
基于CNN-Transformer的欺骗语音检测
2024-07-20 00:00:00徐童心黄俊
无线电工程 2024年5期




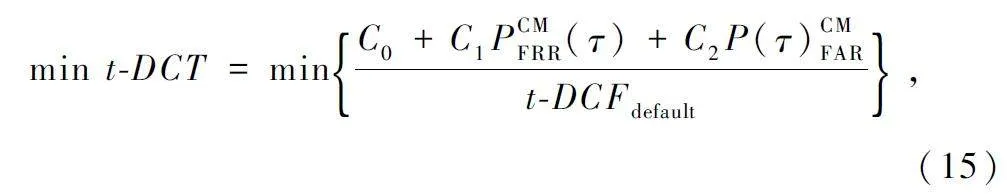







摘 要:语音合成和转换技术的不断更迭对声纹识别系统产生重大威胁。针对现有语音欺骗检测方法中难以适应多种欺骗类型,对未知欺骗攻击检测能力不足的问题,提出了一种结合卷积神经网络(Convolutional Neural Network,CNN) 与Transformer 的欺骗语音检测模型。设计基于坐标注意力(Coordinate Attention,CA) 嵌入的SE-ResNet18 的位置感知特征序列提取网络,将语音信号局部时频表示映射为高维特征序列并引入二维位置编码(two-Dimensional Position Encoding,2D-PE) 保留特征之间的相对位置关系;提出多尺度自注意力机制从多个尺度建模特征序列之间的长期依赖关系,解决Trans-former 难以捕捉局部依赖的问题;引入特征序列池化(Sequence Pooling,SeqPool) 提取话语级特征,保留Transformer 层输出帧级特征序列之间的相关性信息。在ASVspoof2019 大赛官方逻辑访问(Logic Access,LA) 数据集的实验结果表明,提出的方法相对于当前先进的欺骗语音检测系统,等错误率(Equal Error Rate,EER) 平均降低12. 83% ,串联检测成本函数(tandem Detection Cost Function,t-DCF) 平均降低7. 81% 。
关键词:欺骗语音检测;位置感知序列;Transformer;特征序列池化
中图分类号:TP391. 4 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3106(2024)05-1091-08
0 引言
NIST 说话人识别评估挑战[1]的结果显示,在过去的数年里,语音生物识别技术已经达到了令人印象深刻的性能。由该技术衍生出的自动说话人验证(Automatic Speaker Verification,ASV)系统得以被广泛地应用在安全系统、出入境管制、法医实验室、网上银行和其他电子商务系统等社会重要机构。大量研究表明,尽管最先进的ASV 系统具有很高的性能,但在面对语音合成、语音转换等欺骗攻击时依然表现得十分脆弱[2],因此设计有效的欺骗检测方法保证ASV 系统的安全性具有重要意义。
在语音信号的时频表示中,不同的子区域之间存在某些固定的关系,例如基频与谐波[3],语音合成或者语音转换技术通常无法充分对这些关系进行建模[4]。因此有效提取局部时频区域特征并建模它们之间的全局依赖关系能够提高欺骗检测的性能。卷积神经网络(Convolutional Neural Network,CNN)目前是反欺骗对抗最常用的模型。Wang等[5]设计了一种密集连接的卷积神经网络增强音频特征的传播,并通过特征重用确保网络中各层之间的最大信息流,大幅提升特征提取能力。Li 等[6]在Res2Net 的基础上提出了CGRes2Net,通过在特征组之间的连接中加入门控机制,实现根据输入动态选择信道,提升检测效果。Fu 等[7]提出了一种基于快速傅里叶变换的CNN 前端特征提取网络FastAudio,用可学习层取代固定滤波器组实现特征提取,与固定前端相比,能够更加灵活地适应未知欺骗检测。Tak 等[8]使用RawNet2 直接从原始语音波形中学习帧级特征,实验结果表明了避免使用基于先验知识的手工前端特征的端到端架构在欺骗检测中的潜力。但是基于CNN 的模型只适用于建模局部特征,对于全局依赖性通常需要依靠堆叠大量的卷积层实现,效率低下。为了解决该问题,Tak 等[9]通过图注意力网络(Graph Attention Network,GAT)跨越时频点捕获局部时频区域之间的全局依赖关系,但是出于计算量的考虑,构建图结点的数量比较有限,这会导致信息的损失。
最近,基于Transformer[10]的架构在计算机视觉、自然语言处理等领域表现出优秀的效果,其通过自注意机制高效的捕获全局依赖性,这对语音欺骗检测来说至关重要。受此启发,本文提出了一种结合CNN 和Transformer 的欺骗检测模型,增强对局部时频特征的提取能力以及高效建模特征之间的全局依赖关系,提升对未知欺骗攻击检测的性能。
1 Transformer 网络模型
1. 1 Transformer 概述
Transformer 架构引入自注意力机制,通过计算每个特征序列与其他序列之间的关系对当前序列进行更新。自注意力机制的主要特点是高效并行化计算和快速构建全局相关性的能力,这使其比递归神经网络或者CNN 更适合学习长距离依赖关系。Transformer 后来被用于自然语言处理。最近,它的各种变体结构被广泛集成到计算机视觉和说话人识别领域中并取得了优秀的性能。
Transformer 架构由多个Transformer 块堆叠组成,每个Transformer 块包括多头自注意力层和前馈层F(·)。其中多头自注意力层由多个自注意力头Att(·)组成,它是Transformer 学习全局依赖信息的关键。给定输入序列集合h = [h1 ,h2 ,h3 ,…,ht]∈ Rt×d,其中t 和d 分别代表序列的数量和维数,每一个自注意力头可以被看做是对值矩阵V 的加权和,权重由键矩阵K 和查询矩阵Q 之间的相似性得出,计算如下:
式中:矩阵Q、K、V 由序列集合h 与权重矩阵W 相乘得到。
多头注意力机制将多个自注意力的输出进行拼接后传入一个线性层计算全局相关性。
2 本文模型结构
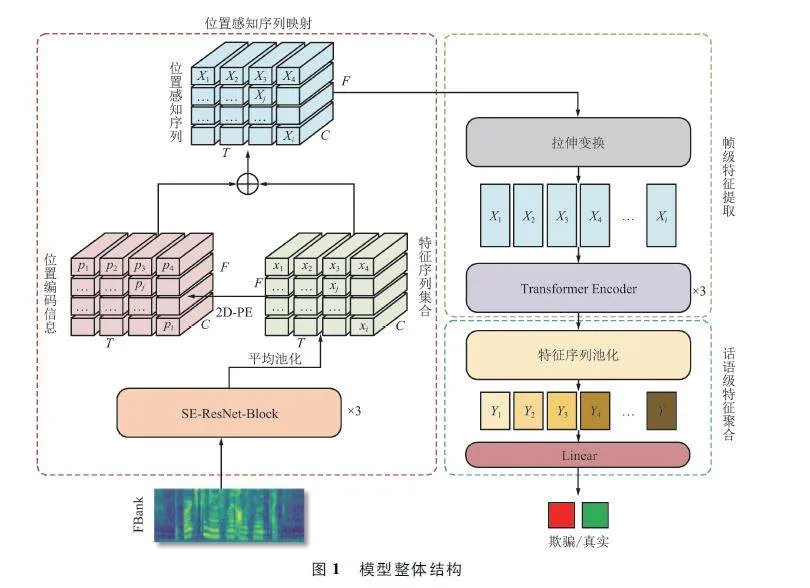
为了高效捕捉语音信号局部时频表示之间的相关性,提升欺骗语音检测的性能,本文设计了一种基于结合CNN 和Transformer 的欺骗语音检测网络,基本结构如图1 所示。主要由位置感知序列映射、帧级特征提取以及话语级特征聚合组成。
对于一段语音信号样本,首先将其转换为时频表示特征FBank,将FBank 通过卷积神经网络映射为C 维特征序列集合X∈RT×F×C 并添加位置编码信息,其中,T、F 为FBank 时间和频率方向的局部时频表示数量。随后,进行拉伸变换,构建位置感知特征序列集合XP ∈RC×D ,其中D = T×F。然后基于改进的Transformer 编码器提取帧级特征,从多个尺度高效建模各个特征序列之间的相关性,最后引入特征序列池化聚合话语级特征用于分类预测。
2. 1 位置感知序列映射
本文采用SE-ResNet18 的前3 层从FBank 中提取局部特征,构建特征序列集合。原SE-ResNet18在每个卷积块之间添加Squeeze Excitation(SE)模块用于学习通道之间的相关性,是一种面向通道的注意力机制。但是SE 模块忽略了空间关系,对于欺骗语音检测而言,难以区分各个局部时频表示的重要性。因此本文通过在每个SE-ResNet18 块之间嵌入坐标注意力(Coordinate Attention,CA)机制[11]对SE-ResNet18 进行改进。此外,特征序列集合的拉伸变换操作会丢失每个时频子区域之间的相对位置关系,故本文引入二维交替正余弦编码[12]对相对位置信息进行保留。
2. 1. 1 CA 嵌入
CA 机制通过将时间方向和频率方向的空间信息编码到通道中,使模型能够关注重要时频区域,忽略无效时频区域,具体结构如图2 所示。首先,对于给定的输入特征H∈RC×T×F ,使用平均池化沿时间和频率方向聚合一对一维空间感知向量st ∈RC×1×F 、sf∈RC×T×1 ,将2 个空间感知向量拼接后经由1×1 卷积进行通道交互和压缩,然后通过批归一化(BatchNormalization,BN)层与非线性变换层(Non-linear)生成空间编码信息sp ∈RCr×1×(F+T),r 表示压缩系数,最后使用2 个1×1 的卷积以及Sigmoid 激活函数分别产生时间方向和频率方向的权重信息对原始特征进行加权。
2. 1. 2 二维交替正余弦编码
Transformer 中通常使用一维位置编码处理自然语言序列中可能出现的由于位置变换导致位置信息丢失的问题,但是这并不适用于由CNN 输出的三维特征序列集合,因此本文引入文献[12]中的二维交替正余弦编码保留特征序列之间的相对位置信息。对于特征序列集合X = [x1 ,x2 ,x3 ,…,xi ]∈ T×F×C ,具体编码信息如下:
2. 2 多尺度自注意机制
Transformer 中的自注意机制优势在于其高效的并行化能力和全局依赖建模,但却难以捕捉特征序列局部之间的依赖,这也导致基于Transformer 的架构通常难以应用到语音领域。为了提升Transformer对的特征序列局部长期依赖的建模能力,本文提出了一种多尺度自注意力(Multiscale Self-Attention,MSA)机制对原自注意力进行改进。该机制利用不同的自注意力头关注不同长度的局部序列以获取多尺度长期依赖信息,提高局部建模能力,结构如图3所示。
首先将特征集合x∈RD×C 按序列长度均分得到n 个局部序列特征集合xi∈RD×(C/n),其中i 表示第i 个局部序列特征集合,C 表示单个特征序列长度,D 表示集合中的特征数量。均分操作之后,每个局部序列特征集合xi 都会通过与之相对应的自注意力头Atti 和激活函数为LeakyReLU 线性层Li,其中线性层的作用是保证xi 和yi 的维度一致。输出yi 表示如下:
如图3 所示,Atti 的输入特征不仅包括当前的局部序列特征集合xi,同时还包括前一项输出局部序列特征集合yi。因此,当前输入局部特征子集包含更长的序列特征以及多种感受野的大小组合。更长的序列特征包含更多的语音信息以及进行更好的上下文分析,多种感受野的大小组合则可以丰富局部子序列长期依赖关系,实现更精准、有效的特征提取。如式(9)所示,将所有的yi 进行拼接后输入线性层LG 和自注意力头AttG 进行全局级多尺度依赖信息整合,输出特征Y∈RCG×D 。
2. 3 特征序列池化
池化操作也称为读出操作,主要作用是将连续的高维帧级序列特征聚合为可用于分类的话语级特征。本文引入特征序列池化(Sequence Pooling,SeqPool)[13]聚合帧级特征,不同于常用的平均池化、最大池化以及总和池化等静态池化方法,特征SeqPool 是一种基于注意力机制的映射变换,其通过保留不同帧级序列之间的相关信息提高性能并且不会带来额外的参数。
该方法一共包括3 个步骤。对于一个L 层的Transformer 编码器输出yL ∈RD×C,特征SeqPool 方法首先利用一个线性层对yL 进行降维以及信息整合,随后,对g(yL )∈RD×1 应用Softmax 激活函数为每一个输入帧级序列产生一个重要性权重,计算如下:
wL = Softmax(g(yL) T )∈ R1 ×D , (10)
式中:g(yL)代表线性层映射。将重要性权重wL 与yL 相乘生成话语级特征z,计算如下:
z = Softmax(g(yL) T )× yL ∈ R1 ×C 。(11)
将z 进行降维后生成z′∈R3. 1 实验环境与参数细节C 输入到全连接层中进行分类。对于欺骗检测任务,全连接层的最后一层是一个包含2 个神经元的线性层,每一个神经元的输出分别代表欺骗类别和真实类别的置信度得分。
3 实验与结果分析
3. 1 实验环境与参数细节
本文采用FBank 作为前端时频表示特征。以20 ms 帧长、10 ms 帧移、汉宁窗以及512 个傅里叶变换变换点提取对数功率谱。所有对数功率谱调整为固定长度400 帧,对于时长不足的语音样本,本实验沿时间轴对特征进行复制。对于长语音,本实验随机选择400 帧连续帧。然后应用60 个线性滤波器提取60 维FBank。
本实验基于Ubuntu 20. 04 操作系统,采用Py-Torch 框架实现,显卡为NVDIA GTX 1080Ti。设置β1 = 0. 9,β2 = 0. 999,初始学习率为5 ×10-5 的Adam优化器,学习速率衰减采用余弦退火方法。总共训练100 个轮次,取其中最好的实验结果作为最终结果。
3. 2 数据集
实验采用ASVspoof2019 大赛的逻辑访问(Logical Access,LA)数据集验证本文模型以及其他不同模型的检测效果。该数据集基于VCTK 语料库的107 位说话人语音样本,由17 种不同的语音合成以及语音转换算法产生后通过16 比特量化下采样到16 kHz 得到。数据集包含训练集、开发集以及评估集3 个子集且彼此之间没有交集。此外,开发集中的欺骗语音采用训练集中相同的欺骗语音算法(A01 ~ A06)产生,用于验证算法对可见欺骗语音的检测效果。评估集中使用了13 种欺骗语音产生算法(A07 ~ A19),其中的A06、A04 与训练集中的A19、A16 是同一种欺骗算法,另外的11 种算法相对于训练集是未知的,用于验证算法对未知欺骗语音的检测效果。数据集详细设置如表1 所示。
3. 3 评估指标
本文采用等错误率[2](Equal Error Rate,EER)作为次要检测指标,采用ASVspoof2019 大赛中所提出的最小串联检测代价函数[14](min tandem-Detection Cost Function,min t-DCF)作为主要检测指标,二者的值均越低代表系统的检测准确度越高。
(1)EER
如式(14)所示,EER 被定义为在阈值为τ 的情况下,错误接受率PFAR(τ)和错误拒绝率PFRR(τ)相等时的值。错误接受率和错误拒绝率由式(12)、式(13)所示,其中Nfa(τ)、Nmiss(τ)分别表示欺骗语音样本被错误接受的数量以及真实语音样本被错误拒绝的数量,Nspoof、Nbonafide 分别表示欺骗语音样本的数量以及真实语音样本的数量。EER 是一种独立评判欺骗语音检测系统的有效指标,通过比较EER可以直观地看出欺骗语音检测系统的性能。
(2)最小串联检测代价函数
实际场景中,ASV 系统通常与反欺骗(CM)系统串联应用,如果只将CM 系统的等错误作为评价指标,无法全面反映CM 系统和ASV 系统对检测结果的影响。因此,ASVspoof2019 大赛采用最小串联检测代价函数作为主要的评价指标。如式(15)所示,其综合考虑CM 系统和ASV 系统的决策,在评价系统性能时更加合理:
式中:PCMFRR(τ)和PCMFAR(τ)分别表示在阈值为τ 的情况下,CM 系统的错误拒绝率和错误接收率;系数C0 、C1 、C2 由ASV 系统和CM 系统的2 种错误率以及先验概率所决定,t-DCFdefault 定义为CM 系统接受或拒绝每条测试语音样本无信息的默认成本。
t-DCFdefault = C0 + min{C1 ,C2 }。(16)
3. 4 消融实验
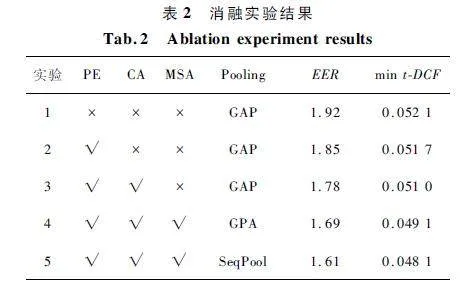
为了验证本文模型中每个组件的有效性,通过移除或者替换对应组件在评估集上进行了多组消融实验,结果如表2 所示。
由表2 可知,实验2 通过添加位置嵌入信息(Position Embedding,PE)保留时频子区域之间的相对位置关系能够在一定程度上提升模型性能。实验3 在SE-ResNet18 层之间添加CA 模块区分局部时频子区域之间的重要性,EER 与min t-DCF 分别降低3. 7% 、1. 3% 。在实验3 的基础上将自注意力机制替换成MSA 机制,EER 降低5. 0% ,min tDCF 降低3. 73% ,这表明丰富尺度信息能有效提升对欺骗伪影的检测。实验5 进一步将全局平均池化(Global Average Pooling,GAP)替换为SeqPool,EER和min t-DCF 达到1. 58 和0. 048 1,对比实验4 分别降低4. 73% 、2. 03% ,因为SeqPool 相对于静态池化方法,能够有效保留Transformer 编码器输出帧级特征之间的相关信息,从而提升模型检测精度。
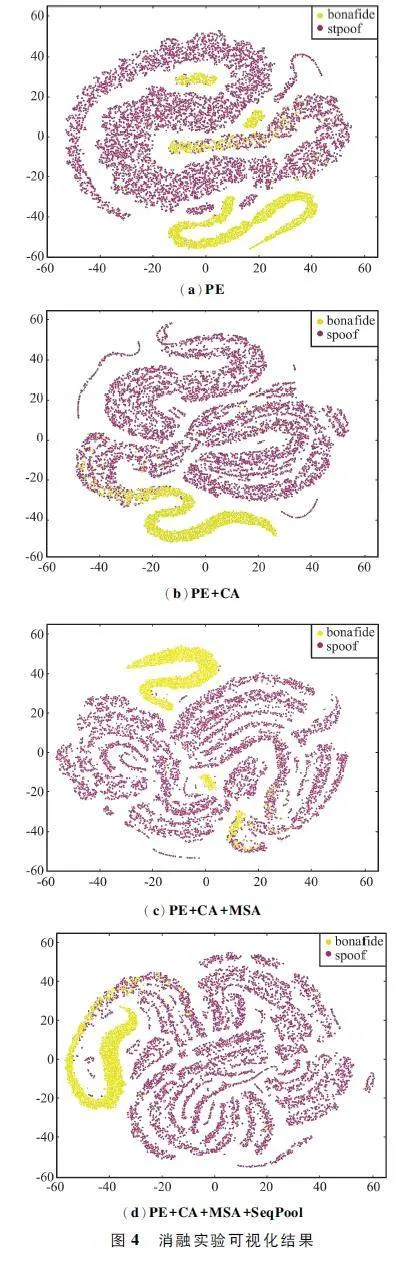
图4 是分别提取2 000 条真实语音和各类欺骗语音的话语级特征进行降维后形成的可视化消融实验对比图,其中紫色代表真实语音,黄色代表欺骗语音,图4 (a)~ 图4 (d)分别对应消融实验2 ~ 5。图4(a)为添加PE 信息后的可视化效果图,可以看出真实语音和欺骗语音类间碰撞情况较多,且对于真实语音的类内聚合度差。图4(b)为在图4(a)的基础上嵌入CA 机制的可视化效果图,相比于图4(a),图4 (b)的类间碰撞情况有所降低,且真实语音类间聚合度有明显提升,这表明CA 提升了模型的特征提取能力,话语级特征具备更强的甄别性。图4(c)为将自注意力机制替换为MSA 机制的可视化效果图,可以看出类间碰撞降低,对于大部分真实语音,类间聚合度明显提高,但是依然存在少部分真实样本聚合度比较差。图4(d)为进一步替换GAP 为SeqPool 的可视化效果图,相比于图4(c),在没有增加类间碰撞的情况下,提升了真实语音之间的相似性,这表明SeqPool 并不会影响主干网络的特征提取能力,且能保留主干网络输出特征序列之间的相关性信息以提升区分度。
3. 5 未知攻击检测性能对比实验
为了验证本文模型对未知攻击检测的性能,在评估集中使用6 种模型与本文模型进行对比,包括OC-Softmax[15]、LCNN-LSTM-sum[16]、Attention + ResNet[17]、MCG-Res2Net50[6]、Raw PC-DARTS[18]和Res-TSSD-Net[19]。上述6 种模型均是单一系统,并没有经过任何分数融合策略。对比实验分别比较7 种模型的EER 和min t-DCF,结果如表3 所示。本研究在EER 指标上达到最优性能,相较于最优模型Res-TSSDNet,min t-DCF 相同,但是EER 降低了1. 83% 。
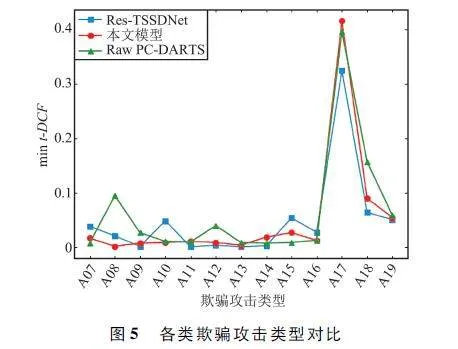
为了进一步对比Raw PC-DARTS、Res-TSSDNet与本文模型对不同攻击类型的检测性能,在评估集上对A07 ~ A19 共13 种未知欺骗攻击分别进行实验并比较min t-DCF 指标,结果如图5 所示。
从图5 可以看出对于大部分的欺骗类型,3 种模型的检测性能表现差距不大。针对A07 ~ A16 共10 种攻击类型,本文模型的整体精度表现得更加稳定,对于A08 和A12 类型,Raw PC-DARTS 无法有效检测,Res-TSSDNet 的检测性能波动最明显,相对于其余攻击类型,其对于A07、A10 以及A15 的检测精度存在明显下降,这表明本文模型的泛化性能更好,能够适应更多种的未知欺骗类型。但是在面对公认难度最高的A17 攻击类型时,3 种模型的min t-DCF均有大幅度上升,其中本文模型的表现最差,主要原因在于A17 是一种基于原始波滤波的转换攻击算法,因此采用A17 算法生成的伪装语音在原始波中会包含更多的欺骗伪影。而Raw PC-DARTS 和Res-TSSDNet 均采用未经手工处理的原始波形作为输入特征,相对于本文采用的前端特征Linear FBank 保留了更多的有效信息。但是以原始波形作为输入特征同时会引入大量冗余信息,提升了模型对特征的提取难度,导致模型无法在多种不同的攻击类型上表现出平稳的性能。
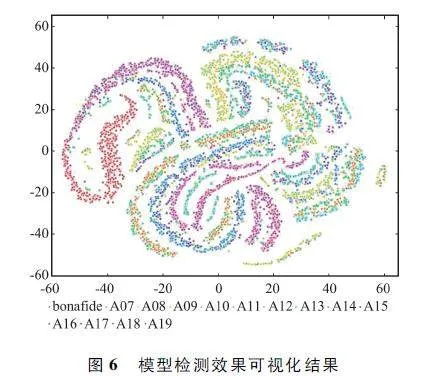
本文模型的话语级特征在评估集上针对各类攻击类型的可视化结果如图6 所示,红色圆点为真实语音,其余颜色圆点为多种欺骗语音。从图6 中可以看出真实语音类内聚合度高,同时与各类欺骗语音之间间距明显,少量类间碰撞主要集中于A17 上,这表明本文模型能够有效区分真实语音和欺骗语音。
4 结束语
本文提出了一种结合CNN 与Transformer 的欺骗语音检测模型,旨在通过高效捕捉语音信息局部时频表示之间的全局相关性来提高来解决现有方法难以适应多种欺骗类型、对未知欺骗攻击检测能力不足的问题。设计基于CA 注意力嵌入的SE-Res-Net18 的位置感知特征序列提取网络,将语音信号局部时频表示映射为高维特征序列,采用二维位置编码保留特征序列之间的相对位置信息,并在原SE-ResNet18 的基础上嵌入CA 注意力区分特征序列之间的重要性,提升特征提取能力;提出MSA 机制替换Transformer 层中的单一自注意力,解决Transformer 难以捕捉局部依赖的问题;引入SeqPool提取话语级特征,保留Transformer 层输出帧级特征序列之间的相关性信息,优化检测精度。实验结果表明,在ASVspoof2019 大赛数据集的LA 场景中,相较于当前先进模型,本文模型适应性更强且min t-DCF 与EER 平均降低7. 81% 和12. 83% ,整体检测精度上具备明显优势。在未来的工作中,将使用多特征融合的方式,丰富前端特征表达,从而提升对未知攻击检测的精度和模型的泛化性。
参考文献
[1] SADJADI S O,GREENBERG C,SINGER E,et al. The2021 NIST Speaker Recognition Evaluation [EB / OL ].(2022-04-21)[2023-05-16]. https:∥arxiv. org / abs /2204. 10242.
[2] NAUTSCH A,WANG X,EVANS N,et al. ASVspoof2019:Spoofing Countermeasures for the Detection of Synthesized,Converted and Replayed Speech [J ]. IEEETransactions on Biometrics, Behavior, and IdentityScience,2021,3(2):252-265.
[3] HUANG P Y,XU H,LI J C,et al. Masked Autoencodersthat Listen[C]∥ NeurIPS 2022. New Orleans:[s. n. ],2022:28708-28720.
[4] HUANG R J,CUI C Y,CHEN F Y,et al. SingGAN:Generative Adversarial Network for Highfidelity SIngingVoice Generation[C]∥Proceedings of the 30th ACM International Conference on Multimedia. Lisboa:ACM,2022:2525-2535.
[5] WANG Z,CUI S S,KANG X G,et al. Densely ConnectedConvolutional Network for Audio Spoofing Detection[C]∥2020 AsiaPacific Signal and Information Processing Association Annual Summit and Conference (APSIPAASC). Auckland:IEEE,2020:1352-1360.
[6] LI X,WU X X,LU H,et al. Channelwise GatedRes2Net:Towards Robust Detection of Synthetic SpeechAttacks [EB / OL]. (2021 - 07 - 19 )[2023 - 05 - 16 ].https:∥arxiv. org / abs / 2107. 08803.
[7] FU Q C,TENG Z W,WHITE J,et al. FastAudio:A Learnable Audio FrontEnd for Spoof Speech Detection[C]∥ICASSP 2022 - 2022 IEEE International Conference onAcoustics,Speech and Signal Processing (ICASSP). Singapore:IEEE,2022:3693-3697.
[8] TAK H,PATINO J,TODISCO M,et al. EndtoEnd Antispoofing with RawNet2 [C]∥ ICASSP 2021 - 2021 IEEEInternational Conference on Acoustics,Speech and SignalProcessing (ICASSP). Toronto:IEEE,2021:6369-6373.
[9] TAK H,JUNG J,PATINO J,et al. Graph Attention Networks for Antispoofing [EB / OL ]. (2021 - 04 - 08 )[2023-05-16]. https:∥arxiv. org / abs / 2104. 03654.
[10] VASWANI A,SHAZEER N,PARMAR N,et al. AttentionIs All You Need [C]∥ NIPS 2017. Long Beach:CurranAssociatior Inc. ,2017:6000-6010.
[11] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attentionfor Efficient Mobile Network Design[C]∥Proceedings ofthe IEEE / CVF Conference on Computer Vision and PatternRecognition. Nashville:IEEE,2021:13713-13722.
[12] RAISI Z,NAIEL M A,FIEGUTH P,et al. 2D PositionalEmbeddingbased Transformer for Scene Text Recognition[J ]. Journal of Computational Vision and ImagingSystems,2020,6(1):1-4.
[13] HASSANI A,WALTON S,SHAH N,et al. Escaping theBig Data Paradigm with Compact Transformers[EB / OL].(2022-06-07)[2023-05-16]. https:∥arxiv. org / abs /2104. 05704v4.
[14] KINNUNEN T,LEE K A,DELGADO H,et al. tDCF:ADetection Cost Function for the Tandem Assessment ofSpoofing Countermeasures and Automatic Speaker Verification[EB / OL]. (2019 -04 -12)[2023 -05 -16]. https:∥arxiv. org / abs / 1804. 09618v2.
[15] ZHANG Y,JIANG F,DUAN Z Y. Oneclass Learning Towards Synthetic Voice Spoofing Detection [J ]. IEEESignal Processing Letters,2021,28:937-941.
[16] WANG X,YAMAGISHI J. A Comparative Study onRecent Neural Spoofing Countermeasures for SyntheticSpeech Detection[EB / OL]. (2021-03 -21)[2023 -05 -16]. https:∥arxiv. org / abs / 2103. 11326v2.
[17] LING H F,HUANG L C,HUANG J R,et al. Attentionbased Convolutional Neural Network for ASV Spoofing Detection[C]∥ Interspeech 2021. Brno:[s. n. ],2021:4289-4293.
[18] GE W Y,PATINO J,TODISCO M,et al. RawDifferentiable Architecture Search for Speech Deepfakeand Spoofing Detection [EB / OL ]. (2021 - 10 - 06 )[2023-05-16]. https:∥arxiv. org / abs / 2107. 12212v2.
[19] HUA G,TEOH A B J,ZHANG H J. Towards EndtoEndSynthetic Speech Detection [J]. IEEE Signal ProcessingLetters,2021,28:1265-1269.
作者简介
徐童心 男,(1999—),硕士研究生。主要研究方向:语音检测与人工智能。
黄 俊 男,(1971—),博士,教授。主要研究方向:深度学习。
基金项目:国家自然科学基金(61771085)
