
基于密度聚类算法改进的语义主路径分析方法研究
2024-05-06 08:26:26陈亮余池尚玮姣许海云吕世炅陈利利
情报学报 2024年3期
陈亮,余池,尚玮姣,许海云,吕世炅,陈利利
(1. 中国科学技术信息研究所,北京 100038;2. 中国林业科学研究院林业科技信息研究所,北京 100091;3. 山东理工大学管理学院,淄博 255000)
0 引 言
了解科技发展的历史过程、研究现状是规划科技发展战略和预测科技发展趋势的重要手段。当前,学科知识更替加速、不同学科之间日渐交融,科技文献和科研数据的规模、类型不断增加,传统的以信息检索和文献综述等方式进行科技知识脉络梳理易受分析人员主观偏见、知识局限的影响,而且分析过程耗时较长、对专家知识依赖较大,方法难以推广。近年来,主路径分析方法逐渐成为科技领域知识脉络发现的重要方法,其采用引文网络来表示文献之间知识的传播通道,采用网络遍历计数来表示引文关系在知识传播过程中的重要程度,进而从引文网络中提取重要文献之间的骨架结构来表示该科技领域的主要发展过程,帮助研究者快速了解科技领域发展过程,为国家科技政策制定和产业发展方向选择提供决策支持。
但是这种无涉文献内容的引文分析方法存在明显不足:基于路径遍历权重的主路径筛选方法会错过地位重要但分属不同子领域的其他主路径。对此,陈亮等[1]将文献内容纳入主路径分析法的考量范围之内,以施引文献和被引文献之间的文本相似度作为引文连线权重,从而产生多条能够反映不同子领域知识脉络的主路径;并进一步提出一套新的主路径分析框架,即语义主路径分析方法[2]。该方法除了将文本相似度和遍历权重相结合以形成复合连线权重外,还利用文本聚类技术将引文网络中的候选主路径划分到不同聚簇,进而从每个聚簇中选出遍历权重最大的候选主路径以作为代表相应子领域知识脉络的主路径;在实证分析中,该方法能够准确抽取电动汽车领域三大核心模块,即电池、电机和电控的技术发展轨迹,并取得了良好的分析效果[2]。
然而,Chen等[2]认为,这种以遍历权重为标准从每个聚簇中选择主路径的做法仍然存在明显不足:①所选主路径的位置可能偏离聚簇中心,其能否代表这一子领域的知识脉络存疑;②不同聚簇的主路径可能彼此相近,影响不同主路径之间的主题区分度。本文在综合考量路径的遍历权重及其所在聚簇位置的基础上,提出一种基于密度聚类算法改进的主路径分析方法,对上述不足加以改进。实证阶段,除沿用Chen等[2]的电动汽车相关领域专利数据用于对比分析之外,还选用材料科学领域高影响力的论文数据集用于验证本文方法在不同领域、不同类型数据上的适用性。实验结果表明,改进后的语义主路径分析法抽取的主路径不仅在路径聚类图上的分布更加合理,而且选中不适合路径(如路径节点较少、拓扑权重较低)的可能性也大大降低。
本文其他部分安排如下:第1节总结主路径分析方法的相关研究进展,第2节对基于改进密度聚类算法的主路径优化分析方法展开叙述,第3节分别使用电动汽车锂离子电池专利数据集和材料科学领域高影响力论文数据进行实证说明,第4节对论文整体进行总结和前瞻。
1 相关研究进展
1.1 主路径分析方法概述
主路径分析方法是一种基于文献引文信息的知识演化路径抽取方法,用于对领域知识发生的各种变化进行总结、归纳与展示[3]。相比于其他使用主题词、SAO(subject-action-object)结构、问题-解决方案二元组等信息的知识演化路径抽取方法,主路径分析法具有成本低、效率高、可移植性和可复用性好等诸多优点,备受科技情报用户青睐,尤其是知名社会网络分析软件Pajek[4]实现了主路径分析法的多个变体,进一步推广了这种知识演化路径抽取方法的应用范围。
主路径分析法最早由Hummon等[5]于1989年提出,他们发现引文网络中连线的重要程度并不相等,有些引文关系充当重要角色,若将其移除,会改变引文网络中的整个知识流动过程,而有些引文关系产生的影响则小得多。这些充当重要角色的引文关系构成了引文网络中的“主路径”,而主路径分析法就是从引文网络中识别出这些重要引文关系,并按照先后顺序展示该领域的重要文献及其知识的传承过程[6]。在当前海量科技文献数据所造成的信息过载环境下,主路径分析方法提供了一种基于连通性降低引文网络复杂程度并从中识别关键路径的定量方法,在知识发展路径抽取中具有重要意义[7]。在算法层面,主路径被定义为非循环网络中从源点(即入度为0的节点)到汇点(即出度为0的节点)的一条通路,该通路上所有弧的权重之和具有最高遍历权重[8]。虽然主路径分析方法在长期发展中形成了规模庞大的家族体系,但总体而言这些家族成员仍然遵从图1所示的统一流程框架:在从文献数据库中获取数据并生成引文网络后,首先,计算引文网络中每条连线的遍历权重;其次,搜索自源点至终点之间的候选路径,所谓源点,即只有出度没有入度的节点,反之,则为终点[9];最后,将每条候选路径上的连线权重累加起来,并将符合条件(如遍历权重最大)的路径筛选出来作为主路径,下文将分别对主路径分析法的各个重要环节展开详细介绍。
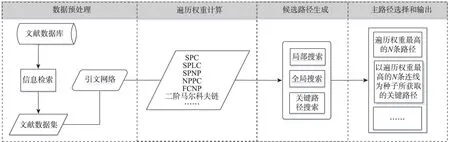
图1 当前主路径分析的方法步骤
1.2 主路径分析法的连线遍历权重计算
在从文献数据库中获取数据集并构建引文网络后,需要根据引文连线在引文网络中的重要程度为其赋予权重。连线重要性一般根据引文网络中与该连线相关的路径数量统计得到。比如,SPNP(search path node pair)指标就是通过统计经过某条边的路径数量来测度这条边的重要程度,还有类似指标SPLC(search path link count)和NPPC(node pair projection count)[5,10],但它们在筛选路径方式上有所不同;Batagelj[11]认为这些路径权重指标计算方式过于复杂、低效,他将直接引用和间接引用同时纳入考量范围,形成了更加高效的连线权重指标SPC(search path count)。当前,常用连线权重指标的详细情况如表1[12]所示。Liu等[10,13]深入剖析了这些权重指标之间的区别:在SPC中引文网络的中间节点只具有知识传导的作用;而在SPNP中,引文网络的中间节点则是一个知识存储单元;相比之下,SPLC更接近实际情况——中间节点不仅在知识扩散的过程中具有中转站的作用,它还引入了新的知识;计算NPPC指标的时间复杂度较高,极少在实际场景中使用。基于以上原因可以发现,Xu等[14]、Huang等[15]和Lai等[16]学者倾向使用SPLC指标,尽管Batagelj[11]、Martinelli[17]、Chen等[2]注意到不同遍历权重指标下产生的主路径结果几乎一致。

表1 主路径方法中主要的弧权重指标[12]
近年来出现了一些关于此类指标的新观点,包括无法反映知识传播时所产生的信息损失[10]、基于这些指标的主路径上各个文献的主题一致性较弱等[19-20]。Liu等[21]将知识传播中的延迟效应纳入考量范围,并形成SPAD(search-path arithmetic de‐cay)、SPGD(search-path geometric decay)和SPHD(search-path harmonic decay)等一系列新指标,以缓解信息损失。至于主路径上文献主题不一致的问题,目前主要解决思路是将文献的文本信息纳入连线权重计算之中,使主路径分析法在搜索主路径时能够确保同一路径上文献具有较高的主题相似度[1,22],也有研究者进一步将文献本身重要性[20]、引用结构相似性、引用情感等信息与主题相似度相结合[23],以提升主路径的主题一致性。夏红玉等[24]认为已有研究忽略了同一引用关系在全文的出现频次以及出现位置,而这两个因素同样对引文权重产生重要影响;Jiang等[25]将引用动机引入引文网络,使得引文连线对应不同分析目的。Oh等[26]运用SAO和DEMATEL(decision mak‐ing trial and evaluation laboratory)方法捕捉专利引用所隐藏的因果关系,并将其量化后赋值于专利引文连线,用于识别能反映技术因果关系的主路径。
1.3 主路径分析法的候选路径生成
一旦连线权重准备完毕,下一步就是在源点和终点之间搜索候选路径,以便从中筛选出最终的主路径结果。为了方便表述,本文将该步骤简称为“候选路径生成”。当前路径搜索主要有两种策略,即贪心策略和穷举策略。其中,前者从源点出发,使用贪心法游走引文网络,即在由当前节点发出的连线中,选取最大权重连线作为通路行进至下一节点,直至遇到终点[27];后者则穷举出引文网络中所有可能的路径,进而选取路径权重最高的路径作为结果输出[28]。
由于贪心策略并不保障搜索结果为全局最优路径,所以也被称为局部搜索策略。与此相对,穷举策略被称为全局搜索策略。根据搜索方向的不同,这些策略还能进一步被细分为由源点到终点的前向局部搜索、前向全局搜索,以及由终点到源点的后向局部搜索、后向全局搜索[29]。Liu等[29]观察到,无论局部搜索策略还是全局搜索策略,所产生的主路径均无法确保包含引文网络中遍历权重最大的连线;因此,他们建议使用一种新的路径搜索策略,即关键路径搜索(key-route search)。所谓关键路径搜索就是先找出引文网络中遍历权重最大的连线并将其作为种子,进而从种子出发向前搜索直至遇到终点、向后搜索直至遇到源点,最终输出一条新的主路径。马瑞敏等[30]注意到,候选路径搜索算法基于连线权重展开,而将同样值得关注的节点重要性排除在外;为此,他们将Pathfinder算法作为候选路径搜索算法,针对重要节点、最大信息承载量和关键关系,构建更具综合性和包含性的主路径。
从路径搜索角度来看,主路径上出现文献主题不一致现象的一个重要原因是,算法只根据当前节点信息选择下一节点而遗忘当前节点的前趋节点。基于此,Yeo等[27]使用二阶马尔科夫链对候选路径展开2跳(2-hop)搜索,用于对抗因遗忘前趋节点所带来的语义漂移问题。与此不同的是,Tu等[31]通过将主路径上主题类似的文献加以合并来区分不同主题,并形成一种新的主路径形式——概念路径;沿着该研究方向,Kim等[20]进一步集成PageRank算法[32]和引文影响力模型(citation influence model,CIM)[33-34]来改善路径的主题一致性,进而抽取蛋白质p53领域的多条主路径。
1.4 主路径选择
早期的主路径分析方法主要选取路径长度最长或者连线累加权重最大的单条路径作为主路径[27]。然而,单条路径由于覆盖面较小,在探索领域知识演化脉络时受限很大[34],同时容易遗失重要节点、连线和路径[19]。为此,Verspagen[28]将路径选择条件放宽,若同时存在多条连线累计权重并列第一的路径,则将其全部纳入进来以形成主路径网络;Fon‐tana等[35]更进一步,将连线累计权重排名第二、第三的候选路径扩充至主路径网络。由于这些主路径网络不仅包含了连线累计权重最大的路径,还包含了排名靠后的其他路径,因此,Liu等[34]称这种新方法为多主路径分析法。
然而,在多主路径分析法中,遍历权重最大的连线仍然可能未被包含在主路径网络结果中。一方面,Xiao等[36]将关键路径搜索策略引入多主路径分析法中。具体来说,他们将遍历权重排名靠前的连线作为种子,对每个种子执行关键路径搜索策略以产生多条主路径,并将这些主路径合并后得到最终结果。由于加持了关键路径搜索策略的多主路径方法在展示科技领域知识演化细节上的良好表现,该方法得到了学者们的广泛关注[14,36-37]。例如,万小萍等[38]将多主路径分析方法推广到多源前向局部路径搜索、多汇反向路径搜索、全局组合路径,用于提升路径的多样性和重要节点的包含性。
另一方面,Kim等[19]和Yu等[37]将研究焦点投向从主路径上旁生的重要分支。具体来说,他们首先采用社区探测算法将引文网络划分为若干子网,继而利用传统主路径分析法从每个子网中抽取子主路径,将全部子主路径合并后即可用于主路径分支分析。Martinelli[17]提出另一种策略,即固定文献的起始年份而改变文献的终止年份,通过筛选符合条件的文献集合形成不同时间段所对应的引文网络,在对不同引文网络进行路径抽取并拼接成总主路径后,就可以分析不同时间段上的知识发展变化情况。Chen等[2]发现遍历权重排名靠前的多主路径通常由于具有相同主题而缺乏多样性,他们将候选路径转化为文本向量后进行聚类,并抽取每个聚簇中遍历权重最大的路径代表这一子领域的知识发展路径,有效解决了多主路径方法的主题单一问题。
2 研究方法
语义主路径分析方法虽然将引文节点所依附的文本信息纳入连线权重计算之中,以优化主路径上文献的主题一致性,但是在使用聚类算法从候选路径所形成的聚簇中选择主路径时,直接选取最大遍历权重路径的做法可能导致主路径偏离聚簇中心,无法展示该聚簇所隐藏的知识演化过程,同时减弱不同子领域主路径之间的主题差异。对此,本文提出一种基于改进密度聚类算法的语义主路径分析方法,除了将语义信息融入主路径以提升节点的语义相似度外,更重要的是将聚簇中候选路径所在节点的密度和候选路径的遍历权重叠加起来形成复合密度,并重新进行密度聚类和输出位于新聚簇中心的主路径。该方法的技术路线如图2所示,下文将对其中主要步骤进行详细说明。
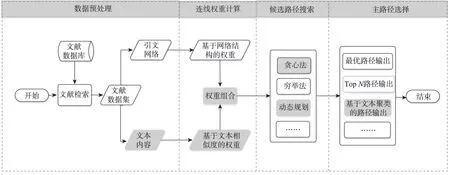
图2 技术路线
2.1 数据预处理
本文需要两种类型数据:一是文献之间的引用信息;二是引文网络中每个节点所依附的文本信息。对于前者,需要在构建引文网络时去除孤立节点、网络碎片和引文回路;对于后者,需要通过文本预处理完成大小写转换、抽词干、词形还原、去停用词等一系列操作,从文本集合中汇集词汇、形成词典并完成文本向量化,即采用向量空间模型将文本转化为向量,从而形成文档-词汇权重矩阵。由于词典规模较大,每个文本向量化后的维度会很高,对应的文档-词汇矩阵非常稀疏,因此,需要使用LSI(latent semantic index)[39]、LDA(latent Dirichelet allocation)[40]等主题模型对其降维以节省存储空间和计算时间,继而在文档主题表示基础上采用余弦公式计算文本之间的相似度。
2.2 连线权重计算
在计算引文连线时,本文将传统遍历权重与语义权重相结合,形成连线综合权重,即
其中,weight(i,j)表示节点i和节点j之间的综合权重,由节点i和节点j之间的遍历权重weightt(i,j)和语义权重weights(i,j)组成。语义权重由节点i和节点j上文档的主题相似度计算得到;遍历权重根据1.2节中连线权重指标计算得到;α是一个取值区间为[0,1] 的超参数,用于调整连线上语义权重和遍历权重的占比。
与此同时,路径的权重计算方式也做了调整。传统主路径分析方法将路径上所有连线的权重进行累加,将其作为路径的权重。然而,这种方法被应用于语义权重会导致路径搜索过程中发生语义漂移。所谓语义漂移是指在一条路径中,直接相连的两个文档之间的主题具有一致性,但相隔较远的、间接相连的文档之间主题并不一致。以图3中的路径为例,节点1和节点2、节点2和节点3、节点3和节点4所依附的文本之间主题高度相似,但节点1和节点4的主题完全偏离。

图3 路径语义偏移示意图
为了解决这一问题,本文提出了一种新的路径权重计算方法,具体表示为
即在计算路径遍历权重时仍然沿用传统的连线权重累加方法,具体表示为
但在计算路径语义权重时,将该路径上所有节点两两配对,并将其主题相似度进行累加,表示为
由于路径语义权重和遍历权重的取值区间处于不同量级,因此,在计算路径综合权重时,需要将其规范化使其处于同一区间。本文选择常用的minmax规范化方法,最终路径的综合权重计算方法为
其中,Wp表示综合路径权重;min(weightp,s)和max(weightp,s)分别表示路径语义权重的最小值和最大值;min(weightp,t)和max(weightp,t)分别表示路径遍历权重的最小值和最大值;超参数β用于调节归一化处理后路径遍历权重与语义权重的比值,取值范围为[0,1] 。
2.3 主路径选择
所谓主路径选择,是指在利用路径搜索算法获取由每个源点引出的最大权重路径后,从这些最大权重路径集合中筛选主路径的过程。原语义主路径分析方法[2]使用基于聚类的主路径选择思路:①将候选路径上全部节点所依附的文本拼接起来,并采用向量表示,用于完成候选路径的向量化;②对候选路径向量应用密度聚类算法[41],并将其划分到不同聚簇中;③从每个聚簇所代表的子领域中遍历权重最大的候选路径代表这一聚簇的知识发展路径。但是,这种以遍历权重为标准的主路径选择方法可能导致所选主路径处于聚簇的边缘位置,无法代表这一聚簇的知识发展路径。
对此,本文将聚簇中代表候选路径的节点的密度和节点所在候选路径的遍历权重进行叠加,形成节点的复合密度,即
其中,ρ'表示节点复合密度,ρ表示节点原始密度,通过统计某节点周围单位面积中所包含的节点数量计算得到;weightp,t表示节点所在候选路径的遍历权重;γ表示用于调解原始密度与路径遍历权重的平衡参数,取值范围为[0,+∞)。本文方法的主路径选择过程是,在密度聚类算法框架下,使γ值从0开始逐步递增,并实时刷新复合密度下各个聚簇中心的变化情况,当聚簇中心的变化趋于稳定后,将各条位于不同聚簇中心的候选路径作为主路径结果输出。
3 实证分析
为展开对比分析以验证本文方法的有效性,本文沿用Chen等[2]使用的电动汽车锂离子电池专利数据集开展实证分析,并在3.4节的实验结果分析中辅以材料科学领域高影响力作者论文数据集,用于展示本文方法在不同学科领域和数据类型上的适用性。
3.1 数据介绍
本文数据集的数据来源为德温特创新索引数据库(Derwent Innovation Index Database),采用Zhang等[42]提出的检索式得到初步专利数据,经领域专家筛选、前向引用和后向引用扩充、专利家族合并、最大连通子图抽取后,得到包含3603个专利家族的独立引文网络,分为1248个源点、1085个中间节点和1270个终点。专利家族数量随基本专利发布年份的分布情况如图4所示。可以看到,电动汽车锂离子电池专利最早出现于1975年,1990年以后为快速发展时期。

图4 基于基本专利公开年份的专利家族数量分布
3.2 超参数调整和候选路径生成
本文遵循主路径方法的基础假设,即路径的遍历权重反映了经过该路径的知识流量。为使本文方法产生的主路径能够反映引文网络中的主要知识发展路径,这些主路径的遍历权重应该尽量接近传统主路径分析方法的路径遍历权重,同时融入尽可能多的语义信息以提升主路径的语义权重。需要说明的是,传统主路径方法是语义主路径方法β=0即不考虑语义信息的特殊情况,为调节超参数β达到上述目的,β不可能偏离原点较远。本文将β取值范围[0,1] 按0.01的单位步长进行划分,并将每个值分配给β以生成对应候选路径。由于引文网络中包含1248个源点,因此,每个β对应由1248条候选路径所组成的路径集合。图5展示了不同β取值下候选路径集合的最大遍历权重、最大语义权重以及平均综合权重变化情况。从图5a可以发现,最大遍历路径权不随β取值不同发生变化,即无论β如何取值,语义主路径搜索得到的遍历权重最大的路径是稳定的,它与传统主路径分析法输出主路径以及遍历权重保持一致;当β=0.05(图5中的垂直虚线)时,能够满足β在距离源点较近的前提下候选路径的两种类型权重的变化处于相对稳定状态,因此,将其作为β的数值,并生成相应的候选路径。

图5 不同路径权重随β值的变化情况
此外,考虑到公式(5)中引入语义路径权重的目的在于对多主路径各自的主题聚焦程度进行优化,为验证该公式的正确性,本文分别取β=0,0.05,1来考察当语义路径权重的重要性不断提升时,所抽取多主路径的变化情况。具体来说,本文将不同β值分别代入语义主路径分析法,并基于节点上的文本信息将抽取的多主路径连同其所在的引文网络分别投射到3个二维语义平面,如图6所示。可以发现,随着β的增加,各条主路径越发聚焦于单一子领域,这表明了公式(5)的正确性。

图6 不同β值下的多主路径在语义空间的分布
3.3 主路径选择
在改进密度聚类算法以选择主路径时,本文选取的改进对象是密度峰值聚类算法[41]。该聚类算法假设每个聚簇中心被具有较低局部密度的邻居包围,并且与具有较高局部密度的其他数据点的距离相对较大,因此,可以通过对比数据点的局部密度及其与较高密度数据点的距离来获得聚类数量和每个聚簇的中心点[43]。该算法的另一个优点是聚类过程不包含随机操作,因此,在相同配置下每次执行不会产生不同结果。
在使用公式(6)优化主路径的选取过程中,将γ的初始值设置为0,步长设定为1,根据每次γ增加后的候选路径密度与距离来更新各个聚簇中心,具体如表2所示。可以发现:①聚簇中心并不随γ值持续变化,而是当γ值位于临界点即表2第一列时,发生突然跳跃;②不同聚簇中心的跳跃并不同步,例如,当γ值由2增加到3时,编号为1的候选路径替代编号为160的候选路径成为路径1的聚簇中心,而其他聚簇中心保持不变;当γ值由172增加到173时,编号为62的候选路径替代编号为251的候选路径成为路径4的聚簇中心,而其他聚簇中心同样保持不变;③γ值的临界点数量有限,当γ取值超过最大临界点后,聚簇中心不再发生变化;④随着γ值的增加,各条位于聚簇中心的候选路径的路径长度和遍历权重不断提升,多主路径选择结果得到持续优化。

表2 中心路径随γ值的变化情况
同时,不同主路径的跳跃距离也存在很大区别。为了清楚展示这一现象,分别使用3种主路径选择策略:直接以聚簇中心所在候选路径作为主路径(简称“策略1”),如图7a所示;以聚簇中遍历权重最大的候选路径作为主路径(简称“策略2”),若有多个并列权重最大的候选路径则将其全部输出,如图7b所示;使用改进密度聚类算法在最大临界点,即γ=896时筛选出的主路径(简称“策略3”),如图7c所示。可以发现,相比于图7a中的各个聚簇中心点,即采用改进密度聚类算法时各条主路径的初始位置,优化结束后路径1、路径2和路径3的位置相对稳定,路径5略有变化,路径4变化最大。

图7 不同路径选择策略下的主路径分布
3.4 结果与分析
本节深入分析主路径上文献的文本内容,对本文方法的正确性、有效性及其与颠覆性技术之间的关系展开进一步探究。同时,为验证本文方法在不同科技领域和不同类型数据上的普适性,选取材料科学作为实证领域,对该领域高影响力作者论文引文网络展开主路径分析。
3.4.1 改进方法的正确性验证
本文调研了相关文献并获取电动汽车的主要架构,如图8[43]所示;本文提出的语义主路径的输出结果如图9所示,其含义如表3中策略3对应条目所示。可以发现,本文方法成功识别了大多数关于电池的电动汽车汽车组件,如路径1和路径2识别的电池控制器、路径3和路径4识别的电池设计技术以及路径5所识别的电机控制器。进一步地,由于每条主路径主题之间的区别较大,用户可以使用语义主路径分析法观察针对同一组件的不同研究方向,比如,尽管路径1和路径2都在讨论电池控制器,但路径1讨论的是温度控制技术,而路径2讨论的是充放电时电压、电流的控制技术和剩余电量的测度技术。根据文献调研可知,这些路径反映了电池管理系统(battery man‐agement system,BMS)中两个关键技术,即温度控制和充放电控制的发展轨迹[44-45]。此外,虽然路径5的遍历权重最小,但这并不意味着电机控制技术不重要,相反地,它是图8中电动汽车主要架构的组成部分,相较于锂离子电池,这部分内容相对独立。路径4与路径1虽然看起来内容较为相似,但是路径1主要描述电池的外在组件,例如,电池固定结构、电池保护套或者电池之间用到的冷却介质分配板;而路径4主要是基于电池组结构设计来达到电池冷却目的的技术路线。两条路径虽然均与电池技术相关,但是侧重点不同。上述实验结果和真实情况的相互印证,验证了本文方法的正确性。

表3 不同选择策略下的主路径主题汇总
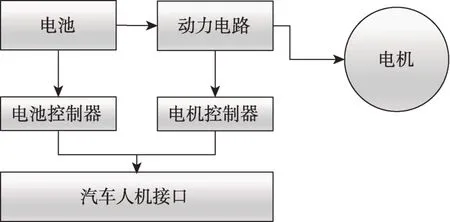
图8 电动汽车架构示意图[43]

图9 语义主路径抽取结果
3.4.2 改进方法的有效性及其能力验证
首先,分析三类策略所产生主路径的主题差异。从主路径在语义空间的布局(图7)可以看出,策略1的主路径结果经策略2调整后,路径1和路径5在保持路径主题没有发生变化或发生较小变化的情况下,提升了路径长度和遍历权重,路径2保持稳定不变,这表明Chen等[2]提出的语义主路径分析方法具备一定的主路径优化能力。路径3和路径4迁移至各自聚簇的边缘位置(图7b)。结合表3和表4可知,虽然路径3和路径4的长度和遍历权重得到了提升,两者主题相比于聚簇中心主题已经发生了较大变化:路径3的主题由“锂离子二级电池正极材料合成技术”转变为“电子、电气设备的二级电池技术”,路径4的主题由“电池冷却结构”转变为“锂二级电池技术和电池包技术”;而这些主题均处于各自聚簇的边缘位置,难以代表各自的知识发展脉络。需要说明的是,表3中主路径的主题采用人工方式提取,先获取主路径上所有节点所依附的文献摘要,再从中解读出主路径的主题内容。

表4 不同选择策略下主路径的统计信息
使用本文提出的策略3对策略1的主路径结果进行调整后,主路径的总体布局(图7c)相对于各个聚簇中心(图7a)基本保持稳定,只有路径4发生较大偏移。与策略2类似,经过策略3调整后,除路径2保持不变外,其他主路径的路径长度和遍历权重均取得了显著提升,但该策略带来的提升幅度弱于策略2。比如,路径3的遍历权重经过策略2调整后由1.07×10-4提升至4.76×10-3,但经策略3调整后提升至6.60×10-4;路径4的遍历权重经过策略2调整后提升至0.24,但经策略3调整后提升至0.22。从路径主题来看,策略3能够维持主路径的主题稳定。仍然以路径3和路径4为例,在策略3下,路径3的主题由“锂离子二级电池正极材料合成技术”转变为“包含锂成分的电池正极材料合成技术”,路径4的主题由“电池冷却结构”转变为“基于电池组结构设计的电池冷却技术”,这些主路径的主题并未发生变化。由此可见,本文方法(策略3)可以在保持主路径主题和聚簇中心主题一致的前提下,对路径长度和遍历权重进行优化,使主路径能够反映聚簇内的知识发展路径,且能够避免出现策略2中过于强调路径长度和遍历权重导致主路径主题发生偏离的问题。
3.4.3 主路径与颠覆性创新的关系探究
主路径是否包含颠覆式创新是一个值得探究的问题。其中颠覆性测度选用CD指数[46],该指标从后续引用角度,通过局域引用结构衡量专利对已有知识的替代作用和对未来专利的影响程度,并以此定义颠覆性。CD指数自2017年被提出后,分别于2019年和2022年被应用于两篇Nature文章中的颠覆性研究[47-48],引起科学界广泛关注与认可。本文采用CD指数测度实证专利的颠覆性,时间窗口按惯例设置为5年,从实证数据中共获得CD5=1的颠覆性专利家族121个(下文简称“颠覆性专利”),其公开年份分布如图10所示,不同策略下各条主路径上所包含的颠覆性专利数量如表5所示。在3种策略下,5条主路径包含的颠覆性专利数量极少,分别为1、1、2。
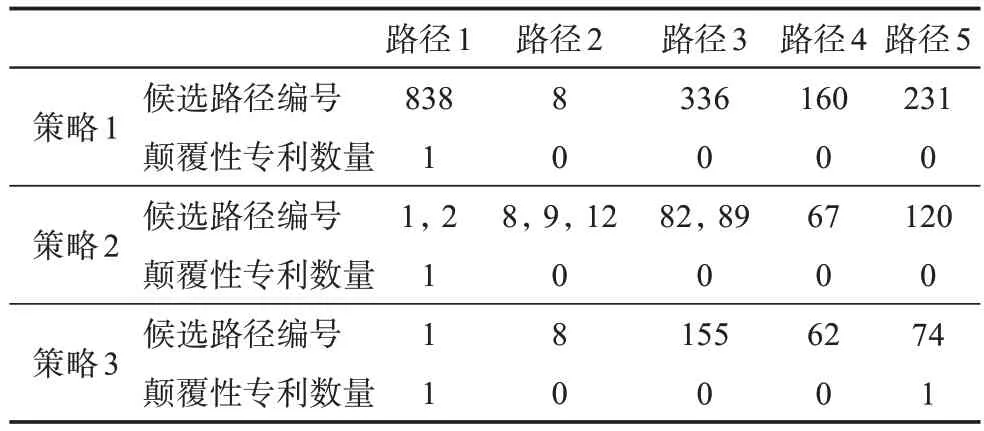
表5 不同选择策略下主路径的颠覆性专利家族数量
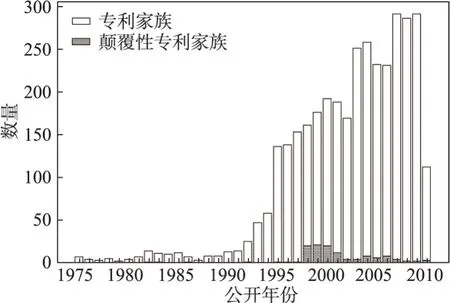
图10 专利家族及其颠覆性专利的数量分布
绘制不同年份颠覆性专利在语义空间的位置分布(图11),能够在一定程度上解释主路径上颠覆性专利稀少的原因。在图11中,从出现颠覆性专利的20个年份中较平均地选取了6个年份。对于每个年份,以1982年为例,在将实证数据集中公开年份在1982年及其之前的专利汇总后,利用MDS(multi-dimension scaling)方法将这些专利的文本信息投射到二维平面,并将1982年出现的颠覆性专利用灰底黑边方框凸显出来。从图11可见,在该数据集的前半阶段,即1982年、1986年和1995年,突破式革新技术因与传统技术在语义上差异较大,相应专利会出现在聚簇边缘位置,而且这些专利与同时期其他专利的语义相似度较弱,削弱了这个突破式专利进入主路径的可能性;在该数据集的后半阶段,虽然突破性专利同样难以进入主路径,但由于这一时期专利数量急剧增加,以及专利中技术公开的制度要求和申请者避免竞争对手发现、模仿己方技术之间的矛盾,专利中存在大量同义词、近义词、模糊术语、上下位概念替换等语言现象,使得颠覆性专利即使创造性很强,仍可能在语义空间上处于聚簇的中心位置,如图11d~图11f所示。
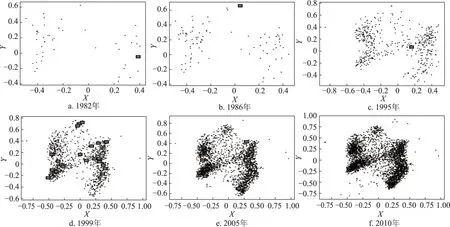
图11 不同年份颠覆性专利在语义空间的位置分布
3.4.4 材料科学领域实证分析
材料科学是一门多学科交叉的应用科学领域,在推动经济发展、社会建设和科技进步上应用广泛、潜力巨大。本文基于美国科学信息研究所(In‐stitute for Scientific Information,ISI)制定的高被引作者遴选方法[49],创建包含该领域中18569篇论文的高影响力作者论文引文网络,这些论文的发表时间为1964—2021年。其中,最大独立子网包括18504篇论文和119384条引文关系,该独立子网与电动汽车锂离子电池专利引文网络在常见网络指标上的描述性统计如表6所示,可以发现这两个网络存在显著差别:在节点数量上差距约为5倍,在连线数量上差距约为20倍。由此可见,论文引文网络的节点之间关联密切,其连线的稠密程度远高于专利引文网络,从而导致前者的层次数量虽然高于后者,但前者的网络直径和网络传递性却低于后者。
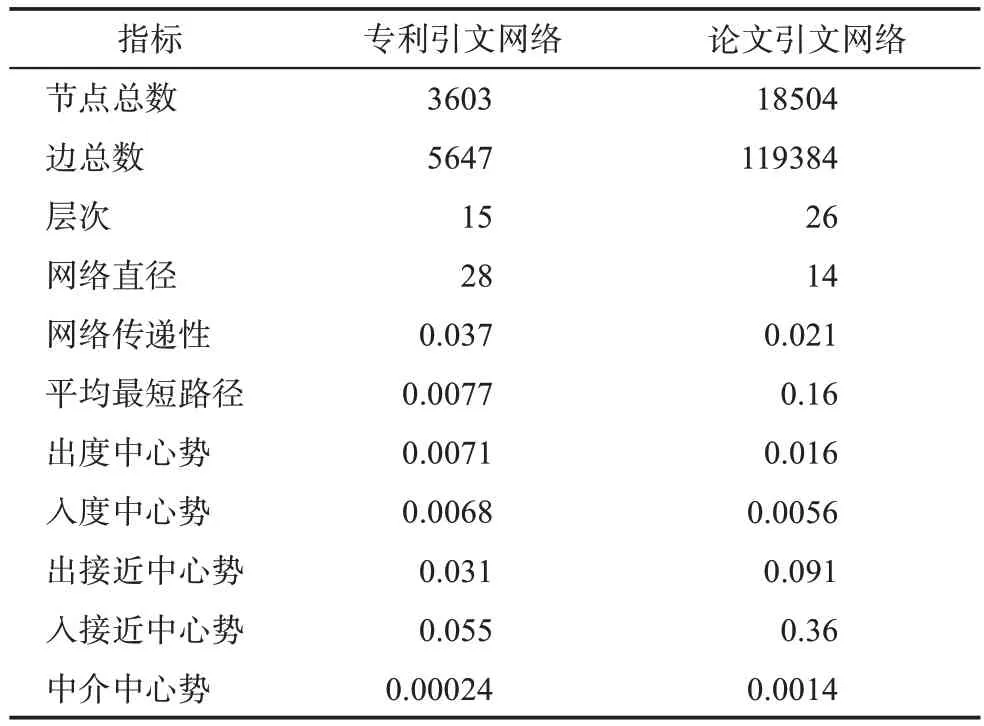
表6 两个引文网络的网络指标统计
通过执行策略2和策略3,对原语义主路径方法和改进后的方法展开对比分析。这两种策略产生的主路径的位置分布如图12所示,统计信息和主题含义如表7和表8所示,路径详情如图13所示。从表7可以看到,两种策略下得到的路径2、路径3和路径4完全相同。路径1中仅在初始的少许节点上存在差别,导致改进后的方法在该路径的长度上减少了1,但在路径遍历权重和主题上保持不变。路径5完全不同,在原语义主路径方法的主路径选择结果中,路径4和路径5在语义空间上距离过近,结合表7和表8可以看出,这两条路径均涉及电池电极制造,缺乏主题区分度,且路径5中仅包含3个节点、路径遍历权重为2.87×10-3,并不适合展示该领域中的知识发展脉络;经过本文方法优化后,路径5的节点数量增加至12,路径遍历权重增加至0.23(表7),更易于反映该领域的知识发展,同时该主路径在语义空间的位置与其他主路径距离较远(图12b),其主题为“基于金属卤化物的钙钛矿材料研究,可用于太阳能光伏发电”(表8),与其他路径主题存在明显区分度。

表7 不同策略下主路径的统计信息
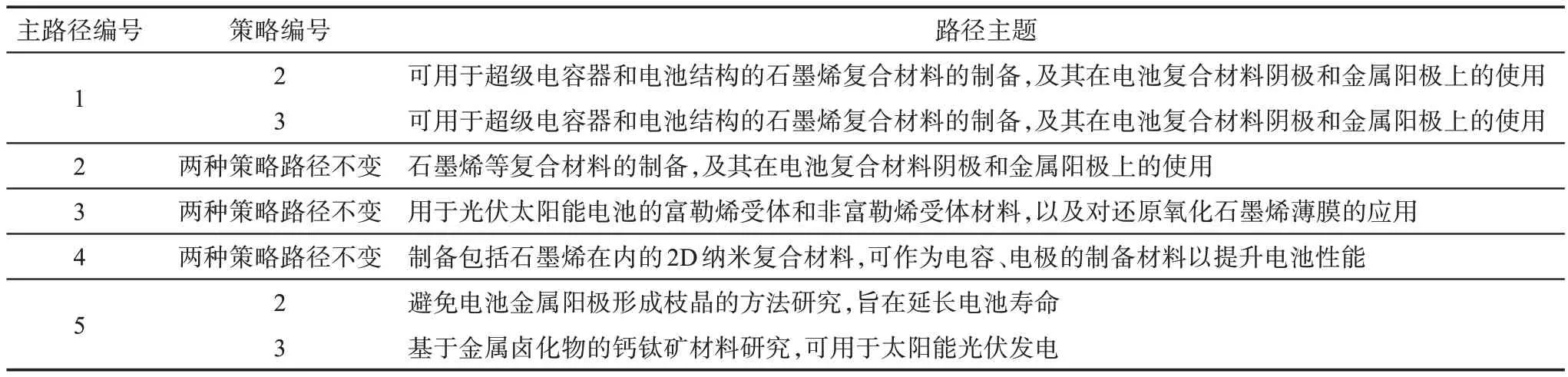
表8 不同策略下主路径的主题汇总

图12 不同策略下主路径在语义空间的布局

图13 不同策略下的主路径详情
4 总结与前瞻
主路径分析法因追踪领域知识发展脉络的强大能力,而被广泛用于科技情报领域,以确定科学、技术的主要发展过程。当引文网络规模庞大、结构复杂时,主路径分析法显著减轻了用户从过载信息中查找文献并将其梳理归纳为知识发展脉络的工作负担。然而,当政府管理者面临科技发展政策规划和战略方向判断、高校院所科研人员面临科技创新机会发现和研究计划制订、企业研发人员面临技术路线选择和未来态势研判时,传统主路径分析方法侧重于单一知识发展脉络抽取、全景覆盖能力羸弱的特点,使之难以应对这些应用场景;语义主路径分析法则给出一套更为科学、合理、有效的解决方案,但其在主路径选择时,偏重于路径遍历权重的做法使得部分主路径偏离聚簇中心,不仅在能否代表这一子领域知识发展脉络方面存疑,而且不同主路径的主题可能相互重叠,区分并不明显。对此,本文提出一种基于改进密度聚类算法的语义主路径分析方法,即把候选路径聚簇密度和路径遍历权重进行叠加形成复合密度,通过调节复合密度中两个要素的比重来优化主题聚簇中心的定位;聚簇中心的位置变化收敛后,将位于不同主题聚簇中心的路径作为结果输出。
为验证本文方法的有效性和普适性,本文选取两个完全不同领域、不同类型的数据集展开实证分析,即电动汽车锂离子电池专利数据集和材料科学高影响力作者论文引文数据集。研究结果表明,在这两类数据集中,本文方法均可以显著优化部分主路径偏离聚簇中心的现象,避免了其在语义空间和路径遍历权重之间的失衡。然而,该方法仍然存在可优化之处,在复合密度调节过程中,聚簇中心的数量会发生变化,因此,需要人工干预以使聚簇中心的数量保持不变;如何在彻底避免人工干预的情况下实现主路径的优化选取,是未来重要研究任务之一。当前,各类主路径分析方法使用的引文网络通常聚焦于某领域的局部引文网络,在构建网络过程中,难免出现数据遗漏或者噪声现象,影响主路径的结果;而基于全局引文网络的测度指标如CD指数,则给出了良好的启发,即形成基于全局引文网络的节点或连线重要性测度指标,以获得更加稳健的主路径分析结果。本文还发现,主路径难以将高颠覆性文献纳入其中;然而,颠覆性是测度文献创造性和影响力的重要指标,因此,如何将颠覆性测度指标与主路径分析方法相结合,形成由最具颠覆性的文献串联起来的知识发展脉络,也是未来重要研究方向之一。
猜你喜欢
快乐语文(2021年27期)2021-11-24 01:29:24
快乐语文(2021年11期)2021-07-20 07:41:48
快乐语文(2020年36期)2021-01-14 01:10:44
当代陕西(2020年17期)2020-10-28 08:18:18
开放教育研究(2020年2期)2020-03-31 01:54:14
快乐语文(2019年12期)2019-06-12 08:41:56
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
