
一种数字乐谱音乐信息快速智能提取算法
2024-10-01 00:00:00王有能
无线互联科技 2024年18期
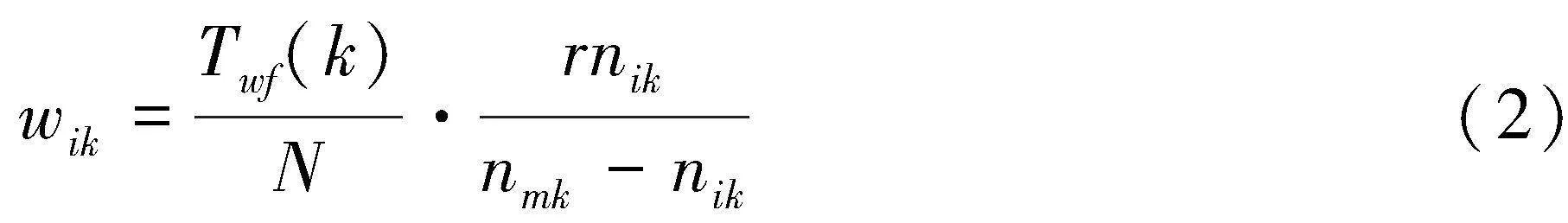
摘要:数字乐谱信息来源广泛且格式多样,导致提取目标信息花费时间较长,为此,文章提出一种数字乐谱音乐信息快速提取算法。从初始音乐信息中提取一级种子URL,将其加入待爬取的数字乐谱URL队列,识别并匹配与目标乐谱相关的特征。基于深度学习算法筛选出与目标乐谱相匹配的信息部分,实现快速准确的信息提取。经验证,该算法在确保FI值达到0.98的前提下,提取测试曲目乐谱的高音音符、长音音符以及节奏音符信息的整体时间开销仅为115 s,展现出了出色的信息提取速度。
关键词:网络爬虫;数字乐谱;音乐信息;快速提取技术;深度学习;目标特征
中图分类号:TP183 文献标志码:A
0 引言
数字乐谱的概念可以追溯到电子音乐的发展,随着计算机技术的进步,人们开始尝试将音乐符号通过数字化的方式呈现出来。随着对数字技术的不断探索和应用,数字乐谱得以不断完善和发展,逐渐成为一种独立且完善的音乐符号系统,广泛应用于音乐行业和音乐教育领域。与传统乐谱相比,数字乐谱具有更直观易懂的特点,使得学习和演奏音乐变得更加便捷和高效。数字乐谱作为一种现代化的音乐符号系统,将继续在音乐领域发挥重要作用,推动音乐文化的传承和发展。数字乐谱作为音乐信息的重要形式之一,其符号和标记种类繁多[1-2]。传统的信息提取方法须要花费大量时间进行识别和解析,无法满足现代音乐创作与传播的高效需求。因此,深入研究数字乐谱有助于更好地理解和利用音乐信息,推动学科交叉与融合[3]。
在当前研究领域智能高效发展的背景下,王腾阳等[4]提出了基于词性标注规则和预设词的文献数据抽取方法,采用远程平滑算法和光学字符识别,对文本内容进行获取,利用用户建立的关键词库保存抽取项,运用正则表达式,对关键词所在语句进行获取,使用自然语言处理语句,进行分词与词性标注,依据规则对目标词进行抽取,融合关键词和预设词距离,对信息进行抽取,完成文献数据抽取。该方法虽然可以基于词性标注规则提取信息,但调试和优化的时间开销较大。梁建军等[5]提出了基于规则模式的瓦斯爆炸事故信息抽取技术。依据事故分析理论基础,融合煤矿重特大瓦斯爆炸事故报告样本库,对事故致因词典库进行构建,采用信息抽取技术,实现基于规则模式的事故致因信息抽取。该方法可以通过规则模式进行信息提取,但须要耗费大量时间和精力。Chantrapornchai等[6]提出了2种基于搜索引擎返回的全文提取特定信息的方法。基于3个任务:名称实体识别、文本经典化和文本摘要。构建训练数据和数据清理,收集旅游数据并建立词汇表。几个小步骤包括句子提取、关系和名称实体提取,用于标记目的。创建正确的训练数据需要这些步骤,可以建立给定实体类型的识别模型。利用Transformer的双向编码器(Bidirectional Encoder Representations from Transformers,BERT)和SpaCy的方法快速提取信息,但该方法存在BERT模型参数较多且微调所需时间久的问题。
为解决上述问题,本文利用网络爬虫技术准确地提取数字乐谱中的音乐信息。通过引入深度学习技术,筛选出符合目标乐谱的信息部分,实现快速且准确的信息提取。
1 算法设计
1.1 数字乐谱信息快速抓取
爬虫从初始化的统一资源定位器(Uniform Resource Locator,URL)和目标音符出发,获取初始音符信息。本文从这些信息中提取一级种子URL,构建待爬取的URL队列,将其作为爬虫爬取数字乐谱的起始点。具体的实现方式可以表示为:
Twf(k)=m(i)/m(j)(1)
其中,Twf(k)表示爬取中的数字乐谱URL队列;k表示队列的长度参数;w表示单词爬取范围;f表示爬取过程中执行步幅参数;m(i)表示初始化的URL中的音符信息;m(j)表示初始音乐信息中提取一级种子URL中的音符信息。
1.2 基于深度学习技术提取目标数字乐谱信息
在爬虫URL队列中,首先,本文以梯形树结构向量化表示目标音乐信息特征,利用乐谱中的特定超文本置标语言(HyperText Markup Language,HTML)标签元素来标记对应的音符特征区域;其次,采用Dom选择器,对乐谱中的特征音乐信息对应的音符特征进行深度学习处理,进一步提升信息提取的效率和准确性。最终,通过这种整合的方法,实现对数字乐谱音乐信息的精确提取。具体的实现方式可以表示为:
其中,wik表示Dom选择器对乐谱中特征音乐信息对应的音符特征的深度学习结果;N表示乐谱中特征音乐信息的音符数量;nik表示特定的html标签元素;nmk表示音符特征包裹的音乐信息;r表示音符乐谱中的目标信息。
2 测试与分析
2.1 测试准备
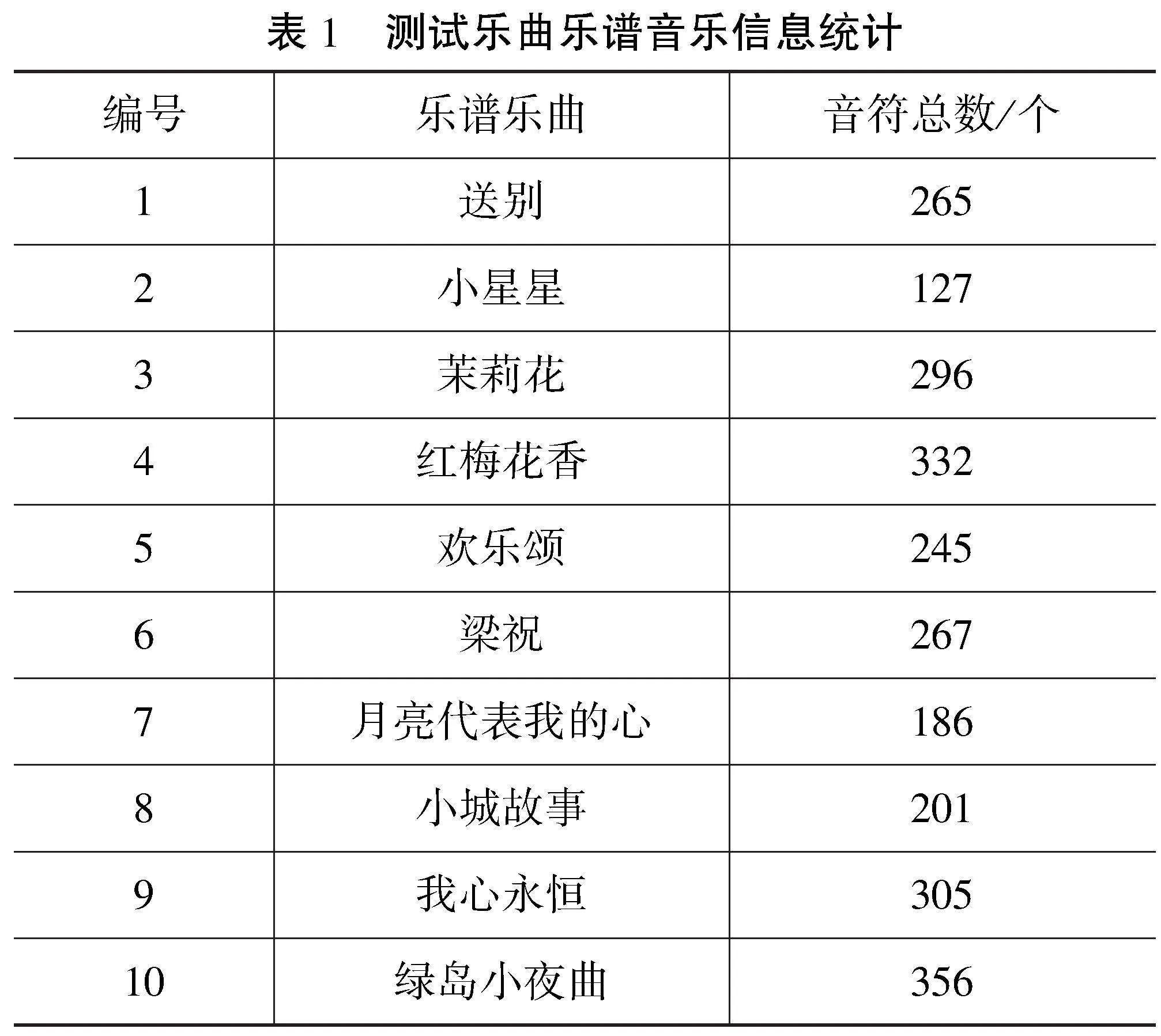
为了确保测试结果的可靠性和分析价值,本文采用梁建军等[5]提出的算法和Chantrapornchai等[6]提出的算法作为对照组。在本文设计的数字乐谱音乐信息快速提取算法中,设置爬取深度为5层,爬取频率的延迟时间为1 s,最大并发连接数为10。为了全面评估算法的性能,在某音乐软件中随机选择了10首乐谱乐曲作为实验样本,具体音乐信息如表1所示。
基于表1所列的10个乐曲乐谱,实验分别采用了3种不同的算法进行音乐信息提取。在本次实验中,设定了具体的提取目标,包括高音音符数量、长音音符数量以及节奏音符数量。为了确保提取结果的准确性,设定FI值达到0.98为基准。
2.2 测试结果与分析
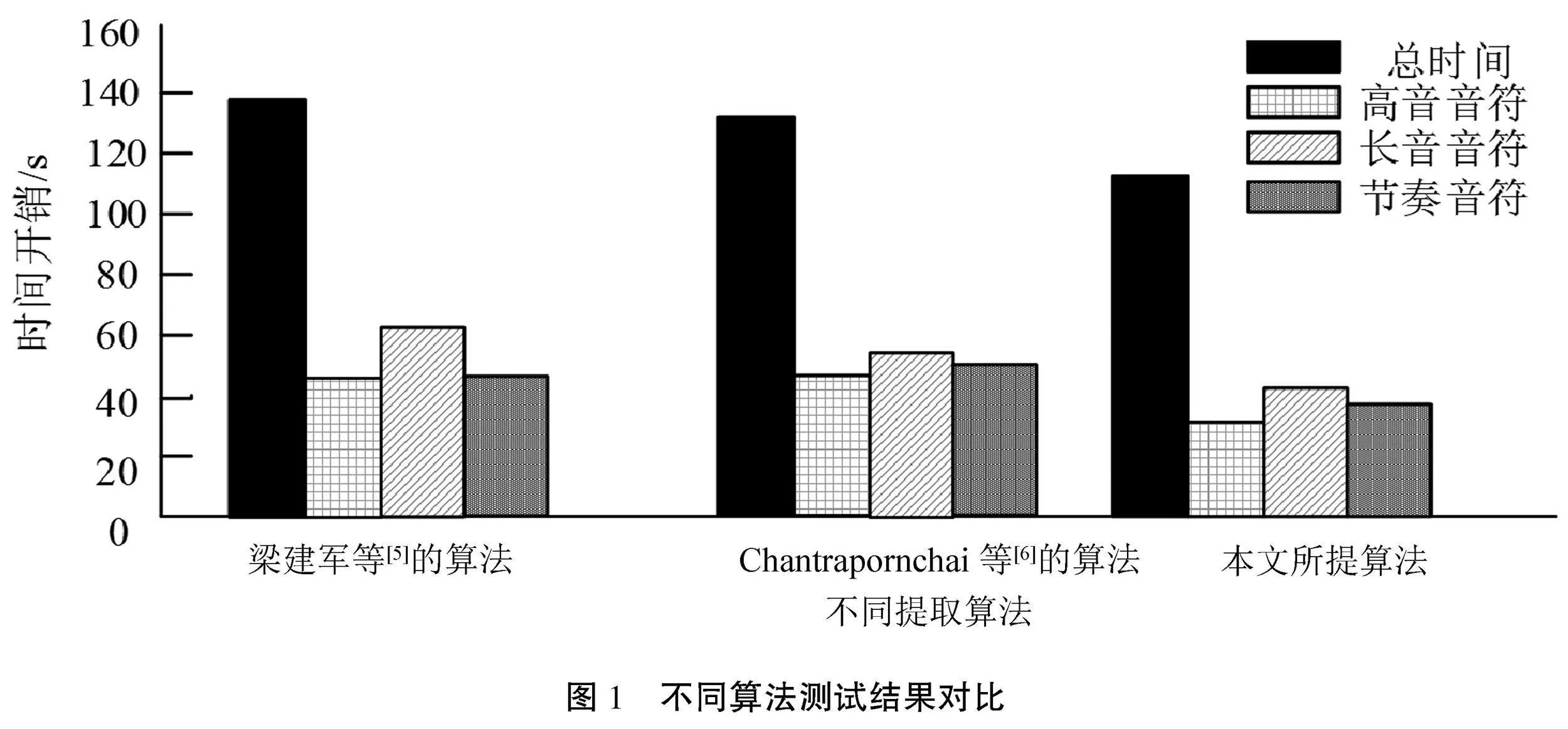
在上述实验条件下,对3种不同算法进行了测试,收集3种算法在数字乐谱音乐信息快速提取过程中的时间开销数据,结果如图1所示。
从图1可以看出,梁建军等[5]提出的算法时间开销最大,达到了140 s;在时间开销的具体分布上,该算法的长音音符信息提取时间最长,而高音音符信息和节奏音符信息的提取时间则较为接近。Chantrapornchai等[6]提出的算法整体时间开销为135 s,对于高音音符信息、长音音符信息和节奏音符信息的提取时间相对均衡,基本在40~50 s。而本文算法具有较高的提取效率,能够显著减少乐谱音乐信息提取所需的时间开销。
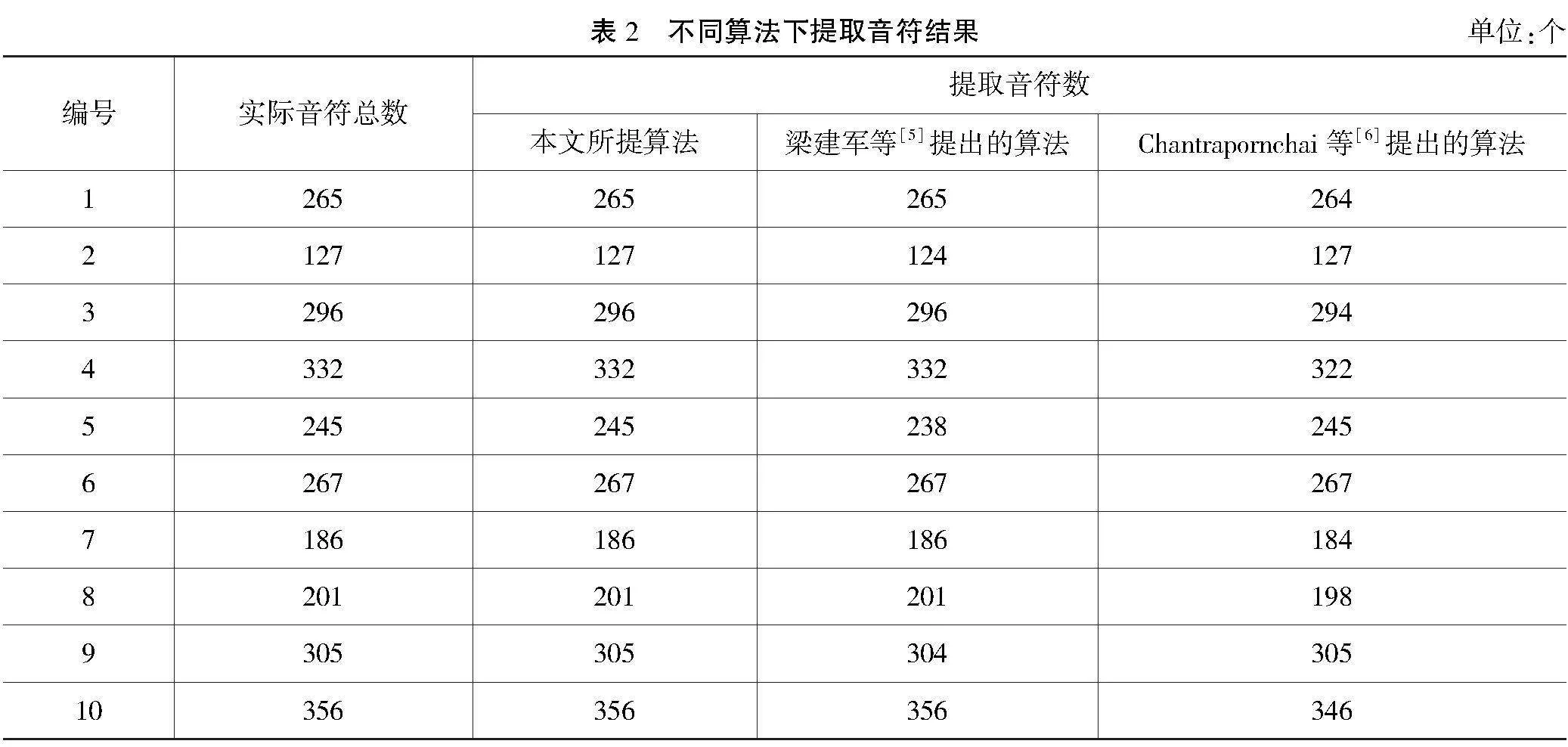
实验使用3种不同算法对10首乐谱乐曲的音符总数进行提取,分析不同算法下音符提取的准确性,具体结果如表2所示。
通过表2可知,使用梁建军等[5]提出的算法,在提取2号、5号、9号乐谱音符时与实际音符总数存在误差;使用Chantrapornchai等[6]提出的算法,在提取4号、7号、8号、10号乐谱音符时也存在误差。相比之下,本文所提算法的音符提取结果与实际音符总数一致,显示出较高的准确性。
3 结语
本文提出一种高效的数字乐谱音乐信息快速提取算法,通过引入深度学习技术,利用数字音乐信息与音符特征之间的内在联系,实现了自动定位并精准爬取目标数字乐谱。经过实验验证,本文所提出的算法能够快速、完整地提取数字乐谱中的音乐信息,整体时间开销仅为115 s,相较于传统算法具有显著优势,提升了信息提取的效率和准确性。
参考文献
[1]时业茂,颜晓宏,章祖华.基于Python使用爬虫从豆瓣网获取最新上映的电影信息[J].电脑编程技巧与维护,2023(12):153-155.
[2]张海霞.基于Python网络爬虫技术的海量教学资源获取研究[J].太原城市职业技术学院学报,2023(11):56-58.
[3]曾炎.德彪西《g小调小提琴与钢琴奏鸣曲》乐谱版本与演奏版本分析[J].中国民族博览,2023(18):142-144.
[4]王腾阳,赵小丹,胡林.基于词性标注规则的马铃薯文献信息抽取方法[J].科学技术与工程,2023(27):11562-11569.
[5]梁建军,雷咸锐,吴斌,等.基于规则模式的瓦斯爆炸事故信息抽取技术[J].煤矿安全,2023(2):239-245.
[6]CHANTRAPORNCHAI C,TUNSAKUL A.Information extraction tasks based on BERT and SpaCy on tourism domain[J].ECTI Transactions on Computer and Information Technology (ECTI-CIT),2021(1):108-122.
Fast and intelligent algorithm for extracting digital score music information
Abstract: Digital score information has a wide source and various formats, which leads to a long time to extract target information. Therefore, this study proposes a fast algorithm for the extraction of digital score music information. The primary seed URL was extracted from the initial music information and added to the digital score URL queue to be crawled to identify and match the features related to the target score. Based on the deep learning algorithm, the information that matches the target score is selected to achieve fast and accurate information extraction. It is proved that on the premise of ensuring the FI value of 0.98, the overall time cost of extracting the test track score is only 115 s, showing excellent information extraction speed.
Key words: web crawlers; digital score; music information; rapid extraction technology; deep learning; target features
