
云-边融合的可验证隐私保护跨域联邦学习方案
2024-03-21 08:15张晓均李兴鹏唐伟郝云溥薛婧婷
计算机工程 2024年3期
张晓均,李兴鹏,唐伟,郝云溥,薛婧婷
(西南石油大学计算机科学学院网络空间安全研究中心,四川 成都 610500)
0 引言
人工智能[1]和物联网(IoT)技术的深度融合推动了联邦学习的快速发展,特别是在计算机视觉、医学预测、语音识别等领域[2-3]取得了突破性的成果。然而,部署联邦学习实现分布式梯度模型训练面临着巨大挑战,特别是来自于联邦学习(FL)数据收集带来的隐私问题[4],用于训练的数据通常是敏感的,可能来自多个具有不同隐私要求的终端用户。
除此之外,联邦学习主要挑战是梯度模型聚合计算结果的完整性问题[5],在某些非法利益的驱动下,恶意的边缘服务器可能会向用户返回不正确的结果,或者恶意伪造发送给终端用户的梯度模型聚合计算结果[6]。此外,参与联邦学习的设备存在异构性[7],在设备间具有不同的计算和通信能力。在这种情况下,一些具有足够计算能力和通信资源的设备可以在规定时间内迅速完成本地训练和上传,而其他资源受限的设备则无法在规定时间内完成本轮更新,从而影响系统整体的训练性能,进而影响全局梯度模型的精度。
针对资源受限的设备梯度隐私、梯度完整性、设备低延迟、高效训练[8]的问题,本文提出一种云-边融合的可验证隐私保护跨域联邦学习框架。该框架设计3 层架构的跨域联邦学习系统模型。该系统模型基于经典联邦学习终端用户对边缘服务器的弱信任,提出可验证安全聚合算法,该算法利用单掩码技术盲化梯度数据并采用轻量级验证方法防止边缘服务器恶意篡改聚合梯度的模型参数,在线终端用户的训练梯度安全有效地被边缘服务器聚合,聚合结果可以被终端用户验证正确性。在可验证安全聚合算法的基础上,本文提出一种可验证隐私保护跨域联邦学习训练算法,该训练算法考虑局部轻量训练克服异构网络资源受限不能及时响应的特性,提高了系统的稳定性,使每个区域的在线终端设备都并行进行同一轮次的局部轻量训练。最后,针对同一模型权重进行局部轻量训练时收敛速度慢、泛化性差和局部轻量训练精度低等问题,使用训练器不共享加密梯度而共享加密模型权重的训练模式[9]来加快收敛速度。
1 相关工作
近年来,已有研究人员对联邦学习中的敏感数据机密性和完整性问题进行研究。GU等[10]提出隐私保护的异步去中心化联邦随机梯度下降算法。ZHANG等[11]采用非对称加密和数字签名技术保护用户隐私并设置验证节点,引入智能合约来评估和选择最佳模型。AKTER等[12]采用传统神经网络模型和人工噪声函数来平衡隐私保护和模型性能。PAREKH等[13]提出在最后1 个卷积层的输出中加密图像的梯度加密技术。LEE等[14]提出基于贪婪算法解决联邦学习的统计异质性问题并加速联邦训练。上述4 个方案[11-14]主要关注梯度数据机密性而对梯度聚合结果的完整性验证没有研究。目前,联邦学习用户希望及时验证服务器聚合结果的正确性。因此,实施具有可验证聚合的隐私保护联邦学习方法是非常重要。为了实现这一目标,需要采取一种高效和安全的方法,然而上述解决方案在解决此问题时存在一定的局限性。
为此,研究人员针对梯度聚合的完整性设计不同的可验证联邦学习方案。ELTARAS等[15]利用单掩码技术确保用户隐私并提出双聚合概念,以验证聚合结果。ZHANG等[16]使用双聚合方法对模型进行聚合,并采用分组链训练结构提高训练效率,然而该结构没有考虑到恶意用户对模型的影响。ZHOU等[17]提出一种反作用差分隐私噪声保护用户隐私,使用同态哈希函数设计一种非追溯性验证机制,但是噪声会降低训练精度。GAO等[18]通过梯度分组和压缩来优化拉格朗日插值,以实现联邦学习的有效可验证性,为保护用户的数据隐私免受串通攻击,提出一种使用不可逆梯度变换的轻量级承诺方案。LI等[6]通过集 成Paillier 同态加 密和随 机数生成技术,保护所有梯度及其密文,并且引入一种基于离散对数的秘密共享方案,以抵御聚合服务器、恶意参与者和边缘节点之间的潜在串通攻击。然而,由于同态加密和密文扩展的计算复杂性,因此该方案具有较大的计算和通信开销。TANG等[19]设计2 个零知识证明来验证梯度的正确性,并提出一种保护局部梯度和全局模型隐私的可验证扰动方案。YANG等[20]设计一种加权掩码技术保护梯度数据并利用同态哈希函数和同态签名构建可验证聚合标签,但计算成本昂贵。XU等[21]提出在训练神经网络过程中进行验证的隐私保护方法,设计一种基于同态哈希函数和伪随机技术的可验证方法来支持每个用户的可验证性。HAHN等[22]对文献[21]方案中的安全和效率问题进行优化,设计安全高效的跨设备联邦学习可验证安全聚合方案。文献[23]指出文献[22]方案仍然存在隐私安全问题。上述可验证联邦学习方案都能验证恶意服务器对聚合梯度的伪造,但是大多数方案的验证开销代价昂贵并且有些方案没有解决训练效率低的问题。因此,为了满足轻量可验证聚合结果的要求并提高训练效率,相比其他方案[15,22],本文提出更高效的可验证聚合方案,解决异构网络联邦训练问题,并提高训练效率。
2 相关概念与技术概述
2.1 联邦学习
Google 提出的FedAvg 算法[24]指出大 量去中 心化的数据存储于移动设备,但数据隐私问题没有得到解决。联邦学习是一种分布式机器学习技术,通过聚合局部计算梯度来训练集中的模型,而训练数据分发给每个终端用户,并且不与其他终端用户共享。边缘服务器通过重复聚合局部梯度来协调训练过程,每轮包括以下过程:
终端用户选择:边缘服务器选择1 组终端用户,并向他们提供当前的模型参数。这些终端用户可以在整轮训练中存活下来,或者在当前一轮训练完成之前退出。
本地训练:每个终端用户在本地进行模型更新。更新通常涉及1 个小批量随机梯度下降规则的变体,该规则返回1 个梯度作为局部训练结果。
梯度聚合:边缘服务器收集有效终端用户发送的梯度,计算梯度模型聚合值。
全局模型更新:边缘服务器使用聚合的梯度更新当前的全局模型。该全局模型将在后续一轮中发布。
尽管终端用户的训练数据永远不会离开每个用户的本地存储器,但是可以利用本地计算的模型参数来推断训练数据。因此,在正确启用局部模型参数聚合的同时,最好保持局部模型参数保密。
联邦学习广泛适用于2 种不同的场景:跨设备和跨孤岛。在跨设备设置中,大量资源受限的终端用户参与学习,而网络条件是高度不可靠的。相比之下,跨孤岛设置包含更稳定的环境,其中少量拥有丰富计算资源的组织作为参与用户,网络通道是可靠的。本文设计的联邦学习方案主要讨论跨设备场景。
2.2 权重转发技术
权重转发技术来自于PHONG等[9]提出的服务器辅助网络系统,系统使用的训练器不共享梯度而共享神经网络权重的隐私保护系统来保护所有训练器的本地数据。在本文方案中训练器是每个终端设备,当某区域训练器在当前轮次的联邦训练结束后,边缘服务器负责与云服务器通信并转发加密权重。
2.3 单掩码技术
梯度向量ru被一种特殊的方式盲化,该盲化技术[25]可以通过盲化计算使聚合梯度向量可以被保密地计算出来。对于终端用户IDu的下标是u,并且用(u,v)表示一对终端用户IDu和IDv的下标。假设有随机向量pu,v且u<v,如果终端用户IDu将pu,v添加到向量ru中进行盲化,则在终端用户IDv中添加向量pu,v的相反值进行盲化。当累加它们的盲化向量时掩码将被抵消,它们的实际值将不会被暴露。每个终端用户IDu的盲化值计算如下:
终端用户IDu给边缘服务器发送λu,边缘服务器计算如下:
基于云-边融合的可验证隐私保护跨域联邦学习架构如图1 所示。
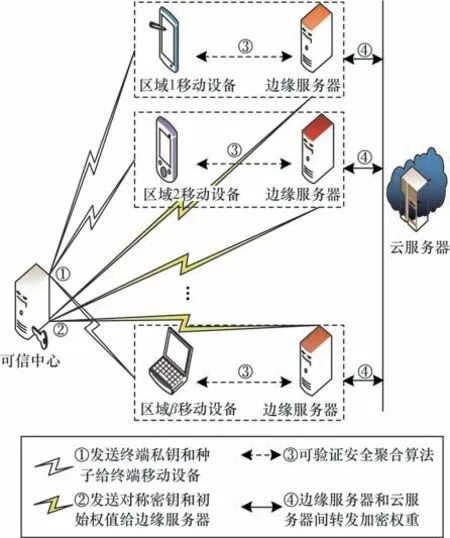
图1 3 层架构的跨域联邦学习系统模型Fig.1 Cross-domain federated learning system model with three layers architecture
3 云-边融合的可验证隐私保护跨域联邦学习方案
本文提出云-边融合的可验证隐私保护跨域联邦学习方案,该方案首先在多区域部署可验证安全聚合算法,在此基础上,提出可验证隐私保护跨域联邦学习训练算法。
3.1 可验证安全聚合算法
可验证安全聚合算法有4 个阶段:系统初始化阶段、梯度盲化及签名产生阶段、去盲化及聚合梯度产生阶段、聚合梯度正确性验证阶段。图2 所示为可验证安全聚合算法的流程。
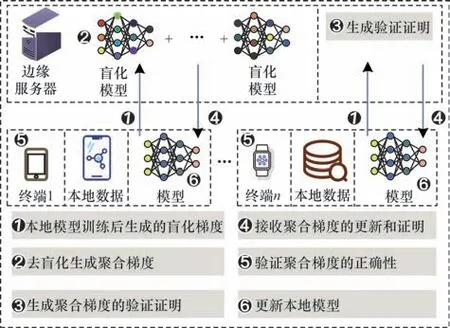
图2 可验证安全聚合算法流程Fig.2 Procedure of verifiable secure aggregation algorithm
在系统初始化阶段,可信中心(TA)执行以下步骤:
1)可信中心生成大整数2η并生成q阶乘法循环群G,q(q<2η)是1 个大素数,选取G的1 个生成元g,并且设置1 个安全的哈希函数H:→{0,1}η。
2)可信中心为β个区域中注册成功的终端用户IDu生成公私钥对{pku,sku},其中pku=,sku∊,可信中心将私钥sku通过安全信道发送给每个终端用户IDu。
3)可信中心设置伪随机数发生器(PRG),将输入种子映射到伪随机输出序列,并保证输出分布在计算上与均匀分布难以区分。假设梯度向量是l维,使用PRG:{0,1}η→将1个输入值扩展为l维输出向量。
4)可信中心设置β个辅助向量的种子{seed(i)}1≤i≤β∊{0,1}η,依次通 过安全 信道给β个区域中注册成功的终端用户发送对应的种子。
在梯度盲化及签名产生阶段,有效终端用户执行以下步骤进行梯度盲化,并同时计算数字签名。在时间周期T内,假设愿意贡献梯度模型数据的有效终端用户至少有t个(t为门限值),将每个有效终端用户IDu的下标记录到集合U1,并且t≤|U1| ≤n。有效终端用户IDu(u∊U1)执行如下步骤;
1)对于下标集合U1中的每个终端用户IDu,利用对应的私钥sku计算集合
2)IDu将集合中的元 素依次 扩展成l维随机向量pu,v=Δu,v∙PPRG(su,v),且有u>v则Δu,v=1;u<v则Δu,v=-1;u=v则Δu,v=0,对所有u≠v有pu,v+pv,u=0。
3)IDu通过本地梯度模型的训练,得到梯度模型可学习数据为向量ru=(ru(1),ru(2),…,ru(l))T,对梯度模型向量进行盲化
在去盲化及聚合梯度产生阶段中,边缘服务器EDi得到每个有效终端用户IDu(u∊U1)发送的可验证梯度盲化信息{λu,σu},执行如下步骤:
在聚合梯度正确性验证阶段中,隶属于区域i的有效终端用户IDu(u∊U1)执行以下步骤:每个参与者IDu(u∊U1) 接收到(y,σ) 之 后,计算σ′=gai∙y=验证σ′=σ是否相等,相等则说明梯度模型信息没有被篡改,并且边缘服务器没有恶意篡改聚合梯度,全局模型参数正确。
3.2 可验证隐私保护跨域联邦学习训练算法
可信中心通过安全信道为各区域的边缘服务器发送1 个对称密钥K,采用AES 作为加密算法。在方案中,m表示各区域重新训练次数,τ表示各区域的全局模型迭代次数,针对资源受限的设备设置较小τ值进行轻量训练,每个区域总共需要的迭代次数为m∙τ次。图3 所示为云-边融合的可验证隐私保护跨域联邦学习训练权重转发流程,在边缘服务器之间不共享梯度而共享神经网络权重。
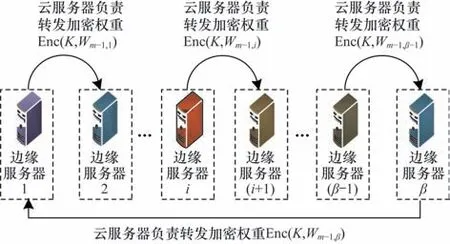
图3 云-边融合的可验证隐私保护跨域联邦学习训练流程Fig.3 Training procedure of cloud-edge fusion verifiable privacy-preserving cross-domain federated learning
训练算法的具体步骤如算法1 所示,算法1 的第1 行表示每个区域总共需要训练m轮次,算法1 的第2~6 行表示当i=1 处在训练的第1 轮时,可信中心生成初始权重W0,计算加密权重并发送给各个服务器。此时,第j个区域的边缘服务器接收到加密权重,边缘服务器EDj对权重进行解密:W0=DecAES(K,Enc(K,W0))。边缘服务器EDj将权重W0发送给在本区域注册成功的终端,在终端和边缘之间执行可验证安全聚合算法VSA(W0,τ),边缘服务器EDj得 到1 个更新权重W1,j,W1,j表示区域j完 成1 轮训练的权重。算法1 第7~14 行表示当训练处在第i(i≥2)轮时,边缘服务器EDj将权重Wi-1,j通过密钥K对称加密发给云服务器,云服务器将加密权重按顺序发给下1 个边缘服务器EDj+1。第9 行表示EDj+1解密加密权重Wi-1,j=DecAES(K,Enc(K,Wi-1,j))。边缘服务器EDj+1将权重Wi-1,j发送给在本区域注册成功的终端。第10 行表示在终端和边缘之间执行可验证安全 聚合算 法VSA(Wi-1,j,τ),最 终EDj+1得 到1 个更新权重Wi,j+1,Wi,j+1表示区域(j+1)完成i轮训练的权重。算法1 第12 行表示最后1 个边缘服务器EDβ的加密权重发送给第1 个边缘服务器进行解密。第13行Wi,1表示区域1 完成i轮训练的权重。
算法1可验证隐私保护跨域联邦学习训练算法
输入m表示每个区域总共训练的轮次;τ表示每个区域每1 轮的全局模型迭代次数;β表示区域的总数;VSA(⋅)表示可验证安全聚合算法;初始权重W0
4 安全性分析
定理1云-边融合的可验证隐私保护跨域联邦学习方案可抵御区域间的合谋攻击。
证明从区域获得的是当前的输入权重和输出权重,输入权重通过梯度下降法的迭代更新后得到输出权重。假设全局迭代次数为n,梯度为G,输入权重为W0=Winit,输出权重为Wn=Wend并且(Xi,Yi)(1 ≤i≤n)表示当前区域数据集的随机批次。梯度下降更新步骤如下:
根据以上梯度下降更新步骤可以推出如下等式:
即使共谋方在权重转发过程中得到输入权重Winit和输出权重Wend,也只能计算梯度的加权和Winit-Wend=α1∙G1+…+αn∙Gn,而当前 区域本地数据集和每轮更新的聚合梯度Gi都是保密的,并且αi也会根据区域边缘服务器的学习速率秘密变化。根据文献[8]的安全分析,假设只有当前区域的边缘服务器是诚实的,而云服务器和其他区域的边缘服务器是恶意的。即使有这样的合谋也不能恢复诚实边缘服务器的任何数据项,除非1 个非线性方程(或1 个子集和问题)在多项式时间内被解决。
定理2云-边融合可验证隐私保护跨域联邦学习方案确保梯度模型训练过程与聚合计算结果完整性。
证明本文方案基于向量内积的数字签名算法,在梯度盲化及签名产生阶段使每个终端IDu都可以利用对应的私钥sku产生数字签名。方案中的数字签名算法满足不可篡改性的可证明安全论证可以归约到基于Diffie-Hellman(CDH)困难问题假设。下面分析方案在训练过程中梯度模型的完整性可得到保证,即敌手试图篡改可验证的梯度盲化信息或聚合梯度来通过完整性验证在多项式时间内是计算不可行的。
Game 2假设存在恶意边缘服务器在去盲化及聚合梯度产生阶段试图以不可忽视的概率替换或篡改聚合梯度y*并生成聚合签名信息其中U1表示正常用户集合,并且在聚合梯度正确性验证阶段成功通过验证方程σ′=σ。
5 实验仿真与分析
5.1 实验环境设置
方案中所有算法的实现都在处理器Intel®CoreTMi7-11800H @2.30 GHz、图形处理器NVIDIA GeForce RTX 3060 Laptop GPU 和运行内存16 GB的主机上运行。
训练实验采用Python3.9、PyTorch 1.21.1 实现,实验设置4 个训练 集CIFAR10、MNIST、CIFAR100、SVHN,2 个深度学习模型ResNet18 和GoogleNet。实验使用模型ResNet18 训练4 个数据集。4 个数据集等同于4 个区域中终端的本地数据集,把每个区域训练完成的模型通过AES加密安全发送给下1个区域进行训练,循环往复。同理GoogleNet模型训练方式同上。
密码实验的计算开销时间都在C 语言环境下进行并使用版本号为7.0.0 密码学函数库Miracl 和pbc-0.5.14 密码学函数库。Tmm表示模乘运行时间,Tme表示模幂运行时间,Tha表示普通哈希函数运行时间,Tad表示模加法的运行时间,TPRG表示伪随机数发生器生成1 次的运行时间。
5.2 计算开销比较
本文将云-边融合的可验证隐私保护跨域联邦学习方案与VerSA 方案[22]和文献[15]方案[15]进行验证阶段的计算开销比较。假设本文方案每个边缘服务器负责区域下愿意贡献梯度向量的终端用户数为n,假设VerSA 方案和文献[15]方案中愿意贡献梯度向量的终端用户数也是n,文献[15]方案的辅助节点数为m并且后续没有终端用户退出。3 个方案梯度向量的维数是l维并且不计算初始化阶段的计算开销。
文献[15]方案中终端用户在保护梯度隐私过程中执行m次(Tme+Tha)运算生成m个PRG(∙)的种子,输入m个种子生成m个l维向量并执行l∙m次(TPRG+Tad)生成梯度的盲化向量。执行l次(Tad+Tmm)运算生成签名向量。随后辅助节点执行n次(Tme+TPRG+Tha)运算和l∙(n-1)次Tad运算生成解盲化参数,最后终端执行l次(Tad+Tmm)运算验证聚合梯度的完整性。终端的总计算开销为(m+n)∙Tme+(l∙m+n)TPRG+l∙(m+n+1)∙Tad+(n+m)∙Tha+2l∙Tmm。服务器端执行l∙(n+m-1)次Tad运算去除梯度的盲化值,执行l(n-1)次Tad运算生成验证凭证。服务器端的计算开销为l∙(2n+m-2)∙Tad。
VerSA 方案终端用户执行n次(Tha+Tme)运算生成n个PRG(∙)的种子,执行(n-1)次Tad运算生成1 个验证种子,执行l∙(n+1)次(TPRG+Tad)运算生成梯度的盲化向量,输入验证种子执行2l次TPRG运算和l次(Tmm+Tad)生成验证函数。执行l∙(n+1)次(TPRG+Tad)运算生成签名向量,最后终端执行2l次Tmm运算和l次Tad运算验证聚合梯度的完整性。终端的计算开销为n∙Tme+l∙(2n+4)(TPRG+Tad)+TPRG+n∙Tha+3l∙Tmm。服务器端执行l∙(2n-1)次Tad运算去除梯度的盲化值,执行l∙(2n-1)次Tad运算生 成验证凭证,服务器端的计算开销为(4n-2)∙l∙Tad。
本文方案终端用户执行n次(Tha+Tme)运算生成n个PRG(∙)的种子,执行l∙n次(TPRG+Tad)运算生 成梯度的盲化向量,输入辅助向量种子执行l次TPRG生成辅助向量。基于向量内积执行l次Tmm运算和(l-1)次Tad运算并执行1次Tme运算生成签名,最后终端执行l次Tmm运算、(l-1)次Tad运算和1次Tme运算验证聚合梯度的完整性。终端的总体计算开销为(n+2)∙Tme+l∙(n+1)TPRG+(l∙n+2l-2)∙Tad+n∙Tha+2l∙Tmm。本文方案的边缘服务器端就是服务器端,服务器端执行l∙(n-1)次Tad运算去除梯度的盲化值,执行(n-1)次Tmm运算生成验证凭证,服务器端的计算开销为l∙(n-1)Tad+(n-1)∙Tmm。
假设q是1 024 位的大素数,向量的维度l是10 000 维,用户数n分别设 置500 个、1 000 个 和1 500 个,根据文献[15]方案中辅助节点的数量m随着用户数增多分别占用户数的10%、30%和50%,则辅助节点m分别设 置50 个、300 个、750 个。不同方案的终端计算开销对比如图4 所示。在固定向量维度的情况下,随着终端用户数的增加,本文方案在终端的计算开销是最低的。不同方案的服务器端计算开销对比如图5 所示。在固定向量维度的情况下,随着终端用户数的增加,本文方案在服务器端的计算开销是最低的。综上所述,在用户端和服务器端,本文方案的计算开销都比VerSA 方案和文献[15]方案低,具有显著的性能优势。
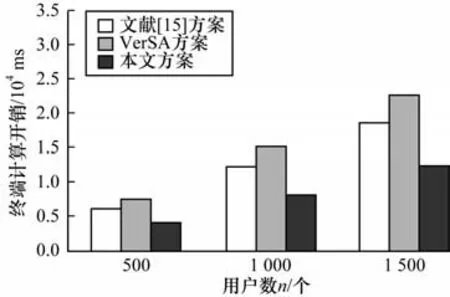
图4 不同方案的终端计算开销Fig.4 Terminal computional costs among different schemes
5.3 系统性能与精度分析
5.3.1 基于数据集训练次数的精度比较
在实验设置系统中每个区域的用户有100 个,使用模型ResNet18 在4 个区域分别训练CIFAR10、MNIST、CIFAR100 和SVHN 数据集。模型在4 个区域初始迭代训练15 次之后通过某种顺序将其发送给下1 个区域,然后接收到新模型的区域进行新一轮的训练,4 个区域重新训练4 次。从实验结果中选出数据复杂度更高的CIFAR100 和SVHN,分别比较CIFAR100 和SVHN 数据集重新训练次数增加时的精度变化。基于重新训练次数的精度比较如图6 所示。图6(a)所示为CIFAR100 数据集初始训练、重新训练2 次和重新训练4 次的精度变化曲线,图6(b)所示为SVHN 数据集初始训练、重新训练2 次和重新训练4 次的精度变化曲线。图6(a)和图6(b)表明当重新训练次数增加时,模型收敛速度越来越快,为此比较本文方案和经典联邦的训练时间,最终本文方案模型收敛的速度比经典联邦模型收敛速度平均提升21.6%。
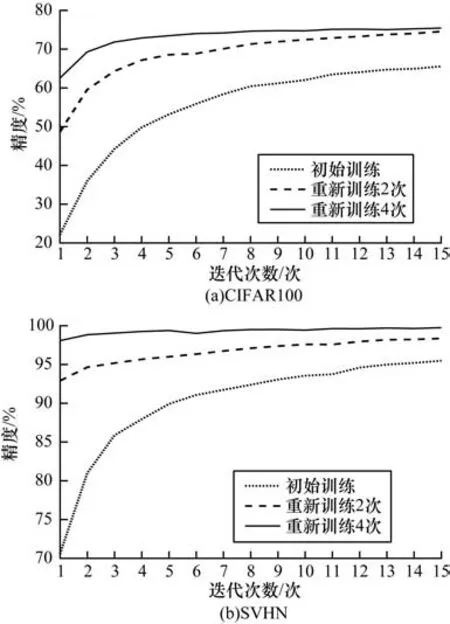
图6 基于重新训练次数的精度比较Fig.6 Accuracy comparison based on retraining times
5.3.2 经典联邦学习与本文方案精度比较
基于CIFAR10、MNIST、CIFAR100 和SVHN 4 个数据集,实验使用2 个模型ResNet18 和GoogleNet 分别进行训练。在实验中,设置系统每个区域有100 个用户,将CIFAR10 训练样本平均分配给每个用户,每个用户得到500 个样本,同时设置该区域的用户本地迭代次数为2 次,全局迭代次数为10 次,重新训练轮数为5 次。将MNIST 训练样本平均分配给每个用户,每个用户得到600 个样本,同时设置该区域的用户本地迭代次数为1 次,全局迭代次数为5 次,重新训练轮数为5 次。将CIFAR100 训练样本平均分配给每个用户,每个用户得到500 个样本,同时设置该区域的用户本地迭代次数为2 次,全局迭代次数为15 次,重新训练轮数为5 次。将SVHN训练样本平均分配给每个用户,每个用户得到730 个样本,同时设置该区域的用户本地迭代次数为2 次,全局迭代次数为15 次,重新训练轮数为5 次。
本文将经典联邦学习方案和本文方案的迭代次数设置为相同的次数,训练CIFAR10 数据集用户本地迭代次数为2 次,全局迭代次数为50 次,训练MNIST 数据集用户本地迭代次数为1 次,全局迭代次数为25 次,训练CIFAR100 数据集用户本地迭代次数为2 次,全局迭代次数为75 次,训练SVHN 数据集本地迭代次数为2 次,全局迭代次数为75 次。
每个终端用户接受1 个预先训练的模型,训练全连接层,同时保留卷积层的参数,对每个测试集的准确性进行评估。经典联邦学习与本文方案的训练精度比较如图7 所示。图7(a)所示为使用模型ResNet18 训练4 个不同的数据集,图7(b)所示为使用模型GoogleNet 训练4 个不同的数据集,由于数据集(MNIST、SVHN、CIFAR10、CIFAR100)之间复杂度不同,因此不同数据集所展示的精度标准是有差异的。从图7 可以看出,本文方案在提升收敛速度和减少训练时间的基础上,达到与经典联邦学习相当的精度。因此,本文方案在保证精度的情况下性能优势更加显著。
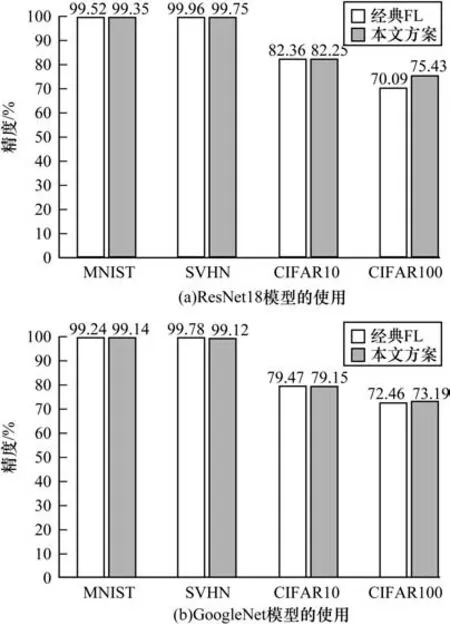
图7 经典联邦学习与本文方案训练精度对比Fig.7 Comparison of training accuracy between classical federated learning and the proposed schemes
6 结束语
本文提出云-边融合可验证隐私保护跨域联邦学习方案,其中训练算法旨在提高联邦学习的稳定性、可验证性和可用不可见性。引入掩码技术和基于向量内积的签名算法来构建可验证的隐私保护联邦学习。算法架构的关键思想是通过区域局部轻量训练来解决异构网络设备计算能力参差不齐的问题,并通过模型权重转发使系统精度与经典联邦学习精度基本相同,在此基础上还提高了模型的泛化性和收敛速度。实验结果表明,该方案在确保梯度模型数据跨域流通的机密性与完整性的同时,保持了与经典联邦学习方案几乎相同的训练精度,并且随着系统各区域训练轮次的增加,模型收敛的速度平均提升了21.6%,具有更优的泛化性。后续将设计基于余弦相似度的检测算法来剔除恶意终端用户,并设计支持在线终端用户退出的系统,从而提高系统的鲁棒性。
猜你喜欢
家庭影院技术(2020年10期)2020-12-14
流程工业(2020年11期)2020-02-28
家庭影院技术(2019年7期)2019-08-27
软件导刊(2018年5期)2018-06-21
长春工程学院学报(自然科学版)(2018年1期)2018-04-20
中国市场(2016年14期)2016-04-28
中国新通信(2016年2期)2016-03-11
当代旅游(2015年8期)2016-03-07
电子技术应用(2015年9期)2015-12-14
俄罗斯问题研究(2013年1期)2013-03-11
