
基于遗传算法的计算机信息管理数据库系统
2024-07-22 00:00:00沈宇翔
电脑知识与技术 2024年16期

关键词:遗传算法;数据库;服务器配置;数据管理
0 引言
随着信息技术发展,传统数据库管理系统在处理大数据环境下复杂查询时面临性能瓶颈。遗传算法作为一种模拟生物进化过程的优化方法,因在全局搜索与并行处理方面的优势,被视为解决此类问题的有力工具。将遗传算法引入计算机信息管理领域,开发基于遗传算法的数据库管理系统,不仅可优化数据查询策略,提高查询处理速度与准确性,还能增强系统对大数据处理的能力,可充分满足现代信息管理的需求。因此研究基于遗传算法的计算机信息管理数据库系统设计与实现,具有重要现实意义。
1 基于遗传算法的计算机信息管理数据库系统设计
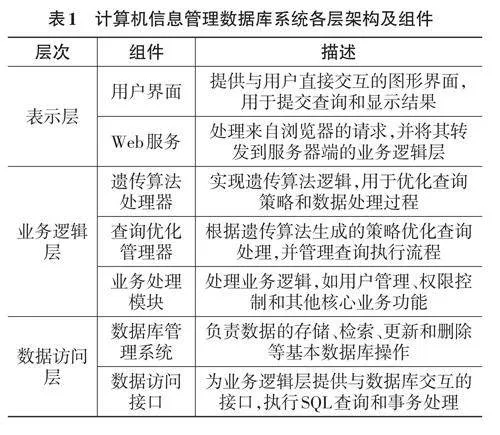
基于遗传算法的计算机信息管理数据库系统总体架构设计,核心目标是通过遗传算法优化数据检索过程,提升系统查询效率与准确性。采用了B/S分层架构,以实现高效的数据管理和查询优化。系统架构分为三个主要层次:表示层、业务逻辑层和数据访问层。1) 表示层位于客户端,主要由Web浏览器组成,负责提供用户交互界面,使用户能通过网络向系统发送查询请求,并接收结果。2) 业务逻辑层位于服务器端,核心是遗传算法引擎,负责生成与优化查询策略,动态调整查询过程以提高效率和准确率。此层还包括处理用户请求、管理会话、执行业务规则的组件[1]。3) 数据访问层是系统与物理数据库之间接口,负责直接与数据库交互,执行SQL语句进行数据的增删查改,也处理由业务逻辑层传递来的经过遗传算法优化的查询请求,具体如表1所示。
2 系统硬件和软件架构
2.1 系统硬件设计
在基于遗传算法的计算机信息管理数据库系统的硬件架构时,需确保硬件能支撑复杂算法的计算需求与大量数据的处理。在服务器选用上,选定了Dell PPloawtienruEmdg 8e2 R809M40处xa理作器为,服CP务U具器有平2台8个,配核备心与Int5el6 X个e线on程,基准频率为 2.7 GHz,最大 Turbo 频率达到 4.0 GHz。为支持高强度计算需求与数据处理,服务器配置了512 GB的DDR4 RAM。数据存储方面,选择Dell EMC Unity XT 880F 全闪存阵列,提供15TB 的高速SSD存储空间,该存储系统能支持高达5 GB/s的数据传输速率,确保大数据集的快速处理与访问能力。网络连接通过Cisco Nexus 9000系列交换机实现,交换机能提供高达100 Gbps传输速率,保证数据在系统内部的高速流通[2]。为增强系统稳定性与可靠性,本系统采用了双电源配置与冗余网络结构。这样的硬件配置为数据库系统提供了高性能的运算能力、快速的数据存取速率与稳定的运行环境,可确保系统能高效、稳定地运行,充分满足复杂数据处理的需求。
2.2 软件模块设计
本系统软件模块主要由数据查询优化与执行模块、数据管理与存储模块、用户界面模块、遗传算法集成模块4个核心模块构成,具体如图1所示,各个模块相互独立,负责不同的功能领域,确保系统整体的高效运作与优秀的性能表现。通过模块化设计,系统可灵活应对各种操作需求,还能整合遗传算法,以提升数据处理与查询的效率。
2.2.1 数据查询优化与执行模块
数据查询优化与执行模块设计是利用遗传算法来优化查询处理流程,达到查询响应时间,提升处理效率的目的。该模块集成了遗传算法优化引擎,负责生成、优化查询策略。优化过程开始于定义一个适应度函数f (q),该函数用于评估查询策略效能,如查询响应时间、资源消耗。遗传算法通过迭代过程不断优化这个适应度函数,以寻找最佳的查询执行路径。适应度函数定义可表示为公式(1) :
式(1) 中,f (q)代表适应度函数;T (q)是执行查询q的时间。通过适应度评估,选择性能较优计划进行遗传操作,包括种群、选择、交叉、变异4个主要概念。种群代表了一组可能的查询执行计划,每个计划被视为一个“个体”。在每次迭代中,算法选择适应度较高个体进行交叉与变异,生成新的查询执行计划。选择操作依据适应度函数确定,采用锦标赛选择方法。交叉与变异操作则用于生成具有新特性的查询计划,其中交叉率与变异率是算法的关键参数,可设定为0.7和0.01,分别表示有70%概率进行交叉与1 %的概率进行变异。通过这种方式,数据查询优化与执行模块不断迭代改进查询策略,直至找到最优或近似最优的查询执行计划。这一过程可提高查询效率,减少数据检索所需时间与资源,从而优化了整个数据库系统的性能。
2.2.2 数据管理与存储模块
数据管理与存储模块设计核心是高效的数据存取与优化的存储结构。本研究采用B+树作为索引结构,查找效率可以表示为O(logn),其中n 是数据块的数量。B+树特点是所有实际数据指针都存在叶节点,叶节点之间以链表形式相连。这种结构使得范围查询变得极为高效。在存储方面,采用分布式存储技术,数据分片(Sharding) 方法按照特定规则将数据分散存储在多个节点上,每个节点操作数据集大小可表示为Dtotal N。其中,Dtotal 是总数据量,N 是节点数量。这种方法旨在平衡负载并优化资源使用,提高数据存取速度。为保证数据一致性与可靠性,该模块实施事务管理,遵循ACID原则,其中一个事务的完整性保证可通过原子性(Atomicity) 操作实现,若事务中的操作表示为 T = {O1,O2,...,O } n ,则要所有操作{O1,O2,...,O } n成功执行,要么全都不执行,从而确保数据的一致性。数据管理与存储模块为系统提供了坚实的数据支撑基础。
2.2.3 用户界面模块
用户界面模块设计核心是提供清晰、直观的操作界面,以支持用户高效地进行数据查询、管理与系统监控。该模块采用现代Web技术栈,如HTML5、CSS3、Ja⁃ vaScript框架来实现响应式设计,确保用户界面能适应不同设备与屏幕尺寸。该模块核心功能包括动态仪表板、显示系统状态、查询统计、性能指标;数据查询界面,支持构建、提交和管理查询,及显示查询结果;数据管理区域,提供数据上传、编辑、删除功能,允许用户调整遗传算法参数、数据库设置、安全配置。用户界面模块集成了高级搜索功能,使用户能通过多条件筛选快速定位数据。所有操作界面都设计为用户友好,支持拖放操作与即时反馈,确保系统操作的直观性与效率[3]。用户界面模块还包含帮助文档支持,可为用户提供系统使用指南与故障排除信息。旨在通过以用户为中心的界面设计,提升用户体验,使非技术用户也能轻松管理、操作复杂的数据库系统。
2.2.4 遗传算法集成模块
遗传算法集成模块专门负责将遗传算法应用于查询优化与数据管理过程,旨在实现高效的数据检索与资源利用。该模块内置遗传算法引擎,通过模拟生物进化过程中的选择、交叉、变异来优化数据库查询。遗传算法核心是适应度函数,用于评估查询计划性能,公式可以定义为:
式(2) 中,f (q)代表适应度函数;t 代表查询执行时间,c代表资源消耗成本。
模块开始工作时,首先生成初始种群,代表不同的查询执行计划。其次通过执行查询并评估其性能,模块根据适应度函数选择最优秀计划进行繁殖,采用交叉、变异操作生成新的查询计划种群。最后整个过程会在多代中迭代,直到找到满足特定性能标准的查询计划。模块还提供界面让数据库管理员可配置遗传算法的参数,如种群大小、交叉率、变异率,以适应不同的数据环境与查询需求。通过集成遗传算法,遗传算法集成模块不仅优化了查询处理过程,还提高了数据库系统的整体性能与资源效率,使系统能动态适应不断变化的数据访问模式与负载条件。
3 系统实现
3.1 系统开发环境
开发环境包括服务器端与客户端两大部分,服务器端使用Java语言配合Spring Boot框架,利用其强大的依赖注入与模块化特性来构建后端逻辑。数据库管理使用PostgreSQL,遗传算法的实现使用Python语言,借助NumPy和Pandas库处理数据分析和算法的数值运算,并使用DEAP库进行遗传算法的实现和优化。客户端开发采用React框架,结合TypeScript语言提高代码可靠性与可维护性。前后端数据交互通过RESTful API实现,使用JSON格式进行数据交换,确保系统灵活性与扩展性。开发过程中,使用Git进行版本控制,支持团队协作与代码管理。在性能测试上,使用JUnit和Selenium进行后端和前端的自动化测试,确保代码质量与功能的正确实现。遗传算法参数,如种群大小、交叉率、变异率等,在初期根据标准测试集进行调优,以确定最佳运行配置[4]。系统开发环境包含持续集成和持续部署(CI/CD) 流程,使用Jen⁃ kins自动化构建过程,确保每次提交的代码都能快速集成,且稳定运行。这种综合的开发环境设计支持了基于遗传算法的计算机信息管理数据库系统的高效开发与稳定运行,可确保系统的高性能与高可靠性。
3.2 遗传算法实现步骤
在系统实现中,遗传算法的具体实施步骤遵循经典遗传算法流程,初始化种群,包含数百到数千个个体,每个个体代表一个潜在的数据库查询优化方案。个体被随机生成,确保种群多样性。适应度函数定义为公式(3) :
式(3) 中,t(q)是查询执行时间;c(q)是资源消耗;λ 是一个权重系数,用于平衡执行时间和资源消耗的重要性。遗传算法的核心参数包括种群大小、交叉率、变异率。在实际应用中,种群大小设置为100到500之间,以确保算法有足够搜索空间,但也不会过于消耗计算资源。交叉率设定在0.6到0.9之间,高交叉率有助于保持种群的多样性;变异率较低,通常在0.01到0.1之间,以避免过多的随机性破坏优良的解决方案。在迭代过程中,通过锦标赛选择方法选出性能优良的个体进行繁殖,再通过单点或多点交叉操作产生新一代个体,通过随机变异引入新的遗传多样性。迭代继续进行,直到达到预设的迭代次数或适应度改进达到平稳状态,最终目的是发现最佳的查询执行策略(最小化查询时间与资源消耗)。为确保算法执行过程能达到最佳性能[5],本研究提出了通过日志记录与性能监控工具跟踪算法的进展,并在必要时调整参数以改善结果。从而确保遗传算法能有效地集成到计算机信息管理数据库系统中,优化查询处理能力。通过这种方法,遗传算法能在庞大的解空间中搜索并优化数据库查询性能。
4 实验设计
4.1 实验过程设计
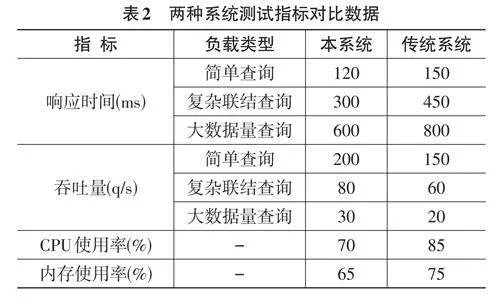
为验证基于遗传算法的计算机信息管理数据库系统(以下简称本系统)性能,本研究采用了对比实验,将本系统与基于传统SQL技术的数据库系统(以下简称传统系统)进行对比,在具体实验中,使用Apache JMeter作为压力测试工具,部署在基于云平台的虚拟机上,确保测试条件的一致性与可控性。对比指标包括查询响应时间、系统处理能力(吞吐量)、资源利用率(如CPU、内存使用率)。实验过程中,首先在两个系统上部署相同规模与结构的数据集,确保公平性。其次通过Apache JMeter配置相同的查询负载,执行一系列标准化测试查询,包括简单查询、复杂联结查询、大数据量查询。再次记录分析两个系统在不同负载条件下的查询响应时间,评估系统的处理能力与资源利用效率。最后监控系统运行状态,包括CPU 与内存使用情况,以全面评价系统性能。
4.2 实验结果分析
如表2所示,本系统在不同的查询负载下表现优于传统系统。验证了遗传算法在数据库查询优化中的有效性,展示了其在提高查询性能与资源管理效率方面的潜力。
5 结束语
本研究通过集成遗传算法优化数据库查询过程,成功实现了一个高效的计算机信息管理数据库系统。实验结果明确展示本系统相较于传统系统在查询效率、数据处理能力、资源利用上的显著优势。证明了遗传算法在数据库查询优化领域的应用潜力,也为未来数据库管理系统研发提供了新思路与技术参考。随着数据量不断增长与查询需求的日益复杂化,基于遗传算法的数据库优化技术将持续发挥其价值,推动数据库技术向更高效、更智能的方向发展。
