
基于图像内容检索的主题爬虫设计
2024-10-09 00:00:00谭湘菲孟晴
电子产品世界 2024年9期
关键词:图像内容检索;主题爬虫;特征提取
中图分类号:TP311;TP391.41 文献标识码:A
0 引言
数字化时代背景下,用户对图像信息的需求日益增加,而基于文本的检索方法已经无法满足现代用户的多样化需求。在此背景下,基于图像特征的检索技术应运而生,它通过深入分析图像的形态、纹理及色彩等属性,为用户带来更直观、准确的搜索结果,有效弥补了传统搜索方法的不足。因此,研究并设计主题爬虫平台具有重要现实意义,其不仅可以有效提升检索的准确性与效率,还能够为用户带来丰富的个性化搜索体验。
1 图像内容检索
图像内容检索作为一种先进的信息检索技术,专注于分析与提取图像的内容语义特征,进而基于这些特征执行相似性匹配。相较于以往的数据检索方法,图像内容检索具备3 个显著优势:第一,它依赖于图像本身的属性信息来执行搜索;第二,与基于文本的检索方法不同,它侧重于图像间的相似性,并以此作为搜索的标准;第三,它采用交互式搜索方法,结合参数调整、概率模型、神经网络与聚类技术,在高级语义与图像信息之间建立关联关系。
图像内容检索通过深入解析图像内容,提取包括空间布局、边缘、纹理、色彩及形状在内的多种特征,并在特征数据库中构建索引。当用户上传查询图像时,平台通过连续的相似性比较,从图像库中检索出符合条件的图像。由于不同的检索方法依据的重点与特征提取机制不同,因此,每种策略都有其独有的特点。例如,基于色彩特征的检索方法通过利用色彩直方图来表示图像中颜色的分布情况,这对于图像的平移或旋转具有较好的鲁棒性;纹理特征检索方法则关注图像中基本结构元素的规律表现,如共生矩阵、Tamura 纹理表示法;而形状特征检索方法则侧重于轮廓与区域特征,通过引入边缘检测等算法来提取物体轮廓,保留主要信息[1]。
2 主题爬虫架构设计
2.1 主要功能模块
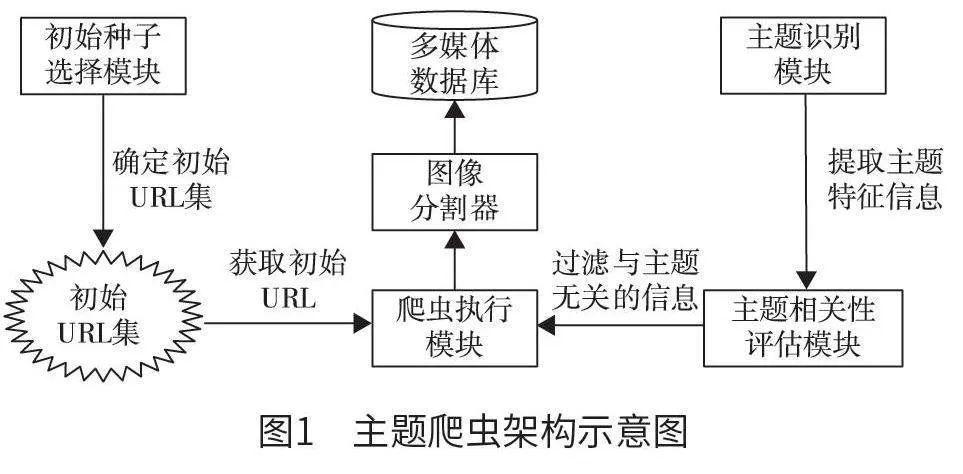
主题爬虫的架构设计涉及多个关键模块,如主题识别、初始种子选择、爬虫执行以及主题相关性评估等。主题识别模块专注于从图像中提取特征,本文选择广泛使用的JPEG图像格式,以确保特征提取的一致性与效率。通过人工筛选出与特定主题相关的图像集合,再利用计算机算法自动抽取这些图像的特征,建立一个包含主题特征的数据库。初始种子选择模块的任务是确定一组针对特定主题的优质起始统一资源定位(uniform resource locator,URL),这些URL 为爬虫的启动与运行提供基础。该URL 集通常由人工精心挑选,以确保其质量与可信度。爬虫执行模块作为整个系统的核心,能够从数据库中提取待处理的URL,然后利用主题相关性评估模块对这些URL 完成分析,筛选并剔除与主题不相关的网页。同时,它还负责对URL 进行分类管理,下载新的URL,并保存与特定主题相关的图像。在访问新的URL 时,主题相关性评估模块不仅可以下载页面中的图像,还负责完成图像的特征提取工作。若所提取的图像特征与预设的主题特征信息存在较大差异,则该页面被视为与主题相关度低,因此不对其进行后续处理。虽然该机制可能会导致部分URL 被遗漏,但它能显著减少整体的爬行工作量。主题爬虫架构示意图如图1所示。
2.2 主题爬虫工作流程
主题爬虫工作流程如下。
步骤1:爬虫执行模块从待处理队列中提取URL,作为爬虫工作的起点。
步骤2:平台利用主题相关性评估模块来深入分析URL 指向的网页,其核心任务为识别网页图像的特征,将其与预设的主题特征完成匹配与比较,以评估网页与主题的关联度。
步骤3:结合主题相关度分析的结果,爬虫执行模块将URL 分配到不同的队列中。对于与主题高度相关的URL,平台将其置于优先处理队列,并下载保存其中的图像至多媒体数据库;而对于与主题相关度较低的URL,平台将其置于较低优先级的队列或直接忽略[2]。
步骤4:平台返回至步骤1,重复执行步骤1至步骤3,该循环过程将持续进行,直至待处理队列中无剩余URL,或满足程序所设定的终止条件。
3 主题爬虫平台设计
3.1 系统编程与数据库设计
本平台采用C++ Builder 6作为核心开发工具,其凭借强大的编程能力,为平台的构建提供了坚实的基础。在数据库选型上,平台选用了数据库管理系统SQL Server 2000,该系统对存储过程具有出色的支持能力。为了确保数据库操作的高效性与稳定性,结合平台的功能需求,开发人员对存储过程进行了详细且全面的规划。同时,利用C++ Builder 的开发优势,本文设计并实现了一个直观且易用的应用界面,该界面涵盖了图像的添加、修改、删除及查询等一系列核心功能,所有功能均基于控件来实现,为用户提供了便捷的操作体验[3]。在数据库交互方面,使用ActiveX数据对象数据库(activeX data objects database,ADODB)编程接口来执行存储过程,确保了数据访问的效率与安全性。
3.2 图像处理与特征分析
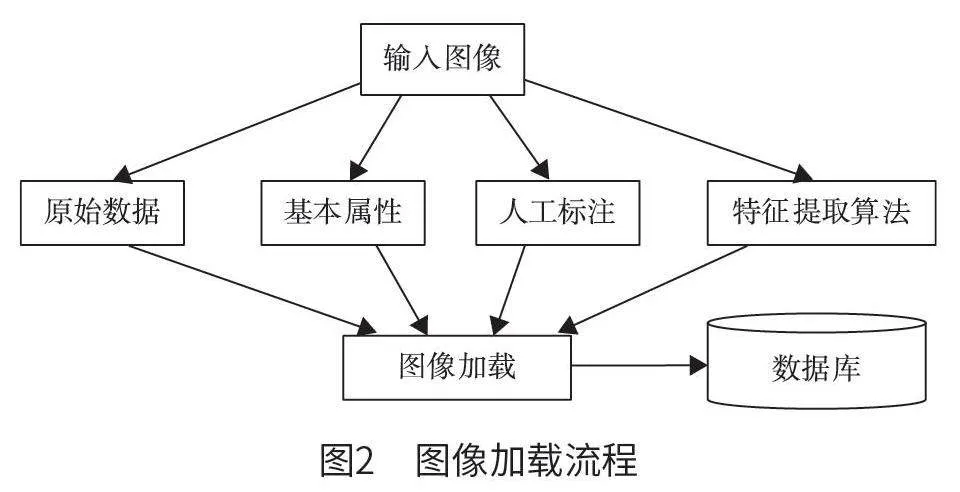
本平台采用面向对象的方法来组织与处理图像数据,将其分为4 个主要部分:原始数据、基本属性、人工标注和特征提取算法。原始图像作为数据的基础,被安全地存储在数据库中,并为其创建索引以加快检索速度。图像的基本属性(如存储位置、格式、尺寸与处理时间等)被封装在对象属性中,并且提供相应的初始化与修改方法。同时,为了增强图像的可理解性与可检索性,平台还实现了人工标注功能,以详细描述图像内容[4]。在图像内容特征提取方面,平台利用特定算法来深入分析图像,提取特征信息,并在检索过程中完成匹配运算。图像加载流程如图2 所示。
在特征提取方面,平台特别采用了直接示例查询法,并结合非均匀量化与主元分析法等,有效降低了特征矢量的维数,同时保留了所需的特征信息。此外,平台还利用颜色常量方法与累加直方图法进一步提取图像的颜色特征,有效克服了量化参数的敏感性,更好地体现彩色信号的相关性。在特征匹配阶段,平台采用加权欧氏距离函数来计算图像之间的相似度,为用户提供准确的检索结果。
3.3 爬虫性能优化
为了进一步提升爬虫的效率,需对下载的图像完成预处理,旨在剔除与检索主题不相关的图像,该预处理过程可以通过检测图像的大小、比例、颜色和动态特性来实现[5]。这个过程主要是去除分辨率过小的图像,因为这类图像往往仅用作网页装饰,并不包含有价值的信息。因此,需要设置一个固定的分辨率阈值,任何低于此分辨率阈值的图像都将被直接排除。同时,预处理过程还需要考虑图像的比例因素,许多网页倾向于使用特定比例的图片进行装饰,如宽高比为3∶1 的图片。通过设定合理的比例阈值,可以进一步排除与检索主题无关的图像。此外,颜色信息也是判断图像是否相关的重要因素。颜色种类过少的图像,如仅包含5 种颜色的图像,往往不包含丰富的内容信息,因此也应被排除。考虑到用户对动态图像的兴趣有限,特别是GIF 格式的图像,在预处理阶段直接排除这类图像,以降低不必要的处理开销。通过详细分析已下载的100 个网页中的图像,约30% 的图像被确认与检索主题不相关,综合运用上述优化策略,这些不相关的图像被直接排除,无须进行后续的特征提取与匹配,从而有效提高了爬虫的处理效率。
4 结语
综上,基于图像内容检索的主题爬虫能够有效提高图像检索效率与准确性。然而,该技术仍面临一些挑战,如图像特征的提取与匹配问题、计算资源的限制、算法复杂性等。未来,将持续研究与探索更多先进技术,以进一步深化图像特征研究,提升计算效能并优化算法,从而推动图像内容检索与主题爬虫技术的创新与发展,为用户提供更具个性化和更多元化的搜索体验。
