
面向真实场景的单帧红外图像超分辨率重建
2024-04-29 03:21:46师奕峰毛文彪李发明王添福张济清姚立斌
红外技术 2024年4期
师奕峰,陈 楠,朱 芳,毛文彪,李发明,王添福,张济清,姚立斌
面向真实场景的单帧红外图像超分辨率重建
师奕峰,陈 楠,朱 芳,毛文彪,李发明,王添福,张济清,姚立斌
(昆明物理研究所,云南 昆明 650223)
现有的红外图像超分辨率重建方法主要依赖实验数据进行设计,但在面对真实环境中的复杂退化情况时,它们往往无法稳定地表现。针对这一挑战,本文提出了一种基于深度学习的新颖方法,专门针对真实场景下的红外图像超分辨率重建,构建了一个模拟真实场景下红外图像退化的模型,并提出了一个融合通道注意力与密集连接的网络结构。该结构旨在增强特征提取和图像重建能力,从而有效地提升真实场景下低分辨率红外图像的空间分辨率。通过一系列消融实验和与现有超分辨率方法的对比实验,本文方法展现了其在真实场景下红外图像处理中的有效性和优越性。实验结果显示,本文方法能够生成更锐利的边缘,并有效地消除噪声和模糊,从而显著提高图像的视觉质量。
红外图像;深度学习;超分辨;真实场景;退化模型
0 引言
红外成像技术广泛应用于安防、电力、交通、医疗、科研等领域。红外热像仪是红外热像技术的核心产品,是红外热像技术的重要组成部分,高分辨率的红外热像仪能够提供更加清晰的红外图像,从而更好地满足用户的需求。但与可见光成像技术相比,红外成像技术的图像分辨率较低,原因主要有以下几点:①红外波段的波长相比于可见光波长较长,根据瑞利分辨率准则,较长的波长会导致成像系统空间分辨率降低;②红外探测器的像元尺寸通常较大,这是因为制造过程中需要权衡探测器灵敏度和空间分辨率,较大的像素尺寸会减少单位面积上的像素数量,从而降低空间分辨率;③红外探测器制造过程中可能会遇到更多技术挑战,如非均匀性、材料缺陷、铟柱互连的成功率等,这些问题可能导致成像系统在空间分辨率方面的性能下降。此外,在某些应用中,红外热像仪为了在成本和体积上达到平衡,可能需要选择具有较低空间分辨率的探测器。尽管红外成像技术在空间分辨率方面存在上述挑战,但随着科学技术的不断发展,超分辨率重建技术也应运而生,该方法能够在不增加探测器像元数量的前提下利用算法提升分辨率。
单帧图像超分辨(single-frame image super-resolution, SISR)是指从一幅低分辨率(low resolution, LR)图像中恢复出具有更高分辨率(high resolution, HR)的图像。传统的超分辨率方法主要包括插值方法、基于学习的方法和基于稀疏表示的方法等。然而,这些方法在面对复杂真实场景的红外图像时,往往受到噪声、模糊和退化等因素的影响,性能受限。因此,如何在真实场景中有效地提高红外图像的空间分辨率成为了一个亟待解决的问题。
近年来,卷积神经网络(convolutional neural networks, CNN)在图像处理领域,尤其是可见光图像超分辨率上,取得了令人瞩目的成果[1-6]。这些基于深度学习的超分辨率方法能够有效地从众多的训练样本中学习图像的高阶特征,从而显著提升图像的空间分辨率。尽管大部分现有方法主要针对可见光图像,但也有一些研究尝试将深度学习应用于红外图像超分辨率[7-15]。然而,这些红外超分方法在实际应用中并未达到预期效果。这暗示在真实场景下,红外图像超分辨率重建的深度学习方法仍然存在较大的优化空间。
本文针对真实场景下的红外图像超分辨率重建问题,提出了一种基于深度学习的方法。该研究的主要贡献可以归纳为以下两个方面:
1)构建了红外图像退化模型,模拟真实场景下的红外图像退化。利用此模型生成了模拟真实场景的红外图像训练数据集,确保处理各种真实退化情况。
2)提出了一个融合了通道注意力[16]与密集连接[17]的网络结构。此结构旨在增强特征提取及图像重建能力,从而有效地对真实场景下的低分辨率图像进行超分辨率重建。
1 相关工作
1.1 基于深度学习的超分辨率重建
在深度学习领域,超分辨率重建常被建模为一个端到端的监督学习任务。利用低分辨率(low resolution, LR)图像和其对应的高分辨率(high resolution, HR)图像作为训练数据,目标是确定一个非线性映射,也被称为模型,此模型旨在将LR图像映射到HR图像。训练中使用的损失函数用于度量模型输出与实际HR图像之间的偏差。此损失函数可以基于像素(例如均方误差损失或L1损失)或基于感知(例如感知损失)。通过最小化损失函数,可以逐步优化模型,使其能够将LR图像重建为更高质量的HR图像。因此,超分辨率重建问题可以被建模为以下优化问题:

式中:为损失函数;为模型;为模型中的参数;LR代表LR图像;HR代表HR图像。
目前,CNN在可见光图像超分辨率重建领域展现出了很好的性能,各种深度学习方法的发展,如SRCNN(super-resolution convolutional neural network)[3]、ESPCN(efficient sub-pixel convolutional neural network)[4]、EDSR(enhanced deep super-resolution network)[5]、ESRGAN(enhanced super-resolution generative adversarial network)[6]等,为可见光图像超分辨率问题提供了丰富的解决方案。SRCNN作为第一个成功应用于超分辨率问题的CNN模型,其优点在于采用三层网络结构来从LR图像中学习复杂的非线性映射关系以重建HR图像,但其网络结构较为简单,可能无法获取图像的深层次特征。ESPCN进一步优化了性能和计算效率,它主要在LR空间中执行计算,大大降低了运算量,然后通过亚像素卷积层,将多通道LR特征图直接排列得到HR图像,避免了在HR空间上的昂贵计算,但它可能在处理某些复杂图像时效果不理想。而EDSR和ESRGAN则利用了更深层次的网络结构和新的技术如残差学习和GANs,以提取更精细的图像特征并生成更清晰的高分辨率图像,虽然这两种方法能够产生高质量的结果,但由于网络深度和复杂度较高,需要较大的计算资源和处理时间。
在红外图像超分辨率重建领域,许多研究团队提出了各种方法和技术。这些方法大致可归为以下类:
1)提升计算效率的方法
Sun等人[7]提出了一种基于缩放机制的快速红外图像超分辨率方法,旨在克服现有方法在速度和精度上的性能限制。该方法引入了一种反卷积层和池化层相结合的缩放机制,大大减少了计算复杂度。Oz等人[10]的方法主要在LR域内完成大部分计算,聚合网络中每层的结果以实现更好的信息流。其所采用的深度可分离卷积,只需大约300k次乘积累加计算,进一步降低计算复杂度。
2)提升模型特征提取和重建能力的方法
Suryanarayana等人[8]针对低密度焦平面阵列的红外成像系统,设计了一种基于多尺度显著性检测和深度小波残差学习的超分辨率技术。该方法整合显著性特征图到LR图像的高频子带中,然后通过深度卷积神经网络学习得到的残差进行融合。Zou等人[11]提出了一种基于跳跃连接的卷积神经网络的红外图像超分辨率重建方法。该方法引入全局残差学习和局部残差学习,降低了计算复杂性并加速了网络收敛。李方彪等人[12]提出了一种基于生成对抗网络的多帧红外图像超分辨率重建方法。其针对GAN(Generative Adversarial Network)在图像重建后可能出现的过度平滑和缺乏高频细节信息的问题,对LR图像序列进行运动补偿,利用权值表示卷积层对补偿后的图像序列进行权值转换计算。胡蕾等人[14]设计了一种改进的SRGAN算法来提高红外图像的分辨率。该改进包括在生成网络中使用密集残差网络获取各网络层提取的图像特征以保留图像的更多高频信息。
3)结合其他先验知识进行优化的方法
Yao等人[9]提出了一种基于判别字典和深度残差网络的红外图像超分辨率方法。该方法结合了压缩感知和深度学习的优点,引入了一种判别字典学习方法,通过这种方式从训练数据集中学习一个共享的子字典和一系列特定的子字典,以更精确地表达每个图像的特征。魏子康等人[13]提出了一种改进的深度复合残差网络模型。该模型改进了原有的残差块,充分利用残差块内部的所有卷积层特征信息,提高生成图像的质量。同时,采用迁移学习的方法,在深度网络结构中增强图像特征信息,使模型性能更稳定。邱德粉等人[15]提出了一种新的神经网络模型,该模型使用HR可见光图像引导红外图像进行超分辨率重建。该方法通过基于引导Transformer的信息引导与融合方法,从HR可见光图像中搜索相关纹理信息,并将这些相关纹理信息与LR红外图像的信息融合,生成合成特征。然后通过超分辨率重建子网络对这个合成特征进行处理,得到最终的超分辨率红外图像。
虽然这些方法在实验数据上展现了一定的性能,但它们在真实场景下的适应性还有待进一步探讨。考虑到超分辨率技术面临的挑战,这些方法在处理真实世界数据时可能会遇到如噪声干扰、数据差异和模型过拟合等问题。未来研究的方向应在提高这些方法在实际场景中的泛化能力。
1.2 退化模型
在基于深度学习的图像超分辨率重建中,为了弥补数据的不足和提高模型的泛化能力,研究人员通常会借助于退化模型合成LR图像。退化模型描述了HR图像在经受各种影响,如模糊、噪声和下采样等因素后,退化为LR图像的过程。式(2)是超分辨率重建研究中常用的经典退化模型:
LR=(HRÄ)↓s+(2)
尽管上述经典退化模型对于某些情况有一定的效果,它们可能在面对某些真实场景的复杂退化现象时表现不足,例如面对红外图像传感器产生的噪声和由于移动引起的模糊。为了更有效地恢复红外图像的细节,有必要采纳或设计更为细致和贴近实际的退化模型。近些年,许多专注于可见光超分辨率的研究者也意识到这一点,开始探索更为精细的退化模型以优化图像细节的恢复。
Zhang等人[18]提出了一个由随机打乱的模糊、下采样和噪声退化组成的退化模型。该模型中,模糊核从各向同性和各向异性高斯模糊核中随机选取,下采样是通过从最近、双线性和双三次插值中随机选择的方式实现,而噪声则是通过添加不同噪声等级的高斯噪声、不同质量因子的JPEG压缩来模拟。
考虑到图像可能会经过多次编辑、传输处理,为了更好地模拟该类退化,Wang等人[19]提出了高阶退化模型。该模型不同于传统的一阶退化模型仅进行一次处理,而是进行多次重复处理,以更好地模拟实际环境中的各种图像退化。虽然这个改进的高阶退化过程并不能完全覆盖真实世界中的所有退化情况,但它确实扩大了超分辨率方法所能解决的退化边界。
虽然上述两个模型在模拟退化过程中考虑了全谱的退化类型,但却忽略了许多在真实世界中常见的特殊情况。为了解决这个问题,Zhang等人[20]提出了统一门控退化模型,可以通过随机门控制器生成广泛的退化情况,包括经典退化和复杂退化,以及许多其他特殊情况。
总体而言,这些模型都在模拟真实世界退化的准确性和完备性方面做出了一定的进步,为当前的超分辨率研究提供了宝贵的参考。值得注意的是,尽管这些研究主要集中在可见光领域,但红外图像与可见光图像在某些退化方面存在相似性。因此,结合并引入这些先进的退化模型至红外超分辨率领域或许能为真实场景下的红外图像超分辨率重建提供新的思路和方向。
2 面向真实场景的红外图像超分辨率重建
2.1 红外图像退化模型
为了准确地模拟红外图像的退化,并克服经典退化模型的局限性,本文提出了一种更加接近实际情况的退化模型,如图1所示。本模型综合了二阶退化模型[19]与门控退化模型[20]的先进研究成果,全面考虑了影响红外成像质量的各种因素。与常规模型相比,所提出的退化模型不仅涵盖了如高斯模糊和高斯白噪声这类常见退化因子,还创新地引入了散粒噪声、盲元、运动模糊等更复杂的退化情况,从而更全面地再现了红外图像在实际应用中的退化特性。
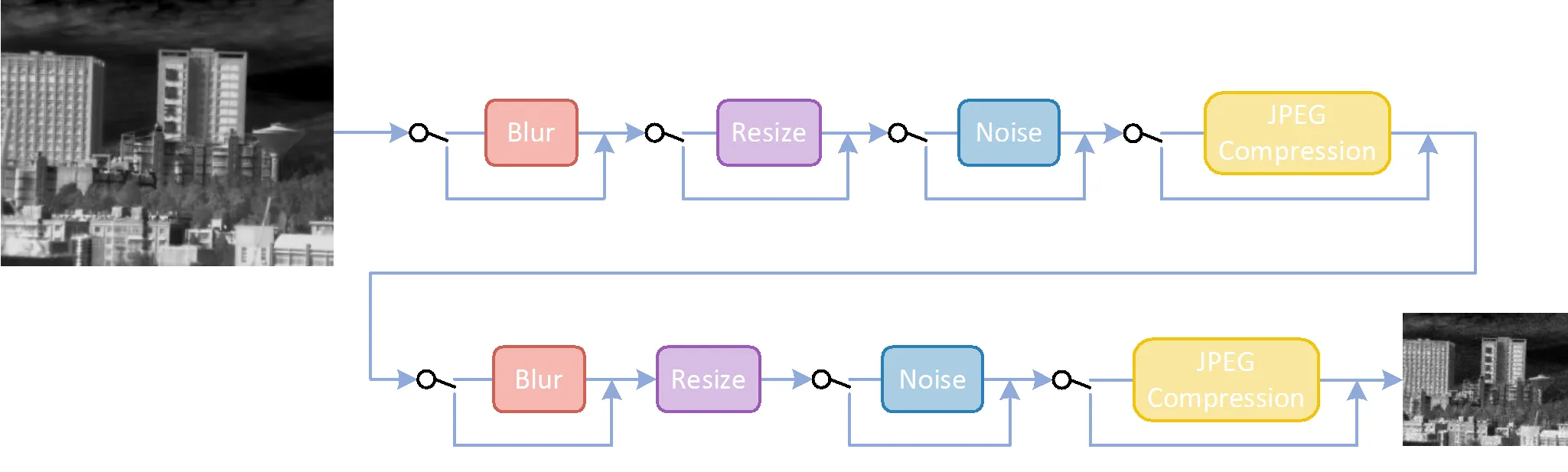
图1 本文提出的红外图像退化模型
本文所提出的退化模型可描述为下式:
=(1)(2)…(m) (4)

式中:表示一阶退化;2表示二阶退化;D表示第个退化因子,且DÎ{b,r,n,j},b、r、n和j分别代表模糊、缩放、噪声和JPEG压缩;表示恒等变换;表示门控激活函数,为服从二项分布(1, 0.5)的随机变量(即,每个退化因子有一半的概率不进行任何处理)。通过将退化操作应用两次,可以模拟各种可能的退化组合,从而获得更为多样化的LR图像。接下来将介绍每个退化因子的细节。
1)模糊(b):模糊操作主要用于模拟成像过程中的光学模糊现象,如失焦、运动模糊等。本文采用的模糊核从高斯模糊核、广义高斯模糊核和台形模糊核中随机选取,这些模糊核的概率密度函数分别为:
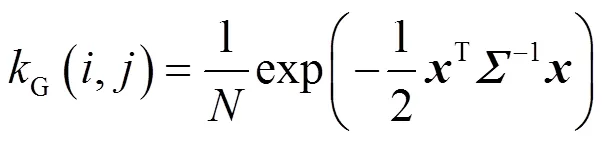
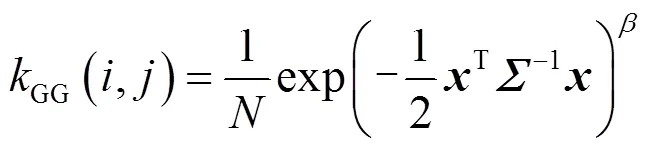
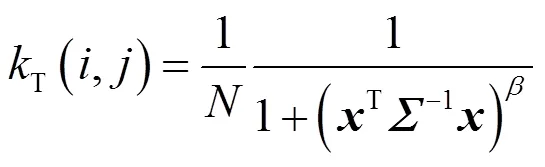
式中:是归一化因子;是协方差矩阵;=[,]T是像素坐标;是形状控制参数。协方差矩阵可以进一步表示为:
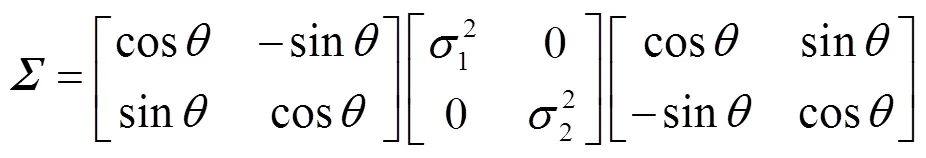
式中:1和2是模糊核沿水平和垂直两个方向的标准差;是旋转角度。实验中,选取高斯模糊、广义高斯模糊和台形模糊的概率分别为0.7、0.15和0.15;模糊核的大小从{3,5,7,…, 21}中随机选取;标准差1和2从均匀分布[0.2,3]中随机采样;旋转角从均匀分布[0,p]中随机采样;对于广义高斯模糊和台形模糊,形状参数分别从均匀分布[0.5,4]和[1,2]中随机采样。
2)缩放(r):在退化模型的构建中,缩放操作是关键步骤。不同于其他方法仅进行单次下采样直接达到目标尺寸,本文采用的二阶退化模型允许图像在第一次缩放时进行随机的下采样或上采样,随后在第二次缩放时再调整至目标尺寸。实验中,缩放过程通过插值方法实现,插值算法将从线性插值、双三次插值和面积插值中等概率选取;第一次缩放的缩放因子从均匀分布[0.2,2]中随机采样。
2.公共危机类型。公共危机事件有多种,分类方法也很多,其中最传统的划分可分为:一种是自然原因造成的,例如地震、台风、水灾、火山爆发、海啸、雪灾、干旱、泥石流等自然灾害;另一种是社会原因造成的,比如战争、罢工、社会骚乱、恐怖袭击、舆论危机等等。但是在现代社会里,要精确区分公共危机是纯粹自然原因导致的,还是社会原因导致的,也会比较模糊,比如说几年前南方特大雪灾,它不仅仅是一次自然灾害,它与电力设施建设、管理体制等是有关系的。也有两种情形兼备的,既有自然的因素,也有人为原因,如矿难、瘟疫等。
3)噪声(n)
噪声是红外图像成像过程中不可避免的影响因素。在真实场景下,图像噪声的分布可能远比高斯白噪声更复杂,如散粒噪声、盲元、热噪声等。因此,本文采用泊松分布、柯西分布和高斯分布进行模拟,这些噪声模型可分别描述为:
(LR=HR+p)~(HR) (10)
LR=HR+c,c~C(0,) (11)
LR=HR+n,n~(0,2) (12)
式中:p、c和n分别表示泊松噪声、柯西噪声和高斯噪声;、和分别为其对应的分布。实验中,选取不同类型噪声的概率均为1/3;高斯噪声的标准差从均匀分布[1,30]中随机采样;柯西噪声的参数从均匀分布[0.1,1]中随机采样。
4)JPEG压缩(j):JPEG压缩是一种广泛应用于图像存储和传输的有损压缩算法。在实际应用中,由于存储空间和传输带宽的限制,红外图像往往需要进行压缩。然而,JPEG压缩过程可能导致图像细节丢失和压缩伪影产生。为了模拟这种退化效果,本文在生成LR红外图像时引入了JPEG压缩操作。实验中,压缩质量因子从{30,31,32,…, 95}中随机选取,以模拟不同压缩程度下的图像质量损失。
通过对上述退化因子随机地处理或不处理,以及对其参数随机地设置,可以实现一个全面而复杂的图像退化模拟。通过这种方式,可以生成大量的LR-HR图像对,用于训练超分辨率网络,以提高其在处理真实世界LR图像时的性能。
2.2 网络结构
本文提出的超分辨率重建网络采用了通道注意力[16]和密集连接[17]相结合的复合网络结构,旨在充分提取和利用LR红外图像中的特征信息,以实现高质量的超分辨率重建,如图2所示。网络结构分为3个主要模块:浅层特征提取、深层特征提取和重建。
1)浅层特征提取:该模块仅包含一个3×3卷积层,对输入的LR红外图像进行初步特征提取,能够捕捉图像中的基本纹理和边缘信息,为后续的特征提取和重建过程提供基础。本模块可由下式表示:
0=SF(LR) (13)
式中:SF表示浅层特征提取模块;LRÎ1××为LR红外图像;0Î××为浅层特征提取得到的特征图。
2)深层特征提取:在浅层特征提取的基础上,网络进一步通过多个相同的RCADB(residual channel attention dense block)模块(如图2(b)所示)和一层卷积层进行深层特征提取。每个RCADB模块包含了3个相同的CADB(channel attention dense block)模块(如图2(c)所示),并引入了残差连接,使网络更好地学习高频细节信息。CADB模块整合了通道注意力机制、密集连接结构和局部残差连接,旨在获取更为丰富的层次特征。通道注意力机制能自适应地为不同通道的特征分配权重,从而强化关键信息并提升网络的表达能力。而密集连接结构则有益于梯度传播和特征重用的增强,使网络能更为有效地捕捉图像中的复杂信息。为进一步提升特征提取效果,整个深层特征提取模块还加入了全局残差连接,使得浅层特征能够直接与深层特征融合,从而增强整个网络的学习能力。通过深层特征提取,网络得以捕捉LR红外图像中的高级语义信息,为后续的重建过程提供更为丰富的特征支持。本模块可由下式表示:
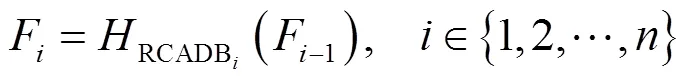
D=0+Conv(n) (15)
图2 红外图像超分辨率重建网络结构
Fig.2 Structure of infrared image super-resolution reconstruction network
3)重建:在完成浅层和深层特征提取后,网络将这些特征信息进行融合和上采样,以生成SR红外图像。在重建过程中,网络采用了上采样接卷积层的结构,以逐步提高图像分辨率。通过这一阶段的操作,网络最终实现对LR红外图像的高质量超分辨率重建。本模块可由式(16)表示:
SR=REC(D) (16)
式中:REC表示重建模块;SRÎ1××为输出的SR红外图像。
综上所述,本文提出的通道注意力和密集连接相结合的复合网络结构充分利用了LR红外图像中的特征信息,实现了高质量的SR图像重建。
3 实验与结果分析
3.1 数据集说明
训练数据来自艾睿红外开源数据平台,该平台提供了大量红外图像,涵盖了多种场景和目标。为方便批处理,裁切为224×224大小,总共91776张图像。
测试数据为南京理工大学开源的红外图像数据集(700张图像)以及笔者使用热像仪采集的红外图像数据(100张图像)。这两个测试数据集包含了不同的场景和环境条件,有助于评估网络在真实场景下的泛化能力。
3.2 网络结构参数说明
本节将详细介绍第2.2节所提出的红外图像超分辨率重建网络的参数。浅层特征提取模块为一个3×3卷积层,该卷积层输入通道为1,输出通道为64。深层特征提取模块中RCADB模块数设置为3;该模块最后的卷积层核大小为3×3,输入输出通道均为64。RCADB模块中包含3个结构相同的CADB模块,CADB模块中的密集连接和通道注意力结构的参数如表1和表2所示。重建模块的参数如表3所示,上采样层采用的方法为最近邻插值。
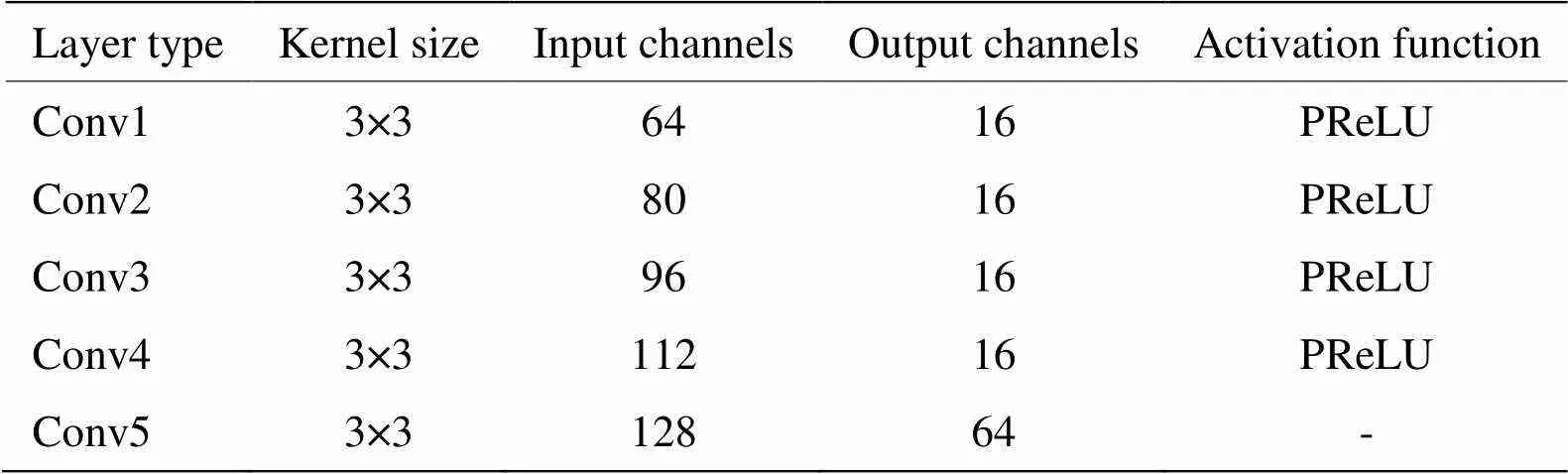
表1 CADB模块中的密集连接结构参数
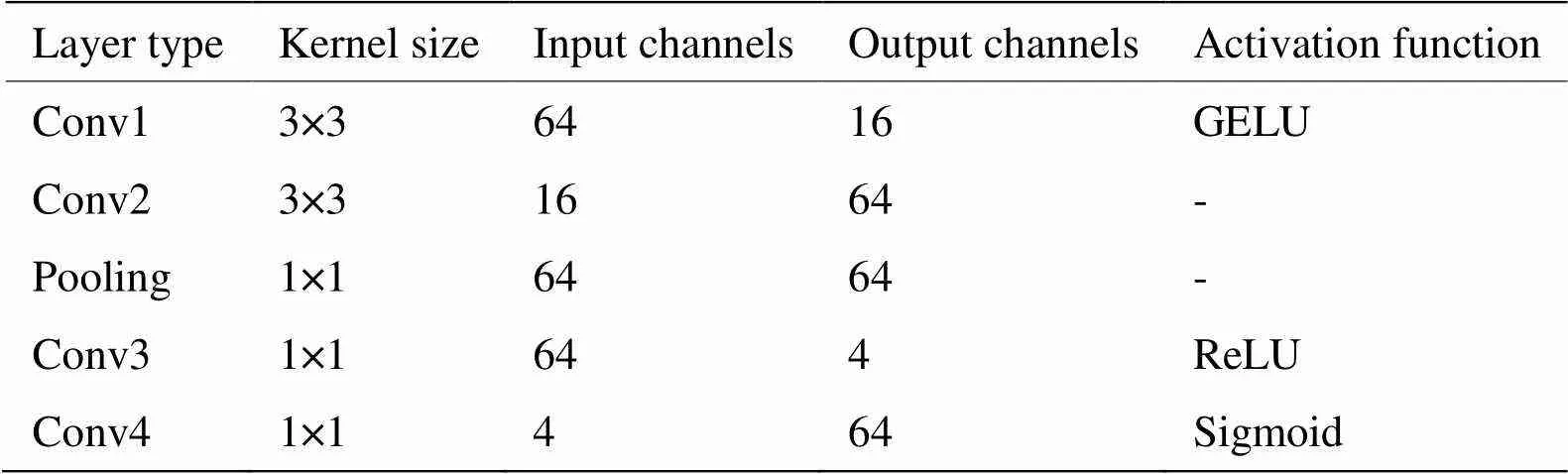
表2 CADB模块中的通道注意力结构参数

表3 重建模块参数
3.3 训练说明
实验采用PyTorch框架实现,并在NVIDIA V100 GPU上进行训练。损失函数采用L1损失,优化器为Adam,初始学习率设置为2×10-4,同时利用学习率衰减策略进行调整。在模型训练过程中,批量大小设置为32,epoch设置为50。
如图3所示,训练时首先将HR图像输入至退化模型处理得到LR图像,然后利用LR-HR图像对训练超分辨网络。

图3 训练流程示意图
3.4 客观评价指标说明
在超分辨率重建研究中,常用的评价指标为PSNR(peak signal-to-noise ratio)和SSIM(structural similarity)。PSNR主要测量待评价图像与参考图像之间的像素差异的均方误差,SSIM则是从亮度、对比度和结构3方面进行衡量。随着新算法的不断涌现,图像超分的性能不断提升,而PSNR和SSIM与主观感知质量之间的一致性却逐渐降低。这是因为,这两种指标主要强调像素级的相似性,无法充分反映人眼的视觉感知。研究表明,在以人眼感知为导向的图像处理领域,PSNR和SSIM这类指标衡量的图像失真程度与人们实际感知到的图像质量往往存在矛盾[22-24]。此外,PSNR和SSIM在评估过程中需要原始HR图像作为参考,但在许多实际应用场景中,获取原始HR图像并不可行,进一步限制了这些指标的应用范围。
基于上述考虑,本文采用了无参考图像质量评估指标,包括NIQE(natural image quality evaluator)[25]、BRISQUE(blind/referenceless image spatial quality evaluator)[26]和PI(perceptual index)[27],以更全面地评估超分辨率重建效果。NIQE通过对一系列高质量自然图像的统计特征进行学习,创建了一个特征库。评估时,它计算待评估图像的特征,并与该特征库进行比较,从而计算出质量分数。BRISQUE采用类似的方法,但专注于图像的空间质量评估。PI则结合了多种视觉感知指标,提供了一个综合性的图像质量评分。对于上述3种评价方法,越低的分数代表着更高的感知质量。
3.5 消融实验
为验证退化模型的有效性,首先进行了消融实验。该实验中引入了Ours-ND(no degradation)版本,这是一个未采用退化模型的变体。在Ours-ND中,通过简单的下采样直接从HR图像生成LR图像,旨在探究退化模型在红外图像超分辨率任务中的作用和影响。
表4和图4所展示的消融实验结果共同表明,本文所提方法在2×和4×倍超分辨率下明显优于未采用退化模型的变体。尤其在图4中对比展示的2×倍超分结果中,加入退化模型后,生成的图像不仅更加均匀,还显著消除了噪点。这些结果强调了复杂退化模型在提升红外图像超分辨率质量中的关键作用,并展现了其在实际红外图像处理中的有效性和实用性。

表4 不同超分倍数下本文方法与无退化模型变体的无参考图像质量评价指标比较

图4 本文方法与无退化模型变体的2×超分结果对比
3.6 对比实验
为全面验证所提方法在真实场景下红外图像超分辨率任务中的有效性,进行了与多种先进超分辨率方法的对比。包括专门针对红外图像的超分辨率方法,如Oz等人[10]提出的方法(Oz)和Zou等人[11]提出的方法(Zou),以及在可见光领域广泛应用的方法,例如SRCNN[3]、ESRGAN[6]和SwinIR[21]。
表5所示的对比实验结果突显了本文方法在真实场景下不同超分倍数下的显著优势。通过与现有先进超分辨率方法比较,本文方法在无参考图像质量评价指标BRISQUE、NIQE和PI上均展现出优秀的性能。
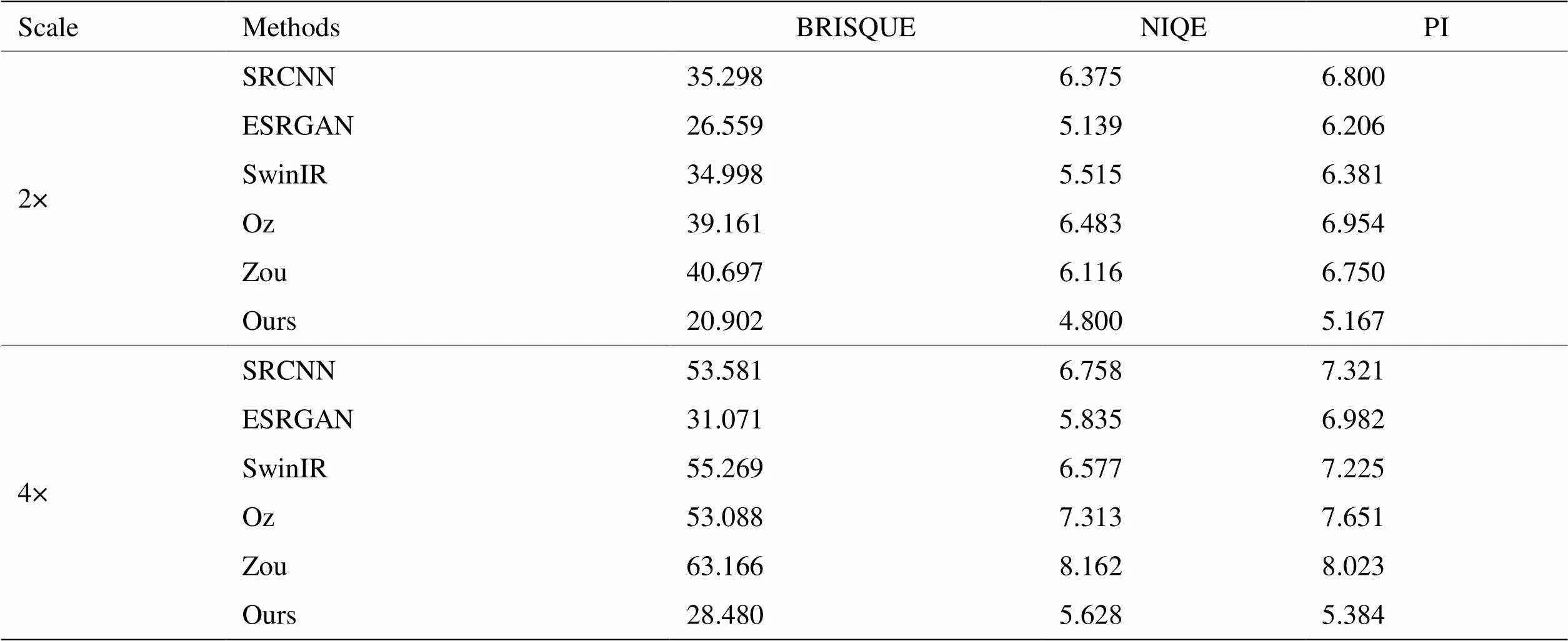
表5 不同超分倍数下本文方法与其他超分辨率方法在无参考图像质量评价指标上的比较
在主观评价层面,图5~图8中各场景下的超分辨率图像对比明显,展示了本研究方法的优势。所生成的超分辨率图像中的边缘更为锐利,如图5和图7中窗户边框的清晰展现,这对于增强红外图像的清晰度和细节表现至关重要。同时,本研究所生成的图像显得更自然,纹理细节更加丰富,如图6中瓦片的细腻纹理。此外,与其他方法相比,本研究的方法在消除图像噪声和减少模糊效应方面表现更为卓越,例如图8中整体图像的平滑度以及噪点几乎完全消除,同时保留了原始的纹理信息。这一效果得益于退化模型中对模糊和噪声等因子的有效利用,使得所提出的网络能够有效地去除模糊并消除噪声。这些优势不仅提升了图像的整体视觉质量,也在真实场景下的红外图像处理中展现了其实用性和高效性。
因此,综合以上客观和主观评价结果,可以进一步证明本文提出的方法在红外图像超分辨率领域的应用潜力和实际效果。

图5 不同方法在场景1下2×倍超分结果对比

图6 不同方法在场景2下2×倍超分结果对比

图7 不同方法在场景3下4×倍超分结果对比

图8 不同方法在场景4下4×倍超分结果对比
4 结论
本研究针对真实场景下的红外图像超分辨率重建问题,提出并验证了一种基于深度学习的方法。与传统方法相比,本文的主要创新在于构建了一个模拟真实场景退化的模型,并设计了一种结合通道注意力和密集连接的网络结构。通过一系列消融实验和对比实验,验证了所提方法在提升真实场景下低分辨率红外图像的空间分辨率方面的有效性,以及在实际应用场景中的实用性和可靠性。尤其是在去噪和去模糊方面,本文方法展现了明显的优势。
尽管本研究取得了一定的成果,但在真实场景下的超分辨率图像重建仍面临许多挑战。未来的工作将集中于进一步提升模型的泛化能力,减少对大量训练数据的依赖,并探索更有效的方法来处理极端的退化情况。此外,我们也将探讨将本研究的方法应用于其他类型的图像处理任务,例如图像去噪、图像增强等,以验证其在广泛应用场景中的有效性和灵活性。
[1] WANG Z, CHEN J, Hoi S C H. Deep learning for image super-resolution: A survey[J]., 2020, 43(10): 3365-3387.
[2] LI J, PEI Z, ZENG T. From beginner to master: A survey for deep learning-based single-image super-resolution[J]. arXiv preprint arXiv:2109.14335, 2021.
[3] DONG C, LOY C C, HE K, et al. Image super-resolution using deep convolutional networks[J], 2015, 38(2): 295-307.
[4] SHI W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//, 2016: 1874-1883.
[5] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]//, 2017: 136-144.
[6] WANG X, YU K, WU S, et al. Esrgan: Enhanced super-resolution generative adversarial networks[C]//(ECCV), 2018: 63-79.
[7] SUN C, LV J, LI J, et al. A rapid and accurate infrared image super-resolution method based on zoom mechanism[J]., 2018, 88: 228-238.
[8] Suryanarayana G, TU E, YANG J. Infrared super-resolution imaging using multi-scale saliency and deep wavelet residuals[J]., 2019, 97: 177-186.
[9] YAO T, LUO Y, HU J, et al. Infrared image super-resolution via discriminative dictionary and deep residual network[J]., 2020, 107: 103314.
[10] Oz N, Sochen N, Markovich O, et al. Rapid super resolution for infrared imagery[J]., 2020, 28(18): 27196-27209.
[11] ZOU Y, ZHANG L, LIU C, et al. Super-resolution reconstruction of infrared images based on a convolutional neural network with skip connections[J]., 2021, 146: 106717.
[12] 李方彪, 何昕, 魏仲慧, 等. 生成式对抗神经网络的多帧红外图像超分辨率重建[J]. 红外与激光工程, 2018, 47(2): 26-33.
LI F, HE X, WEI Z, et al. Multiframe infrared image super-resolution reconstruction using generative adversarial networks[J]., 2018, 47(2): 26-33.
[13] 魏子康, 刘云清. 改进的RDN灰度图像超分辨率重建方法[J]. 红外与激光工程, 2020, 49(S1): 20200173.
WEI Z, LIU Y. Gray image super-resolution reconstruction based on improved RDN method[J].2020, 49(S1): 20200173.
[14] 胡蕾, 王足根, 陈田, 等. 一种改进的SRGAN红外图像超分辨率重建算法[J]. 系统仿真学报, 2021, 33(9): 2109-2118.
HU L, WANG Z, CHEN T, et al. An improved SRGAN infrared image super-resolution reconstruction algorithm[J]., 2021, 33(9): 2109-2118.
[15] 邱德粉, 江俊君, 胡星宇, 等. 高分辨率可见光图像引导红外图像超分辨率的Transformer网络[J]. 中国图象图形学报, 2023, 28(1): 196-206.
QIU D, JIANG J, HU X, et al. Guided transformer for high-resolution visible image guided infrared image super-resolution[J]., 2023, 28(1): 196-206.
[16] ZHANG Y, LI K, LI K, et al. Image super-resolution using very deep residual channel attention networks[C]//(ECCV), 2018: 286-301.
[17] TONG T, LI G, LIU X, et al. Image super-resolution using dense skip connections[C]//, 2017: 4799-4807.
[18] ZHANG K, Liang J, Van Gool L, et al. Designing a practical degradation model for deep blind image super-resolution[C]//, 2021: 4791-4800.
[19] WANG X, XIE L, DONG C, et al. Real-esrgan: Training real-world blind super-resolution with pure synthetic data[C]//, 2021: 1905-1914.
[20] ZHANG W, SHI G, LIU Y, et al. A closer look at blind super-resolution: Degradation models, baselines, and performance upper bounds[C]//, 2022: 527-536.
[21] LIANG J, CAO J, SUN G, et al. Swinir: Image restoration using swin transformer[C]//, 2021: 1833-1844.
[22] Huynh-Thu Q, Ghanbari M. Scope of validity of PSNR in image/video quality assessment[J]., 2008, 44(13): 800-801.
[23] Hanhart P, Korshunov P, Ebrahimi T. Benchmarking of quality metrics on ultra-high definition video sequences[C]//18th(DSP), 2013: 1-8.
[24] Kundu D, Evans B L. Full-reference visual quality assessment for synthetic images: A subjective study[C]//(ICIP), 2015: 2374-2378.
[25] Mittal A, Soundararajan R, Bovik A C. Making a “completely blind” image quality analyzer[J]., 2012, 20(3): 209-212.
[26] Mittal A, Moorthy A K, Bovik A C. No-reference image quality assessment in the spatial domain[J]., 2012, 21(12): 4695-4708.
[27] Blau Y, Mechrez R, Timofte R, et al. The 2018 PIRM challenge on perceptual image super-resolution[C]//(), 2018: 334-355.
Single-frame Infrared Image Super-Resolution Reconstruction for Real Scenes
SHI Yifeng,CHEN Nan,ZHU Fang,MAO Wenbiao,LI Faming,WANG Tianfu,ZHANG Jiqing,YAO Libin
(Kunming Institute of Physics, Kunming 650223, China)
Current infrared image super-resolution reconstruction methods, which are primarily designed based on experimental data, often fail in complex degradation scenarios encountered in real-world environments. To address this challenge, this paper presents a novel deep learning-based approach tailored for the super-resolution reconstruction of infrared images in real scenarios. The significant contributions of this research include the development of a model that simulates infrared image degradation in real-life settings and a network structure that integrates channel attention with dense connections. This structure enhances feature extraction and image reconstruction capabilities, effectively increasing the spatial resolution of low-resolution infrared images in realistic scenarios. The effectiveness and superiority of the proposed approach for processing infrared images in real-world contexts are demonstrated through a series of ablation studies and comparative experiments with existing super-resolution methods. The experimental results indicate that this method produces sharper edges and effectively eliminates noise and blur, thereby significantly improving the visual quality of the images.
infrared image, deep learning, super-resolution, real scene, degradation model
TP391
A
1001-8891(2024)04-0427-10
2023-12-06;
2024-01-19.
师奕峰(1998-),男,硕士研究生,主要从事图像处理方面的研究。
陈楠(1985-),男,博士,正高级工程师,博士生导师,主要从事混合信号集成电路设计方面的研究。E-mail:chennan_kip@163.com。
张济清(1987-),男,博士,高级工程师,硕士生导师,主要从事混合信号集成电路设计方面的研究。E-mail:jiqingzhang@163.com。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
数学物理学报(2019年3期)2019-07-23 01:15:40
电子制作(2019年7期)2019-04-25 13:17:14
电子制作(2018年19期)2018-11-14 02:37:08
家庭影院技术(2018年9期)2018-11-02 05:31:32
自动化学报(2017年5期)2017-05-14 06:20:52
自动化学报(2017年11期)2017-04-04 02:52:58
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
光学精密工程(2016年3期)2016-11-07 09:03:43
