
基于VGG 网络的少样本图像分类方法研究
2024-07-24 00:00:00王国明李苗苗
电脑知识与技术 2024年17期




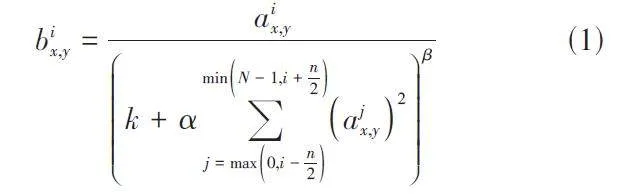
摘要:图像分类是计算机视觉领域的热门研究之一。然而,深度神经网络在面对少样本学习时,可能因数据量不足导致过拟合等问题。为此,提出了一种基于VGG网络模型的多层次滤波器方法(IVGG) 。首先,在VGG网络中引入滤波器组,通过采用1×1、3×3和5×5多层次滤波器组,从多个角度获取图像的形状和纹理等特征信息,从而避免单一滤波器的不足。然后,在卷积层之后引入批归一化处理,可缓解梯度消失、增加模型鲁棒性和学习速率。通过在四种数据集上的对比实验,结果表明,IVGG与DN4、MACO和CovaMNet方法相比,对少样本图像的分类准确率提高了0.82%~1.87%,并且损失值降低了0.02~0.18。证明该方法在处理少样本图像分类中具有更高的准确率与更低的损失值,同时能一定程度上减小网络模型的复杂度。
关键词:VGG网络;图像分类;少样本学习;滤波器组;批归一化
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)17-0006-05 开放科学(资源服务)标识码(OSID) :
0 引言
图像分类是利用特定的算法提取图像的纹理、形状等特征信息,是计算机视觉领域中重要的基础技术之一。图像分类训练神经网络模型依赖于大规模数据。然而,在某些应用场景中(如航天、医疗、军事等领域),由于隐私条例和法律等限制,图像获取异常困难,这就导致了少样本分类问题的出现。
目前,国内外学术界常用的少样本学习方法有数据增强、迁移学习和元学习。在训练样本有限的情况下,可以采用直推学习、半监督学习[1]或生成对抗网络(Generative Adversarial Networks,GAN) 实现数据增强,提高样本多样性。Elezi等[2]提出了一种基于标记的数据增强方法,通过该方法可以生成大量且准确的标签数据,从而获得更好的训练效果。Tran等[3]提出了一种优化GAN的数据增强方法,改善判别器和生成器的学习。尽管生成对抗模型具有强大的性能,但也存在一些不足,如网络训练困难、模型易于坍塌以及生成图像与样本图像相似度过高导致冗余问题等。迁移学习的目标是将已学习到的知识应用到一个新的领域中。He等[4]提出了一种采用监督式自编码或卷积自编码解决学习迁移问题的新型选择性学习方法,从而克服了两个远距离区域之间的信息分配差异,但这种方法在样本数量较少的情况下,准确率会有所下降。元学习的目标是使模型具备学习调参的能力,使其可以在已获取知识的基础上迅速学习新任务。Vinyals等[5]提出了一种基于匹配的网络,实现少样本分类任务。Sung等[6]提出采用卷积神经网络实现对不同属性之间的距离进行度量。这些方法可以学习训练之外的知识,但是复杂度较高,增加了计算开销。
尽管上述研究取得了显著的分类效果,但是缺乏对少样本的多尺度特征分析。因此,本文提出了一种改进的VGG(Visual Geometry Group) 网络结构模型(Improved VGG Network,IVGG) ,该模型在VGG 网络结构的基础上引入了多层次滤波技术和批归一化,从而实现对多个不同角度的图像特征信息的提取,有效地解决了参数在神经网络传递中被放大和过拟合等问题,同时减小了模型复杂度。
1 改进VGG 网络结构
1.1 VGG 网络结构
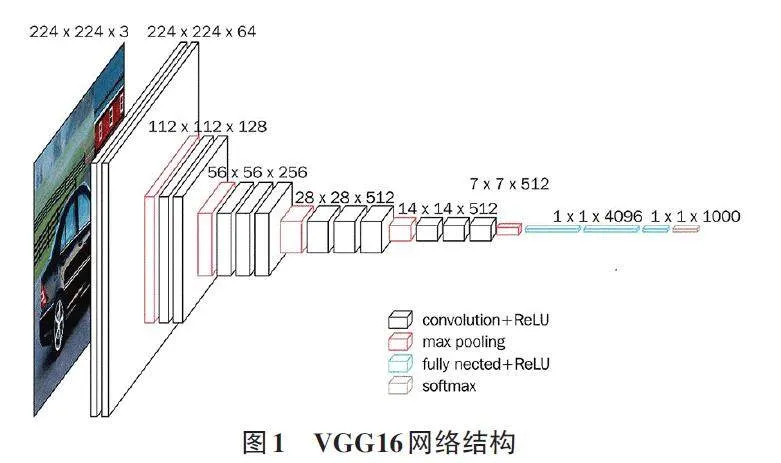
VGG网络结构[7]是2014年ILSVRC竞赛中由牛津大学的几何团队提出的。VGG 网络很好地继承了AlexNet的衣钵,同时也拥有着鲜明的特点,具有较深的网络层次结构。VGG16(见图1) 是比较经典的VGG网络之一。
从图1中可以看出,VGG网络中输入图像的大小默认为224×224×3,每个卷积核包含3 个权值。VGG16代表了包含13个卷积层和3个全连接层的16 层网络结构,不包含池化层和SoftMax层。在不同的卷积层中,卷积核的数量也有差异,VGG16的卷积核尺寸为3×3。池化层大小为2×2。在全连接层中,神经元数目分别为4 096,4 096,1 000。第三级的全部连接层包含了1 000个负责分类输出的神经元,最后一层为SoftMax输出层。
1.2 改进的VGG 网络结构
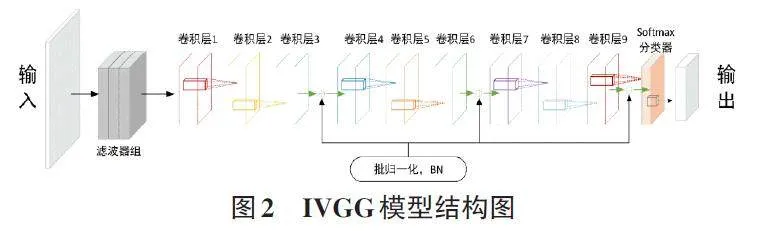
图2为本文提出的IVGG模型结构,由滤波器组、卷积层、批归一化、池化层、分类器等构成。
1.2.1 滤波器组
滤波器实质上是一种矩阵。该方法通过矩阵大小的变化,从多个角度进行特征信息的提取。输入图像的滤波算法,其实就是将m × n 矩阵与图片中同样尺寸的面积相乘并相加。将该矩阵从左至右依次进行1次点乘运算,最后将所得到的结果相加,完成对整幅图像的滤波。矩阵与局部图像相乘的过程与CNN 的卷积操作相同。
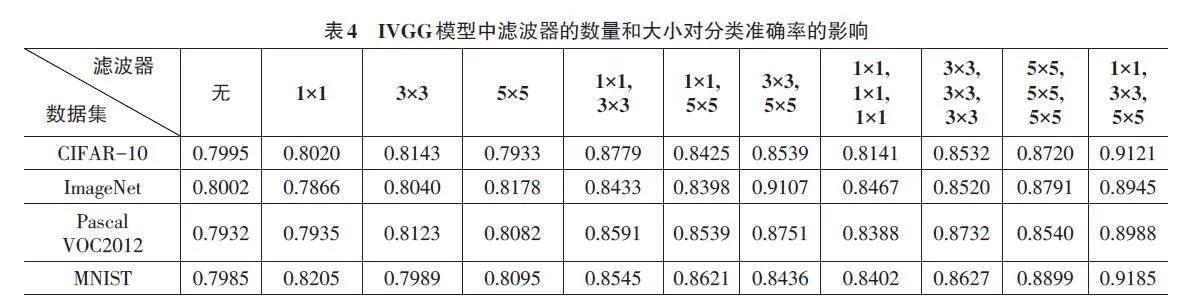
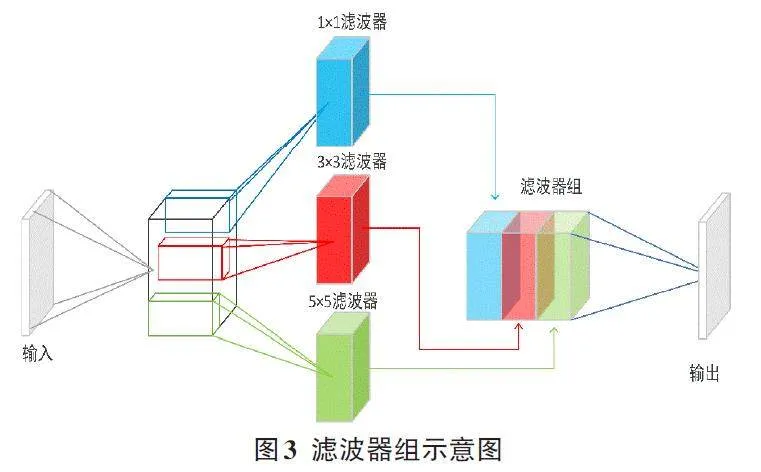
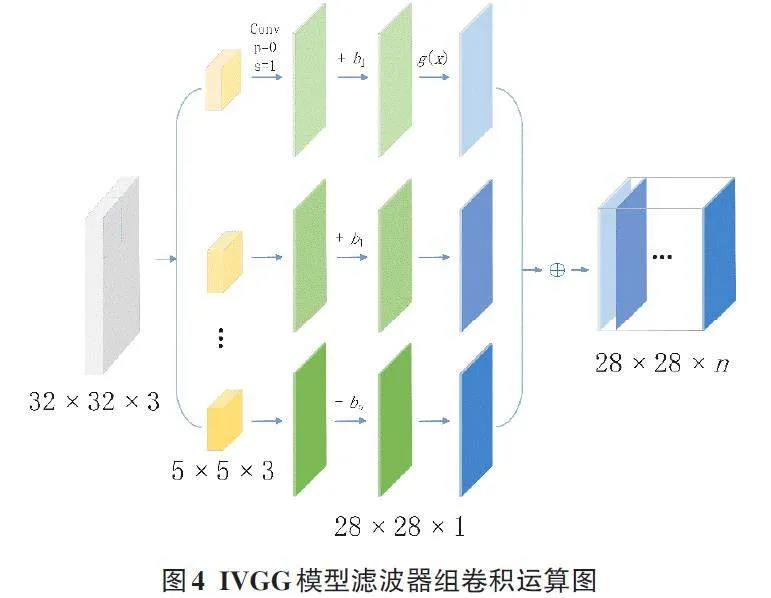
在IVGG模型中,采用了三种不同尺寸的多尺度滤波器(1×1、3×3和5×5) ,以获得多个不同角度的图像特征。滤波器组如图3所示。
针对三个滤波器的特征图的大小差异,本文提出了一种通过调节三个特征图大小来合成联合特征图的方法。首先,将三种不同尺寸滤波器得到的特征图尺寸分别设定为(H+4、W+4) 、(H+2、W+2) 、(H、W) ,其中H与W为输入图像的高与宽。IVGG模型的输入是一个32×32像素值的阵列。利用零来填充图像边缘后,这三种滤波器的尺寸都变成了5×5,卷积后可获得28×28的图像,这是由滤波器经卷积运算获得的图像特征信息。图4描述了滤波器和图像的卷积操作。
在经过一组滤波器的计算后,将其合成特性图输出给下一个卷积层。本文的卷积层视窗设定为1×1,核心数目设定为128,最后得到128 张28×28 的特性图。
1.2.2 批归一化
2012年,AlexNet模型[8]首次提出了局部归一化算法(Local Response Normalization) ,简称LRN。
式(1)中归一化的结构为bix,y,将通道位置的值标记为i,j ~ i 的像素值平方和标记为j,像素的位置表示为x,y,bix,y 为LRN层的输入值同时也是ReLU激活函数的输出值,卷积层表示为α(包括卷积层与池化层操作),N表示通道数量channel。
IVGG网络在提出时抛弃了LRN归一化的处理,采用批归一化来代替。在模型训练过程中,参数会不断更新,数据在各个层次上通过向前传播而不断变化,这种变化导致了分布偏差。针对这一问题,提出了批归一化(Batch Normalization,BN) ,通过引入BN方法,可以使数据保持正常分布,加速模型的收敛,并减少训练过程中网络模型的计算消耗。
1) 记n 为batch样本的总和,{ x1,x2,x3,...,xn }为输入数据集合,计算该批输入数据均值E,表达式为:
由式(5)可以得出,该操作是在水平和垂直两个维度对BN计算后的值进行变换,将最终输出值调整为标准的正态分布。
2 仿真实验与结果分析
2.1 数据集选择
本文采用CIFAR-10 数据集、ImageNet 数据集、Pascal VOC2012数据集、MNIST数据集对IVGG模型进行评价。CIFAR-10的资料包括10种类型的60 000 个样本,每种类型6 000个。ImageNet的资料包括27 个大类别,超过一千四百万张照片,每一个类别都有数千至数万幅。Pascal VOC2012的资料包括17 125 张照片,可以分成20个常见物体类别。MNIST的资料包括10种类型的70 000个样本。
在这四种数据集中,从每个类别的训练样本中选取250个作为训练集,测试样本中选取1 000个作为测试集。在此基础上,选择5%的样本作为训练样本,以模拟在使用少量的样本时,模型能够获得更多的特征信息,从而达到更好的分类效果。
2.2 参数设置
实验相关参数设置如下,设定训练参数Batchsize 为24,Dropout 值为0.5,weight decay 为5 × 10-4,初始学习速率为0.002,学习速率的幅度随着迭代次数的增加不断调节。卷积核窗口大小设定为1×1,数量为128个,卷积步长为1,最终的分类器包含10个神经元,并将其划分为10个类别。迭代次数为300。在所有的实验中,进行了300次随机的训练与分类实验,并报告了整体的分类准确度和损失值。
2.3 实验结果与分析
为了体现IVGG方法的特点和性能,将其与DN4 方法[9]、MACO 方法[10] 以及CovaMNet 方法[11] 进行了对比。
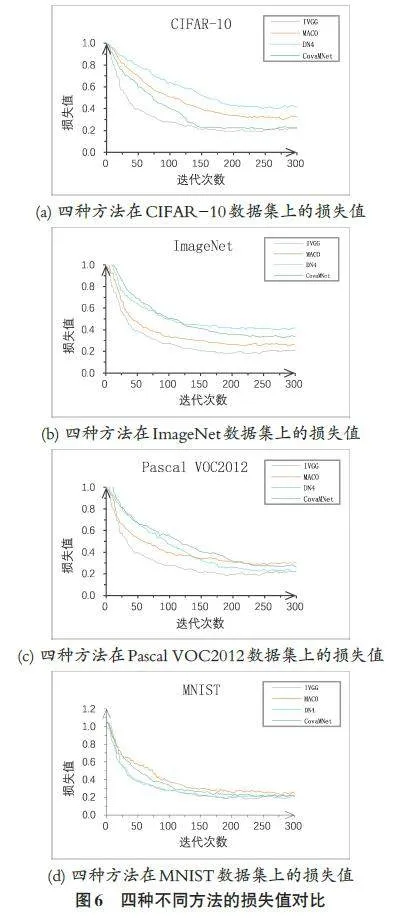
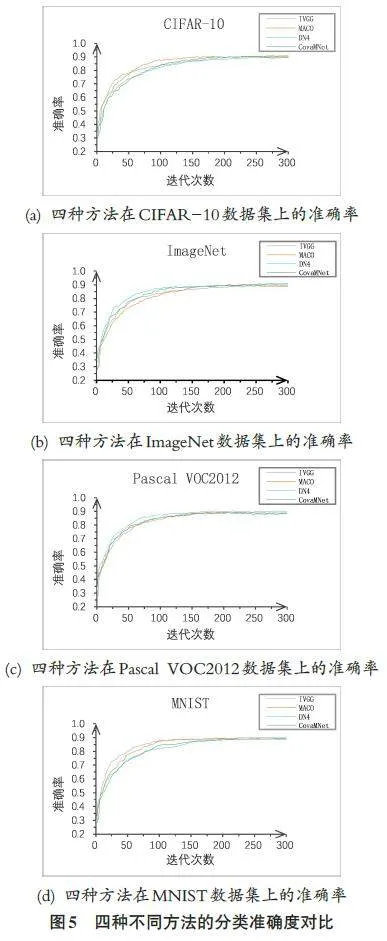
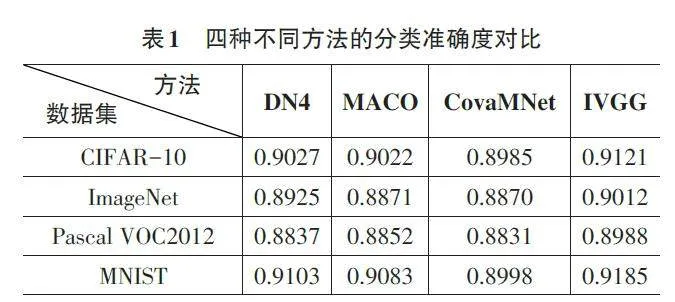
图5中显示了四种方法的分类准确度实验对比结果。实验对每一种方法进行了300 次迭代训练,在CIFAR-10、ImageNet、Pascal VOC2012 和MNIST 四组数据集中,四种方法的准确率在250~285次迭代间逐渐趋于平稳。表1中显示了四种方法的分类准确度实验对比结果。IVGG方法在CIFAR-10、ImageNet、Pas⁃cal VOC2012和MNIST数据集上的分类准确度分别为91.21%、90.12%、89.88%和91.85%。其中,IVGG相较DN4方法的分类准确度提升在0.82%~1.51%。IVGG 相较MACO方法的分类准确度提升在0.99%~1.41%。IVGG 相较CovaMNet 方法的分类准确度提升在1.36%~1.87%,在MNIST 数据集上的准确率提升最高,达1.87%。综合实验结果,对比其他三种方法,IVGG在四种数据集上的分类准确度都取得了最高值,证明了提出模型的有效性;IVGG每次进行特征提取时利用多尺度滤波器组获得多个角度的图像特征,相较于其他方法,在样本数量较少的情况下图像分类的准确率更高。
各网络结构在四种数据集上的损失值随迭代次数的变化趋势如图6所示,可以看出四种方法的损失值在250-290次迭代间得到了比较稳定的结果。其中本文所提的IVGG方法具有更快的收敛速度,最终损失值也最低。表2显示了四种方法的损失值实验对比结果。IVGG 方法在CIFAR-10、ImageNet、PascalVOC2012 和MNIST 数据集上的损失值分别为0.21、0.20、0.19和0.18。相较其他方法,IVGG的损失值均有大幅度下降。与DN4方法相比,IVGG在CIFAR-10 上的损失值下降幅度最大,下降了0.18。与MACO和CovaMNet方法相比,IVGG的损失值下降幅度分别为0.07~0.14和0.02~0.12。从实验结果来看,另外三种方法的损失值比IVGG方法要大得多,证明本文所提出的改进方法在提高模型准确率的同时,拥有更低的损失值。
2.4 消融实验
2.4.1 最优内核数目
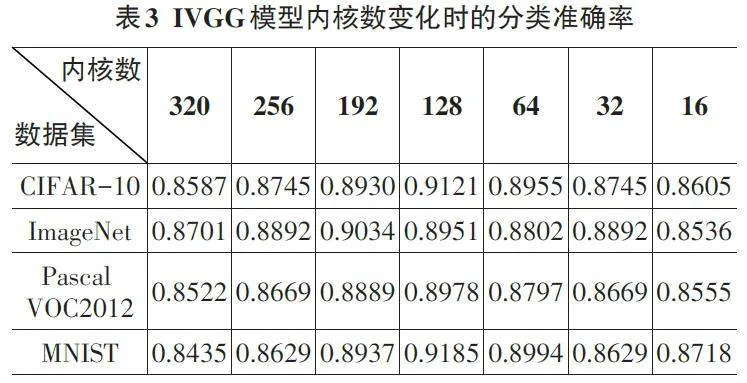
表3 为在CIFAR-10、ImageNet、Pascal VOC2012 和MNIST数据集上验证IVGG模型内核数变化时的分类准确率消融实验结果。由于样本数目和类型的增多,为了获得最优的模型,必须使用更多的卷积核,但加入过多的内核不仅会降低模型性能,还会增加计算开销。本文对不同内核数目组合的IVGG模型进行了少样本图像分类实验。实验结果如表3所示,当内核数为128时,IVGG方法在CIFAR-10、Pascal VOC2012 和MNIST三个数据集上的图像分类正确率最高。在ImageNet数据集上,IVGG方法达到最高分类精度时,内核数为192,而在128个内核的情况下,其精确度也能达到89.51%。因此,IVGG模型选择的最优内核数目为128。
2.4.2 多层次滤波器的有效性
多层次滤波器考虑了从多个角度对图像特征的提取。表4为在CIFAR-10、ImageNet、Pascal VOC2012和MNIST数据集上验证IVGG模型中的滤波器的数量和大小对分类准确率的影响。实验结果显示:在只采用单一滤波器的情况下,模型对四种数据集的分类精度均在80%左右;采用双滤波器对不同类型的样本进行分类,其正确率大多在83%~88%;采用三种不同的卷积滤波,IVGG 模型在CIFAR-10、Pascal VOC2012 和MNIST数据集上分类的正确率分别为91.21%、89.88% 和91.85%;在ImageNet数据集上,使用3×3和5×5的滤波器达到的分类效果最佳,但使用1×1、3×3和5×5 滤波器的分类效果也很好,准确率为89.45%,证明了多层次滤波器的优势。而IVGG模型仅采用单一滤波器时其性能降低的主要原因在于,单一滤波器不具备多层次滤波器多方位特征提取的优点。
3 结论与展望
本文提出了一种基于VGG网络模型的多层次滤波器方法,IVGG。该方法主要利用1×1、3×3和5×5的多个滤波器对输入的图像进行全方位、多角度的特征采集,以便能够最大程度地获取图像的语义信息。在卷积层之后,引入了批归一化处理,以提高模型的鲁棒性和学习效率。最后,通过应用SoftMax函数对输出进行分类,从而达到图像分类的目的。实验结果表明,本文所提出的IVGG模型在少样本图像分类方面具有较高的准确率,并且能够获得更低的损失值,证明了该方法的有效性。然而,由于目前的数据集样本类型相对单一,为了更好地适应处理多个小样本集的情况,需要进行更深入的研究。在未来的工作中,将进一步扩充和丰富数据集,探索更多样本类型的特征,设计泛化能力和稳定性更高的模型。
参考文献:
[1] 刘建伟,刘媛,罗雄麟.半监督学习方法[J].计算机学报,2015,38(8):1592-1617.
[2] ELEZI I,TORCINOVICH A,VASCON S,et al.Transductive la⁃bel augmentation for improved deep network learning[C]//201824th International Conference on Pattern Recognition (ICPR).Beijing,China.IEEE,2018:1432-1437.
[3] TRAN N T,TRAN V H,NGUYEN N B,et al.On data augmenta⁃tion for GAN training[C]//IEEE Transactions on Image Process⁃ing.IEEE,2021:1882-1897.
[4] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vi⁃sion and Pattern Recognition (CVPR). Las Vegas, NV, USA.IEEE,2016:770-778.
[5] VINYALS O,BLUNDELL C,LILLICRAP T, et al.Matching net⁃works for one shot learning[C]//Proceedings of the 30th Interna⁃tional Conference on Neural Information Processing Systems.Barcelona, Spain. MIT Press,2016: 3637-3645.
[6] SUNG F,YANG Y X,ZHANG L,et al.Learning to compare:rela⁃tion network for few-shot learning[C]//2018 IEEE/CVF Confer⁃ence on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA.IEEE,2018:1199-1208.
[7] SIMONYAN K,ZISSERMAN A.Very deep convolutional net⁃works for large-scale image recognition[J].ArXiv e-Prints,2014:arXiv:1409.1556.
[8] KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet clas⁃sification with deep convolutional neural networks[J].Communi⁃cations of the ACM,2017,60(6):84-90.
[9] LI W B,WANG L,XU J L,et al.Revisiting local descriptor based image-to-class measure for few-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Long Beach,CA,USA.IEEE,2019:7253-7260.
[10] LIN T Y,ROYCHOWDHURY A,MAJI S.Bilinear CNN modelsfor fine-grained visual recognition[C]//2015 IEEE Interna⁃tional Conference on Computer Vision (ICCV).Santiago,Chile.IEEE,2015:1449-1457.
[11] LI W B,XU J L,HUO J,et al.Distribution consistency based co⁃variance metric networks for few-shot learning[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33(1):8642-8649.
【通联编辑:梁书】
基金项目:安徽理工大学国家级大学生创新训练项目(2020103661092);安徽理工大学(HX2022082726)
