
结合改进ShuffleNet-V2和注意力机制的无人机图像自主分类预警框架
2024-07-20 00:00:00杨珍吴珊丹贾如
无线电工程 2024年5期
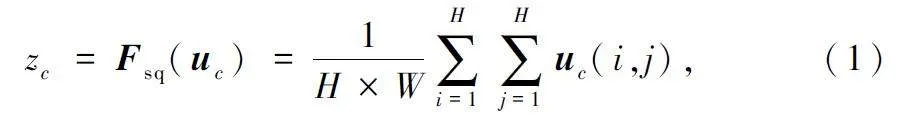








摘 要:为实现灾难事件的无人机(Unmanned Aerial Vehicle,UAV) 自主监测和预警,提出了结合逐通道注意力机制和高效卷积神经网络的新架构。考虑到嵌入式平台的资源限制条件,使用轻量级ShuffleNet-V2 作为骨干网络,能够对更多信息进行高效编码并尽可能降低网络复杂度。为进一步提高灾难场景分类的准确度,在ShuffleNet-V2 网络中结合了挤压-激发(Squeeze-Excitation,SE) 模块以实现逐通道注意力机制,显著增强分类网络对重要特征的关注度。通过数据采集和增强技术获得包括12 876 张图像的UAV 航拍灾难事件数据集,对所提方法进行性能评估,并比较所提方法与其他先进模型的性能。结果表明,所提方法取得了99. 01% 的平均准确度,模型大小仅为5. 6 MB,且在UAV 机载平台上的处理速度超过10 FPS,能够满足UAV 平台自主灾情监测任务的现实需求。
关键词:无人机;图像分类;卷积神经网络;注意力机制;嵌入式平台
中图分类号:TP391 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3106(2024)05-1261-09
0 引言
当前,无人机(Unmanned Aerial Vehicle,UAV)已得到了广泛应用,例如交通监测、搜索救援、精准农业和卫星图像处理等[1]。UAV 尺寸小,可快速部署,是及时分析情况并消减灾难影响的有力工具,但受灾区域常存在连接性和可见性限制[2]。此外,自主UAV 依赖机载传感器和微处理器执行给定任务。需要考虑算力和存储硬件限制,并实现高效视觉处理[3]。
在灾难管理应用的航拍图像分类中,深度学习具有分类准确度高、通用性强的优点,发挥着重要作用[4]。深度学习算法,例如卷积神经网络(Convolutional Neural Network,CNN),被普遍视为许多计算机视觉应用(图像/ 视频识别、检测和分类)的发展方向,并已经在各种应用中表现出优异性能[5]。文献[6]提出了结合CNN 和XGBoost 的道路交通事故分类检测算法,基于组合模型的分类结果进行重要程度排序和特征相关性分析。该方法取得了91. 51% 的预测准确度。但该方法使用的CNN 硬件资源需求较大,不适用于UAV 嵌入式设备。文献[7]提出了在雪崩场景中检测感兴趣目标的方法,使用预训练Inception 网络进行特征提取,并利用线性支持向量机进行分类,并基于隐藏马尔科夫模型,应用后处理以改善分类器的决策。文献[8]提出了基于CNN 的建筑物倒塌预测模型,利用浅层局部特征改善高度和目标形状估计,并使用渐进式情境融合方法改善性能,并取得了最高98. 78% 的整体检测准确度。文献[9]提出了基于深度学习的UAV 航拍图像洪水检测方案,利用Haar 级联分类器捕捉场景特征以识别洪水区域。但该方法使用的训练数据集规模较小,因此在对洪水区域和非洪水区域的分类中仅取得了91% 的准确度。文献[10]提出了UAV 航拍图像的火灾检测算法,其中结合了CNN 和YOLOv3。该方法仅实现了83% 的检测准确度,且在UAV 平台上处理速度FPS 仅为3. 2,不能满足实时应用需求。从过去方法的分析中可发现,当前方法主要采用桌面式系统作为主计算平台,在GPU 上对UAV 视频片段进行远程处理。然而,在特定场景中,通信延迟和连接性问题可能会影响到此类系统的性能,此外,过去方法大部分着眼于单一灾难事件的检测,限制了预警平台的应用范围。
本文提出了使用UAV 机载平台,对灾难事件进行自动分类的解决方案,并针对应急救援应用采集了UAV 航拍图像数据集。以往方法仅针对单一灾难事件,本文方案则训练网络对4 种灾难事件(火灾、洪灾、建筑物坍塌和交通事故)进行识别,极大扩展了UAV 自主监测的应用范围。所提方法使用高效ShuffleNet-V2 架构,大幅降低了硬件资源要求,从而在UAV 嵌入式平台上实现实时处理。利用挤压-激发(Squeeze-Excitation,SE)模块,基于不同通道的重要程度调整注意力机制的关注度,显著改善了分类准确度。由此,在复杂度和准确度之间实现平衡。
1 提出的改进型ShuffleNet-V2
本文开发了基于自主式UAV 平台的灾难事件分类预警方法。在UAV 嵌入式平台上,利用深度学习模型实时分析通过UAV 传感器扑捉到的图像,进行灾难事件监控,并在发生险情时及时发出警报。所提系统中,开发了基于逐通道注意力(Channel-wise Attention,CA)机制的轻量级卷积神经网络。使用ShuffleNet-V2 作为骨干网络,并利用SE 模块作为改善ShuffleNet-V2 架构的注意力机制。
1. 1 ShuffleNet-V2 和SE 模块
近期,基于CNN 的分类系统得到了大量研究,其中对一些性能领先的深度学习框架的简单介绍如下:
AlexNet[11]:VGG 网络被广泛用于从图像中提取CNN 特征。该网络包含5 个卷积和3 个全连接层。该架构准确度较好,但评估成本高,参数量大,内存占用大,不适用于移动应用。
MobileNet[12]:利用可分离卷积的理念,MobileNet 可以在稍微降低分类准确度的前提下减少计算成本。其在每个输入通道处应用单个过滤器,其后进行线性合并。由此,对于移动应用,该网络便于参数化,且易于优化。
为提高深度神经网络(Deep Neural Networks,DNN)在嵌入式设备中的效率并保持准确度,文献[13]提出了ShuffleNet-V1 模型,显著降低了计算成本,并在图像分类任务中取得较好成绩。其中,将模型表示为逐点分组卷积和通道置乱,在特征映射通道中编码更多信息。但由于仅利用小部分输入通道推导出特定通道输出,模型表征能力较差,为此一般采用通道置乱操作,通过将每个分组中的通道分割到不同分组,并将每个分组输入到有着不同子分组的下一层,得到来自不同分组的数据。但瓶颈单元和逐点分组层增加了内存访问成本,过多分组降低了并行度。文献[14]提出了ShuffleNet-V2,考虑到过多分组降低了并行度,利用通道分割替换分组操作,将输入特征分为2个分支,进一步降低了模型复杂度。
近期,注意力机制在各种自然语言处理、图像描述和图像理解领域得到了广泛应用,其中将可用处理资源分配至有用特征表示,同时抑制无用特征表示。文献[15]提出了SE模块,以提高当前模型的性能并降低计算成本,基于逐通道重要性对特征图进行自主调整。与卷积块注意力模块(ConvolutionalBlockAttentionModule,CBAM)[16]、高效通道注意(EffificientChannelAttention,ECA)[17]等其他注意力模块相比,SE模块在准确度和处理速度方面实现了较好的平衡,更适用于针对资源受限的嵌入式平台设计的轻量级模型。
1.2 改进的方法
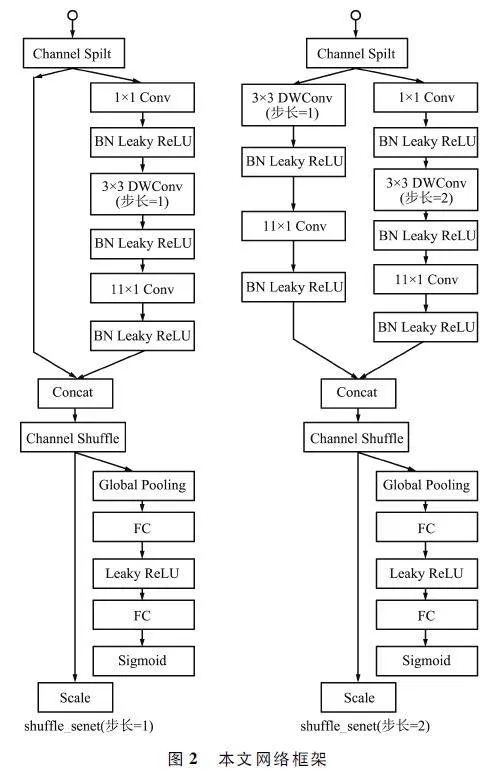
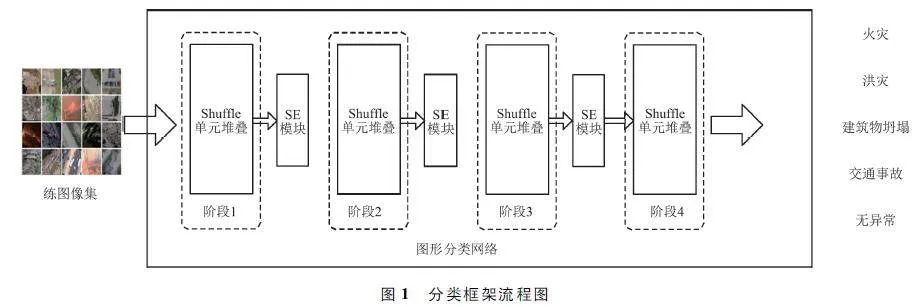
所提基于深度学习模型的UAV灾难图像分类框架的流程如图1所示。首先将训练数据集中的图像输入所提图像分类模型,改进模型中结合了Shuf-fleNet-V2架构和SE模块,在Shuffle架构前3个阶段的级联(Concat)操作后,SE模块输入特征图作为输入,通过对Shuffle模块中不同层级特征图进行加权,从而使网络更加关注重要的特征,在降低计算成本的同时,增强模型的学习能力和分类性能。
所提网络架构如图2所示。ShuffleNet-V2通过4个不同阶段分层逐步提取特征。其中,阶段1学习如边缘和纹理等基础特征,阶段2学习如形状等抽象复杂特征,阶段3学习如语义信息等高级特征,阶段4将高级特征转换为分类预测。所提改进方法在原ShffleNet-V2的前3个阶段的末尾分别添加了一个SE模块,因此,改进架构同样分为4个阶段,第一个阶段的每个模块的步长设为2,以实现下采样。将其余阶段的步长设为1。在每个单元开始时,通过通道分割将特征通道输入分割为2个分支。其中一个分支保持不变,另一个分支则包括有着相同输入和输出通道的3个卷积层,由此替换了分组卷积,降低了内存访问成本。在卷积后,将2个分组串联,使得通道数保持不变。最后,使用通道置乱,确保2个分支之间的信息交换。在ShuffleNet-V2中添加SE模块有3种可行方式。第一种方式是在ShuffleNet单元内部嵌入SE模块,在最后一个卷积层后直接连接SE模块。第2种方式是将SE模块放入与ShuffleNet单元并行的直通分支。第3种方式是将SE模块放置在ShuffleNet架构直通分支的concat操作后。所提方法是针对嵌入式平台实时检测而提出的轻量级模型,应在确保分类准确度的同时,尽量降低计算成本。ShuffleNet-V2架构共包含16个基本区块,如果采取前2种方式,必须嵌入大量SE模块,会使网络变得冗余,大幅增加计算成本。为此,所提方法选择了最后一种嵌入策略,在前3个阶段的末端均放入SE模块,即仅向ShuffleNet-V2架构添加3个SE模块。
在图2框架的下半部分为SE模块。在Shuf-fleNet-V2模块后,使用SENet理念处理特征通道。首先,使用全局平均池化将通道空间特征转换为全局特征;然后,利用全连接(FullyConnected,FC)层降低模型复杂度,提高通用性;使用ReLU作为激活层,使用FC层恢复尺寸;最后,将每个通道的加权系数与原始特征相乘。
在挤压阶段应用全局平均池化,通过生成逐通道统计信息嵌入全局空间信息。具体来说,将输入特征图U=[u1,u2,…,uC]视为通道ui∈RH×W的组合,C为输出通道数。采用简单聚合技术,利用全局平均池化操作对整个图像进行收缩,得到:
式中,Fsq(.)为挤压映射,H×W 为图像尺寸,zc为向量z∈R1×1×C的第c个元素,uc∈U为第c个特征图,(i,j)对应空间位置,i∈ {1,2,…,H},j∈ {1,2,…,W}。U 可视为整个图像的局部描述子集合,包含整个图像的大量统计信息,因此利用全局平均池化降低处理成本。该操作将全局空间信息嵌入向量z。
激发阶段,基于从挤压信息中推导出的聚合信息,充分捕捉逐通道依赖性,学习通道之间的非线性交互以及非互斥信息,以确保允许将多条通道作为重点对象。将z 转换为:
z^= Fex(z,W) = σ(W2 δ(W1 z)), (2)
式中:Fex(. )为激发映射,δ(. )为ReLU 函数,σ 为Sigmoid 层。W1 ∈!Cr×C 和W2 ∈!C×Cr分别为2 个全连接层的权重,其中,参数r 表示压缩比,对逐通道依赖性进行编码。为限制模型复杂度,提高通用性,利用2 个全连接层形成瓶颈,将门限机制参数化,该结构首先为基于参数W1 的降维层,中间为ReLU,其后为基于参数W2 的升维层。根据经验,设r = 2。z^的激活动态区间为[0,1],将其通过Sigmoid 层,即σ(z^)。得到的向量用于对转换输出U 进行重新标定或激发:
U^= [σ(z^ 1 )u1 ,σ(z^2 )u2 ,…,σ(z^ C )uC ], (3)
式中:σ(z^i)表示第i 个通道的重要程度,由此决定对该通道的扩展或收缩。σ(z^i )随着网络学习自适应调整,以忽视不重要的通道,并强调重要通道。图3 给出了修改后的SE 模块在所提框架中的工作原理。
2 实验与分析
本文在Windows 7,CPU Intel i5 9600K @ 3. 7 GHz和GTX 1060 环境下进行,使用Matlab 2016b。现实世界实验中,考虑2 种情况:① 在嵌入式设备上处理所有计算,以验证在资源受限的UAV 平台上的性能;② 使用手机作为UAV 地面基站,连接到UAV控制器以处理输入图像。考虑到实时流处理,即相机按顺序输出每帧图像,重点分析单张图像的处理速度。
2. 1 数据集采集与增强
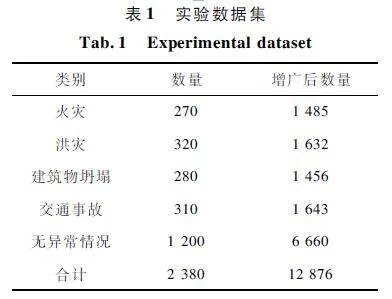
为训练CNN 进行航拍图像分类,首先需要针对该任务采集合适的数据集。为此,本文针对应急救援应用创建了专用数据集。从多个来源采集这些灾难类别的航拍图像,包括百度图像、新闻网站、航拍图像数据库以及从本文的UAV 平台上采集的图像。在数据采集过程中,以不同分辨率、不同的照明和视角条件,捕捉各种不同的灾难事件。最后,为贴近现实世界场景,该数据中的场景占比是不平衡的,其中包含更多的无异常类图像。表1 列举了数据集详情。
UAV 的操作条件会受到不同环境的影响,因此数据集内不应该仅包含清晰的图像。此外,数据采集过程可能非常耗时,成本较高。为进一步扩充数据集,在将图像添加到训练批次之前,先对每个图像应用概率性的随机增广。
① 图像旋转:为得到各种不同方向拍摄到的灾难图像,将数据集中的图像以90°、180°和270°旋转并镜像操作。旋转增强技术能够提高深度神经网络在不同高度执行检测时的分类性能。
② 图像颜色和亮度:为提高灾难事件在不同照明条件下的可见性,以不同亮度水平对图像进行增强,选择合适的图像亮度范围,lmin = 0. 4,lmax = 1. 5。
③ 添加高斯和椒盐噪声:由于UAV 相机可能会捕捉到模糊图像,向图像添加0. 004 的椒盐噪声,以提高模型对不同照明条件下灾难时间的分类能力。
④ 随机裁剪:最高随机裁剪凸显该区域的60% ,并执行翻转、宽度平移和高度平移,从而改善对事故仅仅存在于图片边缘等情况下的检测性能。
⑤ 背景移除:移除背景,以提高模型学习灾难事件的能力。
⑥ 图像缩放:对图像进行0. 8 ~ 1. 0 倍的缩放,用得出的数据集进行训练,以提高模型在UAV 设备上运行时神经网络的分类性能。
以随机概率应用每种变换,并确保不会对训练批次中的所有图像均进行变换,以避免网络将增广属性捕捉为数据集特征。通过数据增强避免过拟合,提高训练集可变性,实现更好的泛化性能。数据集中的一些样本如图4 所示。通过数据集增强技术对初始数据集进行显著扩展,增加了5 倍以上的训练图像。
2. 2 性能度量
本文的最终目标是在UAV 上运行模型,并在线处理每个图像。因此,每个模型取得的每秒帧数(Frame Per Second,FPS)是重要的性能度量。此外,考虑到数据集不均衡情况,在正确分类样本数之外,还使用平均F1 得分作为学习性能指标。
FPS 指标分析分类器处理传入相机帧的速率v:
式中:ti 为单张图像处理速度,Nt 为测试样本数量。
平均F1 得分[18]:该指标测量通过每个类别的测试实例数加权后的所有类别上的平均准确度。该指标同时考虑了精度和召回率,数值较高意味着漏检率和误警率较低:
式中:Nl 为类别数量,pi = tp/tp+fp和sni = tp/tp+fn分别为精度和敏感度,tp 为真阳性检测,fp 为假阳性检测,fn 为假阴性检测。
2. 3 网络训练
通过相同框架对所有网络(AlexNet、MobileNet、ShuffleNet-V1、ShuffleNet-V2 和本文方法)进行训练和测试,以确保相同条件下的公平比较。使用Keras 深度学习框架,并将Tensorflow 作为后端[19]。除了指定较小尺寸输入图像的MobileNet 外,尽可能为所有网络使用相同的图像大小(240 pixel×240 pixel)。将数据集以4 ∶ 1 的比例划分为训练集和测试集。如前文所述,无异常类为主要类,数量超过数据集中其他类别之和,这反映了现实情况,但也可能在网络中产生过拟合问题。为避免数据集不平衡问题,在相同批次内同时对非异常类进行下采样,对其他类别进行上采样。为此,从每个类别中选择相同数量的图像以形成批次,由此实现对各种不同情况的平等表达。
将模型的最后一层替换为输出层,其等于总类别数,本文实验中共5 类,包括4 类灾难场景和1 类无异常场景。对所有网络的超参数进行标准化。使用了Adam 优化方法,初始学习率为0. 001,每5 代乘以0. 95,以实现平滑的学习率衰减。对每个网络进行12 000 代训练,每代包含200 批的迭代,由于GPU 存储限制,将批大小设为16。
2. 4 仿真结果分析
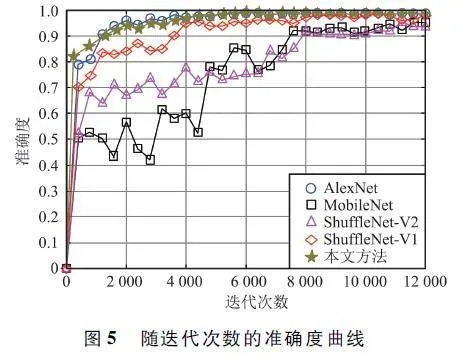
图5 给出了在所提实验数据集上训练时,随着迭代次数增加,AlexNet、MobileNet、ShuffleNet-V1、ShuffleNet-V2 和本文方法的分类准确度。从中可发现,所提方法准确度与AlexNet 大致相当,优于其他方法。这表明所提架构在卷积神经网络中结合了逐通道注意力机制,有效提高了对重要特征的学习能力,改善了网络分类性能,且所提网络在少量迭代次数后就收敛至较高准确度。MobileNet 准确度最低,且曲线波动较大,不适用于对准确度要求较高的灾难监测任务。
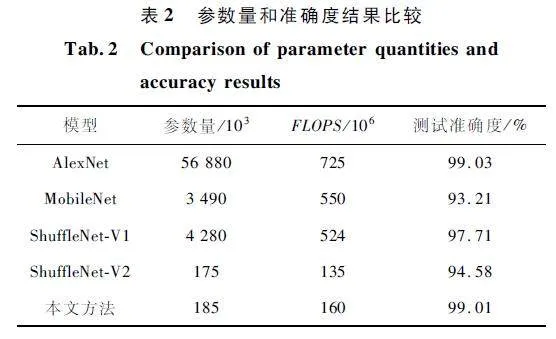
表2 给出了各模型的参数量、每秒浮点运算次数(Floatingpoint Operations Per Second,FLOPS)和在测试数据集上的准确度结果。FLOPS 是与平台无关的复杂度指标。从中可发现,AlexNet 的准确度稍优于所提架构,但该架构的参数量非常大,对计算和存储资源的要求很高,不适用于资源受限的嵌入式设备。ShuffleNet-V2 的准确度低于ShuffleNet-V1,这表明在降低资源使用量的情况下,其分类准确度也受到了影响。所提方法准确度仅稍低于AlexNet,证明所提架构通过结合注意力机制,有效增强了对重要特征的学习和处理能力,使得准确度能够满足UAV 灾难监测任务的要求,且对算力的要求要小得多,能够在低功耗设备上进行实时处理。
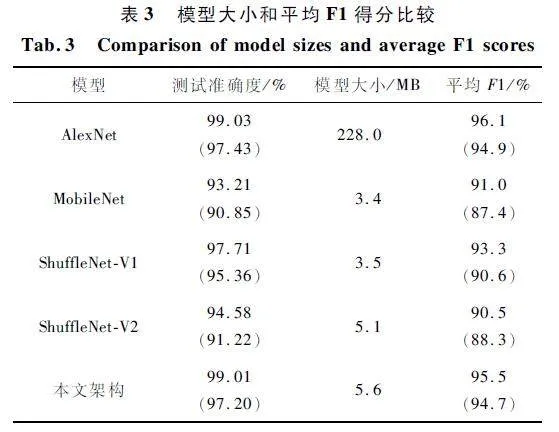
表3 列举了各模型的存储空间和增强训练集上的平均F1 得分。其中,括号内的数值为各模型使用未扩充的训练集进行模型训练后,在同样的测试集上的性能表现。从中可以看出,尽管AlexNet 的平均F1 得分稍优于本文方法,但硬件资源要求过高,不适用于嵌入式平台。MobileNet 的准确度过低,不能满足灾难场景监控任务的要求。所提网络的硬件资源需求和ShuffleNet-V2 大致相当,能够满足实时控制需求,且在分类准确度上获得了较大提升。此外,各方法使用扩充训练集后均取得了显著的性能提升,证明本文使用的训练数据增强策略是有效且必要的。
为分析和比较在进一步降低计算复杂度和模型参数量的情况下所提模型的性能,遵循文献[13 -14]的结构设定,将网络宽度分别缩放至0. 25 倍和1 倍,表示为ShuffleNet(0. 25 ×)和ShuffleNet(1 ×),然后将SE 模块分别应用到这2 个模型中。图6 给出了本文方法分别应用到不同网络宽度的ShuffleNet-V1 和ShuffleNet-V2 时,每个类别(火灾、洪灾、建筑物坍塌、交通事故和无异常)的分类结果,并与原始模型的结果相比较。从中可发现,所提方法在应用到ShuffleNet-V2 后,在5 个类别的分类准确度分别为99. 2% 、99. 6% 、100% 、95% 和88% 。所提方法在应用到ShuffleNet-V1 后,性能得到了进一步提升,但由于网络复杂度过高,如后文现实场景测试结果所示,ShuffleNet-V1 不能满足机载平台的实时性需求。此外,从实验结果中可发现,各方法在无异常场景中的分类准确度都相对较低,这是因为在特别复杂的场景中,例如交通严重拥堵场景,或者拍摄目标被遮挡的情况下,模型可能会将正常场景误分入某种灾难事件类别。
2. 5 现实场景测试结果
在现实场景中评估所提架构的性能。使用计算资源和能量受限的移动设备,测量所提网络的处理速度和比较方法的帧率。测试中使用了2 种不同场景。场景1 针对机载处理平台,场景2 使用手机连接作为UAV 移动地面基站,连接到UAV 控制器以处理输入图像。这2 种场景均易于部署,适合应急场景中的远程监测任务。图7 给出了实验平台,其中,图7 (a)为配置了高清相机的大疆Matrice 200无人机,图7(b)为UAV 控制平台,采用广播式自动相关监视系统(Automatic Dependent Surveillance-Broadcast,ADS-B),参数包括位置精度指标(PositionPrecision Indicator,PPI)和高度指标。ADS-B PPI 是基于水平和垂直位置精度指标计算得出的综合指标,ADS-B 高度为UAV 相对于海平面的垂直高度。
① UAV 机载处理:记载处理平台采用四核ARM Cortext-A53 处理器,性能和功耗方面能够满足UAV 需求。对于图像分类预警等实时应用场景,处理速度对于实时性至关重要。当模型的FPS 较低时,处理速度变慢,可能导致处理延迟,从而无法满足实时性的要求。表4 给出了不同模型在机载平台和移动基站上的处理速度FPS 结果,从中可发现,所提网络在该平台上取得了12. 5 FPS 的结果,优于其他方法,能够满足实时处理需求。
② UAV 移动基站处理:将UAV 控制器连接到作为移动控制基站的手机,接收UAV 相机图片并进行处理。其他方法的帧率均为8 FPS 以下,本文方法取得了约10 FPS 的结果。要指出,在现实场景中,UAV 和控制器之间存在干扰,会影响到灾难事件监测任务的可靠性[20]。UAV 机载平台能够很好地克服连接性和可见性方面的约束,更适用于应急救援任务。
3 结束语
本文提出了应急救灾应用的UAV 机载实时检测预警方案。利用高效深度学习系统,在UAV 平台上对传感器拍摄到的图像进行实时处理,自动对灾难事件进行识别和分类。所提架构结合了轻量级ShuffleNet-V2 网络和SE 单元,在提高分类准确度和降低硬件资源消耗之间实现了较好平衡。实验结果证明所提方案适用于资源受限的嵌入式平台,且分类准确度能够满足实时灾情监控应用的需求。
参考文献
[1] PS R,JEYAN M L. Mini Unmanned Aerial Systems(UAV)A Review of the Parameters for Classification of aMini UAV [J]. International Journal of Aviation,Aeronautics,and Aerospace,2020,7(3):126-134.
[2] 周剑,贾金岩,张震,等. 面向应急保障的5G 网联无人机关键技术[J]. 重庆邮电大学学报(自然科学版),2020,32(4):511-518.
[3] DOBREA D M,DOBREA M C,OBREJA M E. UAV Embedded SystemA Selection Process[C]∥2021 International Symposium on Signals,Circuits and Systems(ISSCS). Iasi:IEEE,2021:1-4.
[4] 程擎,范满,李彦冬,等. 无人机航拍图像语义分割研究综述[J]. 计算机工程与应用,2021,57(19):57-69.
[5] KATTENBORN T,LEITLOFF J,SCHIEFER F,et al. Review on Convolutional Neural Networks (CNN)in Vegetation Remote Sensing[J]. ISPRS Journal of Photogrammetry and Remote Sensing,2021,173:24-49.
[6] 石雪怀,戚盠,张伟斌,等. 基于组合模型的交通事故严重程度预测方法[J]. 计算机应用研究,2019,36(8):2395-2399.
[7] BEJIGA M B,ZEGGADA A,NOUFFIDJ A,et al. A Convolutional Neural Network Approach for AssistingAvalanche Search and Rescue Operations with UAV Imagery[J]. Remote Sensing,2017,9(2):100.
[8] AMIRKOLAEE H A,AREFI H. CNNbased Estimation ofPreand Postearthquake Height Models from SingleOptical Images for Identification of Collapsed Buildings[J]. Remote Sensing Letters,2019,10(7):679-688.
[9] MUNAWAR H S,ULLAH F,QAYYUM S,et al. Applicationof Deep Learning on UAVbased Aerial Images for Flood Detection[J]. Smart Cities,2021,4(3):1220-1242.
[10] JIAO Z T,ZHANG Y M,XIN J,et al. A Deep LearningBased Forest Fire Detection Approach Using UAV andYOLOv3[C]∥2019 1st International Conference on Industrial Artificial Intelligence (IAI). Shenyang:IEEE,2019:1-5.
[11] 党宇,张继贤,邓喀中,等. 基于深度学习AlexNet 的遥感影像地表覆盖分类评价研究[J]. 地球信息科学学报,2017,19(11):1530-1537.
[12] 王威,邹婷,王新. 基于局部感受野扩张DMobileNet模型的图像分类方法[J]. 计算机应用研究,2020,37(4):1261-1264.
[13] ZHANG X Y,ZHOU X Y,LIN M X,et al. Shufflenet:AnExtremely Efficient Convolutional Neural Network for Mobile Devices[C]∥ Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition. Salt LakeCity:IEEE,2018:6848-6856.
[14] MA N N,ZHANG X Y,ZHENG H T,et al. ShuffleNet V2:Practical Guidelines for Efficient CNN Architecture Design[C]∥Proceedings of the European Conference on ComputerVision (ECCV). Munich:Springer,2018:122-138.
[15] HU J,SHEN L,SUN G. SqueezeandExcitation Networks[C]∥Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Salt Lake City:IEEE,2018:7132-7141.
[16] WOO S,PARK J,LEE J Y,et al. CBAM:ConvolutionalBlock Attention Module [C ]∥ Proceedings of theEuropean Conference on Computer Vision (ECCV). Munich:Springer,2018:3-19.
[17] WANG Q L,WU B G,ZHU P F,et al. ECANet:EfficientChannel Attention for Deep Convolutional NeuralNetworks[C]∥Proceedings of the IEEE / CVF Conferenceon Computer Vision and Pattern Recognition. Seattle:IEEE,2020:11534-11542.
[18] HOSSIN M,SULAIMAN M N. A Review on EvaluationMetrics for Data Classification Evaluations [J ].International Journal of Data Mining & Knowledge Management Process,2015,5(2):1-11.
[19] GRATTAROLA D,ALIPPI C. Graph Neural Networks inTensorFlow and Keras with Spektral [Application Notes][J]. IEEE Computational Intelligence Magazine,2021,16(1):99-106.
[20] 张广驰,陈娇,崔苗,等. 无人机交替中继通信及其轨迹优化和功率分配研究[J]. 电子与信息学报,2022,43(12):3554-3562.
作者简介
杨 珍 女,(1982—),硕士,副教授。主要研究方向:计算机图形图像等。
(*通信作者)吴珊丹 女,(1981—),硕士,副教授。主要研究方向:计算机图形图像等。
贾 如 女,(1982—),博士,讲师。主要研究方向:大数据、社交网络和智能推荐。
基金项目:国家自然科学基金(32160506);内蒙古自治区自然科学基金(2014MS0616)
猜你喜欢
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
现代电子技术(2017年1期)2017-02-16 11:13:19
计算机应用(2016年12期)2017-01-13 20:26:21
现代电子技术(2016年22期)2016-12-26 15:51:05
软件导刊(2016年9期)2016-11-07 22:20:49
软件导刊(2016年9期)2016-11-07 22:19:22
软件工程(2016年8期)2016-10-25 15:47:34
