
基于GA-BP神经网络的风电功率预测方法研究
2024-04-07 01:36逯登龙范丽锋郭彦飞周维文
自动化仪表 2024年3期
逯登龙,高 鹏,范丽锋,郭彦飞,周维文
(1.中国广核新能源控股有限公司华北分公司,河北 石家庄 050011;2.南瑞集团有限公司(国网电力科学研究院有限公司),江苏 南京 211106)
0 引言
随着科学技术的不断发展,环境问题越来越被重视。在保持发展速度的情况下,纳入清洁、可再生能源的环境问题也要考虑。风力发电是解决能源环境问题的关键技术之一。风力发电是通过自然界中的风,使风力发电机的叶片产生动能,进而转化成电能。而风作为自然界中一种波动、不稳定的能源,如何提升风电功率预测,以及处理风力发电过程中的异常数据是风电工程的重要组成部分之一。
为了克服风力发电中产生异常数据、提高风电功率预测水平,国内外有多种技术方法。文献[1]在数据预处理阶段对数据进行了一致性检验,并对异常数据进行了简单消除,以得到一个无延时的功率预测曲线模型。该模型的风电功率预测结果较为准确,但其在处理大量的分散型数据时的风电功率预测准确度较低。文献[2]设计了基于小波模的极大值技术方法。该方法能够识别风力相关数据中的奇异点,并且通过自回归滑动平均(auto regressive moving average,ARMA)模型对奇异点进行修正,以提高风电功率预测准确率。但是该方法仅通过单一的ARMA模型修正,效果不理想。文献[3]结合了风电场的风速数据以及风电机的功率数据,通过向量机进行机器学习模型的构建,对中长期的风电功率预测较为准确。但是其异常数据的识别能力不佳,容易受到异常数据干扰,对短期情况下的风电功率预测准确度不高。
本文创新性地考虑多种异常数据,提出了一种基于遗传算法-反向传播(genetic algorithm-back propagation,GA-BP)神经网络的风电功率预测方法。该方法通过设计风电功率预测系统整体架构,实现风电功率的预测;通过包含Web服务器、数据库服务器、应用服务器、气象服务器等组成的服务器模块提高数据信息计算能力;通过构建四分位算法以区分正常数据和异常数据,并有效提高数据序列或者偏态分布的能力。
1 风电功率预测方法概述
本文研究的风电功率预测系统整体框架结构如图1所示。

图1 风电功率预测系统整体框架结构
由图1可知,风电功率预测系统整体框架结构主要包括:由Web服务器、数据库服务器、应用服务器、气象服务器等组成的服务器模块[4-5];基于四分位算法和带通滤波电路的异常数据识别及剔除模块[6-7];由计算机控制器、风电功率预测算法等组成的风电功率预测模块;由风力感应仪组成的风电场风力数据采集模块。
图1系统的整体工作流程如下:首先,风电场内置的监控器将风电场的数据上传至数据库,为风电功率预测提供数据支撑;然后,在风电场的数据分析中心,对所采集到的风力数据、天气预报的数据信息及环境影响等进行综合考虑,通过使用数学模型中的四分位算法识别风电功率预测过程中可能产生干扰的异常数据;最后,通过数据分析与风电功率预测模块中的GA-BP神经网络对风电功率预测模型进行风电功率的预测。
2 异常数据识别及滤波电路设计
风电场在进行风电功率预测时,风力发电机会受到自然界因素(气温、气压等)、设备自身因素(电压、电流、频率等)等的影响。这些因素往往会导致风力发电机组不能正常工作[8-10]。风电机组发出的实际功率大小通常会与预设的理论发电值有很大误差,会降低风电功率预测的准确度。本文选用四分位算法区分正常数据和异常数据。四分位算法指按照大小对任意一个风电功率数据组合进行排序,并将它们平均分成四个等份。当其中的某个风电功率数据处于排序后风电功率数据组的分界处时,称之为四分位数[11-12]。四分位数间距适用于表示数据序列或者偏态分布。因此,四分位算法较为稳定、精确。
四分位算法如图2所示。

图2 四分位算法示意图
这些位于分界点的风电功率数据分别被称为第一四分位数、中位数(第二四分位数)、第三四分位数。从下限到上限,风电功率数据越来越大。这些四分位数的间距代表了数据大小的差值。
四分位算法流程如图3所示。

图3 四分位算法流程图
一个区间内的风速对应着n个风电功率数据。对这些风电功率数据进行升序排列,可以得到样本P={P1,P2,…,Pn}。四分位数的计算如下。
中位数的值P2的计算式为:
(1)

①如果风电功率数据总数n为偶数的时候,将升序排列后的样本PV以中位数P2为界限拆分成两个数据集(P2独立且不包含在这两个数据集中)。对拆分后的两个数据集,分别计算它们的中位数P′2和P″2,那么由四分位的定义可知第一四分位数P1=P′2、第三四分位数P3=P″2。
②当风电功率数据总数n=4k+3时,有:
(2)
③当风电功率数据总数n=4k+1时,有:
(3)
通过上述过程计算出P1和P3,就可以获得四分位间距:
IQR=P3-P1
(4)
依据四分位间距IQR,可以确定数据样本PV中的异常数据值内限的范围为:
[F1,F2]=[Q1-1.5IQR,Q3+1.5IQR]
(5)
式中:F1为序列的下限值;F2为序列的上限值。
由式(5)可知,处于下限到上限范围以外的数据就是异常数据。
为了准确预测风电功率,必须剔除通过四分位算法识别出的异常数据。在异常数据识别及剔除模块中,本文针对正常数据与异常数据的不同频率区间设计了带通滤波电路。
带通滤波电路由四个LM324运算放大器配合不同容值的电容以及不同阻值的电阻共同构成。该带通滤波电路工作时,首先由A1、A2运算器配合电阻、电容进行二次滤波操作,过滤掉系统不需要的频率段信号;然后通过A3、A4运算器配合电阻、电容,对处理后的电流信号进行整流放大;最后将处理后的信号由输出端输送至数据分析中心进行风电功率预测。
带通滤波电路如图4所示。
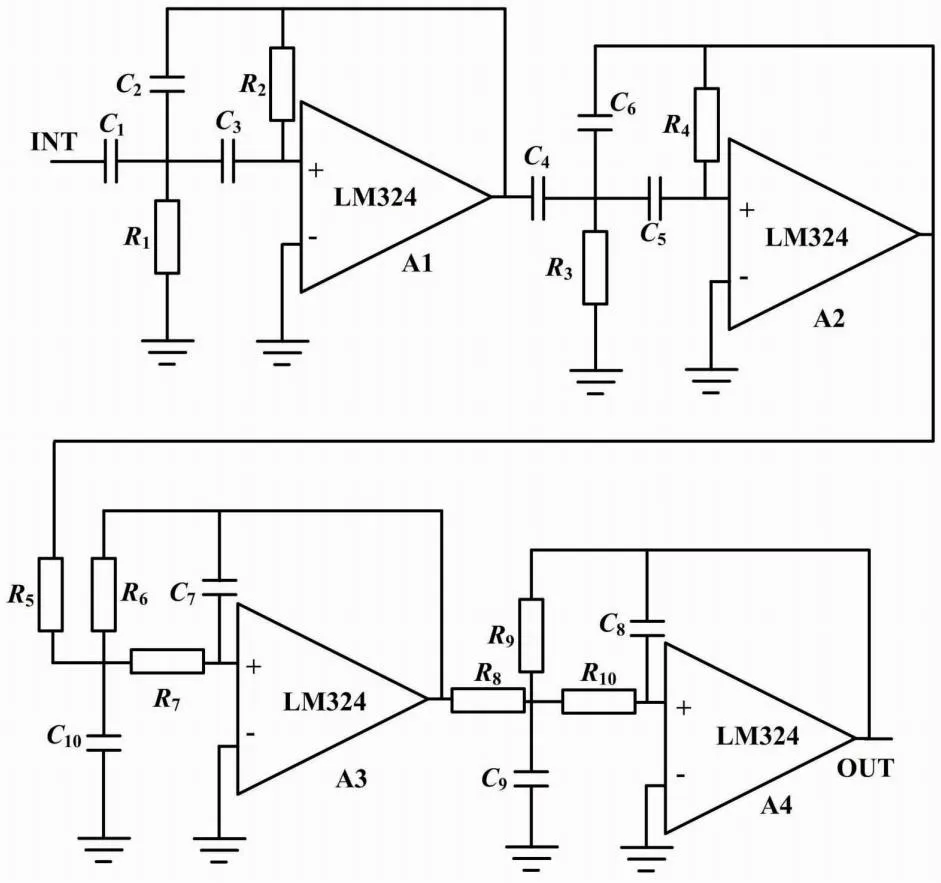
图4 带通滤波电路图
通过四分位算法可以识别出风力发电过程中的正常数据和异常数据,并在此基础上设计带通滤波电路以过滤掉无用的异常数据。这样能够为风电预测提供有效、真实的数据,有助于提高风电功率预测的准确度。
带通滤波器的幅频和相频特性曲线如图5所示。

图5 带通滤波器的幅频和相频特性曲线
3 GA-BP神经网络风电功率预测方法
为了提高风电功率预测的准确度,本文通过对相关技术文献的研究,设计了GA-BP神经网络风电功率预测方法。反向传播(back propagation,BP)神经网络是一种由数据信号正向传播以及数据误差信号反向传播而形成多层前反馈的神经网络,有较强的适应学习能力。
典型的BP神经网络模型如图6所示。

图6 BP神经网络模型图
BP神经网络有输入层、隐含层、输出层这三个层次。每个层次之间的神经元都采用了全连接的形式。BP神经网络对数据信号处理的整体过程如下:首先,风电功率预测所需要的相关数据信息从输入层进入BP神经网络;其次,在BP神经网络内部通过隐含层对输入的相关数据信息进行处理和计算[13-14];最后,将输出的数据值与预设值进行对比。
BP神经网络对风力数据信息处理的相关计算式如下。
在隐含层对风力数据处理时,所采用的函数为:
(6)

在风电功率预测的相关数据信号进行正向传播时,本文将输入BP神经网络的数据表示为XP={Xpt,Xpg,…,Xpm}。经BP神经网络输出的数据与预设的数据值之间的误差E(n)满足:
(7)

如果误差E(n)的值大于用户事先预设的阈值,系统就会将输出值按照输出层、隐含层、输入层的顺序进行BP。在这个过程进行的同时,BP神经网络会依据误差,通过计算式更新权值。所依据的计算式为:
Wij(n+1)=ΔWkj(n+1)+Wkj(n)
(8)
式中:Wij为输入层到隐含层的数据权值;Wkj为隐含层到输出层的数据权值。
虽然BP神经网络技术有很好的风电数据处理能力,但是如果在数据处理的过程中选择的初始权值、阈值不当的话,就会造成数据处理训练效率低下、收敛速度慢等问题,使风电功率预测的准确率下降。因此,本文加入了遗传算法(genetic algorithm,GA)以对BP神经网络进行优化,构成了GA-BP神经网络模型。
GA优化BP神经网络的步骤如下。
①将BP神经网络中的风电功率权值和阈值的初始值进行编码。
②根据BP神经网络输出值与预设值的误差来确定适应函数。适应函数S为:
(9)

S是进行接下来计算的依据。
(10)
③在每次迭代过程中,依据适应度函数最终计算得到的值的大小,对集群当中的样本个体进行排序,并通过交叉和变异的操作生成新的风电功率数据种群。
④在上述步骤完成的情况下,返回步骤②进行循环计算。只有当最后的种群个体满足预期要求的指标时计算才会停止,以输出精确的风电功率预测结果。
通过GA-BP神经网络对风电功率预测,能够有效避免环境和设备自身的干扰。同时,GA-BP神经网络自我调节性良好,能通过适应函数以及对风电相关数据信息进行循环处理来消除误差,从而获得准确的风电功率预测结果。
4 试验与分析
为了验证所设计方法在异常数据识别及风电功率预测方面的性能,本文通过纵向对比进行了相关试验。该试验在西藏风电场进行。试验主机的配置为:处理器选用E5700@3.00 GHz;安装内存设置为8.00 GB;操作系统为Windows10 64位;驱动器为ST3320410SV ATA Device。
试验分别采用文献[1]、文献[2]、文献[3]以及本文方法,根据分布式风力数据采集设备采集到的风力数据以及天气预报预测的自然环境条件信息,执行异常数据识别及风电功率预测。试验通过Matlab软件进行仿真。
试验架构如图7所示。

图7 试验架构示意图
在试验设备中,本文设置一定量的异常数据与标准情况下风电机输出的功率,通过对比异常数据量与风电功率的预测值,反映试验方法各自的异常数据识别能力和风电功率预测的准确度。本文将西藏风电场以往获取的实际记录数据作为本次试验的测试数据。这保证了试验数据的真实性和丰富性。
采用文献[1]、文献[2]、文献[3]以及本文方法,得到的异常数据量如表1所示。
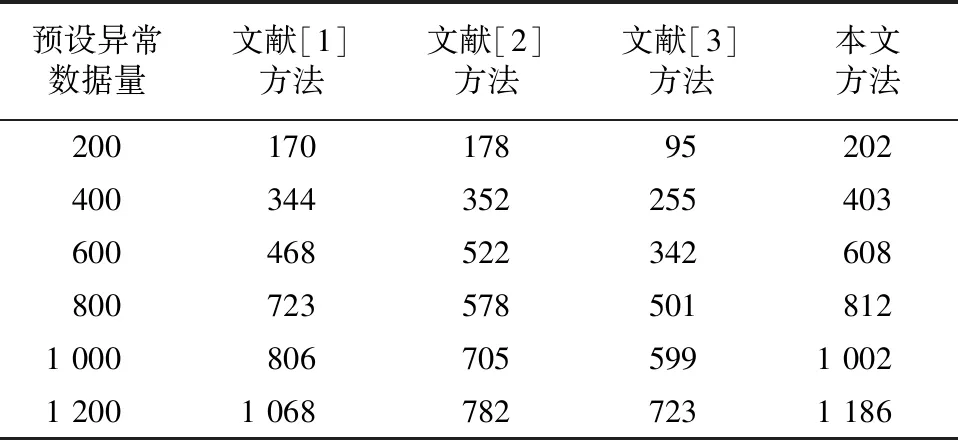
表1 异常数据量
由表1可知,文献[1]、文献[2]、文献[3]方法识别异常数据的能力逐渐落后于本文所设计的方法。尤其是:文献[2]方法识别异常数据的准确度大幅度下降;文献[3]方法准确度一直低于其他三种方法,仅有50.5%左右;本文所设计的方法对异常数据识别的准确度一直保持在90%以上。
在试验几种方法对风电功率的预测能力时,本文通过以预设条件下系统所能输出的功率的标准值为参考,对比输出功率预测值来反映风电功率预测能力的强弱。
四种方法风电功率预测值如表2所示。

表2 四种方法风电功率预测值
由表2可知:文献[1]方法预测风电功率的准确度逐渐上升,最终稳定在80%左右;文献[2]方法的预测准确度维持在75%~85%区间;文献[3]方法对风电功率预测的准确度随功率的增加而降低,仅达到46%左右,证明其无法应对大规模短期风电功率的预测;本文方法对风电功率预测的准确度一直保持在90%以上,证明了本文方法在风电功率预测上的优越性。
5 结论
针对风电场对风电功率的预测容易受到异常数据影响,造成预测准确度不高的难题,本文设计了带通滤波器配合数学模型中的四分位算法来实现对异常数据的识别及剔除的方法。本文方法能够为风电功率的预测提供精准的相关数据信息。为了提高风电功率预测的准确度、满足风电场的管理需要,本文在一般的BP神经网络上加入了GA,以此提高风电预测的准确度。通过试验对比,证明了本文方法无论是在异常数据的识别及剔除能力上还是在风电功率预测的准确度上都有很大的优越性。
猜你喜欢
中学生数理化·八年级物理人教版(2023年6期)2023-05-25
成都信息工程大学学报(2022年2期)2022-06-14
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2018年12期)2019-01-31
建筑科技(2018年6期)2018-08-30
山东工业技术(2016年15期)2016-12-01
中国交通信息化(2016年5期)2016-06-06
天津冶金(2014年4期)2014-02-28
机电信息(2014年35期)2014-02-27
