
出版业人工智能大语言模型应用管窥
2024-03-09 10:32秦艳华李一凡闫玲玲符家宁侯玉丽
中国传媒科技 2024年1期
秦艳华 李一凡 闫玲玲 符家宁 侯玉丽
摘要:【目的】探讨人工智能大语言模型在出版业的应用现状和未来发展趋势。【方法】通过搜集整理现有数据和资料,归纳分析大语言模型在出版业的具体应用案例,分析应用中隐藏的问题,并提出针对性解决策略。【结果】研究发现,大语言模型在出版业的应用,既为出版业发展带来了重大机遇,也可能导致“技术异化”的诸多问题。【结论】大语言模型在出版业的应用,从通用型转向专用化、场景化,从高门槛转向简易化、轻量化,从数据分散转向数据协同,将成为趋势,出版业需要以更加开放包容的心态积极拥抱新技术。
关键词:出版;人工智能;大语言模型;ChatGPT 中图分类号:G220 文献标识码:A
文章编号:1671-0134(2024)01-034-07 DOI:10.19483/j.cnki.11-4653/n.2024.01.005
本文著录格式:秦艳华,李一凡,闫玲玲,符家宁,侯玉丽.出版业人工智能大语言模型应用管窥[J].中国传媒科技,2024,31(1):34-40.
2022年11月30日,美国人工智能研究实验室Open AI向全世界公开发布了ChatGPT。这是一款由人工智能技术驱动的自然语言处理工具,它实现了机器学习算法发展中自然语言处理领域的历史性跨越。这一人工智能大语言模型可分析海量的数据,基于特定输入参数生成原创内容且极其类似于人类创作的文本。大语言模型作为当今人工智能技术的最新成果,给出版这一内容产业带来了深远影响和巨大冲击。对大语言模型在出版业的应用现状进行分析,探讨这一技术为出版业发展带来的重大机遇与挑战,提出积极应对之策,并展望其未来前景,对于推动出版业数字化转型升级、实现出版深度融合发展,具有重要的现实意义,也具有长远的战略意义。
1.出版业大语言模型的应用
2023年4月底,世界报业和新闻出版协会(WAN-IFRA)与施希克勒(Schickler)咨询公司联手,针对全球100多位新闻媒体人进行调研,评估新闻媒体使用大语言模型的情况。[1]调查显示,截至2023年5月,约有一半的出版企业正在积极使用ChatGPT或类似工具,70%的人预计这些工具将对记者有极大帮助。目前,国内外出版企业及与出版企业相关的科技公司正在积极探索使用大语言模型为出版业务赋能。
1.1 国外出版业大语言模型的应用
1.1.1 科企研发
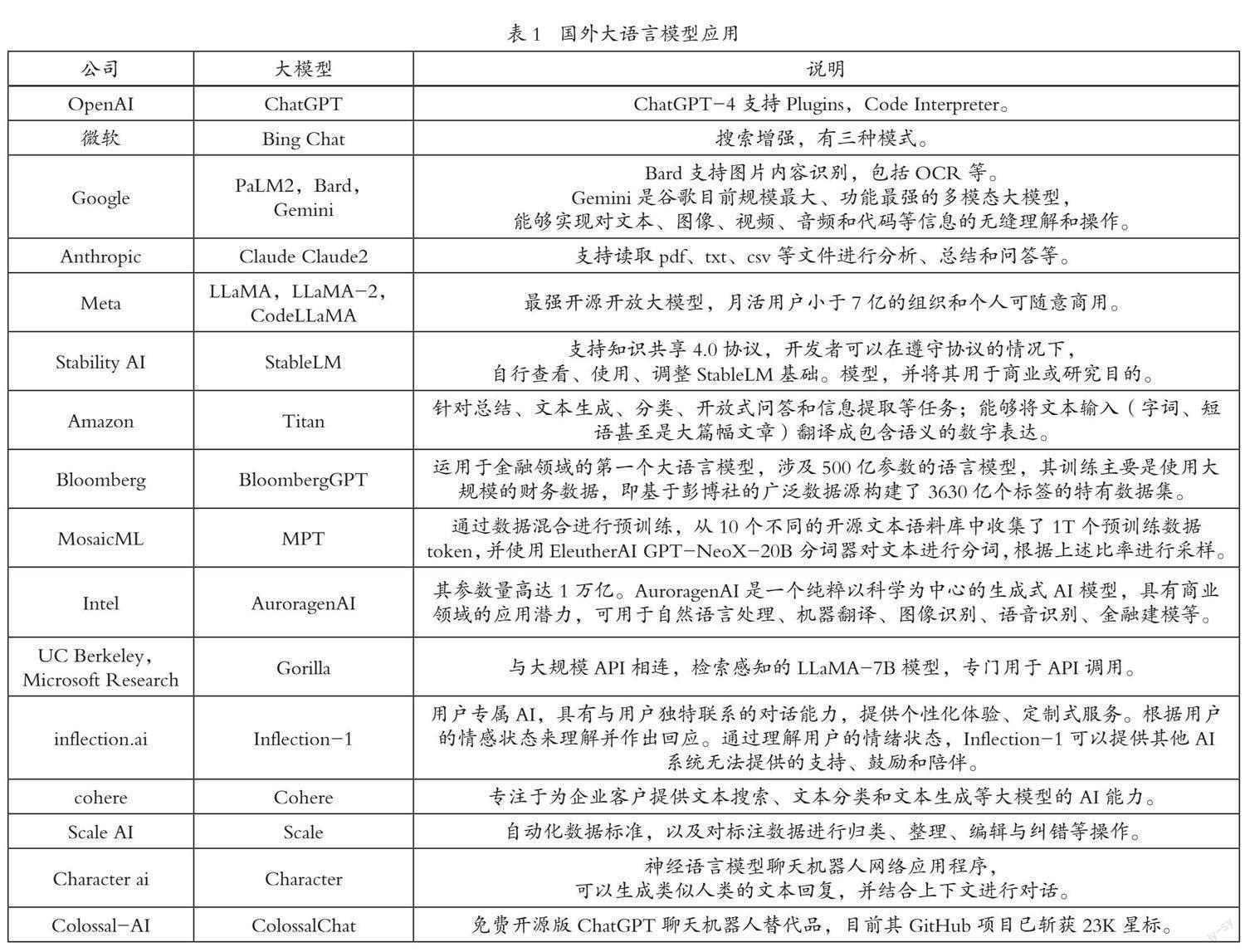
国外已开发的大语言模型不在少数,目前在出版业使用较为广泛的大语言模型如表1所示。
国外的一些大型出版企业纷纷加入到大语言模型开发、应用行列,如美国霍顿·米夫林出版公司(Houghton Mifflin Harcourt)在其写作练习和评估解决方案Writable中,集成OpenAI公司的生成式人工智能能力,为用户提供了更个性化的写作指导和评估;英国麦克米伦教育出版公司(Macmillan Learning)宣布与Packback公司达成合作,把人工智能能力与课程材料相结合;德国斯普林格自然出版公司(Springer Nature)在2023年夏收购了美国的人工智能平台protocols.io,此后,又收购了荷兰的人工智能创新公司Slimmer AI等。
1.1.2 行业应用
在国外,ChatGPT参与图书生产,可以嵌入到内容生成、选题策划、创作编辑、插图设计、有声制作、图书营销等环节中。
内容生成:截至2023年12月21日,在亚马逊官网以“高级检索”方式,检索署名作者为“ChatGPT”的书籍,已有1051本,以“AI”为作者的书籍则更多。以ChatGPT为作者的书籍,主要有自我描摹类工具书,如《ChatGPT入门教程》等、故事小说、基础教材等。“欧洲刑警组织(Europol)”的一份报告预测,到2026年,互联网上多达90%的内容可能是由AI创建或编辑的。[2]这意味着AI将深刻影响出版的内容生产。
选题策划:大语言模型在选题策划中的参与,是通过持续性对话,激发作者灵感,进而协助图书创作。以ChatGPT为代表的大语言模型为作者提供全面细致的选题素材,使作者节省大量案头工作时间。亚马逊kindle平台上架了大量ChatGPT参与编著的书籍,其中不少书籍的选题策划是由ChatGPT单独完成的。选题策划—文本创作—全文校对—编辑出版的全过程,传统书籍或要历时一年以上,但是ChatGPT将这一过程简化,压缩了生产时间,实现了快速上线。不过,需要指出的是,这样的快速生产,是以牺牲伦理与美学为代价的。大语言模型的技术逻辑不可避免地对图书版权和艺术伦理造成威胁,对话式的交流也容易造成对人类思想与文化创造的隐形窃取。
编辑加工:Google團队在2023年2月发布的大语言模型LaMDA驱动的Bard,可以使用较少的计算能力,使其扩展到更多的人并提供反馈。Google首席执行官Sundar Pichai在接受《纽约时报》播客采访时表示,升级版的Bard基于更为强大的模型,在编程能力与逻辑推理能力上有进一步的提升,并在数学运算上有一定突破。紧随其后,Anthropic在3月发布类似ChatGPT的产品Claude,7月升级后的Claude 2的处理能力已经提升到了100K个Token,这意味着它可以处理数百页的技术文档,甚至是整本书。
插图设计:根据内容进行形象创作,设计图书封面与插图,常用的大语言模型有Midjourney AI、Adobe Firefly等。大语言模型对于插图的创作,可以是具象的也可以是抽象的。Alice and Sparkle是作者阿玛尔·雷希(Ammaar Reshi)使用ChatGPT、MidJourney等人工智能工具创作的一本儿童绘本。该书以AI工具绘图被世界各地的媒体广泛报道,但同时也引发了大量负面评论,一些读者指出书中图文不符的情况并不少见。
多语种有声读物制作:微软公司在2023年3月18日发布了一款人工智能工具——VALL.E,它经过了60 000小时英语语音数据的训练,只需3秒的音频样本,就可以模仿人的语音输出。2023年6月,Meta公司声称研制出“迄今功能最强大的语音生成式人工智能Voicebox”,该工具使用了“流匹配”方法,其表现优于当前最先进生成式语音系统使用的扩散模型。据悉,Voicebox能说6种语言:英语、法语、西班牙语、德语、波兰语和葡萄牙语。[3]
营销服务:在图书营销方面,大语言模型可以更好地为读者提供精准服务。如英国的shimmr公司推出的Shimmr.AI突破了传统的推荐算法,利用Trajectory推荐系统来使图书内容与读者阅读偏好双向匹配,通过自动化流程将内容和最合适的读者之间联系起来,强调“书发现读者”的反向可发现性。[4]
1.2 国内出版业大语言模型的应用
1.2.1 科企研發
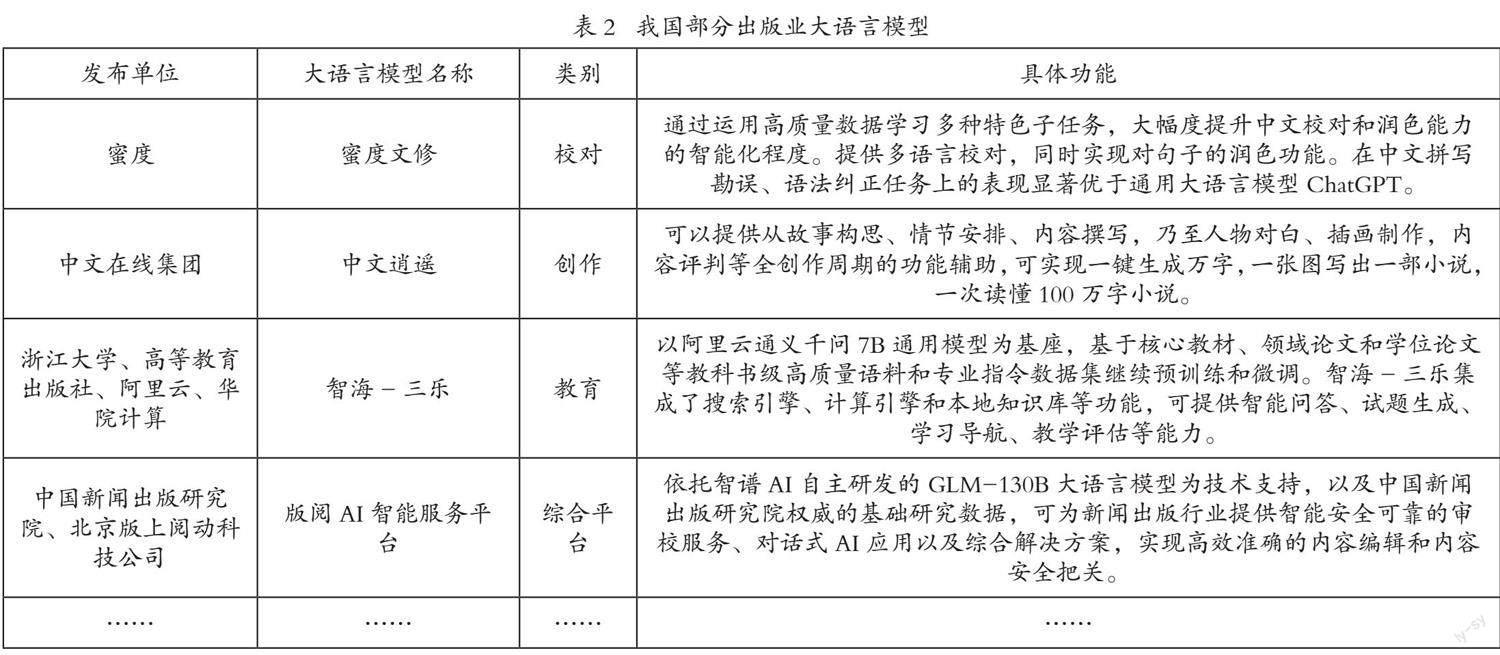
目前国内众多单位和企业都研发了符合自身发展目标的大语言模型,包括通用、工业、科研、商业等多个类型。截至2023年12月21日,据不完全统计,我国共有189个单位研发出202个大语言模型,针对出版业应用的、具有代表性的大语言模型主要有如下几种(表2)。
就出版企业来看,有的引入了科技企业研发的通用大语言模型,有的则自主研发适用于出版业的专业大语言模型。前者如上海报业集团旗下澎湃新闻成为百度“文心一言”的首批体验官,力图打造内容生态人工智能全系产品及服务;苏州新闻出版集团旗下新闻客户端“引力播”也接入“文心一言”大语言模型,期望以此赋能出版流程、模式、内容等众多方面的创新;后者如蜜度公司发布的“蜜度文修”智能校对模型、中文在线集团推出的“中文逍遥”内容创作大语言模型等,在出版的不同环节促进了业务创新。
1.2.2 学界探碛
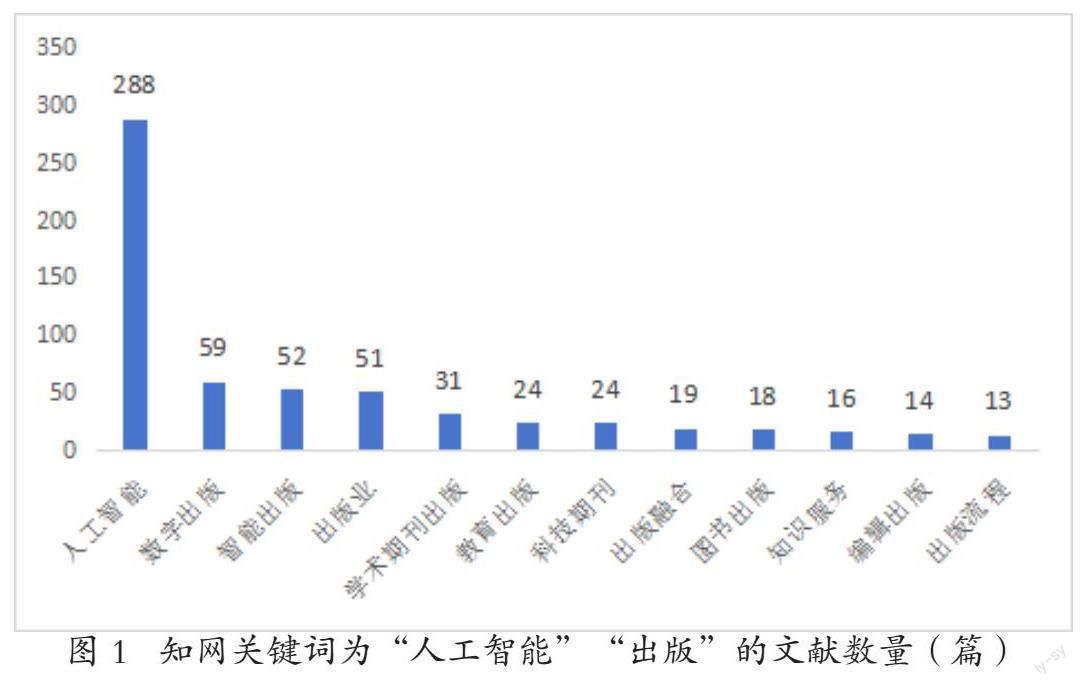
近年来,学术领域对出版业和大语言模型的耦合展开了丰富研究,通过在中国知网中输入“人工智能”“出版”两个关键词,在2023年11月22日抓取2004~2023年间的相关文献,并将关键词进行聚类分析后,整理出结果如图1所示。以“人工智能”“数字出版”“智能出版”为主题的文献大量出现,表明出版界、学术界对于人工智能技术在出版业应用的重视。
随着人工智能技术的不断成熟以及出版业发展战略、发展模式的持续更新,“智能出版”这个概念应运而生。有学者认为智能出版是以智能化的数字技术将作品编辑加工后,经过复制进行传播的新型出版[5]。智能出版是强调数字智能技术并以此为依托作用于出版的整个流程,为内部生产与外部使用提供定制化、自动化、智能化服务的出版新方向,是一个随着技术的革新不断扩充和发展的概念。
1.2.3 行业应用
目前国内出版业对人工智能大语言模型的应用持慎重而乐观的态度,虽然还未将大语言模型完全应用于图书出版全流程,但在部分图书出版环节,比如辅助内容生产、编辑校对、发行营销等方面已有大语言模型应用的探索和实践。
内容生成:大语言模型通过大量语言样本加上人工标注的数据来训练,具有极强的文本生成创作能力,目前主要包括视觉产品创作和听觉产品创作。2023年3月,华龄出版社出版了由人工智能大语言模型生成的图书《ChatGPT:AI革命》。
专攻于听觉方面的大语言模型,也是近年来一个创新性较强的领域,SALMONN就是大语言模型中一个典型的听觉模型,它是清华大学联合字节跳动解锁通用听觉人工智能的大语言模型,具有强大的技术功能和广泛的应用范围,在输入层面,能够感知和理解各种类型的音频内容输入,包括多语言语音识别和翻译以及语音推理等功能;在输出层面,能够胜任英语语音识别、英语到中文的语音翻译、情感识别、音频字幕生成、音乐描述等重要的语音和音频任务,同时可以进行基于音频的故事生成、音频问答、语音和音频联合推理等任务。
在喜马拉雅的TTS(语音合成)技术支持下,2023年第一季度,喜马拉雅AIGC专辑数同比增长354%,是2021年前总量的近3倍。全年,AIGC内容用户播放时长同比增长207%。
编辑校对:当前,大语言模型在一定程度上可以替代人类编辑的部分功能,比如可以检查语法、提供内容摘要、创建通知、为新闻通讯或社交媒体平台量身定制,并将书面内容转换为播客或视频的脚本。尤其是在校对方面,大语言模型得到了较为完善的发展。例如2023年星图比特与果麦文化联合推出AI校审产品,提供对文章错字、语法错误、敏感词错误、网络热词等进行审校排查和分析的相关场景和服务,结合“多审多校”功能全方位提升文本质量,降低差错率。
营销服务:除了内容生成、编辑校对环节外,大语言模型在直达用户的营销服务方面也取得了一些成就。通过大语言模型原理可全面认识和深入学习图书,向读者进行既权威全面、又有差异性和针对性的个性化推荐。读者既可以快速得到一本书的简介,也可以通过输入特定要求获取推荐的书目,从而缩短读者触达图书的路径,具有极大的应用前景。AI大语言模型允许媒体组织为特定读者群体定制内容,可以显著降低出版商的运营成本,简化重复性手动任务,减轻员工工作量。
双向赋能:目前虽然大语言模型对出版行业发挥了较强的创新变革功能,但出版行业也反过来完善了大语言模型训练本身。出版行业有大量权威的文本信息和语料,可以为通用大语言模型训练提供高质量的数据集。出版文本库已经成为众多大语言模型自研单位训练“养料”的可靠来源之一,数量、质量都有较高的保障。
2.新机遇:出版业大语言模型应用引发产业变革
当前,在我国,随着大数据、人工智能等技术的不断发展,出版业将更加深入地应用这些技术以提高出版效率和质量,同时拓展出版物的传播渠道和消费群体。大语言模型引发出版产业变革,对于促进出版深度融合发展具有引领和推动作用。
2.1 政策环境优化
在“十二五”到“十四五”规划期间,国家从宏观层面对人工智能新技术和新产业给予了巨大支持。顶层设计从方向性引导转变为强调实际应用和场景创新,并进一步细化和深化。2016年起,人工智能作为热门领域吸引了众多企业布局。2017年国务院印发《新一代人工智能发展规划》,将人工智能提升至国家战略层面的高度,指出到2025年人工智能基础理论实现重大突破,到2030年我国人工智能理论、技术与应用总体达到世界领先水平,成为世界主要人工智能创新中心。此后,在2021年《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》、2022年《关于支持建设新一代人工智能示范应用场景的通知》等系列文件中,进一步强调并支持人工智能在多行业、多领域的应用发展。国家高度重视人工智能产业的安全可信和伦理秩序,强调规范科技伦理,趋利避害。2023年4月,面对ChatGPT类大语言模型的火热出圈,国家互联网信息办公室及时出臺《大语言模型服务管理办法(征求意见稿)》,进一步促进大语言模型的规范应用和产业整体的高质量发展。
新时代、新技术催生了新的出版生态。在出版业,技术已经渗透到出版全环节、全流程并且越来越发挥着重要作用,政策和规范条例纷纷出台为出版产业善用技术提供了制度保障和方向指引。2022年4月,中宣部印发《关于推动出版深度融合发展的实施意见》中明确提出“加强前沿技术的探索应用”“强化大数据、云计算、人工智能、区块链等技术应用,创新驱动出版深度融合发展”。从对新型出版传播体系的要求可以看出,我国融合出版要形成深度化、体系化、整体化的规模发展,就必须嵌入新媒介技术环境,以适应国家发展需要和时代变革需求。无论是宏观层面的规划指导还是出版细分领域的实施意见,我国在社会层面营造了良好的政策环境,助力人工智能市场及在出版业应用的健康发展。
2.2 催生出版新需求
在图书编辑活动中运用AI技术已不鲜见,AI能够高效完成图书内容的加工整理、图片识别、输出格式转换、智能翻译、内容查重和语音交互等任务。[6]目前,大语言模型已经尝试运用于出版各流程中,大语言模型的突出能力与编辑日常工作紧密贴合,可以有效帮助编辑提高工作效率,提升编辑生产力,不仅能够成为选题策划的辅助手段,为编辑把握用户需求、发掘适宜作者等提供更为准确的参考,而且可以成为书稿审校的得力助手,还可以成为提升翻译质效的宝贵工具,产生比传统机器翻译更自然、准确的回应和比译者更高的效率,有效帮助图书编辑将外语图书迅速转换为本土语言出版。
大语言模型为出版业跨模态生产提供了进一步的可能,有望提升出版产品创新力。在日常生活中,视觉和语言是最常见且重要的两种模态。然而,大语言模型若只能生成单一模态的内容,将使应用场景极为有限,不足以推动内容生成方式的革新。大语言模型产业生态当前已经在文本、音频、视频等多模态交互功能上持续演化升级,奠定了多场景的商用基础。多款大语言模型具备了跨模态、跨语言的深度语义理解与生成能力,为出版业提供了更多的可能性。在大语言模型生成文本的基础上,跨模态生成技术有望进一步帮助出版方迅速打造以纸质图书为主、融合一种乃至多种媒体形式和技术形成的融媒图书,增强图书的趣味性和读者沉浸感,真正实现出版的深度数字化转型。
2.3 赋能营销推广
首先,大语言模型可充当引流工具。大语言模型在国内外已经收割了相当规模的流量,收获了一定的关注热度。其问答和多轮对话形式激发了大众的热情和创造力,许多网友尝试使用ChatGPT并发文分享使用体验,刷屏社交平台。出版商可以将大语言模型技术整合融入自身产品中,提升用户满意度,还能够将其作为引流工具,为用户开辟大语言模型新的使用入口,增加自身品牌、产品的吸引力和曝光度。
其次,大语言模型可优化营销方案。大语言模型能够利用其海量级的数据训练成果,预测出版商拟定的营销方式将产生的实际效果,帮助出版商以低成本获得营销方案的最优解,实现精准有效的营销。此外,出版商还可以通过输入聚焦特定用户的营销与推广的需求,借助大语言模型生成个性推广文案,提高自身关注度。
最后,大语言模型可提升出版物的可发现性。大语言模型具备强大的问答服务与文本分析能力,通过分析提取出图书文本的内容关键词等“DNA”,可以帮助出版商实现搜索引擎优化(SEO),提升图书搜索与读者需求之间的适配度,从而增加读者在网络上发现该出版物的可能。这大大减轻了图书营销人员的推广压力,使他们能够为长尾效应中的作者与作品负责,而非只专注于那些头部热门书籍,从而保持良好的出版发展生态。
2.4 提高媒介人性化
补偿性媒介(Remedial Medium)是由保罗·莱文森提出的,认为每一种媒介都是对前一种媒介的革新,这种革新都补偿了其原先的不足。[7]媒介演化的历史就是媒介补偿的历史。人工智能大语言模型以高精度、高流畅的文本响应模拟了从“人—机”到“人—人”的对话情景,体现出媒介发展“以人为本”的底层逻辑,充当了补偿媒介的角色,主要体现在两方面:一方面,提供情感需求补偿。[8]例如,将大语言模型应用于出版社的客服沟通环节,可对读者提问输出内容的语气、情感进行检测,并以与人类高度相似的知识理解水平与语言表达反馈,增加交流感与信任感,可以给予读者情感和心理层面的补偿;另一方面,提供精细化信息分发补偿。传统的算法分发机制通过机器抓取用户数据后描绘用户画像,进而提供个性化内容,但这种机制更多是针对某一类用户进行内容分发,而大语言模型则是以单个用户为核心,在与特定读者的交流过程中不断学习,提供更智能化的语义识别使其能够提供精准且流畅的回答,满足读者的使用需求与期望,增加读者黏性。通过分析读者阅读习惯、阅读要求等对图书内容进行个性化解析,大语言模型可以帮助读者理解庞大、复杂的文本结构,提高阅读效率。
3.新挑战:出版业应用大语言模型面临的问题與对策
出版业大语言模型应用展现出机遇与挑战并存的态势。大语言模型在图书出版业的应用已经呈现出一些亟须解决的问题,需引起警惕与深思。
3.1 出版业应用大语言模型存在的问题
在创作层面,创作者过分依赖技术可能带来“异化”。“异化”的本意为疏远、脱离、转让、向他者转化等,在一般意义上,异化是指人的活动及其产物对人的目的的背离。[9]大语言模型为出版业带来深刻变革的同时,也有可能在一定程度上将创作者异化为“单向度的人”。这种异化主要体现在两方面:自主性的剥夺和创新性的丧失。大语言模型帮助创作者在短时间内获取大量自己所需要的信息,这是其优势之处,但其提供的信息也具有它固有的思考逻辑,从而影响创作者的思维方式。同时,信息内容甚至是写作思路的“伸手即来”,容易在一定程度上加深创作者对机器人的依赖,久而久之将会使其懒于深度思考和创造新内容,极大地限制了创作者的想象力。当技术成为创作者实践活动的主宰时,会潜移默化地操纵其行为与意识,使创作者不再自主自由,甚至甘愿成为技术的奴隶。异化是新技术发展过程中必须审慎看待的哲学问题和文化问题,创作者的异化将对以“内容为王”的出版业产生巨大的负面影响。
在内容生成层面,质量参差不齐,艺术性存在隐忧。AI幻觉在学界并无明确的定义,其概念可理解为:人们过度信任与依赖人工智能所生产的信息,并未考虑其信息的正确性,AI产出的错误性信息流入大众信息网络造成的虚假信息与幻觉现象。提高AI模型的输出真实性,避免AI“异想天开”,成为重要且紧迫的问题。同时人工智能是基于技术逻辑的内容生成,生成的某些抽象派的作品只是色块的拼接,不具有原创作品的一体化的风格,也几乎不可能具备很高的艺术意义和教养价值。该类“作品”在根源上背离了艺术创作的初衷。当一个社会的艺术创作大多数是由冷冰冰的机器生成时,艺术市场将会迎来一场破坏性的变革,整个社会的文化发展亦存在隐忧。
在社会保障层面,相关法律亟待完善,应用失衡将引发新的数字不平等。大语言模型产出的作品进入市场后,版权问题突出。国外法律依据判例法,此前相关条文无法作为判定大语言模型创作产品版权纠纷的依据。而在我国,即使关于人工智能创作的作品依照相关文件精神判定,但是依旧缺乏体系成文的法律效力对人工智能创作的作品进行标准化的保护与规范。此外,大语言模型的应用失衡也带来新的社会问题。以出版社为例,头部出版社聚集着大量的优质资源,具备雄厚的资金支持,有助于促进出版社工作人员的数字素养进修和大语言模型的应用。在技术参与的助力下,无论是出版内容上的多样性,还是出版过程的审核校对均具有层级性的提高,进一步加大了出版社之间因技术而造成的生产力差距。
3.2 解决对策
和谐人机关系、加强审核监管、完善法治建设等,是应对新挑战的有效对策。
3.2.1 明确人机主次,实现协同发展
大语言模型为创新出版业态、传播方式和运营模式提供了良好契机。在知识生产方式的重大变革中,面对人机协同的模式,需要进一步明确人与技术的主次关系。无论技术的更新还是社会的变迁,始终都是“以人为中心”的,人的各方面素养都亟须提升。面对人可能被大语言模型异化的困境,应该回归人的主体性,提高人在数智时代的媒介使用素养,以平衡好人和机器之间的关系。
在政府层面,应注重对全社会的人工智能普及教育,缩小大语言模型使用层面的数字鸿沟。近年来有学者提出了数智鸿沟的概念,比之前的“信息沟”和“数字鸿沟”更进一步,认为在当前智能化背景下,存在着很多被边缘化而不自知的隐形“数智难民”,他们无法享受大语言模型带来的时代红利。政府应肩负起引领的责任,采取各种措施帮助弱势群体缩小数字鸿沟,如颁布前瞻性政策法规,加强出版行业从业者的职业培训,完善数字基础设施,加强对大语言模型知识的宣传普及教育等。
3.2.2 加强审核监管,提升编辑素养
智能技术应用于出版,使得出版生态、出版产品形态等都发生了重大变化。大语言模型传播错误信息,有可能使出版失去其基本功能。因此,ChatGPT类大语言模型不断进行技术发展与迭代更新的同时,也亟须监管技术的研发。对大语言模型的产出进行内容审核与纠正把关,对其可能涉及的个人隐私信息以及侵权内容进行拦截输出,这在提升大语言模型产出质量的同时,还能进一步保护人的权利。以不侵犯他人权利为前提,在输出内容正确的基础上,大语言模型的创作才更具有创造产出的价值意义。
大语言模型所产生的幻觉需要人来纠偏,出版业编辑的把关人位置显得尤为重要,对编辑职业素养也提出了更高要求。智能时代的编辑职业素养既表现为对编辑基本素养如职业道德修养、文化知识水平、社会交往能力等的继承和发扬光大,又表现为在面对和应用智能技术时的科学精神、技术素养等。
大语言模型的高效输出源于对数据库中信息的人工标记与智能标记。在图书出版业、有声阅读市场、影视制作行业,加速研发大语言模型信息识别的标记技术,提升信息识别的准确性,并进行细致化的识别—分类—管理—应用,为大语言模型提供信息明确的数据库,也能进一步提升创造产出质量,避免不相关的信息元素混入以及虚假信息、垃圾信息、过时信息等不良信息的干扰。
3.2.3 完善法律保护,增强权利意识
大语言模型由人类研发,目的是便捷人类的生活,因此人始终是技术发展的核心。当人的权利受到技术的侵犯时,必要的法律保护与相关完善完备的法制体系建设迫在眉睫。针对大语言模型的创作管理办法,以及处理大语言模型产出作品的版权纠纷的法律依据等,都需要引起相关部门重视,并加速推进立法。
大语言模型的问世在刺激人们的责任意识的同时,也刺激了人们的权利意识与专业意识的进一步提升。一方面,重视人类主观创造的权利意识。在大语言模型的智能威胁下,人类灵活应用工具的同时,也更加注重人类思想的创新表达与传播。另一方面,对自身专业领域的深入研究意识得到进一步加强。大语言模型数据库的繁杂和高密度的预训练,带来的是广泛的知识基础而不是“专精深”的知识体系。因此,人类在使用ChatGPT类大语言模型时,更应注重自身对细分领域专业素质的培养。[10]
4.新方向:出版业应用大语言模型的未来趋势
从通用型转向专用化、场景化。通用型是指适用于多领域和任务的大语言模型,专用型则是大语言模型被设计专用于特定领域或特定任务场景。未来,大语言模型将有望与出版业深度融合,增强专业性,实现通用型和出版专业型大语言模型并行发展,满足出版多种场景需求。传统模型往往只能针对性地支持单一类模态,而在通用型大语言模型从“单模态”转向“多模态”发展的基础上,出版专用大语言模型通过预训练和专用预训练实现业务场景应用,将能够更好地满足多样化的出版形态,促进垂直领域进一步发展。
从高门槛转向简易化、轻量化。大语言模型的简易化发展将实现以最简单便捷的操作实现数据的随时提取与生成,满足用户需求。这意味着出版专用大语言模型将为作者提供更加直观友好的创作工具,为编辑提供更多自动化功能,为用户提供更多个性化定制服务。另一方面,成本压力促使大语言模型朝轻量化发展。大语言模型的特点为大数据、大任务和大参数,因此训练大语言模型需要较高计算资源和计算成本。大语言模型应用于专业领域必须实现其轻量化,降低成本开销。
从数据分散转向数据协同。大语言模型已经在技术上实现内容的有效产出,但这一产出行为依赖庞大的数据资源。目前专门针对出版业的数据库规模较小[11],这会使出版业在图书推荐、精准营销等方面面临“冷启动”问题——因缺乏预训练所需的规模数据资源,无法让出版专用大语言模型成功搭建并良好运转。专用型大语言模型的发展是大势所趋,这意味着在未来各个出版企业需要从数据分散转向数据协同。通过集中数据,可以获得更多的数据样本,从而提高模型的准确性和可靠性。出版企业之间的合作和信息共享,会提高整个行业的效率和竞争力。基于数据协同、数据隐私和安全问题、数据格式和标准的统一性等问题也将得到重视与解决。
结语
大语言模型的出现为出版业带来了重大发展机遇,其在出版实践中的应用,包括文本生成、自动翻译、校对排版、营销推广等,已初显成效,节省了大量的人力和物力成本。但不可否认,它也给传统出版业带来生成内容过剩、加剧数字鸿沟等的负面冲击。
出版业需要以更加開放包容的心态积极拥抱新技术,将大语言模型与出版业务相结合,发挥各自的优势形成新的发展优势。此外,出版专用型大语言模型的搭建也为聚合开发者、高校、实验室、出版企业等多方资源提供了契机,在促进学术研究和技术应用普及的同时,重塑新的出版生态。
参考文献:
[1] Dean Roper.Gauging Generative AIs Impact in Newsrooms[EB/OL].(2023-5-24)[2023-11-22].https://wan-ifra.org/insight/gauging-generative-ais-impact-in-newsrooms.
[2] 3年内90%网络内容或由AI编制,科技大公司如何阻止虚假信息?[EB/OL].(2023-6-6)[2023-12-26].https://m.thepaper.cn/newsDetail_forward_23374311.
[3] 赵秋玥.迄今最复杂人工智能语音模型创建[EB/OL]. (2023-6-26)/[2023-12-26]. http://www.news.cn/tech/20230626/9e1a7807acc54f2c868a71b776d986b3/c.html.
[4] Artificial Intelligence:Threat,Opportunity,and Shimmr[EB/OL].(2023-7-31)[2023-11-22].https://publishingperspectives.com/2023/07/ai-building-shimmr-on-the-threat-opportunity-continuum.
[5] 张新新,齐江蕾.智能出版述评:概念、逻辑与形态[J].出版广角,2021(13):21-25.
[6] 武菲菲.人工智能技术与出版行业的融合应用[J].出版广角,2018(1):26-28.
[7] [美]保罗·莱文森.软利器:信息革命的自然历史与未来[M].何道宽,译.上海:复旦大学出版社,2011:91.
[8] 秦艳华,闫玲玲,李一凡.媒介可供性视角下大语言模型ChatGPT应用于出版业的对策研究[J].出版与印刷,2023(3):20-30.
[9] 何士清,徐勋.科技异化及其法律治理:基于以人为本的视角[M].北京:中国社会科学出版社,2010:45.
[10] 段佳宇,郑汝可,李倩.人机协作背景下AI对新闻业人才培养带来的改变与挑战[J].中国传媒科技,2023(8):14-19.
[11] 谢泽杭,李武.从赋能到融合:生成式AI出版的价值、困境与发展图景[J]. 编辑学刊,2023(6):13-19.
作者简介:秦艳华(1965-),女,山东烟台,教授,博士生导师,国家新闻出版署重点实验室“出版业用户行为大数据分析与应用重点实验室”主任,北京师范大学新闻传播学院,研究方向为新媒体研究、编辑出版;李一凡(1995-),女,山西阳泉,博士研究生,北京师范大学新闻传播学院,研究方向为新媒体研究、编辑出版;闫玲玲(1995-),女,河北邯郸,博士研究生,北京师范大学新闻传播学院,研究方向为新媒体研究、编辑出版;符家宁(1997-),女,河南信阳,博士研究生,北京师范大学新闻传播学院,研究方向为新媒体研究、编辑出版;侯玉丽(2001-),女,河南焦作,硕士研究生,北京师范大学新闻传播学院,研究方向为新媒体研究、编辑出版。
(责任编辑:李净)
猜你喜欢
印刷工业(2020年4期)2020-10-27
文苑(2020年4期)2020-05-30
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小学生作文(中高年级适用)(2018年3期)2018-04-18
小康(2017年16期)2017-06-07
华北电力大学学报(社会科学版)(2016年4期)2016-12-01
新闻传播(2016年23期)2016-10-18
南风窗(2016年19期)2016-09-21
出版与印刷(2016年1期)2016-01-03
