
自动驾驶路径优化的RF-DDPG车辆控制算法研究
2024-03-09 04:53焦龙飞谷志茹舒小华王建斌
湖南工业大学学报 2024年1期
焦龙飞,谷志茹,舒小华,袁 鹏,王建斌
(湖南工业大学 轨道交通学院,湖南 株洲 412007)
1 研究背景
目前,自动驾驶技术是人工智能领域的研究热点之一,而路径跟踪控制是自动驾驶系统中的核心问题。路径跟踪控制的目标是让车辆按照预定的路径行驶,并且尽可能地接近预定运行轨迹。路径跟踪控制方法主要分为基于模型和基于非模型两类。其中,基于模型的路径跟踪控制方法主要依赖于车辆的运动学和动力学模型,通过控制器输出控制信号来控制车辆运动,常见的基于模型的控制方法包括比例-积分-微分控制(PID 控制)[1-5]、模糊控制[6-12]、模型预测控制(model predictive control,MPC)[13-19]等。基于非模型的路径跟踪控制方法则不需要准确的车辆模型,而是通过感知和决策模块来实现控制,基于非模型的控制方法常见的是基于神经网络的控制方法[20-23]等。
已有研究中,针对自动驾驶车辆在行使中对目标路径跟踪精度不高、鲁棒性能较差等问题,研究者们从基于模型的算法中寻找解决方法。如文献[3]提出了一种基于车辆运动学和动力学的模糊自适应PID控制方法,该方法根据预览理论规划下一个行驶路径。其首先利用车辆质心与所需路径预览点之间的位置关系计算横向偏差和航向偏差,然后利用模糊自适应PID 控制器对误差的调整作用调整前轮角度。该方法虽然简单易行,但是在高要求控制场合的适应性和控制精度有限。文献[6]提出了一种基于动态双点预瞄策略的横纵向模糊控制方法,通过模糊控制来动态控制双点预瞄距离,进而控制车辆跟踪相应轨迹,但是模糊控制的效果受预瞄距离的改变影响较大。文献[11]提出了一种基于横向误差和航向误差的复合模糊控制方法,该方法通过指定相应的权重变量来调整两个模糊控制器的输出,采用积分补偿解决传统模糊控制稳态精度较低的问题。但是该方法在复杂道路中的路径跟踪精度较差。文献[14]提出了一种采用线性时变模型预测控制进行车辆轨迹跟踪的控制算法,相比于非线性控制,该方法具有全局最优解,且计算量更小。然而,该方法对车辆的建模要求较高,对非线性系统需要进行线性逼近,并且需要构造二次成本函数。同时,该方法对硬件存储空间和计算能力的要求较高,需要适当考虑计算资源的限制。文献[15]提出了建立模型预测控制和非线性动力学鲁棒控制(MPC-NDRC)框架,以提高轨迹跟踪性能。MPCNDRC框架分为两个阶段:一是构建预测模型控制器,防止在线计算复杂模型带来的实时性能较差的问题;二是创建基于非线性动力学的鲁棒控制器,确保轨迹跟踪性能和控制器模型精度。虽然该控制算法能稳定地跟踪路径,但是系统过于复杂,稳定性能较差。文献[20]采用了神经网络和模糊控制相结合的方法,通过控制方向盘转角来控制车辆的行驶方向,该方法的控制效果较为稳定,但是存在转向控制不够及时和跟踪误差较大等问题。
基于模型的控制算法在路径跟踪中需要依赖车辆模型,而车辆建模是一个复杂的过程,不仅需要考虑机械结构、动力学特性、控制策略等多方面因素的影响,还需要考虑各种不确定因素的影响,因此建模的难度较大。基于非模型的控制算法,如神经网络控制,需要大量的车辆数据和环境数据进行神经网络训练,但是当前的技术条件很难保证环境数据的采集完整性。缺乏完整的环境数据会导致神经网络学习到不准确的信息,从而使得跟踪效果不佳。为了解决这个问题,科研工作者提出了有出色感知能力与决策能力的深度强化学习。深度强化学习方法是通过与环境不断地交互试错地学习,自主探索控制系统的最优行为。强化学习的算法包括SARSA[24](state action reward state action)、Q-learning[25]、DQN[26](deep Q-learning)、DDPG[27]等。SARSA 是先建立一个Q表格,并通过与环境的交互来更新Q 表格的状态,然后根据Q 表格中的值采取动作,但是SARSA 只能针对一些简单的游戏。Q-learning 与SARSA 类似,Q-learning 的不同点是在更新Q 表格时选择不同的策略,但本质上还是以表格的形式,Q-learning 却是通过Q表格来选择最优。DQN是在Q-learning的基础上,通过引入神经网络代替Q 表格,从而节省了软件空间,但是其不适用于连续空间。DDPG 是一种利于深度函数逼近的策略,它可以在高维度和连续空间中应用,而前3 种算法只适用于低维度、离散的行为空间中。但是在高维度、连续动作的自动驾驶中,DDPG的奖惩机制不能很好地设置。
综合上述分析可知,无论是基于模型还是非模型的路径跟踪控制算法,在路径跟踪过程中的表现都有所不足,主要表现在:
1)基于模型的控制算法在路径跟踪过程中对模型的依赖程度比较高,但是车辆的建模比较困难,这会导致跟踪精度不佳。
2)基于非模型的控制算法需要大量的车辆数据和环境数据以供神经网络学习,而环境数据采集的完整性难以满足,这导致跟踪效果比较差。
针对以上路径跟踪控制算法存在的弊端,课题组提出一种RF-DDPG 路径跟踪控制算法,该算法既不依赖系统精准的数据模型,也不需要大量的环境数据,仅通过车辆与期望路径的横向偏差、车辆的横向角速度等设计奖励函数和自适应权重系数,实现自动驾驶车辆的路径跟踪控制。
2 强化学习模型
2.1 马尔可夫决策过程
强化学习的本质是智能体与环境的交互过程,它可以被看作一个马尔可夫决策过程(Markov decision process,MDP)。MDP 是一个跟时间相关的序列决策过程,下一时刻的状态只取决于当前状态和动作。MDP 定义了一个五元组(S,A,R,P,γ),其中:
S={s1,s2,s3,…},代表车辆的状态;
A={a1,a2,a3,…},代表当前状态下智能体所输出的动作;
R={r1,r2,r3,…},代表当前状态下所输出动作的奖励,具有滞后性;
P=p[st+1,rt|st,at],代表当前状态下st输出动作at转移到下一个状态st+1并拿到奖励rt的概率函数;
γ为折扣因子,且γ∈[0,1]。
2.2 强化学习过程
强化学习过程示意图如图1所示。
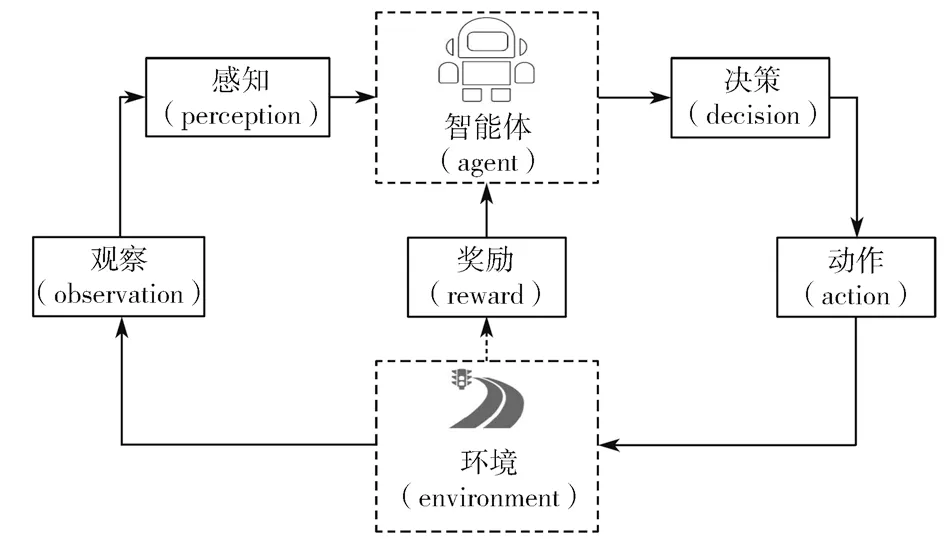
图1 强化学习过程示意图Fig.1 Reinforcement learning process
在强化学习过程中,智能体在每个时间点根据当前的状态参数S给出动作A,然后进入下一个环境状态,给出反馈回报R。然后在记忆池里就会记录一系列的数据(s1,a1,r1,s2,a2,r2,…,st,at,rt),并计算累计回报Gt,其计算式如下:
用π表示智能体的策略,根据当前的状态s选择输出动作a的概率。
用价值函数Q表示当前状态下s采取动作a的价值:
利用贝尔曼方程递归后的价值函数为
式(3)(4)中,E(x)为期望函数。
强化学习的核心任务,就是不断地调整策略,以使得奖励函数值最大化。在强化学习过程中,智能体通过获取奖励函数值最大化来更新策略,策略再给出下一步动作,并且拿到奖励,以此循环,最终达到系统控制目标。
3 轨迹跟踪控制算法
3.1 深度确定性策略梯度算法
DDPG 是一种基于确定性策略梯度的无模型算法,该算法基于Actor-Critic 框架,它可以被应用于连续行为空间中,它由Actor、Actor-target 和Critic、Critic-target 网络构成。其中,Actor 网络的作用是根据环境反馈的状态S输出动作A;Critic 网络的作用是根据环境反馈的状态S和Actor 对应的动作A输出Q值;Actor-target 网络和Critic-target 网络的作用是提高网络的稳定性。网络首先固定自身的参数一段时间,然后通过复制Actor 网络和Critic 网络的参数来更新自己的参数,DDPG 的算法原理框图如图2所示。
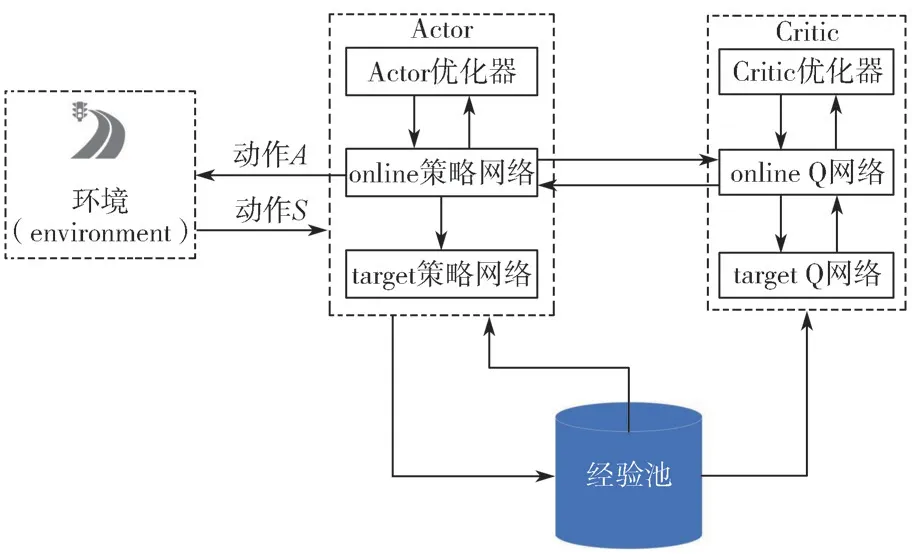
图2 DDPG 算法原理框图Fig.2 DDPG algorithmblock diagram
Actor 网络在状态观测量的基础上,输出对应的决策行为,并且将这些行为参数化为一个包含n维向量θ的策略π。
Actor 网络以策略梯度方法为基础进行更新,通过策略梯度改进策略。
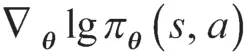
在智能车辆轨迹跟踪控制的学习过程中,Actor神经网络的输入是观测到的环境状态变量,如位置、角度、速度等,其输出是根据策略做出的决策,如方向盘转角和油门刹车等。与此同时,Critic 基于行为价值函数的方法,其输入变量是状态和行为,输出变量是回报值。在学习过程中,Critic 用估计的价值函数作为更新Actor 函数的基准,同时评价Actor 的策略。Actor-Critic 方法的优点在于Critic 通过价值函数提供了更准确的评估,从而改进了Actor 策略,使其更加优化。此外,Actor-Critic 方法不仅可以使用Critic 更新Actor 策略,还可以使用Actor 更新Critic的价值函数,可以更好地评估行为价值。
在实践中,使用如下贝尔曼方程更新Critic 的价值函数:
式中:α为学习率;
Q′为新的价值函数。
Actor 网络更新参数θ采用链式求导得出。
Critic 网络更新参数w取期望值和实际值的均方误差,即
3.2 奖励函数设计
奖励函数的好坏是影响模型结果的关键因素。对于单一任务的智能体都有着明确的奖励目标,故应做到让奖励值最大化。但是在处理复杂的自动驾驶任务中,很难单一明确奖励目标,故本论文拟通过组合的方式来设计奖励函数。
1)路径跟踪能力。本研究中,设计用车辆的质心位置yi与期望轨迹yj的横向距离来描述车辆的跟踪精度。
跟踪精度误差与允许误差之比为Δ1,且
2)速度。R2=Vxcos(θ),其中Vxcos(θ)为车辆沿期望路径方向的速度,在有限的时间和安全的情况下,希望快速完成驾驶任务。
3)车辆稳定性。车辆稳定性主要是由车辆的横摆角速度和质心侧偏角来体现。横摆角速度常采取实际横摆角速度ωp与期望横摆角速度ωt的差值进行描述。
式中:
其中:ωd为横摆角速度上限;
ωdes为稳态转向下的横摆角速度,且ωdes=Gωzss×δ,其中Gωzss为横摆角速度的稳态增益;
δ为转向盘的角度。
横摆角速度误差与期望角速度之比为Δ2,且
同样,质心侧偏角采取实际质心侧偏角βp与期望质心侧偏角βt的差进行描述。
式中:βd为质心侧偏角上限;
βdes为稳态转向下的质心侧偏角,且βdes=Gβzss×δ,其中Gβzss为质心侧偏角的稳态增益。
质心侧偏角误差与期望质心侧偏角之比为Δ3,且
4)转向平稳性。转向的平稳性代表方向盘的震荡程度,这里引入变异系数R5进行描述,且
式中:σ为方向盘转角的标准差;
3.3 自适应权重设计
路径跟踪精度和车辆的稳定性能对自动驾驶路径跟踪控制的影响比较大。当两者不能同时满足时,要确定先处理差距大的那一个指标。本研究设计了自适应权重系数,当跟踪精度误差百分比大于稳定性误差百分比时,跟踪精度的奖励函数权重就会加大,相反亦然。
跟踪精度权重系数为
稳定性权重系数为
跟踪精度权重系数和稳定性权重系数满足如下表达式:
自动驾驶车辆在训练过程中,会出现两种情况:正常行驶和超出车道。正常行驶的奖励函数已经设计完成,超出车道的情况在这里统一设置为0。则奖励函数表达式如下:
4 仿真测试及验证
为了评估本研究中所提出自动驾驶车辆控制方法的优劣,接下来将在apollo 仿真平台上搭建模型,并且对智能车辆在轨迹跟踪过程中采用基于RFDDPG 算法和基于原始的DDPG 算法进行仿真与分析。本文所提出的RF-DDPG 算法基于Actor-Critic网络结构,其中Actor 网络以策略梯度方法更新,根据策略的梯度将策略向更好的方向进行优化。Actor网络的输入为观测量(位置、角度和速度等),输出为控制信号(方向盘转角和油门刹车)。Critic 网络则基于行为价值函数,输入变量为状态和行为,输出变量为回报值,用于评估策略的优劣。与传统的DDPG 算法奖励函数不同,本文的RF-DDPG 算法采用了一种新的奖励函数,这一改进使得算法更加具有鲁棒性和泛化能力。原始DDPG 算法和RF-DDPG算法的评价方式如图3所示。
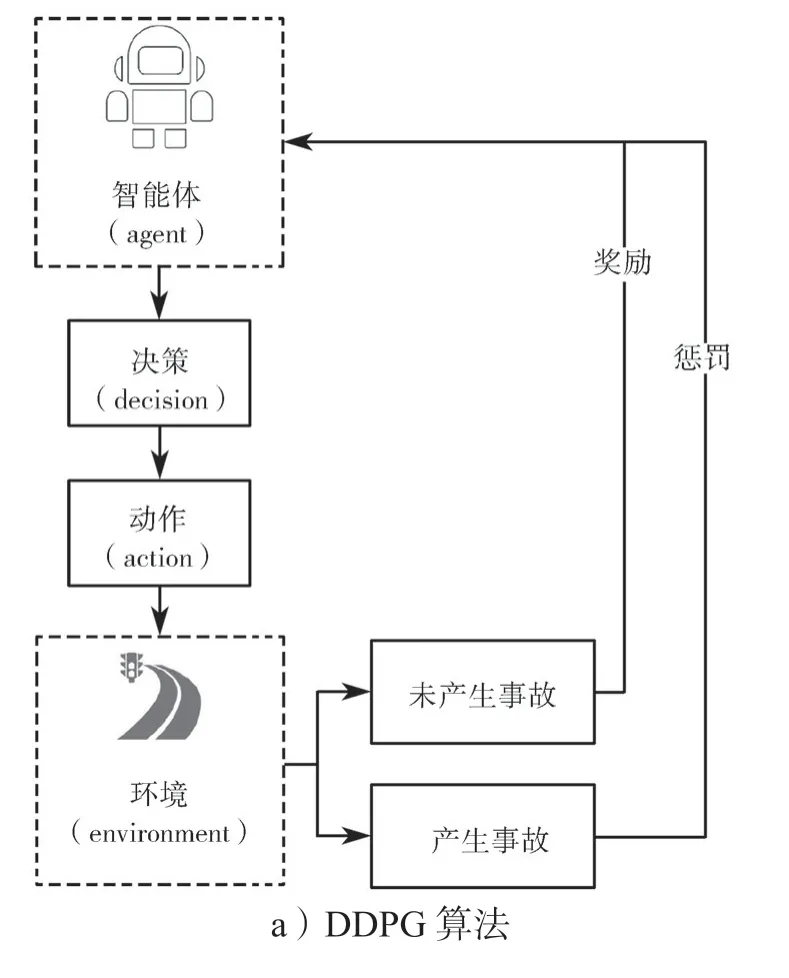
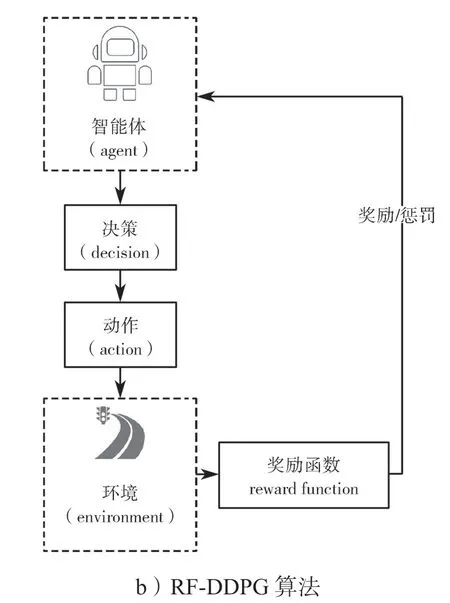
图3 两种算法的评价方式Fig.3 Evaluation method of the two algorithms
图3a 是原始评价算法,可以看出,原始算法对智能车的评价方式只区分了未产生事故和产生事故,训练出来的效果难以达到智能车辆对路径跟踪精度的要求。图3b 是改进后的评价,利用组合方式设计奖励函数,使得评价更加合理,训练后的控制效果也更加精确。
算法改进前后自动驾驶车辆的航向角偏差曲线、横摆角速度偏差曲线、质心侧偏角差曲线,分别如图4~6所示。
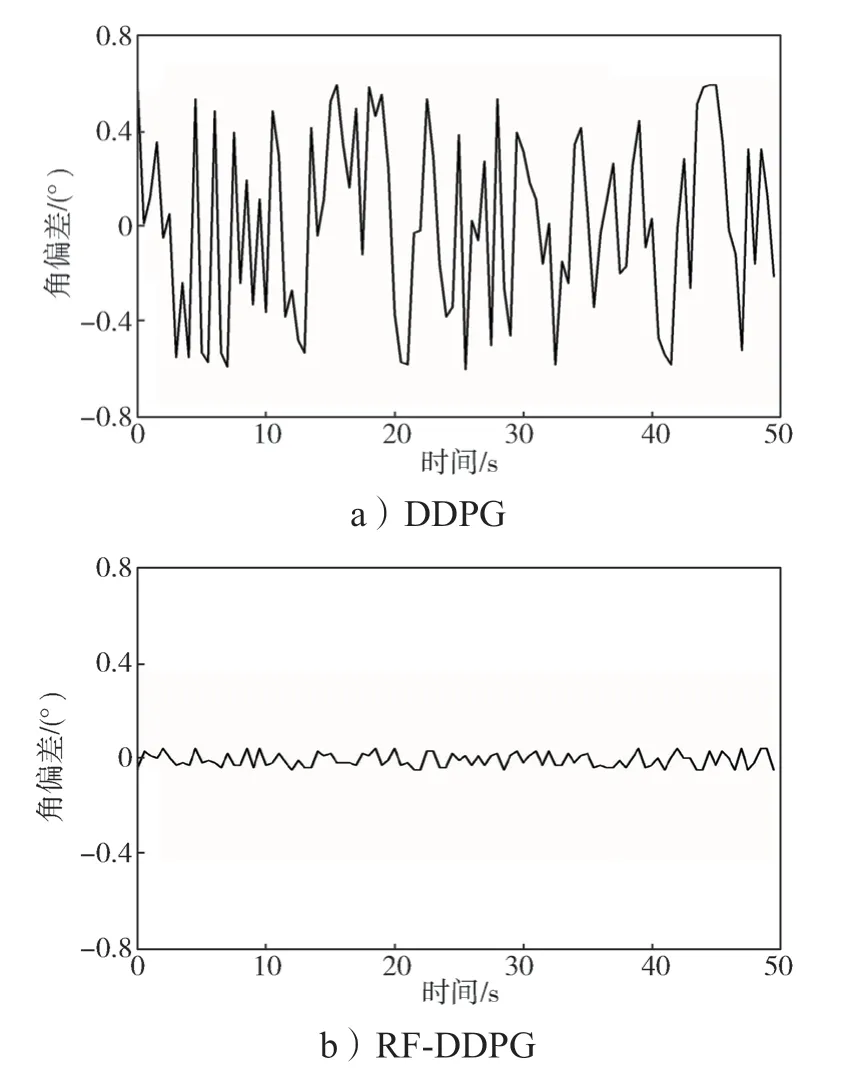
图4 算法改进前后自动驾驶车辆的航向角偏差曲线Fig.4 Heading angle deviation curves of autonomous vehicles before and after an algorithm improvement
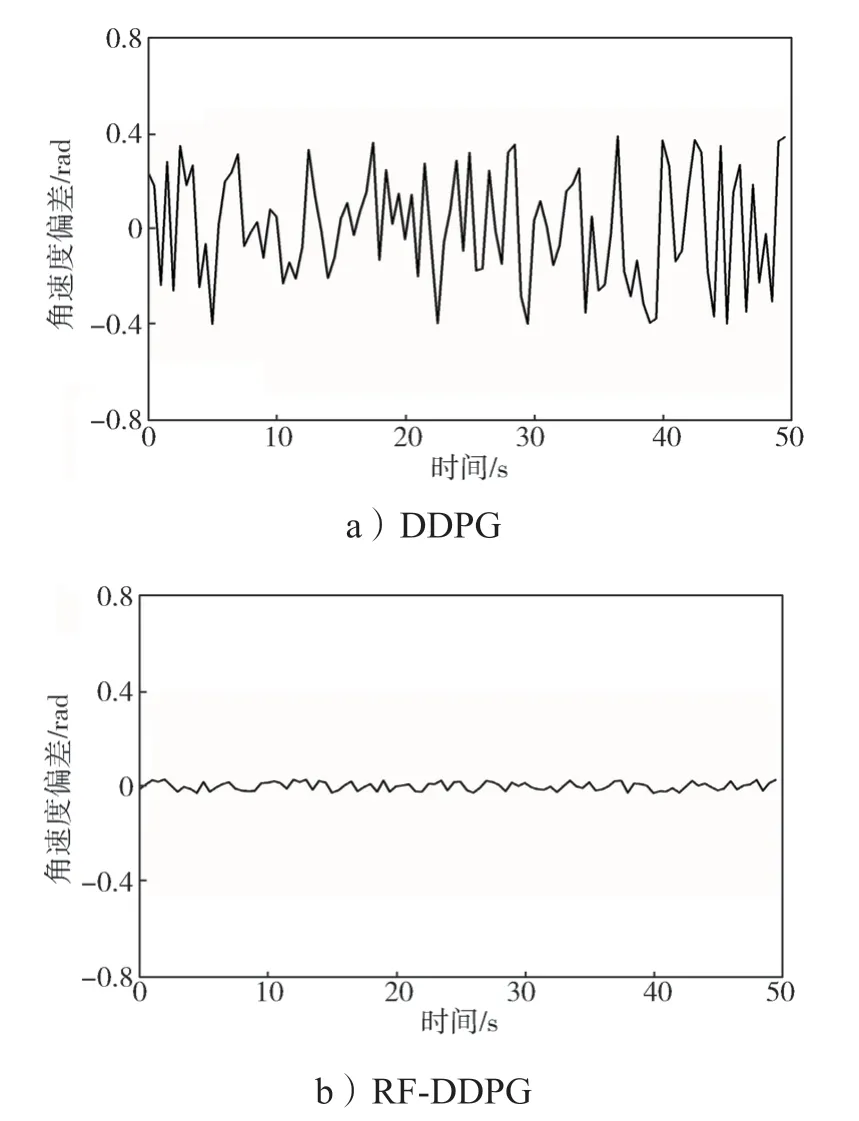
图5 算法改进前后自动驾驶车辆的横摆角速度偏差曲线Fig.5 Yaw rate deviation curves of the autonomous vehicle before and after an algorithm improvement
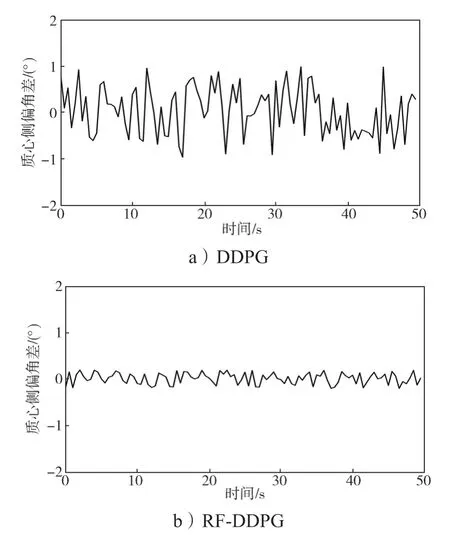
图6 算法改进前后自动驾驶车辆的质心侧偏角差曲线Fig.6 Centroid sideslip angle difference of autonomous vehicles before and after an algorithm improvement
从图4~6 可以看出,采用RF-DDPG 控制算法的自动驾驶车辆在实验过程中的稳定性能明显比采用DDPG 算法车辆的稳定性能高,控制过程更加合理。这不仅验证了本研究对于算法策略输出的改进效果,也说明了本研究的改进方式在仿真环境中拥有良好的泛化性。
图7 是采用RF-DDPG 算法与DDPG 算法的自动驾驶车辆的横向误差对比图。
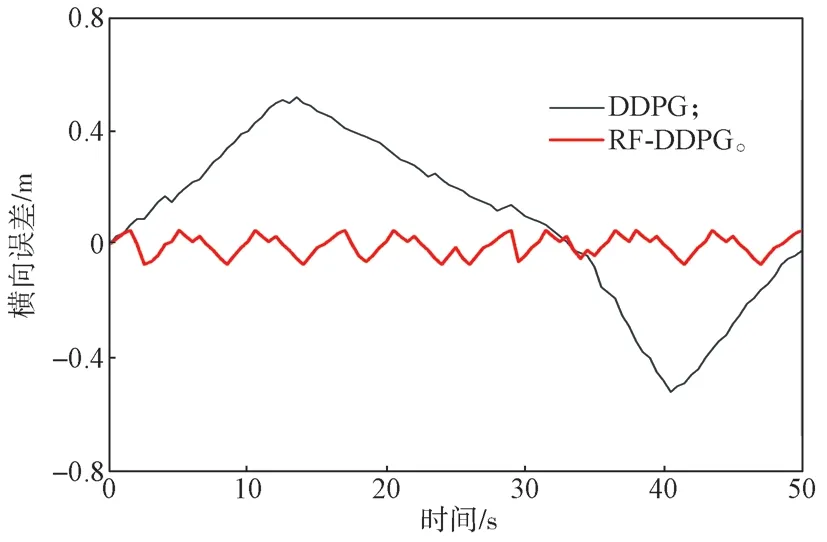
图7 算法改进前后自动驾驶车辆的横向误差对比图Fig.7 Lateral error comparison chart of autonomous vehicles before and after an algorithm improvement
由图7所示采用RF-DDPG 算法与DDPG 算法的自动驾驶车辆的横向误差对比图,同样可以直观地看出,RF-DDPG 控制算法在跟踪精度性能方面表现为比DDPG 算法的跟踪精度更高,控制过程更加合理。
表1 为采用DDPG 和RF-DDPG 控制算法的不同跟踪控制值结果对比,由表1 中的数据可以得出,RF-DDPG 算法的跟踪控制值均优于DDPG 算法的对应值。
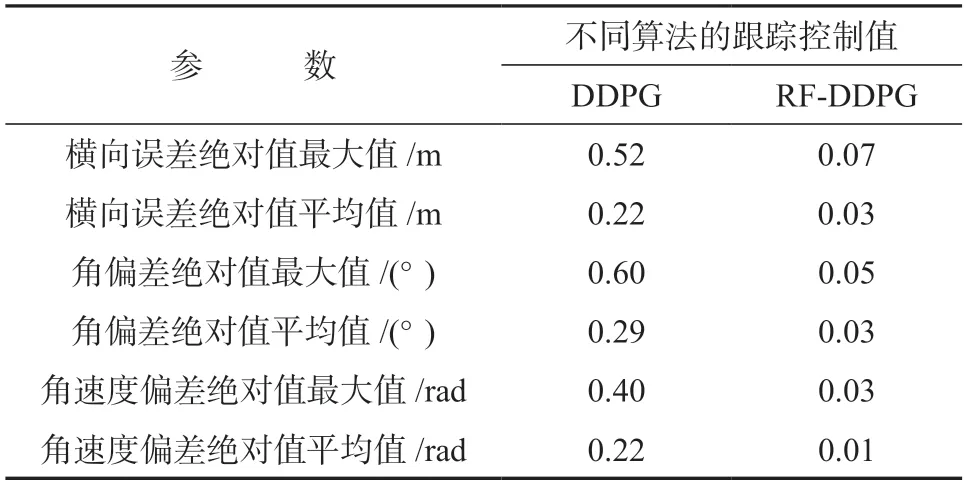
表1 算法改进前后的跟踪控制值对比Table 1 Comparison of tracking control values before and after an algorithm improvement
5 结语
本文以智能车辆为研究对象,采用基于强化学习的方法研究了车辆在跟踪轨迹时的最优控制问题,提出了一种深度确定性策略梯度RF-DDPG 路径跟踪算法,旨在优化车辆的跟踪精度和运行稳定性。该算法在深度强化学习DDPG 的基础上,设计了智能车辆在轨迹跟踪时的奖励函数和自适应权重系数,从而优化了RF-DDPG 的参数。控制器以车辆当前的位置、速度、跟踪路径信息和航向角为输入,输出转向盘转角和油门刹车。并在仿真平台上测试了采用本文提出的算法和基于原始DDPG 算法的智能车辆轨迹跟踪效果。仿真结果表明,相比于基于原始DDPG的强化学习方法,本文提出的基于RF-DDPG 的强化学习方法在跟踪精度和控制效果方面有了显著提高,并保证了车辆行驶过程的安全性和稳定性。
为进一步探究智能车辆轨迹跟踪问题,课题组将继续进行轨迹规划研究,以期将跟踪控制策略应用于所规划的轨迹中,并对轨迹跟踪策略进行仿真验证。在此基础上,进一步完善RF-DDPG 算法,提高其控制精度和鲁棒性。本研究对于智能车辆的自主驾驶和智能交通系统的发展具有重要意义,有望为实现车辆安全行驶和交通流畅提供有效的技术支持。
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代装饰(2018年5期)2018-05-26
小太阳画报(2018年3期)2018-05-14
制造技术与机床(2017年6期)2018-01-19
中国三峡(2017年2期)2017-06-09
阅读与作文(小学低年级版)(2016年12期)2016-12-22
少年博览·小学低年级(2016年9期)2016-11-24
汽车文摘(2015年11期)2015-12-02
电源技术(2015年9期)2015-06-05
