
基于自监督部位感知的行人重识别模型及其在铁路客运站的应用
2024-03-15 10:15李倩
铁路计算机应用 2024年2期
李 倩
(中国铁路兰州局集团有限公司 客运部,兰州 730030)
铁路客运站是连接铁路与旅客的重要枢纽。由于其面积大、结构复杂,旅客在站内候车涉及区域较多,若能自动锁定站内重点人群的行动轨迹,从而为其提供精准帮助,可显著提升铁路客运站内的服务水平和客运管控效率。目前,大多数铁路客运站采用人工监控视频的模式实时跟踪重点旅客,然而,站内旅客数量众多、辨识度低,这种模式不仅费时费力,且易错失处置事件的最佳时机,很难及时阻断相关事件的发生及恶化,亟需研发一种适用于铁路客运站的人员跟踪技术,实现对重点旅客的高效追踪。
依据视觉特征进行行人轨迹跟踪一直是学术界的重点研究方向。该领域早期的算法属于生成式方法[1],即在初始帧中生成目标区域,在后续帧中对目标区域进行搜寻匹配;随后提出的判别式跟踪方式[1],通过区分背景和目标区域,在后续帧中利用算法判定检测框内区域为目标或背景,从而进行跟踪。
在实际应用场景中,行人轨迹跟踪面临的主要问题在于,难以实现跨监控设备的行人轨迹跟踪与匹配。行人重识别算法主要关注同一个体在不同视角下的特征关联性,是实现行人跨场景跟踪的核心技术。近些年来,深度学习迅速发展,越来越多的基于深度学习的行人重识别算法被提出[2-4]。虽然这些算法在计算机视觉领域的公共数据集上均取得了较为不错的成绩,但将其引入铁路客运站后,因人流密集,视频数据中行人被严重遮挡、辨识度低,难以从铁路场景中获取良好的训练数据,导致其跟踪与匹配性能均出现了较大程度的下降。
为此,本文提出了一种基于自监督部位感知的行人重识别模型,有效提升了复杂场景下轨迹跟踪及匹配的性能,实现高性能的铁路客运站重点旅客追踪,将传统的人工检索模式改为智能化模式,显著降低工作人员劳动强度,提升重点事件处置效率和客运服务水平。
1 基于自监督部位感知的行人重识别模型构建
铁路客运站重点人员跟踪的核心是解决不同监控设备中的跨域特征匹配问题,即要求所用的网络模型针对不同场景下的同一个目标,提取出尽可能相似的特征,计算机视觉中将这类问题统称为行人重识别。本文提出的基于自监督部位感知的行人重识别模型架构分为自监督部位感知预训练和行人重识别迁移学习两个部分,如图1 所示。
1.1 自监督部位感知预训练
从人类的通常视角来看,行人外观特征由体型、穿着、随身物品等明显特征,以及发型、人脸、配饰等精细特征构成。这些特征的基本单元是人体的各个部位(头、躯干和四肢等)。
自监督部位感知预训练旨在通过大量无标签的行人数据集对模型进行预训练,通过设置对比任务,利用样本自身信息差作为监督信号,训练得到具有良好视觉理解能力的模型。
本节先介绍自监督部位感知预训练的网络架构,再介绍其网络的优化过程,即损失函数设计。
1.1.1 自监督部位感知预训练网络架构
自监督部位感知预训练部分的网络架构如图1(a)所示。
(1)对输入样本x进行不同方向上的特征增强,形成增强样本对 (m,n);对样本对进行随机掩码和背景掩码,形成随机掩码样本对 (mR,nR) 和背景掩码样本对 (mA,nA),以此构建样本自身的信息差。
(2)采用知识蒸馏的思路,从样本的信息差中训练获得泛化性的行人视觉特征;采用ViT(Vision Transformer)[5]架构构建学生网络S和教师网络T,学生网络S只接收随机掩码样本对 (mR,nR),教师网络只接收背景掩码样本对 (mA,nA)。
(4)通过构建损失函数,形成教师网络T到学生网络S的知识蒸馏,使得预训练获得较好的视觉特征提取能力
(5)最终,在教师网络T的指导下,学生网络S在特征域上对随机掩码的样本进行特征补全,并获得对行人身体部位的感知能力。
1.1.2 网络优化
自监督部位感知预训练网络优化的目标是最小化总体损失函数Lpre,可将其分为身体部位位置特征的损失函数Lpatch和身体部位语义特征损失函数L[PART]两个部分。
学生网络S对随机掩码的样本在特征域上进行重建,身体部位位置特征的损失函数Lpatch公式为
教师网络T和学生网络S均先将输入样本切分为N个图像块,Lpatch计算了N个图像块的损失值之和,用于反向传播更新网络的权重,(mA,nR)为增强样 本对 (m,n) 经过不同方式掩码的结果;T(·)、S(·)分别代表教师网络T和学生网络S的特征提取过程;为教师网络T中身体部位位置的投射过程。是将mA图像拆分为N个图像块之后的第i个子图像块;θi为每个子图像块的位置编码。
身体部位语义特征损失函数L[PART]公式为
本文所构建的自监督部位感知预训练网络可视为对两个损失函数的优化过程,则总体损失函数Lpre为
综上,本文借鉴掩码学习的思路,从遮蔽的图像块中恢复连续的行人特征,使网络对场景中存在遮挡、不完整的行人特征有一定的联想重建能力;通过指定目标行人特征的构成,学生网络S可主动忽略行人身处不同背景的干扰;通过区分不同区域对应的身体部位语义特征,可实现行人身体区域的划分,从而学习到不同部位的区别性语义,丰富行人特征匹配的信息维度。
1.2 行人重识别迁移学习
由自监督部位感知预训练学习到行人的精细化特征后,进一步进行行人重识别迁移学习,从而实现复杂场景下的行人轨迹匹配功能。将预训练好的学生网络S作为视觉特征提取模块,经过相应的投射层,提取样本的行人重识别特征,如图1(b)所示。确定学生网络S的参数,在行人重识别数据集上对patch和[PART] 特征投射层的参数进行微调,输入样本x的行人重识别特征ReID(x) 可表示为
式(4)中,“◦”为特征拼接操作,即通过对[PART]特征和patch特征进行拼接,构建行人重识别特征的表达。
使用三元组损失函数作为行人重识别迁移学习的损失函数,目的是在最小化输入样本x到正样本xP间的特征距离的同时,使得输入样本x到负样本xN之间的距离最大。三元组损失函数Ltri的公式为
式(5)中,ρ 为设定阈值;d(·) 为ReID 特征间的欧氏距离。
2 模型性能分析
2.1 实验数据
(1)选择LUPerson 大规模行人数据集作为自监督部位感知预训练数据集。LUPerson 数据集包含4.18 兆张行人图片,排除遮挡过于严重的图片,并统一将输入图像缩放至256×128 像素。
(2)使用行人数据集Market-1501[5]、MSMT17[6]和Occluded-Duke[7],进行行人重识别模型的迁移学习和验证,并基于Occluded-Duke 行人数据集验证算法对部分遮挡的行人特征的重建能力。其中,Market-1501 行人数据集包含32 668 个图像样本,共1501 个行人;MSMT17 行人数据集包含126 441 个图像样本,共4101 个行人;Occluded-Duke 行人数据集包含15 618 张行人图像样本,是专门为研究遮挡行人重识别而搜集的数据集,最为符合铁路客运站的重点人员追踪场景。
2.2 实验配置
本文使用了不同规模下的ViT 和Swin Transformer(Swin-T)架构[8],将其作为本文模型的主干网络。其中,ViT 架构采用了ViTSmall/16(ViT-S)、ViT-Base/16(ViT-B)两种不同规模;Swin-T 模型的滑窗大小为7×7;patch及[PART]投射层由3 层多层感知机(MLP,Multi-Layer Perception)与L2-正则化共同组成;行人重识别迁移学习的三元组损失函数的超参数 ρ 设置为0.25。
2.3 性能比较
将本文设计的基于自监督部位感知的行人重识别模型与MGN(Multiple Granularity Network)、TransReID、TransReID-SSL 等3 种通用行人重识别模型模型在不同主干网络和数据集下的方法性能进行比较。采用平均精度mAP 和准确率R1 对模型的性能进行评价,具体的实验结果如表1 所示。
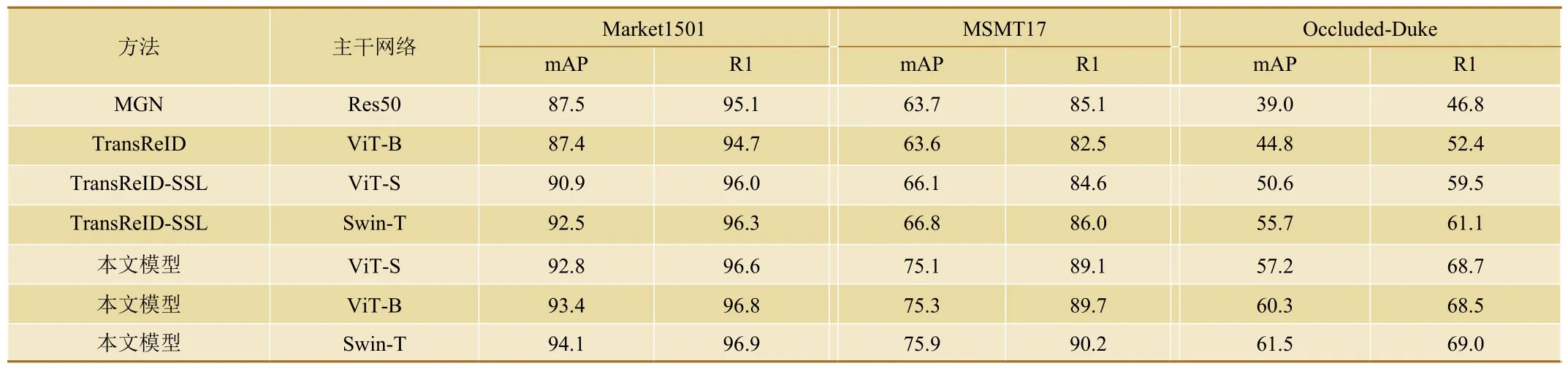
表1 不同模型的试验性能结果
由表1 可知,本文模型在3 个数据集上的性能均高于对比的通用行人重识别模型。为验证本文模型在铁路客运站旅客密集、行人被频繁遮挡场景中的应用效果,使用了行人重识别数据集中针对遮挡问题而构建的Occluded-Duke 数据集。从表1 中的结果可看出,MGN 模型的平均精度不足40,其他模型均表现欠佳,本文模型仍在一定程度上受行人被遮挡的影响,但其基于部位感知的自注意力机制,学习到了行人不同部位的区别性语义,并通过特征重构,获得了一定的特征联想能力,在Occluded-Duke行人重识别数据集上的mAP 性能指标超过60,在基于Swin-T 主干网络的情况下,本文方法的R1 值接近70%。
3 现场试用
将本文研究的行人重识别模型应用于铁路客运站重点人员跟踪,并在中国铁路兰州局集团有限公司白银南站试用。白银南站位于甘肃省白银市内,建筑面积9999.73 m2,最高聚集人数为1500 人,站台规模为3 台7 线。
在白银南站进站安检区域人工圈定需要关注的重点人员,如65 岁以上的旅客,并对其进入候车厅到检票口离站期间的行动轨迹进行实时跟踪,同时展示跟踪轨迹流线图,如图2 所示。
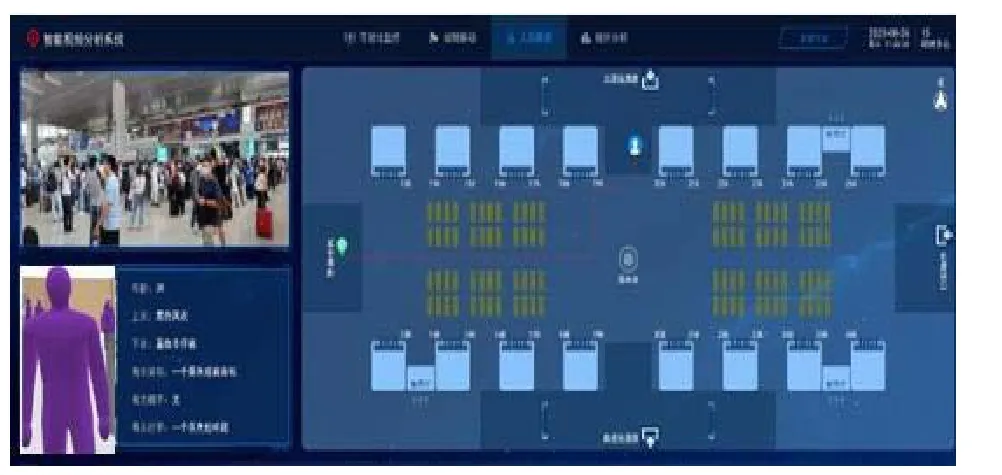
图2 重点人员跟踪界面
图2 中,通过3 个部分展示了重点旅客在铁路客运站内的全流线轨迹,右侧部分为白银南站候车大厅布局图,在该图中实时展示重点旅客的行进轨迹;左侧上部为该重点旅客的实时视频;左侧下部为在安检区域圈定的重点旅客肖像图及相关特征属性。本文模型在白银南站的试用效果良好。
4 结束语
本文提出了一种基于自监督部位感知的行人重识别模型,并根据该模型对铁路客运站的重点人员进行实时跟踪,经试验验证,该模型可在遮挡较为严重的铁路客运站场景下实现精确率较高的行人跟踪。下一步,将研究如何结合空间信息,更好地提升跨域跟踪的精准度。
猜你喜欢
意林(2021年5期)2021-04-18
工程与建设(2019年3期)2019-10-10
通信学报(2019年5期)2019-06-11
扬子江(2019年1期)2019-03-08
减速顶与调速技术(2018年4期)2018-08-27
通信技术(2018年3期)2018-03-21
小天使·一年级语数英综合(2017年6期)2017-06-07
广东石油化工学院学报(2016年6期)2016-05-17
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
