
新高考志愿填报推荐系统的HHRA算法研究
2024-05-20 08:26:02温创新黄桂萍
现代计算机 2024年5期
温创新,黄桂萍,胡 舟
(湘潭理工学院数字科技学院,湘潭 410219)
0 引言
高考作为我国人才选拔的一种主要方式,在中国教育体系中占据着极其重要的地位,它对学生的未来人生有着深远的影响。随着我国经济社会的发展、教育制度改革和教育观念的转变,高考人数逐年增加,报考人数已由2018年的975 万增加到2022 年的1193 万,高考竞争日益激烈。如何最大化地利用自己的分数以及自身特点,选择一个心仪的大学和专业是每个高考考生迫切需要解决的问题。自2014 年新高考改革至今,已有很多省份实现从传统高考向新高考的转变,和以往比较,新高考志愿填报数量有大幅提升,以普通类为例,志愿填报数量由6 个增加到45 个,专业组和专业的组合成百上千,致使考生很难做出选择。每年都有不少考生,因为缺乏科学指引和盲目填报志愿,导致“高分低就”“高分不就”等各类报考事故的发生,遗憾终身。
高考志愿填报作为高校录取的重要环节,一直都是学者们研究的热点。同时,千万量级的考生群体的切实需求和我国多年在高考信息化建设中积累的大量志愿数据,也为高考志愿填报推荐算法的研究提供了牵引动力和数据支撑。于超等[1]针对“高分低录”等问题,采用支持向量机算法建立高考志愿填报模型,最后通过具体仿真对比试验对算法有效性和优越性进行分析。杨博凯等[2]针对高考志愿填报录取最佳匹配问题,提出了基于遗传算法搜索最优解的解决方案。为解决考生志愿填报抉择困难的问题,刘行兵等[3]提出一种融合智能审核的高考志愿推荐模型,能实现志愿智能审核和推荐。王泽卿等[4]在爬取历年高考录取数据的基础上,提出一种基于分数线预测的多特征融合推荐算法(Reco-PMF),该算法首先利用历年高校最低投档位次,通过BP 神经网络预测报考年份各高校最低投档位次以及最低投档分数线。余奎锋等[5]提出一种基于C均值模糊聚类的多特征权重模糊均值聚类算法(MFW-FCM),该算法采用C 均值模糊聚类,形成不同填报风险下的三类推荐结果,并输出各项填报信息。针对“信息过载”问题,徐兰静等[6]将协同过滤思想应用到高考志愿填报这一领域,从构建用户属性矩阵、查找近邻用户和产生推荐三个方面进行详细描述,并对实验产生的推荐结果进行分析。
通过梳理文献,发现当前的志愿推荐算法往往存在算法单一、数据依赖较强、预测误差较大、没有充分考虑考生的个性化需求等问题。针对上述问题,本文通过使用Python 爬虫技术获得较为全面的高考志愿填报信息,并结合考生成绩和填报意愿,通过多个改进的混合算法和大数据计算,为考生智能推荐志愿。
1 数据的获取与处理
推荐算法的准确率与收集数据的准确程度成正比,因此,收集准确的高考志愿数据成为推荐算法能否成功的重中之重。
1.1 获取数据
本文采用Python 爬虫技术从各省教育考试院、各高校网站、掌上高考、中国教育在线、第三方评价机构等教育咨询网站获取多年的高考历史数据,并存储在HDFS 中。HDFS 是Hadoop 生态中的重要组成部分,它可以运行在低配的硬件上,为分布式存储提供底层支持,可将数据分块存储到集群内的不同机器上,其容错性高、扩展性强。对于某些缺失招生信息的候选高校,会从这些院校的官方网站获取相关招生数据,并通过数据整合的方式,来保证数据的完整性和准确性。这些数据主要包括历年高校专业录取分数线、历年高校专业招生计划数据、当年高校专业招生计划数据、各院校在各省最低投档位次、各省一分一段表、软科中国大学排名等。
1.2 处理数据
一般而言,从各大教育咨询网站获取的初始数据集并不能满足推荐算法对数据的要求,因此,需要对这类初始数据进行有针对性的处理,从而保证数据格式的合规性。数据仓库工具Hive 提供了丰富的SQL 查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL 查询功能,能对数据集进行归纳整理。基于Hive 强大的功能,系统能筛选出招生高校、招生年份、招生省份、招生专业、专业录取最高分、专业录取最低分、专业录取平均分、专业录取人数等数据,并将清洗后的数据导入到Hive 中,通过这样的处理,可以提升推荐算法的准确度。
在本项目中将综合使用Hive、HBase 和MR,从而满足不同业务场景的需求。通过分析整理,得到近5年录取年份、招生院校、招生省份、省控线、专业组、录取批次、专业名称、最低分、最低位次、计划招生数等数据。系统采用自定义数据导入接口将这些统计好的数据推送到数据库中,为推荐算法的计算提供数据支撑。而对于某些招生批次发生变化的候选高校,可以进行均值化或忽略处理;对于一些录取数据不完整的候选院校,可用完整部分的平均数进行填充;对于近几年都未在本省进行招生的高校,可以做不参与推荐处理。部分数据整理结果见表1。

表1 高考数据整理表(部分)
2 新高考HHRA模型
为提高志愿推荐的准确度,提升系统性能和满足考生的个性化需求,本文基于大数据技术,提出了融合多种改进推荐算法的混合推荐模型。
2.1 志愿填报推荐引擎HHRA架构
推荐引擎是本研究的重点和难点,高考志愿填报推荐系统的整体架构如图1所示。
图1清晰地描述了推荐引擎在本系统中所处的位置和作用。基于HDFS的混合推荐算法,即HHRA(HDFS hybrid recommendation algorithm)算法,在组成形式上,它是多个子算法的组合,包含改进的基于用户的协同推荐算法、推荐集优化算法和各种相似度和概率计算算法,等等。该算法将充分考虑高考志愿填报机制的各种策略,结合Spark 技术、Hadoop 生态的各种技术,对混合数据进行计算处理,最终得出符合要求的院校专业推荐结果,为新高考志愿填报推荐系统提供算力支撑。
2.2 用户协同过滤推荐算法
为帮助考生在海量数据中找到有价值的数据,本文采用基于用户的协同过滤推荐算法,它作为众多学者研究的一种主流算法,应用相当广泛。其核心思想是相似度计算,该算法可以表示为:首先找到与目标用户兴趣度相似的邻近用户,然后将邻近用户的喜好推荐给目标用户。其基本步骤分为三步:①绘制用户画像矩阵;②搜索近邻用户;③生成推荐结果。
2.2.1 构建用户特征矩阵
高考志愿填报中,其影响因素较多,既有个人、高校等因素,又有社会、经济等因素。通过综合分析,本文选取影响较大的重要因素来构建用户画像矩阵,这些因素包括:学校类型、考生成绩、历年录取分数线、性别、生源地、选科情况、录取批次、学校地区等信息,具体见表2,其中M 代表男,F 代表女。选科1代表首选物理,再选不限;2表示首选物理,再选化学等等,这些因素充分考虑了考生的基础数据和偏好信息,能为高考志愿推荐提供更加准确的数据模型。在用户特征矩阵建立后,将其作为用户属性,为后面的数据分析做准备。
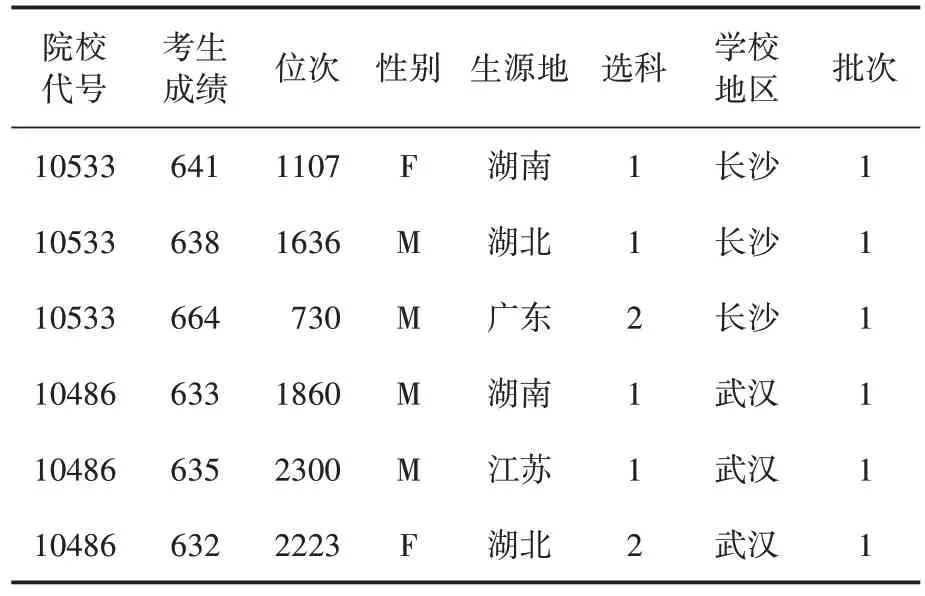
表2 用户特征矩阵表
为了便于进行比较,根据考生填报的成绩和偏好信息,采用min-max法对用户特征矩阵做标准化处理[7]。其计算规则如公式(1)所示:
其中:aij为考生的原始值,为属性j值域中的最大值,为属性j值域中的最小值。
2.2.2 查找相似考生
在标准化属性数据的基础上,本文采用改进的皮尔逊相关系数对目标考生与其他考生进行相似度计算,皮尔逊相关系数就是两个变量的协方差除以两个变量标准差的乘积。距离dij表示考生之间的相似度,距离越近,相似度则越高。考虑到考生特征属性的重要程度不同,所以需要对不同的属性进行加权处理,调整后的相似度计算规则如公式(2)所示:
其中:aik表示用户i的第k个属性值,ajk表示用户j的第k个属性值,wk表示第k个属性的重要程度,即权值。p表示用户属性的个数。
2.2.3 生成推荐结果
在使用大数据技术完成相似度计算后,通过相似度搜索,系统将选取序列中相似度较高的K个用户作为目标用户的近邻用户,并将近邻用户的志愿作为目标用户的推荐集。考虑到每年院校的招生人数和高考试卷难度可能会发生波动,采用分数作为参考值并不是最优方案,所以根据考生的分数对应的位次作为主要参考将更加准确。根据目标用户所处的位次,采用近邻搜索,选取距离最小的M个用户作为候选用户,并将筛选结果放入新的推荐集中。如果推荐集合的志愿条数小于目标数X,系统将回到之前的步骤,扩大候选用户的搜索范围,如可以选择距离最小的2M的用户,或者将M设置为一个常量宏,通过增大M的值来实现候选集的扩大,并最终实现规定数量的志愿推荐。
2.3 推荐集优化算法
为提升算法的匹配度,还需要对推荐集作进一步的优化。如采用线差法和位次法计算其录取概率,并以此为基础进行院校志愿层次划分。从使用范围来看,线差法更具广泛性,所以本文将用线差法对录取概率进行计算。
2.3.1 录取率计算
为了计算高考志愿录取率,首先需要计算均差Dave和最低均差Dlow,其计算规则分别如公式(3)和公式(4)所示:
其中:ai为过去第i年高校在目标考生所在生源地的平均录取分,si为过去第i年高校在目标考生所在生源地的最低录取分,bi为过去第i年高校在目标考生所在生源地的批次分数线。现年考生的批次线差值Dlow[8]的计算规则如公式(5)所示:
其中:sn为目标考生现年的高考分数,bn为目标考生所在生源地现年的省批次分数线。综合式(3)~(5),可以计算高校录取目标考生的概率,其计算规则如公式(6)所示:
基于公式(6)分别对推荐集志愿进行计算,并按录取概率进行分类,分类结果为:P≥0.8为保底志愿;0.5 ≤P<0.8为稳妥志愿;P<0.5为冲击志愿。
2.3.2 考生个性化需求提取和分析计算
考生原始志愿表中包含考生的兴趣喜好信息,如何将这些意愿信息进行特征值提取,并与专业进行匹配,推荐理想院校和专业给目标用户是本文研究的一个重点。如果考生没有填写原始志愿表,也可以采用MBTI 人格类型与职业匹配关系理论,挖掘职业与专业的对应关系,来间接获取考生的专业喜好信息。
本研究利用Jaccard系数,并结合考生的志愿特征计算相似度。Jaccard 系数,又称为Jaccard相似系数,是两个集合的并集与交集的比值,可以用来度量用户的相似度,其计算规则如公式(7)所示:
目标考生的志愿偏好特征与原始推荐集中的院校专业组的相似度计算规则如公式(8)所示:
其中:院校特征为A=(a1,a2,a3,…,ai),专业组特征为B=(b1,b2,b3,…,bi),院校专业组特征为S=(s1,s2,s3,…,si), 即S包括A和B(A∈S,B∈S)。R为目标考生可以填报的志愿数量。例如,目标考生填报了中南大学的107专业组,那么该专业组的特征s=(综合类,湖南省,长沙市,新一线城市,理学),包含的专业有电子信息工程、土木工程、机械设计制造及其自动化、环境科学与工程等专业。所以可以对考生填报的i个院校专业组进行特征挖掘,来获取考生的原始志愿表单集合S。
分别对保底志愿、稳妥志愿、冲击志愿中的志愿组按相似度进行计算,再按相似度进行降序排列,便可以生成符合目标考生兴趣爱好的理想志愿。
3 算法模型验证
为了清晰地描述整个HHRA 算法的整体逻辑,本文以湖南省2022 年新高考某考生T为例来验证与分析模型。该考生的成绩为585 分,选科情况为首选物理,再选化学和生物。
(1)获取考生的基本属性信息,即高考分数、选科情况、性别、生源地等基本信息,这些信息由考生自己输入。
(2)考生按自身喜好填写原始志愿表(见表3)。

表3 考生E原始志愿表
(3)使用改进的皮尔逊相关系数计算相似度,查找相似考生,并得到一个结果序列。系统将选取序列中相似度较高的K个用户作为目标用户的近邻用户,并将近邻用户的志愿作为目标用户的推荐集。
(4)通过考生提供的分数、选科情况计算出各志愿录取概率,并将其划分为冲、稳、保三个层次,继而得到院校专业组原始目标集M。
(5)根据考生的原始志愿表提取其偏好特征,同时利用Jaccard 系数计算院校专业组原始目标集M与提取出的考生偏好的相似度。
(6)根据步骤(4)和(5)得到的内容,在三种院校层次中,按之前计算得到的考生偏好相似度进行降序排列,并得到最终志愿推荐结果,生成的志愿推荐见表4。

表4 考生K的志愿推荐结果
通过模拟考生数据的方式对推荐算法进行验证。模拟数据分为7个分数段,每个分数段随机产生60 名2022 年湖南省考生的分数,验证指定范围各类别所有高校的平均录取概率,实验结果如图2所示。
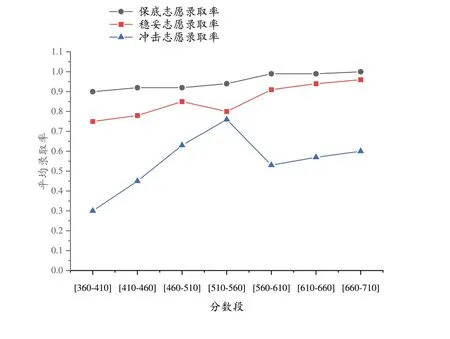
图2 各分数段各类别平均录取率
从图2得知,高分段和中分段的保底志愿和稳妥志愿推荐效果比较好,说明考生对院校的选择更加明确,高分段考生人数少,每年位次比较稳定;而低分段考生的录取概率不高,这是因为低分考生人数较多,高校每年的最低投档线浮动大,“信息过载”问题突出。
4 结语
本文针对当前高考志愿填报存在的问题,结合网络爬虫、大数据处理和存储技术,提出了一种HHRA 混合推荐算法。该算法包含改进的基于用户的协同过滤推荐算法、推荐集优化算法和各种相似度和概率计算算法。相比于其他推荐算法,HHRA 算法提高了算法的实时性和准确度,实验测试表明,该算法能为考生推荐符合考生成绩和自身兴趣爱好的志愿列表,能提升高考志愿选择的效率和准确度,并解决缺乏志愿填报专业知识带来的一系列问题,具有较好的应用价值。虽然本算法在系统的应用中有一定的推荐效果,但是在不同分数段的推荐中,其效果还是存在差异,针对此现象,应考虑在不同分数段采用不同的推荐方法;同样,基于用户的协同过滤推荐算法的推荐精度还不是很理想,还需要通过训练集的不断测试来进行完善,这也是今后研究和努力的方向。
猜你喜欢
求学·理科版(2023年19期)2023-10-28 08:55:09
求学·理科版(2022年12期)2023-01-03 19:49:40
公民与法治(2022年11期)2022-12-06 02:28:28
东方剑·消防救援(2022年3期)2022-04-01 04:24:04
中国现代中药(2019年9期)2019-09-19 09:30:16
公民与法治(2016年18期)2016-05-17 04:17:29
中国卫生(2015年3期)2015-11-19 02:53:26
教育与职业(2014年25期)2014-01-23 06:45:58
教育与职业(2014年19期)2014-01-21 02:34:22
教育与职业(2014年4期)2014-01-19 09:08:24
