
基于单-多视图优化的足球球员三维姿态和体型估计
2024-03-21 08:15谢欢刘纯平季怡
计算机工程 2024年3期
谢欢,刘纯平,季怡
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
0 引言
足球是全世界最受欢迎的运动之一,三维(3D)转播给观众提供了更好的观赛体验。2010 年,天空电视台使用三维专业摄像机拍摄并进行转播,但观众需要戴上特殊的三维眼镜来观看比赛,而且利用当时的技术仅能生成一个固定视角的小范围的三维立体效果。若要带给观众更好的观赛体验,则需要对整个场景进行三维重建,从而使观众能任意切换视角,不遗漏每一个精彩瞬间。因此,随着计算机视觉三维重建技术的发展,实现足球比赛的三维重建是一个具有重要意义的研究方向。在足球比赛场景中球员是非常重要的目标,足球球员的三维姿态和体型估计是关键环节。
人体三维姿态和体型估计在增强现实和计算机游戏中有着广泛的应用。人体三维姿态和体型估计根据是否使用参数化人体模型可划分为两类,即非参数化人体模型和参数化人体模型,其中,非参数化人体模型使用体素占用栅格[1-2]或者三维网格[3-4]来表示人体,参数化人体模型是近年来的研究热点。ANGUELOV等[5]提出数据驱动方法(SCAPE)用于人体体型建模,SCAPE 学习了两个单独的模型,一个对人体表面的非刚性形变建模,另一个对体型的变化建模。随后,许多在SCAPE 的基础上的改进方法被提 出,例 如S-SCAPE[6]和Breath-SCAPE[7]。LOPER等[8]提出一个蒙皮多人线性(SMPL)模型,SMPL 模型使用一个函数来表示人体的各种体型和姿态,其中表示体型的参数和表示姿态的参数是可以分离的。PAVLAKOS等[9]将SMPL 扩展到SMPL-X,通过增加手部、脚部和脸部的特征点来细化手脚和脸部的表示。在SMPL 模型的基础上,大量基于学习的方法[10-12]被提出。基于学习的方法具有以下特点:具有较好的性能,推理速度较快,但是依赖于大型的三维人体数据集;精度受数据集的影响较大,在数据集中的姿态和体型的多样性直接影响模型所产生结果的精度;使用深度神经网络来预测参数化人体模型的相关参数。在基于学习的方法中的一些方法使用整个彩色图像作为输入[13-15],另一些方法使用从图像中生成的中间表示作为输入,例如人体关节点[16]、稠密相关关系[17-18]、剪影[19-20]、人体部件[21-22]和纹理坐标[23]。此外,还有一些研究人员提出了基于优化的方法,将人体模型投影到二维(2D)平面,并与所观测到的二维特征进行拟合,其中的二维特征主要包括人体关节点[24-25]、剪影[26]和身体部位[21]。上述基于优化的方法可以在不需要三维标注的情况下生成可信的结果,但其中有一些方法在多视图图像[27]或者视频[28]中进行优化,利用人物姿态在时间域上的连续性以及体型的一致性实现三维重建。
人体数据集也是三维重建的关键,目前主要有UP-3D[26]和Human3.6M[29]。由于建立这样的数据集需要使用数量众多的硬件设备,因此这两个数据集的规模较小。例如,Human3.6M 只有11 个演员,而全世界大约有13 万名专业足球球员。同时,足球球员的一些专业动作,例如带球、头球和守门,在这些数据集中往往比较少出现。因此,基于学习的方法很难精确预测足球球员的三维姿态和体型。足球比赛通常以单视角视频的形式呈现,IPL Azadi Soccer数据集[30]是一个多视图的足球比赛数据集,但是图像分辨率较低并且不提供公开的访问和下载。同时,由于足球场地相对较大,使得足球球员在转播视图中的相对尺寸很小,而摄像机和球员之间的相对运动产生了大量的运动模糊,从而影响了对球员三维姿态和体型的精确估计。
针对上述问题,本文提出基于单-多视图优化的三维姿态和体型估计方法。对采集到的多视图图像使用目标检测网络(Faster R-CNN)[31]裁剪出球员图像,并且使用二维关节点检测方法(Detectron2)[32]检测球员的二维关节点,同时通过人工标注方式对被遮挡和低分辨率图像的二维关节点进行修正。在此基础上,利用SMPL 模型将球员的三维姿态和体型参数映射成对应的二维关节点,使二维关节点与标注值的差异最小化。本文主要贡献如下:1)构建了一个足球球员多视图数据集;2)为增强立体感知,提出基于单视角和多视角联合优化的足球球员三维姿态和体型评估方法,利用单视角优化缩小了三维模型与二维图像之间的差异,采用多视角优化统一了同一个球员的三维姿态和体型;3)通过实验证明了单-多视图优化方法生成的足球球员三维姿态和体型结果优于对比方法。
1 相关工作
1.1 SMPL 模型
SMPL 模型[8]是一个参数化人体模型,提供的人体各部分参数的平均值是从大量的人体三维模型中学习而来的,这些人体模型具有不同的姿态并进行了对齐操作。该模型使用的三维网格具有6 890 个顶点,并且可以通过一个可微的函数M(θ,β,γ)来表示,其中,姿态参数θ∊R69表示23 个人体关节的旋转角度,γ∊R3表示人体在根节点上的整体旋转角度,体型参数β∊R10表示人体的主成分分析系数。同时,人体关节点的三维坐标可以用一个线性函数来表示,其中的参数就是人体的姿态参数和体型参数。关节点的三维坐标又可以通过正交投影变换为二维坐标,从而使整个过程是可微的。因此,SMPL模型既可以用于基于优化的方法,又可以用于基于学习的方法。
1.2 从游戏中生成的标注
游戏行业发展非常迅速,目前游戏中提供的场景细节非常真实,被计算机视觉相关研究所应用。RICHTER等[33]从《侠盗飞车5》中为25 000 张图像生成了像素级别的语义分割标注。同时,足球游戏也引起了研究人员的关注[34-35],他们使用DirectX 工具从游戏中提取场景图像对应的深度图。REMATAS等[35]提出一个对足球场景进行三维重建的方法,但其中对于球员的重建仅由深度图实现。然而,由低分辨率的深度图转换成点云后再增加三维表面而生成的人体三维模型通常会缺失人体被遮挡部件。
1.3 优化技术
优化技术是指寻找一种解决方案,使某些特定的参数最大化或者最小化。优化技术可以应用在很多领域,例如使生产产品的成本最小化而利润最大化、使研发新产品时所使用的原材料最小化或者使产能最大化。在深度神经网络中,优化器是指可以更新神经网络的参数的算法,用于减少损失和提升精度。Adam 优化器[36]对每个参数使用同一个学习率,这个学习率会随着学习的进行而产生自适应的变化,同时利用动量算法来融合梯度的历史信息。Adam 优化器可用于解决很多问题,包括带噪声梯度的模型,并且其易于精调。
2 基于单-多视图优化的足球球员三维姿态和体型估计
在足球场景中足球运动员和足球本身都是小目标,遮挡和不同角度下的姿态是普遍存在的,本文提出一种单视图与多视图联合优化的足球球员三维姿态和体型估计方法,总体框架如图1 所示(彩色效果见《计算机工程》官网HTML 版,下同)。该方法包括5 个步骤:1)对球员的多视图图像使用Faster RCNN[31]裁剪出单 个球员;2)使用Detectron2[32]提取球员的二维关节点并对结果进行人工标注,得到标注后的二维关节点;3)使用训练好的部分注意力回归的三维人体估计模型(PARE)模型[22]产生初始的三维姿态和体型估计结果;4)使用SMPL 模型和标注的二维关节点进行单视图优化;5)使用多视图优化方法融合单视图优化结果,使融合后的结果投影生成的二维关节点与标注的二维关节点在多个视图上的差异最小化。
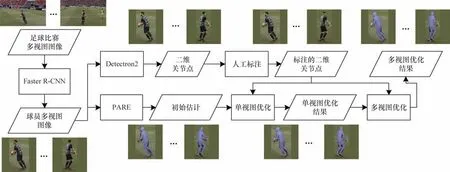
图1 足球球员三维姿态和体型估计总体框架Fig.1 Overall framework of 3D pose and body shape estimation of soccer players
2.1 二维关节点提取
在获取图像的基础上,选择估计的三维人体模型在二维平面上投影的关节点与从图像上标注的人体二维关节点之间的差异作为优化目标。相对于稠密相关关系、剪影、人体部件和纹理坐标,二维关节点相对容易标注。二维关节点只需要确定16 个坐标,而其他二维观测值则要进行像素级别的标注。使用Detectron2[32]中的人体关节点循环神经网络提取球员的二维关节点,其中关节点的分布如图2 所示。在关节点清晰可见的情况下,该方法能够取得较好的效果,如果关节点被遮挡或者图像较模糊,生成的结果则不一定准确,例如图像上只能看到球员的背面,球员面部的关节点有可能错位,图像模糊时会把左脚和右脚上的关节点搞混。人工标注方法可以利用经验和多视图融合来判断关节点的位置,例如可以通过头部的形状确定鼻子和眼睛的位置,通过手臂的延伸确定手腕的位置,同时可以参考多视图图像来确定被遮挡关节点的正确位置,但是人工标注方法需要大量的人力物力,且标注速度慢,无法满足大规模标注的需求。

图2 人体二维关节点示例Fig.2 Example of human body 2D joint points
2.2 单-多视图优化
首先,使用训练好的PARE 模型[22]生成SMPL 参数的初始估计,输入为球员图像,输出为SMPL 参数和相机位姿参数。由于图像裁剪时没有使用固定的比例,因此需要对结果中的相机参数进行优化。因为人体姿态参数的旋转向量在欧几里得空间上是不连续的,所以将其转换成连续的六维旋转表示[37],以适应接下来的优化操作。假设摄像机始终对准球员,摄像机的旋转矩阵可以定义为单位矩阵,只需要考虑球员自身的旋转。相机的位置参数P由一个3×1的向量(s,tx,ty)表示,其中,s代表缩放参数,tx和ty分别表示相机在x和y方向上的位移。初始估计的结果在图像上的投影与实际的二维图像会有差异,因此需要对初始估计的参数进行优化。
然后,利用单视图优化操作使人体三维模型关节点的二维投影与实际的二维关节点差异最小。在休息姿态下,人体模型的顶点可以定义如下:
其中:β表 示SMPL 的体型参数;|β|表示参 数的数量,这里取10;S表示人体模型顶点位移的正交主分量。
将休息姿态下的三维关节点定义如下:
将休息姿态下的三维关节点转换为实际姿态下的三维关节点的函数定义如下:
其中:G表示刚性变换,根据姿态参数中的旋转角度对每个关节点执行相应的旋转操作。
最后,通过正交投影将三维关节点投影到图像平面上生成预测的二维关节点J2pDre。优化的目标函数可以定义如下:
单视图优化使预测的二维关节点拟合实际观测到的二维关节点,但是同一个球员在不同视图上得到的姿态和体型参数是不一致的,这与同一名球员在不同视图上具有相同的姿态和体型的事实相违背,因此需要多视图优化来融合多个视图之间的信息。
受到三维模型投影到二维平面所产生的信息损失的影响,单视图优化的结果往往会过度拟合二维信息以取得更优的得分,而多视图优化可以从多个视图上恢复损失的三维信息,避免上述问题。多视图优化的基础是同一名球员在不同视图上具有相同的姿态和体型。多视图优化将同一名球员在5 个视图上的单视图优化结果的姿态和体型参数的平均值作为输入,同时在多个视图上拟合二维关节点,从而得到最优的姿态和体型参数。
3 实验结果与分析
3.1 实验数据集构建
足球游戏《FIFA 21》在回放中可以调整到不同的视图,其中电视视图是游戏中经常使用的视图,摄像机沿足球场的边界跟随足球平行移动。在现实中足球转播的主要视图是转播视图,摄像机位于足球场看台中部,随着足球的移动而产生左右和上下的旋转。《FIFA 21》中同时提供了环绕视图,可以定位到单个目标上,并且可以进行放大、缩小和旋转操作。在不同视图下采集到的图像如图3 所示。
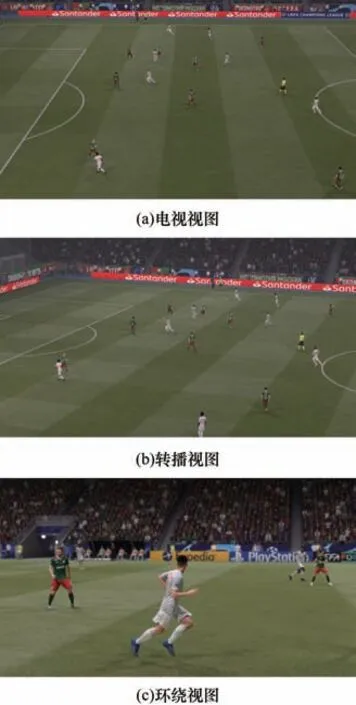
图3 足球游戏《FIFA 21》中的不同视图Fig.3 Different views in the soccer game FIFA 21
本文主要采集转播视图和环绕视图的图像。首先,从转播视图上采集球员图像,从环绕视图上对每名球员采集4 幅图像,这4 幅图像所选择的角度是通过人工观察来确定的,确保尽可能地观测到手、脚和头部,这样场上的22 名球员共有88 幅图像。然后,使用Faster R-CNN 方法[31]检测图像中的球员并标注包围框。最后,对转播视图和环绕视图上的球员进行配对,只保留在转播视图中出现的球员。
自建的足球球员多视图数据集包含《FIFA 21》中的50 场欧洲冠军联赛,每场比赛截取5 个场景,共250 个场景,3 300 名球员。为了增加球员的多样性,其中,30 场比赛使用的是原欧洲冠军联赛球队,另外20 场比赛使用随机的球队。
在单视图上对二维关节点使用均方根误差(RMSE)作为评价指标(该指标越低,估计方法的性能越好),对剪影使用交并比(IoU)作为评价指标(该指标越高,估计方法的性能越好)。对于三维重建精度的度量,将单视图姿态和体型估计结果应用到其他视图上进行交叉验证。
3.2 二维关节点人工标注
二维关节点检测结果和人工标注结果如图4 所示,其中红色方框标注了检测结果中的错误。在图4(a)中,从左到右分别为面部关节点错位、左右脚踝错位和手腕关节点错位,产生的原因分别为人脸正面不可见、图像模糊和手腕被身体遮挡。在图4(b)中,人工标注根据经验和多视图图像来判断关节点的正确位置。

图4 二维关节点检测结果Fig.4 2D joint point detection results
3.3 三维姿态和体型初始估计
使用训练好的PARE 模型获得球员的三维姿态和体型的初始估计,球员图像和人体模型的差异如图5所示。由图5 可以看出,从二维图像上通过基于学习的方法生成的人体模型在图像平面上的投影与实际图像存在明显的偏移。这是由于数据集中球员图像不但有人侧身行走时的腿部姿态,而且还有将身体扭转了一定的角度以便更好地观察球场内情况的姿态,而PARE模型仅考虑了腿部的姿态,忽略了手的位置。

图5 三维姿态和体型的初始估计误差Fig.5 Initial estimation error of 3D pose and body shape
3.4 单视图优化结果
单视图优化能较好地拟合二维关节点,但是造成了三维信息的损失,而且单视图优化没有考虑视图之间的关系,使得一个视图上的三维姿态和体型投影到其他视图上时与实际图像有很大的差异。图6 展示了将其中一个视图的结果应用到其他视图上的可视化差异,其中,第1 行为球员图像,第2~5 行分别将单视图的三维姿态和体型优化结果应用到所有其他视图上。可以看出,生成的人体模型渲染图像在本视图(红框)上几乎与图像完全重叠,而在其他视图上则会有较大的差异。

图6 单视图优化结果应用到其他视图上的差异比较Fig.6 Comparison of differences by applying single-view optimization results to other views
3.5 多视图优化结果
在进行多视图优化时使用3 种不同的方法:1)使用初始估计结果在4 个视图上进行多视图优化;2)使用初始估计结果在5 个视图上进行多视图优化;3)使用单视图优化结果在5 个视图上进行多视图优化。实验先进行单视图优化,再在所有视图上进行多视图优化取得最优的效果,结果如表1 所示,其中最优指标值用加粗字体标示。
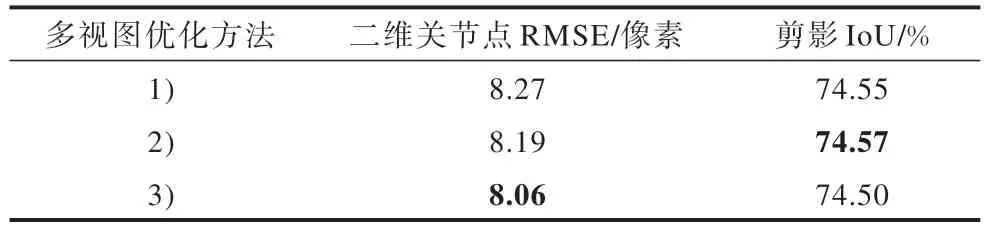
表1 多视图优化结果Table 1 Results of multi-view optimization
3.6 与其他方法的比较
将所提方法与人体网格恢复(HMR)[13]、在循环中优化SMPL(SPIN)[14]、PARE[22]和真实精确姿态和形状的合成训练(STRAPS)[24]方法进行比较,在单视图上的比较结果如表2 所示,在多视图上的比较结果如表3 所示,其中,STRAPS 方法[24]使用人体二维关节点和剪影作为输入,其他方法使用彩色图像作为输入。由于统一了多个视图上的姿态和体型,因此在单视图和多视图上的结果是一致的。
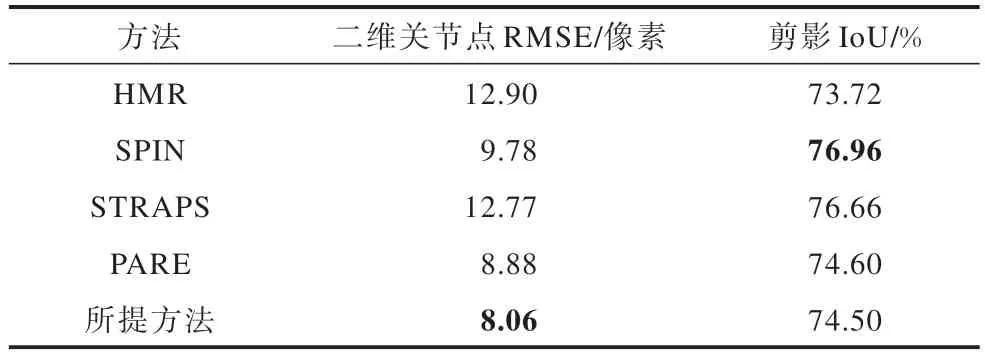
表2 所提方法与其他方法在单视图上的比较Table 2 Comparison of the proposed method with other methods on single-view
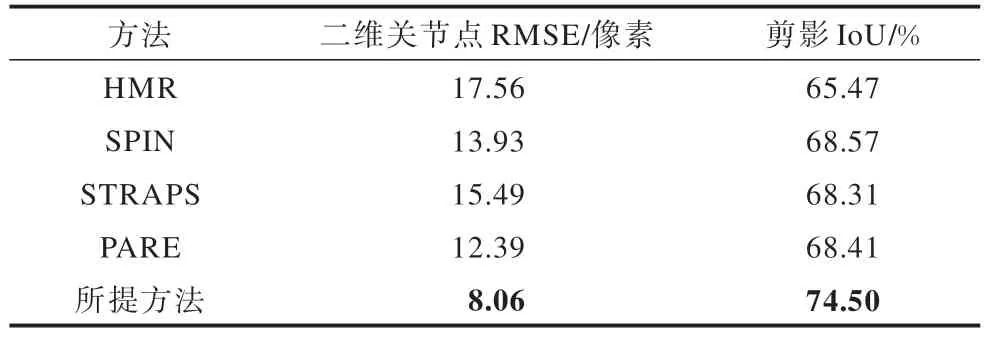
表3 所提方法与其他方法在多视图上的比较Table 3 Comparison of the proposed method with other methods on multi-views
图7 展示了球员的三维姿态和体型的可视化结果,其中,第1~3 行为环绕视图图像,第4~6 为转播视图图像。实验结果表明,多视图优化方法不仅提升了二维关节点和剪影的拟合度,同时将多个视图中球员的三维姿态和体型进行了统一,提高了三维重建精度。

图7 所提方法与其他方法的可视化结果比较Fig.7 Comparison of visualization results of the proposed method with other methods
4 结束语
本文提出基于单-多视图优化的足球球员三维姿态和体型估计方法,利用参数化人体模型的可微性分别在单视图和多视图上融合了球员的二维关节点信息,使同一球员的三维姿态和体型在多个视图上得到统一,同时从游戏中构建一个足球球员多视图数据集。在自建的足球球员多视图数据集上的实验结果表明,所提方法能从多视图图像中有效地估计球员的三维姿态和体型,相比于其他方法更能拟合图像上的二维信息,提高了二维关节点的预测精度。但由于基于单-多视图优化的三维姿态和体型估计方法比较耗时,后续将在该方法的数据基础上使用基于学习的方法来学习并建立足球球员三维姿态和体型估计模型,并将其应用到真实的足球比赛场景中。
猜你喜欢
车主之友(2022年5期)2022-11-23
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
中国生殖健康(2020年5期)2021-01-18
幽默大师(2019年10期)2019-10-17
文苑(2019年14期)2019-08-09
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
军营文化天地(2017年6期)2017-06-28
现代兵器(2017年4期)2017-06-02
