
融合注意力机制的多视图卷积手势识别研究
2024-03-21 08:15袁文涛卫文韬高德民
计算机工程 2024年3期
袁文涛,卫文韬,高德民*
(1.南京林业大学信息科学技术学院,江苏 南京 210037;2.南京理工大学设计艺术与传媒学院,江苏 南京 210094)
0 引言
表面肌电信号(sEMG)是通过放置在皮肤上的电极来记录骨骼肌收缩过程中的生物信号,该类生物信号提供了人们丰富的活动信息。目前,表面肌电信号已经发展成为一种测量、分析和诊断工具,广泛应用于康复医学[1]、人机交互[2]、假肢控制[3]等领域。由于手是人体中最多样化和最灵巧的部分,可以采用不同的运动策略来与环境交互,因此基于表面肌电信号的手势识别成为肌肉计算接口(MCI)的技术核心[4]。与基于视觉图像进行手势识别的方法相比,基于表面肌电信号的手势识别方法可以忽略光照、背景、遮挡等复杂因素的影响[5],记录真实的动作电位,从而更好地应用于现实场景中。
根据所用传感器密度的不同,sEMG 数据采集可分为稀疏多通道sEMG 和高密度sEMG(HDsEMG)。HD-sEMG 一般使用二维电极阵来捕获肌肉活动中运动电位的空间和时间分布[6],这不仅增加了数据收集的数量和成本,还提高了手势识别系统的复杂性。相比之下,稀疏多通道sEMG 使用更少的电极来记录运动信息,并且对sEMG 的域变化非常敏感,在可穿戴设备中得到了广泛应用。
文献[7]提出一种基于卷积神经网络(CNN)的手势识别模型,在HD-sEMG 上得到的手势识别准确率为99.30%。文献[8]所提模型在CapgMyo DB-a高密度sEMG 数据集上达到了99.20%的识别准确率。目前,基于稀疏多通道sEMG 的识别模型准确率与上述模型相比仍有较大差距,因此,如何针对稀疏多通道sEMG 来提升手势识别准确率是一项具有挑战性的工作。基于稀疏多通道sEMG 的手势识别主要使用传统机器学习和深度学习2 种方法,传统机器学习通常在肌电信号中提取时域、频域和时频域特征并进行必要的降维处理[9-10],将其输入传统的机器学习分类模型中,如支持向量机(SVM)、随机森林(RF)、线性判别式分析(LDA)等。文献[11]使用随机森林算法获得了NinaPro DB1 和NinaPro DB2数据集的平均分类准确率,分别为75.32%和75.27%。文献[12]在NinaPro DB7 的40 个手势分类中基于LDA 算法取得的平均分类准确率为60.10%。
深度学习方法主要有2 种模式:一种是直接将原始肌电信号转换为肌电图像输入CNN 中,自动学习高级特征来进行手势识别。如文献[13]使用sEMG 瞬时图像对NinaPro DB1 的平均手势分类准确率为78.90%,MSCANet[14]使用多 流卷积 网络对NinaPro DB1 的平均分类准确率为84.39%;另一种是和机器学习方法一样对原始肌电信号进行特征提取,将肌电特征转换为肌电图像输入CNN 中。文献[15]提出一种双流CNN 结构,在NinaPro DB2 上的平均分类准确率为84.90%。文献[16]提出一种基于注意力的混合CNN-RNN 网络结构,在NinaPro DB1 上的平均分类准确率为84.80%。由于稀疏多通道sEMG 数据通道较少,深度学习方法大多使用特征提取来增强肌电图像质量,提高手势识别准确率。但是,由于特征数量增多导致特征维度变高,硬件计算开销增大,因此输入特征的组合和筛选成为提升模型手势识别准确率的关键。
针对上述问题,本文提出一种融合ECA 注意力机制的多视图卷积识别模型,多视图卷积方法将多个特征集组合成视图输入多流CNN 中,通过融合训练后的高层特征来提高模型准确率。ECA 注意力机制避免使用机器学习中的降维方法,通过跨通道交互提取通道间肌电数据的依赖关系,以得到特征通道权重,便于卷积筛选有效特征并提高模型鲁棒性。使用巴特沃斯(Butterworth)低通滤波对原始肌电信号进行噪声过滤,利用文献[17]验证过的3 个性能较优的经典特征集,即小波包变换(DWPT)、小波变换(DWT)和Phin_FS1 特征集[18]在200 ms 滑动时间窗口上进行特征提取。针对所提取的特征,利用通道重排列算法[19]将其合并成3 个视图输入多流CNN 网络中,网络中融合ECA 注意力机制模块,强化有效特征并弱化无效特征,以加快模型拟合速度并提高手势识别准确率。
1 数据预处理
1.1 信号滤波
巴特沃斯滤波器结构简单,性能优越,通频带的频率响应曲线平滑,很适合处理稀疏多通道sEMG原始肌电数据。巴特沃斯低通滤波器的传递函数如式(1)所示:
其中:N为滤波器的阶数;ωc为截止频率。
sEMG 是一种非平稳的微电信号,有效的肌电信号频谱一般分布在10 Hz~500 Hz 之间。此外,原始sEMG 中可能存在工频干扰噪声、运动伪影、基线漂移以及记录设备引起的噪声[20],这对手势识别准确率有很大影响。为此,本文采用截止频率为1 Hz的一阶巴特沃斯低通滤波对原始肌电信号进行噪声过滤。如图1 所示(彩色效果见《计算机工程》官网HTML 版,下同),经过噪声过滤后的肌电信号曲线更加光滑,体现了巴特沃斯低通滤波很好的去噪效果,为后面手势识别模型训练提供了保证。
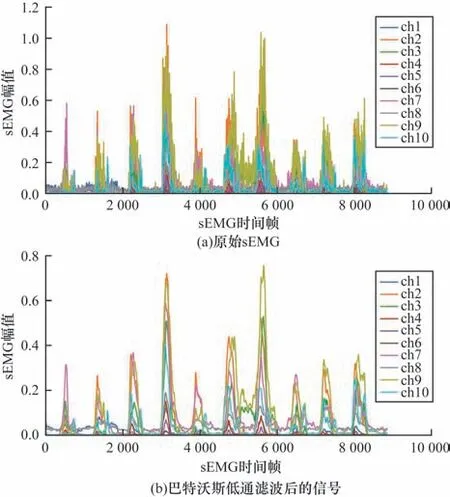
图1 原始sEMG 滤波前后对比Fig.1 Comparison of the original sEMG before and after filtering
1.2 特征提取
sEMG 一般是由多个电极采集的多通道数据,为了贴近真实情况,本文采用滑动窗口的方法对信号进行截取,在sEMG 控制领域,合适的滑动采样窗口可以保证最小的分类误差和系统延迟。参考文献[21]的研究结果,使用150 ms~250 ms 的窗口对肌电信号进行滑动采样能取得最优结果。为了兼顾准确率与实时性,本文采取200 ms 滑动窗口对滤波完的肌电信号进行滑动采样和特征提取,从而得到三维的表面肌电特征图。特征提取采用3 个经典特征集共9 个特征,计算方式如表1 所示。其中:N为sEMG 帧 数;fj和Pj分别为第j帧sEMG 进行傅里叶变换得到的频谱和功率谱;*表示计算方式较复杂,表格中不再赘述。由于Phin_FS1 特征集中包含7 个特征,7 个特征全部输入手势识别模型中会消耗极大的系统资源,为了平衡性能与准确率,将Phin_FS1 特征集中的特征按通道维度拼接成一个视图。
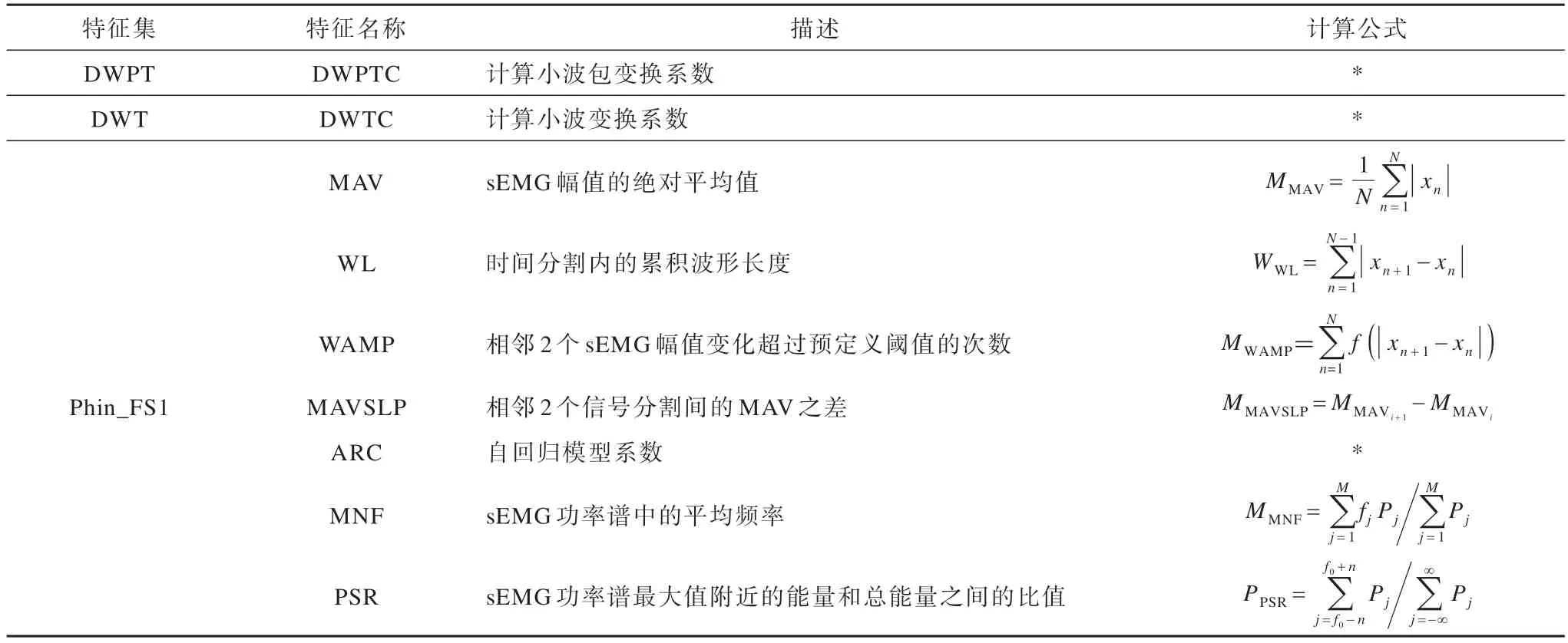
表1 特征集中特征描述与计算方式Table 1 Feature description and calculation method in feature set
为了加强稀疏多通道数据通道之间的相关性,使用改进后的通道重排列算法[17]对特征进行处理。通道重排列算法使得特征每个通道都能与其他通道相邻,从而提取通道间隐藏的相关性。受文献[21]的启发,本文采用已验证准确率最高的混合通道图像的重排列方式来处理提取后的特征。假设原始特征图像大小为L×l×C,L为肌电图像的高度,即原始sEMG 通道数,l为肌电图像的宽度,C为肌电图像的通道数,即特征数量。如图2 所示,混合通道图像方式将重排列算法应用于8 通道原始特征图像,得到33×l×C的肌电图像,33 为应用通道重排列算法得到的图像高度。

图2 通道重排列算法示例Fig.2 Example of channel rearrangement algorithm
2 网络结构设计
2.1 多视图卷积神经网络
本文融合注意力机制的多视图卷积神经网络,也称为多视图卷积注意力网络(MVCANet),主要由特征视图模块、多流卷积模块和特征融合模块组成,网络结构如图3 所示。原始肌电信号经过数据预处理fvc得到多个特征视图,特征视图由多流CNN 并行建模。每个CNN 流由ECA 注意力机制模块、2 个卷积层和1 个局部连接层组成。为避免不同通道提取的sEMG 特征之间有幅度变化的潜在干扰,在第1 个卷积层之前使用批量归一化(BN)。ECA 注意力机制模块对输入的肌电特征图像从通道维度进行加权,便于后面卷积筛选有效特征。前2 个卷积层使用64 个3×3 的2D 滤波器,步长为1,对带有注意力权重的特征进一步进行训练。最后1 个局部连接层(LC)使用64 个1×1 的2D 滤波器,步长为1,使用不共享权重的策略来进一步学习肌电图像不同区域的不同特征分布,同时加入Dropout 层来防止模型过拟合。为了提升模型训练速度并加快收敛过程,在每个层后面都加入BN、ReLU 非线性激活函数。
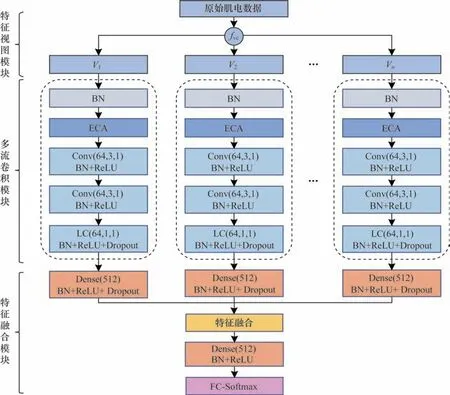
图3 多视图卷积注意力网络框架Fig.3 Multiview convolutional attention network framework
注意力机制是模仿人类视觉系统中可高效关注重点区域这一特性,在语音识别、机器翻译、图像分类等领域得到广泛应用[22],因其对提升模型准确率有显著效果,肌电手势识别领域也逐渐开始应用注意力机制[14,16]。多视图肌电特征经过通道重排列算法后,通道数增加且手势信息更丰富。本文采用ECA 注意力机制来对多视图肌电特征在通道维度进行加权,强化关键手势特征。与对输入特征图通道进行压 缩降维 的SE-Net[23]相比,ECA 注意力 机制更加高效和合理,其使用1D 卷积高效实现了局部跨通道交互,根据肌电图像通道间的依赖关系获得注意力权重。如图4 所示,ECA 注意力模块首先对输入的H×W×C的特征图进行全局平均池化,接着使用卷积核大小为k的1D 卷积操作。卷积核大小k值是由输入通道数C的自适应函数而得到的,如式(2)所示,其中|x|odd表示距离x最近的奇数。
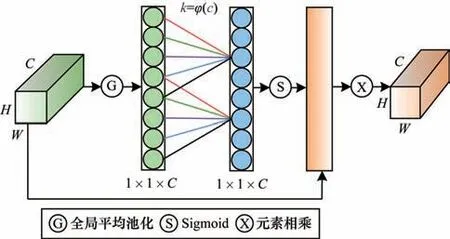
图4 ECA 注意力模块结构Fig.4 ECA attention module structure
卷积操作后经过Sigmoid 激活函数得到各通道的权重W,为进一步提高网络性能,使用卷积共享权重来高效抓取局部交互通道信息,减少网络参数量。共享权重方法如式(3)所示:
其中:σ为Sigmoid 激活操 作;Wi为C个通道 进行分组得到的第i个权重矩阵;为第i个权重矩阵中的第j个局部权重矩阵;同理可得。最后将得到的权重与原始输入特征图相乘得到带有注意力权重的特征图。ECA 注意力机制作为一种即插即用的模块,与其他注意力机制相比,使用了简便的思想和运算,对网络处理速度影响较小,同时还能较好地提升分类准确率。
2.2 特征融合模块设计
由于不同肌电特征集的数据维度和手势信息不同,特征融合模块使用中间融合[24]的方式,即对多视图经过卷积训练后得到的高层特征进行融合。通过融合多视图的高层特征,可以在降低数据维度的同时显著提高识别的准确性和鲁棒性。
模块第1 层将多流卷积层特征扁平化为1D 向量,使用带有512 个神经元的全连接层将卷积层学习到的分布式特征映射到样本标记空间,同时使用Dropout 层来防止过拟合。第2 层在通道维度对第1 个全连接层提取的高层特征进行特征融合。第3 层再次使用带有512 个神经元的全连接层来增加模型深度,提高非线性表达能力。每个全连接层后使用与卷积层相同的BN 层和ReLU 非线性激活函数。最后1 层使用带有Softmax 激活函数的全连接层来进行手势标签预测。手势标签采用one-hot编码形式解决类别数据中的离散值问题,手势预测类别定义公式如下:
其中:N为手势类别总数;pGN为预测为手势N的概率。取概率最大的N作为最终预测的手势G。
3 实验验证
实验基于TensorFlow 2.0 框架来搭建MVCANet,程序编写语言为Python,数据预处理和模型训练在AMAX TD21-Z2 工作站上运行,具体硬件配置为:Ubuntu 20.04 操作系统,运行内存为128 GB,处理器为英特尔I9 10900X,显卡为2 块英伟达Ge-Force GTX3080。
3.1 实验数据集
NinaPro 是目前最大的拥有sEMG 信息的公共数据库之一,它拥有丰富的手势数量和手势动作。本文使用NinaPro 的3 个子集(分别为NinaPro DB1、NinaPro DB5 和NinaPro DB7)进行训练和评估。NinaPro DB1 数据集包含27 名健康被试者(20 名男性,7 名女性;25 名右手,2 名左手)的数据,NinaPro DB5 数据集包含10 名健康被试者(8 名男性,2 名女性;10 名左手)的数据,NinaPro DB7 数据集包含20 名健康被试者和2 名右手截肢被试者(18 名右手,4 名左手)的数据。
数据集记录的动作分为3 个不同类别,包括手指的基本动作、基本手腕动作和抓握及功能性动作。每个动作重复6 次,每次重复持续5 s 后进入持续3 s的休息。本文在NinaPro DB1 上选取52 个动作、在NinaPro DB5 上选取41 个动作、在NinaPro DB7 上选取41 个动作来进行手势识别,选择的这些动作覆盖了日常生活中发现的大多数手部动作,同时考虑到手势分类以及机器人学和康复学的信息[17]。表2 所示为数据集的详细信息,图5 所示为NinaPro DB5 数据集示例手势1~6 的通道1 原始肌电信号波形图,图中手势图片来自文献[11]。
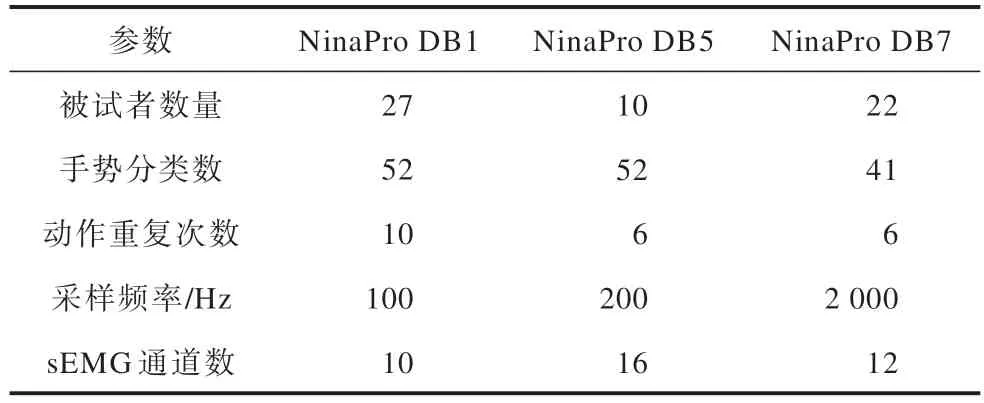
表2 NinaPro 的3 个子数据集信息Table 2 NinaPro's three sub-datasets information
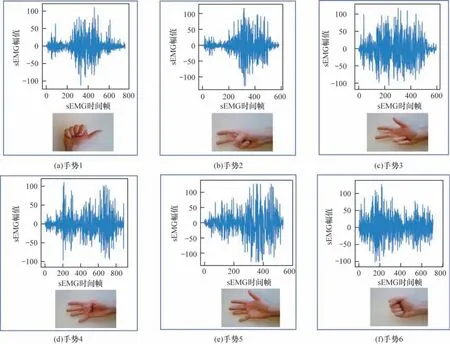
图5 示例手势的sEMG 对比Fig.5 sEMG comparison of example gestures
3.2 实验设置
MVCANet 网络模型使用分类交叉熵损失函数,如式(5)所示,其中,yj为真实标签的第j个值,Sj为Softmax 输出向量的第j个值,N为手势数量。采用随机梯度下降(SGD)进行训练,批处理数据量为64,迭代次数为28。为了使模型更快地拟合,使用动态调整学习率策略,初始学习率设置为0.1,在第16 次和第24 次迭代时将学习率除以10,Dropout设置为0.5。
数据集划分采用与文献[11]中相同的方案,该方案使用每个主题的2/3 作为训练集,剩余部分作为测试集。本文中NinaPro DB1 数据集采用重复次数分别为1、3、4、6、8、9、10 次的数据作为训练集,重复次数分别为2、5、7 次的数据作为测试集;NinaPro DB5 和NinaPro DB7 数据集采用重复次数分别为1、3、4、6 次的数据作为训练集,重复次数分别为2、5 次的数据作为测试集。由于实验设备内存限制,对NinaPro DB7 的sEMG 进 行2 000 Hz~100 Hz 的下采样处理。本文采用被试内(intra-subject)的手势识别方法,即计算数据集中每一名被试者的手势识别准确率,最终取平均准确率作为模型识别准确率,计算公式如式(6)所示,其中n为被试总人数。本文使用预训练方法来加快拟合速度并提高准确率[25],预训练方法使用所有被试者的训练集数据进行训练得到网络权重参数,在每一个被试者进行训练时使用该权重参数进行初始化。
3.3 结果分析
3.3.1 消融实验
为了验证多视图卷积网络模型的合理性和有效性,参考文献[14]中使用的消融实验策略,以不加注意力机制的单视图卷积网络作为基准模型来进行消融实验,各分组网络具体为:
分组1使用多视图卷积网络。
分组2在分组1 的基础上加入注意力机制,即MVCANet。
分组3在分组2 的基础上加入预训练方法。
其中,单视图CNN 网络结构使用MVCANet 中不带注意力机制模块的单流CNN,并且取消特征融合模块中的融合操作,取准确率最高的特征集作为消融实验中的对比特征集。由表3 结果可知,在3 个数据集上,MVCANet+预训练的模型均获得了最高的准确率,相比单视图CNN,MVCANet+预训练的模型最终准确率平均提升1.76 个百分点。
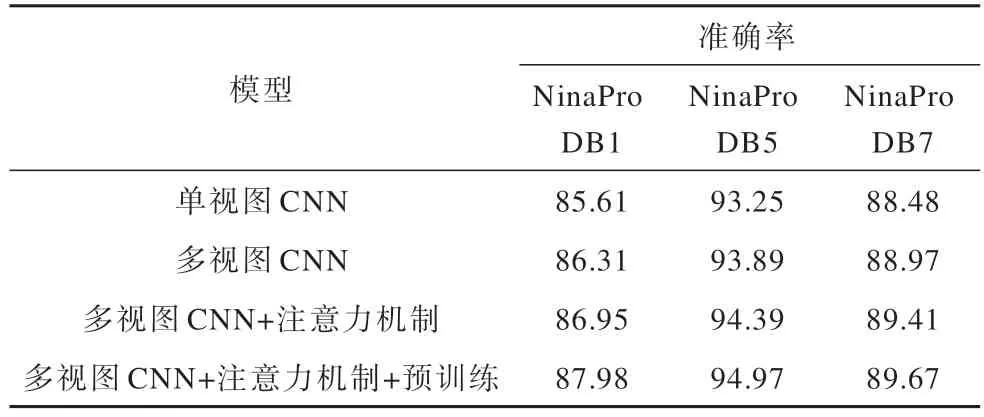
表3 消融实验平均准确率对比Table 3 Comparison of the average accuracy of ablation experiments %
图6 所示为NinaPro DB5 数据集10 个被试者在不同步骤时的消融实验准确率对比结果。由图6 可知,在每一个被试者上,随着实验步骤的增加,准确率均有提升,其中多视图CNN 相比单视图CNN 平均提升最高。由于被试者的个体差异和每次重复实验过程中混合信号的干扰,使得每个被试者的提升程度不一致。

图6 NinaPro DB5 数据集中每个被试者的消融实验结果Fig.6 Ablation experiment results of each subject in the NinaPro DB5 dataset
3.3.2 系统性能分析
为验证手势模型的实时识别性能,使用训练阶段保存的离线模型对测试集上数据进行手势实时测试。手势测试使用多数原则投票来计算所有整段手势动作上的平均准确率,其中多数原则投票的判定方式为:每段手势重复动作上的标签为离线模型对所有200 ms 滑动采样窗口的预测标签中出现次数最多的标签[26]。由于信息传输率(ITR)能够兼顾准确率和识别速度,是脑机接口研究中最优的性能指标之一[26],因此本文引入这一指标来检验系统的实时识别性能。ITR 计算方式如式(7)所示:
其中:N为所有的识别手势数;P为多数原则投票平均准确率;T为系统对一段手势动作的完整识别时间。
由表4 可知,本文系统在3 个数据集上平均投票准确率为97.63%,平均识别时间为0.26 s,平均信息传输率为1 308.71 bit/min。系统在整段手势动作的实时识别上具有更高的识别准确率以及高效的信息传输率,同时也证明了在实时手势识别系统中加入多数投票策略的必要性。

表4 多数原则投票和信息传输率结果Table 4 Majority principle voting and information transmission rate results
3.3.3 多模态实验
随着手势识别中手势数目和手势相似性的增加,仅依靠sEMG 来进行手势分类变得更加困难,sEMG 与IMU(Inertial Measurement Unit)相结合的多模态形式可以有效提升手势识别准确率[12]。使用单视图CNN 和MVCANet 模型在带有IMU 数据的NinaPro DB5 和NinaPro DB7 数据集上进行对比实验,结果如表5 所示。从表5 可以看出,2 种方法通过加入IMU 数据,在2 个数据集上准确率平均提升了2.83 和2.13 个百分点,同时MVCANet 在多模态实验中相比单视图CNN 准确率平均提升了0.75 个百分点。实验结果表明,通过加入IMU 数据可以有效提高手势识别准确率,相比于单视图CNN,MVCANet由于加入了ECA 注意力机制和使用多视图CNN,在多模态手势识别上具有更优的性能。
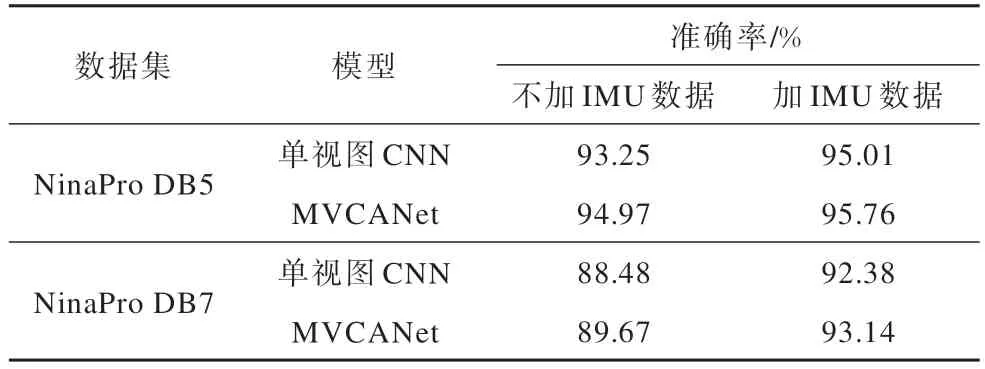
表5 多模态实验结果对比Table 5 Comparison of multimodal experimental results
3.3.4 与其他手势识别模型的对比
表6 所示为本文MVCANet 模型与传统机器学习方法和当今主流深度学习肌电手势识别模型的对比结果。从表6 可知,传统机器学习方法的手势识别准确率与当今主流深度学习模型相比均较低,这是由于深度学习中卷积网络可以更好地捕捉多通道肌电信号与手势动作之间的关联性,因此在肌电手势识别中具有一定的优越性。本文MVCANet 模型在NinaPro DB1、NinaPro DB5、NinaPro DB7 数据集上平均手势识别准确率分别为87.98%、94.97%、89.67%,在3 个数据集上均达到了最高的肌电手势识别准确率。在对比的手势模型中,CNN-RNN 模型结构与本文网络结构最为相似,CNN-RNN 基于MXNet 框架实现,使用融合注意力机制的多视图CNN 与LSTM 组合结构,特征提取采用Phin_FS1 特征集。相比之下,本文基于更优越的TensorFlow 2.0框架实现模型网络结构,特征提取额外使用了更丰富的小波包变换与小波变换特征,同时,在MVCANet 卷积前使用ECA 注意力机制来获得特征通道权重,便于卷积提取有效特征。因此,在NinaPro DB1 数据集上,本文模型手势识别准确率相比CNN-RNN 模型提高了3.18 个百分点。
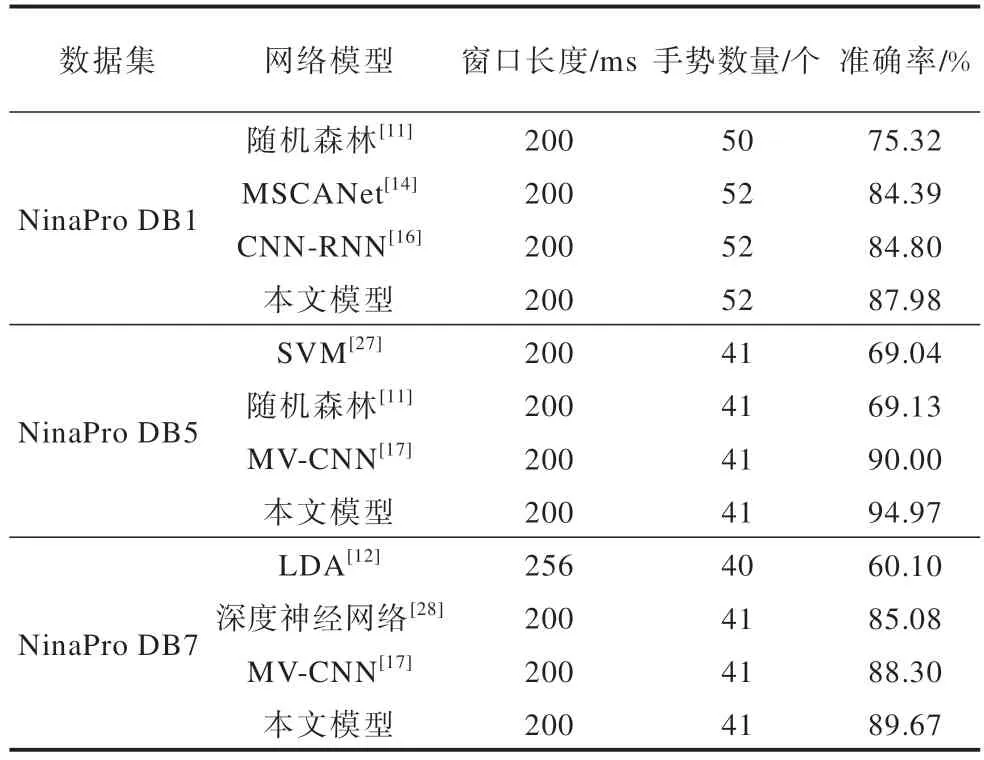
表6 sEMG 手势识别模型性能对比Table 6 Performance comparison of sEMG gesture recognition models
4 结束语
为了提高基于稀疏多通道的sEMG 手势识别准确率,本文提出一种融合注意力机制的多视图卷积神经网络模型。对原始sEMG 进行滤波处理,使用200 ms滑动窗口从原始肌电信号中提取经典的表面肌电信号特征集,对提取后的特征使用通道重排列算法得到通道相关性更高的肌电图。为了提高有效特征关注度,防止模型信息过载,模型加入ECA 注意力机制模块,对特征视图进行加权来强化有效特征,使得多视图卷积网络能够学习到与手势动作相关性更高的特征。在此基础上,通过特征融合模块融合多视图卷积特征来加强手势识别的准确性和鲁棒性。在NinaPro DB1、NinaPro DB5 和NinaPro DB7 公共肌电数据集 上的实验结果验证了该模型的有效性,与传统机器学习方法和近年来主流的深度学习手势识别方法相比,所提模型在肌电手势识别上具有更优的性能。下一步将测试其他类型的肌电信号,如Capgmyo、CSL-HDEMG 等高密度sEMG,同时优化网络结构,以提升本文模型在嵌入式平台上的实时性。
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
成都信息工程大学学报(2021年4期)2021-11-22
红领巾·萌芽(2019年9期)2019-10-09
科技传播(2019年24期)2019-06-15
小学科学(学生版)(2018年12期)2018-12-19
北京航空航天大学学报(2017年9期)2017-12-18
小学阅读指南·低年级版(2017年6期)2017-06-12
现代电生理学杂志(2016年4期)2016-07-10
体育科学研究(2015年4期)2015-02-28
汽车电器(2014年8期)2014-02-28
