
基于词向量的可解释性电视频道个性化推荐方法
2024-07-24 00:00:00邵文倩
电脑知识与技术 2024年17期


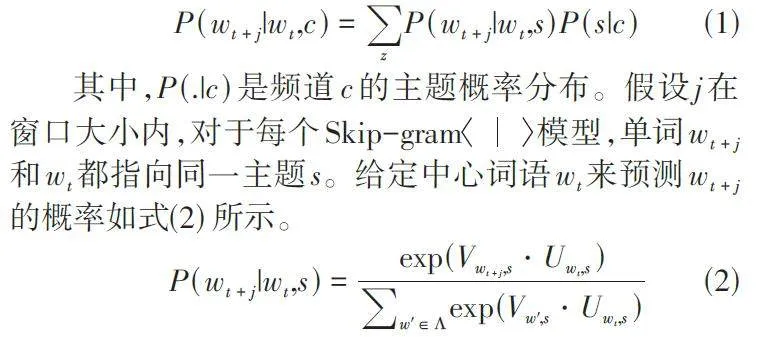

摘要:随着网络和电视服务行业的发展,网络电视平台可以为用户提供更丰富的电视频道,但对于用户来说,挑选喜爱频道的难度也大幅增加。为此,提出一种可解释性电视频道个性化推荐方法,将词向量表示方法Word2Vec和LDA主题模型相结合,通过学习电视频道播放的节目简介中的潜在主题,实现可解释性。与现有方法的实验对比表明,本文提出的算法可以为用户提供比较精确的推荐,能够大大增强用户黏性。
关键词: 可解释性;主题模型;电视频道;推荐方法
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)17-0033-03 开放科学(资源服务)标识码(OSID) :
0 引言
网络电视的广泛普及,使电视行业发生了翻天覆地的变化。用户通过网络电视获得了更丰富的电视频道和观看体验,但信息过载的问题也给电视服务行业带来了前所未有的挑战。在当前的互联网电视服务中,大部分仅为用户提供电视频道的直播和视频点播服务,即电子节目指南(Electronic Program Guides,EPG) 。用户可以根据电子节目指南中的菜单列表选择电视频道或视频等。然而,普通的EPG并非基于用户的个人偏好进行设计。因此,如何引导用户快速找到他们喜爱的频道,提高用户的观看体验,成了IPTV 服务供应商面临的重要挑战。目前,关于电视节目推荐的方法较多,并且能够达到良好的效果,但电视频道推荐方面的研究仍待扩展。
1 研究现状
电视推荐属于推荐系统应用的一大领域。文献[1]中对电视领域推荐系统的研究综述阐明,在电视领域内,大部分项目的推荐已经广泛应用,例如电视节目、电影、电子商务、音乐、教育等,其中推荐项目主要集中在电视节目。文献[2]为了解决在电视节目推荐中的初始数据集稀疏性问题,构造了随机游走模型,能够进一步获取电视节目之间的隐性相似关系,对初始评分矩阵进行填充,进而更加全面地为用户推荐电视节目。在文献[3]中,使用多层感知网络来挖掘用户特征和节目特征,进一步使用协同过滤方法来获取信息,为用户进行个性化推荐。文献[4]关注了电视节目收看中多用户使用同一账号的问题,使用聚类方法将同一用户账号的收视按照不同的观看时段进行划分,从而可以在同一用户账号中挖掘不同用户的观看特征,进而满足不同人群的收视需求,评分替代策略也可以进一步解决冷启动问题。
当前研究大多偏向探究电视领域内的电视节目或电影推荐,也有少部分研究电视频道推荐问题。文献[5]提出了一种新的观看模型,通过观看时间挖掘观看偏好,获得用户的积极与消极反馈,并引入七个关键特征的定义,进一步提升推荐效果。文献[6]通过大数据高性能计算平台与数据仓库进行数据分析,高效地塑造出用户画像和用户观看行为特征,同时引入工程学角度,实现算法自动化监控和运行,基于不同用户的观看场景可以自动化选择不同的推荐方案,以实现在用户使用场景下推荐。文献[7]构建了一种长短期兴趣结合的网络电视直播频道推荐方法,该方法基于一个多层时间自注意力网络,同时结合用户历史观看数据挖掘出用户的观看喜好特征,能够自适应地获取用户历史观看记录中的频道切换模式,从而为用户推荐电视频道。
2 基于词向量的可解释性电视频道个性化推荐方法
在电视频道推荐方法中,基于协同过滤和主题模型的方法虽然可以达到一定的准确率,但在处理短文本问题时还存在部分弊端[8]。而深度学习方法只使用时序信息,并没有利用内容特征,同时也缺乏对推荐的解释性。为了解决其他推荐方法中解释性差和语义不清的问题,本文将LDA主题模型和Word2vec结合起来,即将单词嵌入和主题模型结合,应用于电视频道推荐,提出了可解释性电视频道推荐方法(Ex⁃plainable Recommendation Method of TV Channels,WLDA)。
W-LDA方法不仅可以通过主题-词概率分布对潜在主题的含义进行解释,同时可以通过主题-频道概率分布解释电视频道的主题。更重要的是,能够使用词向量计算用户向量和频道向量之间的相似度,从而表现出电视频道推荐的可解释性。
LDA主题模型为电视节目简介中出现的每个词项指定潜在主题。实际上,主题模型和单词嵌入相似,都是从文本中得到词项的意义。然而,词嵌入和主题模型之间存在一些关键区别,这使得它们相辅相成。首先,词嵌入是连续的表示,而主题分配是离散的表示。其次,单词嵌入是在窗口的概念上训练,而主题模型采用更全局的观点,即分配当前词项的潜在主题时需要依赖于同一文本中出现的其他单词。LDA主题模型和词嵌入的结合使潜在主题在语义方面更加明确和连贯,增加了电视频道推荐的可解释性。
2.1 表示主题与词嵌入
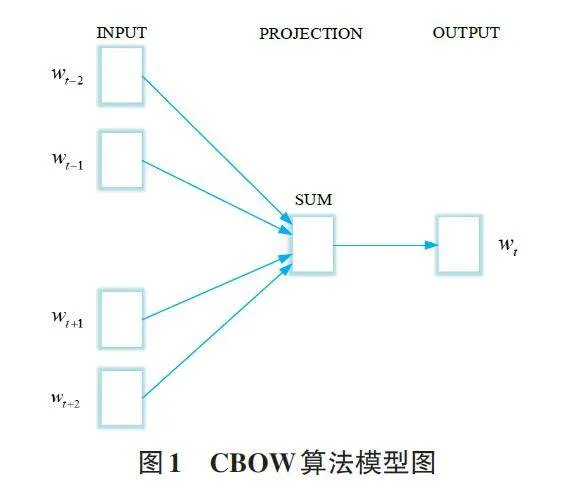
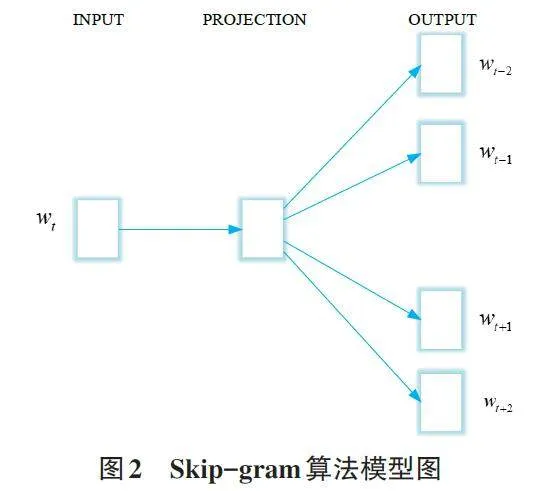
Word2vec作为将文本转换成词向量的训练模型,实际上是一个三层的神经网络模型。该模型通过观察输入词语及其上下文词语的关系,从大量的文本中生成词向量,将词项表示为多维数值向量,从而通过计算词项之间的距离确定语义相似度。实际上,如果单词在相似的上下文中出现,这样的单词也将在Word2vec向量空间中彼此相邻。常用的两种词向量训练方法包括CBOW模型和Skip-gram模型,如图1 和图2所示,这两种方法本质上是交换了输入和输出。
电视频道播放节目介绍中的词w 都与一个输入矩阵Uw 和一个输出矩阵Vw 相关联,两个矩阵的维度为K×z,其中K表示主题数,z表示单词嵌入维度。在频道c 的节目介绍文本和中心词语wt 的影响下,预测周围单词wt + j 的概率也取决于单词w 的主题[9]。假如中心词是“篮球”,如果主题与历史有关,则周围词“发展”“起源”出现的概率较大;如果主题与运动有关,则周围词“竞技”“赛事”出现的概率较大。在主题s 下给定中心词语wt来预测wt + j的概率,公式如式(1) 所示。
式中,Λ 为所有节目介绍的词汇集合。计算P (wt + j|wt,s) 与传统Skip-gram模型类似,可以依靠负采样来解决。
2.2 基于词嵌入的主题模型
W-LDA方法在电视频道播放的节目简介中学习模型参数的值,即学习每个主题s 对应的单词嵌入量Uw,s 和Vw,s,以及每个频道c的主题分布P (s|c)。模型的可解释性在于模型参数的值具有实际意义,并且可以解释推荐过程。算法在每次迭代中,都会更新词嵌入,然后更新频道-主题概率分布P (s|c)。为了更新词嵌入,W-LDA方法迭代每个Skip-gram wt + j| wt ,进行负例采样,然后计算Skip-gram的后验主题概率分布。在模型拟合时,将EM方法与负采样相结合,在E步中,使用贝叶斯定理计算主题概率分布并得出目标函数。在M步中,使用梯度下降法最大化目标函数,并更新Uw和Vw。
对于每个频道c,给定单词w1,w2,...wTd,对数似然函数Lc 定义如式(3) 。
式中,n(c,wt,wt + j )代表在频道c中Skip-gram wt + j| wt的数目。使用拉格朗日乘数法,可以得到P (s|c)的更新规则如式(6) 所示。
3 实验效果
为了通过实验证明电视频道个性化推荐方法的有效性,使用了某广电运营公司大数据基础营销服务平台中的真实数据,即用户收视历史数据。该数据统计了2019年7月1日至2019年9月30日期间的电视频道观看历史记录,共有245个电视频道,1 329个用户,561 288条数据。字段包括用户设备号、统计日期、频道号、收看开始时间、收看结束时间和观看时间。
3.1 推荐过程的可解释性
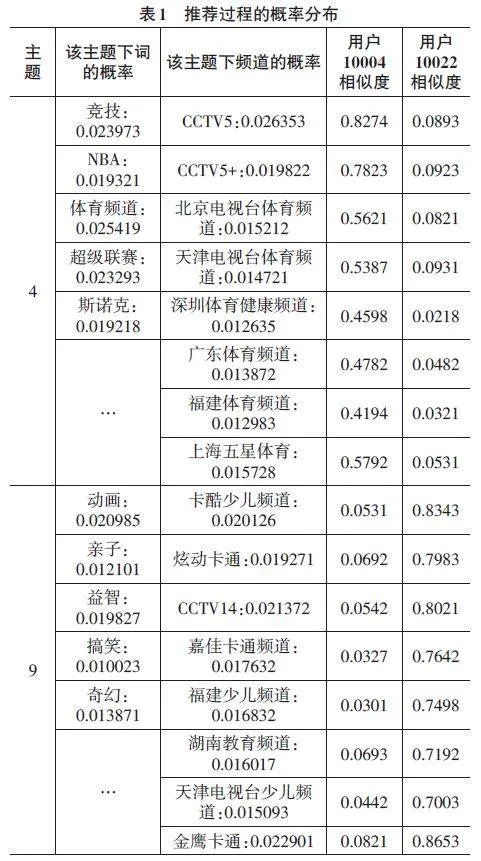
本文选取主题K=50,单词嵌入维度z=400来验证W-LDA的可解释性。如表1所示,在主题4和主题9 下,本文按照概率排序选择了前5个词进行展示。可以看出,主题4中的大部分词与体育竞技相关,而该主题下概率较高的频道主要是体育频道。这与用户10004的兴趣高度相似,而与用户10022相似度较低,说明用户10004 对体育频道相对感兴趣,而用户10022则兴趣不大。
对于主题9来说,概率较高的词和动画少儿有关,所以该主题下的频道主要是少儿频道和教育频道。这与用户10022的相似度较高,说明该用户对少儿教育兴趣较大。总体来说,可以为用户10022推荐卡酷少儿频道、金鹰卡通等电视频道;为用户10004推荐CCTV5、CCTV5+和北京电视台体育频道等相关频道。
3.2 推荐方法效果对比
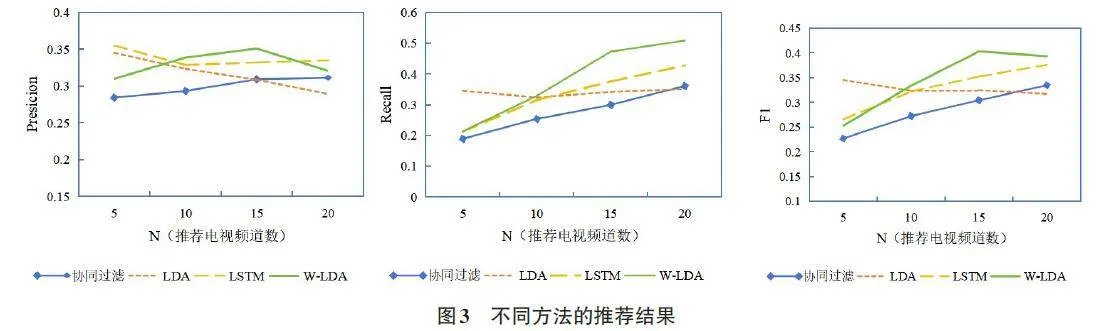
当推荐数N 分别为5、10、15 和20 时,计算WLDA方法、LDA主题模型、协同过滤与LSTM方法[10]四种不同方法的准确率、召回率和F1值来进行对比。所有方法均将原始数据分成前两个月的数据作为训练数据,后一个月作为测试数据。其中,LSTM方法参数设置为:epoch 为50倍,batch size为5,sgd的学习速率为0.01。
如图3所示,在推荐频道数目N较少时,LDA主题模型与LSTM方法有较高的准确率,而随着N的增加,W-LDA方法也能取得了较好的效果。从F1值分析,在N=15和N=20时,W-LDA方法可以获得比较好的效果。
4 结束语
本文提出的词嵌入和主题模型的结合方法不仅可以解释电视频道的潜在主题,还能够利用词向量计算用户向量和频道向量之间的相似度,从而更加明确地解释推荐过程。该方法表明了电视频道推荐的可解释性。同时,使潜在主题在电视节目简介上的语义更加明确和连贯,进一步增强了电视频道推荐的可解释性。
参考文献:
[1] VÉRAS D,PROTA T,BISPO A,et al.A literature review of rec⁃ommender systems in the television domain[J].Expert Systems with Applications,2015,42(22):9046-9076.
[2] 张凌云.基于随机游走模型的电视节目推荐系统设计与实现[D].北京:北京邮电大学,2022.
[3] 黄耀,董安明,周酉,等.融合深度学习和协同滤波的个性化影视节目推荐算法[J].计算机与网络,2021,47(13):40-41.
[4] 朱晓松.直播电视节目推荐方法研究[D].秦皇岛:燕山大学,2020.
[5] LIN S C,LIN T W,LOU J K,et al.Personalized TV recommenda⁃tion:fusing user behavior and preferences[EB/OL].2020:arXiv:2009.08957.http://arxiv.org/abs/2009.08957.
[6] 徐若航.基于在线推荐的广电个性化适配系统的设计与实现[D].成都:电子科技大学,2020.
[7] 杨中伟.基于深度学习的网络电视直播频道推荐算法研究[D].广州:华南理工大学,2022.
[8] 寇菲菲,杜军平,石岩松,等.面向搜索的微博短文本语义建模方法[J].计算机学报,2020,43(5):781-795.
[9] ALAM M H,RYU W J,LEE S.Joint multi-grain topic sentiment:modeling semantic aspects for online reviews[J]. Information Sciences,2016(339):206-223.
[10] 任思璇.网络电视用户个性化直播频道推荐方法研究[D].广州:华南理工大学,2018.
【通联编辑:唐一东】
