方差、低类间差异的问题,并取得了最佳的性能结果。
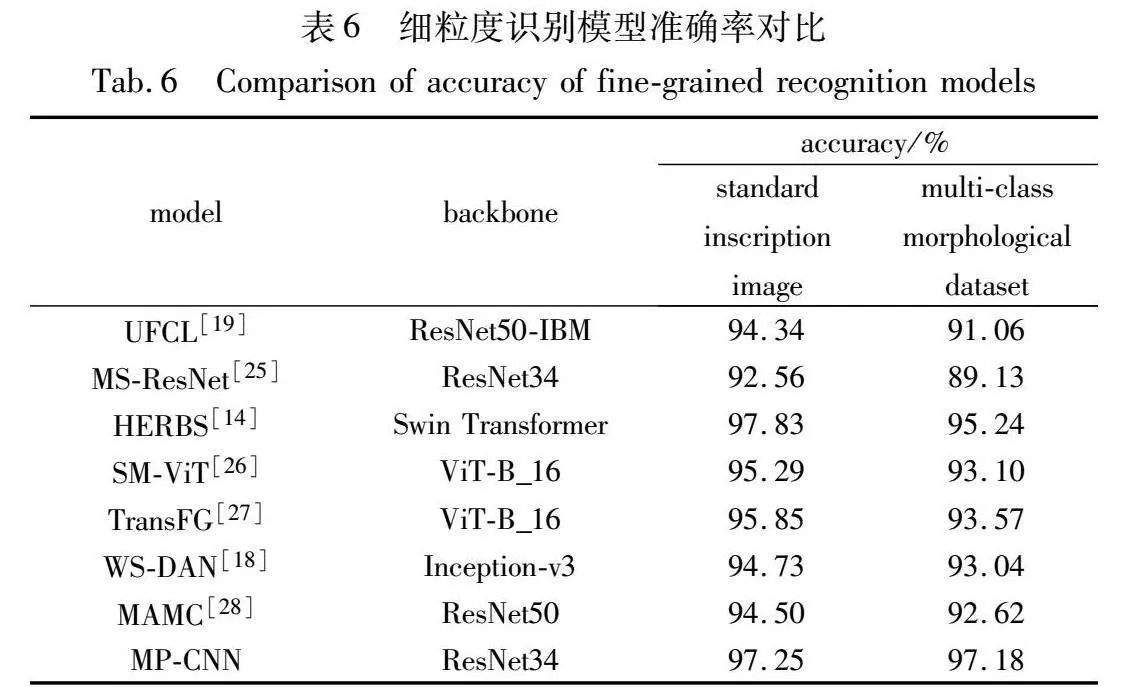
表6展示了两种数据集下,本文MP-CNN模型和细粒度识别模型的对比。UFCL算法[19]通过聚类相邻特征引导模型学习类别间的鉴别信息;MS-ResNet算法[25]通过融合多尺度特征获取充分的细节信息。这两种算法旨在获取图像中的歧视性特征,以区分相似图像,在铭文标准数据集中准确率分别为94.34%和91.06%。然而,在多类别形态的铭文数据集中,识别准确率分别下降了3.28百分点和3.43百分点。模型主要关注于歧视性区域,从而忽略次要部位对于识别的贡献。变体铭文多存在局部结构的变化,且部分铭文背景存在噪斑,模型容易错误地将其识别为有价值的鉴别信息。HERBS算法[14]通过高温细化模块逐层学习图像特征,并结合背景抑制模块增强目标对象;SM-ViT算法[26]通过生成目标对象的掩码引导模型提取鉴别性的局部特征;TransFG算法[27]通过部位选择模块引导模型准确定位鉴别特征。这三种算法虽然增强了目标对象,但是依赖于特征间的关系,忽略了独立部位对识别的作用,难以用于识别构件存在缺损的铭文。在多类别形态的铭文数据集中,识别准确率分别下降2.59百分点、2.19百分点和2.28百分点。WS-DAN算法[18]和MAMC算法[28]通过类激活映射定位图像多个具有鉴别性的局部区域,引导模型提取局部细节特征。这两种算法充分利用了主要和次要鉴别部位,但是忽略了部位识别和特征学习的关系,在多类别形态的铭文数据集中,识别准确率分别下降1.69百分点和1.88百分点。MP-CNN算法通过姿态对齐模块增强目标对象,降低图像的类内差异,其次利用部位识别消除特征间的依赖关系,学习文字具有鉴别力的特征。相较于前述算法,提出模型在标准数据集上识别准确率为97.25%,在多类别形态的铭文数据集上,识别准确率为97.18%,略微下降0.07百分点。
图11展示了不同算法对于标准形态的铭文(A-1)、构件缺损的铭文(A-2)和噪斑干扰的铭文(A-3)的可视化结果,其中,区域亮度表示注意力权重的分布。文献[8]和UFCL算法关注于大面积的焦点区域;其余算法关注于局部的多个鉴别部位。在识别存在缺损和噪斑的铭文图像时,由于缺损位置和噪斑区域存在特征丢失,模型的关注焦点产生偏移。MP-CNN模型采用三个ECA注意力机制,将整片连续的焦点区域替换为独立的部位,以捕捉主要和次要鉴别特征。即使主要特征存在偏差,该模型仍能利用剩余部位完成铭文识别。
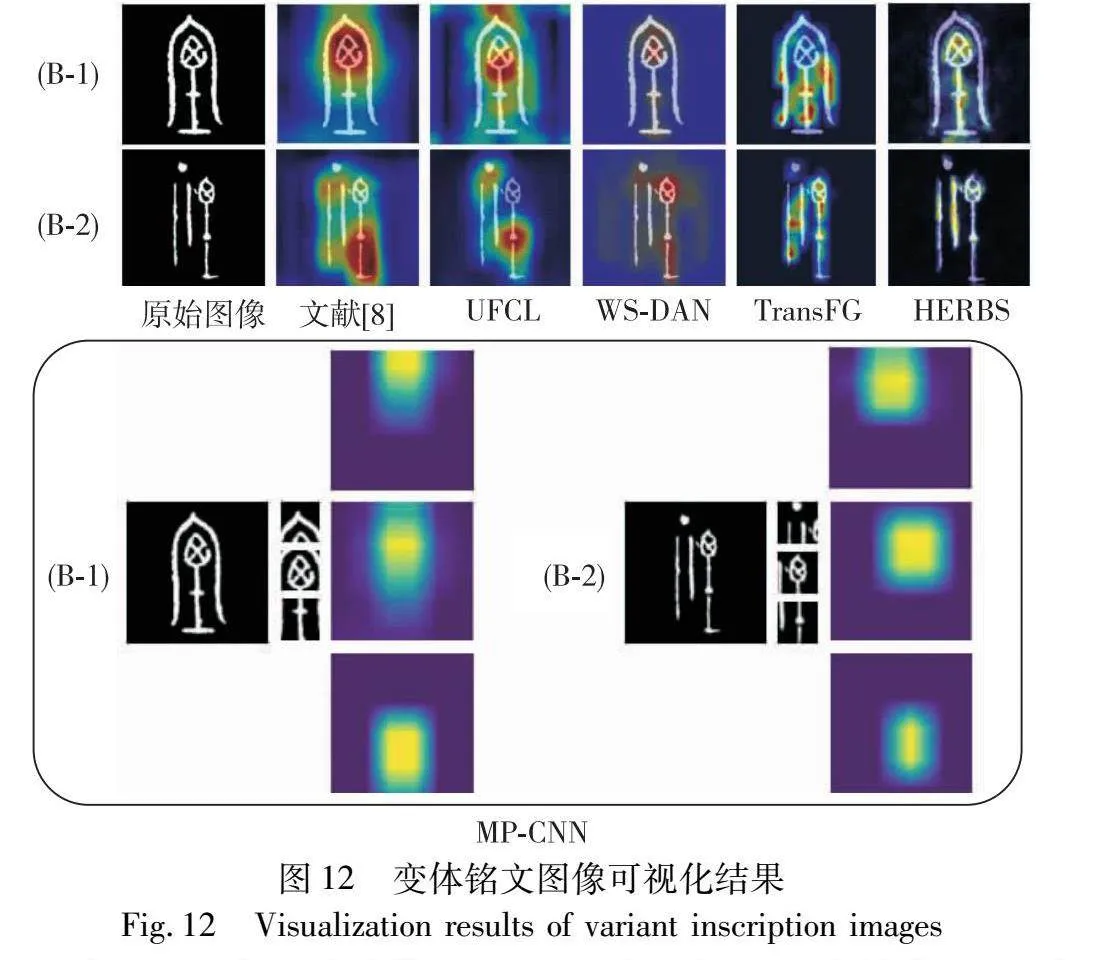
图12展示了同一类别中变体铭文的可视化结果。识别此类文字的关键在于模型能够准确地总结字体结构的内在一致性。文献[8]、UFCL算法和TransFG算法分别定位于两个变体文字的不同结构区域,未能准确地总结出文字真正的歧视性特征;WS-DAN算法基本能够定位于字体的相同结构部位,较为准确地总结出文字的鉴别特征;HERBS算法在定位鉴别区域时存在部分偏差。MP-CNN模型则通过消除区域依赖,分别定位于文字的三个独立部位,其中两个部位的定位区域基本一致,能够较为准确地总结出文字的鉴别特征,应用于部位识别。
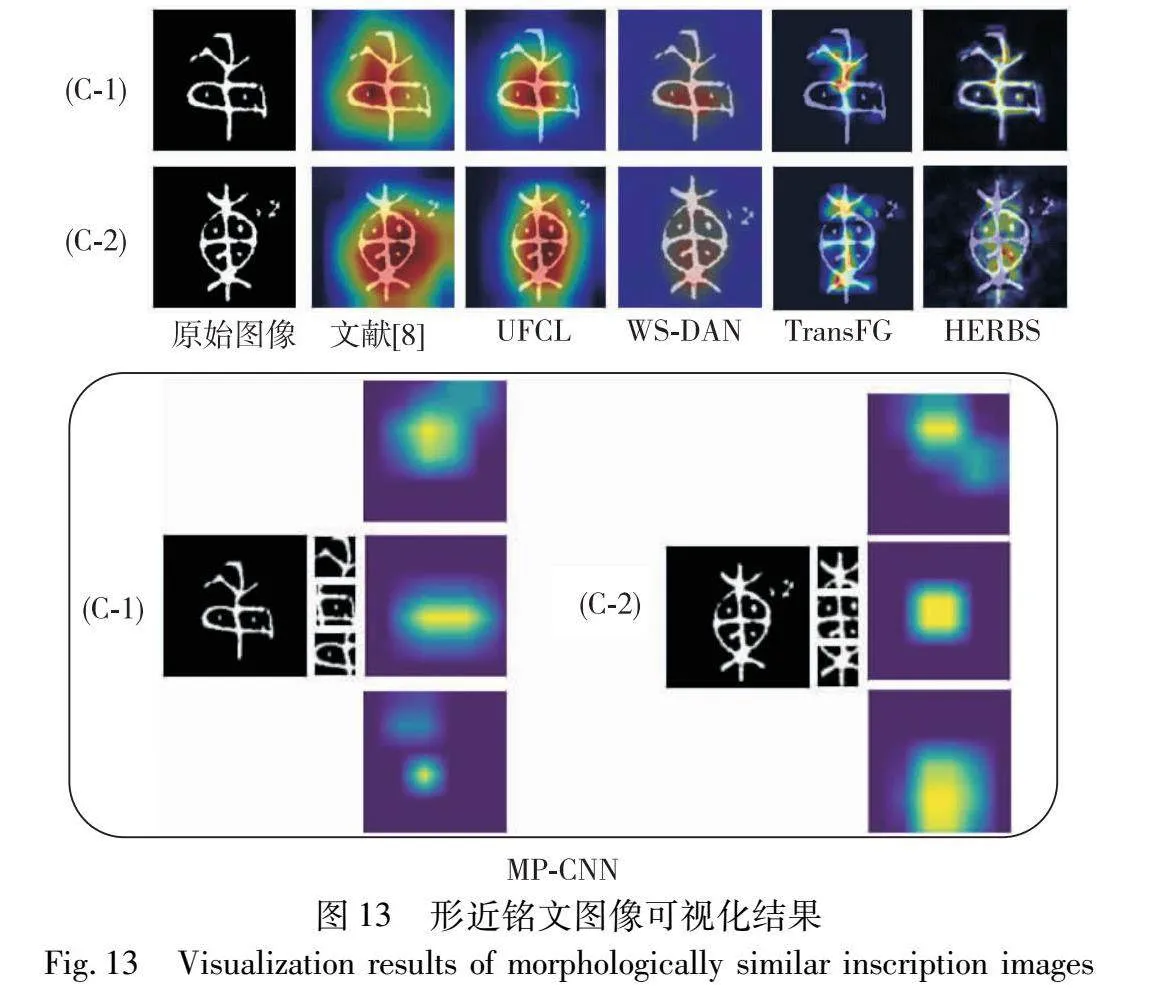
图13展示了不同类别中形近铭文的可视化结果。文献[8]聚焦于文字的整片焦点区域,其他细粒度算法能够更加准确地定位到鉴别区域,提取文字歧视性特征。MP-CNN模型通过部位识别和特征学习相互增强,以精确获取类别之间的细微差异。
4 结束语
本文提出一种细粒度识别的方法,即MP-CNN模型,该方法在多类别形态的未隶定铭文识别任务中展现出卓越性能。本文方法借助空间转换器引导铭文对齐字形姿态,从而减少多样化姿态对类内空间分布的影响。其次,借助独立的鉴别部位实现铭文的部位识别,并通过部位识别和特征学习相互增强的方式,学习文字更具有鉴别力的细节特征,解决铭文图像中高类内方差、低类间差异以及部位残缺的问题。实验结果表明,MP-CNN模型在标准数据集和多类别形态的铭文数据集上的识别准确率分别为97.25%和97.18%,均优于对比模型,该方法在解决实际场景中未隶定铭文的识别问题上取得了显著成效,为相关释读工作提供了更为准确的参考意见。
参考文献:
[1]王固生. 青铜时代——中国青铜器基本知识与辩伪[J]. 收藏界, 2018(5): 86-89. (Wang Gusheng. The bronze age—basic know-ledge of Chinese bronze wares and counterfeiting[J]. Collectors, 2018(5): 86-89.)
[2]李零. 青铜器铭文考释 (三则)[J]. 中国国家博物馆馆刊, 2022(4): 30-37. (Li Ling. Interpretation of three pieces bronze inscriptions[J]. Journal of the National Museum of ChLC46gJzafN2vi/pyBP7I6w==ina, 2022(4): 30-37.)
[3]罗彤瑶, 王慧琴, 王可, 等. 融合形态特征的小样本青铜器铭文分类算法[J]. 激光与光电子学进展, 2023, 60(4): 175-184. (Luo Tongyao, Wang Huiqin, Wang Ke, et al. Small-sample bronze inscription classification algorithm based on morphological features[J]. Advances in Laser and Optoelectronics, 2023, 60(4): 175-184.)
[4]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[5]Bay H, Ess A, Tuytelaars T, et al. Speeded-up robust features(SURF)[J]. Computer Vision and Image Understanding, 2008, 110(3): 346-359.
[6]赵婷婷, 高欢, 常玉广, 等. 基于知识蒸馏与目标区域选取的细粒度图像分类方法[J]. 计算机应用研究, 2023, 40(9): 2863-2868. (Zhao Tingting, Gao Huan, Chang Yuguang, et al. Fine-grained visual classification method based on knowledge distillation and target regions selection[J]. Application Research of Compu-ters, 2023, 40(9): 2863-2868.)
[7]李文英, 曹斌, 曹春水, 等. 一种基于深度学习的青铜器铭文识别方法[J]. 自动化学报, 2018, 44(11): 2023-2030. (Li Wen-ying, Cao Bin, Cao Chunshui, et al. A deep learning based method for bronze inscription recognition[J]. Acta Automatica Sinica, 2018, 44(11): 2023-2030.)
[8]Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[J]. Advances in Neural Information Processing Systems, 2015, 28.
[9]Wang Qilong, Wu Banggu, Zhu Pengfei, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 11534-11542.
[10]马承源. 中国古代青铜器[M]. 2版. 上海: 上海人民出版社, 2016: 9-41. (Ma Chengyuan. Ancient Chinese bronze wares[M]. 2nd ed. Shanghai: Shanghai People’s Publishing House, 2016: 9-41.)
[11]Lenc K, Vedaldi A. Understanding image representations by measu-ring their equivariance and equivalence[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2015: 991-999.
[12]Wang Guan’an, Yang Shuo, Liu Huanyu, et al. High-order information matters: learning relation and topology for occluded person re-identification[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 6449-6458.
[13]Zhang Xuan, Luo Hao, Fan Xing, et al. Alignedreid: surpassing human-level performance in person re-identification[EB/OL]. (2017). https://arxiv.org/abs/1711.08184.
[14]Liugwqiw7QEJkGIgo/Q1bo6EA== Zhenguang, Feng Runyang, Chen Haoming, et al. Temporal feature alignment and mutual information maximization for video-based human pose estimation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 11006-11016.
[15]Zhang Ning, Donahue J, Girshick R, et al. Part-based R-CNNs for fine-grained category detection[C]//Proc of the 13th European Conference on Computer Vision. Cham:Springer International Publishing, 2014: 834-849.
[16]Huang Shaoli, Xu Zhe, Tao Dacheng, et al. Part-stacked CNN for fine-grained visual categorization[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press, 2016: 1173-1182.
[17]Diao Qishuai, Jiang Yi, Wen Bin, et al. MetaFormer: a unified meta framework for fine-grained recognition[EB/OL]. (2022). https://arxiv.org/abs/2203.02751.
[18]Hu Tao, Qi Honggang, Huang Qingming, et al. See better before looking closer: weakly supervised data augmentation network for fine-grained visual classification[EB/OL].(2019).https://arxiv.org/abs/1901.09891.
[19]Wang Jiabao, Li Yang, Wei Xiushen, et al. Bridge the gap between supervised and unsupervised learning for fine-grained classification[J]. Information Sciences, 2023, 649: 119653.
[20]Chou Poyung, Kao Yuyung, Lin Chenghung. Fine-grained visual classification with high-temperature refinement and background sup-pression[EB/OL]. (2023).https://arxiv.org/abs/2303. 06442.[21]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2014). https://arxiv.org/abs/1409.1556.
[22]Wang Fei, Jiang Mengqing, Qian Chen, et al. Residual attention network for image classification[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press, 2017: 3156-3164.
[23]Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press, 2018: 7132-7141.
[24]Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 3-19.
[25]Du Mengxiu, Wang Huiqin, Liu Rui, et al. Research on bone stick text recognition method with multi-scale feature fusion[J]. Applied Sciences, 2022, 12(24): 12507.
[26]Demidov D, Sharif M H, Abdurahimov A, et al. Salient mask-guided vision transformer for fine-Grained classification[EB/OL]. (2023).https://arxiv.org/abs/2305.07102.
[27]He Ju, Chen Jieneng, Liu Shuai,et al. TransFG: a transformer architecture for fine-grained recognition[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 852-860.
[28]Sun Ming, Yuan Yuchen, Zhou Feng, et al. Multi-attention multi-class constraint for fine-grained image recognition[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 805-821.
