
基于邻域依赖度融合信息熵属性约简
2024-05-19 14:36:42李朝清孙洁原頔李毅
电脑知识与技术 2024年7期
李朝清 孙洁 原頔 李毅
摘要:邻域粗糙集是经典粗糙集理论的一个重要扩展,它已成功应用于诸多领域,其中属性约简是其最主要的应用之一。邻域依赖度与信息熵是邻域粗糙集中的重要内容,邻域依赖度属则是通过识别出那些对决策属性具有显著依赖关系的属性,邻域信息熵可以用来衡量条件属性对决策属性的重要性。通过它们构建约简算法可以消除数据集中的冗余信息,提高数据处理和分析的效率。基于此,本文以邻域依赖度融合信息熵为基础,提出了基于邻域依赖度融合信息熵属性约简算法。使用公开数据集,实验结果表明该算法可以选择较少的属性来保持或提高聚类算法的性能,这充分证明了该算法具有较强的有效性。
关键词:属性约简;邻域依赖度;邻域信息熵
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)07-0028-05
开放科学(资源服务)标识码(OSID)
0 引言
属性约简(Attribute Reduction) [1]是数据预处理的一个重要步骤,通常在数据挖掘、机器学习、模式识别等领域中使用。其核心目的是识别并移除数据中的不相关的、冗余的或不重要的属性(特征),以便减少特征空间的维度并简化后续的分析或模型学习过程。这项技术不仅可以降低高维空间数据的复杂性,还可以提高数据处理的效率。属性约简的研究和应用一直是数据科学领域活跃的研究方向,科研工作者不断提出新技术和算法以适应不断增长和变化的数据分析需求。
粗糙集理论(Rough Set Theory) [2]是由Pawlak在1980年初提出,是一种处理不确定性和不完整信息的数学工具。该理论广泛应用于数据挖掘、模式识别和人工智能等领域,特别在属性约简方面展示了其有效性。经典粗糙集理论的应用限于标称型数据,而非数值型数据。但在现实生活中的数据集通常为,为了将数值型数据纳入粗糙集分析,一个常见的做法是離散化,但是,离散化处理通常是导致数据信丢失的重要原因。为了有效处理数值型数据。Lin等人提出了邻域粗糙集的概念,Hu等人针对邻域粗糙集理论进行了广泛的讨论和研究,并提供一种有效的工具来克服离散化处理[3-4]。
信息熵起源于信息论[5],它是一种能够建立衡量不确定性竞争机制的方法。Hu等人在传统信息熵的基础上,将其拓展到邻域粗糙集,提出了邻域信息熵的概念[4]。Chen等人进一步发展了邻域信息熵理论,提出了一种有效的基于邻域信息熵的不确定性度量方法。迄今为止,邻域信息熵已被成功应用于属性约简[6]。
基于此本文提出了基于邻域依赖度及信息熵的属性约简算法。
1 邻域粗糙集理论
本节将回顾本文后续章节中关于邻域粗糙集理论的一些定义及符号。
定义1[1,4]信息系统(Information System,IS)可以用一个四元组来表示,即[IS=(U,A,V,f)]。其中:[U={x1,x2,...,xn}]是非空有限对象集,称为论域;[A]为属性集,它是一个非空有限集;[V=a∈AVa],[Va]为属性[a]的值域;[f:U×A→V]是一个信息函数,它满足对[?xi∈U(1≤i≤n)]及[?a∈A]有[f(xi,a)∈Va]。对于决策信息系统(Decision System,DS),属性[A]可以分为2个互不相交的子集:条件属性子集[C={c1,c2,...,cm}]和决策属性集[D],[C?D=?],[C?D=A]。决策信息系统可以简记为[DS=(U,C?D,V,f)]。
通过信息函数[f]定义不可区分关系。
定义2[1,4]给定一个信息系统[DS=(U,C?D,V,f)],对[?B?C],关于属性子集[B]的不可区分关系[IND(B)]可定义为:
[IND(B)={(xi,xj)∈U×U|f(xi,ck)=f(xj,ck),?ck∈B}] (1)
显然,等价关系仅使用于标称型数据集。
为了处理数值型数据集,本文将引入距离函数来构建邻域信息系统。
定义3[1,4]给定一个[DS=(U,C?D,V,f)]对[?xi,xj,xp∈U] [(1≤i,j,p≤n)] ,假设[B={ck1,ck2,...,ckh}(1≤h≤m)?C],距离函数[ΔB(xi,xj)]需要满足如下关系:
[(1)ΔB(xi,xj)≥0,ΔB(x,y)=0当且仅当x=y(非负性);(2)ΔB(xi,xj)=ΔB(xj,xi)(对称性);(3)ΔB(xi,xp)≤ΔB(xi,xj)+ΔB(xi,xp)(传递性)。]
[ΔB(xi,xj)]计算对象[xi,xj]在属性子集[B]下的距离函数。本文采用欧式距离函数,即:
[ΔB(xi,xj)=(l=1h(f(xi,ckl)-f(xj,ckl))2)12] (2)
其中,[f(xi,ckl)]与[f(xj,ckl)]分别表示对象[xi]与[xj]在属性[ckl]下的属性值。
基于距离函数并引入邻域半径[ε(ε≥0)]来粒化论域,形成邻域关系和邻域类。
定义3[1,4]给定一个[DS=(U,C?D,V,f)],对[?xi∈U], [ε≥0], [?B?C],那么[xi]在属性子集[B]上的[ε-]邻域定义为:
[nεB(xi)={xj|ΔB(xi,xj)≤ε,xj∈U}] (3)
性质1[1,4] 对于[?xi,xj∈U],有定义3可以得到[ε-]邻域具有如下性质:
[(1)nεB(xi)≠?;(2)xj∈nεB(xi)?xi∈nεB(xj);(3)i=1nnεB(xi)=U。]
定义4[1,4]给定一个[DS=(U,C?D,V,f)],对[?B?C],[ε≥0],那么邻域关系[nrεB]定义如下:
[nrεB={(xi,xj)|xi,xj∈U且xj∈nεB(xi)}] (4)
由此可见,邻域关系实际上刻画了论域[U]中对象之间的相似性和不可区分性。
定义5[1,4]给定一个决策信息系统[DS=(U,C?D,V,f)],对[?B?C]及[ε≥0],[U/nrεB]构成[U]的邻域覆盖,称其为[U]上的一个邻域知识。其中,每个邻域称为一个邻域知识或邻域类。
基于给定距离函数和邻域半径来构建邻域信息系统。
定义6[1,4]给定一个[DS=(U,C?D,V,f)]对[?B?C]和[ε≥0],[nrεB]为属性子集[B]导出的[U]上[B-ε]邻域关系:[NRεC={nrεB}]为[U]上全体邻域关系全体,称四元组[NIS=(U,NRεC,V,f)]为邻域信息系统。相应地,[NDS=(U,NRεC?D,V,f)]称为邻域决策信息系统。
在邻域信息系统中可以定义相关的上下近似集,其相关定义如下。
定义7[1,4]给定一个[NIS=(U,NRεC,V,f)],对[X?U],[nrεB∈NRεC],那么[X]基于邻域关系[nrεB]的上近似集[nrεB(X)]与下近似集[nrεB(X)]分别定义为:
[nrεB(X)={xi|nεB(xi)?X≠?,xi∈U}] (5)
[nrεB(X)={xi|nεB(xi)?X,xi∈U}] (6)
其中,称[POSnrεB(X)=nrεB(X)]为[X]的[nrεB]正域,称[NEGnrεB(X)=U-nrεB(X)]为[X] 的[nrεB]负域,称[BNDnrεB(X)=nrεB(X)-nrεB(X)]为[X]的[nrεB]边界域。
基于上述邻域粗糙集理论相关知识,还可以定义一些有实际应用价值的概念,如邻域信息熵。
定义8[5]给定一个[NIS=(U,NRεC,V,f)],邻域关系[nrεB∈NRεC]确定的邻域知识为[U/nrεB={N1,N2,...,Nq}]。那么,邻域关系[nrεB]所关联的邻域信息熵[NEε(B)]可以定义为:
[NEε(B)=-i=1qNiUlog2NiU] (7)
其中,[NiU]为邻域知识元素[Ni]对于论域[U]的隶属度概率。
2 基于邻域依赖度融合信息熵属性约简
在本节中,首先建议邻域依赖度融合信息熵属性选择模型,接着提出了一种基于邻域依赖度融合信息熵属性选择模型,然后基于具体模型对其进行分析。此外,还设计了相应的属性约简算法。
2.1 基于邻域依赖度融合信息熵属性选择模型建立
给定一个[NIS=(U,NRεB,V,f)],条件属性集[C={c1,c2,...,cm}]。设[B={ck1,ck2,...,ckh}][(1≤h≤m)] ,且[B?C],对[?xi,xj∈U] 在属性子集[B]下的领域关系可以用[rBij]来表示如下:
[rBij=1,ΔB(xi,xj)≤ε;0,ΔB(xi,xj)>ε.] (8)
从公式(8) 可以看出,当对象[xi]与[xj]之间的距离小于等领域半径[ε]时,认为它们的领域相似度为1;大于领域半径[ε]时;认为它们的相似度为0.其中邻域半径[ε]是可以调的。[nrεB]是[U]上关于[B]的邻域关系,则邻域关系矩阵[MnrεB]表示如下:
[MnrεB=rB11rB12…rB1nrB21rB22…rB2n????rBn1rBn2…rBnn] (9)
由此可见,在属性[B]下,[U]中对象[xi]的[ε-] 领域可以表示成[0-1]向量形式,即[nεB(xi)=(rBi1,rBi2,...,rBin)]。
定义9 决策[D]相对于条件[B]的邻域正域的定义如下:
[POSεB(D)=X∈UnrεB(X)] (10)
邻域正域定义了决策[D]相对于条件[B]的变精度领域下近似集的并。
定义10 决策[D]相对于条件[B]的邻域正域的定义如下:
[γεB(D)=|POSεB(D)|U] (11)
定义11 如果[γεB(D)=γεB-{b}(D)],称[b]在[B]中是冗余的;否则,称[b]在[B]是必要的。如果[B]中每一个属性都是有必要的,则称[B]是独立的。
定义12 假设给定[B?C],如果[B]满足条件:
[(1)γεB(D)=γεC(D);(2)?b∈B,γεB-{b}(D)<γεB(D),]
定义13 [?b∈C-B],把[b]相对于[B]的重要度定义为:
[IMP(b,B,D)=γεB?{b}(D)-γεB(D)] (12)
由于[0≤γεB(D)≤1]且[γεB?{b}(D)≥γεB(D)],有[0≤IMP(b,B,D)≤1]。如果[IMP(b,B,D)=0],则称属性[b]在[B]中冗余;否则称[b]是必要的。
则称[B]是[C]的一个约简集。
在上述定义中,条件(1)要求约简不能降低系统的区分能力,约简后的条件属性与全部的条件属性具有相同的区分能力。条件(2)要求在属性约简后条件属性中不存在多余的条件属性,所有的条件属性都是必要的。
2.2 基于邻域依赖度融合信息熵选择算法
到目前为止,本文已经建立了邻域依赖融合信息的选择模型,称为“基于邻域依赖度融合信息属性约简算法”。接下来,本小节将分析一个特定的基于邻域依赖度融合信息熵的属性约简算法。
在基于邻域粗糙集模型的数据处理中,通常需要对数据集进行归一化处理,其计算模型如下:
[F(f(xi,ck))=f(xi,ck)-minckmaxck-minck] (13)
其中,[f(xi,ck)] 为对象[xi]在条件属性[ck]下对应的值,[maxck]和[minck]分别是论域[U]中对象关于条件属性[ck] 下的最大值和最小值。归一化后,这些属性的属性值取值范围为[0,1]。
算法:基于邻域依赖度融合信息熵属性约简算法(NDIEAR)
输入:[DIS=(U,NRεC?D,V,f)],其中[|C|=m],邻域半径参数[ε]
输出:一个约简集[red]
1) 初始化[red←?,B←C-red]
2) 计算每个条件属性[ck∈C]的邻域信息熵[NEε({ck})]
3) 选择最大的邻域信息熵[NEε({ck})],选择属性[ck],即[red={ck}]
4) 当[B≠?]时
5) 对[?ckj∈B]
6) 计算属性[ckj]的重要度[IMP(ckj,red,D)=γεred?{ckj}(D)-γεred(D)]
7) end
8) 选择属性[ckj'],使得[IMP(ckj',red,D)=max(IMP(ckj,red,D)]
9) 如果[IMP(ckj',red,D)>0]
10) [red=red?{ckj'}]
11) else
12) break
13) end
基于邻域依赖度融合信息熵属性约简算法以空集为起点,首先,计算每个条件属性的邻域信息熵,选择最大的邻域信息熵的属性加入约简集合。接着,每次计算全部剩余属性的属性重要度,从中选择重要度值最大的属性加入约简集合中,一直到所有剩余属性重要度为0。算法的时间复杂度主要集中在步骤6-8中,计算所有对象邻域依赖度。分析算法可知,邻域依赖度的计算在最坏情况下的时间复杂度为[O(n2)]。假设系统中有[n] 个样本,[m] 个条件属性,约简属性子集有[q]个属性。在步骤6中需要计算每个对象在不同属性下的邻域依赖度,其时间复杂[O(mn2+(m -1)n2+...+(m - q)n2)= O(12(2m - q)(q +1)n2)]。
3 實验及分析
本节通过在聚类任务中的性能来评估VPNDAR算法,主要包括实验数据集、实验方案、实验结果、参数分析等内容。
3.1 实验数据集
从公开数据库中选取6个数值属性数据进行实验。对于某些数据集中的缺失值,采用最大概率值法来填充缺失值,即用该属性上其他样本上出现频率最高的值来填充缺失的属性值。用于聚类的数据集描述如表1。
3.2 实验方案
本文所提基于变精度邻域依赖度属性约简(NDIEAR)算法作用于表1列出的数据集为每一个数据集选择一个最优的属性子集。
对于聚类实验中,本文调用k-Means和FCM(Fuzzy C-Means)聚类算法来评估算法的性能。聚类算法返回数据集的预测决策,本节使用聚类准确率(ACC)来评估聚类算法的性能。其定义如下:
[ACC=i=1nδ(f(xi),f'(xi))n] (14)
其中,[f(xi)]表示[xi]的真实决策属性值,[f'(xi)]为[xi]的预测决策属性值。如果[f(xi)=f'(xi)],则[δ(f(xi),f'(xi))=1]。反之,则等于0。一个聚类算法的ACC值越大,说明其性能越好。由于k-Means和FCM聚类算法具有随机性,所以重复实验10次。最后,使用聚类ACC值的平均值和标准差来作为最终的结果。
NDIEAR算法,计算邻域半径[ε]在[0.1,1]步长为0.1的最优结果。同时,对于NDIEAR算法,通过大量实验表明对于数值属性数据集,通常很难达到以所有剩余属性的重要度为0的停止条件。因此本文设置重要度停止条件为0.000 1。
3.3 实验结果分析
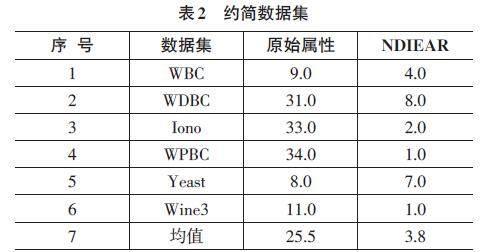
本节首先给基于邻域依赖度融合信息熵属性约简结果,如表2所示。
表2给出了k-Means和FCM聚类算法的平均最优属性个数。NDIEAR算法选择的属性数在所有数据集上均小于原始数据节属性个数。例如,对于WDBC、Iono、WPBC及Wine3数据集而言,NDIEAR算法选择的平均属性个数为8.0、2.0、1.0及1.0,明显小于原始属性个数。此外,对于属性数均值而言,NDIEAR算法远小于原始属性个数。
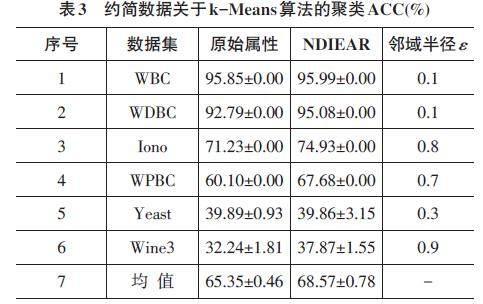
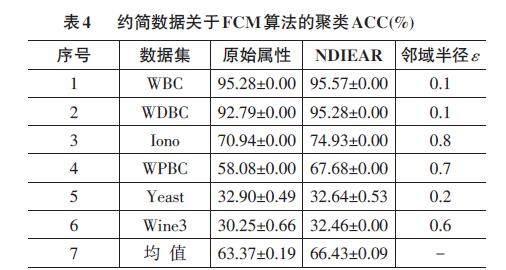
接下来,分别给出约简数据关于聚类算法的聚类ACC(%)。如表3和表4所示。
表3和表4分别给出了基于k-Means算法和FCM算法的最优聚类ACC的结果。其中,粗体部分显示最优值。通过表3和表4中的结果,得到一些相应的分析如下:
1) NDIEAR算法相比原始属性有10种情形达到了最好的聚类ACC,而原始属性只有2种情形。
2) 从ACC的均值来看,所提NDIEAR算法在两种聚类算法中都取得了比较高的均值。
综上所述,本文所提NDIEAR算法获得了较好的聚类性能。它可以选择较小的属性子集,同时能保持或者提高聚类ACC。因此,NDIEAR算法适用于在聚类任务中的数值属性约简。
3.4 实验参数分析
邻域半径参数[ε] 在NDIEAR算法中起着至关重要的作用,它可以用于控制数据分析的邻域粒度,最终影响约简的结果。
接下来,本文将给出不同邻域半径[ε]下约简属性数和平均聚类准确率曲线,如图1所示。
NDIEAR算法,可以通过调整邻域半径参数ε在每个数据集上得到不同的属性子集。图1描述了不同邻域半径参数ε约简属性数和平均聚类准确率曲线。接下来,本文将从属性约简的个数和聚类ACC两个方面进行分析。
通过分析图1,可以看到,在一些数据集上随着邻域半径参数ε的增加,约简属性的个数先保持平稳,接着逐渐降低,最后保持相对平稳,如Yest和Wine3。大部分数据集随着变精度阈值[ε]的增加,约简属性的个数大体上呈逐增加的趋势到达某个峰值,然后逐渐减少,如WBC、WDBC、Iono及WPBC。
在平均聚类准确方面,从图1可知,对于大多数数据集,在多个邻域半径[ε]下可以取得高平均聚类精度。对于每个数据集,可以根据图1选择合适的邻域半径[ε]。因此,使用NDIEAR算法进行属性约简是可行的。
4 结论
本文设计了相应的NDIEAR算法。从公开数据库中选取6个数据在所提NDIEAR算法上进行实验。实验结果表明,该算法可以选择较少的属性来保持或提高学习算法的能力。
参考文献:
[1] 徐波.邻域粗糙集的启发式属性约简算法研究[D].成都:四川师范大学,2019.
[2] PAWLAK Z.Rough sets[J].International Journal of Computer & Information Sciences,1982,11(5):341-356.
[3] HU Q H,YU D R,LIU J F,et al.Neighborhood rough set based heterogeneous feature subset selection[J].Information Sciences,2008,178(18):3577-3594.
[4] 胡清華.混合数据知识发现的粗糙计算模型和算法[D].哈尔滨:哈尔滨工业大学,2008.
[5] 袁钟.混合数据无监督知识发现的模糊粗糙计算方法研究[D].成都:西南交通大学,2022.
[6] CHEN Y M,WU K S,CHEN X H,et al.An entropy-based uncertainty measurement approach in neighborhood systems[J].Information Sciences,2014,279:239-250.
【通联编辑:梁书】
