
面向电商用户评论的细粒度观点挖掘及其分布规律探究
2024-07-14 08:18:40陆晨晨王昊石斌裘靖文
知识管理论坛 2024年3期
陆晨晨 王昊 石斌 裘靖文


摘要:[目的/意义]电商用户评论中蕴含着大量有价值的信息,识别其中的用户观点,探索观点分布的差异和规律,能够为消费者、商家和平台提供参考。[方法/过程] 首先,基于UIE模型,对家居、零食、手机3个行业中的用户评论进行观点抽取;其次,基于商品特征库和BERT模型,计算词间语义相似度对观点进行泛化;最后,基于IPA模型,对用户观点进行统计分析和可视化呈现,为商家和平台提供优化建议。[结果/结论] 在观点挖掘方面,模型在3个行业中均表现优秀,观点抽取的F1值分别为79.85%、83.28%和85.71%,证明该方法的有效性;在规律分析方面,发现手机行业的用户观点主要集中于性能、外观和电池,但不同平台和品牌的观点分布存在明显差异,并且用户情感从初评到追评总体呈现出积极到消极的变化趋势。
关键词:用户评论;细粒度情感分析;观点挖掘;预训练语言模型;IPA分析
分类号:TP391
引用格式:陆晨晨, 王昊, 石斌, 等. 面向电商用户评论的细粒度观点挖掘及其分布规律探究[J/OL]. 知识管理论坛, 2024, 9(3): 253-268 [引用日期]. http://www.kmf.ac.cn/p/391/. (Citation: Lu Chenchen, Wang Hao, Shi Bin, et al. Research on Fine-grained Opinion Mining and Distribution Law of opinion for E-Commerce Customer Reviews[J/OL]. Knowledge Management Forum, 2024, 9(3): 253-268 [cite date]. http://www.kmf.ac.cn/p/391/.)
1 引言/Introduction
在线评论是用户对产品、服务感知的文本形态,也是经验和想法分享传播的一种形式,蕴含着大量有价值的用户观点。电商评论中的用户观点是消费者视角下对产品、服务所持的看法或态度,产品、服务代表评价对象,看法和态度代表评价内容和情感倾向。随着网购的普及和直播带货的兴起,相关电商平台上积累了丰富的用户评论,对这些评论进行观点挖掘可以为潜在消费者提供有价值参考,并为商家提供消费者对产品的反馈和需求,同时可以为平台改善服务提供参考。
然而日益增长的海量用户评论也带来了信息过载的问题,如何挖掘出有价值的信息,是在线评论领域研究的热点。目前,评论观点抽取和情感分类主要采用规则模板[1-2]和机器学习[3-4]两种方法。基于规则模板的方法,通过手动编写规则或模板来匹配评论中的观点,但需要专业知识和经验,且难以达到较高的准确率,无法真实反映用户的心声和需求。基于机器学习的方法,需要标注大量数据且不易进行跨行业迁移,而电商平台包含多样化的商品,不同行业之间用户评论对象和习惯差异较大,很难训练出适用于各行业的通用模型。
随着大型预训练语言模型的兴起,从文本中精确挖掘细粒度知识对象的能力得到显著提升,从语义层面识别细粒度知识元、提取内容观点成为可能,为在线评论的细粒度观点抽取提供了新的研究思路和方法。此外,在电商领域的相关研究中,不少学者基于评论挖掘对不同平台[5]、品牌[6-7]以及追加评论和初次评论[8-9]进行了比较研究。因此,笔者提出两个研究问题:①大型预训练语言模型结合微调的方法能否有效提升观点抽取效果?②不同平台、品牌以及追评和初评之间的用户观点分布存在哪些差异?为什么会产生这些差异?
笔者采用基于大型预训练语言模型结合微调的方法进行用户观点抽取,选取手机、零食、家居3个行业的用户评论进行实验,来验证该方法的有效性;并以手机行业为例,对评论进行细粒度观点挖掘,探索其中的分布规律,比较不同平台、品牌以及追评和初评之间的观点分布,探讨其中的分布差异及其原因。
2 近期相关研究/Recent relevant research
在线评论的相关研究主要集中于电子商务[10]、医疗[11-12]、旅游[13]、在线教育[14]以及政务[15]等领域。其中,医疗、政务领域的研究主要关注评论主题及其情感,而电子商务领域由于其产品和服务的细粒度特性,相关研究更关注产品特征及其情感倾向的抽取[16],随着知识图谱研究的兴起,产品特征对应的观点词抽取[17-18]也逐渐受到关注,它解释了情感产生的原因,并且可以和产品特征结合形成观点摘要。因此,电商用户评论的观点抽取主要包括产品特征抽取、对应观点词抽取以及特征—观点对情感分类3个子任务,在学术上称为方面级情感三元组抽取(aspect sentiment triplet extraction, ASTE[19])或观点三元组抽取(opinion triplet extraction[20])。
自H. Y. Peng等[19]首次提出用一个序列标注任务统一信息抽取和分类任务,一次性实现ASTE任务以来,观点三元组抽取就引起了研究者的关注[21-25]。深度学习方法凭借其出色的效果,成为该领域的热点研究方法。H. Yan等[22]将预训练BERT运用到三元组抽取任务中,提出基于端到端的BARTAB模型,实现了基于统一任务的端到端的BART生成目标序列;S. W. Chen等[23]将ASTE任务转化为多轮机器阅读理解任务,并提出一个双向机器阅读理解框架;W. X. Zhang等[24]提出基于文本生成的GAS模型,该模型通过注释样式和提取样式范式来描述目标句子,使用统一的生成模型来解决多重4种子任务;Y. J. Lu等[25]提出通用信息抽取UIE(universal information extraction)模型,实现实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,在ASTE任务的4个数据集中均达到了SOTA(state-of-the-art)水平。
观点泛化指将具体、个别的观点扩大为一般的观点,目前常用的方法主要有基于LDA(Latent Dirichlet allocation)的主题挖掘模型[26-27]以及基于语义相似度的分类模型[28-30]。LDA模型可以挖掘出评论文本中的评论—主题和主题—关键词映射,实现关键词的聚类;基于语义相似度的方法主要采用Word2Vec和BERT[31]等模型,将抽取出来的特征词转换为词向量,并根据特征词库以及向量距离进行分类和聚类。泛化后的特征观点需要进一步分析,在线评论领域常用的用户观点分析模型有IPA(importance-performance analysis)[32]和Kano[33]模型。IPA模型使用重要性和绩效来创建一个二维矩阵,将产品属性划分到4个象限中[28,34];Kano模型认为产品不同属性的用户满意度随需求被满足情况的变化应是非线性的,根据用户满意度与需求被满足之间的关系,将产品属性分为5类[34-35]。
笔者选取实验效果最好的UIE模型进行观点三元组抽取;同时,由于LDA模型无法抽取细粒度的产品特征,只能得到若干个主题及其关键词,不适合电商领域的观点泛化,故笔者采用基于BERT和商品特征库的观点泛化方法;最后,Kano模型在评论数据中无法得到需求不被满足时的用户满意度变化情况,更适用于问卷数据,而IPA模型的分类较为简单,其重要性和绩效维度都可以从评论数据中挖掘得到,因此笔者使用IPA模型对泛化后的观点进行分析,探究用户观点的分布规律与差异。
3 数据与方法/Data and methodology
3.1 研究框架
本文的研究框架见图1,主要包括3个模块。①观点抽取:首先,利用python爬虫获取电商用户评论文本并进行数据清洗等预处理工作;随后从预处理后的评论语料中随机选取部分并标注,进行UIE模型微调,提升其在垂类行业下的性能;最后应用性能最佳的UIE模型提取出用户评论中的观点三元组<评价特征(F);对应观点词(O);情感倾向(S)>。②观点泛化:首先,爬取商品静态信息并匹配出商品参数,结合高频评价特征词构建商品特征库;随后,利用BERT计算评价特征词与商品特征库中各词的语义相似度,进行特征词的过滤和分类,形成商品特征体系;最后,利用BERT将观点词进行词向量表示,并通过K-Means算法进行聚类,将三元组泛化为<粗粒度属性(F1);细粒度特征(F2);评价特征(F);中心观点词(C);情感倾向(S)>。③观点分析:根据泛化后的结果计算用户关注度和用户满意度,通过IPA模型对用户观点进行分析,并探索其在行业、平台、品牌、追评视角下的深度挖掘与应用。
3.2 数据来源与预处理
笔者选取淘宝、京东、抖音、拼多多4个平台作为研究对象,进行商品数据的采集。商品数据包括商品静态信息和用户评论数据,商品静态信息由商品所属行业类目、商品参数组成,用户评论数据包括初次评语内容、初次评语时间、追加评语内容、追加评语时间、店铺名、商品ID等字段。为了验证本文观点抽取方法的通用性,笔者参考淘宝的商品分类体系,选取差异较大的家居、零食、手机3个热门行业进行数据采集,共获得商品371个,原始评论文本1 004 047条,数量分布如表1所示:
数据预处理工作包括重复评论、垃圾评论和低质量评论的过滤。重复评论分为相同用户的近似评论以及不同用户的相同评论,笔者将同一用户在同一商品下的相同评论定义为重复评论进行过滤;电商评论中的垃圾评论主要指系统默认评价,如“此用户没有填写评论!”“该用户觉得商品不错”等,该类评价内容没有实际意义,将其进行过滤;低质量评论通常具有重复字符多、中文字符少等特征,笔者将重复字符占比大于80%的评论过滤,由于过少字符的评论往往不包括完整的用户观点,笔者将中文字符小于5的评论过滤。
3.3 基于UIE的观点抽取
笔者采用PaddleNLP开源的UIE模型进行观点三元组抽取。该模型在相关数据集上取得了最优的实验表现[25],UIE基于ERNIE 3.0[36]预训练语言模型,是PaddleNLP训练并开源的首个中文通用信息抽取模型,实现了实体抽取、关系抽取、事件抽取、情感分析等信息抽取任务的统一建模,并使得不同任务之间具备良好的迁移能力。
观点三元组抽取属于实体抽取、关系抽取、情感分类的复合任务,UIE提供相应的Schema来实现三元组抽取任务。在UIE中构造Schema为{‘评价特征: [‘观点词, ‘情感倾向[正向,负向]]},Schema会生成prompt指导模型完成相应的信息抽取任务,从用户评论中提取出
UIE还提供模型微调(fine-tune)功能,只需要标注少量数据就可以提升模型在细分场景下的性能。电商平台包含各行业的商品,不同行业之间用户评论对象和习惯差异较大,笔者通过微调来提升模型观点抽取的效果。首先从预处理后的评论集中随机选取部分,使用数据标注平台doccano进行数据标注;随后将标注数据划分为训练集、验证集和测试集,并构造一定的负例数据来提升模型微调效果;最后使用训练集对预训练模型的参数进行更新,并在验证集中检验效果,选择训练过程中性能最佳的模型进行用户评论的观点抽取。
3.4 基于语义相似度的观点泛化
抽取出来的观点三元组中包含许多无意义的评价特征,并且许多特征词和观点词都表达着相同的语义,因此为了更好地了解用户对产品和服务中特定主题的看法和态度,需要将具体的评价特征词进行过滤和分类,对观点词进行聚类,最终得到<粗粒度属性(F1);细粒度特征(F2);评价特征(F);中心观点词(C);情感倾向(S)>。
(1)商品特征库构建。各个行业由于其商品特征的差异,需要单独构建商品特征库,商品特征库包括粗粒度属性和细粒度特征。首先,参照淘宝、京东等主流电商平台的相关参数设置,并结合行业高频评价特征词,来初步构建商品特征库;随后将
(2)评价特征分类。根据商品特征库,利用BERT计算其余评价特征词与商品特征库中各词的语义相似度,设定阈值为α,将评价特征词归类到相似度最高的评价维度下,对评价特征完成过滤与分类,形成最终的商品特征体系。定义词Wa与Wb之间的语义相似度如公式(1)所示,其中K表示词向量的维度,Vai为Va词向量的第i个向量值。
公式(1)
(3)评价观点聚类。不同的观点词可能表达相同的语义,例如物流维度下的“发货神速”和“发货迅速”都表达了发货速度快,因此为了得到高频的观点摘要,需要将表达相似的观点词聚为一类,消除这些观点词之间的语义重复。笔者利用BERT将观点词进行词向量表示,通过K-Means算法完成观点词的聚类,并将距离聚类中心最近的词作为中心观点词来集中表示这一类观点词。
3.5 基于IPA的观点分析
为了从具体的数据中抽象出一般的分布规律,笔者提出用户关注度和满意度两个指标对泛化后的观点进行量化和统计分析。用户关注度反映评论的产品或服务要素,用户满意度反映评论的内容和情感倾向,两者较好地概括了用户观点,具体计算公式如下:
(1)用户关注度计算。根据抽取的观点三元组以及前文构建的商品特征体系,可以计算出各属性的占比作为用户关注度I。假设R表示观点集合,N表示观点总数,Rni定义见公式(2),Ii表示第i个属性的用户关注度,计算方法见公式(3)。
公式(2)
公式(3)
(2)用户满意度计算。根据观点中的情感倾向(正向、负向),可以计算出各属性中正向情感的占比作为用户满意度P。假设R为观点集合,Mi表示属性i下的观点总数,Rim定义见公式(4)。Pi表示第i个属性的用户满意度,计算方法见公式(5)。
公式(4)
公式(5)
(3)IPA模型。该模型由J. A. Martilla, J. C. James于1977年提出[32],其基本思想是通过比较用户对不同属性重要性和绩效的感知来优化产品和服务。用户关注度量化了用户对各属性的重视程度,用户满意度量化了各属性的绩效表现,这两个指标分别对应了IPA模型中的重要性和绩效维度。因此,笔者基于用户关注度和满意度数据构建IPA模型,将产品属性划分到4个象限中,为商家和平台提供各产品和服务属性的优化建议。从图3中可以看出,第一象限中的属性重要性和满意度表现均较高,为产品的优势,在后续经营活动中应当继续保持;第二象限为重要性低而满意度高的属性,是产品的机会点,企业应当抓住这类属性进行优化,满足用户意想不到的需求,使商品在同类商品中脱颖而出;位于第三象限的产品属性有着较低重要性和满意度,属于劣势属性,在资源充足的情况下,可以考虑发展此类属性;第四象限中属性重要性高而满意度低,是产品的威胁属性,应当重点改进。
4 观点挖掘实验与分析/Opinion mining experiment and analysis
笔者以家居、零食、手机3个行业为例进行观点抽取的实验。由于手机产品参数的分类体系较为明确和细粒度化,更适合构建多维度的商品特征体系,因此笔者以手机行业为例,进行观点泛化以及后续的观点分析。手机行业数据包括京东、淘宝、抖音、拼多多4个平台和Apple、华为、小米、OPPO、vivo、荣耀6个品牌的用户评论,评论时间范围取2020年12月1日至2022年11月30日,最终采集到商品静态信息150条、用户评论数据371 204条,数据预处理后,得到有效用户评论数据307 699条。
4.1 观点抽取结果
首先随机从各行业评论中选取50条按照评论观点抽取任务模版进行标注;随后将标注数据转换为模型微调所需的prompt形式,按照8:1:1的比例将数据划分为训练集、验证集和测试集,设置最大负例比例negative_ratio为5;最后对预训练模型进行微调,具体参数设置如下:batch size=16, epochs=70, learning rate=1e-5, max seq length=512。
观点抽取实验的评价指标为精确率、召回率和F1值。在家居、零食、手机行业进行实验研究,实验结果见表2。其中,0-shot表示无训练数据直接进行预测,few-shot表示模型微调后再预测。可以发现,3个行业在微调后的精确率、召回率和F1值均有显著提高,其中F1值分别提高7.85%、5.17%和4.01%。
以性能提升最高的家居行业为例,展示模型微调过程,结果见图4。可以看出:①随着训练轮次的增加,模型性能得到了一定的提升,相较于微调前,精确率从78.52%提升至82.61%,召回率从66.48%增加到77.27%,这表明更多的评论观点被模型识别并召回;②F1值给出了模型精确率和召回率的综合评估,因此笔者选取微调过程中F1值最高的模型作为最优模型来进行最终的观点抽取;③将手机行业中最优模型的参数保存到model_best文件夹中,并对预处理后的307 699条评论进行观点抽取,最终得到观点三元组616 668个。
4.2 观点泛化结果
得到手机行业的观点三元组后,为了对评价特征进行分类和过滤,需要构建手机商品特征库。首先,参照淘宝、京东等主流电商平台以及太平洋电脑网和中关村在线中手机产品的相关参数设置,并结合高频评价特征词,初步构建商品特征库。手机商品的粗粒度属性主要划分为外观、屏幕、性能、摄像头、电池、硬件、网络与通信、价格、品控、服务10个维度,其中每个维度下的细粒度特征见表3。词频数前400的评价特征词所构成的观点三元组占据总量的90.7%,从中选出能较好代表和描述产品特征的词汇,笔者通过人工筛选的方式将评价特征词划分到相应的细粒度特征词下,共获得312个代表词汇,最终形成包含粗粒度属性、细粒度特征和代表词汇3个维度的商品特征库。
基于手机商品特征库,使用BERT模型将评价特征词向量化并计算其与特征库中各词汇向量的余弦距离作为语义相似度,并按照相似度的高低对评价特征词进行分类和过滤。例如,对于“待机”这一特征词,分别计算其与特征库中各词的相似度,得到相似度排前3的特征词为“续航”“电池容量”“充电”,相似度分别为0.953、0.891、0.910,因此将“待机”划分到“续航”这一细粒度特征下。同时,为了过滤无实际意义的特征词,笔者将最大相似度的阈值设为0.9。最终获得由10个粗粒度属性、36个细粒度特征以及8 843个评价特征词构成的多维商品特征体系(见表4)。使用商品特征体系对抽取出来的616 668个
5 用户观点分布规律分析/Analysis of user opinion distribution patterns
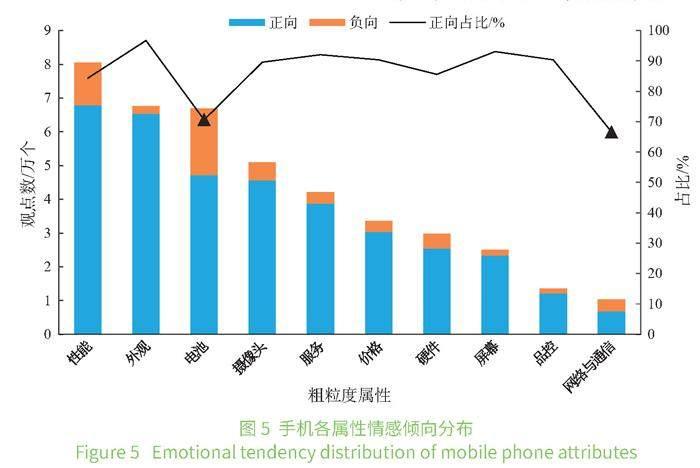
5.1 行业总体观点分布
基于用户关注度和满意度计算,可以得到观点三元组集合中各个属性的正向、负向观点数以及正向观点占比,结果见图5。在用户关注度方面,可以看出:①最受用户关注的手机属性是性能,占比19.15%,其次是外观和电池,分别占16.09%和15.91%,手机的好用、好看、耐用属性是用户能直接感受到的属性,因此在购买前和使用时更容易受到用户的关注,对这类属性的优化能够吸引和锁定用户;②用户对网络与通信的关注度最低,仅占2.45%,这可能与用户对手机的需求逐渐从基础的通信功能转向游戏、看剧、办公等功能有关。
在用户满意度方面,可以看出:①网络与通信是手机行业中用户满意度最低的属性,该属性下的10 293个观点中有3 434个(约33%)显露出负面情感倾向;其次是电池属性,共包括66 768个观点,其中表达负面情感的共19 645个,占比29%;②其余属性的用户满意度都在85%以上,其中外观的满意度最高,达到了97%,这可能是因为用户对外观这类属性在购买前就能较好地感知,用户往往会选择自己喜欢的外观,因此外观的用户满意度通常较高。
对满意度最低的电池和网络与通信属性下的对应观点词进行聚类,得到负面观点摘要(见图6)。可以发现,“耗电快”“续航一般”是用户对电池的主要负面评价;“信号差”“通信质量差”是网络与通信属性的主要痛点。基于上述分析,根据IPA模型,可以得出电池属性的用户关注度高并且满意度较低,被划分到威胁改进区,是手机行业未来需要重点优化的属性;网络与通信用户关注度和满意度均较低,位于次劣发展区,在资源充足的情况下,可以考虑优化该属性。
5.2 基于平台的观点分布分析
为了评估各平台评论的信息质量,笔者根据平均字符数、平均观点数、观点平均所占字符数3个指标进行对比分析,结果见表5。可以看出:①京东平台评论的平均字符数和观点数都明显高于其他平台,这也许与各平台对优质评价的定义不同有关,京东需60字和2张图片,淘宝需40字和2张图片,抖音仅需20字和1张图片; ②抖音平台评论的平均字符数和观点数均为最低,但平均19个字符就包含1个观点,是4个平台中最优秀的,这可能与抖音的评价指引机制有关,其评论界面会显示“服务怎么样?性价比高吗”等类似标语。通过进一步研究,发现京东和抖音都有评价官机制,成为评价官可获得神券、免费试用等权益。因此,各平台可以通过奖励激励、评价指引等方式来提高评论的信息质量。
基于用户满意度计算,对服务属性下物流、包装、客服和售后4个细粒度特征进行分析,比较各个平台服务属性的用户满意度,结果见图7。可以发现:①在各项服务特征中,京东均有着较为明显的优势,而拼多多的用户满意度均为最低。这可能与商家经营方式有关,京东大部分商家为京东自营,而拼多多没有自营商家,并且主要以价格优势吸引用户,为了更低的价格,商家更有可能压缩其服务质量。②售后服务的用户满意度差距最大,京东(88%)最高,其次是淘宝(47%)、抖音(38%)、拼多多(26%),这可能与仓储模式和售后机制有关,京东有自营的仓库,能够做到品质溯源、快速退换货等,并且其为消费者提供“放心购”,提供价保、先退款后退货、上门换新等免费的售后服务。这说明在各项服务中售后服务是各平台需要重点优化的方向之一。
结合上述分析,京东和拼多多在各项服务的用户满意度上均存在较大差异,淘宝和抖音总体上满意度接近,但在客服和售后上存在差异,且均与京东差距明显。
5.3 基于品牌的观点分布分析
基于IPA模型,通过关注度和满意度的计算可以得到各品牌在电池、价格等7个产品核心属性上的观点分布情况,结果见图8。可以发现各品牌的同类属性分布较为集中但又存在差异,故从属性维度对各品牌进行比较分析,具体为:①从电池属性看,各个品牌均落于威胁改进区,应重点改进,其中vivo的满意度最高、小米的关注度最高;②从价格属性看,华为和苹果的关注度和满意度均较低,说明这两个品牌的用户对价格的感知度较低,其他品牌均落于机会优化区,应利用价格优势吸引目标用户;③从屏幕属性看,各品牌均落于机会优化区,是产品优化的机会点,其中vivo和苹果的满意度较高;④从摄像头属性看,vivo在关注度和满意度上都明显高于其他品牌,可见摄像头是vivo手机的优势属性,应当继续保持,小米落于威胁改进区,应重视该属性的优化改进;
⑤从外观属性看,各品牌的满意度均较高,皆位于优势保持区,其中苹果的用户关注度最高,说明其用户相比其他品牌更在意外观;⑥从网络与通信属性看,只有vivo落于机会优化区,应抓住这一属性进行优化,使产品在行业中脱颖而出,其余品牌均落于次劣发展区,在资源充足的情况下应发展该属性,其中苹果的满意度明显低于其他品牌;⑦从性能属性看,各品牌的关注度均较高,其中vivo、荣耀、苹果、OPPO的满意度较高,落于优势保持区,小米、华为的满意度较低,落于威胁改进区,应重点关注。值得注意的是,vivo在各属性上的满意度均为最高,是用户口碑最好的手机品牌,其背后的原因值得探索学习。
5.4 基于初评与追评的观点分布对比
追加评论是消费者使用一段时间、在初次评论后再次发表的评论,能够更真实地反映消费者的使用体验。对观点泛化后的
(1)属性维度变化分析。基于商品特征体系中的粗粒度属性分类以及用户关注度和满意度的计算,可以得到初评和追评中各属性的分布情况。①属性关注度变化分析。在初评中,用户关注度最高的属性为性能、外观和电池,占比分别为18.13%、15.65%和14.90%;而在追评中,性能、电池和服务最受消费者关注,占比分别为22.5%、18.02%和10.57%。可以发现从初评到追评,性能和电池的用户关注度略有上升,而外观的关注度则明显降低,从15.65%降至10.24%,这可能与用户的使用体验有关,随着使用时间的增加,手机的性能和续航可能逐渐降低,用户会对这类属性有更深的感受和新的体验;此外,服务在追评中受到较多关注,客服和售后可能是驱动用户进行追加评论的一大因素,商家和平台应重视购买后的客服和售后服务。②属性满意度变化分析。在初评和追评中,各属性的用户满意度变化情况见图9。可以发现,追评中各属性的用户满意度均低于初评,其中降幅最大的两个属性是网络与通信和性能,占比分别为52%和44%,降幅最小的是外观,占比仅为5%。这表明随着使用的深入,网络通信和性能更加影响使用体验,是用户较为核心的需求,而外观的重要性则逐渐降低。因此,基于各属性关注度和满意度的变化分析,商家应使用外观等外在属性来抓住用户,通过优化性能、电池和网络通信等内在属性来留住用户。
(2)用户维度变化分析。筛选初评和追评中都包含至少一个观点的用户ID,共获得9 541个用户的初追评。①用户关注变化分析。对同一用户在初评和追评中的评价属性流动情况进行分析,结果见图10。可以发现,同属性之间的流动占比较大,但总体呈现出[外观]→[性能、电池]的流动方向。这与上文的分析结果一致,用户在先前关注属性的基础上,关注点逐渐从外在属性转向内在属性。②用户情感变化分析。同属性间的流动代表用户在初评和追评中都评价了某一属性,对其中的情感倾向变化进行分析,发现同向变化占比86.24%,正向到负向占比10.33%,负向到正向仅占3.43%。这说明用户对同一属性前后的情感变化以同向为主,并且负向情感很少能转换为正向情感,经统计仅有13.61%的初评负向观点在追评中转换为正向观点,因此商家、客服应重视初评中的负向观点,针对性解决用户的问题,提高负向情感向正向转换的比率。此外,正向到负向的观点变化解释了用户产生负面情感的原因。例如从初评“服务好,客服态度佳”到追评“黑屏死机,用了半个月就不行了,客服说要自费,客服服务差,就是个摆设”解释了用户对客服产生负面情感的原因。商家、平台应更加关注这类观点变化,有的放矢地解决用户的诉求与痛点。
结合上述分析,初评到追评中的用户情感总体呈积极到消极的变化趋势,并且用户关注点逐渐从外在属性转向内在属性。
6 结论与展望/Conclusions and prospects
笔者针对电商用户评论设计了一套细粒度观点挖掘和分析的技术实现方法。基于预训练语言模型结合微调的观点抽取方法,在家居、零食、手机3个行业中进行实验,F1值分别达到了79.85%、83.28%、85.71%,证明了该方法的有效性和通用性;基于商品特征库的观点泛化方法,对手机行业的用户观点完成分类与聚类,对于其他行业,也可以使用该方法构建出商品特征库以实现观点泛化。此外,笔者以手机行业为例,对用户观点进行规律和差异分析,得出如下结论:性能、外观和电池是最受用户关注的属性,而电池和网络与通信的用户满意度较低;不同品牌、平台的用户对其产品、服务的观点分布均存在显著差异,对这些差异进行分析能够为商家和平台提供优化方向;初评和追评中的用户情感总体呈积极到消极的变化趋势,并且用户关注点逐渐从外在属性转向内在属性。
本研究仍然存在一定不足,后续的研究可以从以下方向开展:①在观点抽取阶段实现了自动化和跨领域抽取,但在观点泛化阶段还需要人工构建商品特征库,后续要考虑自动构建方法;②本文使用的观点抽取方法不能有效识别隐式观点,后续可考虑基于属性聚类、依赖关系分析等方法进行隐式观点的抽取;③在线评论中不仅有文本的信息,还有图片、视频等视觉方面的信息,在后续研究中可以利用多模态情感分析来提升模型的性能。
参考文献/References:
[1] HU M, LIU B. Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international conference on knowledge discovery and data mining. New York: Association for Computing Machinery, 2004, 168-177.
[2] 周知, 方正东.融合依存句法与产品特征库的用户观点识别研究[J]. 情报理论与实践, 2021, 44(7): 111-117. (ZHOU Z, FANG Z D. Research on user opinion recognition based on dependency syntax and product feature thesaurus[J]. Information studies: theory & application, 2021, 44(7): 111-117.)
[3] 睢国钦, 那日萨, 彭振.基于深度学习和CRFs的产品评论观点抽取方法[J]. 情报杂志, 2019, 38(5): 177-185. (SUI G Q, NA R S, PENG Z. Approach to extracting opinion from products reviews based on deep learning and CRFs[J]. Journal of intelligence, 2019, 38(5): 177-185.)
[4] 张诗林.基于Bi-LSTM和CRF的中文网购评论中商品属性提取[J]. 计算机与现代化, 2019, 282(2): 93-97. (ZHANG S L. Commodity attributes extracting in Chinese shopping reviews based on Bi-LSTM and CRF[J]. Computer and modernization, 2019, 282(2): 93-97.)
[5] 李亚琴.电子商务平台用户在线评论比较研究[J]. 现代情报, 2017, 37(7): 79-83. (LI Y Q. Comparative research on online consumer reviews of e-commerce platforms[J]. Journal of modern information, 2017, 37(7): 79-83.)
[6] 曹喆, 郭慧兰, 吴江, 等. 元宇宙的理想与现实:基于评论挖掘的VR产品用户感知研究[J]. 数据分析与知识发现, 2023, 7(1): 49-62. (CAO Z, GUO H L, WU J, et al. The ideal and reality of metaverse: user perception of VR products based on review mining[J]. Data analysis and knowledge discovery, 2023, 7(1): 49-62.)
[7] 王克勤, 刘朝明.基于在线评论的重要度绩效竞争对手分析的产品设计改进方法[J]. 计算机集成制造系统, 2022, 28(5): 1496-1506. (WANG K Q, LIU C M. Product design improvement based on importance performance competitor analysis of online reviews[J]. Computer integrated manufacturing systems, 2022, 28(5): 1496-1506.)
[8] 石文华, 龚雪, 张绮, 等. 在线初次评论与在线追加评论的比较研究[J]. 管理科学, 2016, 29(4): 45-58. (SHI W H, GONG X, ZHANG Q, et al. A comparative study on the first-time online reviews and appended online reviews[J]. Journal of management science, 2016, 29(4): 45-58.)
[9] 张艳丰, 王羽西, 彭丽徽, 等. 基于文本挖掘的在线用户追加评论内容情报研究——以京东商城手机评论数据为例[J]. 现代情报, 2020, 40(9): 96-105. (ZHANG Y F, WANG Y X, PENG L H, et al. Research on information of online users additional comments based on text mining——take the mobile phone review data of Jingdong mall as an example[J]. Journal of modern information, 2020, 40(9): 96-105.)
[10] 史丽丽, 林军, 朱桂阳.基于混合神经网络的中文在线评论产品特征提取及消费者需求分析[J]. 数据分析与知识发现, 2023, 7(10): 63-73. (SHI L L, LIN J, ZHU G Y. A hybrid neural network for product feature extraction and customer requirements analysis on Chinese online reviews[J]. Data analysis and knowledge discovery, 2023, 7(10): 63-73.)
[11] 韩玺, 蒋佩瑶, 韩文婷, 等. 医生在线评价信息特征的影响因素研究:社会资本和社会交换理论的视角[J]. 信息资源管理学报, 2023, 13(1): 78-90. (HAN X, JIANG P Y, HAN W T, et al. Influencing factors of doctors online rating information characteristics: based on social capital theory and social exchange theory[J]. Journal of information resources management, 2023, 13(1): 78-90.)
[12] 余佳琪, 赵豆豆, 刘蕤.在线健康社区慢性病患者评论主题情感协同挖掘研究——以甜蜜家园为例[J/OL]. 数据分析与知识发现, 2023, 7(10): 95-108. (YU J Q, ZHAO D D, LIU R. A topic-sentiment collaborative data mining on the chronic disease patients reviews in online health community —an evidence from “Sweet Homeland”[J]. Data analysis and knowledge discovery, 2023, 7(10): 95-108.)
[13] 孙宝生, 敖长林, 王菁霞, 等. 基于网络文本挖掘的生态旅游满意度评价研究[J]. 运筹与管理, 2022, 31(12): 165-172. (SUN B S, AO C L, WANG J X, et al. Evaluation of ecotourism satisfaction based on online text mining[J]. Operations research and management science, 2022, 31(12): 165-172.)
[14] 邰杨芳.健康教育类在线课程的用户需求及评价挖掘分析[J]. 中国大学教学, 2023(S1): 100-113. (TAI Y F. User demand and evaluation mining analysis of health education online courses[J]. China university teaching, 2023(S1): 100-113.)
[15] 李冠, 赵毅.基于在线评论的政府数据开放平台用户增量需求研究[J]. 数字图书馆论坛, 2022(12): 37-46. (LI G, ZHAO Y. Research on user incremental demand of government data open platform based on online comments[J]. Digital library forum, 2022(12): 37-46.)
[16] 肖宇晗, 林慧苹.基于CWSA方面词提取模型的差异化需求挖掘方法研究——以京东手机评论为例[J]. 数据分析与知识发现, 2023, 7(1): 63-75. (XIAO Y H, LIN H P. Mining differentiated demands with aspect word extraction: case study of smartphone reviews[J]. Data analysis and knowledge discovery, 2023, 7(1): 63-75.)
[17] 丁晟春, 侯琳琳, 王颖.基于电商数据的产品知识图谱构建研究[J]. 数据分析与知识发现, 2019, 3(3): 45-56. (DING S C, HOU L L, WANG Y. Product knowledge map construction based on the e-commerce data[J]. Data analysis and knowledge discovery, 2019, 3(3): 45-56.)
[18] 李叶叶, 李贺, 沈旺, 等. 基于多源异构数据挖掘的在线评论知识图谱构建[J]. 情报科学, 2022, 40(2): 65-73, 98. (LI Y Y, LI H, SHEN W, et al. Construction of online comment knowledge graph based on multi-source heterogeneous data mining[J]. Information science, 2022, 40(2): 65-73, 98.)
[19] PENG H Y, XU L, BING L D, et al. Knowing what, how and why: a near complete solution for aspect-based sentiment analysis[J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 8600-8607.
[20] ZHANG C, LI Q, SONG D, et al. A multi-task learning framework for opinion triplet extraction[C]// Findings of the Association for Computational Linguistics: EMNLP 2020, Online: Association for Computational Linguistics, 2020, 819-828.
[21] XU L, CHIA Y K, BING L D. Learning span-level interactions for aspect sentiment triplet extraction[C]// Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (Volume 1: Long Papers). Online: Association for Computational Linguistics, 2021: 4755-4766.
[22] YAN H, DAI J Q, JI T, et al. A Unified generative framework for aspect-based sentiment analysis[C]// Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (Volume 1: Long Papers). Online: Association for Computational Linguistics, 2021: 2416-2429.
[23] CHEN S W, WANG Y, LIU J, et al. Bidirectional machine reading comprehension for aspect sentiment triplet extraction[J]. arXiv, 2021: arxiv.org/abs/2103.07665.
[24] ZHANG W X, LI X, DENG Y, et al. Towards generative aspect-based sentiment analysis[C]// Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (Volume 2: Short Papers). Online: Association for Computational Linguistics, 2021: 504-510.
[25] LU Y J, LIU Q, DAI D, et al. Unified structure generation for universal information extraction[C]// Proceedings of the 60th annual meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin: Association for Computational Linguistics, 2022: 5755–5772.
[26] 吴江, 侯绍新, 靳萌萌, 等. 基于LDA模型特征选择的在线医疗社区文本分类及用户聚类研究[J]. 情报学报, 2017, 36(11): 1183-1191. (WU J, HOU S X, JIN M M, et al. LDA feature selection based text classification and user clustering in Chinese online health community[J]. Journal of the China Society for Scientific and Technical Information, 2017, 36(11): 1183-1191.)
[27] 单晓红, 孔维嘉, 王蕊.社交媒体数据驱动的老年人智能化需求研究[J]. 情报理论与实践, 2022, 45(8): 23-30. (SHAN X H, KONG W J, WANG R. Research on the intelligent needs of the elderly driven by social media data[J]. Information studies: theory & application, 2022, 45(8): 23-30.)
[28] 吴江, 李秋贝, 胡忠义, 等. 基于IPA模型的乡村旅游景区游客满意度分析[J]. 数据分析与知识发现, 2023, 7(7): 89-99. (WU J, LI Q B, HU Z Y, et al. Analysis on tourist satisfaction of rural tourism attractions based on IPA model[J]. Data analysis and knowledge discovery, 2023, 7(7): 89-99.)
[29] 叶佳鑫, 熊回香, 孟璇.基于细粒度评论挖掘的在线图书相似度计算研究[J]. 情报科学, 2023, 41(1): 166-173. (YE J X, XIONG H X, MENG X. Online book similarity calculation based on fine-grained review mining[J]. Information science, 2023, 41(1): 166-173.)
[30] 肖寒琼, 张馨遇, 肖宇晗, 等. 基于方面词的用户消费心理画像方法[J]. 数据分析与知识发现, 2022, 6(6): 22-31. (XIAO H Q, ZHANG X Y, XIAO Y H, et al. Creating consumer psychology portrait with aspect words[J]. Data analysis and knowledge discovery, 2022, 6(6): 22-31.)
[31] DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[J]. arXiv, 2019: arxiv.org/abs/1810.04805.
[32] MARTILLA J A, JAMES J C. Importance-performance analysis[J]. Journal of marketing, 1977, 41(1): 77-79.
[33] KANO N, SERAKU N, TAKAHASHI F, et al. Attractive quality and must-be quality[J]. Journal of the Japanese Society for Quality Control, 1984, 14(2): 39-48.
[34] 黄官伟, 邵立轲.基于在线评论与IPA-Kano模型的酒店服务质量管理研究[J]. 上海管理科学, 2021, 43(6): 12-17. (HUANG G W, SHAO L K. Research on hotel service quality management based on online reviews and IPA-Kano model[J]. Shanghai management science, 2021, 43(6): 12-17.)
[35] 李贺, 曹阳, 沈旺, 等. 基于LDA主题识别与Kano模型分析的用户需求研究[J]. 情报科学, 2021, 39(8): 3-11, 36. (LI H, CAO Y, SHEN W, et al. User demand based on LDA subject identification and Kano model analysis[J]. Information science, 2021, 39(8): 3-11, 36.)
[36] SUN Y, WANG S, FENG S, et al. ERNIE 3.0: large-scale knowledge enhanced pre-training for language understanding and generation[J]. arXiv, 2021: arxiv.org/abs/2107.02137.
作者贡献说明/Author contributions:
陆晨晨:负责模型构建和实验设计,论文起草、撰写与修改;
王 昊:确定研究思路,指导实验,提出论文框架,指导论文修改;
石 斌:指导论文修改;
裘靖文:指导论文修改。
Research on Fine-grained Opinion Mining and Distribution Law of opinion for E-Commerce Customer Reviews
Lu Chenchen1,2 Wang Hao1,2 Shi Bin1,2 Qiu Jingwen1,2
1School of Information Management, Nanjing University, Nanjing 210023
2Jiangsu Key Laboratory of Data Engineering and Knowledge Service, Nanjing 210023
Abstract: [Purpose/Significance] E-commerce customer reviews contain a wealth of valuable information. By identifying user opinions and analyzing the distribution patterns and differences, this research aims to provide insights for consumers, businesses, and platforms. [Method/Process] Firstly, based on the UIE model, user opinions were extracted from customer reviews in the three industries of furniture, snack, and mobile phone. Secondly, based on the product feature thesaurus and BERT model, the semantic similarity between words was calculated to generalize and filter opinions. Finally, based on the IPA model, statistical analysis and visualization of user opinions were conducted to provide optimization suggestions for businesses and platforms. [Result/Conclusion] In terms of opinion mining, the model performs well across all three industries with the F1 values of 79.85%, 83.28%, and 85.71% respectively, which confirms the effectiveness of the method. In the mobile phone industry, regularity analysis indicates user attention mainly focuses on performance, appearance, and battery, but significant differences in opinion distribution are observed among various platforms and brands. Moreover, user satisfaction generally shows a shifting trend of positive to negative from initial reviews to follow-up reviews.
Keywords: customer reviews fine-gained sentiment analysis opinion mining pre-trained language model IPA analysis
Fund Project(s): This work is supported by the Fundamental Research Funds for the Central Universities “Data Engineering and Knowledge Service Jiangsu Provincial University Key Laboratory Project”(Grant No. 0108-14370323).
Author(s): Lu Chenchen, master candidate; Wang Hao, professor, PhD, doctoral supervisor, corresponding author, E-mail: ywhaowang@nju.edu.cn; Shi Bin, master candidate; Qiu Jingwen, doctoral candidate.
Received: 2023-08-10 Published: 2024-06-12
基金项目:本文系中央高校基本科研业务费专项资金资助项目“数据工程和知识服务江苏省高校重点实验室项目”(项目编号:0108-14370323)研究成果之一。
作者简介:陆晨晨,硕士研究生;王昊,教授,博士,博士生导师,通信作者,E-mail: ywhaowang@nju.edu.cn;石斌,硕士研究生;裘靖文,博士研究生。
收稿日期:2023-08-10 发表日期:2024-06-12

- 知识管理论坛的其它文章
- 大模型在知识管理中的应用与挑战