
共享智慧,解读心愿:公共图书馆用户检索意图库构建关键技术与应用探析
2024-05-24 08:42张宁
四川图书馆学报 2024年3期


收稿日期:2023-07-14
摘 要:
随着数字化时代的到来,传统的关键词匹配检索方式已经无法满足用户个性化的信息需求。因此,构建用户检索意图库成为了解决这一问题的关键。通过收集和分析用户查询数据和目标数据,分析提取用户意图特征,并作为构建用户检索意图库的基本要素,利用自然语言处理技术理解和识别用户检索意图,同时探析了用户检索意图构建过程中的三大关键技术,探讨了用户检索意图库在公共图书馆中的应用。
关键词:
公共图书馆;用户检索意图库;自然语言处理;特征提取
中图分类号:G258.2 文献标识码:A 文章编号:1003-7136(2024)03-0054-09
Sharing Wisdom,Unveiling Desires:Analysis of the Key Technology and Application of the Construction of User Retrieval Intention Library in Public Libraries
ZHANG Ning
Abstract:
With the advent of the digital age,the traditional keyword matching retrieval method has been unable to meet the user′s personalized information needs.Therefore,the construction of user retrieval intention library has become the key to solve this problem.By collecting and analyzing the user query data and target data,the user intention features are analyzed and extracted,as the basic elements of constructing the user retrieval intention library,as well as the natural language processing technology is used to understand and identify the user retrieval intention.This paper analyzes the three key technologies in the process of user retrieval intention construction,and discusses the application of users retrieval intention library in public libraries.
Keywords:
public library;user retrieval intention library;natural language processing;feature extraction
0 引言
在當今信息爆炸的时代,公共图书馆作为知识共享的重要场所,承担着为用户提供丰富、准确信息的责任和使命[1]。然而,随着用户需求的多样化,传统的图书馆检索系统往往无法准确理解用户的真实信息需求。因此,如何准确地理解和识别用户检索意图,解决公共图书馆用户的信息检索问题已经成为迫切需要解决的问题。
在这种背景下,借鉴其他行业目前已经比较成熟的方法,构建用户检索意图库成为一种比较有效的解决方案。在深入分析用户的检索行为、理解用户的搜索意图和需求的基础上,公共图书馆可以利用自身优势提供个性化、精准的信息推荐和导航服务,从而提升用户的信息获取率和利用效率。然而,与此相关的问题也随之而来:如何准确地捕捉和解读用户的检索意图?如何构建一个有效的检索意图库?如何将检索意图库应用到公共图书馆的信息检索系统中?这些问题都需要我们进行深入的研究和探索。
本文旨在回答上述问题,提出共享智慧、解读用户心愿的解决方案,以构建和应用公共图书馆的检索意图库。利用机器学习、自然语言处理和数据挖掘等相关技术,结合图书馆领域的实际需求,研究如何从用户的搜索关键词、浏览下载的资源中提取有用信息,从而识别用户的检索意图,并以此为基础,构建一个具有丰富语义信息的公共图书馆检索意图库,从而更准确地理解用户的真实需求,为用户提供个性化、精准的信息服务。
1 研究综述
1.1 用户检索意图库及意义
所谓用户检索意图库,从数据层面上来说,其实质就是指一个预先构建好的、包含了用户常见检索意图的数据库;从系统层面上来说,它就是一个集合了常见用户意图的库或分类系统。它包含了用户在与系统进行交互时可能表达的各种意图,如获取信息、执行操作、提出问题等。对于公共图书馆来说,用户检索意图库主要根据用户的检索信息,通过自然语言识别的方式从中抽取用户的检索主题和检索目的,以及检索需求中所包含的时间范围、地域范围和目标人物等。
无论是从公共图书馆角度还是从用户角度,建立用户检索意图库都是一件具有重要意义的工作。从公共图书馆的角度来说,建立公共图书馆用户检索意图库,可以帮助图书馆或其他信息机构更准确地理解用户的检索需求,从而提供更精确的检索结果;从用户角度来说,用户的查询可能涉及不同的主题、领域和意图,通过建立一个用户检索意图库,可以收集和整理常见的用户查询意图,并为每个意图提供相应的处理逻辑和响应策略。此外,用户检索意图库也具有极为重要的应用意义,具体包括:
①提升用户体验。公共图书馆是广大读者获取信息和阅读资源的重要场所。建立用户检索意图库可以帮助图书馆系统更准确地理解读者的查询意图,从而能够更快速、精准地提供符合读者需求的资源和服务,提升用户的检索体验。
②提高搜索效果。通过建立用户检索意图库,公共图书馆可以建立丰富的查询意图和相关资源的映射关系。当读者进行查询时,系统可以根据意图库中的信息迅速匹配合适的资源,从而提高搜索结果的质量和相关性。
③个性化服务。通过分析和理解读者的查询意图,公共图书馆可以提供更加个性化的服务。根据读者的喜好、需求和查询意图,图书馆系统可以推荐相关的图书、文章、活动或其他资源,更好地满足读者的阅读需求。
④指导读者。用户检索意图库还可以帮助图书馆系统提供更准确的查询建议和指导。当读者输入查询时,系统可以根据意图库中的信息给出相关的建议或指导,帮助读者更好地组织查询、选择合适的资源或深入探索特定领域。
⑤数据分析与优化。通过对用户检索意图库的使用情况进行分析,公共图书馆可以获取有关读者检索习惯、偏好和需求的宝贵信息。这些数据可以用于图书馆的服务优化、资源采购决策和用户行为分析,进一步提升图书馆的运营效率和服务质量。
1.2 研究进展
用户检索意图是信息检索领域的重要研究方向,指用户在检索信息时,所表达的需求和目的[2],即通过对用户检索意图的识别和理解,帮助用户缩小检索范围,明确检索目的。早期的用户检索意图研究主要基于关键词检索,通过对用户检索关键词的分析,研究用户的检索意图,包括基于关键词集合进行共现分析[3],利用聚类算法对检索词进行聚类分析等[4]。随着信息检索技术的不断发展,研究者开始采用自然语言处理技术和机器学习技术,从文本中提取和分析用户的检索意图。如今,随着大数据技术和人工智能技术的应用,用户检索意图的研究进入了一个新的阶段。目前,用户检索意图的研究和应用主要集中在以下几个方向。
(1)检索意图分类。研究者致力于开发算法和模型,将用户的查询意图进行分类和归纳。常见的方法包括基于标签分类[5-6]、机器学习和深度学习的分类算法[7],通过训练模型从用户查询中识别出不同的检索意图,如信息获取、问题解答、产品比较等。
(2)检索意图理解。研究者关注如何更好地理解用户的检索意图。这涉及自然语言处理、语义理解[8]、语义表示、知识图谱[9]和情感分析[10]等技术。通过构建语义模型和语义表示方法,系统可以更好地理解用户的查询意图,进而提供更加准确和相关的搜索结果。
(3)个性化检索意图。研究者探索如何根据用户的个性化需求和偏好定制检索意图模型。这包括用户模型的构建[11]、个性化推荐和查询扩展等技术。通过分析用户的兴趣[12]、上下文和历史行为[13],系统可以更好地适应用户的个性化需求,提供个性化的检索意图服务。
(4)多模态检索意图。随着多模态数据的广泛应用,研究者开始关注多模态检索意图的研究。这包括文本、图像、语音和视频等多种模态信息的融合和理解[14-15]。通过融合不同模态的信息,系统可以更全面地理解用户的检索意图,提供更丰富和准确的搜索结果。
总体而言,用户检索意图研究在算法、模型和应用方面都取得了一定的进展。通过深入研究用户检索意图,能够更好地理解用户需求,提供个性化、精准和高效的信息检索服务,从而提升用户的搜索体验满意度。随着技术的不断进步和应用场景的拓展,用户检索意图研究仍然是一个具有挑战和潜力的领域。
2 需求场景与技术路线
构建公共图书馆用户检索意图库,其目的在于完整地捕捉用户自然语言中所蕴含的检索意图,使图书馆现有的检索系统能够更加智能化地理解用户的检索意图和需求。从整体上来说,包括检索需求分析及构建场景、设计技术路线两个部分。
2.1 检索需求场景分析
本文从用户视角出发,设计了以用户检索内容为特征的场景树,如图1所示。以查询语句“我想看一本近5年以来美国哈佛大学推荐的如何高效地提取文本信息的关于自然语言处理的书”为例,其检索语句中包含了主题、行为意图、时间、地域、机构等多种信息要素,并通过“关于”“推荐”等显式谓词或隐含关系指示实体与数据属性之间的从属、并列等关系。在智慧图书馆条件下,公共图书馆的搜索引擎需要支持此类自然语言的响应,能够分析和识别出用户期望的需求和给定的各种限定条件,并返回正确的检索结果。
公共图书馆用户检索意图库设计要充分结合用户的实际检索需求和落地的可行性,需要遵循以下几个基本原则。
(1)全面性。意图库应该覆盖用户可能的多样化检索意图。收集和整理不同类型、不同领域的检索意图样本,包括常见的查询目的、问题类型、需求表达方式等。
(2)智能性。利用机器学习和自动化技术对用户检索意图进行建模和识别。通过训练算法和模型,让系统能够自动学习和识别用户的意图,减少人工标注的工作量,提高效率和准确性。
(3)可扩展性。意图库的设计应具备可扩展性,以便随着用户需求的变化和增长不斷更新和扩展。新的检索意图样本可以根据用户反馈、数据分析结果和领域知识变化进行持续补充和更新。
(4)组织性。意图库应该有良好的组织结构,便于快速准确地匹配用户的检索意图。可以根据意图的主题、目的、领域等属性对样本进行分类和标注,方便后续的意图匹配和处理。
(5)实时性。意图库需要保持实时更新,及时反映用户的新兴检索需求和趋势。随着时间的推移,一些检索意图可能会变得不再流行或过时,因此需要定期审查和更新意图库中的样本。
2.2 总体技术方案设计
在明确需求场景和设计原则后,本文提出相应的技术方案,从总体上来说,总共分为四大步骤,具体如图2所示。
(1)数据采集与处理。收集用户的查询数据和相关上下文信息,如搜索日志、用户反馈等。对收集到的数据进行预处理,将清洗、去噪之后的数据制作成标准格式统一组合和存储,以提高后续处理的质量和准确性。
(2)特征提取与表示。特征提取是机器学习和数据分析中的关键概念,指从原始数据中选择和提取最相关、最具有代表性的特征,以捕捉数据的重要信息[16],其目标是减少数据的维度,同时保留尽可能多的有用信息,以便于后续的模型训练和分析。在表示方式上,特征表示是将提取到的特征以一种可操作的方式呈现出来,便于机器学习算法的处理和分析,即需要将自然语言转化为计算机可以理解的文本表示方法[17]。从用户的角度考虑,提取最能表达用户意愿的信息作为本文特征能够更加准确地理解和识别检索意图,缩小检索范围,如主题信息、行为信息、时间信息等。
(3)意图匹配与识别。利用机器学习或深度学习的方法,建立意图匹配模型或分类模型,对用户查询进行意图匹配和识别。可以使用传统的机器学习算法如支持向量机、决策树等,或者使用深度学习算法如循环神经网络、卷积神经网络等。训练模型时,可以使用已标注的数据集进行监督学习,也可以利用无监督学习或半监督学习的方法。由于用户检索意图是大量无标记的数据,比较适用于采用无监督的分类方案对数据进行聚类,因此本文将采用无监督分类的方法对数据进行聚类。(4)意图库构建与维护。根据用户查询数据和已有的标注数据,在特征提取的基础上,构建用户检索意图库,提取的特征包括主题词、行为意图、情感、时间信息、地域信息、人物信息、机构名称、其他专名、作者等信息,并将这些信息以标准数据的形式进行表达和存储,作为检索意图的统一描述,能够满足检索引擎在开发时所面对的功能需求,形成可复用的框架产出[18]。此外,定期维护意图库,更新和扩充其中的意图样本,从而保持其准确性和覆盖范围。
3 流程构建与关键技术
在明确了公共图书馆用户检索意图库的总体设计与实现思路后,本节重点关注用户检索意图库实现流程及所需的关键技术,就其目标与任务等进行阐述,并探讨原型系统的设计与构建。
按照总体技术方案设计,本文将公共图书馆用户检索意图库的构建工作流程分为三个主要部分。
3.1 文本处理与特征提取
文本处理和特征提取是自然语言处理中的重要技术,主要是指在对文本数据进行清洗、分词、词性标注、句法分析、实体识别和文本分类等操作[19]的基础上,按照实际的需求提取能够反映文本主要内容特征的词项,并附有权重,包括文本特征选择和特征权重计算两个主要环节[20]。在特征提取内容上,特征提取分为句法分析特征、文本语义特征、文本结构特征和文本分类特征等。在公共图书馆日常的用户信息检索中,常常会使用查询语句来表达自己的信息需求[21],因此在实际对用户检索意图进行识别和理解之前,需要对其进行检索信息处理和文本特征提取,并且从检索信息中提取有用的信息。
通过对国家图书馆用户检索数据
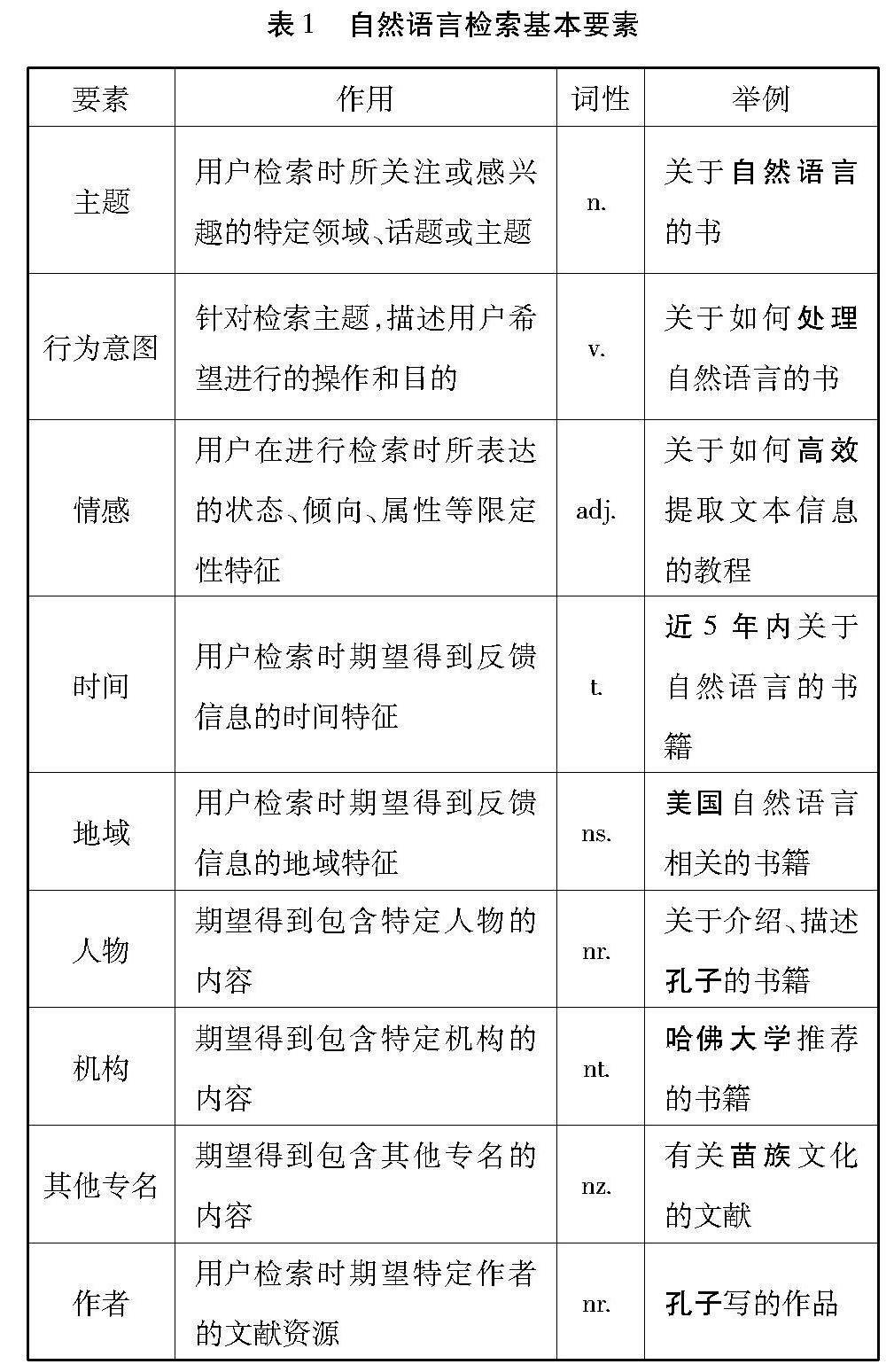
检索数据来源于国家图书馆文津搜索系统。进行分析,发现用户常用的检索语句中一般会包括检索主题、检索行为意图、情感、时间范围、地域范围、人物、机构和其他专名等要素,其中大约有70%的检索信息为检索主题和行为意图[22],词性多为名词和动词,其余要素多数以定状补的形式出现,词性以形容词为主,少数为时间词、地点词或专有名词,具体如表1所示。因此,在建立公共图书馆用户检索意图库时,需要将这些关键信息作为文本语义特征进行提取,作为用户检索意图库的基本信息要素。当然,随着对建立用户检索意图库需求和文本处理能力的不断提高,基本信息要素也会随之不断地修改和完善,这里仅以表1列出的文本特征作为本文用户检索意图库建设的基本信息要素。
3.2 检索意图理解与识别
检索意图理解与识别是自然语言处理和信息检索领域的关键任务和热点之一[23],指对用户输入的搜索查询或问题进行分析和理解,以确定用户的搜索意图或需求,同时按照一定的标准或规则进行分类和组织,以方便用户进行有效的信息检索和浏览[24],本文所考虑的检索意图理解与识别主要包括实体识别、分词权重和依存关系分析三个方面。
实体识别是自然语言处理中的一項任务,旨在从文本中识别和提取具有特定意义的命名实体,在本文中,实体识别主要的识别内容为用户检索的基本特征要素,即检索主题、检索行为意图、情感、时间范围、地域范围、人物、机构和其他专名等,利用分词工具进行分词、词性标注、关键词提取等处理,根据处理和识别结果抽取主要信息。
分词权重是指对文本中的每个词语进行权重计算或赋值的过程,在智能检索系统中,语义分词的权重会对语义检索产生影响[25],通过计算关键词的权重,可以确定文本中哪些词语是重要的关键词,有助于用户快速理解文本的主题和内容,同时,分词权重可以用来计算文档与用户查询之间的相关性,从而对检索结果进行排序。因此,用户检索意图库的建设除了需要对实体进行识别外,还需要利用分词权重技术计算实体的权重值。
依存关系分析是自然语言处理中的一项重要任务,旨在识别句子中单词之间的语法依存关系,并以此表示句子中单词之间的关联性和句子的结构。依存关系分析可以深入理解句子的语法结构,从而帮助解析句子的含义、进行文本理解和其他自然语言处理任务。在具体操作上,通过分析用户检索语言的各个成分之间的依存关系来揭示相互之间的语义修饰关系[26],即分析出一个句子的主、谓、宾、定、状、补结构,从而帮助判断特征要素。本文采用DDParser
DDParser是一个基于深度学习的依存句法分析器,在句法分析任务中具有较高的准确性和鲁棒性。它使用神经网络模型来自动分析句子中词语之间的依存关系,并预测每个词语在句子结构中的角色和语法功能。来分析语句之间的依存关系,并根据需要生成相应依存关系图,如查询语句 “我想了解一下美国学者德里克·贾里尼克写的关于自然语言处理方面的书”,其依存关系如图3所示。
此外,在检索意图表达形式方面,戚越、陈博立等分别在各自的研究中提出了较为一致的想法,即采用标准的结构化形式进行表达[18,27]。为了便于下游任务的使用和调取,本文采用了基于json格式的方式表示和存储用户检索意图理解和识别,以及各关键词的权重结果,示例如图4所示。
3.3 自定义词库构建
在实际的用户检索意图库建设过程中,为了提高自然语言处理系统在特定领域或任务中的准确性和增强效果,同时为了解决在检索语句中存在的歧义问题,需要根据实际需要构建自定义词库。如当用户检索“钢铁是怎样炼成的”时,其本意大概率并不是想了解钢铁的炼制过程,而是希望检索苏联作家尼古拉·奥斯特洛夫斯基所著的一部长篇小说《钢铁是怎样炼成的》。因此,本文除了常用的停用词库之外,还构建了自定义词库,具体包含别称库、特殊名称库和敏感词库三部分,具体见表2。其中:①别称库是为了解决中文中经常出现的别称、简称问题而建立的词库,目的是建立同一种实体的全称与别称或简称之间的关联关系,这种关联关系包括同义词、习惯用语、多义词等。当用户输入一个别称时,系统可以将其映射到对应的实体或概念,从而扩展搜索范围,提高搜索结果的准确性。②特殊名称库用于存储特定领域中的专有名词、实体或术语。这些包括人名、地名、组织机构名、产品名等。特殊名称库可以帮助系统正确识别和标注文本中的命名实体,提高命名实体识别的准确性。③敏感词库用于存储敏感或不良的词汇,如不雅词汇、侮辱性词汇、歧视性词汇等。这样的词汇通常需要在应用中进行过滤或审查,以遵守相关规定或维护良好的用户体验。
3.4 原型验证和分析
本文以国家图书馆2022年文津搜索系统用户检索数据为原型,按照用户检索意图库构建思路和方法构建相应的处理流程,并以此验证技术的可行性和流程的实用性。
数据预处理和清洗方面,本文共计采集了文津搜索系统2022年用户检索记录共计1,132,340条。由于这些数据均以日志形式保存,因此在进行数据清洗时,采用了基于awk技术的处理方式对原始数据进行处理,包括去重、删除无效或低质量数据,提取基本要素信息等,从而实现高效便捷的数据处理过程[28]。
在检索意图理解和识别方面,除检索语句外,由于用户的查询目标即是用户查询意图[29],因此本文以图书检索为例,从已采集的数据中分离了668,633条有效的图书检索记录,并提取记录中的关键信息,包括时间、用户IP、检索词、检索目标图书的摘要信息等,作为本文验证原型的原始数据使用。在具体操作中,由于中文切词是中文自然语言处理工作的基础,对于文本理解、信息提取、机器翻译等任务具有重要作用[30],因此我们首先选取jieba工具
jieba是一个基于Python的中文分词工具,它具有简单易用、高效准确的特点。jieba使用了基于字典的分词算法,可以将中文文本切分成一个个独立的词语。对用户检索信息和图书的摘要信息进行切词,按照词语的划分规则将连续的汉字序列切分成有意义的词语单元,同时为了保证结果的简洁性,本文只保留长度大于1的词语单元;其次在词性标注方面,由于中文词语含义的复杂性,本文选取了thulac工具
thulac是由清华大学自然语言处理与社会人文计算实验室开发的一款中文词法分析工具,支持用户自定义词典,能够高效、准确地对中文文本进行分词、词性标注和命名实体识别等处理。对词性进行标注,从而实现对于中文的快速且较高速度的词性标注[31];最后在上述工作的基础上,根据前文制定的检索意图库基本要素提取相应的关键词,并计算权重,形成基于json格式表达的具有422,809条数据的用户检索意图库。其中有420,274条记录含有主题词,404,447条记录含有行为意图信息,252,188条记录用户情感数据,59,505条记录含有时间数据,121,297条记录含有地域信息,36,703条记录含有专有名称。
4 应用前景
用户检索意图库的应用范围主要集中在自然语言处理和对话系统领域,主要包括信息检索、智能客服、问答系统、信息推荐等多个应用场景,本文以检索意图细化分析和意图预测为例,探讨了用户检索意图庫在公共图书馆的应用。
(1)用户检索意图的细化分析。在以往的研究成果中,公共图书馆领域的用户检索意图往往仅集中在主题分类上,并没有针对某个主题进行深入分析并反馈用户可能会搜索的方面和角度。因此,本文在构建用户检索意图库的基础上,对已有的用户检索记录进行统计分类,分析同类检索主题下不同的检索角度和各种方面,实现对用户检索意图的细化分析。以检索词“自然语言”为例,虽然检索主题词都属于自然语言大类,但用户意图和搜索的角度却有所不同。在利用用户检索意图库进行细化分析过程中,采用dbscan算法对自然语言主题的检索数据以主题词和行为意图进行无监督分类,统计分析用户检索意图和兴趣点。
(2)用户检索意图预测。在对用户检索意图细化分类和分析的基础上,利用检索意图库可以展示与关键词相关的常见问题、关联词汇、预测性搜索以及各种相关主题,帮助用户发现与特定关键词相关的问题、主题和内容,提供相应的检索建议,形成一个类似于AnswerThePublic
AnswerThePublic 是一个与关键词相关问题和内容的探索工具,它提供了广泛的问题和关键词联想,以帮助用户了解与特定主题相关的问题、疑虑、需求等。的检索意图探索工具。如当用户输入“自然语言”时,约有67%的用户选择如分词、词性标注文本提取等与自然语言基本处理相关的内容,19%的用户选择如文法分析、逻辑时态、句子依存关系等与自然语言高级处理的内容。
5 结论与展望
随着信息处理技术的不断发展和公共文化服务水平的不断提高,公共图书馆构建检索意图库在信息服务和用户体验方面将发挥更重要的作用,未来可能会有以下发展方向。
(1)深化语义理解。当前的检索意图库主要基于关键词匹配和规则匹配的方式,对用户的意图进行简单的识别。未来的发展方向是进一步深化语义理解,将自然语言处理和人工智能技术应用于检索意图库的构建,实现对用户意图更准确、细致地理解和分析。
(2)跨领域知识整合。随着知识的日益增长和学科的不断拓展,公共图书馆需要构建一个跨领域的检索意图库,以满足用户跨学科、综合性的信息需求。這需要整合各个学科领域的知识资源,并建立相应的检索意图库,为用户提供全面、多样化的信息服务。
(3)强化个性化推荐。个性化推荐是公共图书馆构建检索意图库的重要应用之一。未来的发展方向是通过用户行为分析、机器学习和推荐算法等技术手段,进一步提升个性化推荐的精度和效果,实现更精准、个性化的信息推荐服务。
(4)引入用户反馈机制。用户反馈是改进和优化检索意图库的重要依据。未来的发展方向是引入用户反馈机制,通过用户评价、评论和推荐等方式,收集用户对检索结果和服务质量的反馈信息,不断优化和改进检索意图库的性能和准确度。
(5)融合社交媒体数据。社交媒体已成为用户获取信息和交流的重要渠道。未来的发展方向是融合社交媒体数据,将社交媒体平台的数据纳入检索意图库的构建和分析中,以更好地理解用户的兴趣和需求,提供与社交媒体相关的信息服务。
(6)优化用户界面和体验。用户界面和体验对于公共图书馆的信息检索服务至关重要。未来的发展方向是不断优化用户界面设计,提供更直观、简洁和易用的检索界面,同时考虑多样化的用户需求和特点,提供个性化的用户体验。
(7)加强安全与隐私保护。随着信息技术的快速发展,安全与隐私保护越来越受到关注。未来的发展方向是加强公共图书馆的安全防护机制,保护用户的个人信息和隐私,建立健全的信息安全管理体系,确保用户的信息安全和权益。
参考文献:
[1]王铮,张珺敏,黄静.公共型知识服务的时代使命、价值定位与完善路径[J].文献与数据学报,2023,5(1):16-26.
[2]田蒂.基于用户检索意图的元搜索引擎研究[D].长春:吉林大学,2016.
[3]亢丽芸,王效岳,白如江.国内语义检索研究计量分析[J].现代情报,2012,32(5):104-109.
[4]杨宇.搜索词的意图分析与应用[D].北京:北京邮电大学,2010.
[5]沈思,吴玺煜.基于多标签分类的学术文献潜在时间意图识别研究[J].湖南大学学报(自然科学版),2017,44(10):158-164.
[6]张晓娟.查询意图自动分类与分析[D].武汉:武汉大学,2014.
[7]钟世敏.基于信息抽取的英文问句意图分类[D].成都:西华大学,2018.
[8]孙佳宝.基于用户意图理解的空间关键字查询研究[D].苏州:苏州大学,2020.
[9]杨峰宇.基于知识图谱的用户意图理解研究[D].长沙:国防科学技术大学,2016.
[10]李沁桐.基于情感增强的用户意图理解的文本生成研究[D].济南:山东大学,2021.
[11]许舸.基于语言模型的个性化检索方法研究[D].武汉:华中师范大学,2018.
[12]王晓春,李生,杨沐昀,等.一种长短期兴趣结合的个性化检索模型[J].中文信息学报,2016,30(3):172-177.
[13]王威.基于上下文的个性化信息检索技术研究[D].厦门:厦门大学,2009.
[14]温皓琨.基于多模态查询的图像检索研究:以时尚领域为例[D].济南:山东大学,2022.
[15]张龙涛.基于社交感知的跨模态检索研究[D].北京:北京邮电大学,2018.
[16]徐冠华,赵景秀,杨红亚,等.文本特征提取方法研究综述[J].软件导刊,2018,17(5):13-18.
[17]韩旭.基于神经网络的文本特征表示关键技术研究[D].北京:北京邮电大学,2019.
[18]戚越.面向自动问答的学术搜索通用查询语言设计与实现[D].武汉:武汉大学,2020.
[19]赵京胜,宋梦雪,高祥,等.自然语言处理中的文本表示研究[J].软件学报,2022,33(1):102-128.
[20]商宪丽,王学东.微博话题识别中基于动态共词网络的文本特征提取方法[J].图书情报知识,2016(3):80-88.
[21]徐博.面向查询理解的扩展词排序模型研究与应用[D].大连:大连理工大学,2018.
[22]丁俊,戴岳,周佳威,等.基于实体行为间语义关联的用户行为意图挖掘方法[J].计算机应用与软件,2021,38(9):343-349.
[23]杜思佳.基于深度神经网络的法律咨询用户意图理解研究与实现[D].哈尔滨:哈尔滨工业大学,2019.
[24]孙悦民.信息分类检索的技术演进及模式[J].情报资料工作,2009(6):49-52.
[25]颜小平,严长春,马顺,等.智能检索系统中生成语义分词的原理及调整策略[J].中国发明与专利,2022,19(9):42-51.
[26]甘丽新,万常选,刘德喜,等.基于句法语义特征的中文实体关系抽取[J].计算机研究与发展,2016,53(2):284-302.
[27]陈博立,鲜国建,赵瑞雪,等.科技文献问答式智能检索总体设计与关键技术探析[J].中国图书馆学报,2023,49(3):92-106.
[28]姜莉.基于网络背景流量的监控信息的模拟与分析[D].长春:吉林大学,2008.
[29]陆伟,周红霞,张晓娟.查询意图研究综述[J].中国图书馆学报,2013,39(1):100-111.
[30]黎佳.浅谈中文切词算法[J].软件,2013,34(7):75-76,120.
[31]陶德彬.基于领域文本大数据的快速分词系统的设计与实现[D].南京:南京大学,2019.
作者简介:
张宁(1982— ),男,硕士,副研究馆员,任职于国家图书馆。研究方向:数字图书馆、大数据分析、数据科学。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
美与时代·美术学刊(2022年3期)2022-04-27
法律方法(2021年3期)2021-03-16
意林图解作文(小学版)(2019年6期)2019-07-16
中国公共安全(2017年7期)2017-10-13
摄影之友(影像视觉)(2017年1期)2017-07-18
专利代理(2016年1期)2016-05-17
实践·思想理论版(2015年4期)2015-04-16
延河(下半月)(2014年3期)2014-02-28
