
数据要素、数据挖掘与中国服务业生产率提升
2024-07-07 19:51:29于柳箐高煜
商业研究 2024年3期
关键词:数据挖掘
于柳箐 高煜

摘 要:数字经济时代下数据要素的出现为实现服务业生产率进一步提升提供了新的可能。本文基于2012—2019年中国省际面板数据,使用双重机器学习方法探究了数据要素影响服务业生产率提升的效应、作用机制与异质性表现。研究发现,数据要素显著促进中国服务业生产率提升;数据挖掘能力的提高增强了数据要素对服务业生产率提升的效应;数据要素更有助于生活性服务业以及中国东部和南方地区服务业的生产率提升。
关键词:数据要素;数据挖掘;服务业生产率;双重机器学习
中图分类号:F719 文献标识码:A 文章编号:1001-148X(2024)03-0009-11
收稿日期:2023-08-01
作者简介:于柳箐(1990—),男,陕西西安人,博士研究生,研究方向:机器学习、计量经济学、产业经济学;高煜(1973—),男,陕西白水人,教授,博士生导师,研究方向:产业经济学、发展经济学。
基金项目:国家社会科学基金后期资助项目“创新驱动价值链升级的理论与实证研究”,项目编号:21FJLB028;陕西省社会科学基金项目“现代产业分工推动西安都市圈与关中平原城市群协调发展研究”,项目编号:2021DA016。
①《中华人民共和国2019年国民经济和社会发展统计公报》显示,服务业超过农业和工业成为第一大产业,其增加值占GDP的比重和对GDP的贡献率均达到50%以上。
一、引 言
党的二十大报告指出,要“构建优质高效的服务业新体系”,而推进服务业生产率提升是其首要任务。当前,中国已经进入了以服务经济为主的新时代①[1],同时也结束了持续近四十年的高速经济增长。从产业结构来看,中国经济增速放缓主要是由于以服务业为主导产业结构的经济体系出现经济增速下行的趋势,而之所以发生这种“结构性减速”,主要原因在于服务业本身具有低效率特征,进而产生了所谓的“成本病”问题。Baumol(1967)研究发现,随着技术进步,制造业对劳动力的需求不断减少,在劳动力要素转移至服务业后,不仅没有推动服务业生产率提升,反而由于产业间效率的不平衡增长导致整体经济增速下滑[2]。因此,为改变中国经济增速下行趋势,必须进一步提升服务业生产率。然而,劳动力、资本等生产要素普遍存在边际报酬递减特性,同时在人口老龄化、工资上涨、资本效率下降等情况下,传统要素提升服务业生产率的动能不足[3-4]。
幸运的是,中国经济在进入以服务业为主的发展阶段时,恰好与数字技术的兴起相重合,因此有可能打破“服务业时代是低增长时代”这个过往的规律[1]。数字技术的应用不仅能从根本上改变传统服务业低效率的特征,还可以创造新的服务和商业模式,使得服务业生产率得以提升[5-8]。更为重要的是,随着大数据、物联网、云计算等数字技术的进步,中国步入了数字经济时代,其中最为鲜明的变化是,数据成为继劳动力、资本等传统要素后形成的又一基础性生产要素。2020年3月30日,印发的《中共中央 国务院关于构建更加完善的要素市场化配置体制机制的意见》,第一次从国家层面确立了数据基础性生产要素的地位。2022年12月2日,又印发了《中共中央 国务院关于构建数据基础制度更好发挥数据要素作用的意见》,进一步强调“为加快构建数据基础制度……激活数据要素潜能”。
数据要素与传统要素最根本的区别在于具有易复制性,使得其额外使用的成本几乎为零,由此又衍生出数据要素的非竞争性,即任何主体都可以使用同一套数据而不会损害其他主体对数据的使用,尤其是与传统要素边际产出不断下降不同,数据要素的回报率较高[9],因此体现出巨大的经济价值[10]。Müller等(2018)与张叶青等(2021)分别针对美国和中国企业的实证研究发现,大数据的应用显著提高了企业生产效率,这无疑提供了数据要素可以提升服务业生产率的部分证据[11-12]。然而,现有研究主要关注网络技术[6-7]、数字经济发展[13]等对服务业低效率特征的改善,以及数字技术[14]、数字基础设施[15]等对服务业生产率提升的作用,并未涉及数据要素对服务业生产率的影响。有鉴于此,本文在厘清数据要素提升服务业生产率内在机理的基础上,以2012—2019年中国省际面板数据为样本,使用双重机器学习方法就数据要素影响服务业生产率提升的效应、作用机制与异质性表现进行检验。本文的研究不仅有助于进一步理解数据要素的价值以及如何发挥其作用,并且对拥有海量数据规模和丰富应用场景优势的中国而言,证实数据要素对服务业生产率具有提升作用,对于激活数据要素潜能,治愈服务业“成本病”,打破经济“结构性减速”规律具有重要的现实意义。
与现有研究相比,本文的创新之处主要体现在以下两个方面:(1)就研究内容而言,明确从数据要素角度对服务业生产率提升问题展开理论分析与实证检验,为相关研究提供了一定补充。首先,理论分析了数据要素对服务业生产率提升的影响,丰富了数据要素、服务业生产率等领域的研究;其次,考察了数据挖掘对数据要素促进服务业生产率提升的调节作用,不仅加深了对数据要素影响服务业生产率内在机制的理解和认识,也为更好发挥数据要素生产率提升效应提供政策参考。(2)就研究方法而言,使用双重机器学习这一较为前沿的因果推断方法,不但满足了本文的研究需求,还得到了更为有效的数据要素提升中国服务业生产率效应估计,提高了结论的可信性。由于影响服务业生产率提升的要素较多,为得到数据要素的一致估计,其他潜在混淆因素均需考虑控制。然而在一定样本容量下,经典因果推断模型仅能控制少量因素,容易发生由遗漏变量引起的内生性问题,但是增加控制变量后,又会产生自由度下降、多重共线性和“维度灾难”等问题,造成估计失效。同时,其他潜在混淆因素对服务业生产率的影响还可能是非线性的,而经典因果推断模型的线性假设将造成估计有偏。在对数据要素提升中国服务业生产率效应的估计中,基于机器学习算法在高维数据处理和非参数拟合上的优势,采用双重机器学习方法不仅可以控制更多的协变量,还可以不受函数形式的限制,从而在一定程度上缓解了使用经典因果推断模型时所遇到的变量遗漏和函数误设问题。
二、理论机制与研究假说
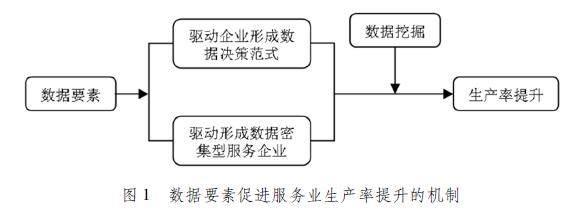
作为生产要素的数据其实质是存在于网络和计算机内的0—1字符,因而相较于劳动力、资本等传统要素更为原始、分散、细碎,需要进行采集、整理(存储)、清洗后才能成为企业生产的投入[16]。尤其是与传统要素依赖直接消耗和形变产生价值不同,数据中蕴藏着规律,仅具有价值潜能,只有通过分析提炼出有用的知识才能将其价值释放[17]。数据要素促进服务业生产率提升的机制如图1所示。
图1 数据要素促进服务业生产率提升的机制
(一)数据要素对服务业生产率提升的影响
1 数据要素驱动企业形成数据决策范式,实现服务业生产率提升
数据作为重要的生产要素之一,改变了服务业企业传统的经营管理决策模式,驱动企业形成数据决策范式。对日常生产、经营、管理中产生的数据进行挖掘,企业可以得到优化自身经营管理决策的有用知识,而对这些知识的应用将赋能决策实践,提高经营管理决策效率。一方面,数据决策范式提升了企业内部信息的透明度,形成对生产经营活动的细致观察,使得决策时可用信息更加丰富,比如在财务决策中,除了使用传统的资产负债表、现金流表、利润表外,还可以引入对口碑、品牌价值等数据资产的测量信息[18]。另一方面,数据决策范式激发了企业在商业洞察、风险预判和业务模式等方面的创新[19],进而增强了对市场环境变化的反应,不仅对未来发展方向的分析更为准确,还可以及时作出相关决策,在瞬息万变的市场变化中降低了经营管理风险,提高了生产效率[20]。
2 数据要素驱动形成数据密集型服务企业,实现服务业生产率提升
随着数据要素规模的扩大,以及机器学习、深度学习、人工智能等算法的优化,更多知识、信息、洞见等得以挖掘提炼,为新产品和新服务的开发提供了有力支持[21]。在服务业层面,以云计算、移动互联网、5G等为技术支撑,数据要素驱动的新业态、新服务、新模式不断涌现,并逐渐形成一批数据密集型服务企业,使得住宿餐饮、交通运输、批发零售等服务领域不仅实现了更为有效精准的供需匹配[22],更是突破了服务的时空限制,改变了服务业不可储存、不可贸易的特性,从根本上解决了传统服务业低效率的问题[7]。据此,本文提出以下假说:
H1:数据要素可以促进中国服务业生产率提升。
(二)数据挖掘对数据要素促进服务业生产率提升的影响
前文分析表明,数据在经过采集、存储、清洗和分析等步骤后,将提炼出有关如何改进企业经营管理决策、供需匹配等知识,进而驱动企业数据决策范式和数据密集型服务企业的形成,实现服务业生产率提升。以上数据处理步骤即为数据挖掘过程,在数据价值释放、知识生产中发挥着关键作用。数据要素的出现以及相关数据挖掘技术的进步改变了知识发现模式,尤其是数据要素所具有的非竞争性和低复制成本特征,使其可以被不同主体重复、同时挖掘,进而促使更多、更有价值的知识被发现,呈现知识倍增态势,提高企业新知识获取的效率。因此,企业数据挖掘能力越强,知识生产效率就越高,即从单位数据中能够产生更多的知识,从而数据要素对企业生产率的提升就越明显。据此,本文提出以下假说:
H2:数据挖掘对数据要素促进服务业生产率提升具有正向调节作用,即数据挖掘能力的提高将增强数据要素对服务业生产率提升的效应。
三、研究设计
(一)模型构建
为避免使用经典线性因果推断方法可能遭遇的变量遗漏和函数误设问题,得到更为有效的数据要素影响中国服务业生产率效应估计,本文建立如下部分线性回归双重机器学习模型(Partially Linear Regression-Double Machine Learning, PLR-DML):
proi,t=θ0datScai,t+g0Xi,t+Ui,t,EUi,tdatScai,t,Xi,t=0(1)
datScai,t=m0Xi,t+Vi,t,EVi,tXi,t=0(2)
其中,下标i代表省份、t代表年份。proi,t为结果变量,表示服务业生产率;datScai,t为处理变量,表示数据要素投入规模;θ0是需要重点关注的数据要素影响服务业生产率的条件平均处理效应;Xi,t是涉及其他影响服务业生产率因素的高维控制变量(协变量),g0Xi,t与m0Xi,t则分别为关于Xi,t影响结果变量proi,t和处理变量datScai,t的未知函数,即厌恶函数;Ui,t和Vi,t是条件均值为零的随机误差项。
传统的参数回归首先设定g0Xi,t为完全线性或交互项、平方项等形式,随后执行OLS估计,然而由于处理变量datScai,t还受协变量Xi,t的影响,如此可能导致函数误设,造成估计有偏。为了避免函数设定偏差,可以使用核回归等非参数方法估计0Xi,t,但是当协变量Xi,t维度很高时,这又会产生“维度灾难”问题,造成估计失效。使用适用于高维数据回归的机器学习方法(如SVM、Lasso、XGBoost)估计0Xi,t即可解决这一问题,此时处理变量系数θ0的估计量为:
0=1n∑i∈I,t∈TdatSca2i,t-11n∑i∈I,t∈TdatScai,t(proi,t-0(Xi,t))(3)
其中,n表示样本容量。然而,直接使用机器学习估计0Xi,t时将引入正则化偏差,造成估计量0有偏。为此,需要从处理变量datScai,t分离出协变量Xi,t的影响,从而得到具有正交性的处理变量,即使用机器学习估计0Xi,t,然后计算残差V[DD(-*2/3][HT6”]^[][HT][DD)]i,t=datScai,t-0Xi,t,此时V[DD(-*2/3][HT6”]^[][HT][DD)]i,t作为处理变量datScai,t的工具变量满足相关性与外生性要求,因此可以使用IV矩估计得到θ[DD(-*2/3][HT6”]^[][HT][DD)]0:
θ[DD(-*2/3][HT6”]^[][HT][DD)]0=1n∑i∈I,t∈TV[DD(-*2/3][HT6”]^[][HT][DD)]i,tdatScai,t-11n∑i∈I,t∈TV[DD(-*2/3][HT6”]^[][HT][DD)]i,t(proi,t-0(Xi,t))(4)
遗憾的是,估计量θ[DD(-*2/3][HT6”]^[][HT][DD)]0依然可能存在偏差,因为使用较为复杂的机器学习算法还引入了过拟合偏差,这可以通过交叉拟合解决,即将样本随机划分为等量的两部分,一部分用于机器学习估计0Xi,t和0Xi,t,另一部分用于θ[DD(-*2/3][HT6”]^[][HT][DD)]0的估计,随后交换两部分样本重新进行以上估计,最后取两次θ[DD(-*2/3][HT6”]^[][HT][DD)]0估计值的平均数此时这一估计方法称为2折交叉拟合,为了提高处理效应估计量的精确性,一般在实践中还采用5折交叉拟合进行估计,即将样本随机划分为5个部分,进行5次交叉估计。。Chernozhukov等(2018)证明,在消除正则化偏差和过拟合偏差后,PLR-DML处理效应估计量是一致的[23]。
(二)变量设定
1 结果变量
本文的结果变量为服务业生产率,以劳动生产率(serLab)和全要素生产率进行衡量,其中,劳动生产率采用人均增加值的自然对数表示,全要素生产率则使用Malmquist指数方法进行测算(以符号Malmquist_TFP表示)产出变量为服务业增加值(经过平减处理),投入变量分别为服务业就业人数和资本存量(基于服务业实际固定资产投资数据使用永续盘存法计算)。需要说明的是,由于Malmquist计算的是以基年(2012)的值为1时后续年份TFP相较于上一年的变化,因此本文通过累乘上一年指数的方式将Malmquist_TFP指标转换为水平值。。
2 处理变量
本文旨在研究数据要素能否提升中国服务业生产率的问题,因此处理变量是数据要素投入规模,使用徐翔等(2021)基于成本法估算的历年中国各省份数据要素规模存量(datSca)的自然对数进行衡量[24]。具体方法如下:数据生产过程中的成本分为人工成本与数据库这里的数据库是指广义上的进行数据采集、存储、清洗和分析等相关软件和ICT设备。成本,前者由相关劳动力的工资支出进行衡量,后者则使用相关ICT资产的投资支出进行衡量。t年份i省份j行业包括《国民经济行业分类》标准中的所有二位数(大类)行业。的数据生产人工成本为αjWagei,j,t,其中αj表示行业j中数据生产劳动力成本占总劳动力成本的比重,Wage表示就业人员工资总额。可以看到,数据生产人工成本测算的关键在于对αj的估计。实际上,任何一类劳动力都不会将全部工作时长均用于数据生产,由于数据生产过程主要依赖相应的ICT设备,因此行业ICT中间投入占总中间投入的比重反映了行业劳动力数据生产时长占总劳动时长的比重,进而反映了行业数据生产劳动力成本占总劳动力成本的比重:
ICT中间投入总中间投入≈劳动力数据生产时长总劳动时长≈数据生产劳动力成本总劳动力成本=αj(5)
加总所有行业的数据生产人工成本即为t年份i省份的数据生产人工成本(∑jαjWagei,j,t),进一步与t年份i省份的数据库成本(datBasei,t)使用软件和信息技术服务业的固定资产投资数据衡量。相加即可得到i省份当年新增的数据要素规模(流量)此时为名义值,采用固定资产投资价格指数进行平减。。最后使用永续盘存法即可计算得到i省份在t年份的数据要素存量:
datScai,t=1-δDdatScai,t-1+(∑jαjWagei,j,t+datBasei,t)(6)
其中,δD为数据要素的折旧率,徐翔和赵墨非(2020)认为,短期内数据要素的折旧率接近于0[9];基期的数据要素存量为当年新增数据要素规模除以后5年数据要素流量的平均增长率。
3 控制变量
考虑到双重机器学习具有控制高维协变量的优势,为避免遗漏变量偏差,本文参考相关研究[8,25],建立了包括7个要素类别,涵盖30种要素的影响服务业生产率提升的投入要素指标体系,如表1所示。不同于现有研究,本文在人力资本要素中包含了数据劳动指数据生产过程中所涉及的有关劳动力。,在物质资本要素中包含了数据资本指数据生产过程中所涉及的有关软件和ICT设备。、网络基础设施以域名数(domNa)和互联网宽带接入端口数(port)作为对网络基础设施建设情况的衡量。,以反映数字经济时代下人力资本与物质资本的新内涵。其中,对于数据劳动人数(datLab)的测算,使用与数据生产紧密相关的7个国民经济大类行业计算机、通信和其他电子设备制造业;仪器仪表制造业;通用设备制造业;专用设备制造业;软件和信息技术服务业;互联网和相关服务;电信、广播电视和卫星传输服务。在各省的就业人数,分别乘以徐翔等(2021)估算的对应行业数据生产劳动力成本占总劳动力成本的比重[24],随后在省份层面对以上计算结果进行加总;数据资本投资(datInv)使用软件和信息技术服务业的固定资产投资数据进行衡量该行业的固定资产包括进行数据生产所需的各种软件、数据库、计算机等。,并基于永续盘存法计算数据资本存量(datK)其中,基期数据资本存量为当年数据资本投资/10%,同时考虑到数据资本的更新换代较快,因此设定折旧率为20%。。
(三)数据说明与变量描述性统计
本文所用面板数据的时间区间为2012—2019年,共涉及31个省区市考虑数据可得性,不包括中国台湾、中国香港和中国澳门。。计算服务业劳动生产率和全要素生产率的相关数据来自《中国第三产业统计年鉴》《中国劳动统计年鉴》《中国固定资产投资年鉴》和《中国投资领域统计年鉴》等。其他控制变量数据的来源除以上统计年鉴外,还包括《中国统计年鉴》《中国科技统计年鉴》《中国人口和就业统计年鉴》《中国教育统计年鉴》以及中国研究数据服务平台(CNRDS)。缺失的数据由线性插值法填补,有关增加值、固定资产投资、收入等涉及价格的变量均进行了平减处理(2012=1)。另外,由于本文样本中变量较多且单位存在较大差异,为消除不同量纲对双重机器学习估计的不利影响,对数据进行了标准化处理。主要变量的描述性统计结果如表2所示。
四、实证结果分析
(一)数据要素影响服务业生产率的效应
表3报告了使用PLR-DML模型得到的数据要素影响服务业生产率效应估计结果采用R语言DoubleML包中的DoubleMLPLR函数进行估计,超参数选择与模型构建对应,一方面对处理变量进行正交化处理(orthogonalization)以消除正则化偏差,即score=“IV-type”;另一方面使用交叉拟合估计处理变量系数,即dml_procedure= “dml1”。。其中,模型(1)和(2)使用5折交叉拟合,模型(3)和(4)则使用2折交叉拟合。对PLR-DML模型中厌恶函数的估计可以使用任意机器学习方法,本文选择默认超参数的XGBoost如无特别说明,后文实证中均使用默认超参数的XGBoost估计厌恶函数,同时DML超参数也与基准估计一致。,因为该方法基于极端梯度提升算法改进了经典提升森林模型,泛化(样本外预测)性能在众多机器学习模型中具有优势,进而能更好地反映高维协变量与数据要素投入、服务业生产率提升之间真实的数据生成过程,使得对数据要素影响服务业生产率效应的估计更为有效。与此同时,为进一步避免不同地区不随时间变化的,以及省际层面随时间变化的不可观测因素对估计的影响,借鉴张涛和李均超(2023)的做法,将省份和年份变量转换为虚拟变量纳入协变量中,以对地区固定效应和时间固定效应加以控制[26]。可以看到,服务业生产率无论以劳动生产率还是全要素生产率进行衡量,在5折和2折交叉拟合下,datSca的系数均在1%的水平上显著为正,说明数据要素显著促进中国服务业生产率提升,假说H1成立。
(二)内生性问题处理
在基准估计中,虽然已经引入了尽可能多的协变量,并控制了地区和时间固定效应,但由于样本限制,依然可能遗漏变量,同时还可能存在处理变量测量误差和双向因果,从而引发内生性问题,造成PLR-DML估计不一致。为此,本文使用双重机器学习的工具变量法予以克服。依据Chernozhukov等(2018),构建部分线性工具变量回归模型(Partially Linear Instrumental Variable Regression Model, PLIV)[23]:
proi,t=θ0datScai,t+g0Xi,t+Ui,t(7)
IVi,t=m0Xi,t+Vi,t(8)
其中,IV表示datSca的工具变量。参考施炳展和李建桐(2020)的研究,本文选择建国初期(1953—1957年)各省份人均函件数量(letter)作为datSca的工具变量[27]。其合理性在于:一方面letter符合相关性要求,函件数量反映了各省份居民对于通信方式的接受程度或者偏好,而这种偏好在省份内相对稳定,进而影响了此后居民对互联网这一现代通讯方式的接受程度,由于互联网是数据要素主要的生成与流通媒介,从而与datSca存在相关性;另一方面letter符合外生性要求,因为函件仅能满足居民的日常通信需求,并不会对服务业生产率产生直接影响,同时建国初期人均函件数量也不可能影响到近期的服务业生产率,因此,letter只能通过地区数据规模这一途径间接影响服务业生产率。另外,参考钞小静和王宸威(2022)的研究,本文还选择1988年各省份每百万人微型电子计算机产量(computer)作为datSca的工具变量[28]。其合理性在于:一方面computer符合相关性要求,由于计算机是数据要素形成、展示、存储以及分析等的重要载体,因此早期计算机产量越高的地区,后期数据要素规模就可能越大,从而computer与datSca存在相关性;另一方面computer符合外生性要求,因为较早时期各省份的计算机产量对近期服务业生产率的直接影响微乎其微。因此,computer只能通过地区数据规模这一途径间接影响服务业生产率。进一步,根据Nunn and Qian(2014)的做法,本文为上述截面工具变量引入时间趋势,具体是将letter和computer分别乘以上一年全国软件和信息技术服务业固定资产投资(不含农户)数据,构造交互项并取自然对数,从而将其扩展为面板工具变量[29]。
表4报告了工具变量估计结果采用R语言DoubleML包中的DoubleMLPLIV函数进行估计,超参数使用默认值,即score=“partialling out”,dml_procedure=“dml2”。,可以看到,在以劳动生产率和全要素生产率衡量服务业生产率时,无论是以computer还是letter作为datSca的工具变量,其系数均在1%的水平上显著为正,这与基准估计一致,说明充分考虑内生性问题后,数据要素促进中国服务业生产率提升的结论依然成立,本文的研究假说H1得到了进一步证实。
(三)稳健性检验
1 更换处理变量
为进一步缓解由处理变量测量误差引发的内生性问题,借鉴杨艳等(2023)在验证其估算的数据要素价值是否合理时的做法,使用移动互联网接入流量(intFlo)作为数据要素投入规模的代理变量[30]。估计结果如表5列(1)所示。
2 更换结果变量
Malmquist指数法属于非参数方法,在测算TFP时不仅无法检验前沿面的适用性,也未能考虑随机因素的影响,为此本文使用基于超越对数生产函数的随机前沿分析法(SFA)重新测算服务业全要素生产率(以符号SFA_TFP表示)。同时,进一步考虑到参数法测算TFP时难以避免内生性问题,本文还使用半参数的OP法测算了服务业全要素生产率(以符号OP_TFP表示)。估计结果如表5列(2)和列(3)所示。
3 解释变量滞后
服务业生产率的提升可能会进一步加快形成新业态、新服务、新模式,在深化服务业数字化程度的同时导致数据要素规模的持续扩大,从而出现双向因果。为进一步缓解由双向因果导致的内生性问题,本文将处理变量和控制变量均滞后一期。估计结果如表5列(4)所示。
4 更换机器学习
相比于其他机器学习算法,XGBoost对数据的拟合能力较强,有可能错误学习样本内的随机误差,进而降低泛化性能(即发生过拟合现象),影响双重机器学习估计量的有效性和一致性。为避免XGBoost过拟合对PLR-DML的估计结果产生影响,分别使用支持向量机(SVM)和套索回归(Lasso)对厌恶函数进行估计。结果如表5列(5)和列(6)所示。
可以看到,在更换处理变量、结果变量、机器学习以及滞后解释变量一期后,数据要素影响中国服务业生产率的效应均在1%的水平上显著为正,这充分说明本文的基本结论稳健。
(四)调节机制检验
本文在基准估计模型(1)、模型(2)的基础上引入数据规模(datSca)与数据挖掘能力变量的交互项,以检验数据挖掘对数据要素促进服务业生产率提升效应的调节作用,具体模型构建如下:
proi,t=θ0datScai,t×datMini,t+g0Xi,t+Ui,t,EUi,tdatScai,t×datMini,t,Xi,t=0(9)
datScai,t×datMini,t=m0Xi,t+Vi,t,EVi,tXi,t=0(10)
其中,datMini,t表示i省份在t年的数据挖掘能力;θ0是本文关心的交互项系数,若显著为正则表明数据挖掘能力的提高增强了数据要素对服务业生产率提升的促进作用。另外,为保证估计的一致性,将datScai,t和datMini,t同时归入协变量Xi,t中。
本文使用多指标综合评价方法构建数据挖掘能力指数,以反映不同省份历年的数据挖掘能力。数据挖掘过程由相关劳动力使用相应软件、数据库、计算机等实现,因此当数据劳动供给和数据资本投资充足时,地区将拥有较强的数据挖掘能力,换言之,数据劳动人数和数据资本水平体现了地区的数据挖掘能力。鉴于此,本文分别基于主成分分析(PCA)、面板熵值法(EEM)以及算术平均法(Mean)将数据劳动人数、数据资本投资和数据资本存量三个指标综合为数据挖掘能力指数(datMin)。
表6报告了调节机制检验结果,可以看到,在以劳动生产率和全要素生产率衡量服务业生产率时,无论以何种方法计算数据挖掘能力指数,交互项datSca×datMin系数均在1%的水平上显著为正,说明数据挖掘对数据要素促进服务业生产率提升具有正向调节作用,即数据挖掘能力的提高显著增强了数据要素对服务业生产率提升的效应,假说H2得到证实。
五、异质性分析
(一)服务业类型差异
服务业可以分为生产性服务业和生活性服务业两种类型,前者是与工业、制造业发展直接配套的一类服务业依据国家统计局发布的《生产性服务业统计分类(2019)》标准,生产性服务业包括以下行业:批发和零售业,交通运输、仓储及邮政业,信息传输、软件和信息技术服务业,金融业,租赁和商务服务业,科学研究和技术服务业。,后者是为满足居民日常生活需求的一类服务业依据国家统计局发布的《生活性服务业统计分类(2019)》标准,生活性服务业包括以下行业:住宿和餐饮业,房地产业,水利、环境和公共设施管理业,居民服务、修理和其他服务业,教育,卫生和社会工作,文化、体育和娱乐业。。由于这两类服务业在国民经济发展中的用途各异,使得它们在数字化进程以及数据要素需求上可能有所不同,进而导致数据要素对这两类服务业生产率提升的效应存在差异。为此,本文使用PLR-DML模型分别估计数据要素对生产性和生活性服务业生产率采用劳动生产率(即增加值/就业人数)的自然对数进行衡量。其中两类服务业的增加值和就业人数数据由各自所包括行业的数据加总而来。需要说明的是,国家统计局一直公布个别服务业行业的增加值数据,比如批发和零售业,交通运输、仓储和邮政业,住宿和餐饮业,金融业,房地产业,而其他服务业行业的增加值数据则全部合并至“其他行业增加值”指标内,因此本文参考夏杰长等(2019)的方法,首先分别计算未公布增加值行业的工资总额在“其他行业”工资总额中所占的比例,随后用这一比例分别乘以“其他行业增加值”,以推算出未公布增加值行业的增加值数据[25]。的影响效应,以探究数据要素对不同类型服务业生产率的影响是否具有异质性。估计结果如表7所示。
从表7可以看到,无论使用5折还是2折交叉拟合进行估计,数据要素影响生产性和生活性服务业生产率的效应均在1%的水平上显著为正,说明数据要素对这两类服务业的生产率均能发挥提升作用。进一步,从datSca系数值来看,生产性服务业中平均为06531,生活性服务业中平均为08234,表明数据要素对这两类服务业生产率提升的作用程度存在明显差异,相比于生产性服务业,数据要素更有助于生活性服务业生产率的提升。本文的解释是,随着相关数字技术的发展,在出行、住宿、餐饮等生活服务领域快速形成了各种数字平台比如滴滴出行、贝壳找房、携程、去哪儿、美团外卖等。,有关企业使用数据要素实现供需匹配的动力较强,在面对诸如消费者画像、服务品推荐等复杂的数据要素应用场景时,培养和引进了更多数据人才,投资了更多数据资本,导致生活性服务业内的企业在数据挖掘能力上具有较大优势,从而能更有效释放数据要素的潜在价值。
(二)东西、南北区域差异
在中国区域经济东西差距依然存在的情况下,南北差距也愈发明显,与此同时,各区域在服务业生产率水平、数字化程度、数据要素禀赋等方面也有所不同,可能导致数据要素对不同区域服务业生产率提升的效应存在差异。鉴于此,本文在基准估计模型(1)和模型(2)的基础上引入数据规模(datSca)与区域虚拟变量的交互项,以考察数据要素提升服务业生产率的区域异质性,模型设定如下:
serLabi,t=θ0datScai,t×region+g0Xi,t+Ui,t,EUi,tdatScai,t×region,Xi,t=0(11)
datScai,t×region=m0Xi,t+Vi,t,EVi,tXi,t=0(12)
其中,serLabi,t表示i省份在t年的服务业劳动生产率;region表示区域虚拟变量,包括东西(EW)、南北(NS)两个变量,属于东部和南方地区的省份定义为1,属于西部和北方地区的省份定义为0东部省份包括:安徽省、北京市、福建省、广东省、海南省、河北省、黑龙江省、吉林省、江苏省、江西省、辽宁省、山东省、上海市、天津市、浙江省,其余省份属于西部地区;以中国北纬35°线为界,南方省份包括:上海市、江苏省、浙江省、安徽省、福建省、江西省、湖北省、湖南省、广东省、广西省、海南省、重庆市、四川省、贵州省、云南省、西藏自治区,其余省份属于北方地区。。同时,为保证估计的一致性,将datScai,t和region归入协变量Xi,t中。估计结果如表8所示。
从表8可知,无论以5折还是2折交叉拟合进行估计,datSca×EW和datSca×NS的系数均在1%的水平上显著为正,说明相较于西部与北方地区,数据要素促进服务业生产率提升的效应在中国东部和南方地区更为明显。对此可能的解释是,东部与南方地区数据要素供给更充裕、流通更通畅、价值释放更充分,即数据要素市场化程度更高这一判断来自国家工业信息安全发展研究中心、北京大学光华管理学院等共同编写的《中国数据要素市场发展报告(2021—2022)》,该报告基于对数据要素市场化过程的分析,建立了“中国数据要素市场化指数”。各区域数据要素市场化指数分别为:南方地区,5816;北方地区,5140;东部地区,7000;西部地区,4545。,进而在数据要素的生成环境、采集渠道、质量水平、价值密度以及知识提炼等方面具有优势,不仅有助于服务业企业加快形成数据决策范式,也有助于数据密集型服务企业更好、更快发展,这无疑更有利于数据要素服务业生产率提升效应的发挥。
六、结论与政策建议
本文试图从理论和实证两个层面探究数据要素对服务业生产率的影响,通过理论分析厘清数据要素影响服务业生产率提升的内在机理,并基于2012—2019年中国省际面板数据,使用双重机器学习方法检验数据要素影响服务业生产率提升的效应、作用机制与异质性表现。实证结果表明:(1)数据要素显著促进中国服务业生产率提升,在使用双重机器学习的工具变量法以及经过一系列稳健性检验后这一结论仍然成立;(2)就作用机制而言,数据挖掘能力的提高显著增强了数据要素对服务业生产率提升的效应;(3)异质性分析还发现,数据要素对不同类型和区域服务业生产率提升的效应存在差异,相比于生产性服务业,数据要素更有助于生活性服务业生产率的提升;相较于西部与北方地区,数据要素促进服务业生产率提升的效应在中国东部和南方地区更为明显。基于上述研究结论,本文的政策建议如下:
第一,扩大数据要素规模,增加数据要素投入。在政策层面,首先,政府应着力提高数据要素市场化配置水平,加快健全数据产权、数据开放、数据安全等法律法规建设,重视数据要素交易和流通的体制机制建立,努力营造良好的、有助于数据要素良性发展的制度和市场环境。其次,政府应积极推进互联网+、物联网、人工智能、大数据等新一代信息技术的发展,以加速数据要素生成、加快数据要素采集。增加数据交易中心、区块链、云服务平台等数字基础设施投入,以加快破除阻碍数据要素流动的技术壁垒。鼓励创新服务业新业态、新服务、新模式,加强金融配套、完善监管制度,以加快构建丰富的数据要素应用场景。在企业层面,服务业企业应加大数据要素投入占比,转换生产率提升动能,进而加快形成数据决策范式,以提高经营管理决策效率,明晰未来发展方向,减少经营风险。另外,对于生产性服务业,政府应积极引导数据资源,数据挖掘人才、设备等集聚,加速数字化转型,同时积极鼓励交通运输(物流)、批发零售、金融等领域深化数字服务、平台等创新。
第二,加快提高数据挖掘能力,充分释放数据要素价值。首先,服务业企业需要加大对数据传感器、数据存储服务器、云计算设备、高速计算机等的投资,为数据要素的采集、存储、清洗和分析等提供硬件保障。其次,政府需要加快数据清洗、分析等人才的培养。由于短期内现行的教育体制无法完全满足企业对数据挖掘人才的旺盛需求,因此政府应牵头开展产学研合作,联合高校、企业和一切社会力量为相关人才的培养与引进提供平台。
第三,探索促进数据要素发展、提高数据挖掘能力的差异化政策。对于西部和北方省份,首先,各级政府应加强数据要素市场化建设,加快相关配套制度建立,以摆脱数据要素供给不足、流通不畅、价值释放不够的困境,并充分利用数据要素服务业生产率提升红利,缩小服务业发展的区域差距,进一步改善中国区域经济发展失衡现状;其次,国家在数据要素市场化配置上应给予西部和北方省份一定的政策倾斜,比如批准建立更多的数据存储或交易中心,使各级政府可以在数据要素市场的供给侧方面做好文章;最后,地方政府应尽力完善数据人才的引进与激励机制,努力做到人才在生活、医疗、子女教育等方面没有后顾之忧,以加快实现数据人才集聚。
参考文献:
[1] 谭洪波.新发展阶段服务业“走出去”:路径、挑战与对策[J].经济纵横,2023(3):60-68.
[2] Baumol W J. Macroeconomicsof Unbalanced Growth: The Anatomy of Urban Crisis[J].American Economic Review, 1967,57(3): 415-426.
[3] 郑江淮,宋建,张玉昌,等. 中国经济增长新旧动能转换的进展评估[J].中国工业经济, 2018(6): 24-42.
[4] 杨晨,原小能. 中国生产性服务业增长的动力源泉——基于动能解构视角的研究[J].财贸经济, 2019(5): 127-142.
[5] Peters B, Riley R, Siedschlag I,et al. Internationalisation, Innovation and Productivity in Services: Evidence from Germany, Ireland and the United Kingdom[J].Review of World Economics, 2018,154(3): 585-615.
[6] 江小涓. 网络空间服务业:效率、约束及发展前景——以体育和文化产业为例[J].经济研究, 2018(4): 4-17.
[7] 江小涓,罗立彬. 网络时代的服务全球化——新引擎、加速度和大国竞争力[J].中国社会科学,2019(2):68-91+205-206.
[8] 胡宗彪,周佳. 服务业全要素生产率再测度及其国际比较[J].数量经济技术经济研究,2020(8):103-122.
[9] 徐翔,赵墨非. 数据资本与经济增长路径[J].经济研究,2020(10): 38-54.
[10]Jones C I,Tonetti C. Nonrivalry and the Economics of Data[J].American Economic Review,2020,110(9): 2819-58.
[11]Müller O,Fay M,Brocke V J. TheEffect of Big Data and Analytics on Firm Performance: An Econometric Analysis Considering Industry Characteristics[J].Journal of Management Information Systems,2018,35(2): 488-509.
[12]张叶青,陆瑶,李乐芸. 大数据应用对中国企业市场价值的影响——来自中国上市公司年报文本分析的证据[J].经济研究,2021(12): 42-59.
[13]矫萍,田仁秀.数字技术创新赋能现代服务业与先进制造业深度融合的机制研[J].广东财经大学学报,2023,38(1): 31-44.
[14]李帅娜. 数字技术赋能服务业生产率:理论机制与经验证据[J].经济与管理研究,2021(10): 51-67.
[15]尚文思. 新基建对劳动生产率的影响研究——基于生产性服务业的视角[J].南开经济研究,2020(6): 181-200.
[16]Abis S,Veldkamp L. The Changing Economics of Knowledge Production[R].SSRN Working Paper,2021,No.3570130.
[17]王超贤,张伟东,颜蒙. 数据越多越好吗——对数据要素报酬性质的跨学科分析[J].中国工业经济,2022(7): 44-64.
[18]陈国青,任明,卫强,等. 数智赋能:信息系统研究的新跃迁[J].管理世界,2022(1): 180-196.
[19]陈国青,曾大军,卫强,等. 大数据环境下的决策范式转变与使能创新[J].管理世界,2020(2): 95-105.
[20]Tanaka M,Bloom N,David J M,et al. Firm Performance and Macro Forecast Accuracy[J].Journal of Monetary Economics,2020,114: 26-41.
[21]蔡跃洲,马文君. 数据要素对高质量发展影响与数据流动制约[J].数量经济技术经济研究,2021(3): 64-83.
[22]Carrière-Swallow Y,Haksar V. The Economics and Implications of Data: An Integrated Perspective[R].IMF Departmental Papers/Policy Papers,2019,18(12).
[23]Chernozhukov V,Chetverikov D,Demirer M,et al. Double/debiased Machine Learning for Treatment and Structural Parameters[J].Econometrics Journal,2018,21(1): C1-C68.
[24]徐翔,田晓轩,厉克奥博. 中国省际数据要素规模——基于就业人员工资与投资数据的测度与分析[R]. 数据要素市场化配置与分配制度改革论坛,2021.
[25]夏杰长,肖宇,李诗林. 中国服务业全要素生产率的再测算与影响因素分析[J].学术月刊,2019(2): 34-43+56.
[26]张涛,李均超. 网络基础设施、包容性绿色增长与地区差距——基于双重机器学习的因果推断[J].数量经济技术经济研究,2023(4): 113-135.
[27]施炳展,李建桐. 互联网是否促进了分工:来自中国制造业企业的证据[J].管理世界,2020(4): 130-149.
[28]钞小静,王宸威. 数据要素对制造业高质量发展的影响——来自制造业上市公司微观视角的经验证据[J].浙江工商大学学报,2022(4): 109-122.
[29]Nunn N,Qian N. US Food Aid and Civil Conflict[J].American Economic Review,2014,104(6): 1630-1666.
[30]杨艳,王理,李雨佳,等. 中国经济增长:数据要素的“双维驱动”[J].统计研究,2023(4): 3-18.
Data Factors,Data Mining,and Productivity Improvement of Chinese Service Industry
——Causal Inference from Double Machine Learning
YU Liuqinga,GAO Yua,b
(Northwest University,a.School of Economics & Management;b.China Western Economic
Development Study Center,Xi′an 710127,China)
Abstract: Chinas economy has entered a development stage dominated by the service industry,but the momentum of traditional factors to improve the productivity of the service industry is insufficient. In the era of digital economy,the emergence of data factors provides new possibilities for further improving service industry productivity. Based on Chinas inter provincial panel data from 2012 to 2019,this paper uses the double machine learning method to explore the effects,internal mechanisms and heterogeneous effects of data factors on the improvement of service industry productivity. The results show that data factors significantly promote the productivity improvement of Chinas service industry; The improvement of data mining ability significantly enhances the effects of data factors on the productivity improvement of the service industry; Data factors are more conducive to the improvement of productivity in the life service industry,and their impact on the improvement of productivity in the service industry in eastern and southern regions of China is more significant.
Key words:data factors; data mining;service industry productivity;double machine learning
(责任编辑:周正)
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中国交通信息化(2020年1期)2020-07-27 02:50:04
电力与能源(2017年6期)2017-05-14 06:19:37
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
信息通信技术(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
河南科技(2014年19期)2014-02-27 14:15:26
电子设计工程(2014年18期)2014-02-27 12:00:13
电子设计工程(2014年18期)2014-02-27 12:00:12
智能系统学报(2013年1期)2013-01-28 10:16:55
