
考虑中转的集装箱码头多资源集成调度
2024-03-12 08:59:04王晓光王宏宇刘博宇
计算机工程与应用 2024年5期
王晓光,王宏宇,刘博宇
1.上海海事大学物流科学与工程研究院,上海 201306
2.上海立信会计金融学院工商管理学院,上海 201209
全球集装箱航运网络呈轮辐式结构,转运港作为航运运输网络的关键节点,在全球供应链中发挥着重要作用,负责长途服务的干线船舶(母船)与负责连接周边小型港口的船舶(支线船)通过转运港码头进行集装箱转换[1]。先到港的船舶将集装箱暂存于码头堆场侧,等待后续船舶装载出港。然而新冠肺炎疫情突然暴发,暴露了枢纽港管理的系统性问题,如码头资源分配不均、船舶装卸作业时间增加等。这些问题不仅影响到枢纽港的整体运行效率造成港口拥堵,同时阻碍了船舶间转运作业的顺利进行,对全球贸易发展造成不利影响。
随着新冠肺炎疫情的持续传播,枢纽港码头管理变得越发复杂,导致码头规划混乱。学者们对如何提高港口运营效率进行了深入研究,主要方法包括码头泊位、堆场调度以及规划船舶到港时间。本文收集了相关研究并对相关文献进行了比较分析。
码头资源分配主要包括战术泊位分配与战术堆场分配。由于泊位和堆场分配相互影响,近年来泊位-堆场等一体化规划正在兴起。Wang 等[2]开发了一种同时优化泊位和堆场决策的列生成算法,提出结合泊位、码头起重机和堆场存储空间三种资源分配的集成优化问题。Guo等[3]研究了堆场和泊位分配之间的多期相互作用,设计了一种禁忌遗传算法以获得来访船舶的靠泊位置和出口集装箱的堆场存放位置。韩笑乐等[4]针对战术层面的泊位—堆场资源联合分配问题,提出不确定性环境下的鲁棒性模板决策,通过松弛时间的启发式调整规则优化启发式算法,为集装箱码头多资源协同分配提供了有效决策思路。针对泊位和堆场进出口同步作业协同分配(BYCA-ⅠESOs)问题,Li 等[5]提出基于计算物流同步或异步集成调度策略的BYCA-ⅠESO 研究模型,通过实验结果的分析,验证了模型和策略的可行性。郭文文等[6]分析了出口箱装船过程中泊位与堆场分配的相互影响关系,建立了以集卡行驶路径最短为目标,以停靠泊位、出口箱堆存位置及堆存在子街区的数量为决策变量的泊位与堆场协调分配模型,并设计了禁忌遗传算法求解。
伴随着研究的不断深入,学者们发现平衡船舶的到港时间对泊位分配具有重要意义,可以避免同时段到达船舶过多造成泊位拥堵,于是将时间窗约束引入研究中。De等[7]引入时间窗口约束限制船舶到达时间,并提出考虑调度、路径约束、装卸约束和船舶约束的混合整数非线性规划模型,最后通过粒子群优化-差分进化算法(PSO-DE)求解,提高了港口服务水平。随后提出了一个考虑时间窗口概念的新型可持续船舶航线问题,并提出一种新的粒子群优化算法(BVNS-PSO)对其进行求解[8]。Jiang 等[9-10]提出通过结合港口时间窗口来解决班轮航线和船期设计同时优化的问题,构建了混合整数非线性模型,将其转化为整数线性优化模型进行求解得到最佳船舶到港时间,缓解了港口拥堵。
此外,为提高码头作业效率,集装箱装卸和转运作业也受到学者们的广泛关注。Liu等[11]定义了两种船舶间转运模式,即直接转运模式和间接转运模式,并设计了一种双目标方法解决集装箱码头综合规划复杂的问题。Emde 等[12]考虑直接转运模式,特别关注到支线船和母船之间的集装箱交换,通过支线船的码头空间和服务时间分配,实现支线船舶交付的集装箱数量不超过母船给定上线。常祎妹等[13]建立了以装卸总完成时间最短为目标的混合整数规划模型,考虑了装卸同步等现实约束和集卡堵塞问题,设计了改进的多层遗传算法求解模型。唐梦宇等[14]采用滚动窗策略方法研究转运进口集装箱作业问题,并建立了以列车在港停留时间和集装箱在堆场的堆存时间最小为目标的整数规划模型,结果表明,增加装卸线数和轨道起重机工作能力可以提高集装箱转运效率。
然而,很少有研究考虑到中转港船舶间的集装箱转运服务,以及船舶间转运服务对码头作业效率的影响。特别是新冠疫情爆发以来,港口拥堵、船舶在港外排起长队的新闻屡见不鲜,随之带来的一系列连锁反应暴露了船期表、转运流量以及码头资源的相互关联性[15-16]。基于此,本文以枢纽港集装箱码头为背景,研究码头多资源集成调度,并综合考虑船舶间转运流管理、船舶服务时间分配、泊位调度和堆场分配因素的内在联系,进行多资源协同优化,旨在高效利用码头资源,实现码头集装箱转运作业时间最小化。
1 问题描述与建模
1.1 多资源集成调度问题
码头运营商的一个主要决策是到港船舶的时间安排,由于母船有更高的泊位权且到港时间稳定,所以码头运营商时间调度主要是遵循母船工作时间请求,设计支线船服务时间表。支线船舶服务时间表需要满足两点要求,第一,周期内支线船对母船有转运需求时,支线船要早于母船到达泊位或与母船同时到达泊位。当母船对支线船有转运需求时,支线船最晚在下一个周期结束前将堆场内货物运出,避免堆场集装箱积压。如图1所示,当母船1 对支线船1 有转运需求但支线船本周期服务时间已过时,支线船需要在下一周期同一班次到港时将转运流货物运出。第二,调整船舶的停靠时间以平衡码头的工作量。一方面船舶服务时间最好在周期内呈均匀分布。另一方面船舶靠泊时间决定了周期内同一时段堆场内集装箱转运流量的多少,这与泊位和堆场模板设计紧密相连,而良好地泊位和堆场规划可以有效管理集装箱转运流,提高码头整体作业效率。船舶服务时间表设计周期为1周,每8小时为一个工作班次,共包含21 个工作班次,支线船在每个周期内按照规定时间服务,服务班次一旦确定,在整个规划期内不能轻易更改。
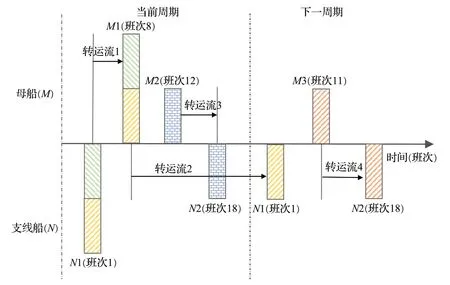
图1 船舶服务时间的说明性示例Fig.1 Ⅰllustrative examples of ship service hours
码头运营商的另一个主要决策为空间规划,即为转运船舶规划停泊位置,对船舶间转运流进行管理(母船和支线船间进行转运的集装箱被称为“转运流”),确定转运流货物在堆场停留期间的存储区块。由于转运流方向不同,在同一节点或路段运输时存在相互干扰,导致堆场存在多转运服务拥堵的情况[17]。所以,通过调整船舶的停泊位置和集装箱的堆场存储区域来均衡堆场内的转运流,实现同时均衡转运流、泊位和堆场分配。此外,堆场发生多业务拥堵时,最短路径可能不是最有效的运输路径,支线船的停泊位置和堆场的存放区域由最小化转运流集装箱的运输时间确认。为了更直观地构建码头多资源分配数学模型,本文将船舶间集装箱运输看作如图2所示的节点-网络图,其中堆场块节点为单向节点,码头泊位节点为双向节点,车道节点分为垂直节点和交叉节点,其中交叉节点为双向节点。
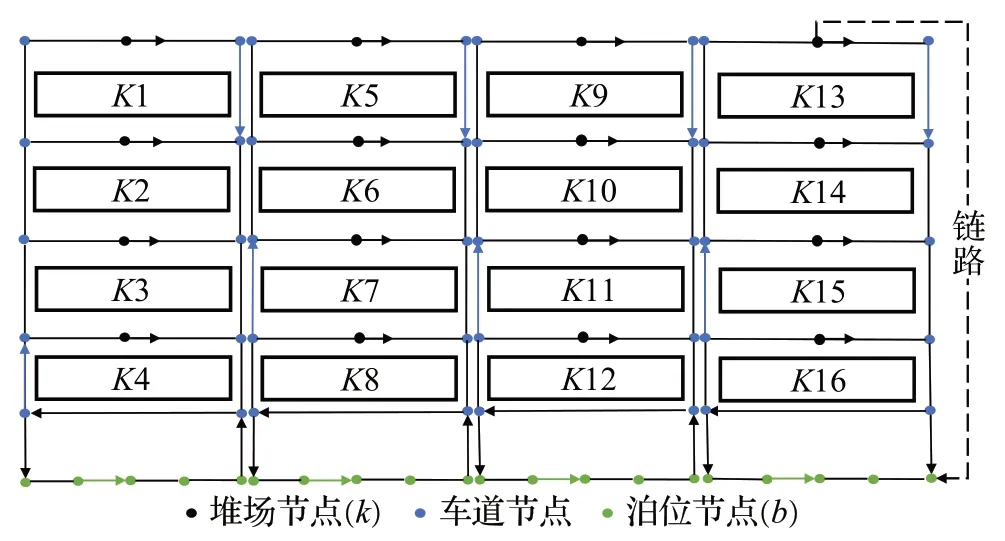
图2 码头集装箱运输节点-链路图Fig.2 Terminal transportation node-link diagram
1.2 模型构建
(1)假设
①由于母船装卸作业量大,优先停靠在主泊位;
②码头运营商在班轮公司给定的船舶可用时间窗内可以决定支线船的停靠时间。
(2)参数设置
本文的符号定义如表1~表3所示。

表1 集合符号定义Table 1 Collection of symbols definition

表2 参数设置Table 2 Parameter setting

表3 0~1变量说明Table 3 0~1 variable description
(3)模型构建
在周期h内转运流F对应的装卸路线是确定的,其中泊位节点集合B以i为索引,堆场块节点K以j为索引,运输路线表示以(i,j) 为索引,装卸时间为tij。假设共享路段(i,j) 上转运服务数量为gh,考虑到共享路段多条转运流之间相互干扰对堆场运输造成影响。本文改进了Zhen[18]提出的基于概率的堆场拥堵公式,构建了集装箱运输时间受共享链路多转运流同时服务影响的预期行程时间公式,决策变量为共享节点或链路中同时作业的转运流数量。将tij(c)定义为链路(i,j)上发生了c次运输中断,预期行程时间tij如式(1)所示,式(2)定义为链路(i,j)发生c次运输中断的概率Pij(c)。
式(3)中cˉ是受转运流量影响造成多服务拥堵的平均次数,式(3)、(4)中a表示卡车运行时的加/减速度;lii表示链接(i,j)的距离;hi,j表示链路(i,j)中的通道数;Ey表示堆场起重机处理单元集装箱的平均时间长度;v表示堆场卡车的正常速度;和分别代表卡车在链接间的初始速度和终止速度,综上转运流f在链路(i,j)上的预期行程时间为式(5):
其中,式(6)、(7)中的参数已知,式(6)的决策变量为gh,即路段( )i,j上的转运流干扰程度影响集装箱转运流作业时间。但gh受码头运营商船舶服务时间、泊位和堆场分配的共同影响,所以可以通过调整码头决策实现最小化预期链路行程时间。在不考虑转运流量过大造成的堆场拥堵时,码头决策受船舶到港时间和码头容量限制,但堆场拥堵情况下,转运流的管理受泊位和堆场块的具体分配影响。
目标函数:
式(8)是模型的目标函数,表示为母船到支线船的装卸时间和母船到支线船的装卸时间之和。
约束条件:
式(9)表示每条转运流货物需存放在同一堆场存储块,不能拆分到多个堆场存储区域,式(10)和(11)分别表明每艘船只在一个泊位停泊。
式(12)表明船只在一个周期内只停靠一次。式(13)表明当支线船对母船有转运需求时,与转运流相关联的支线船应比母船更早或同时到达。式(14)表明,任何时期的转运流量都不应超过分配货场区段的能力上限。式(15)表明,任何时期的总集装箱工作量都不应超过总泊位工作量的上限。
式(16)和(17)表明转运流集装箱在堆场停留时间不超过一个周期,确保货物在周期内装上到港或离港船舶。
式(18)、(19)、(20)表明当转运流货物对母船有转运需求时,转运流早于母船的到港时间提前到达港口,同时对决策变量δft进行约束。
2 基于禁忌搜索的人工免疫算法设计
由于本文设计的模型是非线性整数规划模型构造复杂,一些商用求解器(例如CPLEX 求解器)很难直接求解,所以针对该问题选择采用元启发式算法,一些元启发式方法经常用于解决与本文类似的港口、码头优化问题,例如,人工免疫算法(ⅠA)。然而人工免疫算法在求解优化过程中存在“早熟”问题,为克服早熟现象,提高算法的全局收敛性、稳定性和寻找极值点能力,本文基于人工免疫算法,借鉴禁忌搜索算法的机制,提出基于禁忌搜索的人工免疫算法,在算法中引入禁忌搜索程序以丰富解决方案的多样性。
2.1 编码
本文设计的人工免疫算法中,抗原表示上述的码头规划问题,抗体表示针对该问题的决策方案。本文通过所构建的模型进行编码求解。以随机生成的方式,生成一组初始抗体组,每个抗体包含子船及所连接转运流的堆场、泊位和服务时间窗决策。
(1)抗体与抗原的亲和度计算
抗体亲和度是通过计算期望繁殖率对抗体质量进行评价,期望繁殖率越大则被选中的概率越大。本文设候选抗体为σ,全部种群数量为N,抗原亲和力与抗体亲和力分别为A(σ)与C(σ),则该抗体的期望繁殖率为式(21):
变量ε用于确定A(σ)与C(σ)的各自权重,两种亲和力相互拮抗既能使得高适应度的个体繁殖,又能保证种群的多样性。式(22)为抗体亲和力计算公式,f(σ)代表目标函数值,抗体的亲和力越大,目标函数值越小。
(2)抗体浓度计算
抗体浓度反映了抗体之间的相似程度,浓度越高则说明抗体相似度越高,种群的多样性越低。通过平均信息熵来衡量个体间差异,拥有L个基因的染色体每个基因的信息熵H(a) 计算如式(23)所示:
式中,a为抗体个数,表示a条抗体的平均信息熵,一般取值为2。式(24)中pji是j出现在i位点的比率,pji=(the total number ofjth symbols oni)/a
(3)抗体相似度与抗体浓度计算
本文采用R位连续方法计算抗体之间的亲和力,即对于抗体x与y,若二者的编码有超过R位相同,则表示这两个抗体近似“相同”,否则表示二者不同,构造逻辑判别函数如下:
式(25)、(26)中,Hσ,μ( 2 )表示σ和μ两条染色体的平均信息熵,为了计算抗体相似性,本文引入中间变量S(σ,μ),其中L为抗体的长度,k表示抗体σ与抗体μ中相同的位数,R代表亲和度的阈值,S为抗体是否“相同”的逻辑判别。抗体浓度本文用C(σ)表示,指群体中与抗体σ相似的抗体数量的比率,对于抗体x,若设全部种群数量为N,则其抗体浓度为公式(27):
2.2 免疫操作
免疫操作基本原理是在解集中选择抗体进行变异操作,指改变染色体上的一个或多个基因,得到亲和力更高的染色体,并在迭代过程中逐渐逼近最优解的过程。免疫操作具体包括选择操作、交叉操作和突变操作。本文通过轮盘赌法进行抗体选择,即抗体σ被选择留下的概率为Pσ,且σ的预期繁殖率E( )σ越高,被选中的概率Pσ越大,计算公式如下:
变异操作是相邻抗体信息交互的重要步骤,以确保全部种群中优秀基因被长期保存。对于每次迭代操作,种群进行随机配对并进行统一的交叉操作。给定交叉参数ρ和0 到1 之间的随机数r,若r≤ρ,则执行交叉操作。由于抗体包含三个决策,所以具体操作为随机选定一个位点,交换该位点对应的三个基因。变异操作是保持种群多样性,避免“早熟”的重要手段,除了位点选择后的基因会产生突变外,其他与交叉操作相同。
2.3 基于禁忌搜索的免疫突变操作
避免算法陷入“早熟”的同时提高搜索效率,本文在抗体突变过程中结合禁忌搜索程序来改进后代个体,扩大抗体群种类。首先,通过邻域搜索随机选择抗体的某个因素替代后生成邻域解。在禁忌迭代过程中,若邻域解中的最优解亲和力高于原解,则原解被更优的邻域解替换,反之则保留原解。图3 展示了邻域解的生成过程。如图所示,通过邻域搜索随机选择左侧原解中的某个因素变异后生成右侧的邻域解。原解Gene3中Y5突变为Y6 后生成第一个邻域解,同样方式,在突变T1次后,共生成T1个邻域解。本文将邻域解中最佳方案与原方案更换元素的位置记录在禁忌列表中,遵循先进先出的规则进行存储,记录在紧急列表中的元素不再进行变异。禁忌列表长度设置为T1,当最佳解决方案通过最高迭代限度C次后没有得到改进,则禁忌搜索过程终止。
2.4 算法编码过程
算法的具体编码及数据处理过程如下所示。
算法1基于禁忌搜索的人工免疫算法

3 数值实验与方法评估
3.1 案例研究
为了评估综合规划方法在解决实际的问题时的求解效果,本文基于上海港最大的集装箱码头上海盛东国际集装箱码头(SSⅠCT)生成实验案例。SSⅠCT是位于上海东南部洋山岛上的洋山深水港(YDP)的一部分,拥有3 000 m 长的直线型码头和15 公顷的集装箱堆场,每个月为550多艘深海和支线船提供服务,平均吞吐量为45万标箱[19]。在此基础上,本文生成集装箱码头仿真案例,头堆场布局如图4 所示,码头全场3 000 m,最多有8 个泊位48 个堆场存储区,堆场横向和纵向超车道的宽度分别设置80 m和30 m,泊位到堆场区域距离为55 m,每个堆场存储块容量为1 200 TEU[11]。该码头所有堆场和泊位空间均可服务于到港的船舶及转运流,本文在船舶服务时间的约束下随机生成船舶间转运流方向及数量,并施加了转运流总数限制,与母船相关的转运流不超过六条,支线船则不超过三条。每条转运流的集装箱量在100 到500 间呈均匀分布,每条转运流存放在同一堆场存储区块,此外,模型结合相关研究[18],其他参数设置如表4所示,表中数据均源于上海港专家研究的数据估算结果[20-21]。其中泊位处理能力实际上取决于船舶数量、船舶类型、分配的码头起重机数量等,本文侧重战术规划仅施加限制每个泊位处理的最大集装箱数量。

表4 模型参数设置Table 4 Model parameter setting
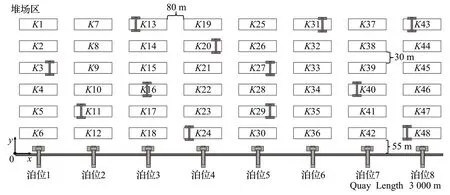
图4 码头实验平面图Fig.4 Terminal experimental plan
3.2 算法评估
为了验证本文提出的基于禁忌搜索的人工免疫算法(TS-ⅠA)解决问题的能力,本文采用当前求解效果较好且具有一定公信力的两种启发式算法,遗传算法(GA)、人工免疫算法(ⅠA),进行算法对比实验。这两种算法广泛应用于各类研究中,Junqueira等[22]研究了集装箱搬迁和港口码头装卸船舶通港的联合规划问题,并应用模拟遗传算法描述了一种优化方法,测试结果表明,能够在6 min 内解决上百个集装箱分配实例给出有效优异的集成方案。Wu 等[23]提出了解决自主水面车辆(ASV)需要遵守拥挤海域海上避碰规则的问题,并设计了一个改进的遗传算法进行的仿真研究,结果表明,提出的智能遗传算法可以有效避让与其他船只碰撞。刘刚[24]将堆场装卸作业时间成本和堆场空间成本作为优化目标,并采用贪心算法改进遗传算法并和原来的遗传算法作对比实验,有效证明了改进后具有较好的效果。程玉龙等[25]与遗传算法做对比,来证明提出的免疫遗传算法对个体的选择和评价更为全面与合理。Xu等[26]在研究中提到免疫算法已被证明在许多实际优化问题中是有效的,具有高效的收敛性和搜索效率。上述各研究均表明,用遗传算法和人工免疫算法做为对比实验算法是具有一定公信力且求解结果较好的算法,在解决相关问题上具有一定的优越性和有效性。
基于文献中所提到的遗传算法和人工免疫算法思想,本文针对码头多资源集成调度问题设计了具体的两种智能算法,进而作对比实验。两种智能算法与基于禁忌搜索的人工免疫算法(TS-ⅠA)共进行了6组不同规模的实验,实验数据如表5 所示,其中Set1 和Set6 分别为最小和最大规模实验。以Set6为例,表示该码头每周有30艘母船和50条支线船(21个工作班次)和110条转运流到访码头。本文通过3 个维度对比了3 种算法的性能,对比结果显示TS-ⅠA 的求解质量、迭代效率和鲁棒性均高于其他两种启发式算法。
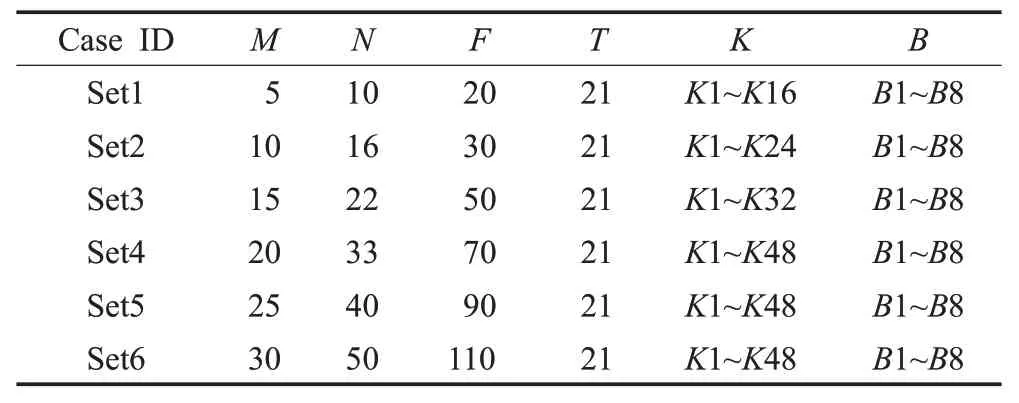
表5 实验案例参数设置Table 5 Experimental case parameter setting
(1)算法的求解结果比较
本文将TS-ⅠA 算法获得的目标函数值对比其他两种算法,表6分别为三种算法在不同规模实验中的结果比对。由于算法的计算过程具有随机性,所以选取6组不同规模案例,每个案例运行10次取最优值如2.4节的代码所示。三种算法在进行小规模Set1 实验的对比结果表明,ⅠA 与TS-ⅠA 的目标函数值相近目标函数差3.8%左右,但GA的目标函数值与前两种算法差距更大为9.87%,所以在进行小规模实验时TS-ⅠA算法最优,ⅠA算法优于GA算法。随着实验规模增大,母船和支线船数量增多,转运流数量增大,三种算法间的目标函数值差距明显增大。TS-ⅠA 的求解结果在大规模实验中依旧优于其他算法,而GA 求解结果则优于ⅠA 的目标函数值。
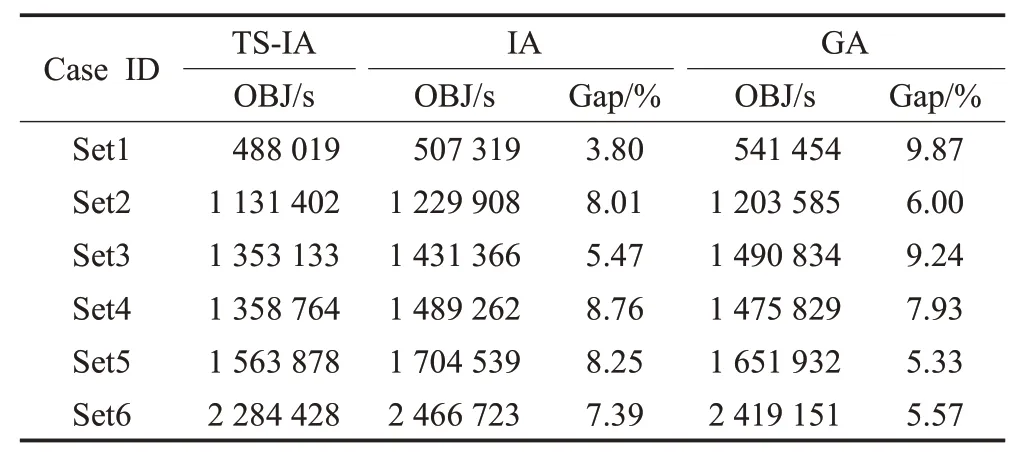
表6 三种算法目标函数值对比Table 6 Comparison of objective function values of three algorithms
(2)算法的性能比较
为进一步展现TS-ⅠA算法的性能优势,本文以Set6的大规模实验案例为例,对三种算法进行了收敛效率比较。如图5所示,GA和ⅠA分别在第154代和第112代收敛,但是本文提出的TS-ⅠA 算法仅需58 代即可收敛,比起其他两种算法具有过好的收敛效率。
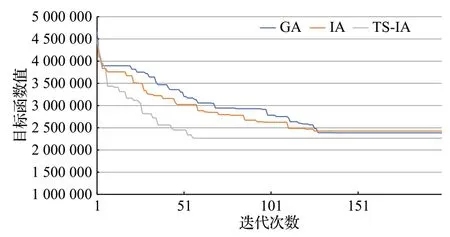
图5 算法迭代图Fig.5 Algorithm iteration
(3)算法的鲁棒性比较
算法的鲁棒性是以波动率为标准判断算法的稳定程度,即反应初始值逼近最优解的程度,初始值越接近最优解,波动率越小,鲁棒性就越好,反之波动率越大,鲁棒性越差,式(29)为波动率的计算公式:
式中,Vol 表示算法的波动率,Navg表示算法的平均值,Nopt表示算法的目标函数值。如图6所示,GA的波动率在8.98%到21.73%之间,ⅠA 的波动率在4.44%到14.06%之间,而TS-ⅠA的波动率在3.03%到6.28%之间,平均值为4.81%,相比其他两种算法,TS-ⅠA 波动率最小,鲁棒性最好。
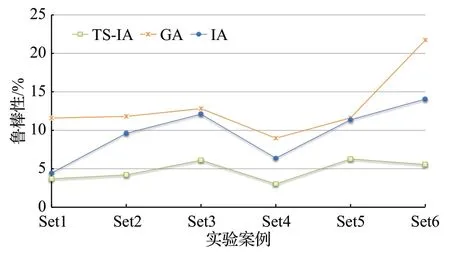
图6 算法鲁棒性对比图Fig.6 Comparison chart of algorithm robustness
3.3 情景分析
为了验证集成调度方法的有效性,设计了三种不同情景决策规则进行对比,决策规则如下:
情景1本文提出方法,集成优化船舶服务时间、船舶间转运流、泊位模板和堆场模板;
情景2不对船舶间转运流进行管理,即转运流货物在堆场的存储区域是固定的,仅进行泊位模板优化和船舶服务时间分配;
情景3指定船舶靠泊泊位,对船舶服务时间和船舶间间转运流进行管理,即分配转运流在堆场的存储区域和船舶服务时间;
情景4船舶服务时间固定,集成优化船舶间转运流的堆场模板和船舶靠泊的泊位模板分配。
本文通过与上述六组实验规模相似的算例进行对比分析,表7 显示了不同情景下目标函数值的大小区别,可以看出本文提出的多资源协同规划方法,无论处理小规模还是大规模问题,求解结果均优于其他情景。
4 结语
本文得到的主要结论如下:
(1)提出了考虑中转的码头集成调度方法,解决了船舶间转运作业、船舶服务时间分配和码头作业规划关联决策的综合性问题,设计了基于禁忌搜索的人工免疫算法进行求解,并利用算例和情景对比实验证明了模型算法的有效性。
(2)其次,贴合实际情况对转运流分配造成的堆场多服务拥堵情况进行量化分析,构建了一个充分考虑码头转运作业相关因素的混合整数规划模型,创新地实现了集装箱转运流的分配平衡、船舶靠泊泊位及服务时段资源分配的平衡,避免港口拥堵。
(3)最后,不同情景的对比实验结果表明,与其他决策方案相比,集成调度模型在预期行程时间上最小缩短4.33%,最大缩短20.19%,可以显著缩短集装箱转运作业时间,提高作业效率,缩短船舶等待时间。
低碳航运是未来港航物流研究的主要问题之一,未来可以在研究中考虑低碳元素,着重码头作业与低碳航运的关系,并采用具有更强鲁棒性的新型智能算法或混合算法进行求解,实现码头资源利用最优化、碳排放量最小化。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17 06:25:50
智能建筑电气技术(2022年2期)2022-02-06 02:30:50
民用飞机设计与研究(2020年4期)2021-01-21 09:15:32
运筹与管理(2019年1期)2019-02-15 09:26:42
中国军转民(2017年9期)2017-12-19 12:11:30
中国工程咨询(2017年11期)2017-01-31 02:58:32
四川电力技术(2015年5期)2015-12-19 11:04:52
哈尔滨工程大学学报(2015年6期)2015-06-24 13:30:59
发明与创新(2015年17期)2015-02-27 10:38:55
集装箱化(2014年12期)2015-01-06 18:31:36
