
基于改进YOLOv5 的路面裂缝检测方法*
2024-04-18 05:08:46王向前成高立夏晓华
电子技术应用 2024年3期
王向前,成高立,胡 鹏,夏晓华
(1.陕西高速机械化工程有限公司,陕西 西安 710038;2.长安大学 公路养护装备国家工程研究中心,陕西 西安 710064)
0 引言
近年来,我国公路蓬勃发展,公路保养维护任务贯穿路面整个使用阶段[1]。在裂缝出现初期及时实现病害检测并修复,可有效地减缓或防止初期裂缝的恶化,对于提高路面使用寿命、保障行车安全具有重要意义。
路面裂缝检测方法主要有3 种:传统的人眼观察识别方法主观性强;常规图像处理方法存在开发成本大、检测精度不高等问题;卷积神经网络相较于常规图像处理方法具有泛化性好、开发成本低等优点,但存在模型体积较大、检测精度有待提高的问题。文献[2]通过实验表明R-CNN 系列、SPP-net 和SSD 等现有卷积神经网络模型体积较大;文献[3]证明YOLO 的参数量较上述目标检测算法较少。但YOLO[3-4]系列算法在实际应用中依然存在模型体积大、裂缝检测精度不高等问题[5]。
因此,为减少YOLO 系列模型体积,本文首先利用轻量级网络MobileNetv3 代替YOLOv5 的主干网络[6-7]。其次,为提高模型的表征能力,在其主干网络末端加入嵌有Transformer[8]的C3TR 模块。此外,文献[9]在YOLOv4 中加入卷积注意力模块(Convolutional Block Attention Module,CBAM)[10]、文献[11]在Faster-RCNN 中加入CBAM 模块,对细小裂缝的检测能力都有提升。鉴于此,在C3TR 模块后引入CBAM 模块。最后,将CIOU损失函数替换为回归性能较好的损失函数(Efficient Intersection-Over-Union,EIOU)[12],提升模型的鲁棒性。
1 航拍路面图像的裂缝检测方法
1.1 裂缝检测方法
本文提出一种基于轻量化网络的无人机航拍图像裂缝检测方法,如图1 所示。通过无人机搭载云台相机采集沥青路面图像,并对其进行预处理,包括数据帧截取、剔除相似度高的图像。用LabelImg 标注工具标记图像,并对数据进行增强,建立沥青路面裂缝数据集,接着随机划分训练集、验证集。训练集用于模型训练;验证集用于模型性能验证;测试集用于检验模型的预测效果。

图1 沥青路面裂缝检测方法
1.2 YOLOv5 网络结构
YOLOv5 是one-stage 目标检测算法的典型代表,其网络结构如图2 所示。
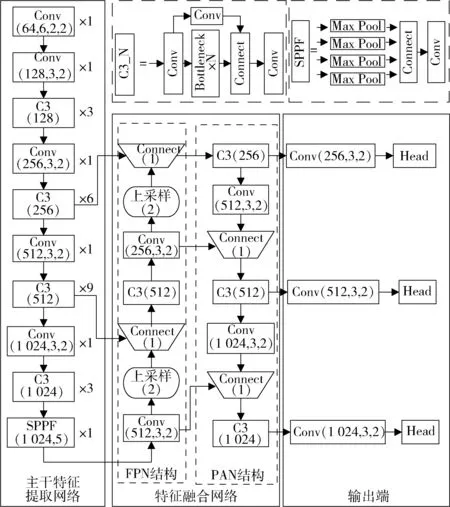
图2 YOLOv5 模型结构
YOLOv5 在YOLOv4 基础上对网络层、数据预处理、损失函数、训练策略和模型优化等层面进行了优化。YOLOv5 中有5 种网络深度和宽度不同的模型,面对不同场景具有更好的适应性。YOLOv5 使用了Leaky ReLU 激活函数和空间金字塔池化融合(Spatial Pyramid Pooling Fusion,SPPF)[13],池化速度得到了提升。采用路径聚合网络(Path Aggregation Network,PAN)和特征金字塔网络(Feature Pyramid Network,FPN)[14-15]结构实现不同尺度特征间的融合。此外,YOLOv5 中采用Mosaic方法对输入数据采用随机旋转、抖动、缩放和裁剪等方式进行增强。YOLOv5 中对损失函数进行正则化优化,增强了网络检测小目标的性能。YOLOv5 采用余弦退火学习率调度策略[16]进行训练调度,能有效地避免过拟合。YOLOv5 还采用TorchScript 对模型进行自动优化,使模型在CPU 和GPU 上运行更加高效。
2 YOLOv5 网络优化
2.1 MobileNetv3 网络
深度神经网络(Deep Neural Network,DNN)模型体积通常较大,不易在边缘化设备上部署。为解决这一问题,将YOLOv5 的主干网络替换为MobileNetv3 网络,以降低模型大小。MobileNetv3 是一种采用深度可分离卷积等轻量化技术的卷积神经网络。深度可分离卷积通过逐通道卷积和逐点卷积两个步骤来实现卷积操作,如图3 所示。它使用3 个相同的卷积核对3 个通道同时进行卷积运算,最后使用一个卷积核对前3 个卷积的结果进行卷积运算。相比于普通标准卷积,深度可分离卷积参与运算的参数更少。
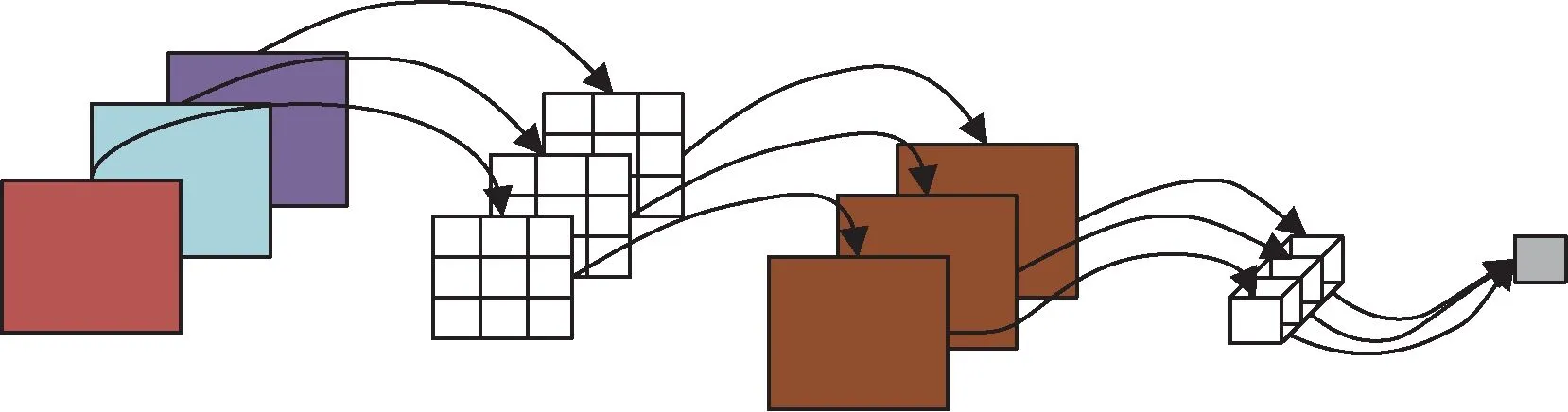
图3 深度可分离卷积
2.2 CBAM 模块
在卷积神经网络中,注意力可以增强模型对目标特征的关注,从而提高检测性能。CBAM 模块是一种混合注意力模块,结构如图4 所示,包括空间注意力模块(Spatial Attention Module,SAM)和通道注意力模块(Channel Attention Module,CAM)。SAM 和CAM 以串行方式连接,CAM 先处理通道信息,SAM 则在CAM 的输出上进行操作。CAM 部分使用最大池化和平均池化操作后,通过共享参数的神经网络生成两个权重向量,相加后得到一个通道维度的注意力权重。这个权重被应用到原始输入特征图上,自适应地调整不同通道的重要性。SAM 部分的输入来自CAM 的输出,首先对输入进行最大池化和平均池化操作,然后将结果堆叠成一个特征图。再通过卷积层将其压缩为一个通道数为1 的特征图。这个特征图的sigmoid 函数计算生成了空间维度上的注意力权重,它被应用到输入特征图上以获得具有空间信息的特征图。CBAM 有助于更好地捕捉裂缝特征信息,从而提高模型的表征能力,进而提高检测性能。
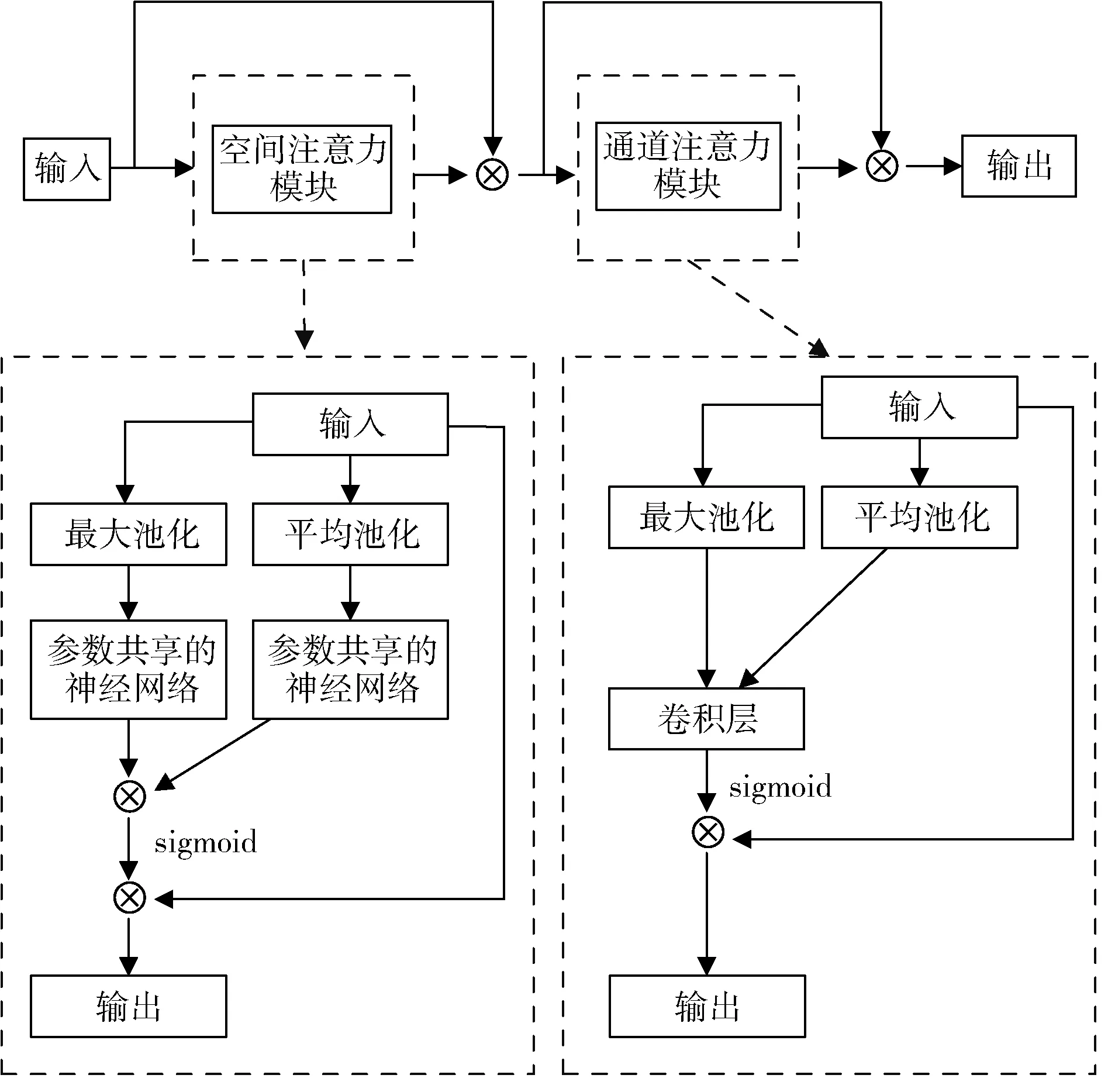
图4 CBAM 注意力机制模块结构
2.3 C3TR 模块
C3TR 模块是基于Transformer 的算法,在区分目标特征和背景特征方面具有强大的优势,将其嵌入到DNN中使网络拥有更强的特征提取能力。Transformer 是一种基于编码器-解码器结构的网络结构[17],如图5 所示,由6 个相同的编码器、解码器串联而成。
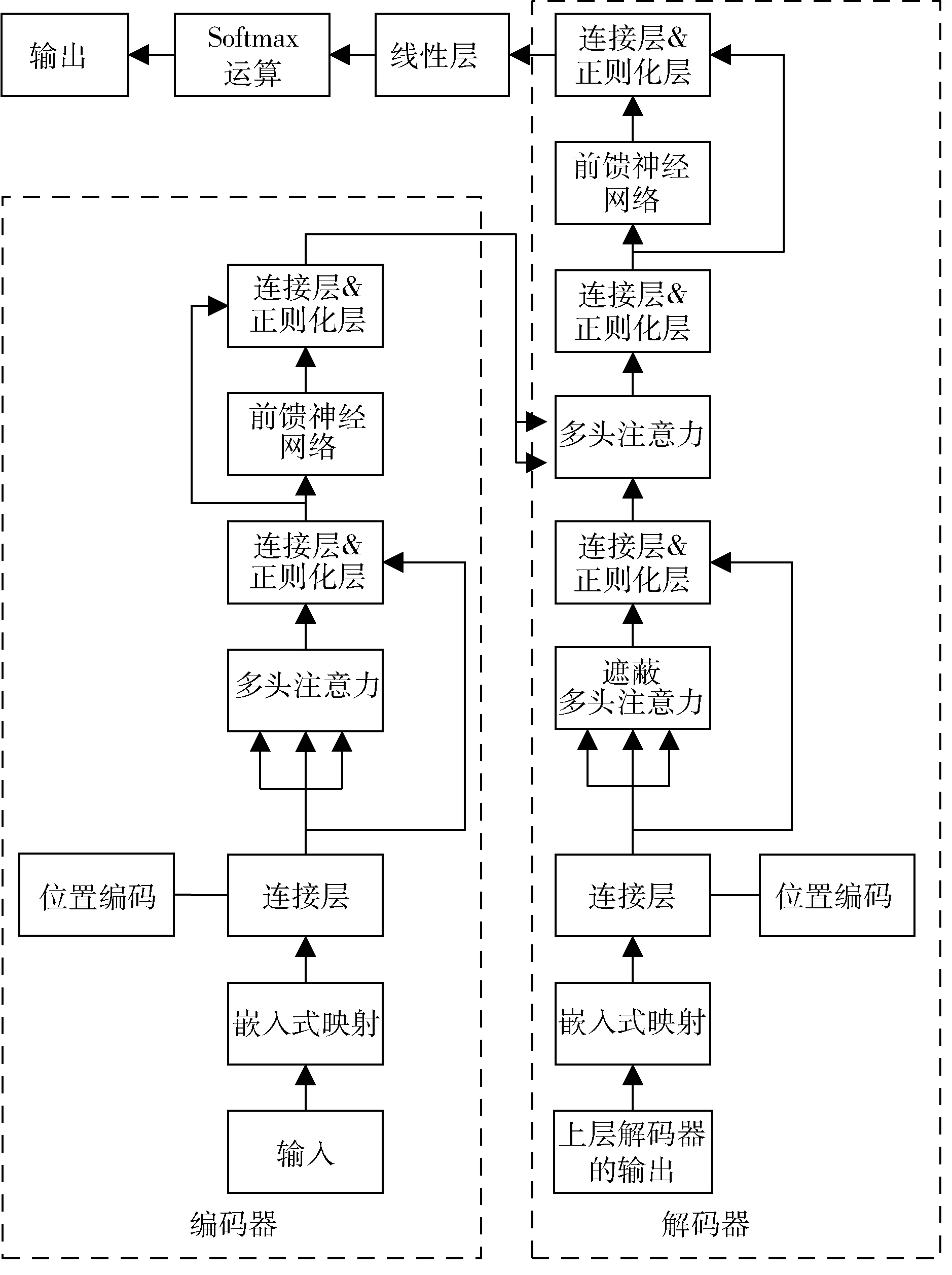
图5 Transformer 网络结构
编码器由堆叠式多头注意力机制和前馈神经网络(Feed Forward Neutral Network,FFN)构成。多头注意力机制由自注意力机制构成,不仅关注当前结点处特征,还能兼顾全局特征之间的相关性。FFN 则不断更新来自上层多头注意力输出的信息。
2.4 损失函数优化
损失函数在目标检测中衡量模型预测值和真实值之间的差异,其选择是至关重要的。好的损失函数可使网络准确、快速地检测出目标。
YOLOv5 采用复合式损失函数,由定位损失、置信度损失和类别损失三者的加权和构成。原始的YOLOv5损失函数CIOU 兼顾了预测框和真实框之间的重叠度、中心点距离以及宽高比例等因素,但采用宽高比例来实现宽高的牵制,导致预测框不能同时增大或缩小,从而阻碍了模型的快速收敛。为此,将CIOU 替换为EIOU 损失函数,其利用真实宽高来实现宽高的牵制,提高了模型的收敛速度和检测精度。
融合了上述方法之后,前12 层为MobileNetv3 结构,第13 层、14 层、15 层分别为C3TR 模块、CBAM 模块、SPPF 模块。
3 实验
3.1 数据集制作与实验环境搭建
数据集的制作包含沥青路面图像采集、裂缝标记和图像增强3 部分。其中,SG906 PR0 无人机搭载云台相机共采集2 000 张分辨率为1 920×1 080 的道路裂缝图像。随后,随机挑选出1 311 张图像作为测试集,并从余下的图像中选择相似度不高的271 张图像,并采用LabelImg 工具进行标记,部分示例如图6 所示。之后,采用旋转、缩放等多种增强方式对数据进行5 倍扩充,扩充后的数据集规模达1 626 张图像。最后,将训练集和验证集按9∶1 的比例随机划分,最终训练集有1 464 张图像,验证集有162 张图像。

图6 部分数据集示例
消融实验在台式机上进行,实验环境如表1 所示。

表1 实验环境
3.2 评价指标
实验采用平均精度均值(mean Average Precision,mAP)、模型大小和检测速度(FPS)作为评价指标。其中,mAP由精确率(P)和召回率(R)两个指标组成,如式(1)~式(3)。另外,FPS 是指模型在测试集上每秒完成预测的图像数量。模型大小则是指模型文件的大小,通常使用MB 或GB 作为单位。
式中,TP 为裂缝被识别为裂缝的样本数,TN 为背景被识别为背景的样本数,FP 为背景被识别为裂缝的样本数,FN 为裂缝被识别为背景的样本数。本文在置信度阈值为0.5 时进行mAP 值的比较,当预测框和真实框的交叉比(Intersection of Union,IoU)大于0.5 时,则确定当前样本为裂缝;当两框的IoU 大于0 小于0.5 时,确定当前样本为背景;当两框的IoU 为0 时,表示没有真实框。
3.3 网络参数设置
网络训练中使用梯度下降算法优化模型权重参数,采用SGD 优化器更新参数,不断减小真实值和预测值之间的差异,提升检测性能。初始学习率为0.001,采用余弦退火策略调整学习率,先增后减,加速模型收敛并避免过拟合。Batch-size(每个训练批次处理的图像数量)为16,worker(多线程)设置为4,以提高训练速度。共进行500 个epoch 的训练,输入图像分辨率设为640×640。模型采用迁移学习策略,首先在DOTA[5]数据集上预训练权重,再通过权重共享微调到本文数据集。
3.4 消融实验
本次消融实验设置了5 组实验,分别验证了添加轻量级网络MobileNetv3、C3TR 模块、CBAM 模块和替换CIOU 损失函数4 种方法对裂缝检测性能的影响,训练过程如图7 所示,图7(a)表示训练批次-损失值曲线,图7(b)表示训练批次-精度曲线。消融实验结果如表2 所示。不同实验的部分检测效果如图8 所示。

表2 消融实验结果
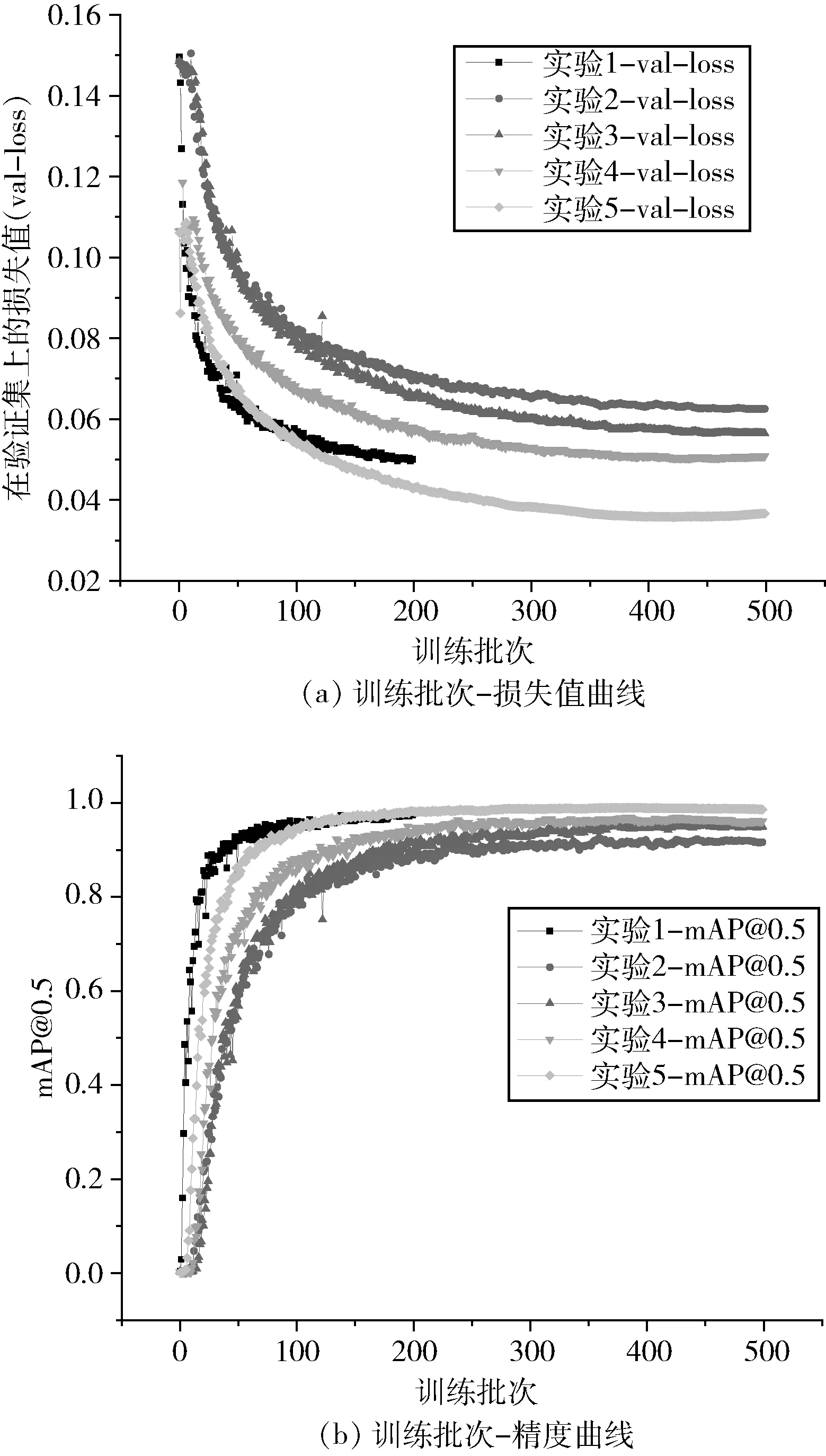
图7 消融实验训练过程

图8 消融实验部分检测结果
由表2 可知,实验2 在实验1 的基础上,使用Mobile-Netv3 作为YOLOv5 主干网络,模型大小减小了55%,检测速度提高,但检测精度下降5.7%。实验3 在实验2 的基础上嵌入C3TR 模块,模型大小和检测速度基本不变,但检测精度提高了2.9%。实验4 在实验3 的基础上引入CBAM 模块,模型大小基本不变,检测精度提高了0.8%。实验5 在实验4 的基础上使用EIOU 损失函数,检测精度提高了3.2%,而检测速度未受影响。综上所述,MobileNetv3 降低了模型大小并提高了检测速度,但牺牲了一些检测精度。C3TR 模块、CBAM 模块和EIOU 损失函数都对提高检测精度有帮助,而且计算成本相对较低,适用于边缘化设备。
3.5 对比实验
为验证本文改进方法的有效性,将其与YOLOv5、Faster-RCNN[18-20]模型、YOLOX[21]模型和Efficientdet[22]模型进行对比,对比结果如表3 所示。
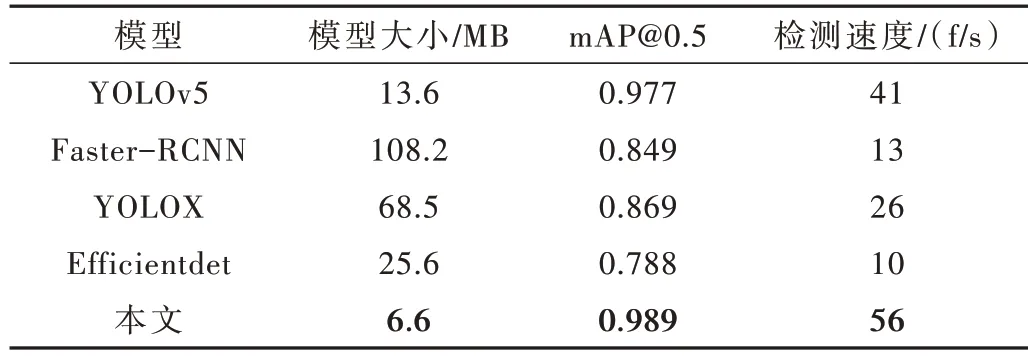
表3 不同模型对路面裂缝的检测效果
结果表明,本文提出的改进方法相较于Faster RCNN 模型、YOLOX 模型和Efficientdet 模型,在mAP@0.5、模型大小和检测速度3 方面都表现更好,验证了本文改进方法的有效性。
4 结论
本文提出一种基于MobileNetv3 轻量化网络的无人机航拍图像裂缝检测方法,旨在实现准确且高效的路面裂缝检测。该方法利用轻量化的Mobilenetv3 网络作为YOLOv5 主干网络,降低了模型的大小,从而更容易在移动平台上部署。此外,引入了C3TR 模块和CBAM 模块,增强了网络对裂缝特征的提取能力,并采用EIOU 损失函数提高模型的鲁棒性。通过消融实验和与其他目标检测模型的对比,证明了该改进方法的有效性,具备在路面裂缝检测领域广泛应用的潜力,为路面养护提供了重要支持。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
石油与天然气地质(2021年3期)2021-06-29 03:33:02
鸭绿江(2021年35期)2021-04-19 12:23:56
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
意林·全彩Color(2018年7期)2018-08-13 09:35:18
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
