
基于空间可变形Transformer 的三维点云配准方法
2024-03-21 08:15谢帅康熊风光朱新杰宋宁栋李文清王廷凤
计算机工程 2024年3期
谢帅康,熊风光,2,3*,朱新杰,宋宁栋,李文清,王廷凤
(1.中北大学计算机科学与技术学院,山西 太原 030051;2.中北大学山西省视觉信息处理及智能机器人工程研究中心,山西 太原 030051;3.中北大学机器视觉与虚拟现实山西省重点实验室,山西 太原 030051)
0 引言
点云配准是计算机视觉领域的重要问题,被广泛应用于三维(3D)重建[1]、虚拟现实[2]、医学成像[3]等领域。三维点云配准技术是将来自不同视角或传感器的多个点云数据对齐并转换到同一个坐标系下的过程。然而,由于噪声、异常值、低重叠率等的影响,使得点云配准成为一个具有挑战性的问题,因此实现高精度、强鲁棒性的点云配准算法有着重要的研究意义和价值。
传统迭代最近点(ICP)算法[4]是被广泛使用的刚性点云配准算法,最小化源点云和目标点云之间点到点或平面的距离,交替更新源点云和目标点云间的对应关系和变换矩阵。然而,ICP 算法的主要缺陷是极易收敛到局部最优。为了解决该问题,YANG等[5]提出全局最优迭代最近点算法(Go-ICP),利用分支定界法缓解了ICP 存在的一些问题,但却极大地降低了配准效率。
随着计算机性能的不断提高,基于深度学习的方法对传统特征提取方式进行了改进。CHOY等[6]提出采用全卷积的特征提取网络(FCGF),使用稀疏三维(3D)卷积缓解点云稀疏性的问题,然而对具有不同旋转分布特点的点云进行配准时效果欠佳。因此,AO等[7]提出SpinNet,用于提取点云的旋转不变特征,SpinNet 由空间点转换器和特征提取器两个模块组成,使得网络能够学习具有较强鲁棒性的局部空间特征,用于点云精配准。针对室内场景数据集,BAI等[8]提出D3Feat,D3Feat 是一种 包含核 点卷积(KPConv)[9]的网络架构,将核点与其邻域内的采样点分组并提取局部几何特征,采用一种新的关键点选择方法和自监督的检测损失函数,消除点云密度对关键点的影响。HUANG等[10]在D3Feat 的基础上结合注意力机制[11]提出高度关注重叠区域的成对点云配准(PREDATOR)。交替使用自注意力和交叉注意力机制,并聚合输入点云局部和全局信息,在3DMatch 场景数据集上表现出较高的配准精度。LI等[12]提出在可变场景中进行点云配准的方法(Lepard),使用具有自注意力和交叉注意力的Transformer 以及可微配准的思想构建网络最终完成点云配准。
然而,这些基于深度学习的三维点云配准方法严重依赖于对应关系的准确性,要求特征提取器学习到的特征必须具备较好的表达能力,否则极易导致点对的误匹配,影响配准精度,并且当存在对应点的局部邻域在另一片点云中被遮挡等问题时也极易造成点对的误匹配。此外,在低重叠、高噪声、形状变化等复杂情况下,这些方法也无法兼顾局部和全局的信息。
为了解决上述方法存在的点云有效信息提取不充分、在低重叠场景下配准困难等问题,本文基于深度学习技术,研究多级分辨率特征的提取与融合方法,并显式地计算点云的局部空间关系,提出一种基于空间可变形Transformer(SDT)的三维点云配准方法。通过SDT 模块来增强学习局部几何特征的能力,利用在相似度矩阵边缘构建松弛向量的方法,有效地降低了不可行匹配对配准算法鲁棒性的影响。同时,根据预测的对应点空间特征是否一致来寻找点云在低重叠场景下更精确的对应关系,实现了一对一的硬匹配关系,获得了更高的配准精度和更强的鲁棒性。
1 点云配准网络模型
本文提出的基于SDT 的三维点云配准方法的网络模型主要由特征提取与空间关系计算、基于SDT的局部与全局特征加权聚合、重叠对应预测3 个模块组成,如图1 所示,彩色效果见《计算机工程》官网HTML 版,下同。对源点云X与目标点云Y进行下采样,对下采样点进行局部空间关系计算,同时通过共享权重的特征提取器学习提取点云特征,然后SDT模块接收特征提取网络学习到的特征以及局部空间关系,聚合点云内的局部自相关关系与点云间的空间结构关系,迭代n次,得到具有良好表达能力的特征图。将高维特征图进行矩阵运算得到的相似度矩阵进行边缘松弛处理,使用Sinkhorn 算法[13]对矩阵归一化并计算软对应置信度矩阵,再经过匈牙利算法求解器[14]把特征的软对应关系转换为一对一的点对应关系,最后使用随机抽样一致性(RANSAC)[15]方法得到源点云X到目标点云Y的最终转换关系。
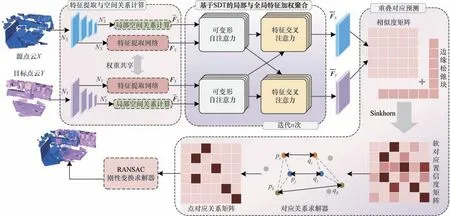
图1 三维点云配准网络模型结构Fig.1 Structure of 3D point cloud registration network model
1.1 特征提取与空间关系计算
1.1.1 特征提取模块
为了有效利用原始点云的输入信息,特征提取模块采用位置自适应卷积(PAConv)[16]结合残差网络(ResNet)[17]进行多级分辨率的特征提取和融合。与一般的卷积网络不同,PAConv 通过动态组装存储在权重库中的基本权重矩阵来构建卷积核,可以更好地处理不规则和无序的点云数据,从而提升模型配准性能。特征提取网络结构如图2所示。
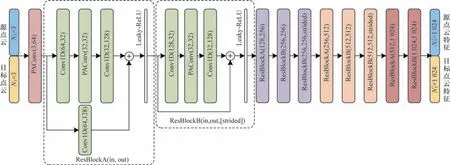
图2 特征提取网络结构Fig.2 Feature extraction network structure
输入点云可以表示为(NX,3)、(NY,3),其中,NX、NY分别为输入源点云X、目标点云Y的个数,3 表示每个点的坐标维度。将原始点云输入到特征提取网络,经过多层ResBlockA(in,out)和ResBlockB(in,out,[strided]),其中,ResBlock 由Conv1D 卷积层、PAConv 卷积层、Layer-Norm 规范化层以及Leaky-ReLU 激活层组成,in 表示输入的通道数,out 表示输出的通道数,strided 为True 表示在执行PAConv 前需要对特征图进行一次降采样,使得N变为原来的1/4。为了保证输入特征图可以与卷积后的结果直接相加,此时会对Shortcut 执行MaxPooling 操作保证维度一致。在特征提取主干网络中结合残差连接,将多级分辨率的特征图与卷积结果逐层相加达到多级特征融合的效果。最终得到点云的相关特征FX和FY,其特征 维度分别为(′,1 024)和(1 024),其中N′的大小为N的1/64。
1.1.2 局部空间关系计算模块
对输入点云进行3 个分辨率级别的下采样,最粗级别的下采样点可表示为。将下采样得到的稀疏点云添加维度为(B,N′,3)并输入空间关系计算模块,依照文献[18]在下采样的点集内显式地计算单片点云内的空间关系,包括点间距离ρi,j和空间夹角,并将稀疏点云的局部空间关系显式地计算为点云的局部空间关系如图3所示。
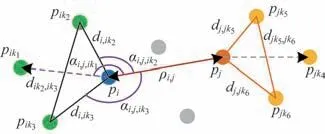
图3 局部空间关系Fig.3 Local spatial relation
在图3 中:pi和pj表示单片点云内的2 个点;pikn表示pi的第n个最近邻点。首先,使用gD,i,j函数化两点之间的距离关系,ρi,j表示pi和pj两点在欧氏空间中的点间距离,σd是用来控制距离变化灵敏度的常量,一般设置为0.2,得到维度为(B,N′,N′,256)的距离关系,计算公式如下:
然后,使用gA,i,j,ik函数化三点之间的角度关系,表示pi和pj及其第n个最近邻点在空间中的夹角,σa是用来控制角度变化灵敏度的常量,一般设置为0.2,得到维度为(B,N′,N′,3,256)的角度关系,计算公式如下:
其中:gD,i,j表示两点之间的距离关系;gA,i,j,ik表示三点之间的角度关系;WD和WA分别是距离关系和角度关系的投影矩阵。
1.2 基于SDT 的局部与全局特征加权聚合
Transformer 利用对点云几何结构信息的编解码进行点云配准。然而,现有的配准模型通常只向Transformer 提供高维特征,导致学习到的特征辨识度不高,从而导致严重的异常匹配。为此,提出SDT模块。它由一个用于增强特征表达能力的可变形自注意力模块和一个用于传递点云间特征的特征交叉注意力模块组成,显式地接收空间关系计算模块计算的空间结构关系和特征提取模块提取的高维特征,并对其进行特征的加权聚合。为了提高计算效率,将主干网络提取的特征由(N′,1 024)增加维度为(B,N′,1 024)并线性 投影到 较低维度的(B,N′,256),其中B表示输入点云的批量大小。与局部空间关系模块计算得到的维度为(B,N′,N′,256)的特征共同输入SDT 模块,计算特征的相关性与相应的注意力分数,获得具有更强表达能力的特征矩阵。将这两个注意力模块交互n次,通过大量实验取n=4以聚合点云局部与全局的特征,最终输出点云的特征聚合矩阵,维度均为(N′,256)。
1.2.1 可变形自注意力模块
最初的注意力机制用来描述输入信息的自相关程度,利用查询向量(Q)、键向量(K)、值向量(V)计算得到的注意力权重矩阵表示,通常根据Q、K的相对重要程度对V进行加权得到注意力矩阵,注意力机制的输出矩阵一般表示如下:
其中:dk表示键向量的维度。
可变形注意力[19-20]机制在局部区域内动态地调整注意力权重以捕捉局部几何特征,与传统注意力机制不同,可以动态地调整感受野以更好地适应输入点云的局部几何形态。借鉴Swin Transformer V2[21]的思想,引入缩放余弦注意力[21]中的连续位置偏移(CPB)[21]技术,可以平滑地跨窗口传输分辨率,这是感受野得以动态调整的关键。由缩放余弦函数计算得到的注意力分数的计算公式如下:
其中:Bi,j是点i的查询向量qi和点j的键向量kj之间的相对位置偏移;τ是一个值大于0.01 的可学习的标量,不在头部和层之间共享。
SDT 模块的核心是可变形自注意力模块,它允许局部感受野内的点云特征相互交互,从而捕获局部的几何信息。具体来说,可变形注意力模块利用CPB 中的空间变形偏移量Bi,j来提高模型对局部几何信息的捕捉能力。Bi,j由以下公式定义,其中Gi,j在默认情况下是一个两层MLP 之间夹一层ReLU 激活函数的小网络:
可变形自注意力模块接收上一模块提供的高维特征与局部空间关系计算得到的局部关系特征,对高维特征输入执行分组策略[22-23],同时对局部空间特征进行栅格偏移采样[24]得到传统注意力机制中的Q、K、V以及局部空间关系表示G。对Q与K、Q与G分别做点积运算,再与空间变形偏移量Bi,j相加得到用ei,j表示的可变形注意力中的注意力分数:
其中:x表示输入的特征矩阵;gi,j表示点i和j的局部空间关系向量;WQ、WK、WG分别是查询向量、键向量和局部空间关系的投影矩阵;dt是输入向量的维度;Bi,j是点i的查询向量qi和点j的键向量kj之间的相对位置偏移。可变形自注意力计算过程如图4所示。
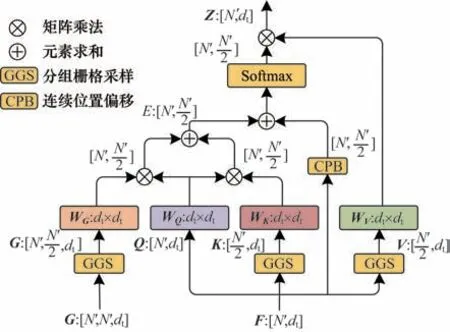
图4 可变形自注意力计算过程Fig.4 Process of deformable self-attention calculation
根据得到的注意力分数容易求得注意力权重矩阵进而得到注意力机制的输出矩阵,输出特征矩阵zi是所有投影输入特征的加权和:
其中:x表示输入的特征矩阵;ai,j表示对ei,j注意力得分逐行Softmax 计算得到的权重系数;WV表示值向量的投影矩阵。
可变形自注意力模块将传统的自注意力中的全局特征交互方式转化为局部的特征交互,从而适应不同的点云几何结构。首先,将一个输入特征图和一个偏移量预测作为输入,偏移量预测由卷积层生成,每个节点值表示对应的特征点的偏移量。然后,通过对输入特征图进行插值和偏移相加来计算可变形注意力的输出。通过可变形自注意力模块使模型自适应地学习点云内的局部几何空间信息,增强特征的表达能力,从而提高点对匹配精度。
1.2.2 特征交叉注意力模块
在三维点云配准任务中的关键模块是特征交叉注意力模块[25],用于交换点云间的全局特征。首先,给定源点云X、目标点云Y的自注意特征矩阵fX和fY,则可用ei,j表示fX和fY之间的特征相关性:
其中:WQ和WK分别是查询向量Q和键向量K的投影矩阵。
接着,使用Y的自注意特征来计算源点云X相对于目标点云Y的交叉注意特征矩阵zX,i:
其中:ai,j是交叉注意力得分ei,j逐行Softmax 的结果。
最后,以相同的方式计算Y相对于X的交叉注意力特征,得到特征交互后更具鲁棒性和判别性的特征表示。
1.3 重叠对应预测
当为某节点寻找对应点时,如果它的大部分邻域区域在另一片点云中被遮挡或者没有足够多的重叠区域时,则认为这两个点没有完全匹配,被标记为不可行匹配点。不可行匹配会导致误匹配结果被计算,从而导致点对应关系出错,使得配准精度下降。针对该情况,对相似度矩阵进行改进,加入边缘松弛块,如图5 所示。当节点间没有完全匹配时,它们可以与相应的边缘松弛块进行匹配,从而降低其在概率分布计算中的权重,从而提高匹配精度和鲁棒性。
图5 边缘松弛块示意图Fig.5 Schematic diagram of edge slack block
首先,重叠对应预测模块接收源点云与目标点云的聚合特征矩阵,并使用双线性插值法[26]将两个特征矩阵的维度对齐,两个聚合特征矩阵的维度变为,将转置,然后直接计算两者的余弦相似度矩阵P,计算得到的P为一个方阵。这时需要将源点云的聚合特征矩阵映射到目标点云的聚合特征矩阵中,且需要最小化映射的总成本。为了解决这个问题,为相似度矩阵添加边缘松弛块,并使用Sinkhorn[13]方法,该方法将相似度矩阵归一化并转化为一个软对应的置信度矩阵,计算公式如下:
其中:P为初始的相似度矩阵;C是一个由相似度矩阵转换而来的常数矩阵,可表示为C=-loga(P),较高的相似度值对应C中较低的元素值,使映射总成本达到最小;ε是一个超参数。
最后,使用RANSAC 刚性变换求解器迭代计算变换矩阵,得到点云的最终转换关系。
1.4 损失函数
受到用于部分点云配准的新型不确定性感知重叠预测网络(UTOPIC)[27]的启发,采用一个用真实对应关系作为监督的损失函数,在α平衡交叉熵损失[28]的基础上进行改进,使用软对应置信度矩阵与真值对应矩阵之间的焦点损失[28]来训练本文模型。α平衡交叉熵损失的计算公式如下:
其中:pt表示软对应置信度矩阵;α是解决对应关系不平衡的平衡因子,α∊[0,1]用于正确的对应,1-α用于不正确的对应。
在α平衡交叉熵损失的基础上,增加调制因子(1-pt)γ得到正确对应的焦点损失Lα、不正确对应的焦点损失以及模型的焦点损失L,分别如式(13)、式(14)、式(15)所示:
其中:N和M分别表示源点云X和目标点云Y经过下采样后的点数;Lα(pt)表示正确对应的焦点损失;(pt)表示不正确对应的焦点损失。
针对3DMatch 和3DLoMatch 场景数据的配准困难问题,采用文献[28]的参数设置,将α和γ设置为α=0.25和γ=2。
2 实验结果与分析
2.1 实验数据集与参数设置
使用公开的3DMatch 和ModelNet40 数据集作为实验数据集。3DMatch 数据集包含62 个场景,使用其中46 个用于训练、8 个用于验证、8 个用于测试;ModelNet40 数据集包含来自40 个不同类别的计算机辅助设计(CAD)模型,使用前20 个类别进行训练和验证,使用后20 个类别进行测试。在实验中,将3DMatch 场景数据中重叠率低于30%的数据作为3DLoMatch 低重叠数据,将ModelNet40 数据中平均重叠率低于53.6%的数据作为ModelLoNet40 低重叠数据,用来测试所提方法在低重叠场景下的效果。为了保证实验的公正性,使用相同的训练参数。在训练期间,使用AdamW 优化器进行优化,初始学习率设置为0.000 1,并使用学习率衰减来降低学习率,并运行40 个epoch 使模型完成收敛。模型使用PyTorch 框架在一台拥有NVIDIA GeForce RTX 3090 GPU 的服务器上进行训练和测试。
2.2 模型评估指标
在3DMatch 和ModelNet40 数据集上进行评估,将训练结果直接泛化到低重叠率的3DLoMatch 和ModelLoNet40 数据集上进行测试,并与PREDATOR[10]等方法进行比较。使用文献[10]中的3 个指标来评估配准方法在3DMatch 数据集上的性能:1)特征匹配召回率(FMR),衡量特征描述能力;2)内点比率(IR),衡量对应关系的正确率;3)配准召回率(RR),衡量最终配准性能,即配准算法可以正确匹配的点对占比。使用文献[10]中的相对旋转误差(RRE)、相对平移误差(RTE)以及倒角距离(CD)来评估模型在ModelNet40 数据集上的性能。
2.3 消融实验
为了探究所提方法的不同组件对配准结果的影响,在3DMatch 数据集上进行消融实验,结果如表1所示,其中最优指标值用加粗字体标示,下同。具体而言,分别测试了SDT 模块和边缘松弛块对最终配准结果的影响。
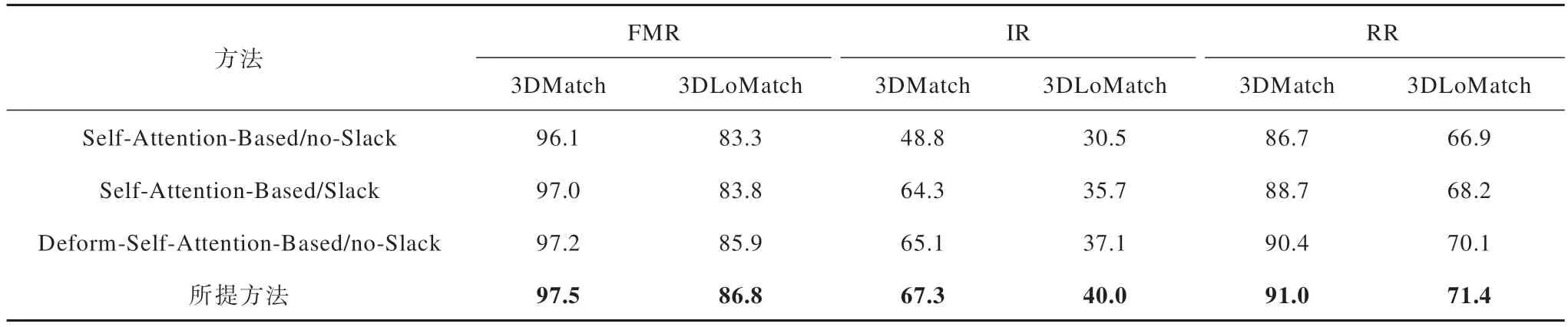
表1 消融实验结果Table 1 Results of ablation experiment %
1)Self-Attention-Based/no-Slack:在提取多级分辨率特征后,使用原始的Self-Attention 来代替SDT模块中的Deformable Self-Attention,在得到特征聚合矩阵FˉX和FˉY并计算相似度矩阵之后,不使用边缘松弛块处理矩阵,其他的网络结构不变。
2)Self-Attention-Based/Slack:使用原始的Self-Attention 来代替SDT 模块中的Deformable Self-Attention 并为相似度矩阵添加边缘松弛块,其他的网络结构不变。
3)Deform-Self-Attention-Based/no-Slack:使用边缘松弛块处理相似度矩阵中的不可行匹配问题,其他的网络结构与所提方法保持一致。
4)所提方法:使用基于SDT 模块的配准方法进行实验。
由表1 可以看出,所提方法对于低重叠场景下刚性变换求解非常重要,其中SDT 模块中的Deformable Self-Attention 对结果影响最大,对3DLoMatch 低重叠场景下的FMR 和RR 的提升约为3 个百分点。虽然边缘松弛块对结果的影响相对较小,但也对IR 和RR 的提高有一定贡献。
2.4 对比实验
不同方法的特征匹配召回率、内点比率以及配准召回率对比如表2 所示。由表2 可以看出,相较于FCGF[6]、D3Feat[8]、PREDATOR[10]、CoFiNet[29]等目前较先进的配准方法,所提方法在3DLoMatch 低重叠场景下的FMR、IR 和RR 均有所提高。除在3DMatch 数据集下的FMR 与IR 指标略低以外,所提方法的其他指标均较高,在3DLoMatch 数据集上FMR 比其他方法至少高出3.7 个百分点,IR 至少高出2.2 个百分点,RR 至少高出3.9 个百分点。这表明所提方法在处理低重叠数据时具有较好的鲁棒性和精度。所提方法与PREDATOR 方法在3DMatch 和3DLoMatch 数据集下的配准结果对比如图6 所示。
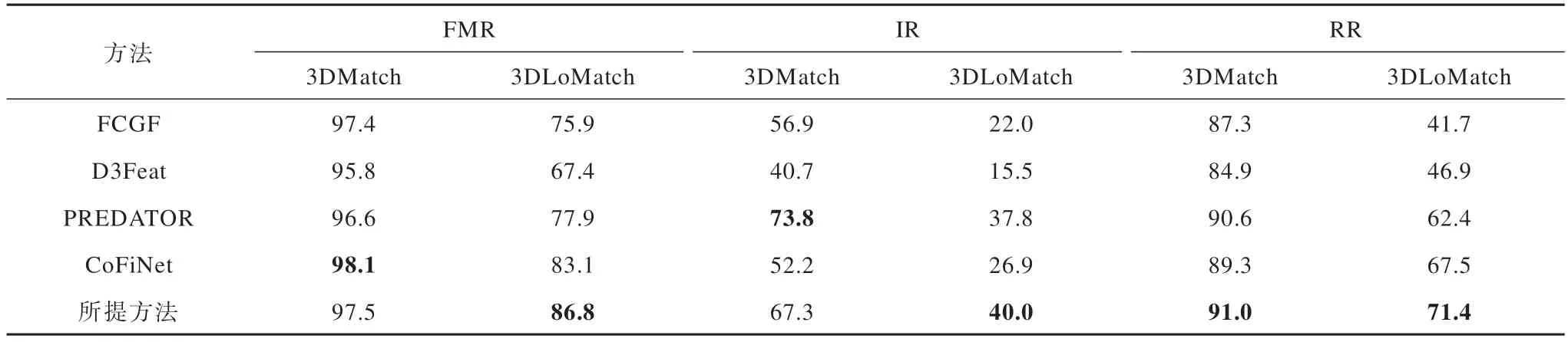
表2 不同方法的特征匹配召回率、内点比率以及配准召回率对比Table 2 Comparison of feature matching recall,inlier ratio,and registration recall of different methods %
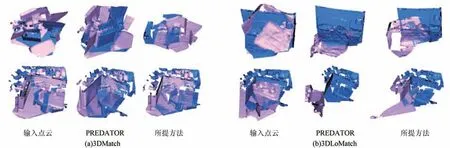
图6 3DMatch 和3DLoMatch 数据集下的配准结果Fig.6 Registration results under 3DMatch and 3DLoMatch datasets
由于3DMatch 和3DLoMatch 的8 个不同的测试场景数据的结构存在差异,因此使得所提方法在不同场景下得到的特征也不同。表3 和表4 分别展示了不同方法在3DMatch 和3DLoMatch 的8 个测试场景中的RR 对比结果。结合表2~表4 的实验结果表明,所提方法在低重叠场景中配准效果较优。当两片点云的重叠区域低于30%时将其配准较困难,例如PREDATOR 方法在3DLoMatch 场景下的FMR 仅有77.9%,不能得到更好的特征表示,进而不能很好地计算点云间的转换关系,使得配准结果存在较大误差。所提方法在传统注意力机制的基础上加入了局部感受野内点云特征的交互,从而捕获更独特的几何信息,使特征得到更好的表达,在寻找两片点云的特征相似度时加入了边缘松弛块,有效解决了配准中存在的不可行匹配问题,在3DLoMatch 的8 个测试场景中所提方法的FMR 仍能达到86.8%,在重叠区域低于30%的情况下依然能很好地完成配准。

表3 不同方法在3DMatch 测试场景下的配准召回率对比Table 3 Comparison of registration recall of different methods under 3DMatch testing scenarios %

表4 不同方法在3DLoMatch 测试场景下的配准召回率对比Table 4 Comparison of registration recall of different methods under 3DLoMatch testing scenarios %
为了验证所提方法在不同采样点数量(s)下的鲁棒性,同时对比其他方法在接收相同采样点数量的情况下的性能,通过逐渐减少提供给模型的采样点数量并对其结果进行分析,实验结果如表5 所示。由表5 可以看出,除在3DMatch 数据集下提供1 000 个采样点时PREDATOR 方法的配准召回率略高于所提方法以外,在其他各种情况下所提方法的性能均优于其他方法。可见,所提方法在接收不同采样点数量时均具有较好的鲁棒性。

表5 不同方法在不同采样点数量下的配准召回率对比Table 5 Comparison of registration recall of different methods under different number of sampling points %
为了进一步验证所提方法的泛化能力,使用ModelNet40 数据集的前20 个类别对模型进行训练,使用其他20 个类别进行测试,将训练好的模型直接泛化到低重叠场景数据集上进行测试,并与PREDATOR[10]、REGTR[25]、DCP-v2[30]、RPM-Net[31]等方法进行对比,实验结果如表6 所示。由表6 可以看出,所提方法在ModelNet40 数据集下的性能略低于REGTR 方法,但所提方法相比于其他方法性能更优。由图7 可以看出,所提方法在ModelNet40数据集下的泛化能力明显优于PREDATOR 方法,且在ModelLoNet40 低重叠场景下的配准效果更优。
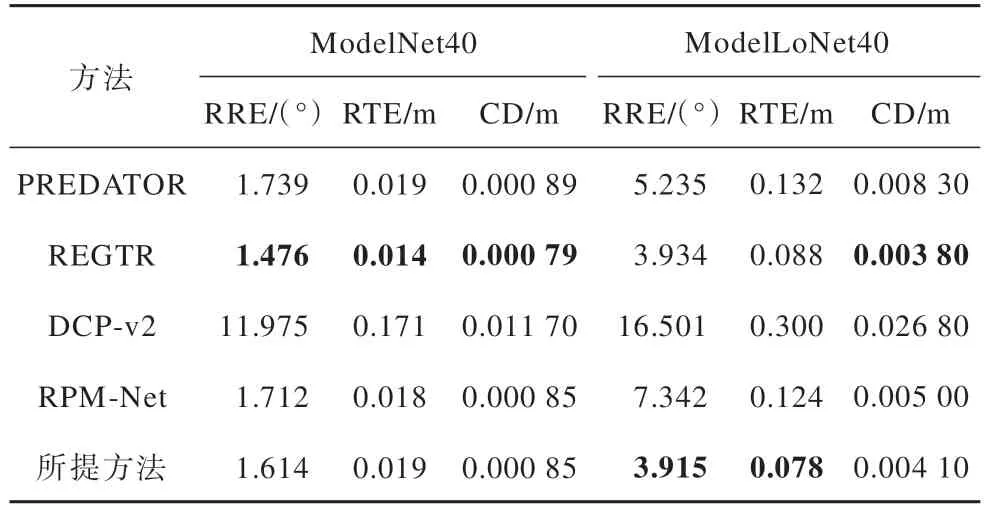
表6 对象类别未知的点云配准实验Table 6 Point cloud registration experiment with unknown object category
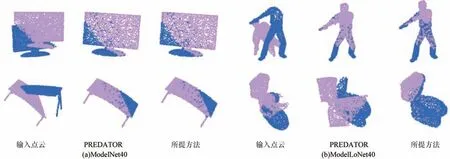
图7 ModelNet40 和ModelLoNet40 数据集下的配准结果Fig.7 Registration results under ModelNet40 and ModelLoNet40 datasets
3 结束语
本文提出一种基于空间可变形Transformer 的三维点云配准方法,计算局部空间关系并提取多级分辨率的特征,设计一个SDT 模块来增强点云空间特征的表达能力,并利用在相似度矩阵边缘添加松弛块的方法降低了不可行匹配对配准鲁棒性的影响。在3DMatch 和ModelNet40 数据集上的大量实验结果表明,所提方法在解决低重叠场景下的点云配准问题方面具有较高的精度及较强的鲁棒性和实际应用价值。但由于模型同时使用了SDT 模块和RANSAC 方法,导致训练和计算耗时较长,后续将进一步探索更加有效的特征提取与聚合方法提升模型效率,并将所提方法应用于更加复杂的场景,扩展其使用范围。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
数学物理学报(2021年2期)2021-06-09
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
噪声与振动控制(2015年4期)2015-01-01
