
基于Sentinel-2 时序数据的新疆焉耆盆地农作物遥感识别与评估
2024-05-25 07:09张旭辉玉素甫江如素力仇忠丽亚夏尔艾斯克尔阿卜杜热合曼吾斯曼
干旱区地理(汉文版) 2024年4期
张旭辉, 玉素甫江·如素力,2, 仇忠丽亚夏尔·艾斯克尔, 阿卜杜热合曼·吾斯曼
(1.新疆师范大学地理科学与旅游学院流域信息集成与生态安全实验室,新疆 乌鲁木齐 830054;2.新疆干旱区湖泊环境与资源重点实验室,新疆 乌鲁木齐 830054)
农作物种植信息是进行农作物产业结构调整和优化的重要基础和前提[1]。焉耆盆地是新疆重要的特色农产品生产基地,为国家供应大量粮食,但粮食生产受到荒漠化、土壤盐碱化及干旱缺水等胁迫,作物种植结构复杂、生态环境脆弱[2]。因此,及时准确地掌握焉耆盆地农作物种植信息对促进干旱区农业可持续发展和保障国家粮食安全具有重要意义[3-4]。
遥感技术因其覆盖面大、探测速度快及成本低的特点,为及时准确地获取大面积农作物种植信息提供了新的技术手段[5-6]。目前,基于单一影像源提取农作物种植结构信息的方法操作简单,但不易捕捉作物种植“最佳识别期”影像[7];基于多时序影像源提取农作物种植信息的方法充分利用了作物季相节律特征,成为当下农作物种植信息提取的主流方法[3];在提取农作物信息时,多特征参数法更适用于复杂的农作物种植区,基于多特征参数的统计模型法在一定程度上解决了混合像元问题[8];遥感影像与统计数据融合法可获得大尺度农作物结构种植图,但因较低的制图分辨率使得产品区域适宜性较差[9-10]。在机器学习方法中支持向量机算法泛化能力强,且有较好的鲁棒性,在遥感信息提取上被广泛应用[11-12]。梁继等[6]、贾银江等[13]和梁习卉子等[14]使用SVM 算法及其改进后的分类器对区域农作物信息进行获取,取得较好的分类效果(分类精度均高于90%)。边增淦等[15]、田鑫等[16]和郭其乐等[17]研究指出,使用机器学习方法进行遥感信息提取时加入光谱特征、纹理特征及物候特征可以提高农作物分类的精度。随着遥感大数据时代的到来,遥感云平台为快速处理和分析海量遥感数据提供了机遇[18]。刘通等[19]、潘力等[20]和姜伊兰等[21]借助GEE平台分别对辽宁盘锦市、淮河流域和开封市杞县的农作物种植信息进行提取,研究结果为当地农作物信息提取和监测提供了参考依据。可是当下GEE平台国内用户不便正常使用,且使用过程和处理结果的下载,受网络条件的影响很大[22]。国产遥感云平台PIE-Engine Studio 为共享数据、算法和计算资源构建了一个开放的环境,以实现对遥感数据的按需访问和海量数据的快速处理[22]。然而目前使用PIE-Engine Studio 云计算平台结合机器学习方法应用于干旱区农作物识别的研究还相对较少,对于该平台在干旱区农作物识别的适用性还待进一步研究,且基于该平台的时间序列Sentinel-2农作物识别的研究还鲜有涉及,Sentinel-2数据的高时间分辨率在农作物分类识别中的优势还需进一步明确。
文章以新疆焉耆盆地为研究区,利用PIE-Engine Studio 平台,基于Sentinel-2时序数据和野外定位采样数据,使用支持向量机算法对2022年焉耆盆地的农作物种植信息进行提取和精度评估,以期获取最佳的农作物信息提取方案,为干旱区农作物种植信息的快速、精确提取提供新的思路和参考依据。
1 材料与方法
1.1 研究区概况
焉耆盆地位于新疆巴音郭楞蒙古自治州境内(85°45′25″~87°26′11″E,41°40′11″~42°25′46″N),塔里木盆地的东北侧,面积约为7500 km2,地势西北高东南低,地理区域包含焉耆回族自治县、和静县、和硕县、博湖县及新疆生产建设兵团部分团场(图1)。该地区四季分明,光照时间充足,昼夜温差大,水热资源丰富,属典型的干旱区绿洲气候。农作物类型有番茄、辣椒、玉米、小麦、甜菜和棉花等,种植结构较为复杂,其中研究区盛产番茄和辣椒,是新疆重要的特色农产品生产基地。
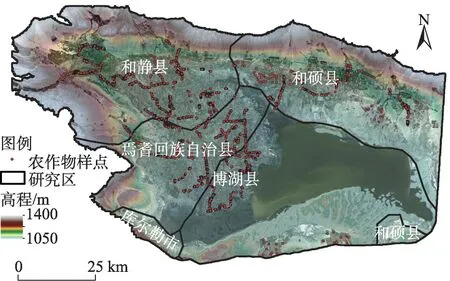
图1 研究区地理位置及作物样本点分布Fig.1 Geographical location of the study area and distribution of crop sample points
1.2 数据来源
1.2.1 Sentinel-2 数据集本文使用的Level-2A 级Sentinel-2 多光谱影像数据集源自欧洲航天局数据中心,该数据由Sentinel-2A 和Sentinel-2B 组成,具有空间分辨率高、重访周期短、光谱波段通道数目多以及波段宽度窄等特点[23]。为方便研究不同农作物生育期影像变化,研究在PIE 平台中选择2022年3—11 月的遥感影像,云量覆盖百分比在10%以下,共9幅(表1)。

表1 研究区Sentinel-2影像数据Tab.1 Sentinel-2 image data for the study area
1.2.2 样本数据研究团队于2022 年7 月26 日至2022年8月4日前往焉耆盆地对农作物种植情况进行调查,采用拍照和GPS 定位的方式,获取1948 个典型地物样点,其中农作物包括5 种经济作物(甘草、葵花、芦苇、棉花和葡萄)、3 种粮食作物(水稻、小麦和玉米)、3种蔬菜(番茄、辣椒、甜菜)和果树作物(果林)。在采样过程中使用GPS 定位作物样点的经纬度和海拔,并且对地物的周边生长环境及灌溉方式进行记录,方便观察不同农作物的分布特征和生长环境。在分类过程中将样点随机分割成训练样本和检验样本,得到5种样点分割方案,即5:5、6:4、7:3、8:2和9:1(表2)。
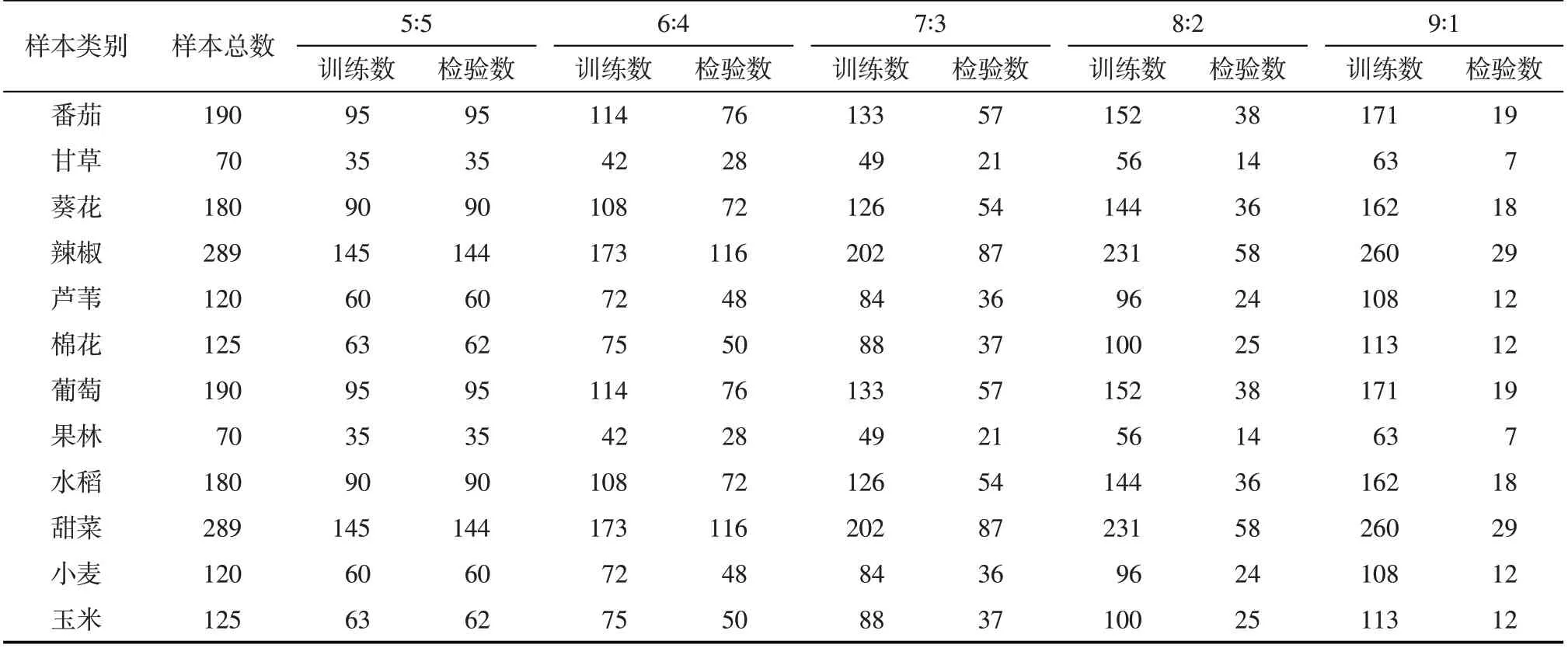
表2 研究区地物样本统计表Tab.2 Statistics of feature samples in the study area
1.3 研究方法
1.3.1 分类特征构建
(1)Sentinel-2光谱波段
Sentinel-2数据共有13 个波段,研究选择其中用于土地类型检测、陆表检测、植被监测和环境检测的波段,共10 个,分别是B2、B3、B4、B5、B6、B7、B8、B8a、B11和B12[23]。
(2)植被指数构建
植被指数因其经过比值处理,可以部分消除因太阳高度角、卫星观测角、地形、大气程辐射等所带来的影响,被广泛用于农作物分类与识别、长势监测与产量估算等方面。研究利用Sentinel-2的波段构建多种植被指数(表3)。

表3 植被指数计算公式Tab.3 Vegetation index calculation formula
1.3.2 特征参数优选方法构建较多的特征参数在一定程度上提高农作物识别精度,但过多的特征参数往往会出现信息冗余现象,影响分类模型的效率和精度[17]。研究采用以下特征参数优选方法:(1)See5.0 决策树算法根据提供最大信息增益的字段对样本数据进行分割,并对决策树的叶子进行裁剪或合并以提高分类精度,最后确定每个叶子的最佳阈值,从而得到每个特征参数的重要性得分[24]。(2)随机森林(Random forest,RF)方法通过对对象和变量进行采样来构建预测模型,即生成多个决策树并依次对对象进行分类,最后将每个决策树的分类结果汇总,所有预测类别的复数就是随机森林预测的对象类别,分类精度得到提高,同时也计算了参与分类的不同特征的重要性[25]。(3)多元回归(Multiple regression,MR)模型指含有多个解释变量的线性回归模型,用于解释被解释的变量与其他多个变量解释变量之间的线性关系[26]。
1.3.3 分类方法与分类方案支持向量机(Support vector machines,SVM)算法是基于统计学习的机器学习方法,该算法利用结构风险最小化原理,在确保误差最小的情况下,通过降低模型泛化误差的上限来提高分类模型的泛化能力[27],SVM算法的径向基核函数可将训练样本映射到高维空间,从而便于进行多特征参数的农作物分类。本文基于Sentinel-2 时序数据构建特征参数,借助R 语言优选特征参数,最后使用SVM 算法构建5 种分类方案进行农作物信息提取(表4)。

表4 农作物分类方案Tab.4 Crop classification schemes
1.3.4 精度评价使用目视解译和混淆矩阵对分类结果进行精度评价,采用以下评价指标评估模型的精度,总体精度(Overall accuracy,OA)、Kappa系数、用户精度(User’s accuracy,UA)、制图精度(Producer’s accuracy,PA)、F1 分数(F1 score)、错分误差(Commission error,CE)和漏分误差(Omission error,OE)。计算公式如下:
式中:n为类别数量;N为验证样本总数;Pii为每类中正确分类样本的数量,是i行i列上的值;Pi+为分类器将验证样本分为某一类别的总数;P+i为某一类别验证样本总数。
2 结果与分析
2.1 农作物植被指数时序特征
基于Sentinel-2 时序数据计算植被指数,得到研究区农作物植被指数时序变化曲线(图2)。由图2 可知,不同农作物因各自生物学差异在各植被指数中呈现不同的曲线波动趋势。由图2a可知,研究区农作物NDVI 值总体呈先上升后下降的变化趋势,其中小麦和甜菜的NDVI 值与其他农作物差异显著,容易区分;引入红边波段后,各农作物的NDVI值在7、8、9月差异较为明显(图2b~d),其中小麦的NDVI 值在5 月达到峰值,与其他农作物差异明显,容易区分;甜菜的NDVI 值在10 月达到峰值,与其他农作物相差较大,容易区分;与NDVI 值相比,不同农作物的NDVI705、NDVI740和NDVI783曲线分离较好,不同农作物的物候特征更直观、更清晰,这是因为红边是绿色植被反射光谱在680~780 nm 之间的最大斜率点,因此更能反映农作物的微小变化。由图2m 可知,水稻的EVI 曲线在8 月达到峰值,与其他农作物相比差异明显;由图2n~o 可知,棉花的RNDVI 和SRI 曲线在7 月达到峰值,与其他农作物相比差异明显。除NDWI(图2e)外,其他农作物植被指数(图2f~o)呈现先增加后减少趋势,由于植被指数与农作物本身的特性有关,不同农作物的物候差异导致植被指数在增加、减少和峰值出现的时间等方面有差异。
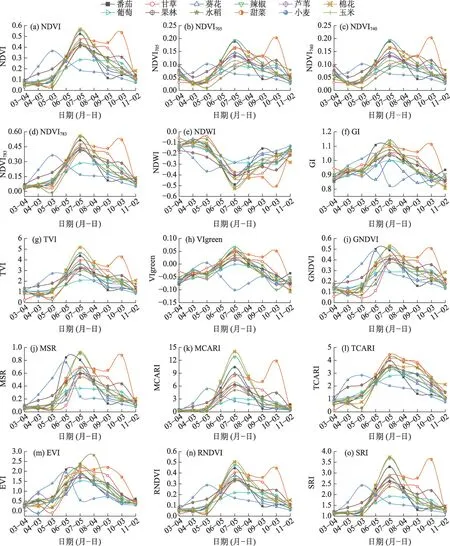
图2 植被指数时序曲线图Fig.2 Time-serie graphs of vegetation index
2.2 特征参数重要性评价
研究利用See5.0、RF 和MR 方法得到特征参数的重要性评价结果(图3)。由图3可知,3种方法得到的特征参数重要性排序均不相同。See5.0 和RF方法的结果中Sentinel-2近红外波段(B8)的重要性得分最高,说明近红外波段对农作物分类结果的贡献最大,对分类精度影响颇深。对比3 种重要性结果发现,排名前10 的特征参数中均有NDVI 或红边NDVI,说明NDVI 或者红边NDVI 可以很好地反映出不同农作物的生长状态和覆盖度,对农作物分类结果贡献较大。因此根据特征参数重要性评价结果选取3个特征参数集:
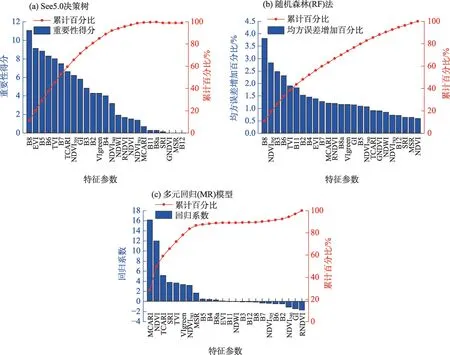
图3 特征参数重要性评价Fig.3 Importance evaluation of feature parameters
(1)See5.0 算法的特征重要性得分和累计百分比(图3a),获取重要性得分大于0的特征参数,符合条件的有B8、EVI、B5、B6、TVI、B7、TCARI、NDVI705、GI、B3、B2、VIgreen、B4、NDVI740、NDWI、RNDVI、NDVI、NDVI783、MCARI、B11、B8a和SRI,共22个。
(2)RF的特征参数重要性评价(图3b),选取累计百分比大于90%的特征参数,符合条件的有B8、NDVI705、B3、B6、TVI、B11、B2、B4、EVI、B7、MCARI、RNDVI、B8a、VIgreen、GI、B5、NDVI740、TCARI、GNDVI和NDWI,共20个。
(3)MR模型的特征参数重要性评价(图3c),选取回归系数大于0的特征参数,符合条件的有MCARI、NDVI、TCARI、SRI、TVI、VIgreen、NDVI783、MSR、B5、B4、B8a和EVI,共12个。
2.3 精度评价
研究对25种分类结果进行精度验证与对比,结果见图4:(1)所有农作物分类模型的OA 均大于92.20%,Kappa 系数均大于0.9037,说明在PIE 平台中使用SVM 算法开展干旱区农作物遥感分类研究是可行的。(2)对比SVM-无红边和SVM-有红边的结果发现,加入红边波段后,农作物的OA 和Kappa系数均有所上升,SVM-有红边分类模型的各样方分割方案OA均大于93.00%,Kappa系数均大于0.9100,由此可见在农作物遥感分类时加入红边波段可以提高分类精度。(3)相较于SVM-有红边,SVM-RF、SVM-MR和SVM-See5.0方法在加入植被指数后,OA均值提高了4.18%、3.82%和3.62%,Kappa系数提高了0.0519、0.0473 和0.0446。(4)对比不同分类模型的均值发现,不同分类模型OA和Kappa的大小关系为:SVM-RF>SVM-MR>SVM-See5.0>SVM-有红边>SVM-无红边,说明SVM-RF分类模型的分类效果最好,相较于其他分类模型更适合在焉耆盆地开展农作物分类研究。
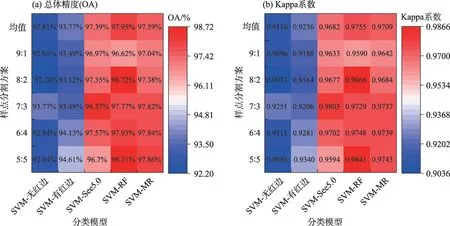
图4 不同分类模型总体精度和Kappa系数的热图Fig.4 Heat map of overall accuracy and Kappa coefficient for different classification models
2.4 分类结果对比
选取每种分类模型与样方分割方案的最佳组合进行对比分析(图5)。由图5可知,5种最佳分类组合的OA关系为:SVM-RF(8:2)>SVM-See5.0(7:3)>SVM-MR(5:5)>SVM-有红边(5:5)>SVM-无红边(7:3),5 种最佳分类组合中分类效果最好的是SVM-RF 分类模型在样方分割为8:2时取得的分类结果,其OA和Kappa 系数最高,分别是98.72%和0.9866,表明SVM-RF(8:2)分类组合与地面实际情况具有较好的一致性;对比5 种最佳分类组合的PA 和UA 精度发现,SVM-RF(8:2)的PA和UA最高,分别比SVM-MR(5:5)、SVM-See5.0(7:3)、SVM-有红边(5:5)和SVM-无红边(7:3)的PA和UA高出0.21%和0.68%、0.09%和0.76%、1.60%和7.21%、4.68%和9.88%,表明SVM-MR(5:5)分类图中的结果与地面真实情况较为相符;F1 score 的关系为SVM-RF(8:2)>SVM-See5.0(7:3)>SVM-MR(5:5)>SVM-有红边(5:5)>SVM-无红边(7:3),说明SVM-RF(8:2)分类模型精确度较其他分类模型高。OE 和CE 的关系均为SVM-无红边(7:3)>SVM-有红边(5:5)>SVM-MR(5:5)>SVM-See5.0(7:3)>SVM-RF(8:2),表明SVM-无红边(7:3)的“错分”和“漏分”现象较多,SVM-RF(8:2)的“错分”和“漏分”现象较少。综上,SVM-RF(8:2)分类模型的分类结果在OA、Kappa 系数、PA、UA、F1 score、CE和OE 等方面表现最好,其分类效果优于其他分类模型。

图5 5种最佳分类模型评价指标的雷达图Fig.5 Radar plot of evaluation indicators for the 5 best classification models
研究借助PIE 平台对5种最佳分类模型的分类结果进行制图,研究区作物空间分布如图6 所示。对比图6c~e 可见,3 种分类模型的分类结果与当地实际数据吻合度较高。焉耆盆地农作物以辣椒、玉米、小麦和葡萄为主,种植面积分别约为1166.98 km2、430.32 km2、344.23 km2和205.79 km2,分别约占研究区耕地面积的43.58%、16.07%、12.85%和7.68%。整体上,焉耆盆地工业辣椒的种植面积最广,主要分布在焉耆回族自治县和博湖县;玉米、小麦和葡萄主要种植在和硕县;甜菜主要种植在和静县,水稻和果林主要种植在博湖县;兵团地区农作物种植分布较为集中,主要种植经济作物(工业辣椒和工业番茄)。综上,焉耆盆地主要农作物集中分布在土壤肥沃且灌溉设施较为完善的地区,种植面积较大且在研究区内连续分布,其他农作物种植较少且呈镶嵌式分布在研究区。
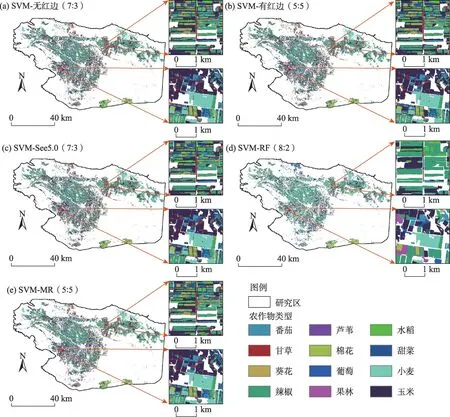
图6 5种分类模型的农作物分类结果Fig.6 Crop classification results for the five classification models
3 讨论
本文借助PIE-Engine Studio 平台,使用支持向量机算法,调用Sentinel-2时序数据,构建农作物时序植被指数,分割训练样本和检验样本,实现了对焉耆盆地农作物种植信息的提取与评估。PIE平台免费向公众开放,可以实时调用平台中存储的Sentinel-2 遥感影像,在强大的云计算服务支持下,降低了遥感数据获取的门槛和计算成本,可满足不同尺度的研究需求[22]。研究结果在一定程度上解决了因干旱区生态环境脆弱、种植结构复杂且地块破碎、农作物生长周期相近及光谱差异小等原因产生的分类精度较低的问题,为利用国产云平台实现干旱区农作物种植信息的快速、精确提取提供了新的思路和参考依据。
3.1 引入红边特征对分类精度的影响
从特征重要性结果可以看出,排名前十的特征参数中均有红边特征参数,表明红边特征参数在农作物分类识别领域具有明显优势,对于农作物生长状态和健康状况的判断具有重要的指导作用。研究中红边特征参数的引入使得SVM-有红边分类模型的OA和Kappa系数均值分别比SVM-无红边提高了0.96%和0.012。因此,在特征重要性分析中,排名前十的特征参数中出现红边特征参数是合理的,并且可以说明红边特征参数在农作物分类识别中的重要性。黄双燕等[28]和牛乾坤等[29]研究表明,在农作物遥感分类中引入红边光谱和红边指数,使机器学习分类器的OA得到提高,并使春、冬小麦的识别效果得到明显提升,表明红边光谱特征对分类精度起着决定性作用,河套灌区平均OA 达到81%,Kappa 系数达到0.68。综上,红边特征参数可以帮助分类器更灵敏地捕捉到不同农作物特有的生长特征和物候学差异从而提高分类模型的精度。
3.2 引入植被指数对分类精度的影响
研究中农作物植被指数的引入使得SVMSee5.0、SVM-RF 和SVM-MR 分类模型的OA 均值比SVM-有红边分别提高了3.62%、4.18%和3.82%,Kappa系数均值分别提高了0.0446、0.0519和0.0473,说明植被指数在农作物分类中具有有效性和重要性,能够捕捉到农作物的生长特征并帮助区分不同农作物的类别。姜伊兰等[21]研究指出利用NDVI时序差异指数提取的农作物OA 和Kappa 系数比最大似然法和支持向量机法分别提高10.02%、0.21 和4.18%和0.09;谷祥辉等[30]研究表明时间序列组合植被指数用于农作物分类是可行的,分类模型的精度和Kappa系数分别达到88.52%和0.8650;综上,多种植被指数结合时间序列信息可以从生长时期和生长状态上区分农作物,从而提高农作物识别的准确性。
研究使用了3种特征优选方法获得特征参数的重要性排序,排名前十的特征参数均含有红边波段或红边指数,表明红边波段和红边指数在农作物分类中发挥着重要作用。因此,在后续研究中将考虑更多与红边波段有关的植被指数,选取其中重要性较高的植被指数,提高作物分类精度。研究也存有不足,作物分类结果中部分农田存在“错分”和“漏分”现象,后续需通过人工干预和增加分类特征来减少“错分”和“漏分”现象的发生;另外,本次研究影像数据较为单一,后续考虑将Sentinel-2 影像与其他遥感影像进行融合[31-32],充分挖掘地物的光谱特征、纹理特征和物候特征,进一步提高农作物识别精度。
4 结论
(1)使用PIE 平台可快速地访问海量遥感图像及其他数据资源,因其高性能的云计算能力可快速完成覆盖焉耆盆地影像数据的去云、裁剪及植被指数构建等处理。基于多时间序列影像源与PIE相结合可方便快捷地进行作物种植信息提取,较本地处理具有明显优势。
(2)25 种分类模型的OA 和Kappa 系数均在92.20%和0.9037 以上,其中SVM-RF 方法在样方分割为8:2 时,OA 和Kappa 系数最高,分别为98.72%和0.9866,说明在PIE 中使用SVM 算法提取作物信息是可行的。
(3)5 种SVM 算法分类组合的OA 均值关系为SVM-RF(97.95%)>SVM-MR(97.59%)>SVM-See5.0(97.39%)>SVM-有红边(93.77%)>SVM-无红边(92.81%),Kappa系数均值关系为SVM-RF(0.9755)>SVM-MR(0.9709)>SVM-See5.0(0.9682)>SVM-有红边(0.9236)>SVM-无红边(0.9116),其中SVM-RF、SVM-See5.0 和SVM-MR 方法中加入了红边波段和植被指数,提高了作物识别的精度。
(4)焉耆盆地农作物以辣椒、玉米、小麦和葡萄为主,种植面积分别约为1166.98 km2、430.32 km2、344.23 km2和205.79 km2,分别约占研究区耕地面积的43.58%、16.07%、12.85%和7.68%,集中分布在土壤肥沃且灌溉设施较为完善的地区,种植面积较大且在研究区内连续分布,其他农作物种植较少,呈现镶嵌式分布。
猜你喜欢
军事文摘(2024年6期)2024-02-29
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
水土保持研究(2018年5期)2018-10-12
中国农业信息(2018年2期)2018-07-28
制造技术与机床(2017年11期)2017-12-18
西藏科技(2015年1期)2015-09-26
