
基于本土对象数据集的人工智能教学
2024-10-12 00:00:00陈凯
中国信息技术教育 2024年19期


摘要:本文围绕具有跨学科特性的利用人工智能进行校园植物观测的活动,探讨用于人工智能学习的本土对象的数据集构建的相关问题,提出应该从学生日常生活出发,结合真实情境,为数据采集和分类任务建立具有一定合理性、真实性的目标框架,可以为分类目标限定范围,分类任务中的对象的特征既要有相似性又要有区分度,可以通过计算机视觉库的自动化处理来提高特征数据采集和记录的效率。
关键词:人工智能;自然观测;数据集
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2024)19-0015-04
用于人工智能教学的数据集可以是人为主动生成的,如用摄像头拍摄手势、用加速度传感器记录人的运动状态、对电脑中的涂鸦截屏等,也可以利用机器学习库生成某些带有随机性的数据。更多情况下,数据集的数据来自真实环境中某些对象的特征,如道路、建筑、动物、植物等对象的某些特征数据。对于具有跨学科特征的与自然观测相关的实践活动或自主研究项目,往往希望学生能够完整地体验到在自然环境中采集数据、整理数据、处理和分析数据的过程,其中面临的一些问题就是应当采集哪些对象的数据、采集哪一方面特征的数据、如何采集数据等。
虽然有很多数据集采集自真实世界中的某种自然的对象,但它们可能距离学生的生活较远。例如,鸢尾花数据集(Iris Dataset)是在机器学习和统计学中常用的一个经典数据集,该数据集包含了150个样本,分为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)三种类别,每类包含50个样本,每个样本有花萼长度(Sepal Length)、花萼宽度(Sepal Width)、花瓣长度(Petal Length)和花瓣宽度(Petal Width)四个特征。由于数据集结构简单且易于理解,常被用作人工智能教学中的示例或实验素材。可是,由于活动范围的限制,笔者尚未亲眼见到鸢尾花数据集中三种鸢尾中的任意一种,笔者所处的上海市区,常见的是公园中作为园林花卉栽种的路易斯安那鸢尾、西伯利亚鸢尾或日本鸢尾。但这些鸢尾采集数据却存在颇多问题,如:较少有学校同时种植多个品种的鸢尾;鸢尾花虽然花期可能长达三个月,但对于全年的教学安排来说,可供观察和记录数据的时间相对有限;较少有供学生自由对鸢尾花开展测量的场所;这些种类的鸢尾花的颜色和形态差异太大,利用机器学习进行分类的必要性不足。
因此,本文围绕具有跨学科特性的利用人工智能进行校园植物观测的活动,来探讨构建用于人工智能学习(而非科学研究)的本土对象的数据集的相关问题。为了方便说明问题,本文的讨论基于这样的活动过程:首先,安排学生在校园内采集标本;其次,将标本输入计算机,生成数据集,继而由机器学习算法或人工神经网络进行训练生成分类模型;最后,针对测试集的样本验证分类效果。
数据采集
需要结合教学情境,为数据采集建立具有一定合理性、真实性的目标框架。从学生日常生活出发创设情境,相较专业的科学研TEwFPT+8Ym/z7IiEKxo7jw==究的分类,更容易找到具有合理性、真实性的分类任务。例如,首先,可以让学生仔细观察道路两旁的行道树,思考如何通过观察特征来区分不同的行道树种类;其次,用现有的人工智能软件来对行道树的种类进行区分;接着,讨论人工智能软件是如何成功进行分类的;再次,采集标本,记录数据,借助生成式人工智能,利用机器学习库或神经网络库,自行架设机器学习或人工神经网络模型;最后,用这些模型进行分类测试。
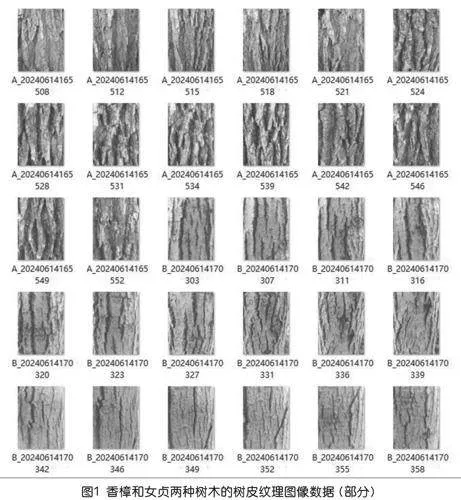
以行道树为数据采集对象的原因有:①行道树种类不多,相较极为庞大的植物家族来说,仅对行道树分类是一个相对可控的分类任务,当然可能有其他的分类任务框架,如分辨校园中的玉兰科植物、分辨蔷薇科植物等,特定范围的限定,能够极大地简化分类任务。②获取行道树的特征数据也较容易。例如,容易采集到树木的落叶,除了秋季能采集到多种树木的落叶外,春季也有多种树木在换叶期,如香樟、女贞、广玉兰等,香樟和女贞的树叶形态相近但又略有区别,用来作为机器学习分类任务的对象,既为特定情境提供任务(人可能因为树叶形状相似而误认),又具有用人工智能解决问题的挑战性(需要研究如何合理选取特征数据)。在教学过程中,可以安排学生拾取校园中的落叶带至教室再用摄像头进行记录,建议在拍摄时设置统一的背景,便于后期图像处理。除了树叶,不同树种的树皮纹理也是一个可以较为方便获得的特征。如图1所示是香樟和女贞这两种树木的树皮图像数据的一部分。
在植物学中,植物分类主要以植物的花、果实和种子作为分类依据,且尤其突出花作为分类依据的作用。原因主要是花、果实和种子受环境影响较小,形态结构相对稳定,在进化过程中,花、果实和种子的形态结构变化不大,保持了相对的稳定性,它们的形态结构特征能够反映植物之间的亲缘关系和进化关系;相比之下,植物的茎、叶等器官在生长周期中变化较多,更易受外界环境的影响,形态、大小、颜色等方面与植物种类对应关系不确定,所以不太适合作为植物分类的主要依据。不过,如果是在校园环境中实施利用人工智能进行植物分类的活动,情况就有所不同,因为校园中植物的类别总体有限,植物的茎、叶等器官能够和有限的植物种类建立起对应关系。而若要对花进行观测和数据采集,容易受到多方面的限制,如:花的花期是有限的;不同花的开放时间不同;较难将花单独摘取下来记录数据,而若不摘取下来,测量和记录又比较麻烦;另外,花的形态更为多样细致,数据描述更为困难,对图片的像素要求高,在后期自行构造人工智能分类模型时,可能会有算力上的压力。当然,可以设法人为地解决以上困难,如为人工智能教学建设一块专用的植物试验田。
图像处理与数据记录
在教学过程中,虽然可以人工测量并记录特征数据,但这通常需要花费大量时间,测量过程也较容易受主观因素影响,所以,可以利用计算机视觉库(如OpenCV库)自动测量并获取特征数据。自动采集的数据可能有偏差,但只要样本数量足够大,记录得到的特征数据仍然是可靠的。
以树叶为例,可以通过视觉库获取特征数据——树叶的颜色、长宽比例、边缘平滑程度、图像信息熵等,相关代码可以利用生成式人工智能快速编写完成。例如,为了获得树叶的多项特征,可撰写如下提示语句交由生成式人工智能处理:“读取当前文件夹下所有图片,选取每张图片正中间19*19像素区域,获取其RGB值,将R值除以G值所得到的数据存储于dataset.csv文件的color字段中;选取图片背景中的唯一物体,计算其边缘平滑程度,将数据存储于dataset.csv文件的edge字段中;计算该物体长度除以宽度数据,存储于dataset.csv文件的shape字段中;根据文件名首字母判断物体种类到底是A还是B,存储于dataset.csv文件的species字段中。”当然,在实际操作中,需要调整提示词以及生成代码中的阈值参数,以求得较佳效果。如果后续实验是利用人工神经网络构造树叶的分类模型,则需要根据实际的算力,将图像转换成灰度并降低像素值,当然,这样会面临颜色信息丢失的问题,可以通过颜色空间转换,或提取颜色信息作为神经网络的辅助输入等方法解决问题。
如图2所示是利用生成式人工智能的代码,测量树叶并获取相关数据的dataset.csv文件内容的局部。其中,第0个字段表示种类,A代表香樟落叶,B代表女贞落叶;第1个字段是颜色数据,表示树叶红色成分比上绿色成分的程度;第2个字段表示树叶边缘光滑程度;第3个字段表示树叶所占区域矩形长度和宽度的比例。从数据中可以看出,香樟落叶偏红一些,女贞落叶偏绿一些;香樟落叶边缘没有女贞落叶边缘平滑;香樟落叶比女贞落叶长宽比例更小一些,也就是说,香樟落叶看上去更胖一些。当然,这些特征是从样本数据的整体程度上体现出来的,每一片树叶个体上的特征有时候和种类关联性不强,但机器学习算法通过处理大量数据,以及同时考虑多个特征的综合影响,来更准确地预测植物种类。对于获取到的样本数据,可以采用特定的机器学习算法来生成预测模型并进行分类测试,比较容易理解的机器学习算法有K近邻、朴素贝叶斯、决策树等。
值得一提的是,现实世界具有高度的复杂性,特征数据的提取过程必然经过高度的抽象,抽象简化了计算过程,但也掩盖了部分真相。例如,香樟树叶和女贞树叶的长宽比例事实上非常接近,它们的边缘本来也都相当光滑,但在树叶落下后,香樟树叶和女贞树叶分别以不同的方式蜷曲,许多香樟树叶边缘容易蜷曲,产生边缘不光滑的视觉效果,许多女贞树叶以主叶脉对称作整体蜷曲,如果不将树叶压平而是自然放置,就产生出瘦长的视觉效果。所以,对香樟和女贞掉落树叶进行分类,相较于对摘取树枝上的树叶进行分类,对初学者而言,实施分类任务的难度反而降低了。
数据集的使用
如果利用生成式人工智能和机器学习库,那么分类模型的构建是相当方便的。例如,图3所示的是用Scikit-learn库划分数据集,并采用K近邻算法为树叶数据建立分类模型,并对测试集进行测试的例子。即便采集的样本数量不是特别多,也能够利用传统的机器学习算法构建分类模型,不过,需要通过人为观察选择出适合用于分类模型的特征。若是利用人工神经网络来进行分类,那就不需要人为选取特征,但需要有更多样本来供神经网络训练学习,而且训练耗时也较长。图4所示的是用neurolab库,对转换为40*30像素灰度的树皮的图案,用人工神经网络进行分类训练的Python代码。
学生亲自采集样本、测量样本、记录数据,并利用机器学习算法或人工神经网络对数据进行分类,相比于单纯下载和使用数据集进行人工智能学习,具有以下几个显著的好处。
①通过亲手采集样本、测量和记录数据的过程,不仅锻炼了学生的观察力和动手能力,还能让他们了解数据处理和分析的基本步骤,在理论知识与实践的结合中,增强学习兴趣和记忆深度。
②加深学生对真实世界问题的理解。来自现实世界的数据往往比用于理论学习的数据更加复杂和多变。学生通过处理自己采集的样本数据,能更好地理解实际情况下可能遇到的各种数据问题,如数据获得方式、数据选取方式等,同时,在实践过程中,学生能建立起与数据的更深的情感联系。
③引导学生更加重视现实中的问题,如环境保护和生物多样性的问题,增强他们的环保意识和责任感。学生需要对自己的数据负责,确保数据的准确性和可靠性,这样有助于培养研究中的科学精神和严谨态度。
④活动具有跨学科特性,涉及生物学、统计学、机器学习等领域的知识。在任务实施过程中,学生需要将不同学科的知识技能进行整合。
