
QGAE: an end-to-end answer-agnostic question generation model for generating question-answer pairs
2024-03-23 04:33:26LinfengLiLichengZhangChiweiZhuandZhendongMao
中国科学技术大学学报 2024年1期
Linfeng Li,Licheng Zhang,Chiwei Zhu,and Zhendong Mao ✉
1School of Cyber Science and Technology, University of Science and Technology of China, Hefei 230027, China;
2School of Information Science and Technology, University of Science and Technology of China, Hefei 230027, China
Abstract: Question generation aims to generate meaningful and fluent questions,which can address the lack of a questionanswer type annotated corpus by augmenting the available data.Using unannotated text with optional answers as input contents,question generation can be divided into two types based on whether answers are provided: answer-aware and answer-agnostic.While generating questions by providing answers is challenging,generating high-quality questions without providing answers is even more difficult for both humans and machines.To address this issue,we proposed a novel end-to-end model called question generation with answer extractor (QGAE),which is able to transform answeragnostic question generation into answer-aware question generation by directly extracting candidate answers.This approach effectively utilizes unlabeled data for generating high-quality question-answer pairs,and its end-to-end design makes it more convenient than a multi-stage method that requires at least two pre-trained models.Moreover,our model achieves better average scores and greater diversity.Our experiments show that QGAE achieves significant improvements in generating question-answer pairs,making it a promising approach for question generation.
Keywords: deep learning;natural language processing;answer-agnostic question generation;answer extraction
1 Introduction
Question generation[1,2](QG) is defined as the task of generating fluent,meaningful questions automatically from texts with optional answers,so it can be mainly divided into two streams: answer-aware QG[3]that requires answers,and answer-agnostic QG[4]that does not.QG is the reverse task of question answering (QA),which is a long-standing and valuable task helping computers achieve machine reading comprehension[5,6],dating back to the 1960s[7].As with many other supervised learning[8,9]tasks,QA will also encounter the lack of annotated data in spite of the fact that annotated data sometimes make the most essential part of the whole work.
QG is a popular choice for data augmentation for QA to alleviate insufficient labeled data.With the continuous development of Internet technology,it is becoming increasingly easier to obtain valuable data from the Internet.However,question-answer pairs (as shown in Table 1) are still such expensive corpora that typically require manual annotation by crowdsourcing before being used for supervised learning on QA and QG tasks.To alleviate the high-cost problem of generating question-answer pairs,it is natural to consider answeragnostic QG,since its only input is raw text.

Table 1. A case of QA-pairs generated by our QGAE model: the model accepts unannotated texts as input,extracts the highlighted phrase“Lorentz’s law” as an answer,then uses this answer to make question generation.
Although labeled answers are not necessary,answeragnostic QG is still facing a great challenge.Most previous works focused on providing additional information to their models by leveraging named entity recognition (NER)[10]to obtain extra linguistic features,adding answer position features[11],using knowledge graphs[12],and some other methods to improve the generation effect.These methods effectively improve the fluency and accuracy of generated texts,but answer-agnostic QG still performs worse than answer-aware QG.Thus,answer-aware QG may play an irreplaceable role,and changing answer-agnostic QG to answer-aware QG is a good choice.Apart from this,there is still an obstacle in generating question-answer pairs that answer-agnostic QG can’t generate answers.To address this issue,researchers often add an additional measure for question-answer pair generation:answer extraction.Compared with generating an answer,extracting an exact span in the context is much simpler.
Explicitly extracting candidate answers will not only resolve the demand for the lack of answers but also can transform answer-agnostic QG into answer-aware QG.As shown in Fig.1,some works such as RGF[13](retrieve-generate filter)proposed a multi-stage pipeline method to handle the problem.A multi-stage pipeline method is often designed in complexity,including several parts,and each part may need different inputs.Some early RNN-based[14-17]works optimized pipeline methods in an end-to-end way,which makes the overall structure lighter and faster.Though pre-trained language models (PLMs) have occupied dominance in both natural language generation and understanding,there is still no end-to-end work using pre-trained models to generate question-answer pairs.We are sure there is enough potential for PLMs to achieve the task.
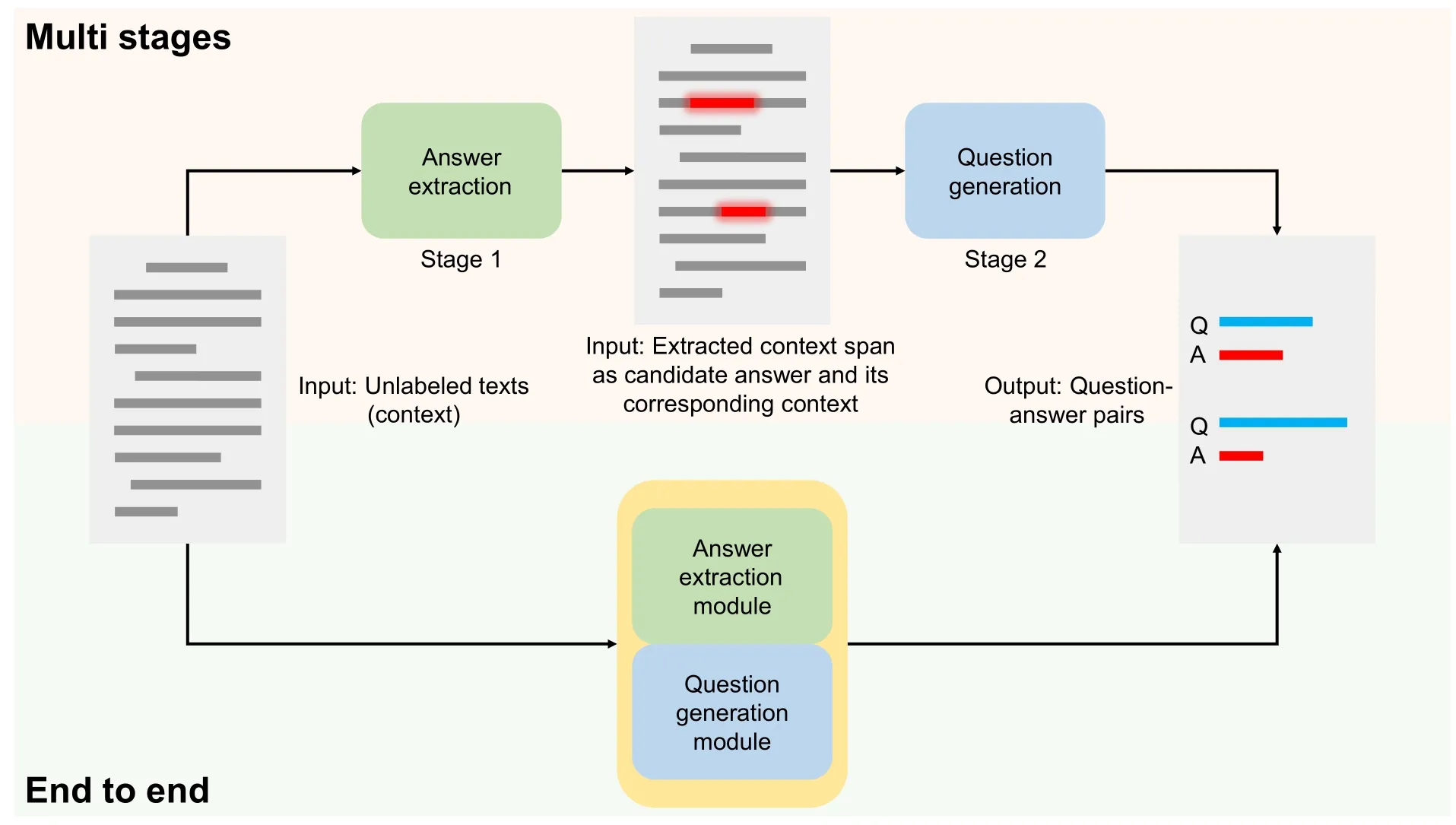
Fig.1. The difference between multi-stage methods and end-to-end models is that a multi-stage method usually has more than one model in the whole workflow.In every stage,a multi-stage method may need to deal with different inputs and outputs,while on the contrary,an end-to-end model only needs a definite kind of input.
In this study,we are motivated by the weak performance of answer-agnostic QG compared to answer-aware QG,inspired by the combination of QG and AE tasks,trying to propose an answer-agnostic question generation model called question generation with answer extractor (QGAE) to alleviate the high demand for large-scale QA pairs.QGAE is a multi-task model that requires only raw texts as input and can achieve the dual tasks: answer extraction and question generation.We design our model based on the PLM model BART[18],which has dual encoders and a decoder to generate questions and extract answers in parallel.In our study,question generation is the main task,which is the most challenging part similar to all other generation tasks for generated texts’ high syntactic diversity and semantic substitutability,so we pay more attention and assign a higher weight to the corresponding module.Therefore answer extraction is considered an auxiliary task.The design not only makes it feasible to turn answer-agnostic question generation into answer-aware question generation but also enables the model to be considered capable of generating question-answer pairs.The contributions of this paper are summarized as follows:
● We are the first to propose a new end-to-end model using PLMs,which is called QGAE for answer-agnostic question generation.
● The QGAE model generates question-answer pairs from unannotated texts without requiring any additional information.
● Our model achieves state-of-the-art performance in generating high-quality question-answer pairs,outperforming existing methods by a significant margin.
The rest of this paper is organized as follows.In Section 2,we review the related works of question generation and answer extraction.In Section 3,we formulate the QG task and AE task.In Section 4,we describe each module of our QGAE model.In Section 5,we introduce our experiment in detail.In the last Section 6,we conclude this work and give a detailed analysis.
2 Related works
2.1 Question generation
The QG field was devoted great interest by researchers for its great potential benefits;therefore,it has made great progress in application scenarios such as data augmentation[19],chatbots[20],machine reading comprehension[21],and intelligent tutors[22].
In the neural model age,Du et al.[4]proposed the first neural QG model focused on answer-agnostic QG.They investigated the effect of encoding sentence-vs.paragraph-level information by using an attention-based model and found that as the size of the input text increased,the evaluation score of the output decreased.To deal with the rare or unknown word problem,Gulcehre et al.[23]proposed a copy mechanism that was first used in the neural machine translation[24]to solve the out-of-vocabulary problem.This mechanism was absorbed in the QG task and widely used.Following the old experience of rule-based QG[25],Wu et al.[26]suggested two new strategies to deal with this task: question type prediction and a copy loss mechanism.Du et al.[15]combined answer extraction and question generation in an LSTM[27]model including answer feature embedding,denoting answer span with the usual BIO tagging scheme[28].
In the transformer-based[29]PLM era,compared to autoencoder models,auto-regressive[30]models are widely picked as baselines for the QG task.Laban et al.[20]fine-tuned a GPT2[31]as the base part of a question-driven news chatbot.Wang et al.[32]leveraged BART to propose QAGS (question answering and generation for summarization) to evaluate automatic summarization.Bhambhoria et al.[33]leveraged T5[34]to generate QA pairs for COVID-19 literature.Paranjape et al.[13]developed a retrieve-generate filter (RGF) technique to create counterfactual evaluation and training data with minimal human supervision,which is a multi-stage job.
The traditional works above have motivated us to explicitly infer the candidate answer to transform the answeragnostic QG into the answer-aware QG.Meanwhile,PLMs with fine-tuning achieved SOTA in many NLP fields,becoming benchmarks hard to bypass.In multi-stage work,researchers will choose different PLMs for different stages in question-answer pair generation,which is effective but heavy.There’s still no end-to-end work to handle the whole task.Therefore,we combine answer extraction and question generation using PLMs and propose an end-to-end model that extracts answers and generates questions in parallel.
2.2 Answer extraction
Information extraction[35,36](IE) is basically defined as the task of turning the unstructured information expressed in natural language text into a structured 3-tuple representation as (NE1;R;NE2).Thus,answer extraction can be seen as a sub-field of IE,expecting to pick the most valuable phrase from tuples,regardless of whether it is a named entity,a relation,or their combination: an event.Many IE systems have been proposed for open domains.Yahya et al.[37]describe ReNoun,an open information extraction system that complements previous efforts that rely on big knowledge bases by focusing on nominal attributes and on the long tail.Del Corro and Gemulla[38]proposed ClausIE,a novel,clause-based approach to open information extraction,which extracts relations and their arguments from natural language text.Additionally,some rulebased systems using man-made extraction rules have been proposed,including verb-based[39],semantic role labeling[40],and dependency parse trees[41].
In the era of pre-trained models,auto-encoder[42]models,such as BERT[43]have made great progress in natural language understanding (NLU) tasks.BERT achieves SOTA in the GLUE[44]score which is a multi-task benchmark including named entity recognition.It is a declaration that large PLMs are blossoming in the IE field and will take the place of traditional methods.
3 Task definition
Answer-agnostic question generation.It aims to generate fluent,meaningful questionsQ={q1,q2,···,qn} from unlabeled input contextC={c1,c2,···,cm} without a specific answer.Suppose the length of the question sequence isnwhile the length of the context sequence ism.During training,this task aims to maximize the conditional probability ofQ.All relevant parameters in the model are denoted by θ:
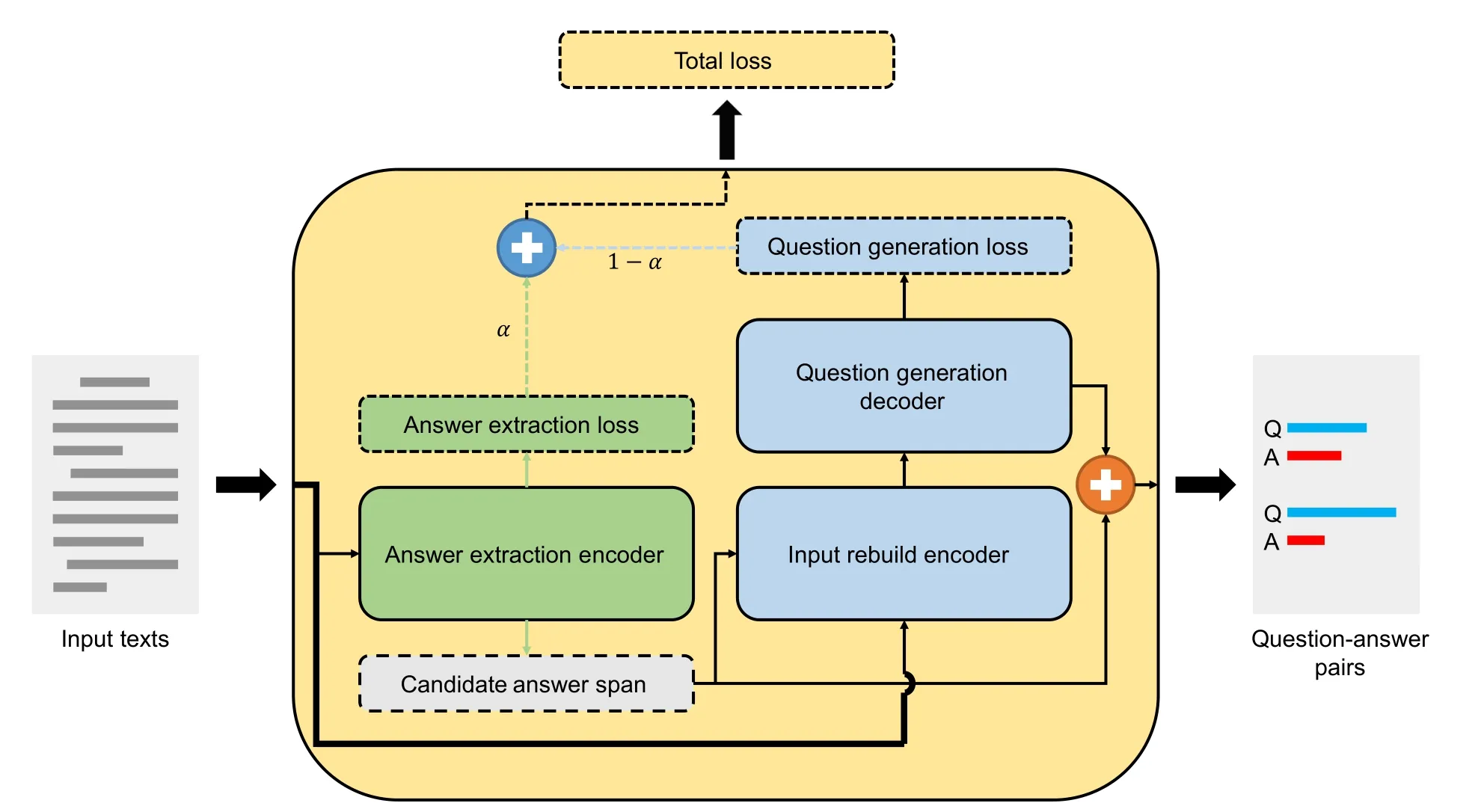
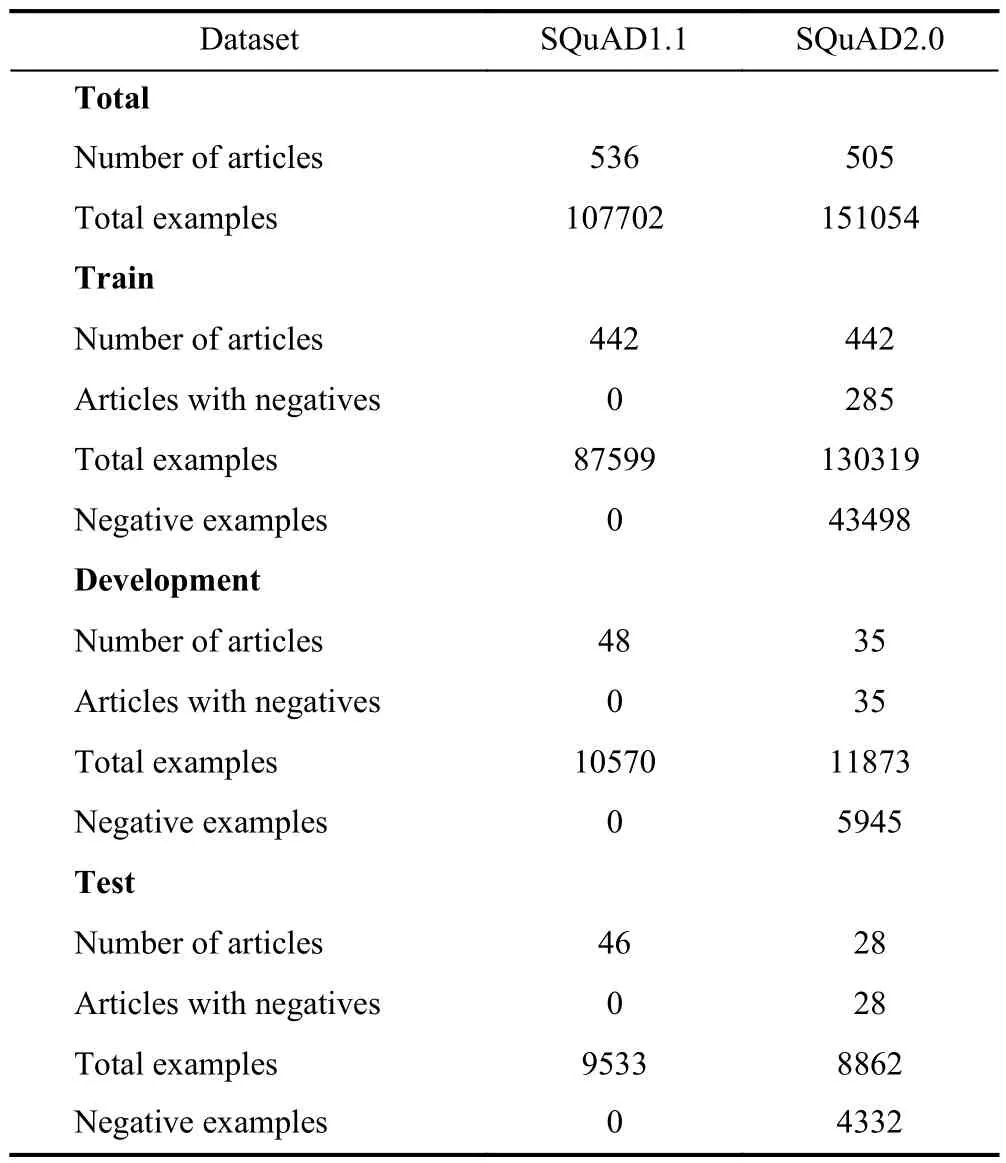
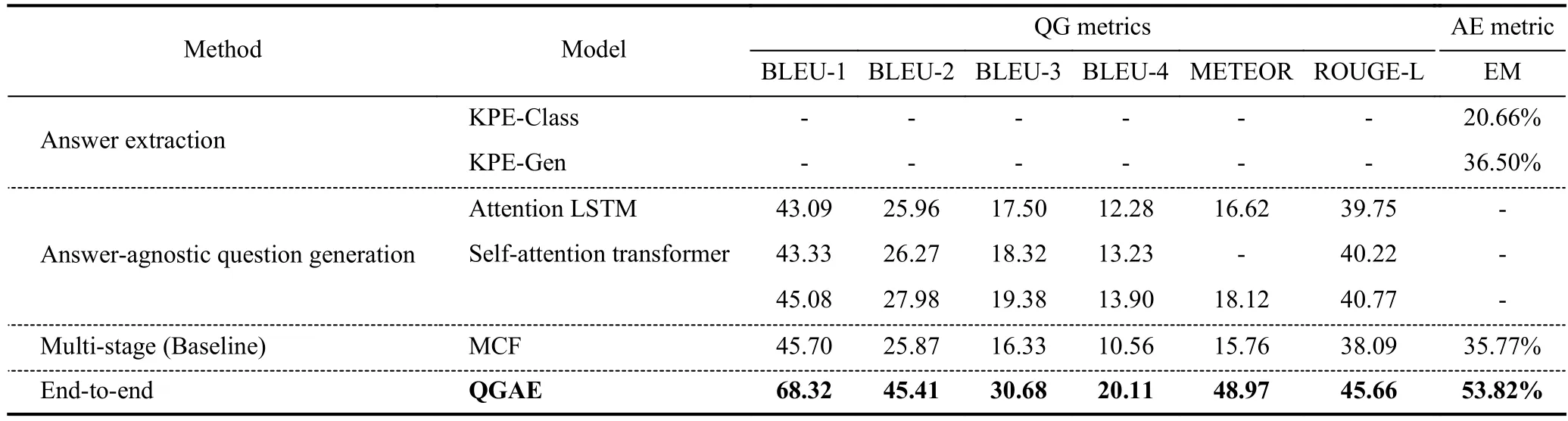
where the probability of eachqtis predicted based on all the words generated previously (i.e.,qi In our work,we split traditional answer-agnostic question generation into 2 sub-tasks: answer extraction and answeraware question generation,as in early works. Answer extraction.It supposes there is at least one question-worthy candidate answer in the input contextC={c1,c2,···,cm}and then returns its answerA={ai,ai+1,···,aj},whereA’s span is limited byC,therefore,1 ≤i≤j≤m. Answer-aware question generation.It is similar to answer-agnostic question generation while it provides an additional answerA={a1,a2,···,al},lis the length of the answer: We choose BART (bidirectional and auto-regressive transformer) as our foundation model.BART is a sequence-tosequence model that uses a standard transformer-based encoder-decoder architecture,inheriting its encoder from BERT’s bidirectional encoder and its decoder from GPT’s leftto-right decoder,and is particularly effective for text generation as well as reading comprehension tasks.One limitation of BART is that it cannot simultaneously perform NLU and NLG (natural language generation) tasks.It excels at tasks such as text generation and reading comprehension individually,but integrating these tasks in a single model remains a challenge.However,with its strong foundation,we believe that BART has the potential to be further improved to handle such tasks effectively. QGAE is a sequence-to-sequence model as shown in Fig.2 which mainly adopts BART’s architecture while adding an additional encoder,so there are two encoders and a decoder.The model first extracts the phrase with high probability asAand rebuilds inputCtoA,C.The model will return the rebuild inputA,C,andQ. Fig.2.The architecture of QGAE consists of two encoders and one decoder,which take raw texts as input and generate question-answer pairs. 4.2.1 Answer extractor encoder Answer extractor encoder is the first encoder inherited from BART similar to BERT and is used to understand the input context and extract the most valuable phrase.We leverage this encoder by appending an extra linear as a classifier to predict the high probability answer span position.Because BART only supports,at most,a pair of sequences as input,we choose the highest score answer of all predictions as the candidate answer.This module will focus on the first task answer extraction (AE). We select cross entropy to calculate the loss of the AE task.Kis the number of classes.In this task,classKis the position of the input paragraph span in the range [0,m-1],andmis the input context length.xi,kindicates that theith sample is thekth category.pis the probability distribution of annotated data whileqis the probability distribution of prediction data: Concretely,we put the specific answer into Eq.(3),and the equation can be changed as: whereais the labeled answer span as ground-truth,is the target candidate answer span,andNis the data size.ti,kindicates that the true label of theith answer is thekth category,which can only take 0 or 1. 4.2.2 Question generation encoder-decoder Question generation encoder-decoder is mainly derived from BART but adds a unique function leveraging the candidate answer extracted from the first encoder to rebuild input〈s〉C〈/s〉 to traditional QG inputs as 〈s〉A〈/s〉〈/s〉C〈/s〉.Then,the module uses rebuilt input to generate text as BART does.This module will focus on the second task question generation (QG). The loss of the QG task is also cross entropy with the only difference being that we use the labeled questionsqas groundtruth and prediction questionsand classKis the vocabulary size of the model: 4.2.3 QGAE loss The QGAE loss is the loss of the multi-task model,in this work,it is the sum of the answer extraction loss and question generation loss: where α is the weight of the AE task as a hyper-parameter. The Stanford question answering dataset (SQuAD) is the most famous reading comprehension dataset for reversible tasks: question answering and question generation.As the Table 2 shows,it has two versions,SQuAD1.1[45]and SQuAD2.0[46],consisting of questions posed by crowdworkers on a set of Wikipedia articles.Each article has several paragraphs,and each paragraph is asked a set of questions and provided answers,where the answer to every question is a segment of text,or span,from the corresponding reading passage.In SQuAD2.0,because of a percentage of unanswerable questions are added to the dataset,some answers may be null. Table 2. Statistics of datasets SQuAD1.1 and SQuAD2.0.No matter in which dataset,an example consists of a context,a question,and an optional answer.The term “negative example” refers to a context passage paired with an unanswerable question,which is intended to help models learn to identify when a question cannot be answered correctly based on the given context. We implement our models in HuggingFace[47]architecture and fine-tune the model with V100 32 GB GPUs.We first finetune BART-base on SQuAD2.0 for 2 epochs to obtain checkpoint BART-base-SQuAD2.0-2 epoch (BbS2).Then we use BbS2 to initialize our QGAE model;more specifically,QGAE’s dual encoder is initialized by the BbS2’s encoder twice and some linear layers that do not exist in BbS2 but in the QGAE will be initialized randomly.We set the batch size to 20,epoch to 3,learning rate to 0.00002,dropout to 0.2,beam search size to 10,max input length to 1024,max question size to 20,and min question size to 3.We perform gradient descent by the Adam optimizer[48].The coefficient α of task 1 answer extraction is 0.3 while the coefficient of the question generation task is 0.7. We report the evaluation results with four metrics: BLEU,METEOR,ROUGE-L,and exact match (EM). BLEU.BLEU is an algorithm first for evaluating machinetranslated text from one natural language to another,later adopted by the text generation task.BLEU compares n-gram words appearing in candidates and references and punishes too-short sentences with a brevity penalty. ROUGE.ROUGE is a set of metrics including ROUGE-N,ROUGE-L,and ROUGE-W.In this work,we mainly choose ROUGE-L,which is the longest common sub-sequence(LCS)-based statistic.LCS takes into account sentence-level structure similarity naturally and identifies the longest cooccurring in sequence n-grams automatically. METEOR.METEOR is also a metric based on the harmonic mean of unigram precision and recall,with recall weighted higher than precision. Exact match.Exact match measures the percentage of predictions that match any one of the ground truth answers exactly. As each paragraph in the SQuAD dataset may have several question-answer pairs,we use paragraphs as input and compare outputs with a group of question-answer pairs and choose the highest score with BLEU-4 as the main indicator. In Table 3,we compare our proposed end-to-end QGAE model with 3 other types of earlier works: standalone answer extraction task,standalone answer-agnostic question generation,and multi-stage QA-pair generation pipeline.All the data used in the experiments have been replicated from the following paper. Table 3. Comparison of method performance in major metrics (including QG metrics and AE metric) on the SQuAD dataset.These methods are divided into four types according to their primary research fields.The first two classifications focus on their own independent fields,while the latter two classifications can accomplish these two tasks at the same time. (Ⅰ) Standalone answer extraction KPE.Key phrase extraction (KPE)[49]is a part of a neural question-answer pair generation system.It has two approaches: KPE-class and KPE-Gen. (Ⅱ) Standalone answer-agnostic question generation Attention LSTM.Attention LSTM was proposed by Du et al.[4]and was the first work to focus on answer-agnostic QG. Self-attention transformers.Self-attention transformers[50]explore how transformers can be adapted to the task of neural question generation without constraining the model to focus on a specific answer passage. Question-driven LSTM.Question-driven LSTM[26]proposed two new strategies question type prediction and a copy loss mechanism to address the task. (Ⅲ) Multi-stage QA-pair generation pipeline MCF.Wang et al.[51]proposed a multi-stage framework that can extract question-worthy phrases and improve the performance of question generation.We chose this framework as the baseline for the specific task of generating QA pairs and used it to evaluate the performance. The performance shows that our end-to-end QGAE model not only achieves SOTA in the answer extraction task but also makes a great improvement in the answer-agnostic question generation compared with the traditional encoderdecoder architecture.Even if multi-stage work MCF has a much more complex workflow,has a weaker comprehensiveperformance than our work.What is more? QGAE is lighter,more convenient,and more portable since it only requires finetuning of one pre-trained model,whereas multi-stage methods need at least two models for stage AE and QG. Although great progress has been made in the EM score,reaching 53.82%,there is still much room for improvement in extraction accuracy.Our model may extract candidate answers that are not ground truth but also meaningful,while extraction accuracy is judged and limited by the labeled data.Specifically,the range of candidate answers is very wide,ranging from named entities to relationships,to events.However,only a small percentage of key phrases are included in the training dataset while others are out of range.Candidate answers beyond the confines of the dataset may make the later question generation task in the wrong direction,performing worse when choosing traditional machine-translation evaluation indicators.Despite all this,prediction sentences not in the ground truth are still valuable and reasonable.The high diversity of generated sentences,to a certain extent,is an advantage that will make our model competitive in different scenes for data augmentation. Therefore it can be concluded that we have expanded our model’s function not only to generate questions but also to generate QA-pairs compared to the baseline model and better than any previous work,which proved our model is diverse and efficient. In this paper,our focus is on answer-agnostic question generation,which can be extended to question-answer pair generation.This task can be divided into two sub-tasks: answer extraction and question generation.We proposed an end-to-end model called question generation with answer extractor(QGAE) using raw text without costing any additional information,which can generate question-answer pairs in parallel.Compared to the multi-stage question-answer generation method,QGAE has several advantages.First,QGAE is able to generate question-answer pairs in parallel,whereas the multi-stage method requires multiple rounds of generation and refinement.Second,it is lighter,more convenient,and more portable than multi-stage methods in training,which reduces the complexity of the overall system.Third,our model achieves a better average score and greater diversity.Overall,QGAE is a more efficient and versatile approach to answeragnostic question generation,with potential applications in various natural language processing tasks. In further work,we will try to compile more datasets into one ensemble to improve the accuracy of answer extraction.Not only that,we will try to change our main task to information retrieval to optimize our answer extraction,as different weight biases in sub-tasks lead to an imbalance in the model’s focus in the two sub-tasks.All in all,this is still pioneering work in pre-trained language models adapting questionanswer pair generation. Acknowledgements This work was supported by the Fundamental Research Funds for Central Universities (WK3480000010,WK3480000008). Conflict of interest The authors declare that they have no conflict of interest. Biographies Linfeng Liis currently pursuing a master’s degree at the School of Cyber Science and Technology,University of Science and Technology of China.His research interest is natural language processing. Zhendong Maoreceived his Ph.D.degree in Computer Application Technology from the Institute of Computing Technology,Chinese Academy of Sciences (CAS) in 2014.From 2014 to 2018,he was an Assistant Professor at the Institute of Information Engineering,CAS.He is currently a Professor at the School of Cyber Science and Technology,University of Science and Technology of China.His research interests include the fields of computer vision,natural language processing,and cross-modal understanding.4 Model
4.1 Foundation model
4.2 QGAE
5 Experiments
5.1 Dataset
5.2 Experiments settings
5.3 Evaluation
6 Results and discussion
6.1 Results
6.2 Discussion
7 Conclusions

- 中国科学技术大学学报的其它文章
- 中文概要
- Constitutive modeling of the magnetic-dependent nonlinear dynamic behavior of isotropic magnetorheological elastomers
- Dual-modality smart shoes for quantitative assessment of hemiplegic patients’ lower limb muscle strength
- Efficient secure aggregation for privacy-preserving federated learning based on secret sharing
- Robustness benchmark for unsupervised anomaly detection models
- BEV-radar: bidirectional radar-camera fusion for 3D object detection