
Agricultural Investment Project Decisions Based on an Interactive Preference Disaggregation Model Considering Inconsistency
2024-03-24 01:31XingliWuHuchangLiaoShuxianSunandZhengjunWan
Xingli Wu ,Huchang Liao ,Shuxian Sun and Zhengjun Wan
1Business School,Sichuan University,Chengdu,610064,China
2National Institute of Measurement and Testing Technology,Chengdu,610021,China
ABSTRACT Agricultural investment project selection is a complex multi-criteria decision-making problem,as agricultural projects are easily influenced by various risk factors,and the evaluation information provided by decisionmakers usually involves uncertainty and inconsistency.Existing literature primarily employed direct preference elicitation methods to address such issues,necessitating a great cognitive effort on the part of decision-makers during evaluation,specifically,determining the weights of criteria.In this study,we propose an indirect preference elicitation method,known as a preference disaggregation method,to learn decision-maker preference models from decision examples.To enhance evaluation ease,decision-makers merely need to compare pairs of alternatives with which they are familiar,also known as reference alternatives.Probabilistic linguistic preference relations are employed to account for the presence of incomplete and uncertain information in such pairwise comparisons.To address the inconsistency among a group of decision-makers,we develop a pair of 0–1 mixed integer programming models that consider both the semantics of linguistic terms and the belief degrees of decision-makers.Finally,we conduct a case study and comparative analysis.Results reveal the effectiveness of the proposed model in solving agricultural investment project selection problems with uncertain and inconsistent decision information.
KEYWORDS Multiple criteria analysis;preference disaggregation;inconsistency;probability linguistic preference relation;investment project selection
1 Introduction
Agricultural industrial investment fund is a new type of financial investment institution with high policy,risk,growth,and social benefit,which takes equity investment as the main form of investment.This kind of investment can establish capital ties between social investors and agricultural enterprises,alleviate the financial difficulties of agricultural enterprises,and provide diversified investment channels for social capital.Selecting appropriate investment projects is an important link to improve the investment efficiency of agricultural industry investment funds.Agricultural investment project selection is a complex multi-criteria decision-making (MCDM) problem under uncertainty since agricultural projects are easily influenced by many risk factors such as climate,ecological environment,and technological change[1].
The MCDM technique is a decision process that supports ranking,selecting,or sorting a finite set of alternatives considering their performances on a family of conflicting criteria[2].A significant part of an MCDM practice is to establish a decision model (or preference model) of the decision maker(DM) participating in the decision process,incorporating his/her preferences and judgments.Direct preference elicitation methods require decision makers (DMs) to judge preference parameters such as criterion weights in the decision model.As an indirect preference elicitation method,preference disaggregation analysis is a data-driven MCDM technique that aims to infer the preference structure of DMs from decision examples.It has lower evaluation difficulty for DMs as they only need to synthesize judgments on familiar options.Therefore,this paper focuses on agricultural investment project selection problems using a preference disaggregation approach.
Moreover,as pointed out by Lindell [3] and Kahneman et al.[8],DMs are unreliable since their judgments are significantly influenced by many irrelevant factors such as their experience,knowledge,current mood,and even the weather.For this reason,a DM’s holistic judgments on reference alternatives may be inconsistent1“Inconsistent”here means that a DM provides decision examples that are incompatible with a single preference model..For example,the DM is contradictory in the statements,judging that A is better than B,B is better than C,and C is better than A.In this case,it is unable to find a preference model that is compatible with all decision examples [9].Resolving inconsistencies in holistic judgments is a basic task of preference disaggregation analysis,but it has not received due attention in existing methods.The stream of research at this point incorporated optimization models to find a minimal set of constraints that lead to infeasibility [5,6,10,11].The models were primarily proposed to restore feasibility in situations where a set of constraints results in an empty hyper-polyhedron;however,they failed to account for constraints being uncertain due to uncertain holistic judgments.
Given the analysis above,we initiate a preference disaggregation method to solve agricultural investment project selection problems.Given that judgments are often made in comparative rather than absolute terms[3],we suggest DMs make holistic judgments on reference alternatives through pairwise comparisons.The preference relations with preference tendencies and intensities between reference alternatives are described by linguistic terms.In addition to expressing possible preference relations between each pair of alternatives,DMs can also express their different belief degrees in these possible relations.Such a way of expression is consistent with subjective probability judgments[7,12],and each judgment is formalized as a piece of probabilistic linguistic preference information[13,14].
The contributions of this study are outlined as follows:
1)We construct a comprehensive preference disaggregation framework for agricultural investment project selection.Compared with existing MCDM-based project selection methods,this framework can estimate preference models from decision examples and reduce the cognitive effort that DMs spend on evaluation.
2)We address the uncertainty and inconsistency problems in agricultural investment project evaluation.Specifically,we use probabilistic linguistic preference relations to characterize hesitancy and incomplete belief degrees in pairwise comparisons.We convert pairwise comparisons into constraints using additive value functions and preference thresholds.We propose an inconsistency management process based on 0–1 mixed integer programming to identify and eliminate inconsistent information in uncertain pairwise comparisons.
The paper is organized in the following way.Related work is reviewed in the next section.Section 3 describes an agricultural investment project selection problem with probabilistic linguistic information.Section 4 proposes a preference disaggregation framework.Section 5 conducts a case study.Conclusions and future research directions are provided in Section 6.
2 Related Work
This section begins with a literature review of agricultural investment project selection research to identify challenges faced in this application area.Secondly,the research on preference disaggregation analysis is reviewed to identify its research progress and gaps.
2.1 Research on Agricultural Investment Project Selection
The agricultural sector requires substantial investment to increase agricultural productivity and promote agricultural industry development[15].However,in many countries,especially in developing countries,agricultural investments have a poor track record of success.In Ethiopia,the anticipated contribution of agricultural investment to the country’s economic growth remained at par for the last more than 20 years period[16].The poor performance of agricultural investments is mainly attributed to the complexity of agricultural development environments and data scarcity[1].More specifically,risks brought by uncertain factors,such as climate,ecological environment,and technological change,have a greater impact on the agricultural industry than other industries.These factors make agricultural investments a complex decision-making problem under uncertainty.How to choose agricultural investment projects reasonably is a significant problem for investors in the agricultural industry.
Cost-benefit analysis is a common technique for the selection of agricultural investment projects[1,15],which focuses on explicitly quantifying and monetizing all costs and benefits of investment projects [17].However,the World Bank2Cost benefit analysis in World Bank projects.Washington DC;2010.Available:https://openknowledge.worldbank.org/handle/10986/2561.warned that the proportion of projects justified by costbenefit analysis has been falling for decades due to a decline in adherence to standards and to the difficulty in applying cost-benefit analysis.It is hard to develop effective and appropriate approaches that handle the multitude of driving forces,uncertainty,and lack of data in agricultural development projects[15].In addition,the selection of agricultural investment projects is no longer based solely on the pursuit of profits but is entrusted with the mission of promoting the development of agricultural industry and ultimately improving social welfare.MCDM methods were widely used in investment selection under uncertainty because they can support DMs in situations where multiple conflicting criteria need to be considered simultaneously[18,19].The knowledge and experience of DMs play an important role in MCDM,making up for the lack of reliable and quantitative data[20,21].Unlike the cost-benefit analysis [22],decision results obtained by MCDM methods are determined by a DM’s personalized preference model,rather than just the economic cost and benefit of investment projects.Most studies[18,23]on investment selection used a direct preference exploitation process to capture a DM’s preference model.
2.2 Research on Preference Disaggregation Analysis
There are two types of preference elicitation methods in the field of MCDM.The first type is direct elicitation of preference parameters[24].The second type is the indirect inference of preferences through disaggregation from decision examples [25].Direct elicitation methods operate under the assumption that the DM fully understands the meaning of each parameter in the preference model and provides information about those parameters directly.However,this approach requires a significant cognitive effort on the part of the DM [9].In contrast,preference disaggregation analysis is more user-friendly.It only requires the DM to make holistic judgments on a small subset of alternatives that they are familiar with.The inferred preference model can then reconstruct the decision examples using ordered regression techniques.Preference disaggregation has gained increasing interest in the field of MCDM and has been applied in various real-world scenarios,such as credit risk modeling and management[26],market segmentation[27],and purchase decisions[28].
The UTA(UTilités Additives)method,originally proposed by Jacquet-Lagrèze and Siskos[29],is a preference disaggregation framework used for multi-criteria ranking.Its objective is to construct a preference model that aligns with decision examples provided by a DM through linear programming.This preference model comprises an additive value function for criterion aggregation and a set of piecewise linear marginal value functions for normalizing the performance values of alternatives under each criterion [30].The resulting model is then utilized to determine the ranking of all alternatives,including non-reference alternatives that the DM has not directly assessed.Motivated by the UTA method,several preference disaggregation techniques have been developed to model different preference structures in various decision problems.For example,the utilites additives discriminantes(UTADIS)[31]method aimed at solving multiple criteria sorting problems which concern an assignment of alternatives to a set of ordered classes.Considering interactive criteria,Liu et al.[32]applied a general value function with bonus and penalty components to construct a preference structure.In addition to value functions,other well-known MCDM models,including outranking relation-based methods such as the ELECTRE Tri-C[33]and PROMETHEE-based method[34],and decision ruleoriented methods such as the dominance-based rough set approach [35],have been also considered as underlying preference structures under the preference disaggregation framework.Nevertheless,the most widely used approach remains the additive value function based on the principle of multiple criteria utility theory[36,37].
3 An Agricultural Investment Project Selection Problem with Probabilistic Linguistic Information
To reduce the cognitive efforts of DMs in providing preferences,this study evaluates agricultural investment projects with uncertain data using preference disaggregation analysis.We focus on specifying the preference model of a DM for investment decisions through an indirect preference exploitation process.In this way,a large number of alternative projects can be evaluated and screened based on the holistic judgments on a small number of reference alternatives.Given the uncertainty in this decisionmaking problem,we adopt the probabilistic linguistic information to represent preferences,which can depict DMs’hesitation and incomplete assurance in judgments.The main notations used in this study are summarized in Table 1.
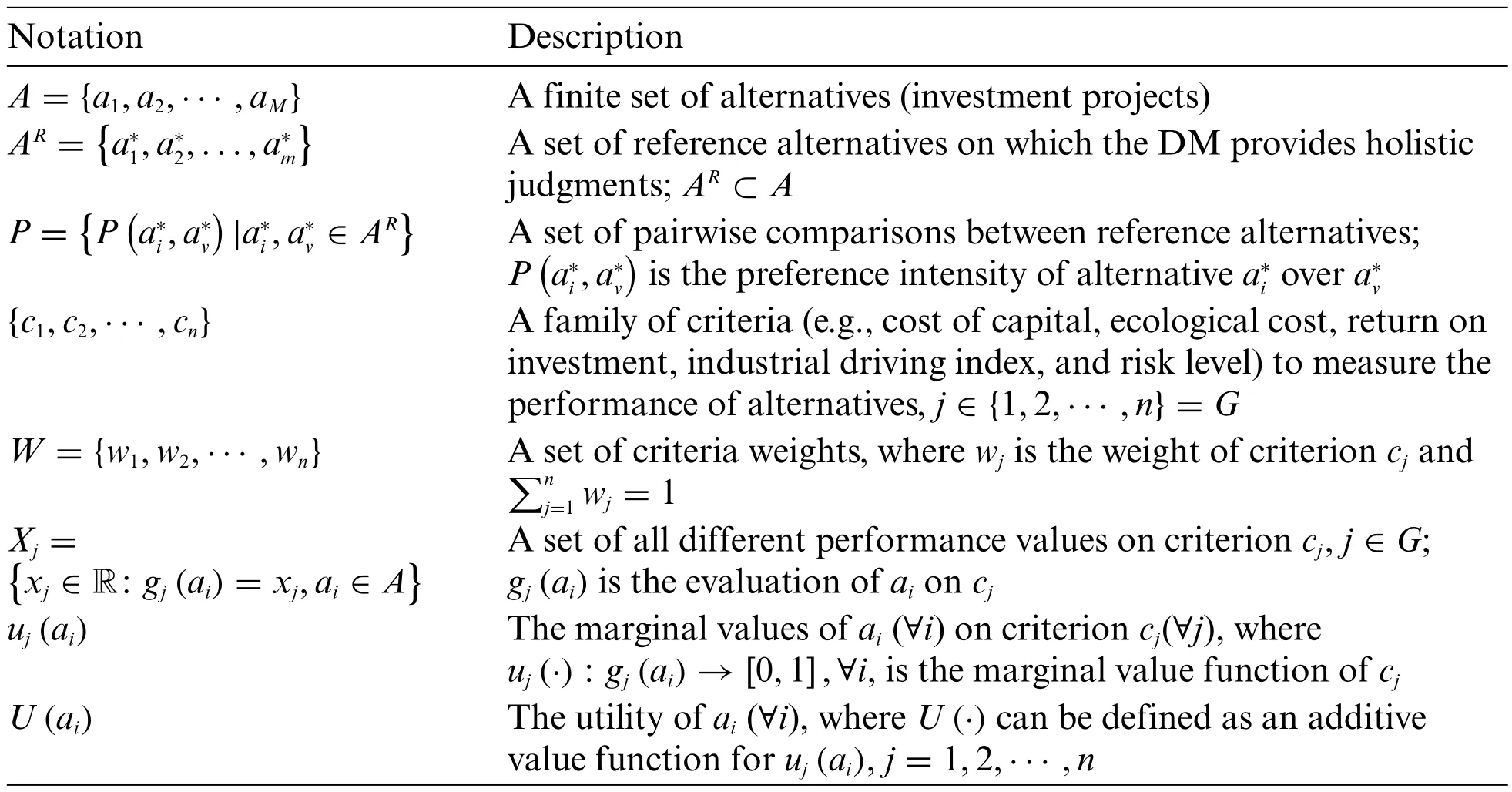
Table 1:Main notations used in this study
To facilitate judgment,we suppose that the DM is provided with a set of options regarding the preference relation of one alternative over another.In general,the options can be described by a linguistic term setS={s-τ,···,s-1,s0,s1,···,sτ} where the linguistic termsα(α∈{-τ,···,τ})represents a binary relation: (1)α >0 means a positive preference relation,(2)α=0 means an indifference relation,and (3)α <0 means a negative preference relation [14].The larger |α|is,the greater the preference intensity is.An example of a linguistic term set is{strongly less preferred(SLP,s-2),less preferred(LP,s-1),indifferent(I,s0),more preferred(MP,s1),strongly more preferred(SMP,s2)}.Due to the limited cognition of the DM to reference alternatives,the difficulty of the tradeoff process between criteria for holistic judgments,and the inherent fuzziness of linguistic terms,in this study,we consider that the preference information provided by the DM is uncertain.The DM is allowed to choose one or more linguistic terms to describe the preference relation between a pair of reference alternatives.In addition,the DM can use a numerical value in[0,1]to express his/her belief degree in each linguistic term.Such a piece of pairwise comparison information is called a probabilistic linguistic preference relation,whose elements are probabilistic linguistic term sets[13]shown as Eq.(1)whereindicates the DM’s belief degree in the preference of alternativebeing the linguistic termsα,and≤1.
This study considers the additive value function as a basic preference model,which assumes that the marginal values of an alternative under different criteria are independent of each other[41].Considering the trade-off weights of criteria,the additive value function can be expressed as Eq.(2),wherewj≥0 is the trade-off weight of criterioncjwith=1,andU(ai)is the global value of alternativeai.The marginal value functionuj(·)defines a mapping of criterioncjto a value scale in[0,1],and is usually supposed to be piecewise linear[29].
The inferred aggregation rule can be used to calculate the global value of each alternative,and then determine the ranking of all alternatives in setA.The ranking rule is that:(1)ifU(ai)>U(av),thenai≻av(“≻”represents a preference relation);and(2)ifU(ai)=U(av),thenai∼av(“∼”represents an indifference relation).
4 Methodology
This section proposes a preference disaggregation method to deal with agricultural investment project selection problems considering uncertain and inconsistent preference information.
4.1 Framework of the Proposed Method
The framework of the proposed model is shown in Fig.1,while the detailed steps are enumerated in Table 2.
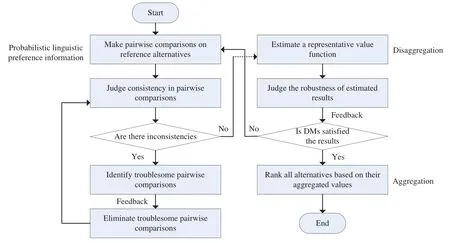
Figure 1:The framework of the proposed model

Table 2 The detailed steps of the proposed model
Overall,the proposed model consists of three stages,which can also be deemed as an interactive process between the analyst and DM.Firstly,the analyst introduces the DM the agricultural investment project selection problem,including the alternatives and criteria,and asks the DM to compare reference alternatives in pairs based on their overall performances.The DM can be asked to provide preferences through face-to-face questioning or questionnaires.The judgments provided by the DM are expressed as probabilistic linguistic term sets.The second stage (See Section 4.2 for details) is the management of inconsistencies in pairwise comparisons.The DM is recommended to change or remove some of the troublesome pairwise comparison values identified by Models 1 and 2.In the last stage(See Section 4.3 for details),the analyst estimates a value function through Model 3 based on consistent pairwise comparison values.Post-optimality analysis is used to check the robustness of estimations.The analyst returns the estimated result to the DM.If the DM is satisfied with the result,the preference disaggregation process is finished,and the estimated value function is used to make aggregation,such that the alternatives can be ranked based on their aggregated values.If the DM is not satisfied with the result,then (s)he is required to change original pairwise comparison values according to the estimated results,and the preference disaggregation process is repeated until the DM satisfies the estimated results.It should also be noted that the six optimization models(Models 1–6)introduced in this paper are all linear programming models that can be solved using mathematical programming solvers such as Gurobi and Cplex.In addition,none of the constraints in each model are conflicting or contradictory,so they always have solutions.
4.2 Managing Inconsistencies in Uncertain Pairwise Comparisons
There are three reasons which lead to the fact that we cannot find an additive value function to reproduce the pairwise comparisons provided by a DM [5,42]: (1) the DM’s preference model is not additive (which may occur when decision criteria are interactive);(2) the DM makes errors in the statements (e.g.,statingbut in fact);and (3) the DM provides contradictory statements(e.g.,providingat the same time)because of his/her limited ability to make holistic judgments on reference alternatives and unstable judgment policy.The first one is a technique problem,that is,the additive value function cannot model the DM’s preferences.Interested readers may refer to Liu et al.[32],which investigated non-additive preference models in preference disaggregation analysis.This study only focuses on multi-criteria ranking problems where the preference model is additive.Thus,the first scenario is not considered here.The last two reasons are subjective problems regarding unreliable judgments of the DM.In this sense,inconsistencies can be eliminated by dealing with troublesome pairwise comparisons.
If the constraints on all pairwise comparison values provided by the DM are feasible,then the preference information is consistent,and at least one value function is compatible with all the provided decision examples.Otherwise,incompatibility (i.e.,inconsistent pairwise comparison information)exists.In this case,we can find a set of pairwise comparisons which make the constraints on the remaining pairwise comparison values are feasible when we remove them.Searching for the smallest number of troublesome pairwise comparison values is consistent with the idea that the DM first considers “less complex” ways to resolve inconsistencies [10].The identification procedure to find troublesome pairwise comparison values can be performed by solving Model 1.
There may be multiple subsets of troublesome pairwise comparisons that lead to inconsistency with the optimal objective function value of Model 1 beingF∗.An intuitive goal of dealing with inconsistency is to maintain the original preference information provided by the DM as much as possible.We can find a value function that represents the most likely preference model with the minimum estimation error [6].Pairwise comparison values that are not compatible with this value function can be identified as a representative option to remove inconsistency.The identification procedure can be performed by solving Model 2,which is a 0–1 mixed integer programming model.
Overall,the procedure to manage inconsistencies in pairwise comparison values is presented as follows:
Step 2.1.The analyst uses Model 1 to check if the pairwise comparisons are consistent.IfF∗=0,the preference information is consistent,and the process of dealing with inconsistency is finished.Otherwise,the preference information is inconsistent,andF∗is the minimum number of pairwise comparisons that lead to inconsistency,and then go to the next step.
Step 2.2.The analyst uses Model 2 to identify a subset of troublesome pairwise comparisons,and return such information to the DM.Go to the next step.
Step 2.3.The DM is required to change or remove the preference statements on all or some of the identified troublesome pairwise comparisons.Go to Step 2.1.
If multiple DMs participate in decision-making,we follow the aforementioned steps to assess consistency in the pairwise comparisons provided by each DM.Once the pairwise comparisons of all DMs satisfy consistency,we integrate their comparisons.In this process,if multiple DMs simultaneously compare a pair of reference alternatives,their collective opinion is also expressed as a probabilistic linguistic term set.The probability of each linguistic term in this set is the average of the probabilities corresponding to that linguistic term provided by different DMs(Details can be found in[42]).In this setting,the collective opinion of DMs is applied for preference disaggregation.It should be noted that when dealing with large numbers of DMs,individually interacting with them to revise troublesome pairwise comparisons is costly.Therefore,we may consider deleting the identified troublesome pairwise comparisons in Step 2.2 without further requiring the DMs’interaction with the analyst.
4.3 Deriving a Value Function through Preference Disaggregation
The value function should satisfy the setting in which the value difference of each pair of reference alternatives is as close as possible to the semantics of their probabilistic linguistic preference information.In this sense,can be taken as the underestimation and overestimation errors,respectively.Estimating a value function can be achieved through linear programming to minimize the total estimation errors for all pairwise comparison values.Thus,Model 3 is constructed,where the first part of the constraints is basic requirements for a value function that describes the preference relation between each pair of reference alternatives.The second part of the constraints is critical for estimating a value function that makes the difference between the global values of each pair of reference alternative close to the semantics of their probabilistic linguistic preference information provided by the DM.The third part of the constraints is about the marginal values of criteria.The fourth one is about the semantics of linguistic terms,defined by adjacent preference thresholds.The last two parts of constraints are about the values of decision variables,including the weights of criteria and the estimation errors.
However,due to the uncertainty in the preference information provided by the DM,the value function corresponding to the optimal solution obtained in Model 3 does not always reflect the DM’s preference structure well.In this sense,we need to explore suboptimal solutions in the neighborhood of the optimal solution obtained by Model 3.Therefore,we conduct post-optimality analysis by Model 4,with the objective of minimizing and maximizing the trade-off weight of each criterion,respectively[29].It aims to explore other possible values of the variables with an additional constraint asT≤(1+k)T∗,whereT∗is the objective value of Model 3,andkis a user-defined small positive number.
Model 4.Max/Minwj
5 Case Study:Agricultural Investment Project Selection
To demonstrate the applicability of the proposed model,we elaborate a case study on agricultural investment project selection.
5.1 Case Description
The local government in a region prioritizes agricultural development and has established a Rural Revitalization Investment Fund.This fund selects outstanding agricultural projects for annual funding,focusing on key sectors such as local characteristic industries,modern farming,agricultural product processing and distribution,rural leisure tourism,new service industries,and the information industry.The fund is committed to providing capital support for rural revitalization based on mature,promising,and market-oriented industrial projects.After an initial screening,the fund managers have shortlisted 25 project applications(P1–P25)as candidates and plan to choose 5 projects for funding.They have decided to use the following 5 decision criteria to evaluate the projects after conducting in-depth project analysis:
1.Cost of capital(cost criterion):the capital cost of the agricultural industry investment funds.
2.Ecological cost (cost criterion): the cost of ecological environmental damage.Due to the large use of natural resources such as land,agricultural enterprises would inevitably affect the ecological environment system formed over a long period and even change the ecological balance of the surrounding land.
3.Return on investment(benefit criterion):the economic return value through the investment.
4.Industrial driving index (benefit criterion): the economic driving force of agricultural enterprises (projects) can be divided into three aspects: regional driving force,industrial driving force,and technological driving force.It reflects the economic driving effect of investments.
5.Risk level(target criterion):the object of the agricultural industry investment fund is the agricultural enterprises in the initial stage,which belongs to the venture capital fund.Investment risk,including natural risk,operation risk,and market risk,is an important factor in evaluating projects.Here the risk of projects is divided into five levels.Different DMs have different attitudes to risk.
The performance values of the 25 projects under the five criteria were collected from the materials provided by agricultural enterprises(see Table 3).The first two criteria are in cost form,while the next two criteria are in benefit form.The last criterion is a target-type criterion,and its optimal value is not the minimum or maximum,but rather between them.Suppose that the optimal value of the last criterion is 3.
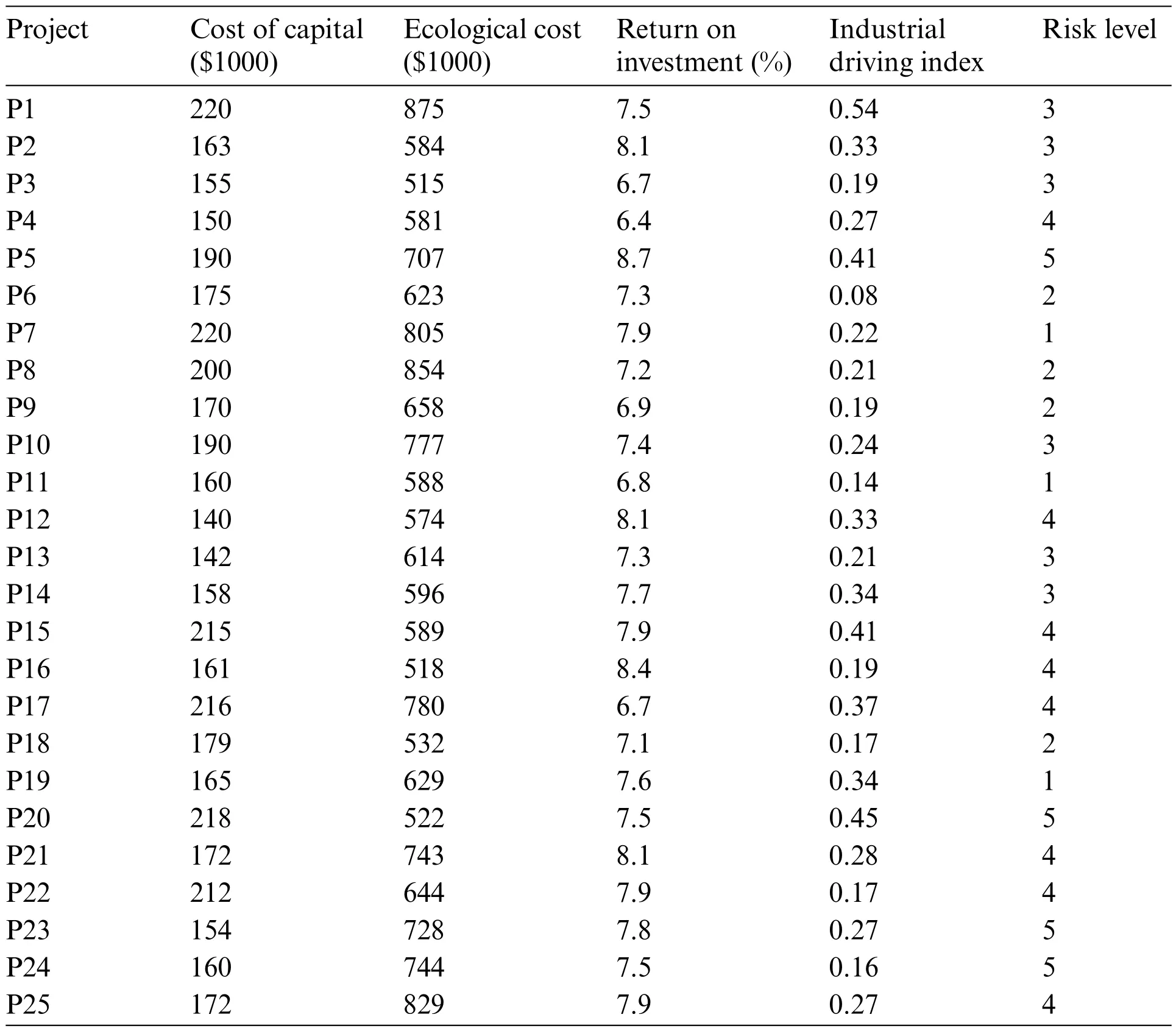
Table 3:Performance values of the agricultural projects under the five criteria
5.2 Resolving Process Based on the Proposed Model
To assess the alternative projects rigorously,this study employs the proposed method to develop a decision model,offering decision support.The first step involves inviting a DM to conduct pairwise comparisons of the alternative projects (s)he is familiar with.The linguistic term set for pairwise comparisons is set to {SLP,LP,I,MP,SMP}.The judgments are shown in Table 4.There are uncertain preference intensities between some reference alternatives.For example,the possible preference intensities between P2 and P5 are MP and SMP,and the belief degree of the DM in MP is 0.2,and that in SMP is 0.8.
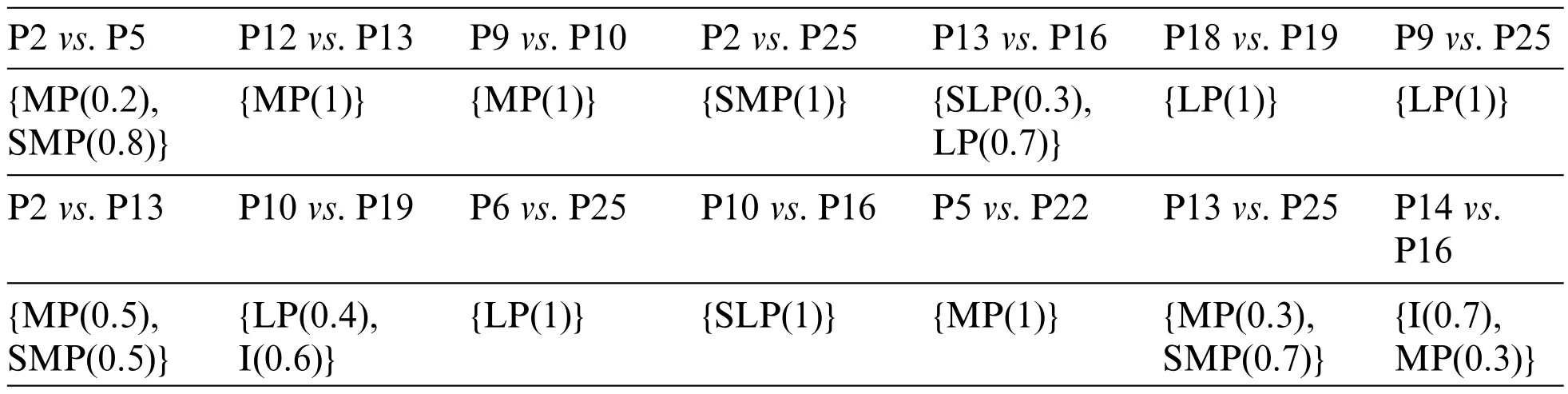
Table 4:Pairwise comparisons between reference projects expressed as probabilistic linguistic term sets
Before the solving process is performed,the parameters in the model need to be determined.Considering that all the five criteria have an impact on the decision result,we set the weight of each criterion to be greater than 0.05,i.e.,γ=0.05,which is lower than the average weight 0.2.To measure the marginal values of the first four criteria,we set the number of subintervals in the marginal value function to a moderate value,3.Given that the last criterion is valued between 1 and 5,we set each risk level as a segment point of the marginal value function of the criterion.For generality,the minimum difference between each pair of adjacent segment points is set to 0.2.In addition,the preference thresholds are set tot1=0.05,t2=0.15,andt3=0.25.It means that,if the difference in values between a pair of alternatives is less than 0.05,they are indifferent;if their difference is greater than 0.15,they have a strong preference relation;otherwise,their preference relation is weak.The parameter for post-optimality analysis is set ask=0.01.
Using Model 1 to test the consistency of the original pairwise comparison values provided by the DM,we find at least one troublesome pairwise comparison value.Then,using Model 2,the most likely troublesome pairwise comparison value is identified as the preference of P2 over P25,i.e.,{MP(1)}.After the feedback,the DM changes the preference of P2 over P25 to{SMP(1)}.Based on Model 1,we find that the pairwise comparison values after update are consistent.Then,the updated pairwise comparison values are disaggregated through Model 3,and a value function is obtained to describe the preference structure of the DM.The weights of five criteria are estimated to be 0.29,0.09,0.3,0.14,and 0.19,respectively,indicating that the DM pays the most attention to the return on investment and cost of capital,and pays the least attention to the ecological cost.Except for the two cost criteria,the other criteria have different marginal utility functions,as shown in Fig.2.According to the estimated value function,criterion values of each alternative are aggregated to determine the ranking of all alternatives.The top five alternatives are P2,P12,P14,P16 and P13,which can be recommended to the DM for project investment.
We further use Model 4 to carry out post-optimality analysis for the preference parameters.The estimated weight of each criterion is shown in Fig.3.Except for the industrial driving index,the weights of other four criteria are relatively stable.At the same time,the marginal value functions of all criteria are stable.We average the ranks of alternatives obtained in the post-optimality analysis.The results also show that the top five alternatives are P2,P12,P14,P16,and P13,respectively,indicating that the estimated value function is robust.
5.3 Comparative Analysis
Based on the case study,this section compares the proposed model with a UTA-like method and a preference disaggregation model without consistency management.
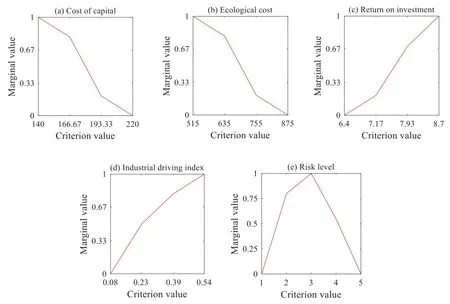
Figure 2:The marginal value functions of five criteria
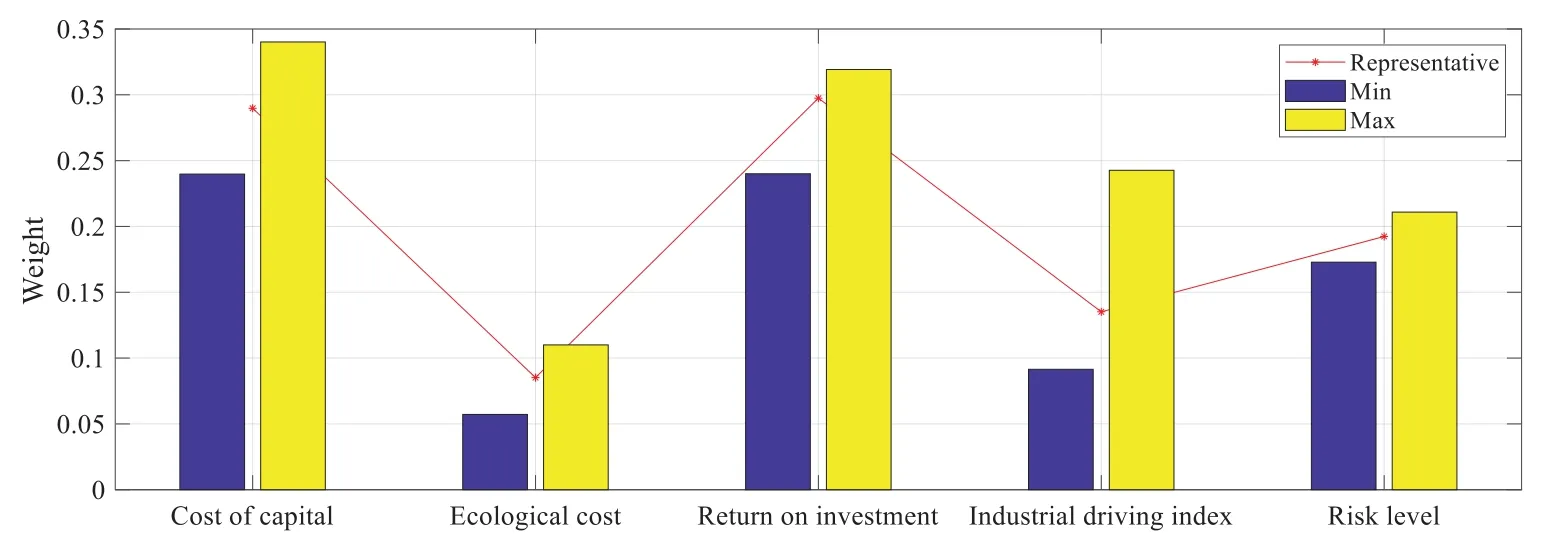
Figure 3:The maximum,minimum,and representative weights of criteria
5.3.1 Preference Disaggregation by a UTA-Like Method
In the UTA method as well as most of its extensions,the preference relation between reference alternatives is expressed as an“indifferent(I)”or“preferred(P)”relation[25].To illustrate the necessity of considering the uncertainty of preference intensities between reference alternatives in preference disaggregation analysis,we re-invite the DM to provide preferences based on the linguistic term set{I,P},as shown in Table 5.

Table 5:Pairwise comparisons between reference projects expressed as single linguistic terms
In the original version of UTA [29],an error function to be minimized is introduced for each reference alternative.This error function is not sufficient to completely minimize the error.To solve this problem,the UTASTAR method [46] uses a double positive error function.According to the UTASTAR method,Model 5 can be established to estimate the DM’s preference model.
Through Model 5,the weights of the five criteria are estimated to be 0.36,0.05,0.25,0.13 and 0.21,respectively.The top five alternatives are P12,P2,P14,P16,and P13,respectively,which are slightly different from the results obtained by our proposed model.
5.3.2 Preference Disaggregation without Consistency Management
An important part of our proposed preference disaggregation technique is to deal with inconsistent preference information.To illustrate the need to eliminate inconsistent preferences before preference disaggregation,we compare the results obtained by the proposed model with those obtained by the preference disaggregation analysis based on inconsistent preference information.In the model for comparative analysis,the constraints on the value function to be compatible with all pairwise comparison values are not considered,so Model 6 is established.Model 6 does not contain the first part of the constraintsin Model 3,and all other constraints and decision variables are consistent with Model 3.
Through Model 6,the weights of five criteria are estimated to be 0.13,0.12,0.27,0.30,and 0.18,respectively.The top five alternatives are P2,P14,P12,P16,and P1,respectively.
5.3.3 Discussions
Table 6 shows the global values and ranks of the projects estimated by the three preference disaggregation models.In the following,a detailed comparison of the results obtained from the three models is presented,and the advantages of the proposed model are highlighted:
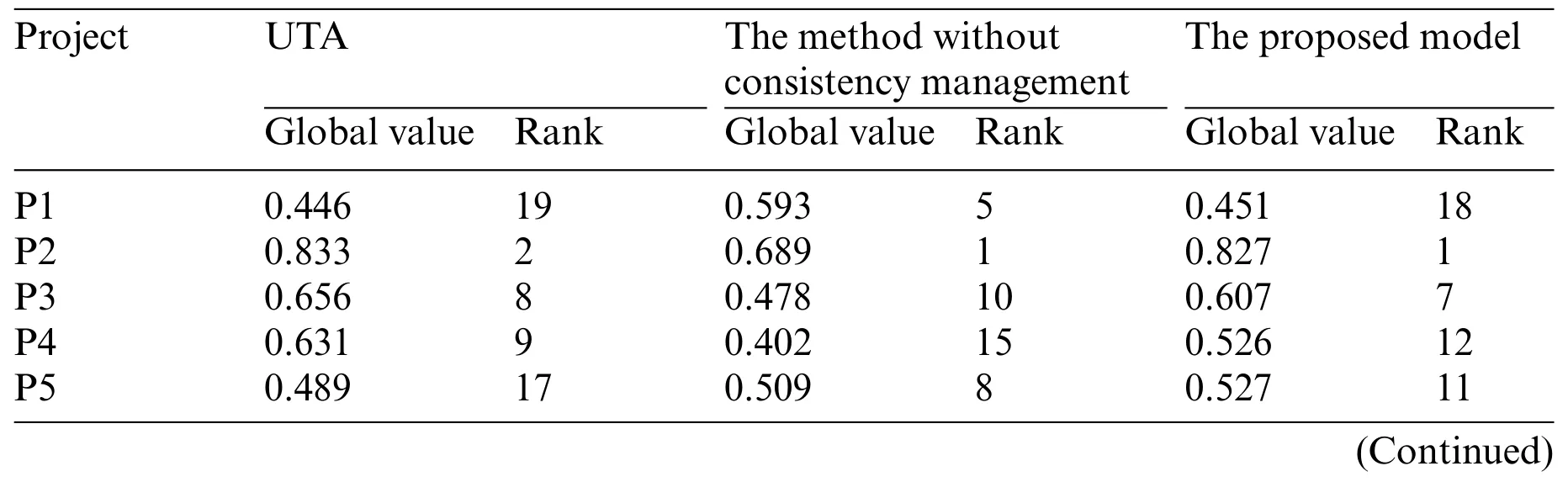
Table 6:The global values and ranks of projects estimated by the three preference disaggregation models
(1)According to the Pearson correlation coefficient[47],we calculate the similarity between the ranking obtained by the UTA method and the ranking obtained by our proposed model.The result is 0.965.This high similarity indicates that the proposed model is reliable.In addition,the results of the two methods are slightly different as the uncertainty in preference intensities is considered in our proposed model.For example,the global values of P6,P25,and P2 obtained by our proposed model are 0.486,0.586,and 0.827,respectively,and those obtained by the UTA method are 0.495,0.671,and 0.833,respectively.The results of the proposed model conform to the original opinion of the DM,that is,the preference intensity of P2 over P25 is greater than the preference intensity of P25 over P6.However,the results of the UTA method do not conform to this opinion.Therefore,when the DM is allowed to express preferences as probabilistic linguistic information,the results of preference disaggregation can be more compatible with the DM’s underlying preference model.
(2)The Pearson correlation coefficient between the ranking results obtained by Model 6 and those obtained by our proposed model is 0.8,indicating that there is a significant difference between the results obtained by the two models.The value function estimated by Model 6 is not compatible with all the pairwise comparison values provided by the DM.For example,the DM stated that P9 is preferred to P10;however,the global value(0.352)of P9 estimated by Model 6 is smaller than that(0.394)of P10.In this regard,we can conclude that the use of inconsistent preference information can mislead the estimation results of preference disaggregation analysis.
6 Conclusions
This study proposes a preference disaggregation method to solve multi-criteria ranking problems with inconsistent preferences under uncertainty.The underlying preference model was set as an additive value function consisting of a set of piecewise linear marginal value functions that measure the values of criteria that may be in benefit,cost,or target form.Two 0–1 mixed integer programming models were constructed to check and eliminate inconsistencies in the holistic judgments of reference alternatives provided by the DM.A linear programming model was established to infer a value function that is not only compatible with all the holistic judgments but also can reproduce the desired preference relations between reference alternatives as much as possible.Based on the semantics of linguistic terms and the DM’s belief degrees in each term,the holistic judgments were transformed into the constraints in these optimization models.A case study on agricultural investment project selection demonstrated the desirable characteristics of the proposed method.Overall,the proposed model provides impact and insights for dealing with agricultural investment project selection problems with uncertainty.The implementation of the proposed model not only mitigates the complexity of evaluation for DMs but also minimizes inconsistencies in collective evaluation information.Furthermore,this approach enables DMs to utilize a blend of linguistic and probabilistic expressions that they are familiar with during the evaluation process.
Future research can be carried out in the following three aspects.(1)Future research into project evaluation and selection problems,where criteria interact,could harness non-additive value functions such as Choquet integrals and multilinear utility functions to portray the preference structure of DMs.(2) Future research into MCDM problems that involve a large number of DMs should take into account the trade-off between the consistency of decision information and the cost of interaction to achieve consensus.(3) For MCDM problems with large-scale historical decision examples,crossvalidation can be investigated to evaluate the preference disaggregation framework objectively.In this way,the fitting and prediction ability of the estimated preference models can be measured.
Acknowledgement:We would like to thank the anonymous reviewers who have helped to improve the paper.
Funding Statement:None.
Author Contributions:The authors confirm contribution to the paper as follows:study conception and design: Xingli Wu;data collection: Xingli Wu,Shuxian Sun;analysis and interpretation of results:Xingli Wu,Shuxian Sun;draft manuscript preparation: Xingli Wu,Huchang Liao,Shuxian Sun,Zhengjun Wan.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials:All data are available in this paper.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2024年6期
Computer Modeling In Engineering&Sciences2024年6期
- Computer Modeling In Engineering&Sciences的其它文章
- A Study on the Transmission Dynamics of the Omicron Variant of COVID-19 Using Nonlinear Mathematical Models
- Novel Investigation of Stochastic Fractional Differential Equations Measles Model via the White Noise and Global Derivative Operator Depending on Mittag-Leffler Kernel
- Saddlepoint Approximation Method in Reliability Analysis:A Review
- A Review of the Tuned Mass Damper Inerter(TMDI)in Energy Harvesting and Vibration Control:Designs,Analysis and Applications
- Recent Advances on Deep Learning for Sign Language Recognition
- A Survey on Blockchain-Based Federated Learning:Categorization,Application and Analysis