
基于改进BP-Bagging算法的光伏电站故障诊断方法
2024-03-28 02:11:16祁炜雯陈建国
浙江电力 2024年3期
祁炜雯,张 俊,吴 洋,范 强,赵 峰,陈建国,王 健
(1. 国网浙江省电力有限公司绍兴供电公司,浙江 绍兴 312362;2. 国网浙江省电力有限公司,杭州 310007;3. 河海大学 能源与电气学院,南京 211100)
0 引言
在“双碳”目标下,传统电力系统将向以新能源为主体的新型电力系统转变,光伏发电将成为未来电源结构中的重要主体。截至2023年2月底,全国累计发电装机容量约26.0 亿kW,同比增长8.5%。其中,风电装机容量约3.7亿kW,同比增长11.0%;太阳能发电装机容量约4.1 亿kW,同比增长30.8%。2023 年1—2 月份,全国主要发电企业电源工程完成投资676 亿元,同比增长43.6%。其中,核电87 亿元,同比增长44.8%;太阳能发电283亿元,同比增长199.9%[1]。
光伏发电是实现“双碳”目标的重要手段。在光伏发电迅猛发展的同时,其运行安全问题愈发凸显。若故障处理不及时,极易导致光伏面板、汇流箱烧毁,造成经济损失,威胁站内人员安全。快速检测光伏电站是否发生故障以及精准诊断故障类型对于光伏供电系统安全可靠运行至关重要。现有光伏故障诊断方法大致包括红外图像诊断法、数学模型诊断法和人工智能诊断法。文献[2-4]基于红外成像原理,提出自动检测光伏热斑的方法,提高了热斑故障诊断的自动化水平,但此类方法过分依赖红外设备的精密程度,成本较高且仅能诊断单一故障类型。文献[5-8]基于数学模型诊断法实现了光伏电站故障诊断,该方法仅需提供光伏运行数据,不依赖于价格高昂的红外检测设备,但是诊断效果依赖模型的精准性。文献[9-13]基于人工智能技术,采用数据驱动的方式实现光伏电站故障的精确诊断,此类方法既避免了红外图像法高昂的设备费用,又弥补了数学模型诊断法难以在线应用的问题,但其高度依赖数据,存在过拟合问题。
人工智能诊断法凭借使用成本低、诊断精准的优点逐渐成为故障诊断的主流方法。文献[14]提出了基于1D-CAE(一维卷积自动编码器)的故障诊断方法,1D-CAE 通过高维信号的降噪来学习分层特征,与卷积核和池化单元集成的自动编码器使特征提取特别有效,这对于多变量的故障检测和诊断具有重要意义。文献[15]提出基于1DCNN-BiLSTM算法的电力电缆故障诊断模型,基于CNN(卷积神经网络)和LSTM(长短期记忆)的特征提取能力实现多类型故障的准确识别,但并未解决电力电缆故障数据与正常数据之间的平衡问题。文献[16]提出一种基于数据增强型CNN的变压器故障诊断方法,通过改进变分自编码器生成变压器故障数据,再借助改进的CNN实现变压器故障诊断。该方法通过模型生成故障数据,在一定程度上解决了故障诊断中存在的类不平衡问题。但是由于模型生成的故障数据可能根本不存在,基于不存在的样本数据训练得到的模型准确性有待考证。文献[17]提出了一种基于电压电流量测的SSLN(半监督阶梯网络)光伏故障诊断模型,利用少量标记样本训练SSLN故障诊断模型,实现对线间故障、开路故障的诊断。文献[18]提出一种基于CatBoost 算法的光伏阵列故障诊断方法,CatBoost 算法能高效处理光伏阵列故障类别特征,提高故障诊断的准确率。但是该算法仍没有在本质上改变样本的类不平衡问题,并且Boost算法采用串行框架,模型训练花费的时间成本较高。
上述人工智能算法在电力系统故障诊断领域取得了一定的成果,但仍存在不足。对光伏电站运行故障诊断而言,正常运行状态的样本数据要远多于故障运行状态的样本数据,这种类不平衡问题会导致模型更倾向于学习样本类型占比更大的样本特性。同时,单个基学习器模型学习深度有限,对特征较为相似的运行故障误判率较高。
针对目前人工智能算法在光伏电站故障诊断问题上的不足,本文提出了一种基于随机欠采样BP-Bagging 算法的光伏电站故障诊断方法,借助BP(反向传播)神经网络实现多故障类型的诊断识别,基于Bagging框架搭建并行故障学习网络,克服单个网络模型存在的过拟合问题,用随机欠采样替换原Bagging中的采样方法,在保证样本数据真实性的前提下,均衡样本不平衡度,提高模型的故障诊断效果。
1 Bagging算法的改进
Bagging算法是应用最为广泛的集成学习算法之一,其基本思想是将多个不同的弱学习器按照一定规则组成强学习器,以提高模型的准确性。其特点是可并行计算,降低弱学习算法的不稳定性,从而改善整个模型的泛化能力[19-20]。
Bagging算法的基本流程:采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时出现两个类收到同样票数的情形,最简单的做法是随机选择一个,大多情况下将T设置为奇数。
图1 为Bagging 方法的框架示意图,图中给出了Bagging方法的形象表达:首先对训练集随机抽样,形成多个存在数据特征差异的训练子集;然后基于各个子集训练基学习器(基模型);最后对各个基模型的预测结果进行综合,得到最终的综合预测结果。
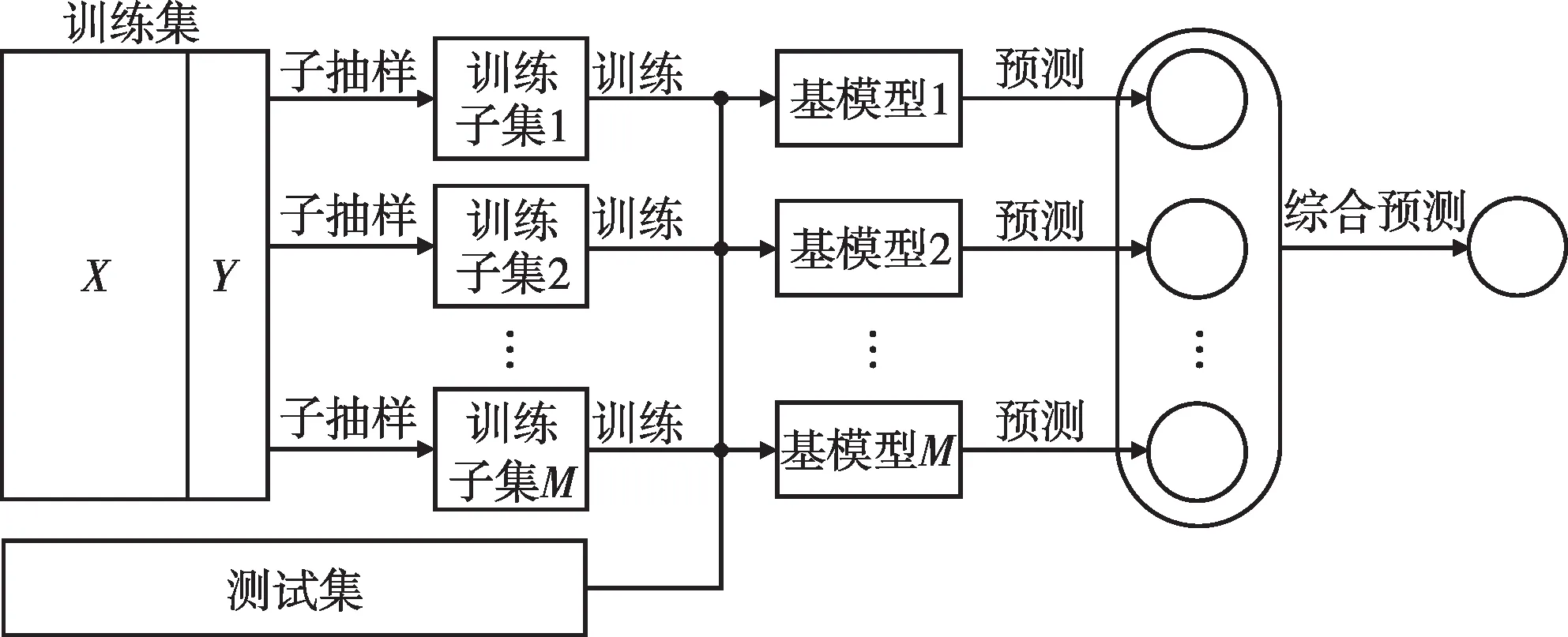
图1 Bagging方法框架示意图Fig.1 Framework diagram of Bagging method
Bagging方法具有以下优势:
1)可以降低模型方差。使用不同子样本训练出多个弱分类器,并将它们进行整合,可以减少模型方差和过拟合现象。
2)并行计算效率高。每一个基础模型可以并行地训练、测试和预测,因此Bagging具有较高的计算效率。
3)通用性强。在各种机器学习任务中都表现良好,特别适用于易受噪声影响或容易过拟合的模型。
4)对异常值具有鲁棒性。由于采取随机抽样方式生成多组数据集,因此能有效处理极端值问题。
对于某些分类问题,尤其是故障诊断问题,其样本数据分布存在明显的类不平衡特点。正常运行状态的样本总是占总体样本量的绝大多数,而各种故障状态的样本数量较少,这在很大程度上会促使模型过度学习正常运行状态的样本特征,致使模型会将“故障”误判为“正常”。
对此,在改进Bagging方法中引入了并行随机欠采样方法,以此均衡训练集中各类数据集的占比。本文参考文献[21]中提出的随机欠采样方法,具体如图2 所示,使用随机欠采样步骤取代原Bagging方法中的并行随机采样步骤,通过降低对原数据集中多数样本的采样频率,缓解原数据集的类不平衡问题,从而有效提升模型对少数样本的学习效率,提高模型的准确率。

图2 随机欠采样方法示意图Fig.2 Schematic diagram of the random under-sampling method
不同于过采样方法易引入错误的样本,从而损害少数样本的学习效果[22],欠采样方法通过削减多数样本的比例,间接提高少数样本的占比,从而起到均衡样本分布的作用。
假设重采样数据集的大小为S,其中S≤NP×2,NP为多数集P 的大小。从多数集P和少数集N中随机抽取样本,放入新的训练数据集D[23]。为了确保训练的每个子集Di都是相对独立的,并且尽可能多地覆盖原始集的样本,引入重叠率概念。
给定两个数据集D1和D2,大小为m,mS是两个数据集中相同样本的个数,D1和D2的重叠率为:
设置阈值RT限制每个子集的重叠率:
将欠采样方法与Bagging方法相结合,得到改进Bagging 方法,如图3 所示。改进Bagging 方法采用并行随机欠采样,将训练集分为多个子集,基于各个子集进行模型训练,最终统计各个模型输出结果,按票数多少输出模型最终的评估结果。随机欠采样方法可以改善样本集的类均衡性,Bagging提高了模型整体的稳定性和鲁棒性。

图3 改进Bagging方法示意图Fig.3 Framework diagram of the enhanced Bagging method
设ht表示第t个学习器的输出;Ⅱ(·)表示指示函数,在·为真和假时分别取值1 和0。则基于随机欠采样的Bagging算法代码实现如下:
输入:训练集D={(x1,y1),(x2,y2),…,(xm,ym};基学习器算法ζ;训练轮数T。
for t=1,2,…,T do
采用随机欠采样方法从数据集D中抽取子训练集Drus
end
2 基于改进BP-Bagging 算法的光伏电站故障诊断模型
2.1 问题描述
如图4所示,光伏面板由线路串并联组成光伏发电阵列,经由汇流箱、逆变器、变压器与电网并联。光伏电站内具备相应的数据采集设备,能够采集光伏发电相关数据,如光照幅度、气温、气压、空气湿度、各光伏串列直流侧电压电流、逆变器侧电压电流等。光伏电站一般建设在光照充裕的室外,受自然条件的影响较大,工作环境较为恶劣,因此光伏电站时常出现故障,其中光伏面板发生故障的概率最高,主要故障类型包括:冰雹碎石撞击光伏电池板造成面板短路、断路,长时间暴晒、雨水侵蚀使发电组件老化,沙尘污秽遮挡使得面板出现热斑。基于站内数据资源驱动人工智能模型实现光伏电站的故障诊断是本文的研究重心。

图4 光伏电站故障诊断示意图Fig.4 Schematic diagram of PV power plant fault diagnosis
2.2 故障诊断模型
假设对任意一个光伏电站,可以采集到第i组光伏组串数据Xi=[Ai1,…,Aij,…,Aim]T,其中Aij表示第i组光伏组串第j个面板的运行状态向量。Aij=[E0ij,EDij,ESij,Tij,Hij,Pij],其中,E0ij表示第i个组串第j个面板的总辐照度;EDij表示第i个组串第j个面板的直射辐照度;ESij表示第i个组串第j个面板的散射辐照度;Tij表示第i个组串第j个面板的温度;Hij表示第i个组串第j个面板的相对湿度;Pij表示第i个组串第j个面板的输出有功功率。
由于各类数据的量纲和量级存在差异,需要对这些数据进行归一化处理。按照同类物理属性进行归一化处理[24]:
式中:xmax表示光伏电站某类发电数据的最大值;xmin表示光伏电站某类发电数据的最小值。
搭建用于分类的人工神经网络,选用ReLU函数作为隐藏层激活函数,避免梯度消失的问题;选用softmax函数作为输出层激活函数,实现网络的多分类功能[25]。
ReLU函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被称为单侧抑制。
对维数为k的任意实向量,softmax 函数都可以将其压缩为相同维数、值在[0,1]范围内、向量元素总和为1的实向量:
将神经网络内部按照不同功能划分为输入层、隐含层和输出层,图5 为典型的BP 神经网络结构。

图5 典型的BP神经网络结构Fig.5 Typical structure diagram of BP neural network
X为输入列向量,xi为第i行元素;W为权重矩阵,具体地,某个元素可以用wf,ij表示,下标f表示对应层,下标ij表示本层i节点与下层j节点连接关系;Y为输出列向量,yi为第i行元素;∑为求和符号;φi为隐含层第i个神经元激活函数;ϕi为输出层第i个神经元激活函数;θi为隐含层第i个神经元阈值;bi为输出层第i个神经元阈值;N、M、K分别表示输入数据维度、隐含层神经元个数和输出层神经元个数。
神经网络借助大量的隐含层神经元进行数据流处理和网络训练。不失一般性,以图5中单个神经元为例,简要介绍神经网络数据流处理过程。
假设隐含层第i个神经元输出为oi,由图5 可知第i个神经元输出如式(7)所示:
同理,可以推导出输出层第i个神经元输出为:
为进一步降低模型误判风险,提升模型性能,本文采用集成学习框架,利用Bagging方法实现单个BP模型的并行建模。对于光伏电站故障分类问题,样本不均衡问题依然存在,如若不解决,那么经过Bagging后的模型将会进一步放大由样本不均衡导致的模型故障诊断正确率低的问题。本文提出的改进Bagging方法恰当地解决了此问题。
对于光伏故障诊断问题,假设每个基学习器的诊断错误率为ε,那么对每个基学习器ht有:
结合T个基学习器的故障诊断结果,采用投票法得到最终诊断结果。当有超过T/2的基学习器给出正确的故障诊断结果时,则该集成模型正确:
假设每个基学习器相互独立,则集成模型的错误率为:
式中:[·]表示取整运算;CkT表示从T个学习器中取出k个学习器的组合数。
对式(11)进行缩放:
显然,随着T的增多,Bagging集成模型的诊断错误率将呈指数下降。表1给出了基学习器错误率为0.4的条件下,集成模型错误率与基学习器数量的关系。

表1 模型错误率与基学习器数量之间关系Table 1 Relationship between model error rate and the number of base learners
由表1可知,随着基学习器个数的增加,集成模型的错误率呈指数下降。
如图6所示,光伏电站的运行数据经由设备采集、数据预处理后再打包制作成模型训练数据集。该数据集样本特征为正常运行样本占绝大数、故障运行样本占少数。利用并行随机欠采样方法,得到数组类平衡训练集,将每组数据集都作为BP模型的训练数据集,用于训练BP模型,累计每个BP模型的故障诊断结果,按照投票法得到最终诊断结果。

图6 基于改进BP-Bagging的光伏电站故障诊断方法示意图Fig.6 Schematic diagram of PV plant fault diagnosis method based on an enhanced BP-Bagging
3 算例分析
3.1 模型训练
基于Pytorch平台进行模型训练,选用数据集样本数量为1 373 798 条,将其划分为训练集和测试集两部分,各占总体样本的85%和15%。设置训练循环次数为100 次,并行的BP 网络为51 个,记录并分析训练过程中每个BP模型产生的误差函数值和诊断准确率。训练误差函数值和诊断准确率如图7所示。

图7 模型训练误差值与准确率Fig.7 Model training error values and accuracy rates
图7中,每个点的数据都是所有BP 模型产生的误差函数值或是诊断准确率的平均值。图中蓝色线条和橘红色线条分别代表51 个子模型的平均诊断准确率和平均误差值。蓝、橘两条曲线呈明显的“此消彼长”特性,这是符合客观规律的,随着模型训练次数的增加,模型愈发精准,准确率提升,误差降低。对于本文所用算例模型,模型大约在第20 次训练后趋于收敛,因此可以设置训练次数为20 次作为模型训练终止的条件,以提高时间利用效率。
完成训练后,将模型应用于测试集,对其性能进行测试,得到结果如图8所示。
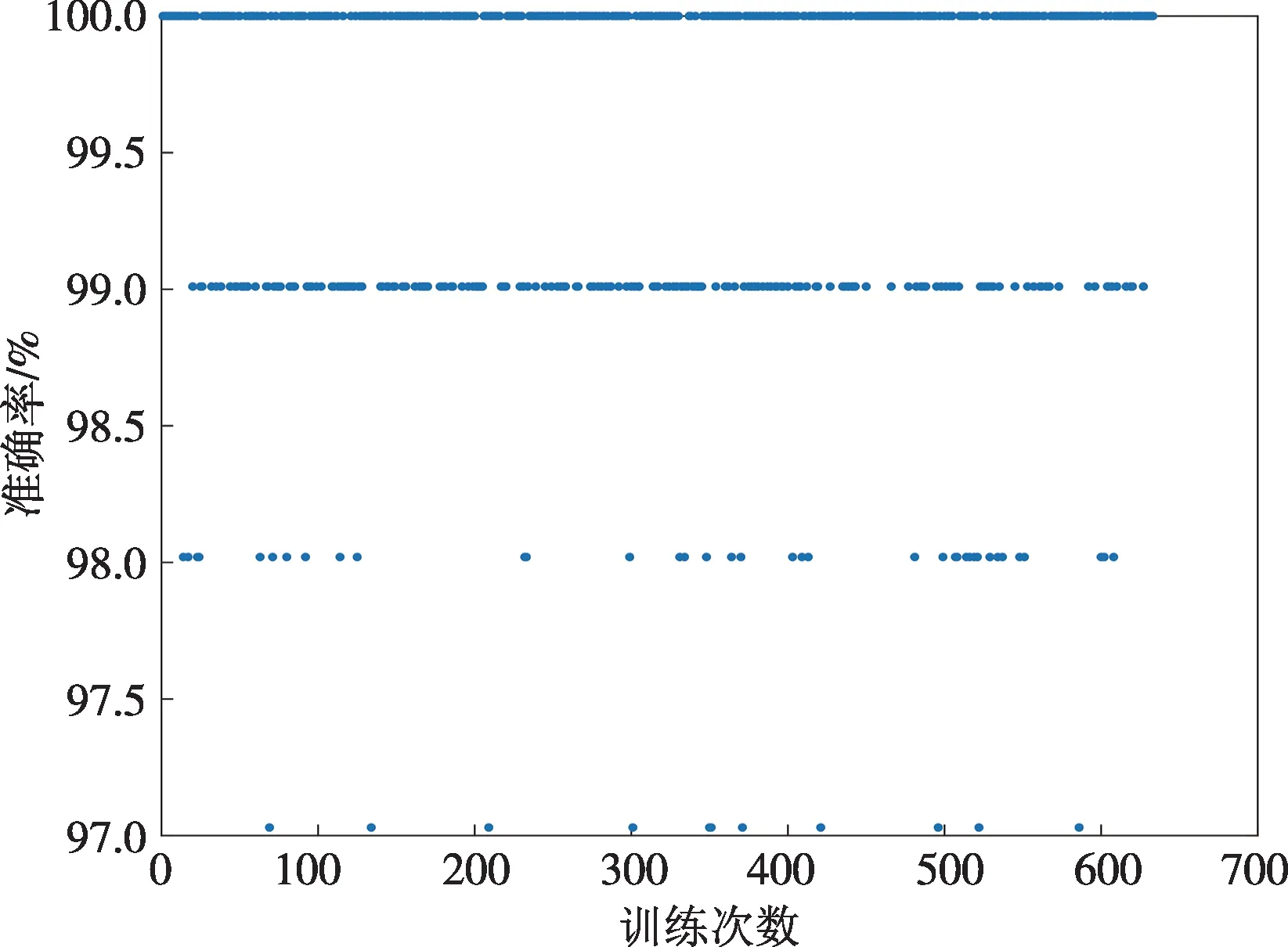
图8 模型测试准确率Fig.8 Model test accuracies
图8中,模型在测试集上的准确率介于97%~100%,表2 中给出了所提模型在测试集上的准确率,其值为99.71%。图8 中子模型平均准确率约为98.2%,与99.71%有着明显差距,这正是由于Bagging方法的集成效果,实现了整体大于个体之和的突破。

表2 各算法分类评价指标结果Table 2 Results of classification and evaluation indicators of the algorithms%
3.2 算法对照
3.2.1 二分类算法评价指标
为证明所提算法的有效性,设置了4种不同的算法进行对照,比较各个算法在测试集上的诊断效果。常用的分类评价指标有:准确率Ac、召回率Re、精确率Pr和F1等。
1)准确率,表示模型正确分类的个数占测试集总数的比例。
式中:TP表示实际为正例、模型评估结果为正例的样本;TN表示实际为反例、模型评估结果为反例的样本;FP表示实际为反例、模型评估结果为正例的样本;FN表示实际为正例、模型评估结果为反例的样本。本文中的正例为光伏电站无故障状态样本,反例为其余故障状态样本。
2)召回率,也称查全率,表示模型正确分类的正例个数占测试集实际正例个数的比例。
3)精确率,也称查准率,表示模型正确分类的正例个数占模型分类为正例的比例。
4)F1是基于召回率和精确率的调和平均值,是对召回率和精确率的综合评价。
根据上述各式得到各算法在测试集上的评价指标,结果如表2所示。
由表2 可知,所提算法模型不论是在准确率、召回率还是精确率上都有亮眼的表现,综合表现在4种算法中最优。
3.2.2 多分类算法评价指标
本文讨论的光伏故障诊断问题归属于多分类问题,以上的二分类算法评价指标还不够细致,因此,采用多维混淆矩阵具体展示各算法的故障诊断性能。
光伏运行共有5 种状态,图9 给出了4 种算法的5×5 故障诊断混淆矩阵,矩阵中行表示实际样本的故障类型,列表示模型评估出的样本故障类型。
图9(a)为BP模型的混淆矩阵。该矩阵第一列皆为100%,其余列皆为0%,这表明BP 模型将所有故障类型皆评估为“无故障”,这显然是不合理的。
图9(b)为BP-Bagging模型的混淆矩阵。该矩阵第一列和最后一列有非零值,其余列皆为0%,这表明该模型不能区分“短路”“老化”和“开路”故障,并且对“阴影”故障的判断准确率只有77.81%。该模型是BP 模型的Bagging 集成算法,在一定程度上有所进步,但距离目标模型仍有不小差距。
图9(c)为Random Forest模型的混淆矩阵。该矩阵是对角占优阵,这表明该模型对各种故障都有着较高的诊断准确率。具体地,模型对于“无故障”“开路”和“阴影”这三类运行状态有着极高的诊断准确率,对“老化”故障有着较高的诊断准确率,但有15.02%的概率将“老化”故障识别为“无故障”,存在较大的安全隐患,在实际工程中极易造成财产损失。
图9(d)为改进BP-Bagging 模型的混淆矩阵。该矩阵也是对角占优阵,相比于Random Forest模型具有更明显的优势。该模型对所有运行状态的诊断评估都有着非常高的准确率。对“开路”故障的识别率达到100%,对“无故障”“短路”和“阴影”的诊断识别率也接近100%,对“老化”故障的诊断识别率为94.77%。
同时,模型对故障的忽视现象仅出现在“阴影”故障诊断中,发生率为0.48%,由于“阴影”故障出现的概率仅为13.72%,因此该模型对故障的忽视率仅为0.066%,不足千分之一。虽然模型仍有一定的误判,但此行为不会在本质上造成光伏电站的故障扩大和设备财产损失。
考虑到样本集中样本的非均衡特性,上述分类指标并不能客观全面地反映算法性能。例如BP模型的准确率为86.28%,但根据表3 给出的各类型故障数据占比情况可知,一个模型无论其输入数据如何,如果将所有故障都诊断为无故障,那么该模型的准确率可达到84.65%。

表3 各类型故障统计数据Table 3 Statistical data for various types of failure
因此,考虑到样本集的非均衡特性,使用指标AU、TR、FR对分类结果进行补充评价。
式中:TR表示在所有实际为正例的样本中模型评估为正例的比例;FR表示在所有实际为反例的样本中模型评估为正例的比例。AU数值范围在0~1,数值越高代表模型的性能越佳,当AU=0.5时,表示当前的模型等同于随机猜测,一般认为当AU≥0.5时,模型才有实际意义。
按照式(17)计算得到4种算法在测试集上的评价指标,结果如表4 所示。根据定义可知,TR和AU为正向指标值,即数值越大,模型评价越高;FR为负向指标值,数值越大,模型评价越低。其中,改进BP-Bagging算法在评价指标上再次位列第一,证明了该算法在光伏电站故障诊断问题上的有效性。

表4 4种算法的评价指标Table 4 Evaluation metrics for the four algorithms%
为直观比较各模型的性能,绘制各算法5种评价指标值如图10 所示。可以看出,改进BPBagging 算法5 种指标值几乎都达到100%,较其余3种算法有着绝对的优势。
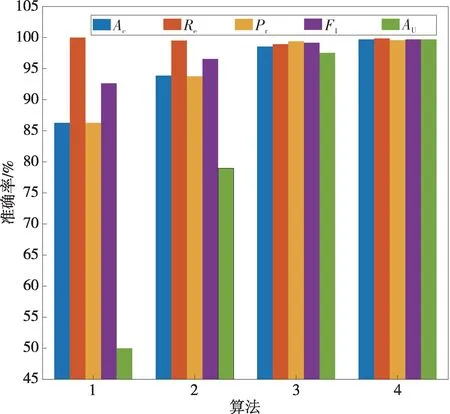
图10 各算法性能评价指标Fig.10 Performance evaluation indicators of the algorithms
4 结语
在“双碳”背景下,浙江省光伏装机容量快速增长,规模仅次于火电。在可预见的未来,光伏装机比例还将进一步增加,因此准确诊断光伏电站的故障类型对其安全稳定运行至关重要。
本文提出一种基于改进BP-Bagging算法的光伏电站故障诊断方法,取得如下研究成果:通过随机欠采样方法解决了样本分布不均衡的问题,有效提升了模型对故障样本特征的学习效果;基于Bagging集成学习框架,搭建光伏电站故障并行诊断模型,解决了单个BP模型存在的过拟合问题,有效提升了故障诊断的准确率。
猜你喜欢
中学生数理化·中考版(2021年12期)2021-12-31 03:24:42
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
建材发展导向(2019年5期)2019-09-09 09:23:00
中国交通信息化(2018年5期)2018-08-21 03:37:40
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
机械与电子(2014年1期)2014-02-28 02:07:31
河南科技(2014年3期)2014-02-27 14:05:48
